Het creëren van schaalbare en efficiënte machine learning (ML)-pijplijnen is cruciaal voor het stroomlijnen van de ontwikkeling, implementatie en beheer van ML-modellen. In dit bericht presenteren we een raamwerk voor het automatiseren van het maken van een gerichte acyclische grafiek (DAG). Amazon SageMaker-pijpleidingen gebaseerd op eenvoudige configuratiebestanden. De raamwerkcode en voorbeelden die hier worden gepresenteerd, hebben alleen betrekking op modeltrainingspijplijnen, maar kunnen ook gemakkelijk worden uitgebreid tot pijpleidingen voor batchgewijze inferentie.
Dit dynamische raamwerk maakt gebruik van configuratiebestanden om voorverwerkings-, trainings-, evaluatie- en registratiestappen te orkestreren voor gebruiksscenario's met zowel één model als meerdere modellen, op basis van door de gebruiker gedefinieerde Python-scripts, infrastructuurbehoeften (inclusief Amazon virtuele privécloud (Amazon VPC) subnetten en beveiligingsgroepen, AWS Identiteits- en toegangsbeheer (IAM) rollen, AWS Sleutelbeheerservice (AWS KMS)-sleutels, containersregister en instantietypen), invoer en uitvoer Amazon eenvoudige opslagservice (Amazon S3) paden en brontags. Met configuratiebestanden (YAML en JSON) kunnen ML-professionals ongedifferentieerde code specificeren voor het orkestreren van trainingspijplijnen met behulp van declaratieve syntaxis. Dit stelt datawetenschappers in staat om snel ML-modellen te bouwen en te herhalen, en stelt ML-ingenieurs in staat om ML-pijplijnen voor continue integratie en continue levering (CI/CD) sneller te doorlopen, waardoor de productietijd voor modellen wordt verkort.
Overzicht oplossingen
De voorgestelde raamwerkcode begint met het lezen van de configuratiebestanden. Vervolgens wordt op dynamische wijze een SageMaker Pipelines DAG gemaakt op basis van de stappen die zijn gedeclareerd in de configuratiebestanden en de interacties en afhankelijkheden tussen de stappen. Dit orkestratieframework is geschikt voor gebruiksscenario's met zowel één model als meerdere modellen, en zorgt voor een soepele stroom van gegevens en processen. Dit zijn de belangrijkste voordelen van deze oplossing:
- Automatisering – De gehele ML-workflow, van gegevensvoorverwerking tot modelregistratie, wordt georkestreerd zonder handmatige tussenkomst. Dit vermindert de tijd en moeite die nodig is voor het experimenteren en operationeel maken van modellen.
- reproduceerbaarheid – Met een vooraf gedefinieerd configuratiebestand kunnen datawetenschappers en ML-ingenieurs de volledige workflow reproduceren, waardoor consistente resultaten worden bereikt over meerdere runs en omgevingen.
- Schaalbaarheid - Amazon Sage Maker wordt door de hele pijplijn gebruikt, waardoor ML-beoefenaars grote datasets kunnen verwerken en complexe modellen kunnen trainen zonder zorgen over de infrastructuur.
- Flexibiliteit – Het raamwerk is flexibel en biedt plaats aan een breed scala aan ML-gebruiksscenario's, ML-raamwerken (zoals XGBoost en TensorFlow), training met meerdere modellen en training in meerdere stappen. Elke stap van de training DAG kan via het configuratiebestand worden aangepast.
- Modelbestuur - The Amazon SageMaker-modelregister Dankzij de integratie kunnen modelversies worden gevolgd, waardoor deze met vertrouwen naar productie kunnen worden gepromoveerd.
Het volgende architectuurdiagram laat zien hoe u het voorgestelde raamwerk kunt gebruiken tijdens zowel het experimenteren als het operationeel maken van ML-modellen. Tijdens het experimenteren kunt u de in dit bericht verstrekte framework-coderepository en uw projectspecifieke broncoderepository's klonen naar Amazon SageMaker Studioen stel uw virtuele omgeving in (later in dit bericht gedetailleerd). U kunt vervolgens de scripts voor voorverwerking, training en evaluatie herhalen, evenals configuratiekeuzes. Om een SageMaker Pipelines-trainings-DAG te maken en uit te voeren, kunt u het toegangspunt van het raamwerk aanroepen, dat alle configuratiebestanden zal lezen, de noodzakelijke stappen zal creëren en deze zal orkestreren op basis van de gespecificeerde stapvolgorde en afhankelijkheden.
Tijdens de operationalisering kloont de CI-pijplijn de repository voor raamwerkcodes en projectspecifieke trainingsrepository's naar een AWS CodeBuild job, waarbij het entrypoint-script van het raamwerk wordt aangeroepen om de SageMaker Pipelines-training DAG te maken of bij te werken, en deze vervolgens uit te voeren.
