Data-integratieprocessen profiteren net als elke andere software van geautomatiseerd testen. Toch is het zeldzaam om een datapijplijnproject te vinden met een geschikte set geautomatiseerde tests. Zelfs als een project veel tests heeft, zijn deze vaak ongestructureerd, communiceren ze hun doel niet en zijn ze moeilijk uit te voeren.
Een kenmerk van datapijplijn ontwikkeling is het regelmatig vrijgeven van gegevens van hoge kwaliteit om gebruikersfeedback en acceptatie te verkrijgen. Aan het einde van elke herhaling van de gegevenspijplijn wordt verwacht dat de gegevens van hoge kwaliteit zijn voor de volgende fase.
Geautomatiseerd testen is essentieel voor het testen van de integratie van datapijplijnen. Handmatig testen is onpraktisch in zeer iteratieve en adaptieve ontwikkelomgevingen.
Primaire problemen met handmatige gegevenstests
Ten eerste duurt het te lang en is het een kritieke belemmering voor de frequente levering van pijpleidingen. Teams die voornamelijk afhankelijk zijn van handmatig testen, stellen het testen uiteindelijk uit tot speciale testperiodes, waardoor bugs zich kunnen ophopen.
Ten tweede is handmatige datapijplijntesten onvoldoende reproduceerbaar voor regressietesten.
Het automatiseren van de datapijplijntests vereist initiële planning en voortdurende zorgvuldigheid, maar zodra de technische teams automatisering toepassen, is het succes van het project zekerder.
Varianten van datapijplijnen
- Extraheren, transformeren en laden (ETL)
- Extraheren, laden en transformeren (ELT)
- Datalake, datawarehouse-pijplijnen
- Realtime pijplijnen
- Machine learning-pijplijnen
Componenten voor gegevenspijplijnen voor overweging van testautomatisering
Datapijplijnen bestaan uit verschillende componenten, die elk verantwoordelijk zijn voor een specifieke taak. De elementen van een datapijplijn omvatten:
- Data bronnen: De oorsprong van de gegevens
- Gegevensopname: Het proces van het verzamelen van gegevens uit de gegevensbron
- Gegevenstransformatie: Het proces waarbij de verzamelde gegevens worden omgezet in een formaat dat kan worden gebruikt voor verdere analyse
- Gegevensverificaties/validaties: Het proces om ervoor te zorgen dat de gegevens nauwkeurig en consistent zijn
- Data opslag: Het proces van het opslaan van de getransformeerde en gevalideerde gegevens in een datawarehouse of datalake
- Data analyse: Het proces van het analyseren van de opgeslagen gegevens om patronen, trends en inzichten te identificeren
Best practices voor het automatiseren van het testen van datapijplijnen
Wat en wanneer te automatiseren (of zelfs of u automatisering nodig heeft) zijn cruciale beslissingen voor het test- (of ontwikkel)team. De selectie van geschikte producteigenschappen voor automatisering bepaalt grotendeels het succes van automatisering.
Bij het automatiseren van tests voor een datapijplijn omvatten best practices:
- Definieer duidelijke en specifieke testdoelstellingen: Voordat u begint met testen, is het essentieel om te definiëren wat u met testen wilt bereiken. Als u dit doet, kunt u effectieve, efficiënte tests maken die waardevolle inzichten opleveren.
- Test alle workflows van de datapijplijn: Een gegevenspijplijn bestaat meestal uit verschillende onderdelen: gegevensopname, verwerking, transformatie en opslag. Het is belangrijk om elk onderdeel te testen om de juiste en soepele gegevensstroom door de pijplijn te garanderen.
- Gebruik geloofwaardige testgegevens: Bij het testen van een gegevenspijplijn is het belangrijk om realistische gegevens te gebruiken die realistische scenario's nabootsen. Dit helpt bij het identificeren van eventuele problemen die kunnen optreden bij het omgaan met verschillende gegevenstypen.
- Automatiseer met effectieve tools: Dit kan met behulp van testkaders en tools.
- Controleer de pijplijn regelmatig: Zelfs nadat het testen is voltooid, is het essentieel om de pijplijn regelmatig te controleren om er zeker van te zijn dat deze werkt zoals bedoeld. Dit helpt problemen te identificeren voordat ze kritieke problemen worden.
