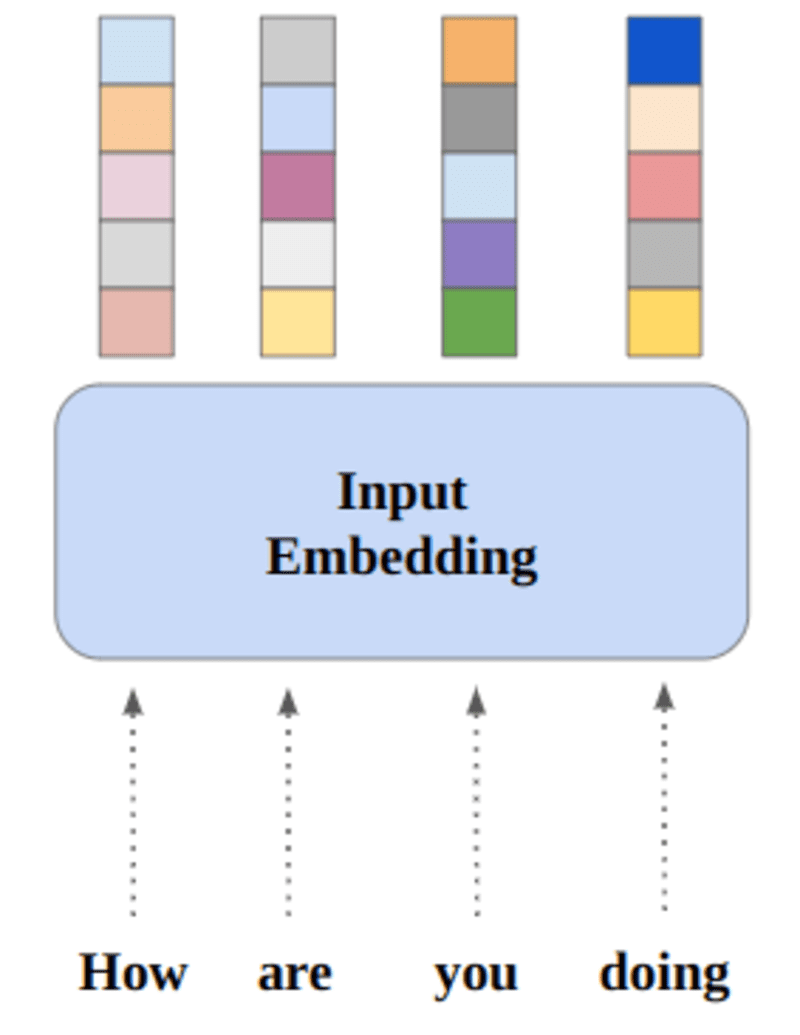
Neurale netwerken leren door getallen, dus elk woord wordt toegewezen aan vectoren om een bepaald woord weer te geven. De inbeddingslaag kan worden gezien als een opzoektabel die woordinbeddingen opslaat en ophaalt met behulp van indices.
Woorden met dezelfde betekenis zullen dicht bij elkaar liggen in termen van euclidische afstand/cosinusovereenkomst. in de onderstaande woordweergave worden bijvoorbeeld "Zaterdag", "Zondag" en "Maandag" geassocieerd met hetzelfde concept, dus we kunnen zien dat de woorden vergelijkbaar zijn.

Het bepalen van de positie van het woord, waarom moeten we de positie van het woord bepalen? omdat de transformator-encoder geen herhaling heeft zoals terugkerende neurale netwerken, moeten we wat informatie over de posities toevoegen aan de ingangsinbeddingen. Dit gebeurt met behulp van positionele codering. De auteurs van het artikel gebruikten de volgende functies om de positie van een woord te modelleren.
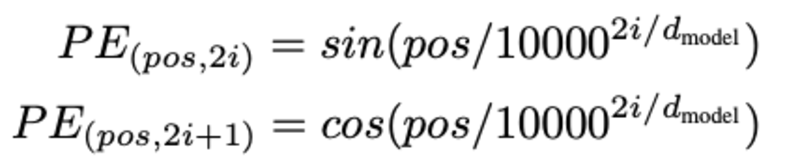
We zullen positionele codering proberen uit te leggen.