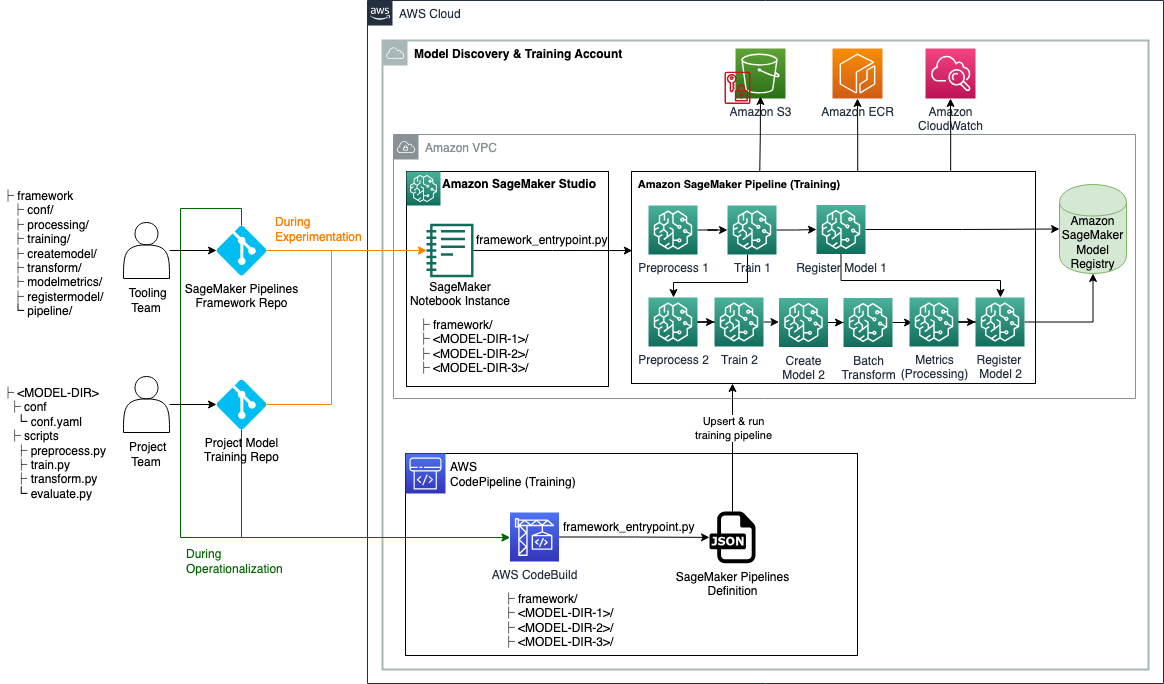
Opslagplaatsstructuur
De GitHub-repository bevat de volgende mappen en bestanden:
- /framework/conf/ – Deze map bevat een configuratiebestand dat wordt gebruikt om gemeenschappelijke variabelen in te stellen voor alle modelleringseenheden, zoals subnetten, beveiligingsgroepen en IAM-rollen tijdens de runtime. Een modelleringseenheid is een reeks van maximaal zes stappen voor het trainen van een ML-model.
- /framework/createmodel/ – Deze map bevat een Python-script dat een SageMaker-model object gebaseerd op modelartefacten uit a SageMaker Pipelines-trainingsstap. Het modelobject wordt later gebruikt in a SageMaker batch-transformatie taak voor het evalueren van de prestaties van modellen op een testset.
- /framework/modelmetrics/ – Deze map bevat een Python-script dat een Amazon SageMaker-verwerking taak voor het genereren van een JSON-rapport met modelmetrieken voor een getraind model op basis van de resultaten van een batchtransformatietaak van SageMaker die is uitgevoerd op testgegevens.
- /framework/pijplijn/ – Deze map bevat Python-scripts die Python-klassen gebruiken die zijn gedefinieerd in andere framework-mappen om een SageMaker Pipelines DAG te maken of bij te werken op basis van de opgegeven configuraties. Het model_unit.py script wordt door pipeline_service.py gebruikt om een of meer modelleringseenheden te maken. Elke modelleringseenheid is een reeks van maximaal zes stappen voor het trainen van een ML-model: het model verwerken, trainen, model maken, transformeren, metrieken en registreren. Configuraties voor elke modelleringseenheid moeten worden gespecificeerd in de respectieve repository van het model. De pipeline_service.py stelt ook afhankelijkheden in tussen de stappen van SageMaker Pipelines (hoe stappen binnen en tussen modelleringseenheden worden gesequenced of aan elkaar gekoppeld) op basis van de sectie sagemakerPipeline, die moet worden gedefinieerd in het configuratiebestand van een van de modelrepository's (het ankermodel). Hiermee kunt u de standaardafhankelijkheden die door SageMaker Pipelines worden afgeleid, overschrijven. We bespreken de configuratiebestandsstructuur later in dit bericht.
