조직은 Salesforce와 같은 협업 문서 작성 솔루션을 사용합니다. 경구 실시간 협업 문서를 Salesforce 레코드에 포함합니다. Quip은 기업이 함께 작업하는 방식을 혁신하는 Salesforce의 생산성 플랫폼으로 모든 장치에서 안전하고 간단하게 최신 공동 작업을 제공합니다. Quip 리포지토리는 협업 문서 및 워크플로의 형태로 귀중한 조직 지식을 캡처합니다. 그러나 이 조직 지식을 Box 또는 아마존 단순 스토리지 서비스 (Amazon S3), 어려울 수 있습니다. 또한 협업 워크플로우의 대화형 특성은 정보가 여러 위치에 조각나고 분산되어 있기 때문에 기존의 키워드 기반 검색 방식을 비효율적으로 만듭니다.
이제 아마존 켄드라 Quip 리포지토리에서 메시지 및 문서를 검색하기 위한 Quip용 커넥터. 이 게시물에서는 기계 학습으로 구동되는 Amazon Kendra의 지능형 검색 기능을 사용하여 Quip 리포지토리에서 필요한 정보를 찾는 방법을 보여줍니다.
솔루션 개요
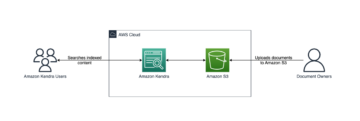
Amazon Kendra를 사용하면 여러 데이터 소스 문서 저장소 전체에서 검색할 수 있는 중앙 위치를 제공합니다. 솔루션의 경우 Quip용 Amazon Kendra 커넥터를 사용하여 Quip 리포지토리를 검색 인덱스의 데이터 원본으로 구성하는 방법을 보여줍니다.
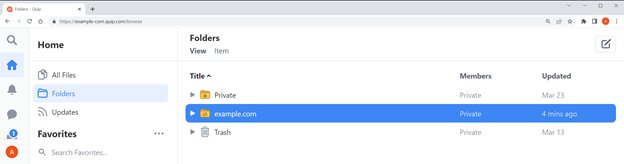
다음 스크린샷은 Quip 리포지토리의 예를 보여줍니다.

이 예의 작업공간에는 공유되지 않는 개인 폴더가 있습니다. 해당 폴더에는 비용 영수증을 보관하는 데 사용되는 하위 폴더가 있습니다. example.com이라는 또 다른 폴더는 다른 사람과 공유되며 팀과 협업하는 데 사용됩니다. 이 폴더에는 개발 문서가 들어 있는 XNUMX개의 하위 폴더가 있습니다.
Quip 커넥터를 구성하려면 먼저 Quip 리포지토리의 도메인 이름, 폴더 ID 및 액세스 토큰을 확인합니다. 그런 다음 Amazon Kendra 인덱스를 생성하고 Quip을 데이터 소스로 추가하기만 하면 됩니다.
사전 조건
Amazon Kendra용 Quip 커넥터 사용을 시작하려면 Quip 리포지토리가 있어야 합니다.
Quip에서 정보 수집
Quip 데이터 소스를 설정하기 전에 리포지토리에 대한 몇 가지 세부 정보가 필요합니다. 미리 모아두자.
도메인 이름
도메인 이름을 찾으십시오. 예를 들어 Quip URL의 경우 https://example-com.quip.com/browse, 도메인 이름은 quip. 조직에서 SSO(Single Sign-On)가 설정된 방식에 따라 도메인 이름이 다를 수 있습니다. 나중에 사용할 수 있도록 이 도메인 이름을 저장하십시오.
폴더 ID
Quip의 폴더에는 연결된 고유 ID가 있습니다. 올바른 폴더 ID를 제공하여 올바른 폴더에 액세스하도록 Quip 커넥터를 구성해야 합니다. 이 게시물에서는 폴더를 인덱싱합니다. example.com.
폴더의 ID를 찾으려면 폴더를 선택합니다. 폴더 ID를 표시하도록 URL이 변경됩니다.

이 경우 폴더 ID는 xj1vOyaCGB3u. 스캔할 폴더 ID 목록을 작성하십시오. 커넥터를 구성할 때 이러한 ID를 사용합니다.
