Introductie
Gewone kleinste kwadraten is een optimalisatietechniek. OLS is dezelfde techniek die wordt gebruikt door de scikit-learn LinearRegression-klasse en de functie numpy.polyfit() achter de schermen. Voordat we ingaan op de details van de OLS-techniek, zou het de moeite waard zijn om het artikel waarover ik heb geschreven door te nemen de rol van optimalisatietechnieken bij machine learning en deep learning. In hetzelfde artikel heb ik kort de reden en context voor het bestaan van de OLS-techniek uitgelegd (hoofdstuk 6). Dit artikel is in hoge mate een voortzetting van hetzelfde artikel en van de lezers wordt verwacht dat ze hiermee vertrouwd zijn.

Bron: Pixbay
Leerdoelen:
In dit artikel ga je
- Leer wat OLS is en begrijp de wiskundige vergelijking ervan
- Krijg een overzicht van OLS in scaler-vorm en de nadelen ervan
- Begrijp OLS aan de hand van een real-time voorbeeld
Inhoudsopgave
- Wat zijn optimalisatieproblemen?
- Waarom hebben we OLS nodig?
- De wiskunde achter het OLS-algoritme begrijpen
- OLS-oplossing in Scaler-vorm
- OLS in actie aan de hand van een echt voorbeeld
- Problemen met de Scaler-vorm van OLS Solution
- Conclusie
Wat zijn optimalisatieproblemen?
Optimalisatieproblemen zijn wiskundige problemen waarbij de beste oplossing moet worden gevonden uit een reeks mogelijke oplossingen. Deze problemen worden doorgaans geformuleerd als maximalisatie- of minimalisatieproblemen, waarbij het doel is om een bepaalde doelfunctie te maximaliseren of te minimaliseren. De doelfunctie is een wiskundige uitdrukking die de te optimaliseren grootheid beschrijft, en een reeks beperkingen definieert de reeks mogelijke oplossingen.
Optimalisatieproblemen doen zich voor op verschillende gebieden, waaronder engineering, financiën, economie en operationeel onderzoek. Ze worden gebruikt om problemen zoals toewijzing van middelen, planning en portfolio-optimalisatie te modelleren en op te lossen. Optimalisatie is een cruciaal onderdeel van veel algoritmen voor machine learning. Bij machine learning wordt optimalisatie gebruikt om de beste set parameters voor een model te vinden die het verschil tussen de voorspellingen van het model en de werkelijke waarden minimaliseert. Optimalisatie is een actief onderzoeksgebied op het gebied van machine learning, waarbij nieuwe optimalisatie-algoritmen worden ontwikkeld om de snelheid en nauwkeurigheid van het trainen van machine learning-modellen te verbeteren.
Enkele voorbeelden van waar optimalisatie wordt gebruikt bij machine learning zijn:
- Bij begeleid leren, wordt optimalisatie gebruikt om de parameters van een model te vinden die het verschil tussen de voorspellingen van het model en de werkelijke waarden voor een bepaalde trainingsdataset minimaliseren. Lineaire regressie en logistische regressie gebruiken bijvoorbeeld optimalisatie om de beste waarden van de coëfficiënten van het model te vinden. Bovendien worden sommige modellen, zoals beslissingsbomen, willekeurige forests en modellen voor het stimuleren van gradiënten, gebouwd door iteratief nieuwe modellen aan het ensemble toe te voegen en de parameters van de nieuwe modellen te optimaliseren die de fout op de trainingsgegevens minimaliseren.
- Bij onbegeleid leren, helpt optimalisatie bij het vinden van de beste configuratie van clusters of het in kaart brengen van de gegevens die de onderliggende structuur in de gegevens het beste weergeven. In clustering, wordt optimalisatie gebruikt om de beste configuratie van clusters in de gegevens te vinden. Het K-Means-algoritme gebruikt bijvoorbeeld een optimalisatietechniek genaamd Lloyd's-algoritme, die iteratief gegevenspunten opnieuw toewijst aan het dichtstbijzijnde clusterzwaartepunt en de clusterzwaartepunten bijwerkt op basis van de nieuw toegewezen punten. Evenzo gebruiken andere clusteralgoritmen, zoals hiërarchische clustering, op dichtheid gebaseerde clustering en Gaussiaanse mengselmodellen, ook optimalisatietechnieken om de beste clusteroplossing te vinden. In reductie van dimensies, vindt optimalisatie de beste gegevenstoewijzing van een hoog- naar een lager-dimensionale ruimte. Principal Component Analysis (PCA) gebruikt bijvoorbeeld Singular Value Decomposition (SVD), een optimalisatietechniek, om de beste lineaire combinatie van de oorspronkelijke variabelen te vinden die de meeste variantie in de gegevens verklaart. Bovendien gebruiken andere dimensionaliteitsreductietechnieken zoals Linear Discriminant Analysis (LDA) en t-distributed Stochastic Neighbor Embedding (t-SNE) ook optimalisatietechnieken om de beste weergave van de gegevens in een lager-dimensionale ruimte te vinden.
- Bij diep leren, wordt optimalisatie gebruikt om de beste set parameters voor neurale netwerken te vinden.
Waarom hebben we OLS nodig?