- /framework/verwerking/ – Deze map bevat een Python-script dat een SageMaker Processing-taak maakt op basis van de opgegeven Docker-image en het ingangspuntscript.
- /framework/registermodel/ – Deze map bevat een Python-script voor het registreren van een getraind model samen met de berekende statistieken in SageMaker Model Registry.
- /kader/training/ – Deze map bevat een Python-script dat een SageMaker-trainingstaak maakt.
- /framework/transformeren/ – Deze map bevat een Python-script dat een batchtransformatietaak van SageMaker maakt. In de context van modeltraining wordt dit gebruikt om de prestatiemetriek van een getraind model op basis van testgegevens te berekenen.
- /framework/hulpprogramma's/ – Deze map bevat hulpprogrammascripts voor het lezen en samenvoegen van configuratiebestanden, evenals voor logboekregistratie.
- /framework_entrypoint.py – Dit bestand is het toegangspunt van de raamwerkcode. Het roept een functie aan die is gedefinieerd in de map /framework/pipeline/ om een SageMaker Pipelines DAG te maken of bij te werken en deze uit te voeren.
- /voorbeelden/ – Deze directory bevat verschillende voorbeelden van hoe u dit automatiseringsframework kunt gebruiken om eenvoudige en complexe trainings-DAG's te maken.
- /env.env – Met dit bestand kunt u algemene variabelen, zoals subnetten, beveiligingsgroepen en IAM-rollen, instellen als omgevingsvariabelen.
- /vereisten.txt – Dit bestand specificeert Python-bibliotheken die vereist zijn voor de raamwerkcode.
Voorwaarden
U moet aan de volgende vereisten voldoen voordat u deze oplossing implementeert:
- Een AWS-account
- SageMaker Studio
- Een SageMaker-rol met lees-/schrijf- en AWS KMS-machtigingen voor Amazon S3
- Een S3-bucket voor het opslaan van gegevens, scripts en modelartefacten
- Optioneel kan de AWS-opdrachtregelinterface (AWS-CLI)
- Python3 (Python 3.7 of hoger) en de volgende Python-pakketten:
- boto3
- sagemaker
- PyYAML
- Extra Python-pakketten die worden gebruikt in uw aangepaste scripts
Implementeer de oplossing
Voer de volgende stappen uit om de oplossing te implementeren:
- Organiseer uw modeltrainingsrepository volgens de volgende structuur:
- Kloon de raamwerkcode en uw modelbroncode uit de Git-opslagplaatsen:
-
- Kloon
dynamic-sagemaker-pipelines-frameworkrepository in een trainingsdirectory. In de volgende code gaan we ervan uit dat de trainingsdirectory wordt aangeroepenaws-train: - Kloon de modelbroncode onder dezelfde map. Voor training met meerdere modellen herhaalt u deze stap voor zoveel modellen als u wilt trainen.
- Kloon
Voor training met één model moet uw directory er als volgt uitzien:
Voor training met meerdere modellen moet uw map er als volgt uitzien:
- Stel de volgende omgevingsvariabelen in. Sterretjes geven omgevingsvariabelen aan die vereist zijn; de rest is optioneel.
| Omgevingsvariabele | Omschrijving |
SMP_ACCOUNTID* |
AWS-account waar de SageMaker-pijplijn wordt uitgevoerd |
SMP_REGION* |
AWS-regio waar de SageMaker-pijplijn wordt uitgevoerd |
SMP_S3BUCKETNAME* |
S3-bucketnaam |
SMP_ROLE* |
SageMaker-rol |
SMP_MODEL_CONFIGPATH* |
Relatief pad van de configuratiebestanden voor één of meerdere modellen |
SMP_SUBNETS |
Subnet-ID's voor SageMaker-netwerkconfiguratie |
SMP_SECURITYGROUPS |
Beveiligingsgroep-ID's voor SageMaker-netwerkconfiguratie |
Voor gebruiksscenario's met één model, SMP_MODEL_CONFIGPATH zal zijn <MODEL-DIR>/conf/conf.yaml. Voor gebruiksscenario's met meerdere modellen, SMP_MODEL_CONFIGPATH zal zijn */conf/conf.yaml, waarmee u alles kunt vinden conf.yaml bestanden met behulp van de glob-module van Python en combineer ze om een globaal configuratiebestand te vormen. Tijdens het experimenteren (lokaal testen) kunt u omgevingsvariabelen opgeven in het bestand env.env en deze vervolgens exporteren door de volgende opdracht in uw terminal uit te voeren:
Merk op dat de waarden van omgevingsvariabelen in env.env moet tussen aanhalingstekens worden geplaatst (bijvoorbeeld SMP_REGION="us-east-1"). Tijdens de operationalisering moeten deze omgevingsvariabelen worden ingesteld door de CI-pijplijn.