액세스 토큰
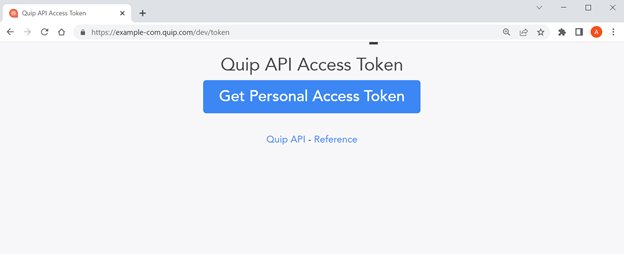
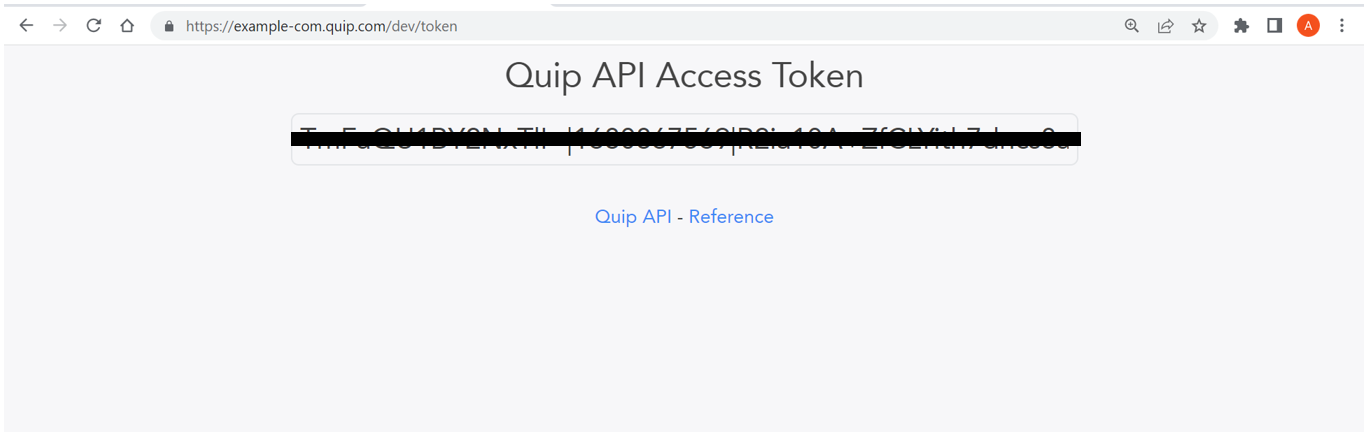
Quip에 로그인하여 열기 https://{subdomain.domain}/dev/token 웹 브라우저에서. 다음 예에서는 다음으로 이동합니다. https://example-com.quip.com/dev/token. 그런 다음 개인 액세스 토큰 받기.
이후 단계에서 사용할 토큰을 복사합니다.
이제 데이터 원본을 구성하는 데 필요한 정보가 있습니다.
Amazon Kendra 인덱스 생성
Amazon Kendra 인덱스를 설정하려면 다음 단계를 완료하십시오.
- 에 로그인 AWS 관리 콘솔 Amazon Kendra 콘솔을 엽니다.
Amazon Kendra를 처음 사용하는 경우 다음 스크린샷이 표시됩니다.
- 왼쪽 메뉴에서 색인 만들기.
- 럭셔리 색인 이름, 입력
my-quip-example-index. - 럭셔리 상품 설명, 선택적 설명을 입력하십시오.
- 럭셔리 IAM 역할, 기존 역할을 사용하거나 새 역할을 만듭니다.
- 왼쪽 메뉴에서 다음 보기.

- $XNUMX Million 미만 액세스 제어 설정, 고르다 아니 모든 사용자가 모든 인덱싱된 콘텐츠를 사용할 수 있도록 합니다.
- 럭셔리 사용자 그룹 확장, 고르다 없음.
- 왼쪽 메뉴에서 다음 보기.

