Organisaties hebben ervoor gekozen om datameren bovenop te bouwen Amazon eenvoudige opslagservice (Amazon S3) voor vele jaren. Een data lake is de meest populaire keuze voor organisaties om al hun organisatiegegevens op te slaan die zijn gegenereerd door verschillende teams, in verschillende bedrijfsdomeinen, in alle verschillende indelingen en zelfs in de loop van de geschiedenis. Volgens Een studie, ziet het gemiddelde bedrijf het volume van hun gegevens groeien met een snelheid van meer dan 50% per jaar, en beheert het gewoonlijk gemiddeld 33 unieke gegevensbronnen voor analyse.
Teams proberen vaak duizenden taken uit relationele databases te repliceren met hetzelfde ETL-patroon (extraheren, transformeren en laden). Er wordt veel moeite gestoken in het onderhouden van de taakstatussen en het plannen van deze individuele taken. Deze aanpak helpt de teams tabellen toe te voegen met weinig wijzigingen en handhaaft ook de taakstatus met minimale inspanning. Dit kan leiden tot een enorme verbetering in de ontwikkelingstijdlijn en het gemakkelijk volgen van de taken.
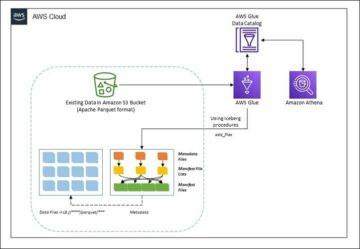
In dit bericht laten we u zien hoe u eenvoudig al uw relationele datastores kunt repliceren naar een transactioneel datameer op een geautomatiseerde manier met een enkele ETL-taak met behulp van Apache Iceberg en AWS lijm.
Oplossingsarchitectuur
Datameren zijn meestal georganiseerd het gebruik van afzonderlijke S3-buckets voor drie gegevenslagen: de onbewerkte laag met gegevens in de oorspronkelijke vorm, de faselaag met tussentijdse verwerkte gegevens die zijn geoptimaliseerd voor gebruik, en de analyselaag met geaggregeerde gegevens voor specifieke gebruikssituaties. In de onbewerkte laag zijn tabellen meestal georganiseerd op basis van hun gegevensbronnen, terwijl tabellen in de werklaag zijn georganiseerd op basis van de bedrijfsdomeinen waartoe ze behoren.
Dit bericht geeft een AWS CloudFormatie sjabloon die een AWS Glue-taak implementeert die een Amazon S3-pad leest voor één gegevensbron van de onbewerkte laag van het datameer en de gegevens opneemt in Apache Iceberg-tabellen op de werkgebiedlaag met behulp van AWS Glue-ondersteuning voor data lake-frameworks. De taak verwacht dat tabellen in de onbewerkte laag op de manier worden gestructureerd AWS-databasemigratieservice (AWS DMS) neemt ze op: schema, dan tabel, dan databestanden.
Deze oplossing maakt gebruik van AWS Systems Manager-parameteropslag voor tafelconfiguratie. U moet deze parameter aanpassen door de tabellen op te geven die u wilt verwerken en hoe, inclusief informatie zoals de primaire sleutel, partities en het bijbehorende bedrijfsdomein. De taak gebruikt deze informatie om automatisch een database te maken (als deze nog niet bestaat) voor elk bedrijfsdomein, de Iceberg-tabellen te maken en het laden van gegevens uit te voeren.
Eindelijk kunnen we gebruiken Amazone Athene om de gegevens in de Iceberg-tabellen op te vragen.
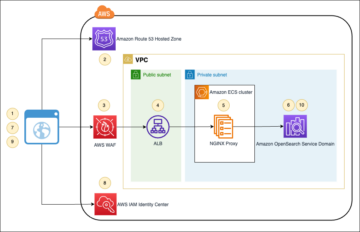
Het volgende diagram illustreert deze architectuur.

Deze implementatie heeft de volgende overwegingen:
- Alle tabellen van de gegevensbron moeten een primaire sleutel hebben om met deze oplossing te kunnen worden gerepliceerd. De primaire sleutel kan een enkele kolom zijn of een samengestelde sleutel met meer dan één kolom.
- Als de data lake tabellen bevat die geen upserts nodig hebben of geen primaire sleutel hebben, kunt u ze uitsluiten van de parameterconfiguratie en traditionele ETL-processen implementeren om ze in de data lake op te nemen. Dat valt buiten het bestek van dit bericht.
- Als er aanvullende gegevensbronnen zijn die moeten worden opgenomen, kunt u meerdere CloudFormation-stacks implementeren, één voor elke gegevensbron.