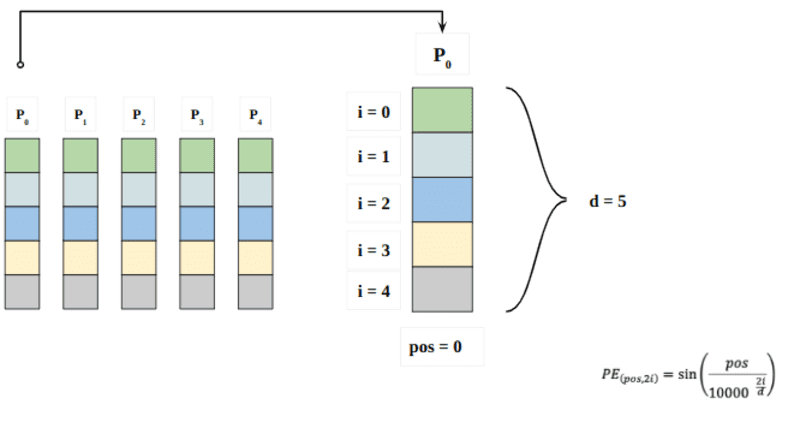
Hier verwijst "pos" naar de positie van het "woord" in de reeks. P0 verwijst naar de positie-inbedding van het eerste woord; "d" betekent de grootte van de inbedding van het woord/token. In dit voorbeeld d=5. Ten slotte verwijst "i" naar elk van de 5 individuele dimensies van de inbedding (dwz 0, 1,2,3,4)
als "i" varieert in de bovenstaande vergelijking, krijgt u een aantal curven met verschillende frequenties. Het aflezen van de positie-inbeddingswaarden tegen verschillende frequenties, geeft verschillende waarden bij verschillende inbeddingsdimensies voor P0 en P4.
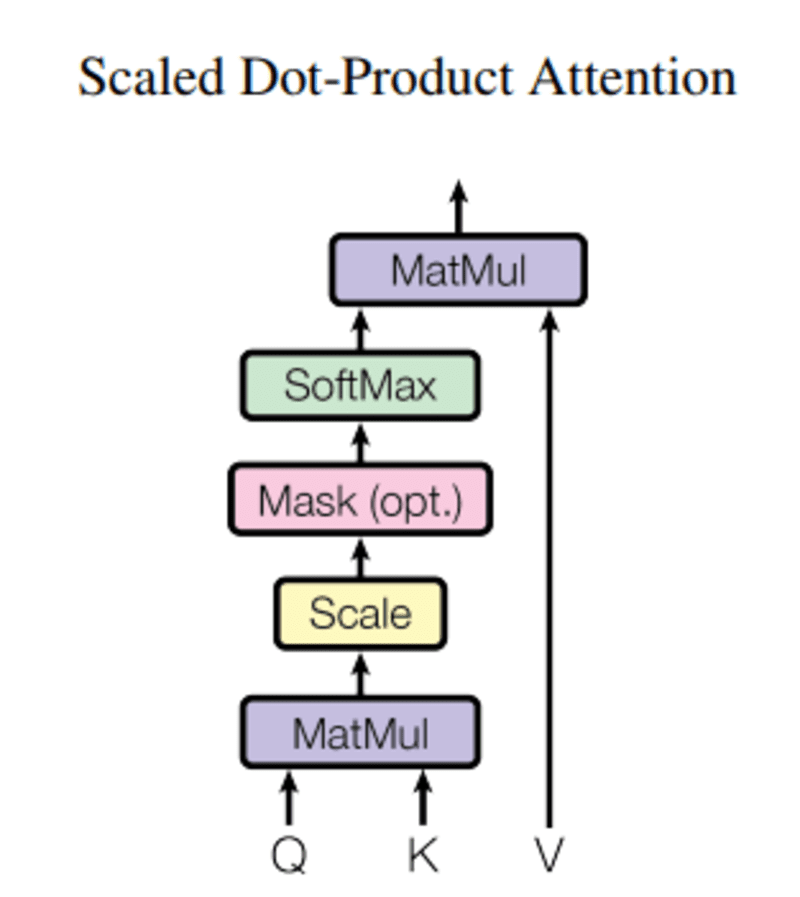
In deze vraag, Q vertegenwoordigt een vectorwoord, de sleutels K zijn alle andere woorden in de zin, en waarde V vertegenwoordigt de vector van het woord.
Het doel van aandacht is om het belang van de sleutelterm te berekenen in vergelijking met de zoekterm die betrekking heeft op dezelfde persoon/ding of hetzelfde concept.