De gewone kleinste kwadraten (OLS) algoritme is een methode voor het schatten van de parameters van een lineair regressiemodel. Het OLS-algoritme probeert de waarden te vinden van de parameters van het lineaire regressiemodel (dwz de coëfficiënten) die de som van de gekwadrateerde residuen minimaliseren. De residuen zijn de verschillen tussen de waargenomen waarden van de afhankelijke variabele en de voorspelde waarden van de afhankelijke variabele gegeven de onafhankelijke variabelen. Het is belangrijk op te merken dat het OLS-algoritme ervan uitgaat dat de fouten normaal verdeeld zijn met een gemiddelde en constante variantie van nul en dat er geen multicollineariteit (hoge correlatie) is tussen de onafhankelijke variabelen. Andere methoden, zoals gegeneraliseerde kleinste kwadraten of gewogen kleinste kwadraten, moeten worden gebruikt in gevallen waarin niet aan deze aannames wordt voldaan.
De wiskunde achter het OLS-algoritme begrijpen
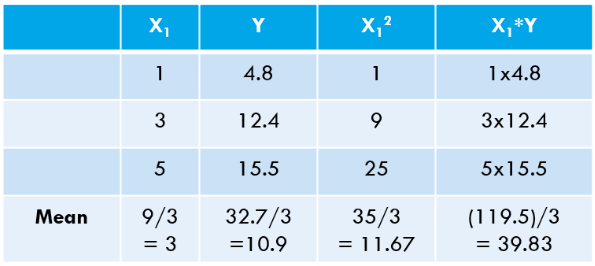
Om het OLS-algoritme uit te leggen, neem ik het eenvoudigst mogelijke voorbeeld. Beschouw de volgende 3 gegevenspunten:
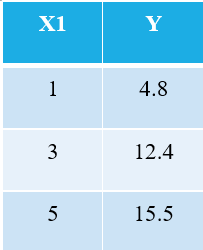
Iedereen die bekend is met machine learning zal onmiddellijk herkennen dat we verwijzen naar X1 als de onafhankelijke variabele (ook wel "Voordelen"Of "Kenmerken"), en de Y is de afhankelijke variabele (ook wel de "Doelwit" or "Resultaat"). Daarom is de algemene taak van elke machine het vinden van de relatie tussen X1 & Y. Deze relatie is eigenlijk "geleerd" door de machine van de GEGEVENS. Daarom noemen we de term machine learning. Wij mensen leren van onze ervaringen. Op dezelfde manier wordt dezelfde ervaring als data in de machine ingevoerd.
Laten we nu zeggen dat we de best passende lijn willen vinden door de bovenstaande 3 gegevenspunten. De volgende grafiek toont deze 3 gegevenspunten in blauwe cirkels. Ook getoond is de rode lijn (met vierkanten), die we claimen als de "best passende lijn” via deze 3 datapunten. Ook heb ik ter vergelijking een "slecht passende" lijn (de gele lijn) getoond.
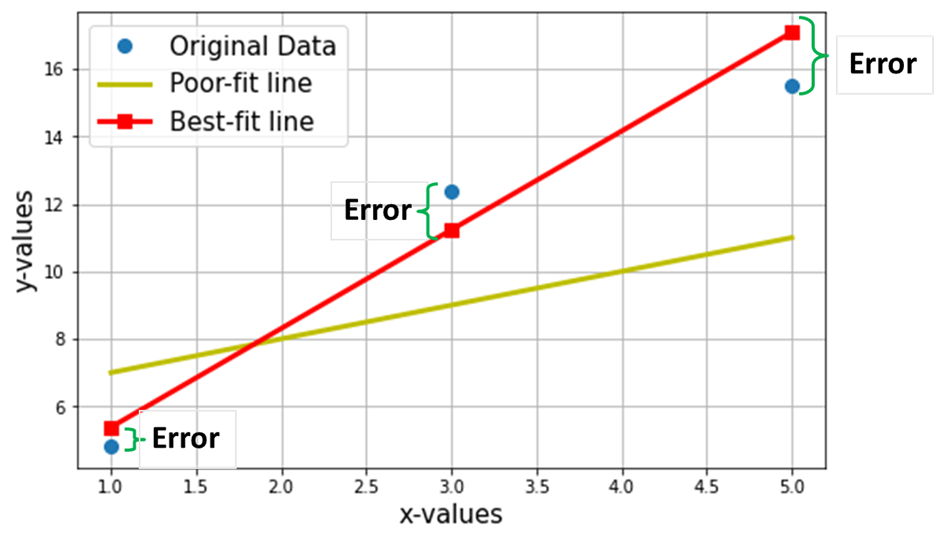
Het netto doel is om de vergelijking van de te vinden Best passende rechte lijn (via deze 3 gegevenspunten die in de bovenstaande tabel worden genoemd).

Het is de vergelijking van de best passende lijn (rode lijn in de bovenstaande grafiek), waar w1 = helling van de lijn; w0 = onderschepping van de lijn.
Bij machine learning wordt deze best fit de Lineair Regressie (LR) model, en w0 en w1 worden ook wel genoemd modelgewichten of modelcoëfficiënten.
