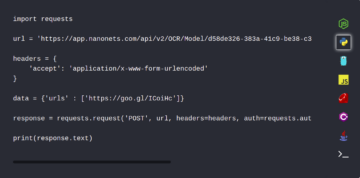
Wilt u gegevens uit gescande documenten extraheren? Poging Nanonetten™ vergevorderd AI-gebaseerde OCR-scanner om informatie uit te extraheren en te ordenen gescande documenten webmaster..
Introductie
Nu de wereld voor het gemak is veranderd van papieren en handschriften in digitale documenten, is het belang van het omzetten van afbeeldingen en gescande documenten in zinvolle gegevens enorm toegenomen.
Om de behoefte aan zeer nauwkeurige extractie van documentgegevens bij te houden, hebben talrijke onderzoeksfaciliteiten en bedrijven (dwz Google, AWS, Nanonets enz.) zich diep gefocust op de technologieën op het gebied van computervisie en Natural Language Processing (NLP).
De bloei van deep learning-technologieën heeft gezorgd voor een enorme sprong in het soort gegevens dat kan worden geëxtraheerd; we zijn niet langer beperkt in het extraheren van tekst, maar ook in andere datastructuren zoals tabellen en sleutel-waardeparen. Veel oplossingen bieden nu verschillende producten om te voldoen aan de behoeften van individuen en bedrijfseigenaren bij het extraheren van documentgegevens.
Dit artikel duikt in de huidige technologie die wordt gebruikt voor gegevensextractie uit gescande documenten, gevolgd door een korte praktische tutorial in Python. We zullen ook kijken naar enkele van de populaire oplossingen die momenteel op de markt zijn en die het beste aanbod op dit gebied bieden.

Wat is gegevensextractie?
Gegevensextractie is het proces van het omzetten van ongestructureerde gegevens in interpreteerbare informatie door programma's om verdere gegevensverwerking door mensen mogelijk te maken. Hier vermelden we enkele van de meest voorkomende soorten gegevens die uit gescande documenten kunnen worden geëxtraheerd.
Tekstgegevens
De meest voorkomende en belangrijkste taak bij het extraheren van gegevens uit gescande documenten is het extraheren van tekst. Dit proces, hoewel ogenschijnlijk eenvoudig, is in feite erg moeilijk omdat gescande documenten vaak worden gepresenteerd in de vorm van afbeeldingen. Bovendien zijn de extractiemethoden sterk afhankelijk van het type tekst. Hoewel tekst het grootste deel van de tijd aanwezig is in dichte gedrukte formaten, is de mogelijkheid om schaarse tekst te extraheren uit minder goed gescande documenten of uit handgeschreven brieven met drastisch verschillende stijlen even belangrijk. Met een dergelijk proces kunnen programma's afbeeldingen converteren naar machinegecodeerde tekst, waar we ze verder kunnen ordenen van ongestructureerde gegevens (zonder bepaalde opmaak) naar gestructureerde gegevens voor verdere analyse.
Tafels
Tabelvormen zijn de meest populaire benadering voor gegevensopslag, omdat het formaat gemakkelijk te interpreteren is met menselijke ogen. Het proces van het extraheren van tabellen uit gescande documenten vereist technologie die verder gaat dan tekendetectie - men moet de lijnen en andere visuele kenmerken detecteren om een juiste tabelextractie uit te voeren en die informatie verder om te zetten in gestructureerde gegevens voor verdere berekening. Computervisiemethoden (in detail beschreven in de volgende paragrafen) worden veel gebruikt om tabellen met hoge nauwkeurigheid te extraheren.

Sleutel-waardeparen
Een alternatief formaat dat we vaak gebruiken in documenten voor gegevensopslag zijn key-value pairs (KVP's).

KVP's zijn in wezen twee gegevensitems - een sleutel en een waarde - die aan elkaar zijn gekoppeld als één. De sleutel wordt gebruikt als een unieke identificatie voor de op te halen waarde. Een klassiek KVP-voorbeeld is het woordenboek, waar de vocabulaires de sleutels zijn en de bijbehorende definities de waarden. Deze paren, hoewel meestal onopgemerkt, worden eigenlijk heel vaak gebruikt in documenten: vragen in enquêtes zoals naam, leeftijd en prijzen van items op facturen zijn allemaal impliciet KVP's.