In ons geval is V gelijk aan Q.
Het aandachtsmechanisme geeft ons het belang van het woord in een zin.
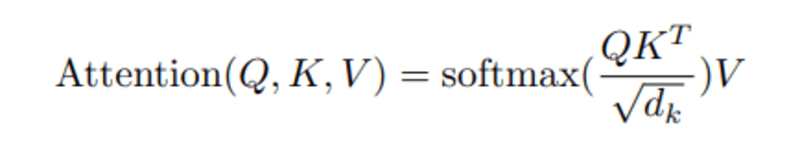
Wanneer we het genormaliseerde puntproduct tussen de query en de sleutels berekenen, krijgen we een tensor die het relatieve belang van elk ander woord voor de query weergeeft.
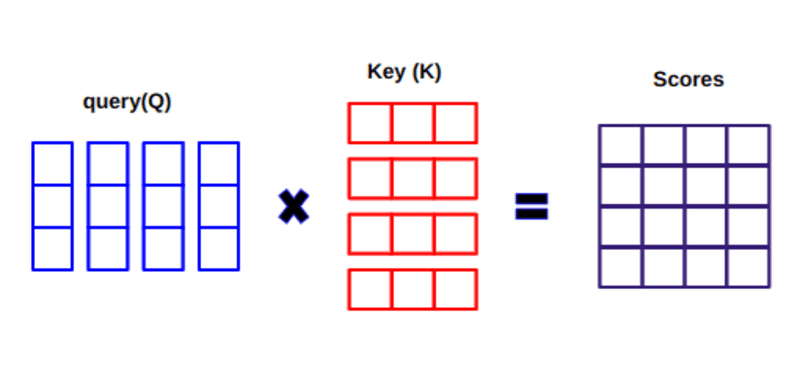
Bij het berekenen van het puntproduct tussen Q en KT proberen we te schatten hoe de vectoren (dwz woorden tussen query en sleutels) zijn uitgelijnd en geven we een gewicht terug voor elk woord in de zin.
Vervolgens normaliseren we het resultaat in het kwadraat van d_k en de softmax-functie regulariseert de termen en herschaalt ze tussen 0 en 1.
Ten slotte vermenigvuldigen we het resultaat (dwz gewichten) met de waarde (dwz alle woorden) om het belang van niet-relevante woorden te verminderen en alleen op de belangrijkste woorden te focussen.
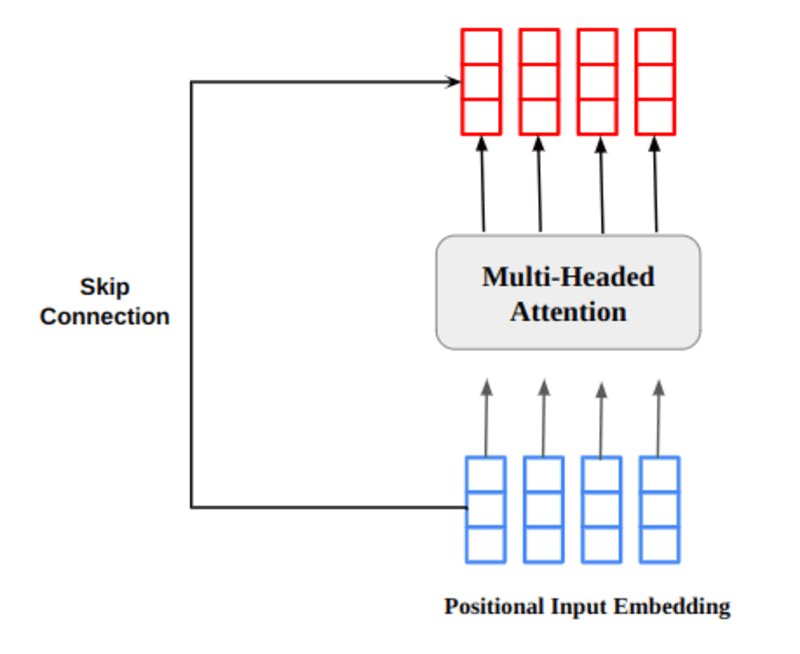
De meerkoppige attentie-outputvector wordt toegevoegd aan de originele positionele input-inbedding. Dit wordt een restaansluiting/skip-aansluiting genoemd. De uitvoer van de resterende verbinding gaat door laagnormalisatie. De genormaliseerde residuele output wordt voor verdere verwerking door een puntsgewijs feed-forward netwerk geleid.