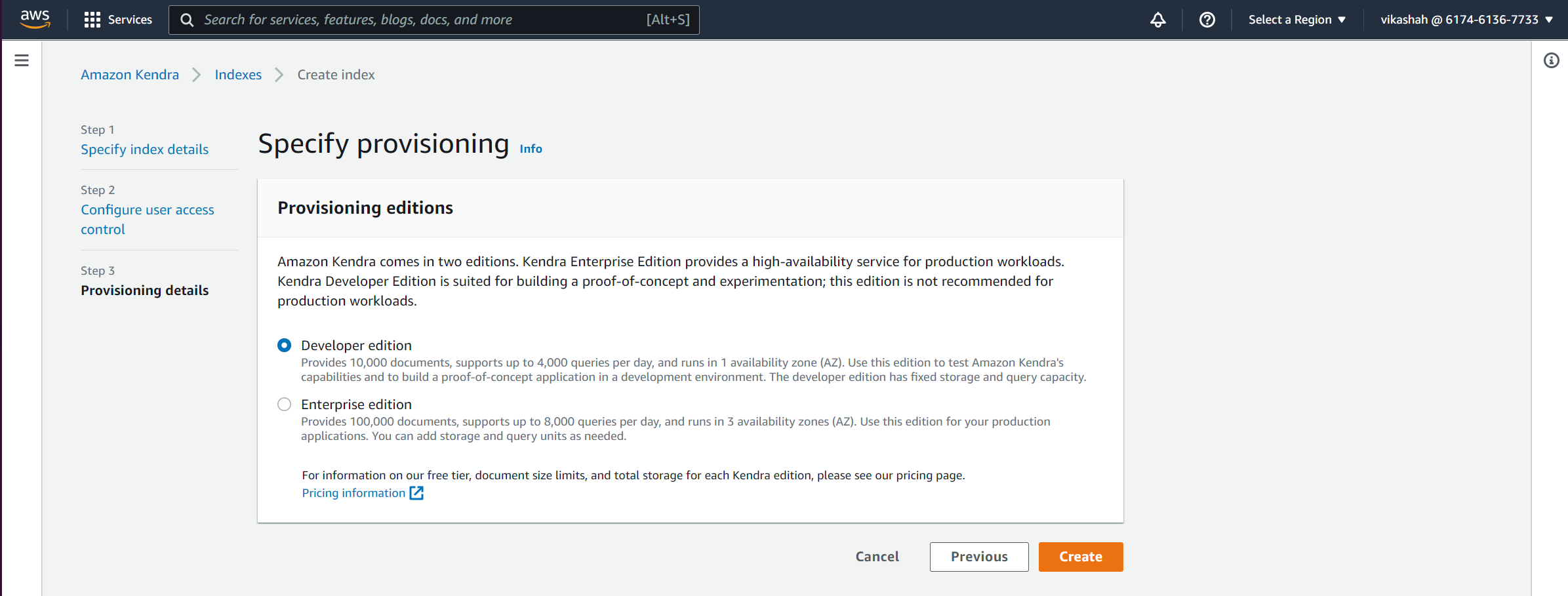
럭셔리 프로비저닝 에디션, 콘텐츠의 양과 액세스 빈도에 따라 두 가지 옵션 중에서 선택할 수 있습니다.
- 이 게시물의 경우 개발자 에디션.
- 왼쪽 메뉴에서 만들기.
역할 생성에는 약 30초가 걸립니다. 인덱스 생성에는 최대 30분이 소요될 수 있습니다. 완료되면 Amazon Kendra 콘솔에서 인덱스를 볼 수 있습니다.

Quip을 데이터 소스로 추가
이제 Quip을 인덱스에 데이터 소스로 추가해 보겠습니다.
- Amazon Kendra 콘솔에서 데이터 관리 탐색 창에서 데이터 소스.
- 왼쪽 메뉴에서 커넥터 추가 아래에 경구.

- 럭셔리 데이터 소스 이름, 입력
