Afbeelding door auteur
Exploratieve data-analyse (of EDA) vormt een kernfase binnen het data-analyseproces, waarbij de nadruk wordt gelegd op een grondig onderzoek naar de innerlijke details en kenmerken van een dataset.
Het primaire doel is om onderliggende patronen bloot te leggen, de structuur van de dataset te begrijpen en eventuele afwijkingen of relaties tussen variabelen te identificeren.
Door het uitvoeren van EDA controleren dataprofessionals de kwaliteit van de data. Daarom zorgt het ervoor dat verdere analyse is gebaseerd op nauwkeurige en inzichtelijke informatie, waardoor de kans op fouten in volgende fasen wordt verkleind.
Laten we dus samen proberen te begrijpen wat de basisstappen zijn om een goede EDA uit te voeren voor ons volgende Data Science-project.
Ik ben er vrij zeker van dat je de zin al hebt gehoord:
Afval erin, afval eruit
De kwaliteit van inputdata is altijd de belangrijkste factor voor elk succesvol dataproject.
Helaas zijn de meeste gegevens in eerste instantie vuil. Via het proces van verkennende data-analyse kan een dataset die bijna bruikbaar is, worden getransformeerd in een dataset die volledig bruikbaar is.
Het is belangrijk om duidelijk te maken dat het geen magische oplossing is voor het zuiveren van welke dataset dan ook. Niettemin zijn talrijke EDA-strategieën effectief bij het aanpakken van verschillende typische problemen die zich binnen datasets voordoen.
Dus... laten we de meest elementaire stappen leren volgens Ayodele Oluleye in zijn boek Exploratory Data Analysis with Python Cookbook.
Stap 1: gegevensverzameling
De eerste stap in elk dataproject is het beschikken over de data zelf. In deze eerste stap worden gegevens uit verschillende bronnen verzameld voor daaropvolgende analyse.
2. Samenvattende statistieken
Bij data-analyse is het verwerken van tabelgegevens vrij gebruikelijk. Tijdens de analyse van dergelijke gegevens is het vaak nodig om snel inzicht te krijgen in de patronen en distributie van de gegevens.
Deze eerste inzichten dienen als basis voor verdere verkenning en diepgaande analyse en staan bekend als samenvattende statistieken.
Ze bieden een beknopt overzicht van de distributie en patronen van de dataset, samengevat in metrieken zoals gemiddelde, mediaan, modus, variantie, standaarddeviatie, bereik, percentielen en kwartielen.
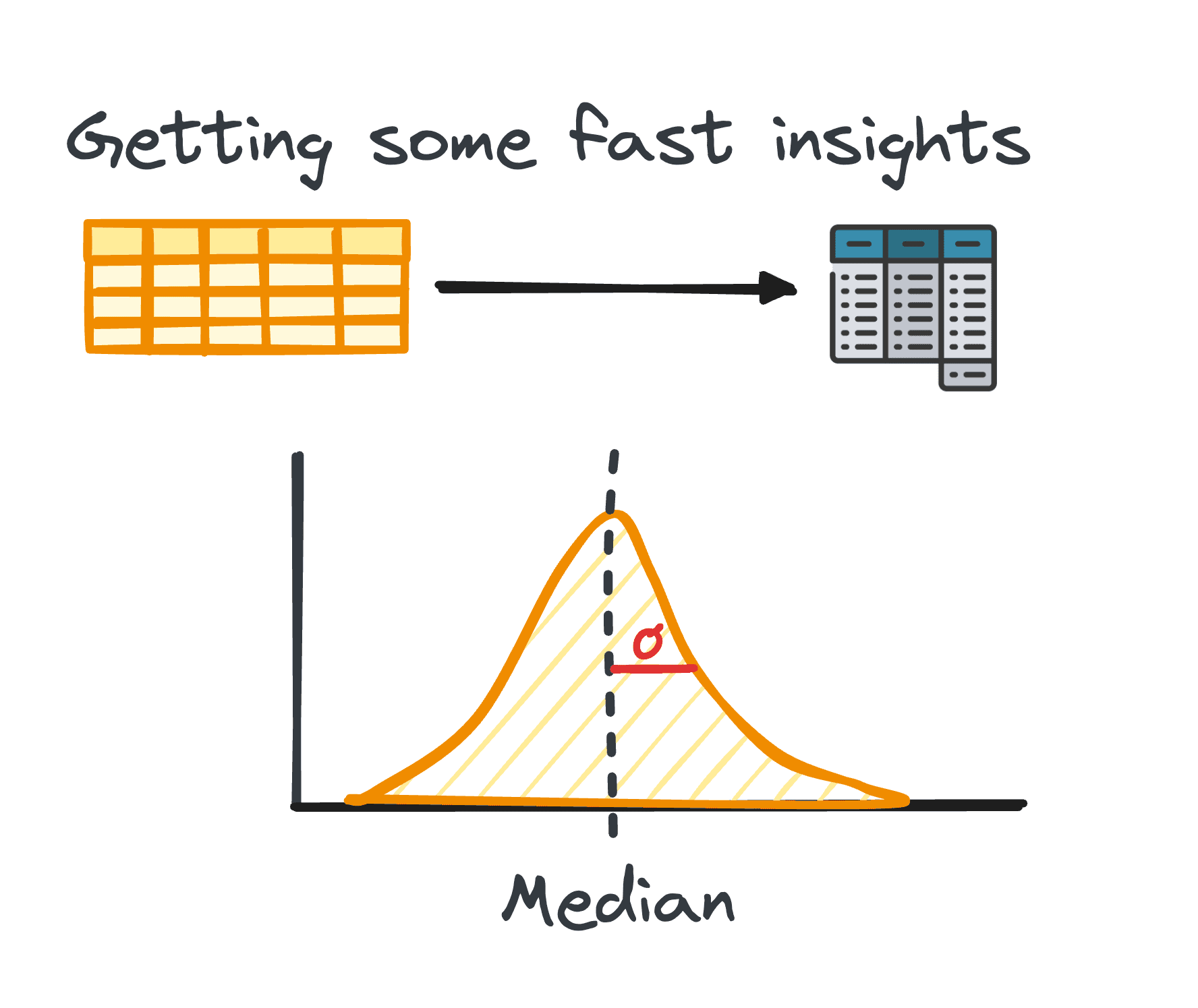
Afbeelding door auteur
3. Gegevens voorbereiden voor EDA