- Betrek belanghebbenden: Betrek belanghebbenden zoals data-analisten, data-engineers en zakelijke gebruikers bij het testproces. Dit helpt ervoor te zorgen dat de tests relevant en waardevol zijn voor alle belanghebbenden.
- Documentatie bijhouden: Het is belangrijk om documenten bij te houden die de tests, testgevallen en testresultaten beschrijven. Dit helpt ervoor te zorgen dat de tests in de loop van de tijd kunnen worden gerepliceerd en onderhouden.
Wees voorzichtig; automatisering van het wijzigen van onstabiele kenmerken moet worden vermeden. Tegenwoordig kan geen enkele bekende zakelijke tool of reeks methoden/processen worden beschouwd als een volledige end-to-end-test van de datapijplijn.
Overweeg uw testautomatiseringsdoelen
Testautomatisering van datapijplijnen wordt beschreven als het gebruik van tools om 1) testuitvoering te controleren, 2) vergelijkingen van werkelijke uitkomsten met voorspelde uitkomsten, en 3) het opzetten van testvoorwaarden en andere testcontrole- en testrapportagefuncties.
Over het algemeen omvat testautomatisering het automatiseren van een bestaand handmatig proces dat gebruikmaakt van een formeel testproces.
Hoewel handmatige datapijplijntests veel datafouten kunnen aan het licht brengen, zijn ze arbeidsintensief en tijdrovend. Bovendien kunnen handmatige tests niet effectief zijn bij het opsporen van bepaalde defecten.
Datapijplijnautomatisering omvat het ontwikkelen van testprogramma's die anders handmatig zouden moeten worden uitgevoerd. Zodra de tests zijn geautomatiseerd, kunnen ze snel worden herhaald. Dit is vaak de meest kostenefficiënte methode voor een datapijplijn die een lange levensduur kan hebben. Zelfs kleine fixes of verbeteringen gedurende de levensduur van de pijplijn kunnen ervoor zorgen dat functies kapot gaan die eerder werkten.
Het integreren van geautomatiseerd testen in de ontwikkeling van datapijplijnen vormt een unieke reeks uitdagingen. De huidige testtools voor geautomatiseerde softwareontwikkeling kunnen niet gemakkelijk worden aangepast aan database- en datapijplijnprojecten.
De grote verscheidenheid aan datapijplijnarchitecturen maakt deze uitdagingen nog ingewikkelder omdat ze meerdere databases omvatten die speciale codering vereisen voor gegevensextractie, transformaties, laden, data-opschoning, gegevensaggregaties en gegevensverrijking.
Testautomatiseringstools kunnen duur zijn en worden meestal samen met handmatig testen gebruikt. Ze kunnen echter op de lange termijn kosteneffectief worden, vooral wanneer ze herhaaldelijk in regressietests worden gebruikt.
Frequente kandidaten voor testautomatisering
- BI-rapport testen
- Zakelijk, naleving door de overheid
- Verwerking van gegevensaggregatie
- Gegevens opschonen en archiveren
- Testen van gegevenskwaliteit
- Gegevensafstemming (bijv. Bron naar doel)
- Data transformaties
- De gegevens van de dimensietabel worden geladen
- End-to-end testen
- ETL, ELT validatie- en verificatietesten
- Feitentabelgegevens worden geladen
- Verificatie van het laden van bestanden/gegevens
- Incrementele belastingstests
- Belasting- en schaalbaarheidstesten
- Ontbrekende bestanden, records, velden
- prestatietests
- Referentiële integriteit
- Regressietesten
- Beveiligingstests
- Brongegevens testen en profileren
- Staging, validaties van ODS-gegevens
- Unit-, integratie- en regressietesten
Het automatiseren van deze tests kan nodig zijn vanwege de complexiteit van de verwerking en het aantal bronnen en doelen dat moet worden geverifieerd.
Voor de meeste projecten zijn testprocessen voor datapijplijnen ontworpen om de datakwaliteit te verifiëren en te implementeren.