- De AWS Glue-taak is ontworpen om gegevens in twee fasen te verwerken: de initiële belasting die wordt uitgevoerd nadat AWS DMS de volledige laadtaak heeft voltooid, en de incrementele belasting die wordt uitgevoerd volgens een schema dat CDC-bestanden (Change Data Capture) toepast die zijn vastgelegd door AWS DMS. Incrementele verwerking wordt uitgevoerd met behulp van een AWS Glue-taakbladwijzer.
Er zijn negen stappen om deze zelfstudie te voltooien:
- Stel een broneindpunt in voor AWS DMS.
- Implementeer de oplossing met behulp van AWS CloudFormation.
- Bekijk de AWS DMS-replicatietaak.
- Voeg optioneel machtigingen toe voor codering en decodering of AWS Lake-formatie.
- Bekijk de tabelconfiguratie in Parameter Store.
- Voer het initiële laden van gegevens uit.
- Voer incrementeel laden van gegevens uit.
- Tabelopname bewaken.
- Plan het incrementeel laden van batchgegevens.
Voorwaarden
Voordat u aan deze zelfstudie begint, moet u al bekend zijn met Iceberg. Als u dat niet bent, kunt u aan de slag gaan door een enkele tabel te repliceren volgens de instructies in Implementeer een op CDC gebaseerde UPSERT in een datameer met behulp van Apache Iceberg en AWS Glue. Stel bovendien het volgende in:
Stel een broneindpunt in voor AWS DMS
Voordat we onze AWS DMS-taak maken, moeten we een broneindpunt instellen om verbinding te maken met de brondatabase:
- Kies op de AWS DMS-console: Eindpunten in het navigatievenster.
- Kies Eindpunt maken.
- Als uw database op Amazon RDS draait, kiest u Selecteer RDS DB-instantieen kies vervolgens de instantie uit de lijst. Kies anders de bronengine en geef de verbindingsinformatie op via AWS-geheimenmanager of handmatig.
- Voor Eindpunt-ID, voer een naam in voor het eindpunt; bijvoorbeeld source-postgresql.
- Kies Eindpunt maken.
Implementeer de oplossing met behulp van AWS CloudFormation
Maak een CloudFormation-stack met behulp van de meegeleverde sjabloon. Voer de volgende stappen uit:
- Kies Start stapel:

- Kies Volgende.
- Geef een stapelnaam op, zoals
transactionaldl-postgresql. - Voer de vereiste parameters in:
- DMSS3EindpuntIAMRolARN – De IAM-rol ARN voor AWS DMS om gegevens naar Amazon S3 te schrijven.
- ReplicatieInstanceArn – De AWS DMS-replicatie-instantie ARN.
- S3BucketStage – De naam van de bestaande bucket die wordt gebruikt voor de stagelaag van het datameer.
- S3BucketLijm – De naam van de bestaande S3-bucket voor het opslaan van AWS Glue-scripts.
- S3EmmerRaw – De naam van de bestaande bucket die wordt gebruikt voor de onbewerkte laag van het datameer.
- BronEndpointArn – Het AWS DMS-eindpunt ARN dat u eerder hebt gemaakt.
- Bron naam – De willekeurige identificatie van de gegevensbron die moet worden gerepliceerd (bijvoorbeeld
postgres). Dit wordt gebruikt om het S3-pad van het datameer (onbewerkte laag) te definiëren waar gegevens worden opgeslagen.
- Wijzig de volgende parameters niet:
- BronS3BucketBlog – De bucketnaam waarin het meegeleverde AWS Glue-script is opgeslagen.
- BronS3BucketPrefix – De naam van het bucketvoorvoegsel waarin het meegeleverde AWS Glue-script is opgeslagen.
- Kies Volgende tweemaal.
- kies Ik erken dat AWS CloudFormation IAM-bronnen met aangepaste namen kan maken.
- Kies Maak een stapel.
Na ongeveer 5 minuten wordt de CloudFormation-stack geïmplementeerd.
Bekijk de AWS DMS-replicatietaak
De AWS CloudFormation-implementatie heeft een AWS DMS-doeleindpunt voor u gemaakt. Vanwege twee specifieke eindpuntinstellingen worden de gegevens opgenomen zoals we die nodig hebben op Amazon S3.
- Kies op de AWS DMS-console: Eindpunten in het navigatievenster.
- Zoek en kies het eindpunt dat begint met
dmsIcebergs3endpoint. - Controleer de eindpuntinstellingen:
DataFormatis gespecificeerd alsparquet.TimestampColumnNamezal de kolom toevoegenlast_update_timemet de aanmaakdatum van de records op Amazon S3.

De implementatie creëert ook een AWS DMS-replicatietaak die begint met dmsicebergtask.
- Kies Replicatie taken in het navigatievenster en zoek naar de taak.
Je zult zien dat de Taaktype is gemarkeerd als Volledige belasting, voortdurende replicatie. AWS DMS voert een eerste volledige belasting van bestaande gegevens uit en maakt vervolgens incrementele bestanden met wijzigingen in de brondatabase.
