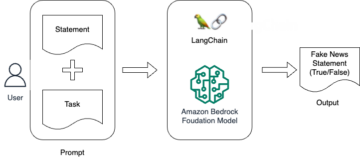
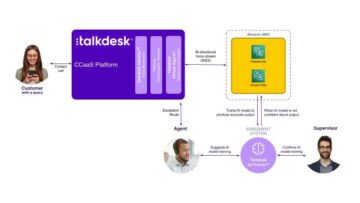
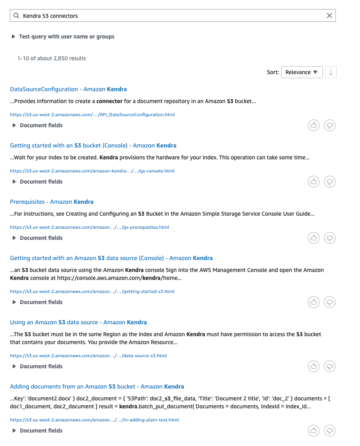
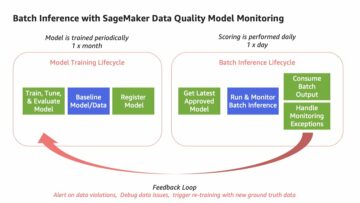
De ingebouwde Amazon Sage Maker XGBoost-algoritme biedt een beheerde container om de populaire XGBoost machine learning (ML) framework, met extra gemak van ondersteuning van geavanceerde training of inferentiefuncties zoals gedistribueerde training, datasetsharding voor grootschalige datasets, A/B-model testenof gevolgtrekking met meerdere modellen eindpunten. U kunt dit krachtige algoritme ook uitbreiden om aan verschillende vereisten te voldoen.
Het verpakken van de code en afhankelijkheden in een enkele container is een handige en robuuste benadering voor het onderhoud, reproduceerbaarheid en auditing van code op de lange termijn. Het wijzigen van de container volgt de basiscontainer getrouw en vermijdt het dupliceren van bestaande functies die al door de basiscontainer worden ondersteund. In dit bericht bekijken we de interne werking van de SageMaker XGBoost-algoritmecontainer en bieden we pragmatische scripts om de container rechtstreeks aan te passen.
SageMaker XGBoost-containerstructuur
Het ingebouwde XGBoost-algoritme van SageMaker is verpakt als een op zichzelf staande container, beschikbaar op GitHub, en kan worden uitgebreid onder de ontwikkelaarvriendelijke Apache 2.0 open-sourcelicentie. De container verpakt de open-source XGBoost-algoritme en aanvullende tools om het algoritme uit te voeren in de SageMaker-omgeving die is geïntegreerd met andere AWS Cloud-services. Hiermee kunt u XGBoost-modellen trainen op verschillende data bronnenmaken batchvoorspellingen op offline gegevens, of host een inferentie eindpunt in realtime pijpleiding.
De container ondersteunt trainings- en inferentiebewerkingen met verschillende toegangspunten. Voor de inferentiemodus is de invoer te vinden in de hoofdfunctie in de serving.py-script. Voor realtime inferentieweergave loopt de container a FlaconGebaseerde webserver dat wanneer ingeroepen, ontvangt een HTTP-gecodeerd verzoek met de gegevens, decodeert de gegevens in de XGBoost's DMatrix formaat, laadt het model, en retourneert an HTTP-gecodeerd antwoord terug. Deze methoden zijn ingekapseld onder de Scoreservice class, die ook grotendeels kan worden aangepast via de scriptmodus (zie de bijlage hieronder).
Het startpunt voor de trainingsmodus (algoritmemodus) is de hoofdfunctie in de training.py. De hoofdfunctie stelt de opleidingsomgeving in en roept de opleidingsfunctie aan. Het is flexibel genoeg om gedistribueerde of single-node training mogelijk te maken, of hulpprogramma's zoals kruisvalidatie. Het hart van het trainingsproces is te vinden in de train_baan functie.
Docker-bestanden die de container verpakken, zijn te vinden in de GitHub repo. Merk op dat de container in twee stappen wordt gebouwd: a baseren container wordt eerst gebouwd, gevolgd door de finale bak erop.