De verscheidenheid aan gegevenstypen die tegenwoordig beschikbaar zijn, stelt testuitdagingen voor
Er is tegenwoordig een grote verscheidenheid aan gegevenstypen beschikbaar, variërend van traditionele gestructureerde gegevenstypen zoals tekst, getallen en datums tot ongestructureerde gegevenstypen zoals audio, afbeeldingen en video. Daarnaast worden verschillende soorten semi-gestructureerde gegevens, zoals XML en JSON, veel gebruikt bij webontwikkeling en gegevensuitwisseling.
Met de komst van het Internet of Things (IoT) is er een explosie geweest van verschillende datatypes, waaronder sensordata, locatiedata en machine-to-machine communicatiedata. Aangezien deze gegevenstypen worden geëxtraheerd en getransformeerd, kan het testen ingewikkelder worden zonder de juiste hulpmiddelen. Dit heeft geleid tot nieuwe datamanagementtechnologieën en analytische technieken zoals stream processing, edge computing en real-time analytics.
Afbeelding 1 toont voorbeelden van gegevenstypen die tegenwoordig veel worden gebruikt. Het enorme aantal vertegenwoordigt uitdagingen bij het testen of vereiste transformaties correct worden uitgevoerd. Als gevolg hiervan moeten dataprofessionals goed thuis zijn in een breed scala aan datatypen en zich kunnen aanpassen om opkomende trends en technologieën te testen.
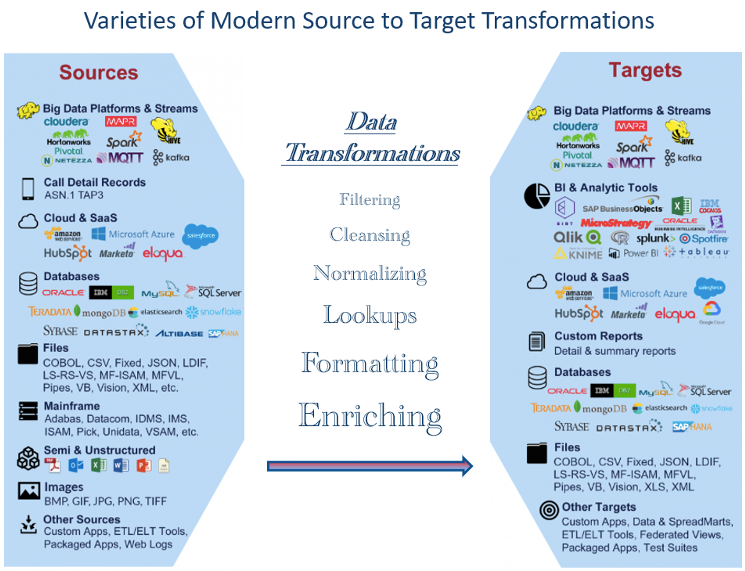
Evalueer pijplijncomponenten voor mogelijk geautomatiseerd testen
Een sleutelelement van agile en andere moderne ontwikkelingen is geautomatiseerd testen. Dit bewustzijn kunnen we toepassen op de datapijplijn.
Een essentieel aspect van het testen van datapijplijnen is dat het aantal uitgevoerde tests zal blijven toenemen om toegevoegde functionaliteit en onderhoud te controleren. Figuur 2 laat veel gebieden zien waar testautomatisering kan worden toegepast in een datapijplijn.