- Creëer en activeer een virtuele omgeving door de volgende opdrachten uit te voeren:
- Installeer de vereiste Python-pakketten door de volgende opdracht uit te voeren:
- Bewerk uw modeltraining
conf.yamlbestanden. We bespreken de structuur van het configuratiebestand in de volgende sectie. - Roep vanaf de terminal het toegangspunt van het raamwerk aan om de SageMaker Pipeline-training DAG te maken of bij te werken en uit te voeren:
- Bekijk en debug de SageMaker Pipelines die op de Pijpleidingen tabblad van de gebruikersinterface van SageMaker Studio.
Structuur van het configuratiebestand
Er zijn twee soorten configuratiebestanden in de voorgestelde oplossing: raamwerkconfiguratie en modelconfiguratie. In deze sectie beschrijven we ze allemaal in detail.
Kaderconfiguratie
De /framework/conf/conf.yaml -bestand stelt de variabelen in die gemeenschappelijk zijn voor alle modelleringseenheden. Dit bevat SMP_S3BUCKETNAME, SMP_ROLE, SMP_MODEL_CONFIGPATH, SMP_SUBNETS, SMP_SECURITYGROUPS en SMP_MODELNAME. Raadpleeg stap 3 van de implementatie-instructies voor beschrijvingen van deze variabelen en hoe u deze kunt instellen via omgevingsvariabelen.
Modelconfiguratie
Voor elk model in het project moeten we het volgende specificeren in de <MODEL-DIR>/conf/conf.yaml bestand (sterretjes geven vereiste secties aan; de rest is optioneel):
- /conf/modellen* – In deze sectie kunt u een of meer modelleereenheden configureren. Wanneer de raamwerkcode wordt uitgevoerd, worden tijdens runtime automatisch alle configuratiebestanden gelezen en aan de configuratieboom toegevoegd. Theoretisch gezien kunt u alle modelleringseenheden in hetzelfde specificeren
conf.yamlbestand, maar het wordt aanbevolen om elke modelleringseenheidconfiguratie in de betreffende map of Git-opslagplaats op te geven om fouten te minimaliseren. De eenheden zijn als volgt:- {modelnaam}* – De naam van het model.
- bronmap* - Een gewone
source_dirpad dat voor alle stappen binnen de modelleereenheid moet worden gebruikt. - voorbewerken – In deze sectie worden de voorverwerkingsparameters gespecificeerd.
- trein* – In deze sectie worden de trainingstaakparameters gespecificeerd.
- transformeren* – In deze sectie worden SageMaker Transform-taakparameters gespecificeerd voor het maken van voorspellingen op basis van de testgegevens.
- schatten – In deze sectie worden SageMaker Processing-taakparameters gespecificeerd voor het genereren van een JSON-rapport met modelmetrieken voor het getrainde model.
- register* – In deze sectie worden parameters gespecificeerd voor het registreren van het getrainde model in SageMaker Model Registry.
- /conf/sagemakerPipeline* – In deze sectie wordt de SageMaker Pipelines-stroom gedefinieerd, inclusief afhankelijkheden tussen stappen. Voor gebruiksscenario's met één model wordt deze sectie gedefinieerd aan het einde van het configuratiebestand. Voor gebruiksscenario's met meerdere modellen is de
sagemakerPipelinesectie hoeft alleen te worden gedefinieerd in het configuratiebestand van een van de modellen (een van de modellen). Dit model noemen wij het ankermodel. De parameters zijn als volgt:- pijplijnNaam* – Naam van de SageMaker-pijplijn.
- modellen* – Geneste lijst met modelleringseenheden:
- {modelnaam}* – Model-ID, die moet overeenkomen met een {model-name}-ID in de sectie /conf/models.
- stappen* -
- stap_naam* – Stapnaam die moet worden weergegeven in de SageMaker Pipelines DAG.
- stap_klasse* – (Union[Verwerking, Training, CreateModel, Transform, Metrics, RegisterModel])
- stap_type* – Deze parameter is alleen vereist voor voorbewerkingsstappen, waarvoor deze op voorbewerking moet worden ingesteld. Dit is nodig om voorbewerkings- en evaluatiestappen te onderscheiden, die beide een
step_classvan Verwerking. - enable_cache – ([Unie[Waar, Onwaar]]). Dit geeft aan of dit moet worden ingeschakeld SageMaker Pipelines-caching voor deze stap.
- chain_input_source_step – ([lijst[stapnaam]]). U kunt dit gebruiken om de kanaaluitgangen van een andere stap in te stellen als invoer voor deze stap.
- chain_input_additioneel_voorvoegsel – Dit is alleen toegestaan voor stappen van de transformatie
step_classen kan worden gebruikt in combinatie metchain_input_source_stepparameter om het bestand aan te wijzen dat moet worden gebruikt als invoer voor de transformatiestap.
- stappen* -
- {modelnaam}* – Model-ID, die moet overeenkomen met een {model-name}-ID in de sectie /conf/models.