Op de Kaartregels tabblad, zijn er twee soorten regels:
- Een selectieregel met de naam van het bronschema en de tabellen die worden opgenomen uit de brondatabase. Standaard gebruikt het de voorbeelddatabase die is opgegeven in de vereisten,
dms_sample, en alle tabellen met het trefwoord %. - Twee transformatieregels die in de doelbestanden op Amazon S3 de schemanaam en tabelnaam als kolommen opnemen. Dit wordt door onze AWS Glue-taak gebruikt om te weten met welke tabellen de bestanden in het datameer overeenkomen.
Raadpleeg voor meer informatie over het aanpassen van dit voor uw eigen gegevensbronnen Selectieregels en acties.

Laten we enkele configuraties wijzigen om onze taakvoorbereiding te voltooien.
- Op de Acties menu, kies wijzigen.
- In het Taakinstellingen sectie, onder Stop de taak nadat de volledige belasting is voltooid, kiezen Stop na het aanbrengen van wijzigingen in de cache.
Op deze manier kunnen we de initiële belasting en het incrementeel genereren van bestanden als twee verschillende stappen regelen. We gebruiken deze aanpak in twee stappen om de AWS Glue-taak één keer per stap uit te voeren.
- Onder Taaklogboeken, kiezen Schakel CloudWatch-logboeken in.
- Kies Bespaar.
- Wacht ongeveer 1 minuut totdat de status van de databasemigratietaak wordt weergegeven als Klaar.
Voeg machtigingen toe voor codering en decodering of Lake Formation
Optioneel kunt u machtigingen toevoegen voor codering en decodering of Lake Formation.
Voeg machtigingen voor codering en decodering toe
Als uw S3-buckets die worden gebruikt voor de raw- en stage-lagen zijn versleuteld met AWS Sleutelbeheerservice (AWS KMS) door de klant beheerde sleutels, moet u machtigingen toevoegen om de AWS Glue-taak toegang te geven tot de gegevens:
Machtigingen voor Lake Formation toevoegen
Als u machtigingen beheert met behulp van Lake Formation, moet u uw AWS Glue-taak toestaan om de databases en tabellen van uw domein te maken via de IAM-rol GlueJobRole.
- Verleen machtigingen om databases te maken (voor instructies, zie Een database maken).
- Geef SUPER-machtigingen aan de
defaultdatabase. - Machtigingen voor gegevenslocatie verlenen.
- Als u handmatig databases maakt, moet u alle databases toestemming geven om tabellen te maken. Verwijzen naar Tabelmachtigingen verlenen met behulp van de Lake Formation-console en de benoemde resourcemethode or Machtigingen voor gegevenscatalogus verlenen met behulp van de LF-TBAC-methode volgens uw gebruikssituatie.
Nadat u de latere stap van het uitvoeren van de eerste gegevenslading hebt voltooid, moet u ervoor zorgen dat u ook machtigingen toevoegt voor consumenten om de tabellen te doorzoeken. De taakrol wordt de eigenaar van alle gemaakte tabellen en de data lake-beheerder kan vervolgens toekenningen uitvoeren aan extra gebruikers.
Bekijk de tabelconfiguratie in Parameter Store
De AWS Glue-taak die de gegevensopname in Iceberg-tabellen uitvoert, gebruikt de tabelspecificatie in Parameter Store. Voer de volgende stappen uit om het parameterarchief te bekijken dat automatisch voor u is geconfigureerd. Wijzig indien nodig volgens uw eigen behoeften.
- Kies op de Parameter Store-console Mijn parameters in het navigatievenster.
De CloudFormation-stack heeft twee parameters gemaakt:
iceberg-configvoor taakconfiguratiesiceberg-tablesvoor tafelconfiguratie
- Kies de parameter ijsberg-tafels.
De JSON-structuur bevat informatie die AWS Glue gebruikt om gegevens te lezen en de Iceberg-tabellen op het doeldomein te schrijven:
- Eén voorwerp per tafel – De naam van het object wordt gemaakt met behulp van de schemanaam, een punt en de tabelnaam; Bijvoorbeeld,
schema.table. - hoofdsleutel – Dit moet voor elke brontabel worden gespecificeerd. U kunt een enkele kolom opgeven of een door komma's gescheiden lijst met kolommen (zonder spaties).
- partitieCols – Dit verdeelt optioneel kolommen voor doeltabellen. Als u geen gepartitioneerde tabellen wilt maken, geeft u een lege tekenreeks op. Geef anders een enkele kolom op of een door komma's gescheiden lijst met te gebruiken kolommen (zonder spaties).