Het masker is een matrix die even groot is als de aandachtsscores gevuld met waarden van nullen en negatieve oneindigheden.
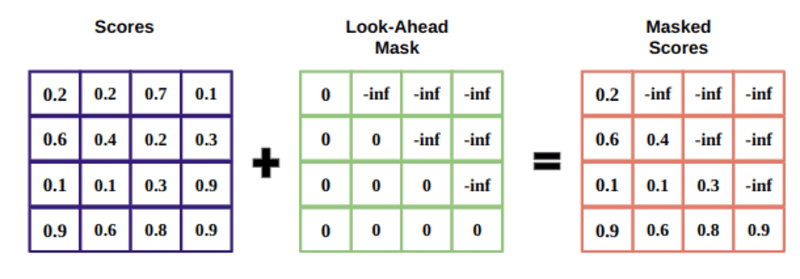
De reden voor het masker is dat als je eenmaal de softmax van de gemaskeerde scores hebt genomen, de negatieve oneindigheden nul worden, waardoor er geen aandachtsscores overblijven voor toekomstige tokens.
Dit vertelt het model om geen focus op die woorden te leggen.
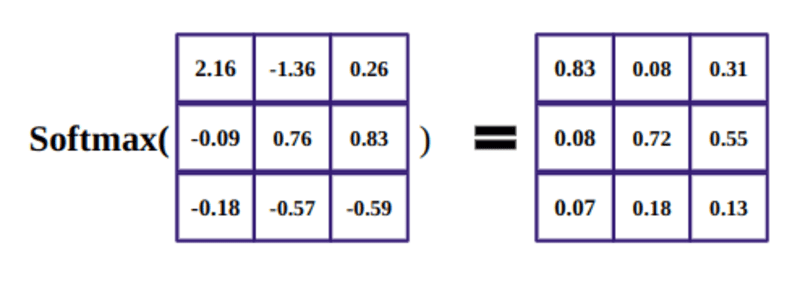
Het doel van de softmax-functie is om reële getallen (positief en negatief) te pakken en ze om te zetten in positieve getallen die optellen tot 1.
Ravikumar Naduvin is bezig met het bouwen en begrijpen van NLP-taken met behulp van PyTorch.
ORIGINELE. Met toestemming opnieuw gepost.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- Over
- boven
- toegevoegd
- tegen
- uitgelijnd
- Alles
- en
- geassocieerd
- aandacht
- auteurs
- omdat
- vaardigheden
- onder
- tussen
- Gebouw
- Bos
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- geval
- Sluiten
- vergeleken
- Berekenen
- computergebruik
- concept
- concepten
- versterken
- Bepalen
- bepalen
- anders
- Afmeting
- DOT
- elk
- schatting
- voorbeeld
- Verklaren
- gevuld
- Tot slot
- Voornaam*
- Focus
- volgend
- functie
- functies
- verder
- toekomst
- krijgen
- het krijgen van
- GitHub
- geeft
- Vrijgevigheid
- Goes
- grijpen
- Hoe
- HTTPS
- belang
- belangrijk
- in
- Index
- individueel
- informatie
- invoer
- KDnuggets
- sleutel
- toetsen
- blijven
- lagen
- LEARN
- verlaten
- lookup
- maskeren
- Matrix
- betekenis
- middel
- mechanisme
- model
- meest
- Noodzaak
- negatief
- netwerk
- netwerken
- Neural
- neurale netwerken
- nlp
- nummers
- origineel
- Overige
- Papier
- bijzonder
- voorbij
- toestemming
- Plato
- Plato gegevensintelligentie
- PlatoData
- positie
- posities
- positief
- verwerking
- Product
- doel
- zetten
- pytorch
- lezing
- vast
- reden
- herhaling
- verminderen
- verwijst
- verwant
- vertegenwoordigen
- vertegenwoordiging
- vertegenwoordigt
- resultaat
- verkregen
- terugkeer
- dezelfde
- zin
- Volgorde
- moet
- gelijk
- Maat
- So
- sommige
- squared
- winkels
- tafel
- Nemen
- taken
- vertelt
- termen
- De
- gedachte
- Door
- naar
- tokens
- transformers
- BEURT
- begrip
- us
- waarde
- Values
- gewicht
- welke
- wil
- Woord
- woorden
- zephyrnet
- nul