In tegenstelling tot tabellen bestaan KVP's echter vaak in onbekende formaten en zijn ze soms zelfs gedeeltelijk met de hand geschreven. Sleutels kunnen bijvoorbeeld voorgedrukt zijn in vakjes en waarden worden met de hand geschreven bij het invullen van het formulier. Daarom is het vinden van de onderliggende structuren om automatisch KVP-extractie uit te voeren een continu onderzoeksproces, zelfs voor de meest geavanceerde faciliteiten en laboratoria.
Figuren
Ten slotte is het ook erg belangrijk om te extraheren of gegevens vastleggen van figuren in een gescand document. Statistische indicatoren zoals cirkeldiagrammen en staafdiagrammen bevatten vaak cruciale informatie voor documenten. Een goed proces voor het extraheren van gegevens zou in staat moeten zijn om uit de legenda's en getallen af te leiden om gegevens gedeeltelijk uit cijfers te extraheren voor verder gebruik.
Wilt u gegevens uit gescande documenten extraheren? Geef Nanonetten™ een draai voor hogere nauwkeurigheid, grotere flexibiliteit, nabewerking en een brede reeks integraties!
Technologieën achter gegevensextractie
Gegevensextractie draait om twee hoofdprocessen: optische tekenherkenning (OCR) gevolgd door natuurlijke taalverwerking (NLP).
OCR-extractie is het proces waarbij tekstafbeeldingen worden omgezet in machinegecodeerde tekst, terwijl de laatste de analyse van de woorden is om betekenissen af te leiden. Vaak gaan de OCR gepaard met andere computervisietechnieken zoals box- en lijndetectie om bovengenoemde gegevenstypen zoals tabellen en KVP's te extraheren voor een uitgebreidere extractie.
De kernverbeteringen achter de data-extractiepijplijn zijn nauw verbonden met de vooruitgang in deep learning die in hoge mate heeft bijgedragen aan computervisie en natuurlijke taalverwerking (NLP).
Wat is diep leren?
Deep learning speelt een grote rol achter de hype van het kunstmatige-intelligentietijdperk en is in tal van toepassingen voortdurend op de voorgrond geschoven. In traditionele engineering is ons doel om een systeem/functie te ontwerpen die een output genereert uit een bepaalde input; deep learning daarentegen vertrouwt op de input en output om de tussenliggende relatie te vinden die kan worden uitgebreid tot nieuwe ongeziene gegevens via de zogenaamde neuraal netwerk.
Een neuraal netwerk of een meerlaags perceptron (MLP), is een machine learning-architectuur die is geïnspireerd op hoe menselijke hersenen leren. Het netwerk bevat neuronen, die biologische neuronen nabootsen en "activeren" wanneer ze andere informatie krijgen. Sets neuronen vormen lagen, en meerdere lagen worden op elkaar gestapeld om een netwerk te vormen om de voorspellingsdoeleinden van meerdere vormen te dienen (dwz beeldclassificaties of begrenzingskaders voor objectdetectie).

Op het gebied van computervisie wordt een soort neuraal netwerkvariatie veel toegepast - convolutionele neurale netwerken (CNN's). In plaats van traditionele lagen, gebruikt een CNN convolutionele kernels die door tensoren (of hoogdimensionale vectoren) glijden voor feature-extractie. In combinatie met traditionele netwerklagen zijn CNN's uiteindelijk zeer succesvol in beeldgerelateerde taken en vormden ze verder de basis voor OCR-extractie en andere functiedetectie.
Aan de andere kant is NLP afhankelijk van een andere reeks netwerken, die zich richt op tijdreeksgegevens. In tegenstelling tot afbeeldingen, waarbij één afbeelding onafhankelijk van elkaar is, kan tekstvoorspelling grotendeels worden bevorderd als ook rekening wordt gehouden met woorden ervoor of erna. De afgelopen jaren is er een familie van netwerken ontstaan, namelijk lange kortetermijnherinneringen (LSTM's), die eerdere resultaten als invoer gebruikt om de huidige resultaten te voorspellen. Bilaterale LSTM's werden ook vaak gebruikt om de voorspellingsoutput te verbeteren, waarbij zowel de resultaten ervoor als erna werden overwogen. In de afgelopen jaren begint echter een concept van transformatoren dat een aandachtsmechanisme gebruikt, te stijgen vanwege de grotere flexibiliteit die leidt tot betere resultaten dan traditionele netwerken die sequentiële tijdreeksen verwerken.