- Als u uw eigen gegevensbron wilt gebruiken, gebruikt u de volgende JSON-code en vervangt u de tekst in CAPS uit het meegeleverde sjabloon. Als u de meegeleverde voorbeeldgegevensbron gebruikt, behoudt u de standaardinstellingen:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Kies Wijzigingen opslaan.
Voer het initiële laden van gegevens uit
Nu de vereiste configuratie is voltooid, nemen we de eerste gegevens op. Deze stap bestaat uit drie delen: het opnemen van de gegevens uit de relationele brondatabase in de onbewerkte laag van het datameer, het maken van de ijsbergtabellen op de werklaag van het datameer en het verifiëren van de resultaten met behulp van Athena.
Neem gegevens op in de onbewerkte laag van het datameer
Voer de volgende stappen uit om gegevens van de relationele gegevensbron (PostgreSQL als u het verstrekte voorbeeld gebruikt) op te nemen in ons transactionele gegevensmeer met behulp van Iceberg:
- Kies op de AWS DMS-console: Databasemigratietaken in het navigatievenster.
- Selecteer de replicatietaak die u hebt gemaakt en op de Acties menu, kies Herstarten/Hervatten.
- Wacht ongeveer 5 minuten totdat de replicatietaak is voltooid. U kunt de tabellen controleren die zijn opgenomen op de Statistieken tabblad van de replicatietaak.

Na enkele minuten eindigt de taak met het bericht Volle lading compleet.
- Kies op de Amazon S3-console de bucket die u hebt gedefinieerd als de onbewerkte laag.
Onder het S3-voorvoegsel dat is gedefinieerd op AWS DMS (bijvoorbeeld postgres), zou u een hiërarchie van mappen moeten zien met de volgende structuur:
- Schema
- Tafel naam
LOAD00000001.parquetLOAD0000000N.parquet
- Tafel naam

Als uw S3-bucket leeg is, controleert u Problemen met migratietaken oplossen in de AWS Database Migration Service voordat u de AWS Glue-taak uitvoert.
Creëer en neem gegevens op in Iceberg-tabellen
Laten we, voordat we de taak uitvoeren, door het script van de AWS Glue-taak navigeren die wordt geleverd als onderdeel van de CloudFormation-stack om het gedrag ervan te begrijpen.
- Kies op de AWS Glue Studio-console: Vacatures in het navigatievenster.
- Zoek de baan die begint met
IcebergJob-en een achtervoegsel van uw CloudFormation-stacknaam (bijvoorbeeldIcebergJob-transactionaldl-postgresql). - Kies de baan.

Het taakscript haalt de configuratie die het nodig heeft uit Parameter Store. De functie getConfigFromSSM() retourneert taakgerelateerde configuraties zoals bron- en doelbuckets van waaruit de gegevens moeten worden gelezen en geschreven. De variabele ssmparam_table_values bevatten tabelgerelateerde informatie zoals het gegevensdomein, de tabelnaam, de partitiekolommen en de primaire sleutel van de tabellen die moeten worden opgenomen. Zie de volgende Python-code:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']Het script gebruikt een willekeurige catalogusnaam voor Iceberg die is gedefinieerd als my_catalog. Dit wordt geïmplementeerd op de AWS Glue Data Catalog met behulp van Spark-configuraties, dus een SQL-bewerking die naar my_catalog verwijst, wordt toegepast op de Data Catalog. Zie de volgende code:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
Het script herhaalt de tabellen die zijn gedefinieerd in Parameter Store en voert de logica uit om te detecteren of de tabel bestaat en of de binnenkomende gegevens een initiële belasting of een upsert zijn:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')De initialLoadRecordsSparkSQL() functie laadt initiële gegevens wanneer er geen bewerkingskolom aanwezig is in de S3-bestanden. AWS DMS voegt deze kolom alleen toe aan Parquet-gegevensbestanden die zijn geproduceerd door de continue replicatie (CDC). Het laden van gegevens wordt uitgevoerd met behulp van de opdracht INSERT INTO met SparkSQL. Zie de volgende code:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Nu voeren we de AWS Glue-taak uit om de eerste gegevens in de Iceberg-tabellen op te nemen. De CloudFormation-stack voegt de --datalake-formats parameter, waarbij de vereiste Iceberg-bibliotheken aan de taak worden toegevoegd.
- Kies Voer de taak uit.
- Kies Taak loopt om de stand te bewaken. Wacht tot de status is Rennen geslaagd.
Controleer de geladen gegevens
Voer de volgende stappen uit om te bevestigen dat de taak de gegevens heeft verwerkt zoals verwacht:
- Kies op de Athena-console Query-editor in het navigatievenster.
- Controleren
AwsDataCatalogis geselecteerd als gegevensbron. - Onder Database, kies het gegevensdomein dat u wilt verkennen, op basis van de configuratie die u hebt gedefinieerd in de parameteropslag. Als u de meegeleverde voorbeelddatabase gebruikt, gebruik dan
sports.