Rode vierkanten in de bovenstaande grafiek vertegenwoordigen de voorspelde waarden van het lineaire regressiemodel (Y^). Natuurlijk zijn de voorspelde waarden NIET hetzelfde als de werkelijke waarden van Y (blauwe cirkels). Het verticale verschil vertegenwoordigt de fout in de voorspelling gegeven door (zie onderstaande afbeelding) voor elk i-de datapunt.
![]()
Nu beweer ik dat deze best passende lijn de minimale voorspellingsfout zal hebben (van alle mogelijke oneindige willekeurige "slecht passende" lijnen). Deze totale fout over alle gegevenspunten wordt uitgedrukt als de Mean Squared Error (MSE) -functie, wat de minimum voor de best passende lijn.
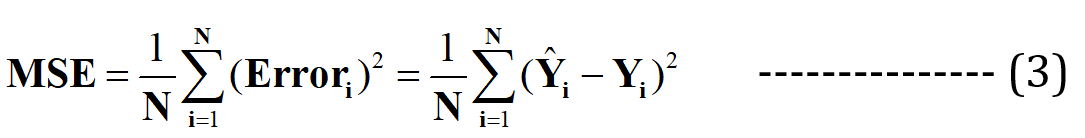
N = Totaal aantal van datapunten in de dataset (in het huidige geval is dit 3)
Het minimaliseren of maximaliseren van een hoeveelheid wordt wiskundig een genoemd optimalisatie probleem, en daarom verwijst de oplossing (het punt waar het minimum/maximum bestaat) naar de optimale waarden van de variabelen.

Lineaire regressie is een voorbeeld van onbeperkte optimalisatie, gegeven door:
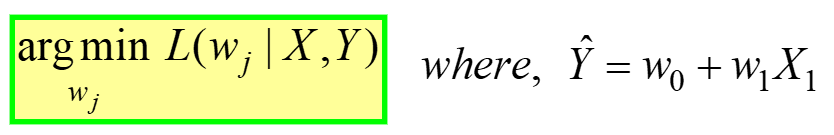 ---- (4)
---- (4)
Dit wordt gelezen als "Zoek de optimale gewichten (wj) waarvoor de MSE Verliesfunctie (gegeven in vergelijking 3 hierboven) heeft minimale waarde, voor een GEGEVEN X-, Y-gegevens" (zie allereerste tabel aan het begin van het artikel). L(gej) vertegenwoordigt het MSE-verlies, een functie van de modelgewichten, niet X of Y. Denk eraan, X & Y zijn uw GEGEVENS en zouden CONSTANT moeten zijn! Het subscript "j" vertegenwoordigt de jde modelcoëfficiënt/gewicht.
Bij vervanging van Y^ = w0 + met1X1 in de vgl. 3 hierboven, de finale MSE-verliesfunctie (L) ziet eruit als:
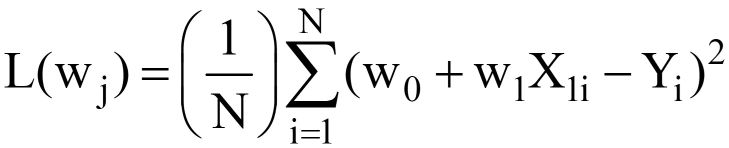 ---- (5)
---- (5)
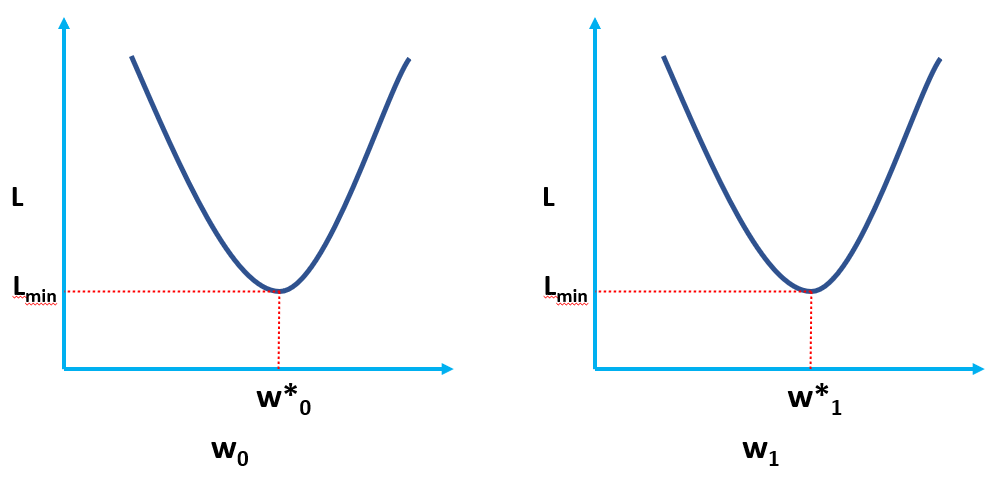
Het is duidelijk dat L een functie is van modelgewichten (w0 & w1), waarvan we de optimale waarden moeten vinden bij het minimaliseren van L. De optimale waarden worden weergegeven door (*) in de onderstaande afbeelding.