Overzicht oplossingen
U kunt de container wijzigen en opnieuw opbouwen via de broncode. Dit houdt echter in dat alle afhankelijkheden en pakketten vanaf het begin worden verzameld en opnieuw opgebouwd. In dit bericht bespreken we een meer rechttoe rechtaan benadering die de container rechtstreeks wijzigt bovenop de reeds gebouwde en openbaar beschikbare SageMaker XGBoost-algoritmecontainerafbeelding.
In deze benadering hebben we trek een kopie van de openbare SageMaker XGBoost-afbeelding, wijzig de scripts of voeg pakketten toe en bouw de container opnieuw op. De gewijzigde container kan worden opgeslagen in een privérepository. Op deze manier vermijden we het opnieuw opbouwen van intermediaire afhankelijkheden en bouwen we in plaats daarvan rechtstreeks bovenop de reeds gebouwde bibliotheken die in de officiële container zijn verpakt.
De volgende afbeelding toont een overzicht van het script dat wordt gebruikt om de openbare basisafbeelding op te halen, de afbeelding te wijzigen en opnieuw op te bouwen en deze te uploaden naar een Amazon Elastic Container-register (Amazon ECR) opslagplaats. De bash-script in de bijbehorende code van dit bericht voert alle workflowstappen uit die in het diagram worden getoond. De begeleidende notitieboekje toont een voorbeeld waarbij de URI van een specifieke versie van het SageMaker XGBoost-algoritme eerst wordt opgehaald en doorgegeven aan de bash-script, die twee van de Python-scripts in de afbeelding vervangt, deze opnieuw opbouwt en de gewijzigde afbeelding naar een privé Amazon ECR-repository pusht. U kunt de bijbehorende code aanpassen aan uw behoeften.

Voorwaarden
De GitHub-repository bevat de code bij dit bericht. U kunt de voorbeeld notebook in uw AWS-account, of gebruik de meegeleverde AWS CloudFormatie stack om de notebook te implementeren met behulp van een SageMaker-notebook. Je hebt de volgende voorwaarden nodig:
- Een AWS-account.
- Noodzakelijke machtigingen om SageMaker batchtransformatie- en trainingstaken uit te voeren, en Amazon ECR-privileges. De CloudFormation-sjabloon maakt een voorbeeld AWS Identiteits- en toegangsbeheer (IAM) rollen.
Implementeer de oplossing
Om uw oplossingsbronnen te maken met AWS CloudFormation, kiest u: Start Stack:
![]()
De stack implementeert een SageMaker-notebook die vooraf is geconfigureerd om de GitHub-repository te klonen. de doorloop notitieboekje bevat de stappen om de openbare SageMaker XGBoost-image voor een bepaalde versie op te halen, aan te passen en de aangepaste container naar een privé Amazon ECR-repository te pushen. De notebook gebruikt het publiek Abalone-gegevensset traint als voorbeeld een model met behulp van de ingebouwde trainingsmodus van SageMaker XGBoost en hergebruikt dit model in de aangepaste afbeelding om batchtransformatietaken uit te voeren die inferentie produceren samen met SHAP-waarden.
Conclusie
De ingebouwde algoritmen van SageMaker bieden een verscheidenheid aan functies en functionaliteiten en kunnen verder worden uitgebreid onder de Apache 2.0 open-sourcelicentie. In dit bericht hebben we bekeken hoe we de ingebouwde productiecontainer voor het SageMaker XGBoost-algoritme kunnen uitbreiden om te voldoen aan productievereisten zoals achterwaartse code en API-compatibiliteit.
Het voorbeeldnotitieboekje en helper scripts bieden een handig startpunt om de SageMaker XGBoost-containerimage aan te passen zoals u dat wilt. Probeer het eens!
Bijlage: Scriptmodus
Scriptmodus biedt een manier om veel ingebouwde algoritmen van SageMaker te wijzigen door een interface te bieden om de functies te vervangen die verantwoordelijk zijn voor het transformeren van de invoer en het laden van het model. De scriptmodus is niet zo flexibel als het rechtstreeks wijzigen van de container, maar het biedt een volledig op Python gebaseerde route om het ingebouwde algoritme aan te passen zonder dat u er rechtstreeks mee hoeft te werken havenarbeider.