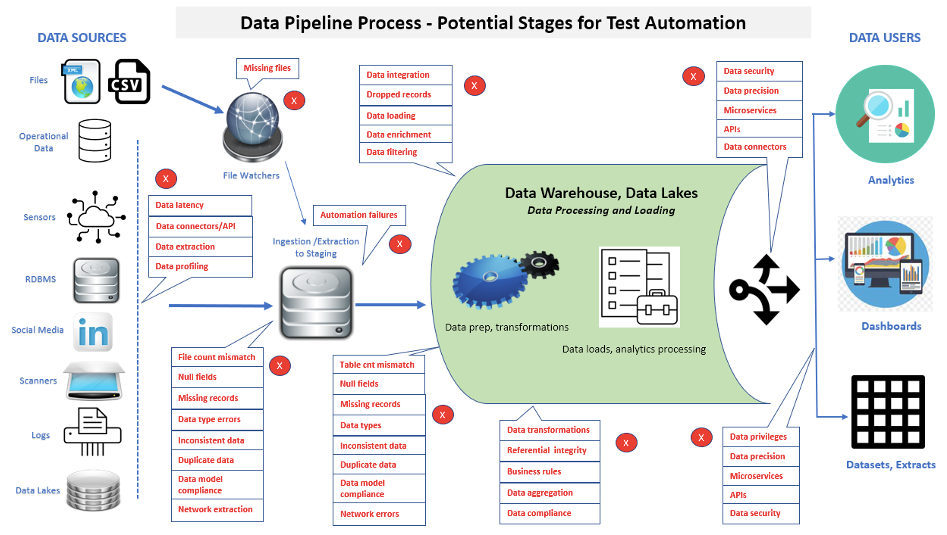
Bij het implementeren van testautomatisering kunnen gegevens worden gevolgd van bronlagen, via gegevenspijplijnverwerking, naar ladingen in de gegevenspijplijn en uiteindelijk naar de front-end-applicaties of rapporten. Stel dat er corrupte gegevens worden gevonden in een front-end applicatie of rapport. In dat geval kan de uitvoering van geautomatiseerde suites helpen sneller te bepalen of individuele problemen zich bevinden in databronnen, een datapijplijnproces, een nieuw geladen datapijplijndatabase/datamart of business intelligence/analytics-rapporten.
De nadruk op de snelle identificatie van gegevens- en prestatieproblemen in complexe datapijplijnarchitecturen biedt een belangrijk hulpmiddel voor het bevorderen van ontwikkelingsefficiëntie, het verkorten van bouwcycli en het voldoen aan releasecriteria.
Bepaal testcategorieën om te automatiseren
De kunst is om te bepalen wat er geautomatiseerd moet worden en hoe elke taak moet worden afgehandeld. Er moet rekening worden gehouden met een aantal vragen bij het automatiseren van tests, zoals:
- Wat zijn de kosten van het automatiseren van de tests?
- Wie is verantwoordelijk voor testautomatisering (bijv. Dev., QA, data-engineers)?
- Welke testtools moeten worden gebruikt (bijv. open source, leverancier)?
- Zullen de gekozen tools aan alle verwachtingen voldoen?
- Hoe worden de testresultaten gerapporteerd?
- Wie interpreteert de testresultaten?
- Hoe worden de testscripts onderhouden?
- Hoe organiseren we de scripts voor gemakkelijke en nauwkeurige toegang?
Afbeelding 3 toont voorbeelden van tijdsduren (voor testuitvoering, defectidentificatie en rapportage) voor handmatige vs. geautomatiseerde testcases uit een daadwerkelijke projectervaring.
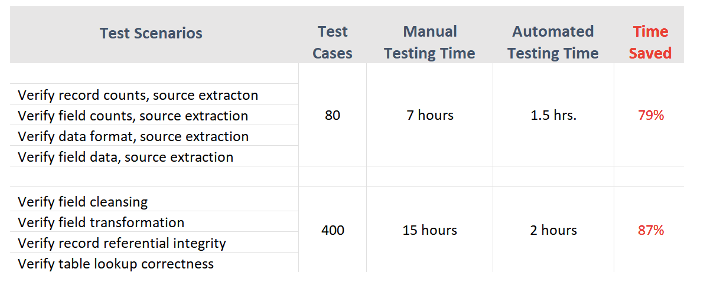
Geautomatiseerde datapijplijntests hebben tot doel de meest kritieke functies voor het laden van een datapijplijn te dekken: synchronisatie en afstemming van bron- en doelgegevens.
Voordelen en beperkingen van geautomatiseerd testen
Uitdagingen op het gebied van testautomatisering
- Testen rapporteren: Testen van business intelligence of analytische rapporten door middel van automatisering
- Data complexiteit: Bij het testen van datapijplijnen zijn vaak complexe datastructuren en transformaties betrokken die moeilijk te automatiseren zijn en gespecialiseerde expertise vereisen.
- Pijplijn complexiteit: Gegevenspijplijnen kunnen complex zijn en kunnen meerdere verwerkingsfasen omvatten, wat een uitdaging kan zijn om te testen en te debuggen. Daarnaast kunnen wijzigingen aan een deel van de pijpleiding stroomafwaarts onbedoelde gevolgen hebben.