OLS-oplossing in scaler-vorm
de vgl. 5 hierboven gegeven vertegenwoordigt de OLS Loss-functie in de scaler-vorm (waar we de optelling van fouten voor elk datapunt. Het OLS-algoritme is een analytische oplossing voor het optimalisatieprobleem dat wordt gepresenteerd in de vergelijking. 4. Deze analytische oplossing bestaat uit de volgende stappen:
Stap 1:

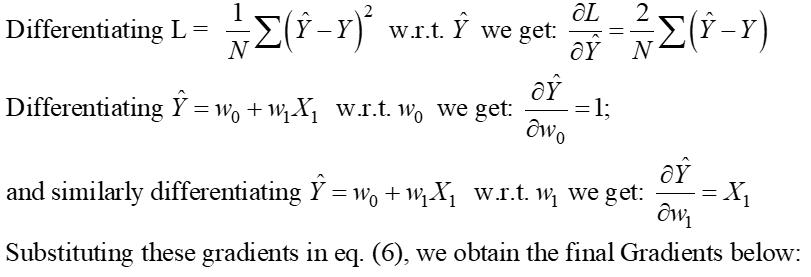

Stap 2: Stel deze gradiënten gelijk aan nul en los op voor de optimale waarden van de modelcoëfficiënten wj.
Dit betekent in feite dat de helling van de raaklijn (de geometrische interpretatie van de gradiënten) aan de verliesfunctie bij de optimale waarden (het punt waar L het minimum is) nul zal zijn, zoals weergegeven in de bovenstaande figuren.

Uit de bovenstaande vergelijkingen kunnen we de "2" verschuiven van de LHS naar de RHS; de RHS blijft 0 (aangezien 0/2 nog steeds 0 is).


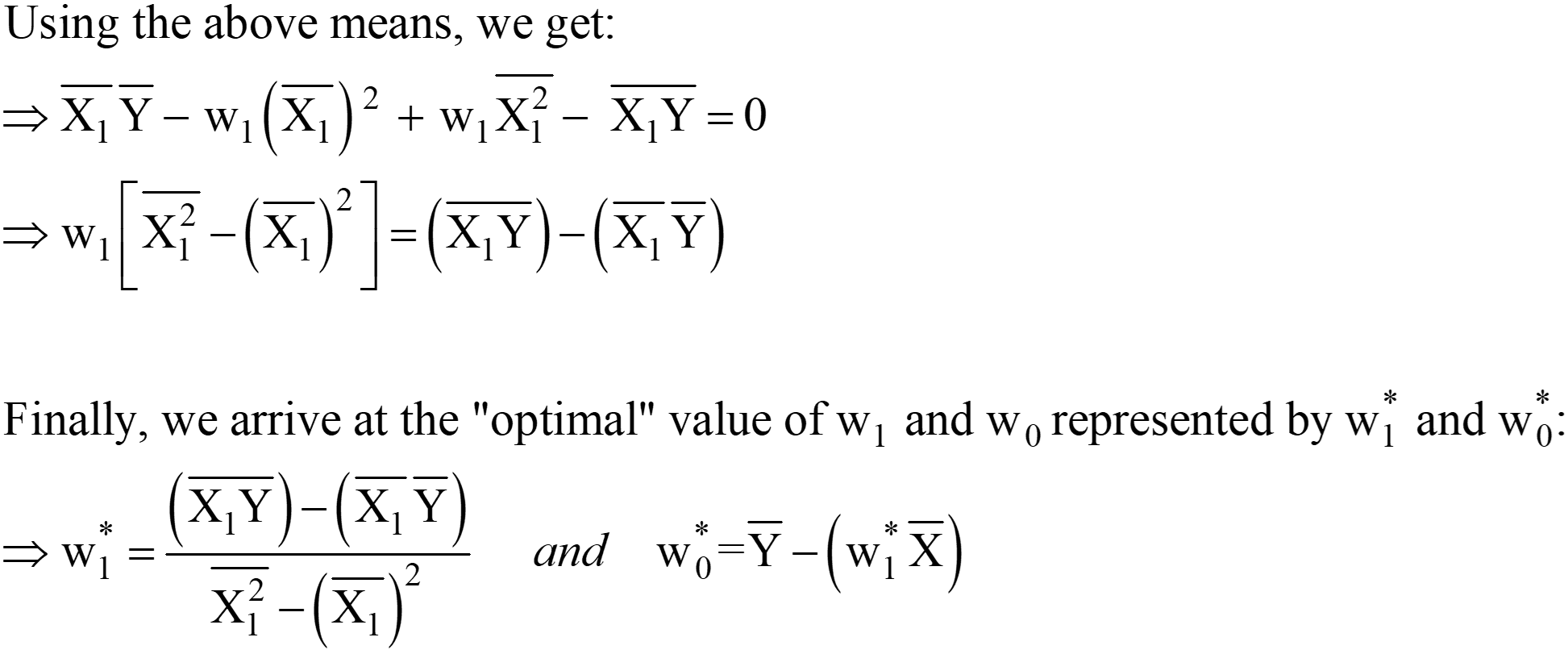
Deze uitdrukkingen voor w1* en w0* zijn de uiteindelijke OLS Analytical-oplossing in de Scaler-vorm.
Stap 3: Bereken de bovenstaande gemiddelden en vervang in de uitdrukking w1* & w0*.