In scriptmodus, a user-module wordt geleverd om gegevensdecodering, het laden van het model en het maken van voorspellingen aan te passen. De gebruikersmodule kan een transformer_fn die alle aspecten van het verwerken van het verzoek tot het voorbereiden van het antwoord afhandelt. Of in plaats van te definiëren transformer_fn, u kunt aangepaste methoden bieden model_fn, input_fn, predict_fn en output_fn individueel om het laden van het model en het decoderen en voorbereiden van de invoer voor voorspelling aan te passen. Voor een uitgebreider overzicht van de scriptmodus, zie Breng uw eigen model mee met de SageMaker-scriptmodus.
Over de auteurs
 Peyman Razaghi is een datawetenschapper bij AWS. Hij heeft een doctoraat in informatietheorie van de Universiteit van Toronto en was een postdoctoraal onderzoeker aan de Universiteit van Zuid-Californië (USC), Los Angeles. Voordat hij bij AWS kwam, was Peyman een stafsysteemingenieur bij Qualcomm die bijdroeg aan een aantal opmerkelijke internationale telecommunicatiestandaarden. Hij is auteur van verschillende wetenschappelijke onderzoeksartikelen, peer-reviewed op het gebied van statistiek en systeemtechniek, en geniet van ouderschap en wielrennen buiten het werk.
Peyman Razaghi is een datawetenschapper bij AWS. Hij heeft een doctoraat in informatietheorie van de Universiteit van Toronto en was een postdoctoraal onderzoeker aan de Universiteit van Zuid-Californië (USC), Los Angeles. Voordat hij bij AWS kwam, was Peyman een stafsysteemingenieur bij Qualcomm die bijdroeg aan een aantal opmerkelijke internationale telecommunicatiestandaarden. Hij is auteur van verschillende wetenschappelijke onderzoeksartikelen, peer-reviewed op het gebied van statistiek en systeemtechniek, en geniet van ouderschap en wielrennen buiten het werk.
- "
- 100
- toegang
- accommoderen
- Account
- vergevorderd
- algoritme
- algoritmen
- Alles
- al
- Amazone
- api
- nadering
- GEBIED
- artikelen
- AWS
- bouw
- ingebouwd
- Californië
- Kies
- klasse
- Cloud
- cloud-diensten
- code
- Het verzamelen van
- compleet
- Containers
- bevat
- gemak
- gemakkelijk
- creëert
- gewoonte
- gegevens
- data scientist
- implementeren
- ontplooit
- anders
- direct
- bespreken
- verdeeld
- havenarbeider
- ingenieur
- Milieu
- voorbeeld
- verlengen
- Voordelen
- Figuur
- Voornaam*
- flexibel
- volgend
- formaat
- gevonden
- Achtergrond
- functie
- verder
- GitHub
- groot
- houdt
- Hoe
- How To
- HTTPS
- Identiteit
- beeld
- informatie
- invoer
- geïntegreerde
- Interface
- Internationale
- IT
- Jobomschrijving:
- Vacatures
- leren
- Vergunning
- langdurig
- Los Angeles
- machine
- machine learning
- MERKEN
- maken
- beheerd
- ML
- model
- modellen
- meer
- notitieboekje
- aantal
- officieel
- offline
- Operations
- Overige
- het te bezitten.
- punt
- Populair
- krachtige
- voorspelling
- Voorspellingen
- privaat
- produceren
- productie
- zorgen voor
- biedt
- het verstrekken van
- publiek
- doeleinden
- real-time
- bewaarplaats
- te vragen
- Voorwaarden
- onderzoek
- Resources
- antwoord
- verantwoordelijk
- Retourneren
- beoordelen
- weg
- lopen
- Wetenschapper
- Diensten
- serveer-
- sharding
- Software
- oplossing
- broncode
- Zuidelijk
- stack
- normen
- statistiek
- ondersteunde
- Ondersteuning
- steunen
- Systems
- De Bron
- Door
- samen
- tools
- top
- toronto
- Trainingen
- treinen
- Transformeren
- transformeren
- universiteit-
- .
- variëteit
- Wikipedia
- Mijn werk
- zou