- afhankelijkheden – Deze sectie specificeert de volgorde waarin de SageMaker Pipelines-stappen moeten worden uitgevoerd. We hebben de Apache Airflow-notatie voor deze sectie aangepast (bijvoorbeeld
{step_name} >> {step_name}). Als deze sectie leeg wordt gelaten, worden expliciete afhankelijkheden gespecificeerd door dechain_input_source_stepparameter of impliciete afhankelijkheden definiëren de SageMaker Pipelines DAG-stroom.
Houd er rekening mee dat we één trainingsstap per modelleringseenheid aanbevelen. Als er meerdere trainingsstappen zijn gedefinieerd voor een modelleringseenheid, omvatten de daaropvolgende stappen impliciet de laatste trainingsstap om het modelobject te maken, metrieken te berekenen en het model te registreren. Als u meerdere modellen moet trainen, is het raadzaam meerdere modelleereenheden te maken.
Voorbeelden
In deze sectie demonstreren we drie voorbeelden van DAG's voor ML-modeltraining die zijn gemaakt met behulp van het gepresenteerde raamwerk.
Eénmodeltraining: LightGBM
Dit is een voorbeeld van één model voor een classificatie-use-case waar we gebruik van maken LightGBM in scriptmodus op SageMaker. De dataset bestaat uit categorische en numerieke variabelen om het binaire label Inkomsten te voorspellen (om te voorspellen of het onderwerp een aankoop doet of niet). De voorbewerkingsscript wordt gebruikt om de gegevens te modelleren voor training en testen en vervolgens plaats het in een S3-emmer. De S3-paden worden vervolgens aan de trainingsstap in het configuratiebestand.
Wanneer de trainingsstap wordt uitgevoerd, laadt SageMaker het bestand in de container op /opt/ml/input/data/{channelName}/, toegankelijk via de omgevingsvariabele SM_CHANNEL_{channelName} op de container (kanaalnaam= 'train' of 'test'). De trainingsscript doet het volgende:
- Laad de bestanden lokaal vanuit lokale containerpaden met behulp van de NumPy-belasting module.
- Stel hyperparameters in voor het trainingsalgoritme.
- Sla het getrainde model op op het lokale containerpad
/opt/ml/model/.
SageMaker neemt de inhoud onder /opt/ml/model/ om een tarball te maken die wordt gebruikt om het model voor hosting in SageMaker te implementeren.
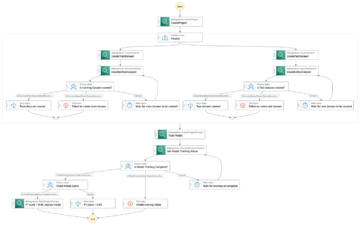
De transformatiestap heeft als invoer de geënsceneerde stap testbestand als invoer en het getrainde model om voorspellingen te doen op basis van het getrainde model. De uitvoer van de transformatiestap is geketend naar de metrische stap om het model te evalueren aan de hand van de grond waarheid, die expliciet wordt opgegeven bij de metrische stap. Ten slotte wordt de uitvoer van de metrische stap impliciet gekoppeld aan de registerstap om het model te registreren in het SageMaker Model Registry met informatie over de prestaties van het model die in de metrische stap wordt geproduceerd. De volgende afbeelding toont een visuele weergave van de training DAG. U kunt de scripts en het configuratiebestand voor dit voorbeeld raadplegen in de GitHub repo.

Eénmodeltraining: LLM-verfijning
Dit is nog een trainingsvoorbeeld met één model, waarbij we de verfijning van een Falcon-40B groot taalmodel (LLM) van Hugging Face Hub orkestreren voor een gebruiksscenario voor tekstsamenvatting. De voorbewerkingsscript laadt de samen dataset van Hugging Face, laadt de tokenizer voor het model en verwerkt de trein-/testgegevenssplitsingen voor het verfijnen van het model op deze domeingegevens in de falcon-tekst-samenvatting-voorverwerkingsstap.
De output is geketend naar de stap voor het afstemmen van de falcon-tekst-samenvatting, waarbij de trainingsscript laadt de Falcon-40B LLM vanuit Hugging Face Hub en begint met versnelde fijnafstemming LoRA op de treinsplitsing. Het model wordt na verfijning in dezelfde stap geëvalueerd poortwachters het evaluatieverlies dat de stap voor het afstemmen van de falcon-tekst-samenvatting mislukt, waardoor de SageMaker-pijplijn stopt voordat deze het verfijnde model kan registreren. Anders wordt de stap voor het afstemmen van de falcon-text-samenvatting met succes uitgevoerd en wordt het model geregistreerd in het SageMaker Model Registry. De volgende afbeelding toont een visuele weergave van de LLM-fijnafstelling DAG. De scripts en het configuratiebestand voor dit voorbeeld zijn beschikbaar in de GitHub repo.