Laten we deze waarden voor onze dataset berekenen:
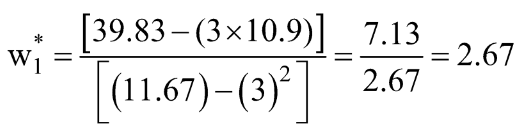
![]()
Laten we hetzelfde berekenen met behulp van Python-code:
[OUTPUT]: Dit is de vergelijking van de "Best passende" lijn: 2.675 x + 2.875
U kunt zien dat onze "met de hand berekende" waarden zeer nauw overeenkomen met de waarden van helling en onderschepping verkregen met behulp van NumPy (het kleine verschil is te wijten aan afrondingsfouten in onze handmatige berekeningen). We kunnen ook verifiëren dat dezelfde OLS "achter de schermen draait" van de klasse LinearRegression uit de scikit-leren pakket, zoals gedemonstreerd in de onderstaande code.
# importeer de LinearRegression-klasse uit het scikit-learn-pakket van sklearn.linear_model importeer LinearRegression LR = LinearRegression() # maak een instantie van de LinearRegression-klasse # definieer uw X en Y als NumPy Arrays (kolomvectoren) X = np.array([1,3,5 ,1,1]).reshape(-4.8,12.4,15.5) Y = np.array([1,1]).reshape(-0) LR.fit(X,Y) # bereken de modelcoëfficiënten LR .intercept_ # de bias of de interceptterm (wXNUMX*)
[Uitvoer]: array([2.875])
LR.coef_ # de hellingsterm (w1*) [Uitvoer]: array([[2.675]])
OLS in actie aan de hand van een echt voorbeeld
Hier gebruik ik de dataset Boston House Pricing, een van de meest voorkomende datasets tijdens het leren van Data Science. Het doel is om een Lineair regressiemodel om de mediaanwaarde van de huizenprijzen te voorspellen op basis van de 13 onderstaande kenmerken/kenmerken.
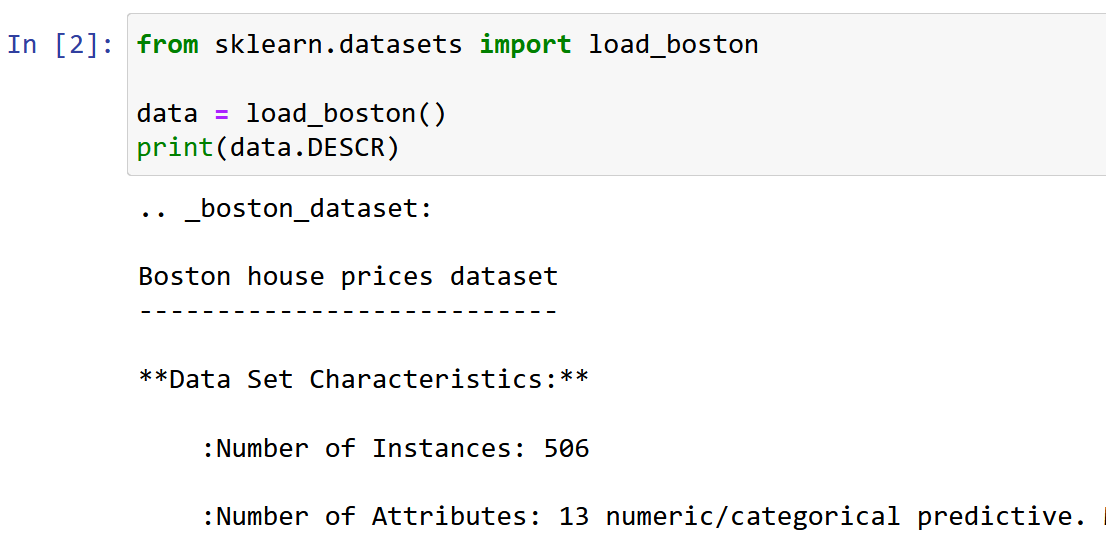
Importeer en verken de dataset.