Onder Tabellen en weergaven, kunnen we de lijst met tabellen zien die zijn gemaakt door de AWS Glue-taak.
- Kies het optiemenu (drie puntjes) naast de eerste tabelnaam en kies vervolgens Voorbeeld weergeven.
U kunt de gegevens zien die in Iceberg-tabellen zijn geladen. 
Voer incrementeel laden van gegevens uit
Nu beginnen we met het vastleggen van wijzigingen uit onze relationele database en deze toe te passen op het transactionele datameer. Deze stap bestaat ook uit drie delen: de wijzigingen vastleggen, toepassen op de Iceberg-tabellen en de resultaten verifiëren.
Leg wijzigingen vast uit de relationele database
Vanwege de configuratie die we hebben opgegeven, stopte de replicatietaak na het uitvoeren van de volledige belastingsfase. Nu herstarten we de taak om incrementele bestanden met wijzigingen toe te voegen aan de onbewerkte laag van het datameer.
- Selecteer op de AWS DMS-console de taak die we eerder hebben gemaakt en uitgevoerd.
- Op de Acties menu, kies Hervat.
- Kies Taak starten om te beginnen met het vastleggen van wijzigingen.
- Om het aanmaken van nieuwe bestanden op het datameer te activeren, voert u invoegingen, updates of verwijderingen uit op de tabellen van uw brondatabase met behulp van uw favoriete databasebeheertool. Als u de meegeleverde voorbeelddatabase gebruikt, kunt u de volgende SQL-opdrachten uitvoeren:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- Kies op de pagina AWS DMS-taakdetails de optie Tabel statistieken tabblad om de vastgelegde wijzigingen te bekijken.

- Open de onbewerkte laag van het datameer om een nieuw bestand te vinden met de incrementele wijzigingen in het voorvoegsel van elke tabel, bijvoorbeeld onder de
sporting_eventvoorvoegsel.
Het record met wijzigingen voor de sporting_event tabel ziet eruit als de volgende schermafbeelding.

Let op de Op kolom in het begin geïdentificeerd met een update (U). De tweede datum/tijd-waarde is ook de controlekolom die door AWS DMS is toegevoegd met het tijdstip waarop de wijziging is vastgelegd.

Breng wijzigingen aan op de Iceberg-tabellen met behulp van AWS Glue
Nu voeren we de AWS Glue-taak opnieuw uit en deze zal automatisch alleen de nieuwe incrementele bestanden verwerken aangezien de taakbladwijzer is ingeschakeld. Laten we eens kijken hoe het werkt.
De dedupCDCRecords() functie voert deduplicatie van gegevens uit omdat meerdere wijzigingen in een enkele record-ID kunnen worden vastgelegd in hetzelfde gegevensbestand op Amazon S3. Deduplicatie wordt uitgevoerd op basis van de last_update_time kolom toegevoegd door AWS DMS die het tijdstempel aangeeft van wanneer de wijziging is vastgelegd. Zie de volgende Python-code:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFOp lijn 99, de upsertRecordsSparkSQL() De functie voert de upsert op een vergelijkbare manier uit als bij de initiële belasting, maar deze keer met een SQL MERGE-opdracht.
Bekijk de aangebrachte wijzigingen
Open de Athena-console en voer een query uit die de gewijzigde records in de brondatabase selecteert. Als u de meegeleverde voorbeelddatabase gebruikt, gebruikt u een van de volgende SQL-query's:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Tabelopname bewaken
Het AWS Glue-taakscript is gecodeerd met simple Afhandelen van Python-uitzonderingen om fouten op te vangen tijdens het verwerken van een specifieke tabel. De taakbladwijzer wordt opgeslagen nadat elke tabel met succes is verwerkt, om te voorkomen dat tabellen opnieuw worden verwerkt als de taakuitvoering opnieuw wordt geprobeerd voor de tabellen met fouten.
De AWS-opdrachtregelinterface (AWS CLI) biedt een get-job-bookmark commando voor AWS Glue dat inzicht geeft in de status van de bladwijzer voor elke verwerkte tabel.
- Kies op de AWS Glue Studio-console de ETL-taak.
- Kies de Taak loopt tabblad en kopieer de taakuitvoerings-ID.