my-quip-data-source. - 럭셔리 상품 설명, 선택적 설명을 입력하십시오.
- 왼쪽 메뉴에서 다음 보기.
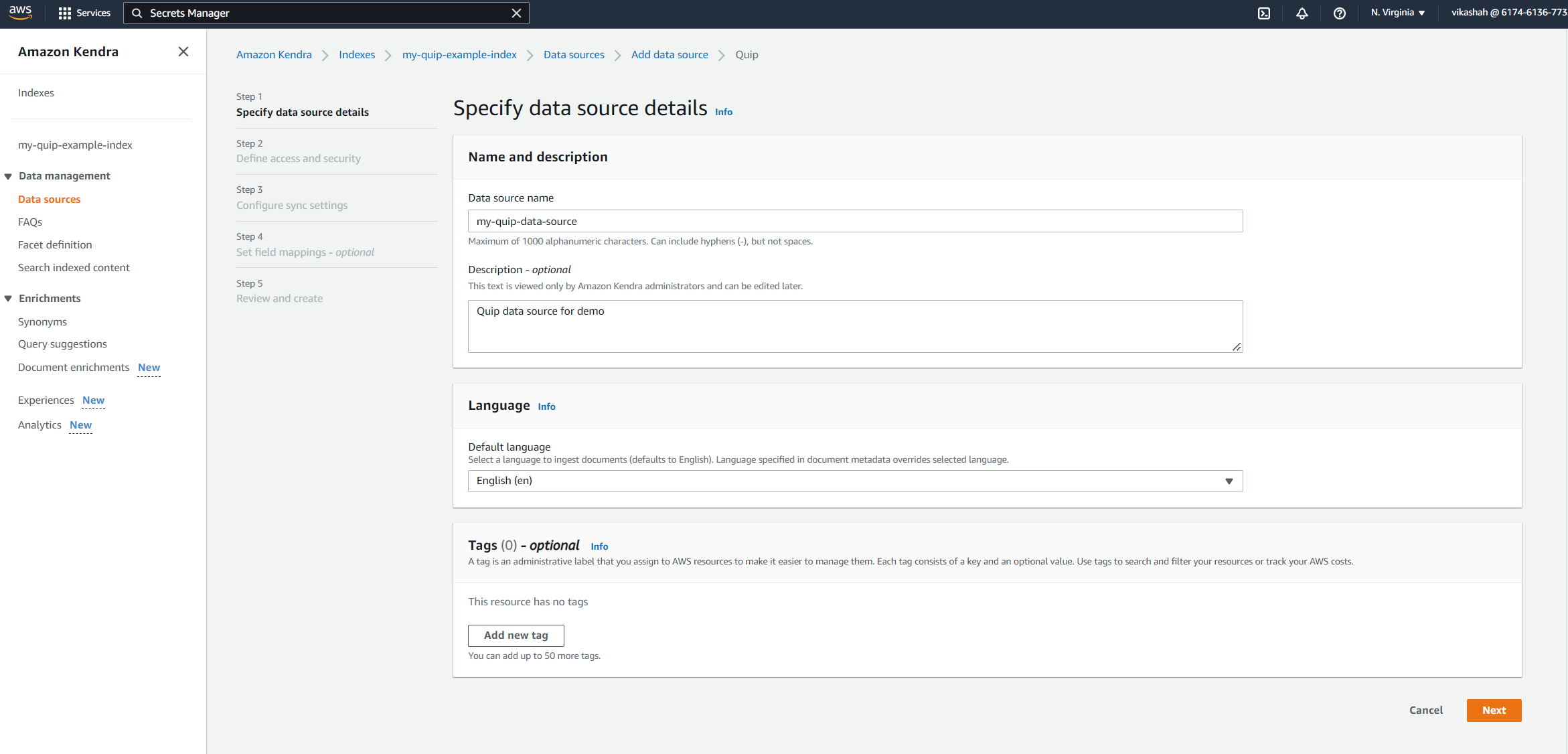
- 이전에 저장한 Quip 도메인 이름을 입력합니다.
- $XNUMX Million 미만 기미선택한다. 새 Secrets Manager 암호 생성 및 추가.
- 럭셔리 비밀 이름, 비밀의 이름을 입력합니다.
- 럭셔리 Quip 토큰, 이전에 저장한 액세스 토큰을 입력하십시오.
- 왼쪽 메뉴에서 비밀 저장 및 추가.

- $XNUMX Million 미만 IAM 역할, 역할을 선택하거나 새 역할을 만듭니다.
- 왼쪽 메뉴에서 다음 보기.

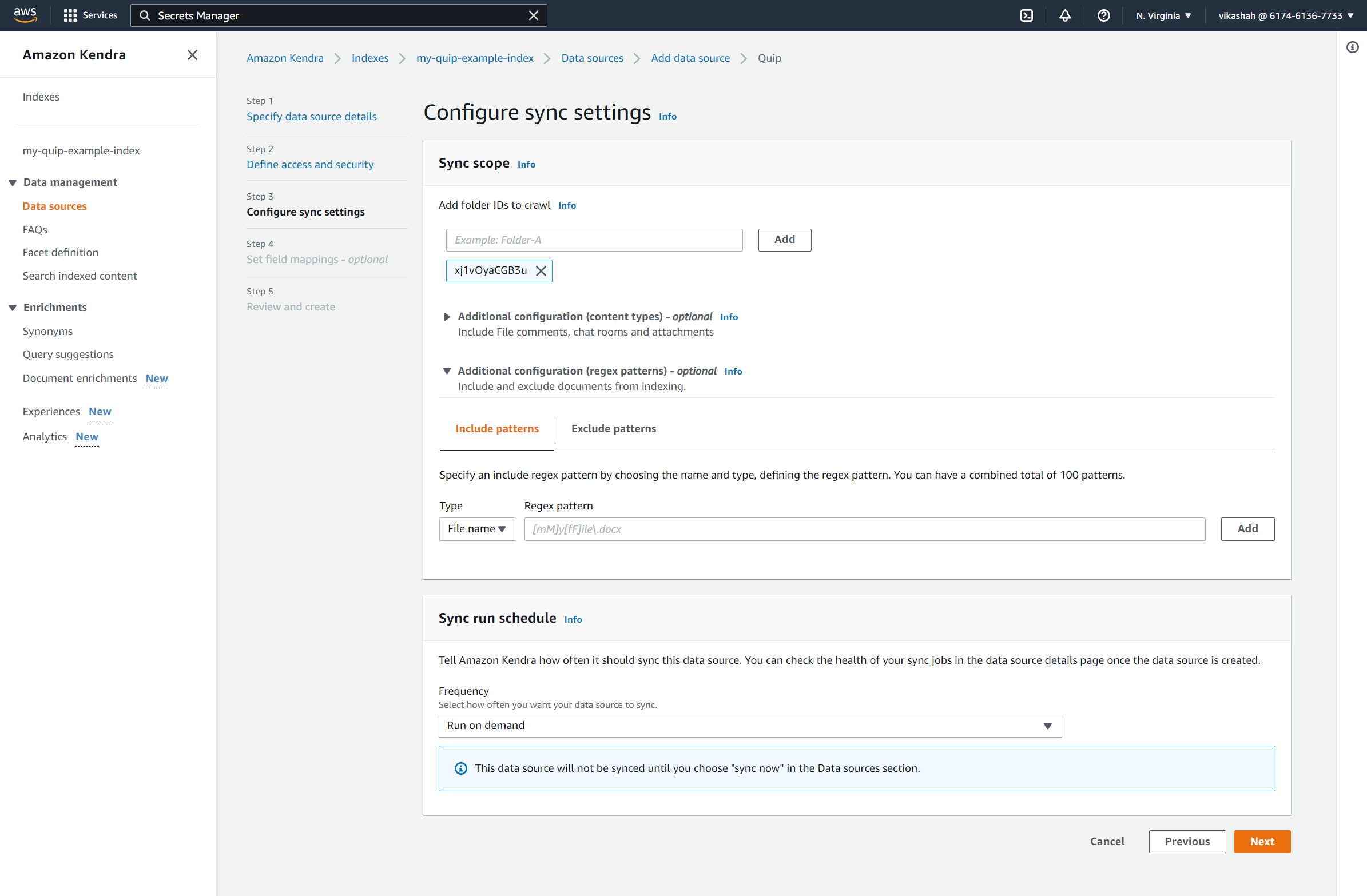