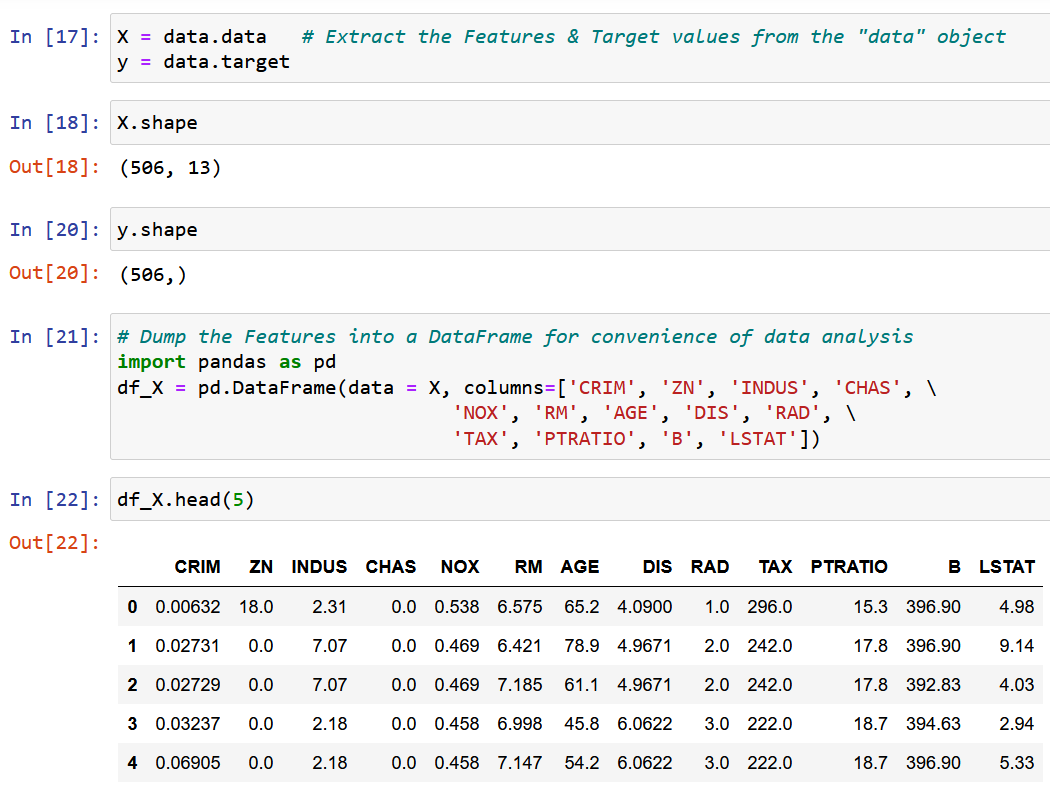
We extraheren een enkel kenmerk RM, de gemiddelde kamergrootte in de gegeven plaats, en passen deze aan met de doelvariabele y (de mediaanwaarde van de huizenprijs).
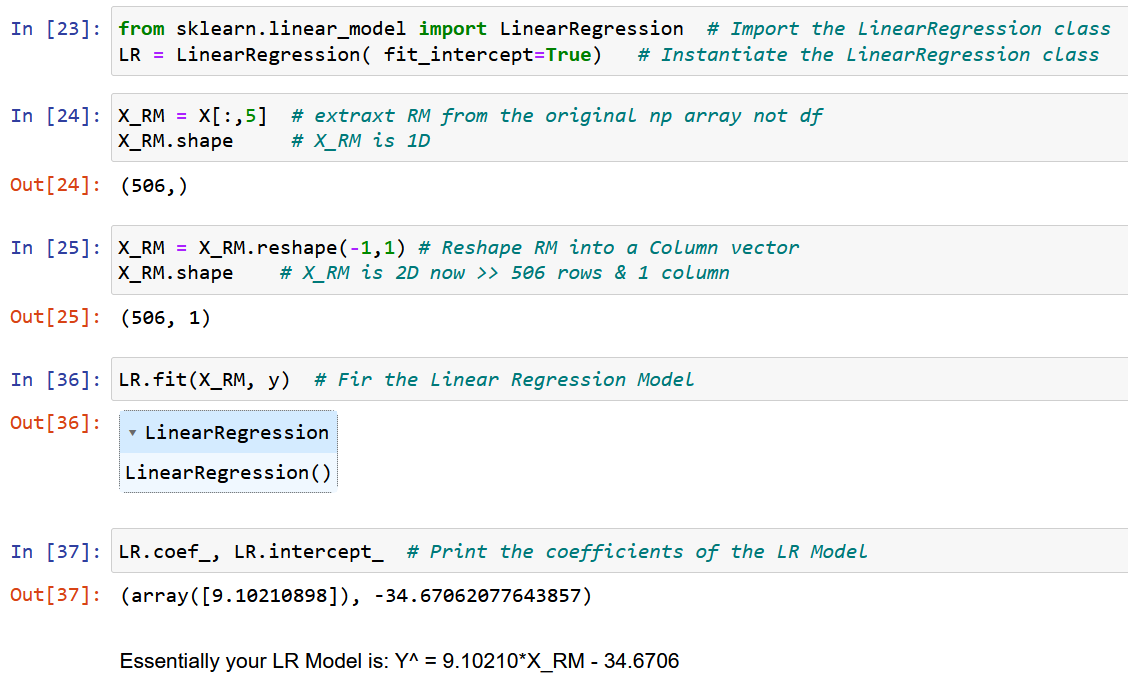
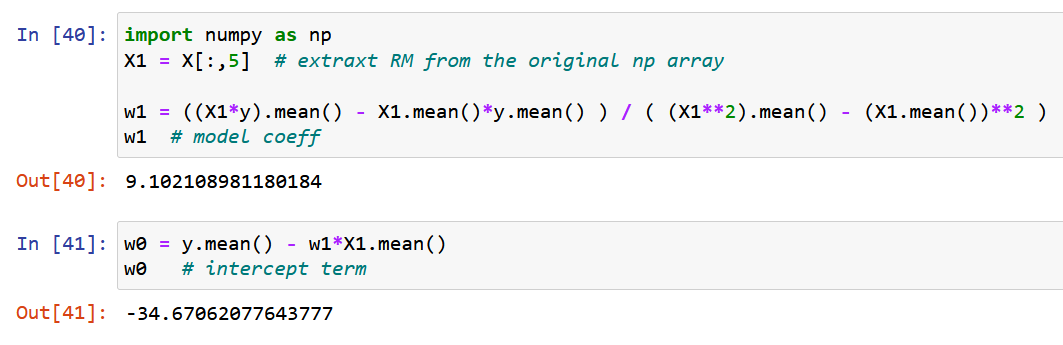
Laten we nu pure NumPy gebruiken en de modelcoëfficiënten berekenen met behulp van de uitdrukkingen die zijn afgeleid voor de optimale waarden van de modelcoëfficiënten w0 & w1 hierboven (einde van stap 2).