Voordelen van testautomatisering
- Voert testgevallen sneller uit: Automatisering kan de implementatie van testscenario's versnellen.
- Creëert een herbruikbare testsuite: Zodra de testscripts zijn uitgevoerd met de automatiseringstools, kunnen ze worden geback-upt zodat ze gemakkelijk kunnen worden teruggehaald en hergebruikt.
- Vergemakkelijkt testrapportage: Een interessant kenmerk van veel geautomatiseerde tools is hun vermogen om rapporten en testbestanden te produceren. Deze mogelijkheden geven de gegevensstatus nauwkeurig weer, identificeren duidelijk tekortkomingen en worden gebruikt bij nalevingscontroles.
- Vermindert personeels- en herwerkkosten: Tijd die wordt besteed aan handmatig testen of hertesten na het corrigeren van defecten kan worden besteed aan andere initiatieven binnen de IT-afdeling.
Potentiële beperkingen
- Kan handmatig testen niet volledig vervangen: Hoewel automatisering voor verschillende toepassingen en testgevallen kan worden gebruikt, het kan handmatig testen niet volledig vervangen. Er zullen nog steeds ingewikkelde testcases bestaan waarbij automatisering niet alles zal vastleggen, en voor gebruikersacceptatietesten zullen eindgebruikers vaak handmatig tests moeten uitvoeren. Daarom is het essentieel om de juiste combinatie van geautomatiseerd en handmatig testen in het proces te hebben.
- Kosten gereedschap: Commerciële testtools kunnen duur zijn, afhankelijk van hun grootte en functionaliteit. Op het eerste gezicht kan een bedrijf dit als onnodige kosten beschouwen. Hergebruik alleen kan het echter al snel tot een aanwinst maken.
- Kosten opleiding: Testers moeten niet alleen worden getraind in programmeren, maar ook in het plannen van geautomatiseerde tests. Geautomatiseerde tools kunnen ingewikkeld zijn om te gebruiken en hebben mogelijk gebruikerstraining nodig.
- Automatisering heeft planning, voorbereiding en speciale middelen nodig: Het succes van geautomatiseerd testen is voornamelijk afhankelijk van nauwkeurige testvereisten en de zorgvuldige ontwikkeling van testgevallen voordat het testen begint. Helaas is de ontwikkeling van testcases nog steeds voornamelijk een handmatig proces. Omdat elke organisatie- en datapijplijntoepassing uniek kan zijn, zullen veel geautomatiseerde testtools geen testcases maken.
Aan de slag met datapijplijntestautomatisering
Niet alle datapijplijntesten zijn geschikt voor automatisering. Beoordeel de bovenstaande situaties om te bepalen welke soorten automatisering uw testproces ten goede zouden komen en hoeveel er nodig is. Evalueer uw testvereisten en identificeer efficiëntiewinsten die kunnen worden behaald door middel van geautomatiseerd testen. Datapijplijnteams die veel tijd besteden aan regressietesten zullen het meest profiteren.
Ontwikkel een businesscase voor geautomatiseerd testen. IT moet eerst de zaak verdedigen om de waarde over te brengen aan het bedrijf.
Evalueer de opties. Bepaal na het beoordelen van de huidige status en vereisten binnen de IT-afdeling welke tools aansluiten bij de testprocessen en -omgevingen van de organisatie. Opties kunnen leveranciers, open source, intern of een mix van tools zijn.
Conclusies
Omdat testautomatisering snel een essentieel alternatief is geworden voor handmatig testen, zoeken steeds meer bedrijven naar tools en strategieën om automatisering met succes te implementeren. Dit heeft geleid tot een aanzienlijke groei van testautomatiseringstools op basis van Appium, Selenium, Katalon Studio en vele anderen. De datapijplijn en data-engineers, BI en kwaliteitsborgingsteams moeten echter over de juiste programmeervaardigheden beschikken om deze automatiseringstools volledig te gebruiken.
Veel IT-experts hebben voorspeld dat de kenniskloof tussen testers en ontwikkelaars continu moet en zal worden verkleind. Geautomatiseerde tools voor het testen van datapijplijnen kunnen de tijd die wordt besteed aan het testen van code aanzienlijk verkorten in vergelijking met conventionele handmatige methoden.