- $XNUMX Million 미만 동기화 범위에 대한 크롤링할 폴더 ID 추가, 이전에 저장한 폴더 ID를 입력합니다.
- $XNUMX Million 미만 동기화 실행 일정을위한 진동수, 고르다 주문형 실행.
- 왼쪽 메뉴에서 다음 보기.
Quip 커넥터를 사용하면 작성자, 범주 및 폴더 이름과 같은 추가 필드를 캡처할 수 있습니다(필요에 따라 이름 바꾸기도 가능).
- 이 게시물에서는 필드 매핑을 구성하지 않습니다.
- 왼쪽 메뉴에서 다음 보기.

- 모든 옵션을 확인하고 데이터 소스를 추가합니다.
데이터 소스가 몇 분 안에 준비됩니다.
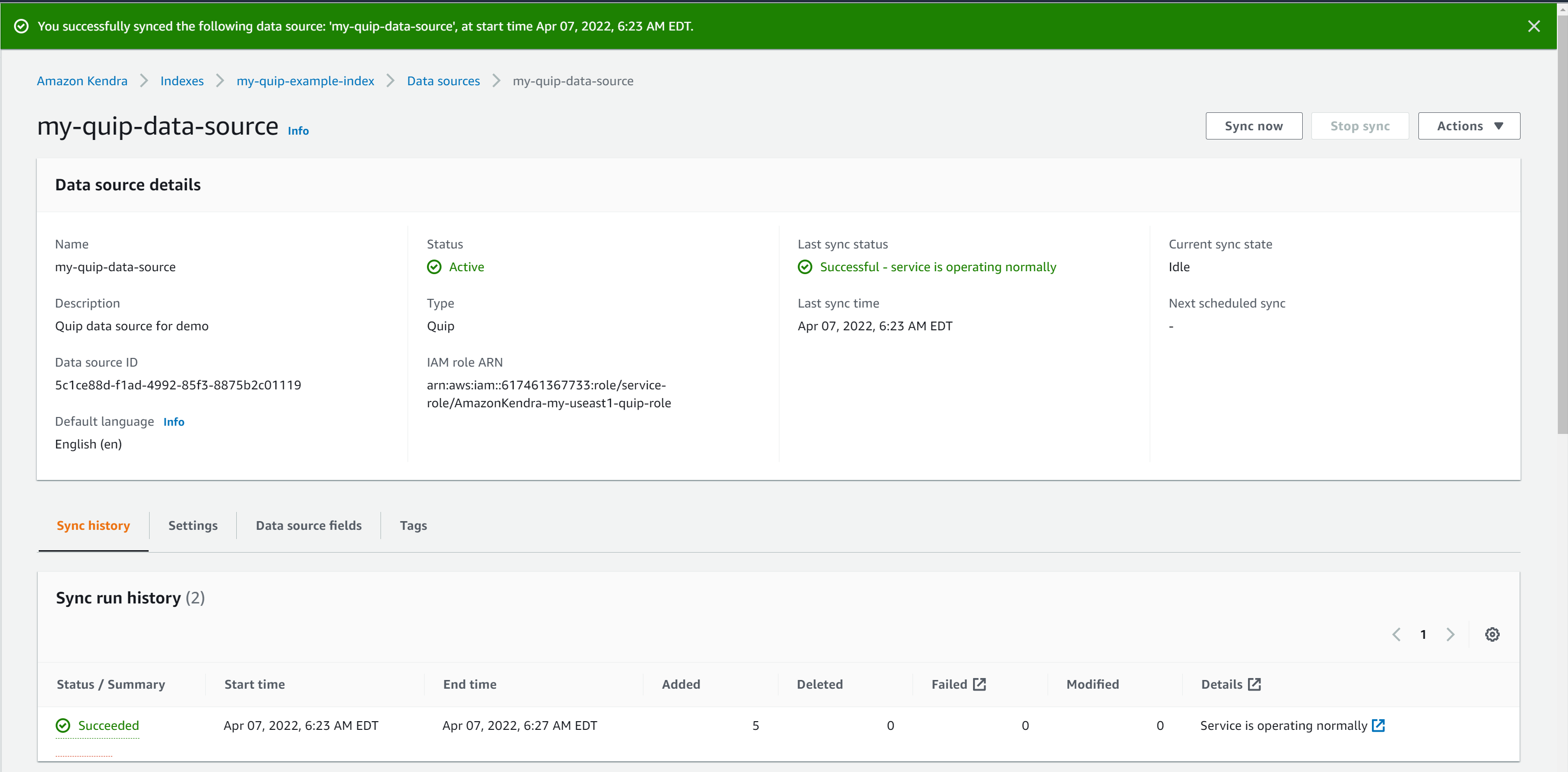
- 데이터 소스가 준비되면 다음을 선택하십시오. 지금 동기화.

Quip 리포지토리의 데이터 크기에 따라 이 프로세스는 몇 분에서 몇 시간이 걸릴 수 있습니다. 동기화는 XNUMX단계 프로세스입니다. 먼저 문서를 크롤링하여 인덱싱할 문서를 결정합니다. 그런 다음 선택한 문서가 인덱싱됩니다. 동기화 속도에 영향을 미치는 몇 가지 요인에는 리포지토리 처리량 및 제한, 네트워크 대역폭 및 문서 크기가 포함됩니다.
동기화가 완료되면 동기화 상태가 성공으로 표시됩니다. 이제 Quip 리포지토리가 연결되었습니다.
Amazon Kendra에서 검색 실행
몇 가지 검색을 실행하여 커넥터를 테스트해 보겠습니다.
- Amazon Kendra 콘솔에서 데이터 관리 탐색 창에서 인덱싱된 콘텐츠 검색.