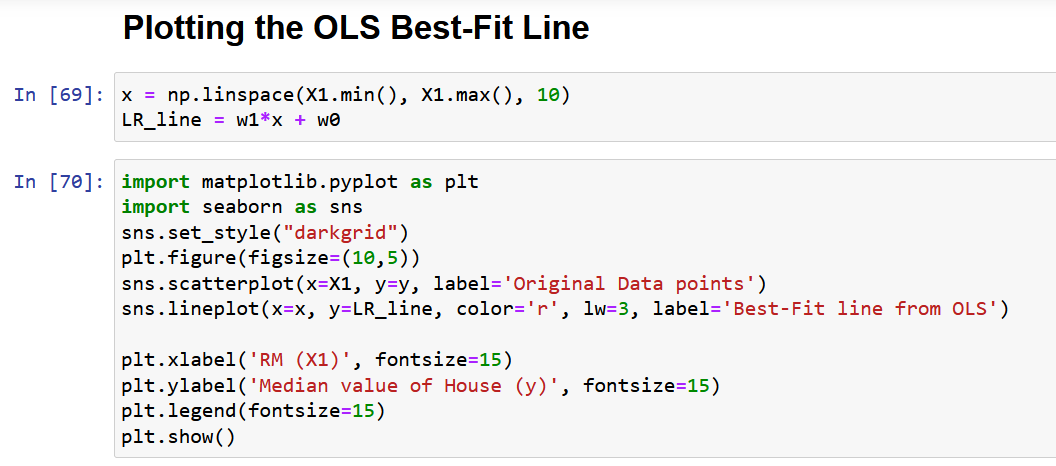
Laten we tot slot de oorspronkelijke gegevens plotten samen met de best passende lijn, zoals hieronder weergegeven.

Problemen met de scaler-vorm van OLS-oplossing
Laat me tot slot het belangrijkste probleem met de bovenstaande aanpak bespreken, zoals beschreven in sectie 4. Zoals je kunt zien aan de bovengenoemde dataset, zal elke real-life dataset meerdere kenmerken hebben. De belangrijkste reden dat ik slechts één kenmerk heb genomen om de OLS-methode in de bovenstaande sectie te demonstreren, was dat naarmate het aantal kenmerken toeneemt, het aantal gradiënten ook zou toenemen, vandaar het aantal vergelijkingen dat tegelijkertijd moet worden opgelost!
Om precies te zijn, voor 13 kenmerken (Boston dataset hierboven), hebben we 13 modelcoëfficiënten en één onderscheppingsterm, wat het totale aantal te optimaliseren variabelen op 14 brengt. Daarom verkrijgen we 14 gradiënten (de partiële afgeleide van de verliesfunctie met betrekking tot elk van deze 14 variabelen). Daarom moeten we 14 vergelijkingen oplossen (na deze 14 partiële afgeleiden gelijk te hebben gesteld aan nul, zoals beschreven in stap 2). Je hebt de complexiteit van de analytische oplossing al gerealiseerd met slechts 2 variabelen. Eerlijk gezegd heb ik geprobeerd je de MEEST uitgebreide uitleg van OLS te geven die beschikbaar is op internet, en toch is het niet gemakkelijk om de wiskunde te assimileren.
Daarom, in eenvoudige woorden, de bovenstaande analytische oplossing is NIET SCHAALBAAR!
De oplossing voor dit probleem is de "Gevectoriseerde vorm van de OLS-oplossing", die in detail zal worden besproken in een vervolgartikel (deel 2 van dit artikel), met secties 7 en 8.
Conclusie
Concluderend, de OLS-methode is een krachtig hulpmiddel voor het schatten van de parameters van een lineair regressiemodel. Het is gebaseerd op het principe van het minimaliseren van de som van de gekwadrateerde verschillen tussen de voorspelde en werkelijke waarden.
Enkele van de belangrijkste afhaalrestaurants uit het artikel zijn als volgt:
- De OLS-oplossing kan in scaler-vorm worden weergegeven, waardoor deze eenvoudig te implementeren en te interpreteren is.
- Het artikel besprak het concept van optimalisatieproblemen en de behoefte aan OLS in regressieanalyse en gaf een wiskundige formulering en een voorbeeld van OLS in actie.
- Het artikel belicht ook enkele van de beperkingen van de scaler-vorm van de OLS-oplossing, zoals schaalbaarheid en de aannames van lineariteit en constante variantie. Ik hoop dat je iets nieuws uit dit artikel hebt geleerd.