Toepassingen van gegevensextractie
Het belangrijkste doel van gegevensextractie is het converteren van gegevens van ongestructureerde documenten naar gestructureerde formaten, waarbij een zeer nauwkeurige opvraging van tekst, figuren en gegevensstructuren zeer nuttig kan zijn voor numerieke en contextuele analyse. Deze analyses kunnen met name voor bedrijven zeer nuttig zijn:
Business
Zakelijke bedrijven en grote organisaties hebben dagelijks te maken met duizenden papierwerk met vergelijkbare formaten. Grote banken krijgen talloze identieke aanvragen en onderzoeksteams moeten stapels formulieren analyseren om statistische analyses uit te voeren. Daarom vermindert de automatisering van de eerste stap van het extraheren van gegevens uit documenten de overtolligheid van personeel aanzienlijk en stelt het werknemers in staat zich te concentreren op het analyseren van gegevens en het beoordelen van applicaties in plaats van het invoeren van informatie.
- Toepassingen verifiëren — Bedrijven ontvangen massa's sollicitaties, of ze nu met de hand zijn geschreven of alleen via aanvraagformulieren. In de meeste gevallen kunnen deze applicaties voor verificatiedoeleinden vergezeld gaan van persoonlijke ID's. Gescande documenten van ID's zoals paspoorten of kaarten komen meestal in batches met vergelijkbare formaten. Daarom kan een goed geschreven gegevensextractor de gegevens (teksten, tabellen, figuren, KVP's) snel omzetten in machine-begrijpelijke teksten, wat de manuren voor deze taken aanzienlijk zou kunnen verminderen en zich zou kunnen concentreren op toepassingsselectie in plaats van extractie.
- Betalingsafstemming — Betalingsreconciliatie is het proces van het vergelijken van bankafschriften om ervoor te zorgen dat getallen tussen rekeningen op elkaar worden afgestemd, dat sterk draait om gegevensextractie uit documenten - een uitdagend probleem voor een bedrijf met een aanzienlijke omvang en verschillende bronnen van inkomstenstroom. Gegevensextractie kan dit proces vergemakkelijken en werknemers in staat stellen zich te concentreren op foutieve gegevens en mogelijke frauduleuze gebeurtenissen over de cashflow te onderzoeken.
- Statistische analyse — Feedback van klanten of deelnemers aan experimenten wordt door bedrijven en organisaties gebruikt om hun producten en service te verbeteren, en een uitgebreide feedbackevaluatie vereist meestal een statistische analyse. Onderzoeksgegevens kunnen echter in verschillende formaten voorkomen of tussen tekst met verschillende formaten worden verborgen. Gegevensextractie zou het proces kunnen vergemakkelijken door voor de hand liggende gegevens uit documenten in batches aan te wijzen, het proces van het vinden van nuttige processen te vergemakkelijken en uiteindelijk de efficiëntie te verhogen.
- Eerdere records delen — Van gezondheidszorg tot overstappen van bankdiensten, grote industrieën hebben vaak nieuwe klantinformatie nodig die elders al aanwezig was. Een patiënt die van ziekenhuis verandert vanwege verhuizing, kan bijvoorbeeld reeds bestaande medische dossiers hebben die nuttig kunnen zijn voor het nieuwe ziekenhuis. In dergelijke gevallen komt goede software voor gegevensextractie van pas, aangezien het individu alleen een gescande geschiedenis van records naar het nieuwe ziekenhuis hoeft te brengen, zodat deze automatisch alle informatie kan invullen. Dit zou niet alleen handig zijn, het zou ook grote risico's kunnen voorkomen, vooral in de gezondheidszorg, dat belangrijke patiëntendossiers over het hoofd worden gezien.
Wilt u gegevens uit gescande documenten extraheren? Geef Nanonetten™ een draai voor hogere nauwkeurigheid, grotere flexibiliteit, nabewerking en een brede reeks integraties!
Tutorials
Om een duidelijker beeld te geven van het uitvoeren van gegevensextractie, laten we twee sets methoden zien voor het uitvoeren van gegevensextractie uit het scannen van documenten.