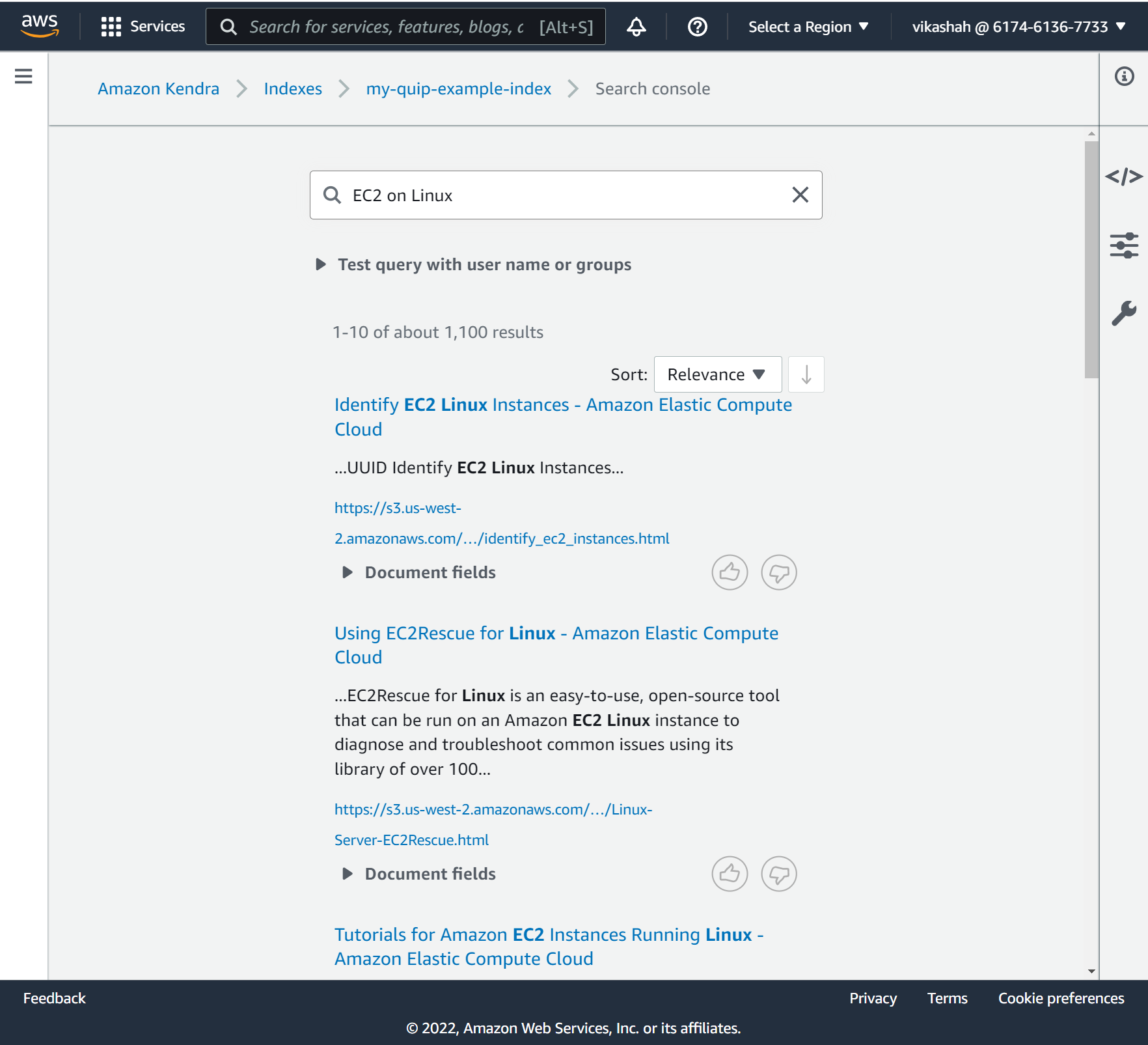
- 검색 필드에 검색어를 입력하십시오. 이 게시물의 경우 다음을 검색합니다.
EC2 on Linux.

다음 스크린샷은 결과를 보여줍니다.
제한 사항
데이터 원본 수집에 대해 알려진 몇 가지 제한 사항이 있습니다. 일부 제한 사항은 일부 콘텐츠에 액세스하기 위해 관리자 액세스가 필요하기 때문이고 다른 제한 사항은 특정 구현 세부 정보로 인해 발생합니다. 그것들은 다음과 같습니다:
- 전체 크롤링만 지원됩니다. 커넥터가 변경 로그 크롤링을 지원하도록 하려면 관리 API 액세스가 필요하며 Quip 웹 사이트에서 관리 API를 활성화해야 합니다.
- 공유 폴더만 크롤링됩니다. 관리 사용자의 개인 액세스 토큰을 사용하더라도 다른 사용자의 개인 폴더에 있는 데이터를 크롤링할 수 없습니다.
- Quip은 파일 유형 확장자를 저장하지 않고 파일 이름만 저장하기 때문에 이 솔루션은 포함 및 제외할 파일 유형 지정을 지원하지 않습니다.
- 실시간 이벤트에는 구독 및 관리 API 액세스가 필요합니다.
결론
Quip용 Amazon Kendra 커넥터를 사용하는 조직은 Amazon Kendra에서 제공하는 지능형 검색을 사용하여 Quip 문서에 저장된 귀중한 정보를 사용자가 안전하게 사용할 수 있도록 할 수 있습니다. 또한 커넥터는 작성자, 파일 유형, 소스 URI, 생성 날짜, 상위 파일 및 범주와 같은 Quip 리포지토리 특성에 대한 패싯을 제공하므로 사용자는 원하는 항목을 기반으로 검색 결과를 대화식으로 구체화할 수 있습니다.