- Voer de volgende opdracht uit op een terminal die is geverifieerd voor de AWS CLI, ter vervanging
<GLUE_JOB_RUN_ID>op regel 1 met de waarde die u hebt gekopieerd. Als uw CloudFormation-stack geen naam heefttransactionaldl-postgresql, geef de naam van uw taak op regel 2 van het script:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunIn deze oplossing, wanneer een tabelverwerking een uitzondering veroorzaakt, zal de AWS Glue-taak niet mislukken volgens deze logica. In plaats daarvan wordt de tabel toegevoegd aan een array die wordt afgedrukt nadat de taak is voltooid. In een dergelijk scenario wordt de taak gemarkeerd als mislukt nadat deze heeft geprobeerd de rest van de tabellen te verwerken die in de onbewerkte gegevensbron zijn gedetecteerd. Op deze manier hoeven tabellen zonder fouten niet te wachten tot de gebruiker het probleem op de conflicterende tabellen identificeert en oplost. De gebruiker kan snel taakuitvoeringen detecteren die problemen hadden met behulp van de AWS Glue-taakuitvoeringsstatus, en identificeren welke specifieke tabellen het probleem veroorzaken met behulp van de CloudWatch-logboeken voor de taakuitvoering.
- Het taakscript implementeert deze functie met de volgende Python-code:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')De volgende schermafbeelding laat zien hoe de CloudWatch-logboeken zoeken naar tabellen die fouten veroorzaken bij de verwerking.

Afgestemd op de AWS goed ontworpen raamwerk voor data-analyse praktijken, kunt u meer geavanceerde controlemechanismen aanpassen om belanghebbenden te identificeren en op de hoogte te stellen wanneer er fouten in de gegevenspijplijnen verschijnen. U kunt bijvoorbeeld een Amazon DynamoDB controletabel om alle tabellen en taakuitvoeringen met fouten op te slaan, of met behulp van Amazon eenvoudige meldingsservice (Amazon SNS) naar stuur waarschuwingen naar operators wanneer aan bepaalde criteria is voldaan.
Plan het incrementeel laden van batchgegevens
De CloudFormation-stack implementeert een Amazon EventBridge regel (standaard uitgeschakeld) die ervoor kan zorgen dat de AWS Glue-taak volgens een schema wordt uitgevoerd. Voer de volgende stappen uit om uw eigen planning op te geven en de regel in te schakelen:
- Kies op de EventBridge-console Reglement in het navigatievenster.
- Zoek naar de regel voorafgegaan door de naam van uw CloudFormation-stack gevolgd door
JobTrigger(bijvoorbeeld,transactionaldl-postgresql-JobTrigger-randomvalue). - Kies de regel.
- Onder Evenementenplanning, kiezen Edit.
Het standaardschema is geconfigureerd om elk uur te activeren.
- Geef het schema op waarop u de taak wilt uitvoeren.
- Daarnaast kunt u een EventBridge cron-expressie door selecteren Een fijnmazig schema.

- Wanneer u klaar bent met het instellen van de cron-expressie, kiest u Volgende drie keer, en kies uiteindelijk Regel bijwerken om wijzigingen op te slaan.
De regel wordt standaard uitgeschakeld gemaakt, zodat u eerst de eerste gegevens kunt laden.
- Activeer de regel door te kiezen Enable .
U kunt gebruik maken van de Monitoren tabblad om regelaanroepen te bekijken, of rechtstreeks op de AWS Glue Werk uitvoeren details.
Conclusie
Na het implementeren van deze oplossing heeft u de opname van uw tabellen op één enkele relationele gegevensbron geautomatiseerd. Organisaties die een data lake als hun centrale dataplatform gebruiken, hebben meestal te maken met meerdere, soms zelfs tientallen databronnen. Ook vereisen steeds meer use-cases dat organisaties transactiemogelijkheden implementeren in het datameer. U kunt deze oplossing gebruiken om de acceptatie van dergelijke mogelijkheden in al uw relationele gegevensbronnen te versnellen om nieuwe zakelijke use-cases mogelijk te maken en het implementatieproces te automatiseren om meer waarde uit uw gegevens te halen.
Over de auteurs
 Luis Gerardo Baeza is een Big Data Architect in het Amazon Web Services (AWS) Data Lab. Hij heeft 12 jaar ervaring met het helpen van organisaties in de gezondheidszorg, de financiële sector en het onderwijs bij het implementeren van enterprise-architectuurprogramma's, cloud computing en data-analysemogelijkheden. Luis helpt momenteel organisaties in heel Latijns-Amerika om strategische data-initiatieven te versnellen.
Luis Gerardo Baeza is een Big Data Architect in het Amazon Web Services (AWS) Data Lab. Hij heeft 12 jaar ervaring met het helpen van organisaties in de gezondheidszorg, de financiële sector en het onderwijs bij het implementeren van enterprise-architectuurprogramma's, cloud computing en data-analysemogelijkheden. Luis helpt momenteel organisaties in heel Latijns-Amerika om strategische data-initiatieven te versnellen.