Gebouw van Scratch
Men kan een eenvoudige OCR-engine voor het extraheren van gegevens bouwen via de PyTesseract-engine als volgt:
try: from PIL import Image
except ImportError: import Image
import pytesseract # If you don't have tesseract executable in your PATH, include the following:
pytesseract.pytesseract.tesseract_cmd = r'<full_path_to_your_tesseract_executable>'
# Example tesseract_cmd = r'C:Program Files (x86)Tesseract-OCRtesseract' # Simple image to string
print(pytesseract.image_to_string(Image.open('test.png'))) # List of available languages
print(pytesseract.get_languages(config='')) # French text image to string
print(pytesseract.image_to_string(Image.open('test-european.jpg'), lang='fra')) # In order to bypass the image conversions of pytesseract, just use relative or absolute image path
# NOTE: In this case you should provide tesseract supported images or tesseract will return error
print(pytesseract.image_to_string('test.png')) # Batch processing with a single file containing the list of multiple image file paths
print(pytesseract.image_to_string('images.txt')) # Timeout/terminate the tesseract job after a period of time
try: print(pytesseract.image_to_string('test.jpg', timeout=2)) # Timeout after 2 seconds print(pytesseract.image_to_string('test.jpg', timeout=0.5)) # Timeout after half a second
except RuntimeError as timeout_error: # Tesseract processing is terminated pass # Get bounding box estimates
print(pytesseract.image_to_boxes(Image.open('test.png'))) # Get verbose data including boxes, confidences, line and page numbers
print(pytesseract.image_to_data(Image.open('test.png'))) # Get information about orientation and script detection
print(pytesseract.image_to_osd(Image.open('test.png'))) # Get a searchable PDF
pdf = pytesseract.image_to_pdf_or_hocr('test.png', extension='pdf')
with open('test.pdf', 'w+b') as f: f.write(pdf) # pdf type is bytes by default # Get HOCR output
hocr = pytesseract.image_to_pdf_or_hocr('test.png', extension='hocr') # Get ALTO XML output
xml = pytesseract.image_to_alto_xml('test.png')Voor meer informatie over de code, kun je hun officiële afrekenen documentatie.
In eenvoudige bewoordingen extraheert de code gegevens zoals teksten en begrenzingsvakken uit een bepaalde afbeelding. Hoewel redelijk nuttig, is de engine niet zo sterk als die van geavanceerde oplossingen vanwege hun aanzienlijke rekenkracht voor training.
Google Document API gebruiken
def async_detect_document(gcs_source_uri, gcs_destination_uri):
"""OCR with PDF/TIFF as source files on GCS""" import json import re from google.cloud import vision from google.cloud import storage # Supported mime_types are: 'application/pdf' and 'image/tiff' mime_type = 'application/pdf' # How many pages should be grouped into each json output file. batch_size = 2 client = vision.ImageAnnotatorClient() feature = vision.Feature( type_=vision.Feature.Type.DOCUMENT_TEXT_DETECTION) gcs_source = vision.GcsSource(uri=gcs_source_uri) input_config = vision.InputConfig( gcs_source=gcs_source, mime_type=mime_type) gcs_destination = vision.GcsDestination(uri=gcs_destination_uri) output_config = vision.OutputConfig( gcs_destination=gcs_destination, batch_size=batch_size) async_request = vision.AsyncAnnotateFileRequest( features=[feature], input_config=input_config, output_config=output_config) operation = client.async_batch_annotate_files( requests=[async_request]) print('Waiting for the operation to finish.') operation.result(timeout=420) # Once the request has completed and the output has been # written to GCS, we can list all the output files. storage_client = storage.Client() match = re.match(r'gs://([^/]+)/(.+)', gcs_destination_uri) bucket_name = match.group(1) prefix = match.group(2) bucket = storage_client.get_bucket(bucket_name) # List objects with the given prefix. blob_list = list(bucket.list_blobs(prefix=prefix)) print('Output files:') for blob in blob_list: print(blob.name) # Process the first output file from GCS. # Since we specified batch_size=2, the first response contains # the first two pages of the input file. output = blob_list[0] json_string = output.download_as_string() response = json.loads(json_string) # The actual response for the first page of the input file. first_page_response = response['responses'][0] annotation = first_page_response['fullTextAnnotation'] # Here we print the full text from the first page. # The response contains more information: # annotation/pages/blocks/paragraphs/words/symbols # including confidence scores and bounding boxes print('Full text:n') print(annotation['text'])Uiteindelijk stelt de document-AI van Google u in staat om met hoge nauwkeurigheid tal van informatie uit documenten te extraheren. Bovendien wordt de service ook aangeboden voor specifiek gebruik, inclusief tekstextractie voor zowel normale als in het wild-afbeeldingen.