콘텐츠가 Quip 리포지토리에서 수집될 때 사용자 지정 문서 보강을 사용하여 데이터 및 메타데이터를 생성, 수정 및 삭제하는 방법에 대한 자세한 내용은 다음을 참조하십시오. 수집 프로세스 중 문서 메타데이터 사용자 지정 와 콘텐츠와 메타데이터를 강화하여 Amazon Kendra의 사용자 지정 문서 강화로 검색 경험을 향상시키십시오..
저자에 관하여
 아시시 라그완카르 AWS의 시니어 엔터프라이즈 솔루션 아키텍트입니다. 그의 핵심 관심사는 AI/ML, 서버리스 및 컨테이너 기술입니다. Ashish는 매사추세츠주 보스턴에 거주하며 독서, 야외 활동, 가족과 함께 시간 보내기를 즐깁니다.
아시시 라그완카르 AWS의 시니어 엔터프라이즈 솔루션 아키텍트입니다. 그의 핵심 관심사는 AI/ML, 서버리스 및 컨테이너 기술입니다. Ashish는 매사추세츠주 보스턴에 거주하며 독서, 야외 활동, 가족과 함께 시간 보내기를 즐깁니다.
 비카스 샤 Amazon 웹 서비스의 엔터프라이즈 솔루션 아키텍트입니다. 그는 고객이 복잡한 비즈니스 문제에 대한 혁신적인 솔루션을 찾도록 돕는 것을 즐기는 기술 애호가입니다. 그의 관심 분야는 ML, IoT, 로봇 공학 및 스토리지입니다. 여가 시간에 Vikas는 로봇 만들기, 하이킹, 여행을 즐깁니다.
비카스 샤 Amazon 웹 서비스의 엔터프라이즈 솔루션 아키텍트입니다. 그는 고객이 복잡한 비즈니스 문제에 대한 혁신적인 솔루션을 찾도록 돕는 것을 즐기는 기술 애호가입니다. 그의 관심 분야는 ML, IoT, 로봇 공학 및 스토리지입니다. 여가 시간에 Vikas는 로봇 만들기, 하이킹, 여행을 즐깁니다.
- "
- 10
- 100
- 소개
- ACCESS
- 가로질러
- 추가
- 관리자
- All
- 아마존
- Amazon Web Services
- 알리다
- 다른
- API를
- API 액세스
- 접근
- 대략
- 지역
- 속성
- 작성자
- 가능
- AWS
- 경계
- 보스턴
- 보물상자
- 브라우저
- 건물
- 사업
- 포착
- 캡처
- 범주
- 과제
- 도전
- 왼쪽 메뉴에서
- 협력
- 협동
- 복잡한
- 연결
- 콘솔에서
- 컨테이너
- 함유량
- 제어
- 핵심
- 창조
- 관습
- 고객
- 데이터
- 날짜
- 배달
- 보여
- 의존
- 개발
- 장치
- 서류
- 하지 않습니다
- 도메인
- 도메인 이름
- 용이하게
- 가능
- 엔터 버튼
- Enterprise
- 이벤트
- 예
- 경험
- 요인
- 가족
- Fields
- 발견
- 먼저,
- 처음으로
- 수행원
- 형태
- 가득 찬
- 기능
- 데
- 도움이
- 보유
- 방법
- How To
- HTTPS
- 이행
- 포함
- 포함
- 색인
- 정보
- 혁신적인
- 지능형
- 관심
- 이해
- IOT
- 지식
- 알려진
- 배우기
- 명부
- 찾고
- 기계
- 기계 학습
- 구축
- 매니저
- ML
- 배우기
- 여러
- 이름
- 자연
- 카테고리
- 네트워크
- 열 수
- 옵션
- 조직
- 조직
- 조직
- 기타
- 야외에서
- 확인
- 플랫폼
- 사설
- 방법
- 생산력
- 제공
- 제공
- 읽기
- 실시간
- 기록
- 저장소
- 필요
- 필수
- 결과
- 로봇
- 달리기
- 달리는
- 주사
- 검색
- 초
- 안전하게
- 선택된
- 서버리스
- 서비스
- 세트
- 공유
- 단순, 간단, 편리
- 크기
- So
- 해결책
- 솔루션
- 일부
- 속도
- 지출
- 시작
- Status
- 저장
- 저장
- 신청
- 성공한
- 공급
- SUPPORT
- 지원
- 팀
- 기술
- Technology
- test
- 시간
- 함께
- 토큰
- 전통적인
- 여행
- 유일한
- 사용
- 사용자
- 관측
- 음량
- 웹
- 웹 브라우저
- 웹 서비스
- 웹 사이트
- 뭐
- 누구
- 작업