Voordat we met onze verkenning beginnen, moeten gegevens meestal worden voorbereid voor verdere analyse. Gegevensvoorbereiding omvat het transformeren, aggregeren of opschonen van gegevens met behulp van de panda-bibliotheek van Python om aan de behoeften van uw analyse te voldoen.
Deze stap is afgestemd op de structuur van de gegevens en kan het groeperen, toevoegen, samenvoegen, sorteren, categoriseren en omgaan met duplicaten omvatten.
In Python wordt het uitvoeren van deze taak vergemakkelijkt door de panda-bibliotheek via zijn verschillende modules.
Het voorbereidingsproces voor tabelgegevens volgt geen universele methode; in plaats daarvan wordt het gevormd door de specifieke kenmerken van onze gegevens, inclusief de rijen, kolommen, gegevenstypen en de waarden die deze bevatten.
4. Gegevens visualiseren
Visualisatie is een kerncomponent van EDA, waardoor complexe relaties en trends binnen de dataset gemakkelijk begrijpelijk worden.
Het gebruik van de juiste grafieken kan ons helpen trends binnen een grote dataset te identificeren en verborgen patronen of uitschieters te vinden. Python biedt verschillende bibliotheken voor datavisualisatie, waaronder onder andere Matplotlib of Seaborn.
Afbeelding door auteur
5. Variabele analyse uitvoeren:
Variabele analyse kan univariate, bivariate of multivariate zijn. Elk van hen biedt inzicht in de verdeling en correlaties tussen de variabelen van de dataset. Technieken variëren afhankelijk van het aantal geanalyseerde variabelen:
Univariaat
De belangrijkste focus bij univariate analyse ligt op het afzonderlijk onderzoeken van elke variabele binnen onze dataset. Tijdens deze analyse kunnen we inzichten ontdekken zoals de mediaan, modus, maximum, bereik en uitschieters.
Dit type analyse is toepasbaar op zowel categorische als numerieke variabelen.
bivariate
Bivariate analyse heeft tot doel inzichten te onthullen tussen twee gekozen variabelen en richt zich op het begrijpen van de verdeling en relatie tussen deze twee variabelen.
Omdat we twee variabelen tegelijkertijd analyseren, kan dit type analyse lastiger zijn. Het kan drie verschillende paren variabelen omvatten: numeriek-numeriek, numeriek-categorisch en categorisch-categorisch.
multivariate
Een veel voorkomende uitdaging bij grote datasets is de gelijktijdige analyse van meerdere variabelen. Hoewel univariate en bivariate analysemethoden waardevolle inzichten bieden, is dit meestal niet voldoende voor het analyseren van datasets die meerdere variabelen bevatten (meestal meer dan vijf).