Stuur me alsjeblieft een opmerking als je vindt dat een punt/vergelijking in dit artikel uitleg behoeft of als je wilt dat ik zo gedetailleerd schrijf over een ander machine learning-algoritme.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/01/a-comprehensive-guide-to-ols-regression-part-1/
- 1
- 10
- 214
- 7
- a
- Over
- boven
- absoluut
- nauwkeurigheid
- over
- Actie
- actieve
- werkelijk
- toevoeging
- Daarnaast
- Na
- wil
- algoritme
- algoritmen
- Alles
- toewijzing
- al
- onder
- analyse
- Analytisch
- en
- nadering
- GEBIED
- dit artikel
- toegewezen
- Beschikbaar
- gemiddelde
- gebaseerde
- Eigenlijk
- vaardigheden
- achter
- Achter de schermen
- wezen
- onder
- BEST
- tussen
- vooringenomenheid
- Blauw
- het stimuleren
- Boston
- kort
- Brengt
- bebouwd
- Bellen
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- geval
- gevallen
- Centreren
- zeker
- cirkels
- aanspraak maken op
- klasse
- van nabij
- TROS
- clustering
- code
- Kolom
- combinatie van
- commentaar
- algemeen
- vergelijking
- ingewikkeldheid
- bestanddeel
- uitgebreid
- Berekenen
- concept
- conclusie
- Configuratie
- bijgevolg
- Overwegen
- constante
- beperkingen
- verband
- voortzetting
- Correlatie
- cursus
- en je merk te creëren
- cruciaal
- Actueel
- Donker
- gegevens
- data punten
- data science
- datasets
- beslissing
- deep
- definieert
- gedemonstreerd
- demonstrating
- afhankelijk
- Derivaten
- Afgeleid
- beschreven
- detail
- gegevens
- ontwikkelde
- verschil
- verschillen
- bespreken
- besproken
- verdeeld
- Val
- elk
- Economie
- beide
- uitwerken
- Engineering
- vergelijkingen
- fout
- fouten
- etc
- Ether (ETH)
- voorbeeld
- voorbeelden
- bestaat
- verwacht
- ervaring
- Ervaringen
- Verklaren
- uitgelegd
- Verklaart
- uitleg
- Verken
- uitgedrukt
- uitdrukkingen
- extract
- vertrouwd
- Kenmerk
- Voordelen
- Fed
- Velden
- Figuur
- Figuren
- finale
- Tot slot
- financiën
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- het vinden van
- vondsten
- Voornaam*
- geschikt
- volgend
- volgt
- formulier
- oppompen van
- functie
- Geven
- gegeven
- doel
- gaan
- gradiënten
- Groep
- gids
- helpt
- Hoge
- highlights
- hoop
- Huis
- HTTPS
- Mensen
- beeld
- per direct
- uitvoeren
- importeren
- belangrijk
- verbeteren
- in
- omvatten
- Inclusief
- Laat uw omzet
- onafhankelijk
- instantie
- Internet
- interpretatie
- betrekken
- IT
- sleutel
- LEARN
- leren
- LG
- beperkingen
- Lijn
- lijnen
- LOOKS
- uit
- machine
- machine learning
- Hoofd
- maken
- maken
- veel
- in kaart brengen
- Match
- wiskundig
- mathematisch
- wiskunde
- max-width
- Maximaliseren
- middel
- vermeld
- methode
- methoden
- minimalisatie
- minimaliseren
- minimum
- mengsel
- model
- modellen
- meest
- meervoudig
- Noodzaak
- behoeften
- netto
- netwerken
- Neural
- neurale netwerken
- New
- normaal
- aantal
- numpy
- doel van de persoon
- doelstellingen
- verkregen
- EEN
- Operations
- optimale
- optimalisatie
- Optimaliseer
- geoptimaliseerde
- origineel
- Overige
- totaal
- overzicht
- pakket
- parameters
- deel
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- punten
- portfolio
- mogelijk
- krachtige
- voorspellen
- voorspeld
- voorspelling
- Voorspellingen
- gepresenteerd
- prijs
- Prijzen
- prijsstelling
- Principal
- principe
- probleem
- problemen
- mits
- Python
- hoeveelheid
- willekeurige
- Lees
- lezers
- real-time
- realiseerde
- reden
- herkennen
- Rood
- verwezen
- verwijst
- regressie
- verwantschap
- stoffelijk overschot
- niet vergeten
- vertegenwoordigen
- vertegenwoordiging
- vertegenwoordigd
- vertegenwoordigt
- onderzoek
- hulpbron
- Rol
- Kamer
- dezelfde
- Schaalbaarheid
- Scenes
- Wetenschap
- scikit-leren
- sectie
- secties
- reeks
- SGD
- verschuiving
- moet
- getoond
- Shows
- evenzo
- Eenvoudig
- single
- enkelvoud
- Maat
- helling
- Klein
- oplossing
- Oplossingen
- OPLOSSEN
- sommige
- iets
- Tussenruimte
- snelheid
- squared
- pleinen
- begin
- Stap voor
- Stappen
- Still
- recht
- structuur
- dergelijk
- vermeend
- tafel
- Nemen
- Takeaways
- doelwit
- Taak
- technieken
- De
- Door
- naar
- tools
- Totaal
- Trainingen
- Bomen
- waar
- typisch
- die ten grondslag liggen
- begrijpen
- updates
- us
- .
- waarde
- Values
- divers
- controleren
- zichtbaar
- Wat
- welke
- en
- wil
- woorden
- de moeite waard
- zou
- schrijven
- geschreven
- X
- Your
- zephyrnet
- nul