Training met meerdere modellen
Dit is een trainingsvoorbeeld met meerdere modellen waarbij een Principal Component Analysis (PCA)-model wordt getraind voor dimensionaliteitsreductie, en een TensorFlow Multilayer Perceptron-model wordt getraind voor Voorspelling van de huizenprijs in Californië. De voorverwerkingsstap van het TensorFlow-model maakt gebruik van een getraind PCA-model om de dimensionaliteit van de trainingsgegevens te verminderen. We voegen een afhankelijkheid toe aan de configuratie om ervoor te zorgen dat het TensorFlow-model wordt geregistreerd na PCA-modelregistratie. De volgende afbeelding toont een visuele weergave van het DAG-voorbeeld met meerdere modellen. De scripts en configuratiebestanden voor dit voorbeeld zijn beschikbaar in de GitHub repo.

Opruimen
Voer de volgende stappen uit om uw bronnen op te schonen:
- Gebruik de AWS CLI om lijst en verwijderen eventuele resterende pijplijnen die zijn gemaakt door de Python-scripts.
- Verwijder optioneel andere AWS-bronnen, zoals de S3-bucket of IAM-rol die buiten SageMaker Pipelines is gemaakt.
Conclusie
In dit bericht presenteerden we een raamwerk voor het automatiseren van het maken van SageMaker Pipelines DAG op basis van configuratiebestanden. Het voorgestelde raamwerk biedt een toekomstgerichte oplossing voor de uitdaging van het orkestreren van complexe ML-workloads. Door een configuratiebestand te gebruiken, biedt SageMaker Pipelines de flexibiliteit om orkestratie te bouwen met minimale code, zodat u het proces van het maken en beheren van pijplijnen met zowel één als meerdere modellen kunt stroomlijnen. Deze aanpak bespaart niet alleen tijd en middelen, maar bevordert ook de beste praktijken van MLOps, wat bijdraagt aan het algehele succes van ML-initiatieven. Voor meer informatie over implementatiedetails raadpleegt u de GitHub repo.
Over de auteurs
 Luis Felipe Yepez Barrios, is een Machine Learning Engineer bij AWS Professional Services, gericht op schaalbare gedistribueerde systemen en automatiseringstools om wetenschappelijke innovatie op het gebied van Machine Learning (ML) te versnellen. Bovendien helpt hij zakelijke klanten bij het optimaliseren van hun machine learning-oplossingen via AWS-services.
Luis Felipe Yepez Barrios, is een Machine Learning Engineer bij AWS Professional Services, gericht op schaalbare gedistribueerde systemen en automatiseringstools om wetenschappelijke innovatie op het gebied van Machine Learning (ML) te versnellen. Bovendien helpt hij zakelijke klanten bij het optimaliseren van hun machine learning-oplossingen via AWS-services.
 Jinzhao Feng, is een Machine Learning Engineer bij AWS Professional Services. Hij richt zich op het ontwerpen en implementeren van grootschalige generatieve AI en klassieke ML-pijplijnoplossingen. Hij is gespecialiseerd in FMOps, LLMOps en gedistribueerde trainingen.
Jinzhao Feng, is een Machine Learning Engineer bij AWS Professional Services. Hij richt zich op het ontwerpen en implementeren van grootschalige generatieve AI en klassieke ML-pijplijnoplossingen. Hij is gespecialiseerd in FMOps, LLMOps en gedistribueerde trainingen.
 Harde Asnani, is een Machine Learning-ingenieur bij AWS. Zijn achtergrond ligt in Applied Data Science met een focus op het op grote schaal operationeel maken van Machine Learning-workloads in de cloud.
Harde Asnani, is een Machine Learning-ingenieur bij AWS. Zijn achtergrond ligt in Applied Data Science met een focus op het op grote schaal operationeel maken van Machine Learning-workloads in de cloud.
 Hassan Shojaei, is een Sr. Data Scientist bij AWS Professional Services, waar hij klanten in verschillende sectoren helpt bij het oplossen van hun zakelijke uitdagingen door het gebruik van big data, machine learning en cloudtechnologieën. Voorafgaand aan deze rol leidde Hasan meerdere initiatieven om nieuwe op fysica gebaseerde en datagestuurde modelleringstechnieken te ontwikkelen voor topenergiebedrijven. Buiten zijn werk heeft Hasan een passie voor boeken, wandelen, fotografie en geschiedenis.
Hassan Shojaei, is een Sr. Data Scientist bij AWS Professional Services, waar hij klanten in verschillende sectoren helpt bij het oplossen van hun zakelijke uitdagingen door het gebruik van big data, machine learning en cloudtechnologieën. Voorafgaand aan deze rol leidde Hasan meerdere initiatieven om nieuwe op fysica gebaseerde en datagestuurde modelleringstechnieken te ontwikkelen voor topenergiebedrijven. Buiten zijn werk heeft Hasan een passie voor boeken, wandelen, fotografie en geschiedenis.