Naarmate de mogelijkheden voor het ontwikkelen van datapijplijnen blijven toenemen, neemt ook de behoefte aan uitgebreidere en modernere geautomatiseerde datatests toe.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.dataversity.net/best-practices-in-data-pipeline-test-automation/
- :is
- $UP
- 1
- a
- vermogen
- boven
- acceptatie
- toegang
- Accumuleren
- accuraat
- nauwkeurig
- Bereiken
- bereikt
- toegevoegd
- toevoeging
- Daarnaast
- adopteren
- komst
- Na
- aggregatie
- behendig
- wil
- Alles
- Het toestaan
- alleen
- alternatief
- Hoewel
- analyse
- analisten
- analytisch
- Analytisch
- analytics
- het analyseren van
- en
- Aanvraag
- toepassingen
- toegepast
- Solliciteer
- passend
- ZIJN
- gebieden
- AS
- verschijning
- Het beoordelen
- aanwinst
- zekerheid
- verzekerd
- At
- audio
- audits
- automatiseren
- geautomatiseerde
- automatiseren
- Automatisering
- Beschikbaar
- vermeden
- bewustzijn
- met een rug
- gebaseerde
- basis
- BE
- omdat
- worden
- vaardigheden
- Begin
- voordeel
- BEST
- 'best practices'
- tussen
- Breken
- breed
- bugs
- bouw
- bedrijfsdeskundigen
- business intelligence
- ondernemingen
- CAN
- kandidaten
- kan niet
- mogelijkheden
- vangen
- voorzichtig
- geval
- gevallen
- categorieën
- Veroorzaken
- zeker
- uitdagingen
- uitdagend
- Wijzigingen
- veranderende
- karakteristiek
- kenmerken
- controle
- uitgekozen
- duidelijk
- duidelijk
- code
- codering
- Het verzamelen van
- combinatie van
- communiceren
- Communicatie
- vergeleken
- compleet
- compleet
- complex
- ingewikkeldheid
- nakoming
- ingewikkeld
- bestanddeel
- componenten
- uitgebreid
- computergebruik
- Gevolgen
- aanzienlijk
- beschouwd
- voortzetten
- doorlopend
- doorlopend
- onder controle te houden
- conventioneel
- correct
- Kosten
- kostenefficient
- Kosten
- deksel
- en je merk te creëren
- geloofwaardig
- criteria
- kritisch
- cruciaal
- Actueel
- Huidige toestand
- cycli
- gegevens
- gegevensverrijking
- Gegevensuitwisseling
- gegevensbeheer
- data kwaliteit
- datawarehouse
- Database
- databanken
- DATAVERSITEIT
- Data
- beslissingen
- toegewijd aan
- levering
- afdeling
- afhankelijk
- Afhankelijk
- beschreven
- ontworpen
- Bepalen
- bepaalt
- bepalen
- Dev
- ontwikkelaars
- het ontwikkelen van
- Ontwikkeling
- ontwikkelingen
- anders
- ijver
- displays
- documentatie
- documenten
- doen
- e
- elk
- Vroeger
- En het is heel gemakkelijk
- rand
- edge computing
- effectief
- efficiëntie
- doeltreffendheid
- doeltreffend
- element
- geeft je de mogelijkheid
- opkomende
- nadruk
- eind tot eind
- Ingenieurs
- verzekeren
- omgevingen
- vooral
- essentieel
- schatten
- Zelfs
- Alle
- alles
- voorbeelden
- uitwisseling
- uitvoering
- bestaand
- verwachtingen
- verwacht
- duur
- ervaring
- expertise
- deskundigen
- extractie
- sneller
- Kenmerk
- Voordelen
- feedback
- Figuur
- Bestanden
- Tot slot
- het vinden van
- Voornaam*
- gebreken
- stroom
- Voor
- formeel
- formaat
- gevonden
- frameworks
- veelvuldig
- oppompen van
- geheel
- functionaliteit
- functies
- verder
- Krijgen
- verdiensten
- kloof
- Overheid
- handvat
- Behandeling
- Hard
- Hebben
- met
- hulp
- Hoge
- hoogwaardige
- zeer