Deze kwestie van het beheren van hoogdimensionale gegevens, gewoonlijk de vloek van de dimensionaliteit genoemd, is goed gedocumenteerd. Het hebben van een groot aantal variabelen kan voordelig zijn, omdat hierdoor meer inzichten kunnen worden verkregen. Tegelijkertijd kan dit voordeel tegen ons werken vanwege het beperkte aantal beschikbare technieken voor het gelijktijdig analyseren of visualiseren van meerdere variabelen.
6. Tijdreeksgegevens analyseren
Deze stap richt zich op het onderzoeken van gegevenspunten die over regelmatige tijdsintervallen zijn verzameld. Tijdreeksgegevens zijn van toepassing op gegevens die in de loop van de tijd veranderen. Dit betekent in feite dat onze dataset is samengesteld uit een groep datapunten die over regelmatige tijdsintervallen worden geregistreerd.
Wanneer we tijdreeksgegevens analyseren, kunnen we doorgaans patronen of trends ontdekken die zich in de loop van de tijd herhalen en een tijdelijke seizoensinvloed vertonen. Belangrijke componenten van tijdreeksgegevens zijn onder meer trends, seizoensvariaties, cyclische variaties en onregelmatige variaties of ruis.
7. Omgaan met uitschieters en ontbrekende waarden
Uitschieters en ontbrekende waarden kunnen de analyseresultaten vertekenen als ze niet op de juiste manier worden aangepakt. Daarom moeten we altijd één enkele fase overwegen om ze aan te pakken.
Het identificeren, verwijderen of vervangen van deze datapunten is cruciaal voor het behouden van de integriteit van de analyse van de dataset. Daarom is het van groot belang om deze aan te pakken voordat u begint met het analyseren van onze gegevens.
- Uitschieters zijn gegevenspunten die een significante afwijking vertonen van de rest. Ze vertonen meestal ongewoon hoge of lage waarden.
- Ontbrekende waarden zijn de afwezigheid van gegevenspunten die overeenkomen met een specifieke variabele of observatie.
Een cruciale eerste stap bij het omgaan met ontbrekende waarden en uitschieters is begrijpen waarom ze in de dataset aanwezig zijn. Dit inzicht is vaak de leidraad bij de keuze van de meest geschikte methode om deze problemen aan te pakken. Bijkomende factoren waarmee rekening moet worden gehouden, zijn de kenmerken van de gegevens en de specifieke analyse die zal worden uitgevoerd.
EDA vergroot niet alleen de duidelijkheid van de dataset, maar stelt dataprofessionals ook in staat om door de vloek van de dimensionaliteit te navigeren door strategieën te bieden voor het beheren van datasets met talrijke variabelen.
Door deze nauwgezette stappen voorziet EDA met Python analisten van de tools die nodig zijn om betekenisvolle inzichten uit data te halen, waardoor een solide basis wordt gelegd voor alle daaropvolgende data-analyse-inspanningen.
Joseph Ferrer is een analytisch ingenieur uit Barcelona. Hij is afgestudeerd in natuurkunde en werkt momenteel op het gebied van datawetenschap toegepast op menselijke mobiliteit. Hij is een parttime contentmaker die zich richt op datawetenschap en -technologie. U kunt contact met hem opnemen via LinkedIn, Twitter or Medium.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/7-steps-to-mastering-exploratory-data-analysis?utm_source=rss&utm_medium=rss&utm_campaign=7-steps-to-mastering-exploratory-data-analysis
- :is
- :niet
- :waar
- 1
- 7
- a
- bereiken
- Volgens
- accuraat
- Extra
- adres
- aangesproken
- aanpakken
- aanhangen
- Voordeel
- voordelig
- tegen
- aggregeren
- streven
- wil
- Alles
- toestaat
- al
- ook
- altijd
- am
- onder
- an
- analyse
- analisten
- analytics
- analyseren
- geanalyseerd
- het analyseren van
- en
- elke
- toepasselijk
- toegepast
- geldt
- ZIJN
- AS
- At
- Beschikbaar
- Barcelona
- baseren
- gebaseerde
- basis-