 Alec Jenab, is een Machine Learning Engineer die gespecialiseerd is in het ontwikkelen en operationeel maken van machine learning-oplossingen op schaal voor zakelijke klanten. Alec heeft een passie voor het op de markt brengen van innovatieve oplossingen, vooral op gebieden waar machinaal leren de eindgebruikerservaring op betekenisvolle wijze kan verbeteren. Buiten zijn werk speelt hij graag basketbal, snowboarden en het ontdekken van verborgen pareltjes in San Francisco.
Alec Jenab, is een Machine Learning Engineer die gespecialiseerd is in het ontwikkelen en operationeel maken van machine learning-oplossingen op schaal voor zakelijke klanten. Alec heeft een passie voor het op de markt brengen van innovatieve oplossingen, vooral op gebieden waar machinaal leren de eindgebruikerservaring op betekenisvolle wijze kan verbeteren. Buiten zijn werk speelt hij graag basketbal, snowboarden en het ontdekken van verborgen pareltjes in San Francisco.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/automate-amazon-sagemaker-pipelines-dag-creation/
- :is
- :niet
- :waar
- $UP
- 120
- 160
- 2%
- 4
- 5
- 7
- 8
- 9
- a
- in staat
- Over
- versneld
- toegang
- beschikbaar
- accommoderen
- Volgens
- Account
- het bereiken van
- over
- activeren
- acyclische
- aangepast
- toevoegen
- Na
- tegen
- AI
- algoritme
- Alles
- toelaten
- toegestaan
- toestaat
- langs
- ook
- Amazone
- Amazon Sage Maker
- Amazon SageMaker-pijpleidingen
- Amazon Web Services
- onder
- an
- analyse
- Anker
- en
- Nog een
- elke
- apache
- toegepast
- nadering
- architectuur
- ZIJN
- gebieden
- AS
- helpt
- ervan uitgaan
- At
- automatiseren
- webmaster.
- automatiseren
- Automatisering
- Beschikbaar
- AWS
- AWS professionele services
- achtergrond
- gebaseerde
- Basketbal
- BE
- vaardigheden
- betekent
- BEST
- 'best practices'
- Groot
- Big data
- binair
- Boeken
- zowel
- Bringing
- bouw
- bedrijfsdeskundigen
- maar
- by
- berekenen
- berekend
- Bellen
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- oproepen
- CAN
- geval
- gevallen
- is geschikt
- oorzaken
- geketend
- uitdagen
- uitdagingen
- Kanaal
- keuzes
- klassen
- classificatie
- schoon
- cli
- klanten
- Cloud
- code
- combineren
- Gemeen
- Bedrijven
- complex
- bestanddeel
- Zorgen
- vertrouwen
- Configuratie
- configuraties
- samenwerking
- consequent
- bestaat uit
- Containers
- containers
- bevat
- content
- verband
- doorlopend
- bij te dragen
- deksel
- en je merk te creëren
- aangemaakt
- creëert
- Wij creëren
- het aanmaken
- cruciaal
- gewoonte
- Klanten
- aangepaste
- DAG
- gegevens
- data science
- data scientist
- Gegevensgestuurde
- datasets
- gedeclareerd
- afnemende
- Standaard
- bepalen
- gedefinieerd
- definieert
- verwijderen
- levering
- tonen
- afhankelijkheden
- Afhankelijkheid
- implementeren
- het inzetten
- inzet
- beschrijven
- detail
- gedetailleerd
- gegevens
- ontwikkelen
- het ontwikkelen van
- Ontwikkeling
- diagram
- anders
- gerichte
- directories
- directory
- het ontdekken van
- bespreken
- weergegeven
- onderscheiden
- verdeeld
- gedistribueerde systemen
- gedistribueerde training
- havenarbeider
- doet
- domein
- gedurende
- dynamisch
- dynamisch
- elk
- doeltreffend
- inspanning
- machtigt
- in staat stellen
- maakt
- waardoor
- einde
- energie-niveau
- ingenieur
- Ingenieurs
- verzekeren
- Enterprise
- zakelijke klanten
- Geheel
- toegang
- Milieu
- omgevingen
- fouten
- vooral
- Ether (ETH)
- schatten
- geëvalueerd
- evalueren
- evaluatie
- Alle
- voorbeeld
- voorbeelden
- bespoedigen
- ervaring
- uitdrukkelijk
- exporteren
- uitgebreid
- Gezicht
- FAIL
- vals
- sneller
- veld-
- Figuur
- Dien in
- Bestanden
- Tot slot
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Flexibiliteit
- flexibel
- stroom
- Focus
- gericht
- richt
- volgend
- volgt
- Voor
- formulier