 Sai Kiran Reddy Aenugu is een Data Architect in het Amazon Web Services (AWS) Data Lab. Hij heeft 10 jaar ervaring met het implementeren van datalaad-, transformatie- en visualisatieprocessen. SaiKiran helpt momenteel organisaties in Noord-Amerika bij het adopteren van moderne data-architecturen zoals datalakes en datamesh. Hij heeft ervaring in de retail-, luchtvaart- en financiële sector.
Sai Kiran Reddy Aenugu is een Data Architect in het Amazon Web Services (AWS) Data Lab. Hij heeft 10 jaar ervaring met het implementeren van datalaad-, transformatie- en visualisatieprocessen. SaiKiran helpt momenteel organisaties in Noord-Amerika bij het adopteren van moderne data-architecturen zoals datalakes en datamesh. Hij heeft ervaring in de retail-, luchtvaart- en financiële sector.
 Narendra Merla is een Data Architect in het Amazon Web Services (AWS) Data Lab. Hij heeft 12 jaar ervaring in het ontwerpen en in productie brengen van zowel real-time als batch-georiënteerde datapijplijnen en het bouwen van datalakes in zowel cloud- als on-premise-omgevingen. Narendra helpt momenteel organisaties in Noord-Amerika bij het bouwen en ontwerpen van robuuste data-architecturen en heeft ervaring in de telecom- en financiële sector.
Narendra Merla is een Data Architect in het Amazon Web Services (AWS) Data Lab. Hij heeft 12 jaar ervaring in het ontwerpen en in productie brengen van zowel real-time als batch-georiënteerde datapijplijnen en het bouwen van datalakes in zowel cloud- als on-premise-omgevingen. Narendra helpt momenteel organisaties in Noord-Amerika bij het bouwen en ontwerpen van robuuste data-architecturen en heeft ervaring in de telecom- en financiële sector.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Over
- versnellen
- toegang
- Volgens
- erkennen
- over
- aanpassen
- toegevoegd
- Extra
- Daarnaast
- Voegt
- beheerder
- administratie
- adopteren
- Adoptie
- Na
- luchtvaart
- Alles
- al
- Amazone
- Amazone Athene
- Amazon RDS
- Amazon Web Services
- Amazon Web Services (AWS)
- Amerika
- analyse
- analytics
- en
- Angeles
- apache
- verschijnen
- Aanvraag
- toegepast
- Het toepassen van
- nadering
- ongeveer
- architectuur
- reeks
- geassocieerd
- geverifieerd
- automatiseren
- geautomatiseerde
- webmaster.
- automatiseren
- gemiddelde
- vermijd
- AWS
- AWS CloudFormatie
- AWS lijm
- gebaseerde
- vleermuizen
- omdat
- worden
- vaardigheden
- Begin
- Groot
- Big data
- bouw
- bouwer
- Gebouw
- bedrijfsdeskundigen
- Kan krijgen
- mogelijkheden
- caps
- vangen
- Het vastleggen
- geval
- gevallen
- catalogus
- het worstelen
- Veroorzaken
- oorzaken
- veroorzakend
- CDC
- centraal
- zeker
- verandering
- Wijzigingen
- keuze
- Kies
- het kiezen van
- uitgekozen
- Cloud
- cloud computing
- code
- Kolom
- columns
- afstand
- compleet
- computergebruik
- Configuratie
- configuraties
- Bevestigen
- Tegenstrijdig
- Verbinden
- versterken
- overwegingen
- troosten
- Consumenten
- consumptie
- bevat
- voortzetten
- doorlopend
- onder controle te houden
- kon
- en je merk te creëren
- aangemaakt
- creëert
- Wij creëren
- het aanmaken
- criteria
- Op dit moment
- gewoonte
- klant
- aan te passen
- gegevens
- gegevens Analytics
- Datameer
- Gegevensplatform
- Database
- databanken
- Datum
- Standaard
- gedefinieerd
- implementeren
- ingezet
- het inzetten
- inzet
- ontplooit
- Design
- ontworpen
- ontwerpen
- gegevens
- gedetecteerd
- Ontwikkeling
- anders
- direct
- invalide
- Verdeeld
- Nee
- domein
- domeinen
- Dont
- gedurende
- elk
- Vroeger
- gemakkelijk
- Onderwijs
- inspanning
- beide
- in staat stellen
- ingeschakeld
- versleutelde
- encryptie
- Endpoint
- Motor
- Enter
- Enterprise
- omgevingen
- fouten
- Ether (ETH)
- Zelfs
- Alle
- voorbeeld
- overschrijdt
- Behalve
- uitzondering
- bestaand
- bestaat
- verwacht
- verwacht
- ervaring
- Verken
- extensies