- Hoe
- How To
- Echter
- HTTPS
- Identificatie
- identificeren
- afbeeldingen
- uitvoeren
- uitvoering
- uitvoering
- belangrijk
- in
- omvatten
- Inclusief
- Laat uw omzet
- Verhoogt
- individueel
- eerste
- initiatieven
- integratie
- Intelligentie
- interessant
- intern
- Internet
- internet van dingen
- betrekken
- gaat
- iot
- problemen
- IT
- herhaling
- json
- sleutel
- kennis
- bekend
- meer
- grotendeels
- Legkippen
- leren
- LED
- Life
- levensduur
- als
- beperkingen
- laden
- het laden
- ladingen
- gelegen
- plaats
- lang
- op zoek
- onderhoud
- maken
- management
- handboek
- handmatig
- veel
- max-width
- Maak kennis met
- vergadering
- methode
- methoden
- minder
- Modern
- monitor
- meer
- meest
- meervoudig
- noodzakelijk
- Noodzaak
- nodig
- behoeften
- New
- volgende
- aantal
- nummers
- doelstellingen
- of
- on
- EEN
- open
- open source
- Opties
- organisatie
- Oorsprong
- Overige
- Overig
- anders-
- deel
- patronen
- uitvoeren
- prestatie
- periodes
- fase
- pijpleiding
- planning
- Plato
- Plato gegevensintelligentie
- PlatoData
- mogelijk
- praktijken
- nauwkeurig
- voorspeld
- cadeautjes
- in de eerste plaats
- problemen
- processen
- verwerking
- produceren
- Product
- professionals
- Programming
- Programma's
- project
- projecten
- Het bevorderen van
- gepast
- zorgen voor
- biedt
- doel
- Q & A
- kwaliteit
- Contact
- snel
- reeks
- variërend
- snel
- snel
- BIJZONDER
- echte wereld
- real-time
- realistisch
- verzoening
- archief
- verminderen
- regressie
- regelmatig
- regelmatig
- los
- relevante
- vertrouwen
- herhaald
- HERHAALDELIJK
- vervangen
- gerepliceerd
- verslag
- gemeld
- Rapportage
- Rapporten
- vertegenwoordigen
- vertegenwoordigt
- vereisen
- nodig
- Voorwaarden
- vereist
- Resources
- verantwoordelijk
- resultaat
- Resultaten
- herbruikbare
- onthullen
- lopen
- Schaalbaarheid
- scenario's
- scheduling
- scripts
- selectie
- service
- reeks
- setup
- verscheidene
- moet
- Shows
- aanzienlijke
- aanzienlijk
- situaties
- Maat
- vaardigheden
- So
- Software
- software development
- bron
- bronnen
- special
- gespecialiseerde
- specifiek
- snelheid
- besteed
- personeelsbezetting
- stadia
- stakeholders
- begin
- gestart
- Land
- Status
- Still
- mediaopslag
- opgeslagen
- strategieën
- stream
- gestructureerde
- studio
- succes
- Met goed gevolg
- dergelijk
- geschikt
- suite
- Oppervlak
- synchronisatie
- tafel
- neemt
- doelwit
- doelen
- Taak
- team
- teams
- Technisch
- technieken
- Technologies
- proef
- Testen
- testen
- dat
- De
- hun
- daarom
- Deze
- spullen
- Door
- niet de tijd of
- tijdrovend
- naar
- vandaag
- ook
- tools
- tools
- traditioneel
- getraind
- Trainingen
- Transformeren
- Transformatie
- transformaties
- getransformeerd
- transformeren
- Trends
- types
- unieke
- .
- Gebruiker
- gebruikers
- doorgaans
- gevalideerd
- bevestiging
- waardevol
- waarde
- variëteit
- divers
- groot
- verkoper
- vendors
- Verificatie
- geverifieerd
- controleren
- Video
- Bekijk
- vitaal
- vs
- Magazijn
- web
- Webontwikkeling
- Wat
- of
- welke
- WIE
- breed
- wijd
- wil
- Met
- binnen
- zonder
- workflows
- werkzaam
- zou
- XML
- Your
- zephyrnet