- toekomstgericht
- Achtergrond
- frameworks
- Francisco
- oppompen van
- functie
- Bovendien
- het genereren van
- generatief
- generatieve AI
- Git
- Globaal
- bestuur
- diagram
- meer
- Groep
- Groep
- Hebben
- met
- he
- helpt
- hier
- verborgen
- wandelen
- zijn
- geschiedenis
- Hosting
- behuizing
- Hoe
- How To
- HTML
- http
- HTTPS
- Naaf
- IAM
- ICS
- identificatie
- Identiteit
- ids
- if
- beeld
- uitvoering
- uitvoering
- verbeteren
- in
- Anders
- omvat
- Inclusief
- aangeven
- geeft aan
- industrieën
- afgeleide
- informatie
- Infrastructuur
- initiatieven
- Innovatie
- innovatieve
- invoer
- binnen
- installeren
- instantie
- instructies
- integratie
- interacties
- tussenkomst
- in
- IT
- HAAR
- Jobomschrijving:
- aansluiting
- jpg
- json
- sleutel
- toetsen
- label
- taal
- Groot
- Achternaam*
- later
- leren
- LED
- links
- bibliotheken
- als
- Lijn
- Lijst
- lm
- laden
- ladingen
- lokaal
- plaatselijk
- logging
- Kijk
- ziet eruit als
- uit
- machine
- machine learning
- maken
- MERKEN
- maken
- management
- beheren
- handboek
- veel
- Markt
- Match
- metriek
- Metriek
- minimaal
- verkleinen
- ML
- MLops
- Mode
- model
- modellering
- modellen
- module
- meer
- meervoudig
- naam
- noodzakelijk
- Noodzaak
- nodig
- behoeften
- genesteld
- netwerken
- volgende
- geen
- roman
- numeriek
- object
- of
- Aanbod
- on
- EEN
- Slechts
- optimaliseren
- or
- georkestreerd
- orkestratie
- bestellen
- Overige
- anders-
- uitgang
- uitgangen
- buiten
- totaal
- override
- Paketten
- parameter
- parameters
- hartstochtelijk
- pad
- paden
- voor
- prestatie
- uitgevoerd
- fotografie
- pijpleiding
- geplaatst
- Plato
- Plato gegevensintelligentie
- PlatoData
- spelen
- punt
- Post
- praktijken
- voorspellen
- Voorspellingen
- vereisten
- presenteren
- gepresenteerd
- prijs
- Principal
- Voorafgaand
- privaat
- processen
- verwerking
- geproduceerd
- productie
- professioneel
- project
- bevordert
- Het bevorderen van
- voorgestelde
- mits
- biedt
- inkomsten
- Python
- snel
- reeks
- Lees
- gemakkelijk
- lezing
- adviseren
- aanbevolen
- verminderen
- vermindert
- reductie
- verwijzen
- regio
- registreren
- geregistreerd
- registreren
- Registratie
- register
- resterende
- herhaling
- verslag
- bewaarplaats
- vertegenwoordiging
- nodig
- Voorwaarden
- hulpbron
- Resources
- degenen
- REST
- Resultaten
- inkomsten
- beoordelen
- Rol
- rollen
- lopen
- lopend
- loopt
- runtime
- sagemaker
- SageMaker-pijpleidingen
- dezelfde
- heilige
- San Francisco
- schaalbare
- Scale
- Wetenschap
- wetenschappelijk
- Wetenschapper
- wetenschappers
- script
- scripts
- sectie
- secties
- veiligheid
- Volgorde
- Diensten
- reeks
- Sets
- verscheidene
- moet
- Shows
- Eenvoudig
- ZES
- glad
- So
- oplossing
- Oplossingen
- OPLOSSEN
- bron
- broncode
- gespecialiseerde
- specialiseert
- gespecificeerd
- spleet
- splits
- starts
- Stap voor
- Stappen
- stop
- mediaopslag
- bewaartemperatuur
- gestroomlijnd
- stroomlijnen
- structuur
- studio
- onderwerpen
- subnetten
- volgend
- succes
- Met goed gevolg
- dergelijk
- geleverde
- syntaxis
- Systems
- Nemen
- neemt
- technieken
- Technologies
- tensorflow
- terminal
- proef
- Testen
- tekst
- dat
- De
- Het register
- hun
- Ze
- harte
- theoretisch
- daarom
- Deze
- dit
- drie
- Door
- overal
- niet de tijd of
- naar
- top
- Tracking
- Trainen
- getraind
- Trainingen
- Transformeren
- boom
- waar
- twee
- types
- ui
- voor
- eenheid
- eenheden
- bijwerken
- .
- use case
- gebruikt
- Gebruiker
- Gebruikerservaring
- toepassingen
- gebruik
- utility
- Values
- variabele
- variabelen
- versies
- via
- Virtueel
- visuele
- we
- web
- webservices
- GOED
- wanneer
- of
- welke
- WIE
- breed
- Grote range
- wil
- Met
- binnen
- zonder
- Mijn werk
- workflow
- XGBoost
- YAML
- u
- Your
- zephyrnet