- extract
- Mislukt
- vertrouwd
- Mode
- Kenmerk
- weinig
- Dien in
- Bestanden
- Tot slot
- financiën
- financieel
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- afmaken
- Voornaam*
- gevolgd
- volgend
- Voor consumenten
- formulier
- vorming
- Achtergrond
- oppompen van
- vol
- functie
- gegenereerde
- generatie
- krijgen
- toe te kennen
- subsidies
- Groeiend
- handvat
- gezondheidszorg
- het helpen van
- helpt
- hiërarchie
- geschiedenis
- bezit
- Hoe
- How To
- HTML
- HTTPS
- reusachtig
- IAM
- geïdentificeerd
- identificatie
- identificeert
- identificeren
- uitvoeren
- uitvoering
- geïmplementeerd
- uitvoering
- gereedschap
- verbetering
- in
- omvatten
- omvat
- Inclusief
- Inkomend
- geeft aan
- individueel
- informatie
- eerste
- initiatieven
- Inzetstukken
- inzicht
- instantie
- verkrijgen in plaats daarvan
- instructies
- Gemiddeld
- kwestie
- problemen
- IT
- herhaling
- Jobomschrijving:
- Vacatures
- json
- Houden
- sleutel
- toetsen
- blijven
- laboratorium
- meer
- Latijns
- Latijns Amerika
- lagen
- Legkippen
- leiden
- LEARN
- bibliotheken
- LIMIT
- Lijn
- Lijst
- laden
- het laden
- ladingen
- plaats
- Kijk
- LOOKS
- de
- Los Angeles
- lot
- Hoofd
- onderhoudt
- maken
- beheerd
- management
- manager
- beheren
- handmatig
- veel
- in kaart brengen
- gemarkeerd
- Menu
- gaan
- Bericht
- macht
- migratie
- minimum
- minuut
- minuten
- Modern
- wijzigen
- monitor
- Grensverkeer
- meer
- meest
- Meest populair
- meervoudig
- naam
- Genoemd
- namen
- OP DEZE WEBSITE VIND JE
- Navigatie
- Noodzaak
- nodig
- behoeften
- New
- volgende
- noorden
- Noord-Amerika
- notificatie
- aantal
- object
- objecten
- EEN
- lopend
- OP
- operatie
- geoptimaliseerde
- Opties
- organisatorische
- organisaties
- Georganiseerd
- origineel
- anders-
- buiten
- het te bezitten.
- eigenaar
- brood
- parameter
- parameters
- deel
- onderdelen
- pad
- Patronen
- uitvoeren
- uitvoerend
- presteert
- periode
- permissies
- fase
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- Populair
- Post
- postgresql
- praktijken
- bij voorkeur
- vereisten
- presenteren
- primair
- probleem
- processen
- verwerking
- geproduceerd
- Programma's
- zorgen voor
- mits
- biedt
- Python
- snel
- verhogen
- tarief
- Rauw
- ruwe data
- Lees
- real-time
- record
- archief
- vervangen
- gerepliceerd
- kopiëren
- vereisen
- nodig
- hulpbron
- Resources
- REST
- Resultaten
- <HR>Retail
- terugkeer
- Retourneren
- beoordelen
- robuust
- Rol
- Regel
- reglement
- lopen
- lopend
- dezelfde
- Bespaar
- scenario
- rooster
- omvang
- scripts
- Ontdek
- Tweede
- Sectoren
- te zien
- gekozen
- selecteren
- selectie
- apart
- Diensten
- reeks
- het instellen van
- settings
- moet
- tonen
- Shows
- gelijk
- Eenvoudig
- sinds
- single
- So
- oplossing
- Lost op
- sommige
- geraffineerd
- bron
- bronnen
- ruimten
- Vonk
- specifiek
- specificatie
- gespecificeerd
- Sport
- SQL
- stack
- Stacks
- Stadium
- stakeholders
- begin
- gestart
- Start
- starts
- Staten
- statistiek
- Status
- Stap voor
- Stappen
- gestopt
- mediaopslag
- shop
- opgeslagen
- winkels
- strategisch
- structuur
- gestructureerde
- studio
- Met goed gevolg
- dergelijk
- Super
- ondersteuning
- Systems
- tafel
- doelwit
- Taak
- taken
- team
- teams
- telecom
- sjabloon
- terminal
- De
- De Bron
- hun
- duizenden kosten
- drie
- Door
- niet de tijd of
- tijdlijn
- keer
- tijdstempel
- naar
- tools
- top
- Totaal
- Tracking
- traditioneel
- transactionele
- Transformeren
- Transformatie
- leiden
- zelfstudie
- types
- voor
- begrijpen
- unieke
- bijwerken
- updates
- .
- use case
- Gebruiker
- gebruikers
- doorgaans
- waarde
- het verifiëren
- Bekijk
- visualisatie
- volume
- wachten
- Magazijn
- web
- webservices
- welke
- wil
- binnen
- zonder
- Bedrijven
- schrijven
- geschreven
- YAML
- jaar
- jaar
- Your
- zephyrnet