- Eigenlijk
- BE
- vaardigheden
- tussen
- Groot
- boek
- zowel
- maar
- by
- CAN
- categoriseren
- uitdagen
- verandering
- kenmerken
- Grafieken
- controle
- uitgekozen
- helderheid
- Schoonmaak
- verzamelde
- columns
- Gemeen
- complex
- bestanddeel
- componenten
- samengesteld
- beknopt
- uitgevoerd
- Overwegen
- contact
- bevat
- content
- Kern
- correlaties
- Overeenkomend
- schepper
- kritisch
- cruciaal
- Op dit moment
- vervloeken
- Cyclische
- gegevens
- gegevensanalyse
- data punten
- Data voorbereiding
- data kwaliteit
- data science
- data visualisatie
- datasets
- transactie
- omgang
- Afhankelijk
- gegevens
- afwijking
- anders
- vuil
- distributie
- doesn
- twee
- duplicaten
- gedurende
- elk
- gemakkelijk
- effectief
- beide
- nadruk te leggen op
- maakt
- ingekapseld
- omvatten
- inspanningen
- ingenieur
- Engineering
- Verbetert
- genoeg
- waarborgt
- fouten
- Zelfs
- onderzoek
- Onderzoeken
- exploratie
- Verkennende gegevensanalyse
- extract
- extractie
- vergemakkelijkt
- factor
- factoren
- veld-
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- vijf
- Focus
- gericht
- richt
- Voor
- Foundation
- veelvuldig
- oppompen van
- geheel
- verder
- Krijgen
- verzameld
- goed
- grijpen
- Groep
- Guides
- Behandeling
- Hebben
- met
- he
- gehoord
- hulp
- verborgen
- Hoge
- zeer
- hem
- zijn
- HTTPS
- menselijk
- identificeren
- if
- belangrijk
- in
- diepgaande
- omvatten
- Inclusief
- informatie
- eerste
- binnenste
- inzichtelijke
- inzichten
- verkrijgen in plaats daarvan
- integriteit
- in
- onderzoek
- gaat
- kwestie
- problemen
- IT
- HAAR
- zelf
- KDnuggets
- sleutel
- bekend
- Groot
- houdende
- LEARN
- bibliotheken
- Bibliotheek
- waarschijnlijkheid
- Beperkt
- Laag
- magie
- Hoofd
- behoud van
- maken
- beheren
- het beheersen van
- matplotlib
- maximaal
- gemiddelde
- zinvolle
- middel
- samen te voegen
- methode
- methoden
- nauwkeurig
- Metriek
- vermist
- mobiliteit
- Mode
- Modules
- meer
- meest
- meervoudig
- OP DEZE WEBSITE VIND JE
- bijna
- noodzakelijk
- behoeften
- volgende
- Geluid
- aantal
- numeriek
- vele
- observatie
- of
- bieden
- Aanbod
- vaak
- on
- EEN
- Slechts
- or
- Overig
- onze
- over
- overzicht
- het te bezitten.
- paren
- panda's
- patronen
- uitvoeren
- uitvoerend
- fase
- Fysica
- Plato
- Plato gegevensintelligentie
- PlatoData
- punten
- potentieel
- voorbereiding
- bereid
- voorbereiding
- presenteren
- mooi
- primair
- professionals
- project
- naar behoren
- biedt
- het verstrekken van
- Python
- kwaliteit
- heel
- reeks
- snel
- opgenomen
- vermindering
- verwezen
- regelmatig
- verwantschap
- Relaties
- het verwijderen van
- herhaling
- REST
- Resultaten
- onthullen
- rechts
- s
- dezelfde
- Wetenschap
- Wetenschap en Technologie
- Seaborn
- seizoensgebonden
- selectie
- -Series
- dienen
- verscheidene
- gevormd
- moet
- aanzienlijke
- simultaan
- single
- scheef
- solide
- oplossing
- bronnen
- specifiek
- stadia
- standaard
- staat
- begin
- Start
- statistiek
- Stap voor
- Stappen
- strategieën
- structuur
- volgend
- geslaagd
- dergelijk
- Pak
- geschikt
- OVERZICHT
- zeker
- T
- op maat gemaakt
- Taak
- technieken
- Technologie
- neem contact
- dat
- De
- Ze
- daarbij
- daarom
- Deze
- ze
- dit
- grondig
- toch?
- drie
- Door
- niet de tijd of
- Tijdreeksen
- naar
- samen
- tools
- getransformeerd
- transformeren
- Trends
- proberen
- twee
- type dan:
- types
- typisch
- typisch
- ontdekken
- die ten grondslag liggen
- begrijpen
- begrip
- Universeel
- us
- bruikbaar
- gebruik
- doorgaans
- waardevol
- Values
- variabele
- variabelen
- variaties
- divers
- variëren
- visualisatie
- we
- Wat
- Waarom
- wil
- Met
- binnen
- werkzaam
- u
- Your
- zephyrnet