Raadpleeg hier voor meer info.
Huidige oplossingen voor gegevensextractie
Naast grote bedrijven met API's voor het extraheren van documentgegevens, zijn er verschillende oplossingen die zeer nauwkeurig zijn PDF OCR Diensten. We presenteren verschillende opties voor PDF OCR die gespecialiseerd zijn in verschillende aspecten, evenals enkele recente onderzoeksprototypes die veelbelovende resultaten lijken te bieden*:
*Kanttekening: er zijn meerdere OCR-services die zijn gericht op taken zoals afbeeldingen in het wild. We hebben die services overgeslagen omdat we ons momenteel alleen concentreren op het lezen van PDF-documenten.
- Google-API — Als een van de grootste online serviceproviders biedt Google verbluffende resultaten bij het extraheren van documenten met hun baanbrekende computervisietechnologie. Je kunt hun diensten gratis gebruiken als het gebruik vrij laag is, maar de prijs stijgt naarmate de API-aanroepen toenemen.
- Diepe lezer — Deep Reader is een onderzoekswerk gepubliceerd in ACCV Conference 2019. Het bevat meerdere state-of-the-art netwerkarchitecturen om taken uit te voeren zoals documentovereenkomst, het ophalen van tekst en het verwijderen van ruis. Er zijn extra functies zoals tabellen en extractie van sleutel-waarde-paar waarmee gegevens op een georganiseerde manier kunnen worden opgehaald en opgeslagen.
- Nanonets ™ — Met een zeer bekwaam deep learning-team is Nanonets™ PDF OCR volledig sjabloon- en regelonafhankelijk. Daarom kan Nanonets™ niet alleen werken op specifieke typen PDF's, maar kan het ook worden toegepast op elk documenttype voor het ophalen van tekst.
Wilt u gegevens uit gescande documenten extraheren? Geef Nanonetten™ een draai voor hogere nauwkeurigheid, grotere flexibiliteit, nabewerking en een brede reeks integraties!
Conclusie
Concluderend biedt dit artikel een grondige uitleg over gegevensextractie uit gescande documenten, inclusief de uitdagingen erachter en de technologie die nodig is voor dit proces.
Er worden twee zelfstudies met verschillende methoden gepresenteerd, en de huidige oplossingen die het out-of-the-box bieden, worden ook ter referentie gepresenteerd.
- 2019
- Over
- absoluut
- Account
- accuraat
- Bereiken
- toevoeging
- Extra
- vergevorderd
- voorschotten
- AI
- algoritmen
- Alles
- al
- alternatief
- analyseren
- analyse
- Nog een
- api
- APIs
- Aanvraag
- toepassingen
- nadering
- architectuur
- rond
- dit artikel
- kunstmatig
- kunstmatige intelligentie
- aandacht
- Automatisering
- Beschikbaar
- AWS
- achtergrond
- Bank
- Banken
- basis
- wezen
- BEST
- Verder
- Grootste
- grens
- Box camera's
- bouw
- bedrijfsdeskundigen
- ondernemingen
- Kaarten
- gevallen
- Contant geld
- cash flow
- zeker
- uitdagingen
- uitdagend
- Grafieken
- Afrekenen
- klassiek
- Cloud
- CNN
- code
- hoe
- Gemeen
- Bedrijven
- afstand
- compleet
- het invullen van
- uitgebreid
- berekening
- computer
- concept
- Conferentie
- vertrouwen
- gekoppeld blijven
- permanent
- bevat
- bijgedragen
- gemak
- gemakkelijk
- conversies
- Kern
- Bedrijven
- Overeenkomend
- kon
- cruciaal
- Actueel
- Op dit moment
- klant
- Klanten
- gegevens
- gegevensverwerking
- gegevensopslag
- transactie
- beschreven
- Design
- detail
- Opsporing
- anders
- moeilijk
- digitaal
- documenten
- gemakkelijk
- doeltreffendheid
- medewerkers
- Motor
- Engineering
- vooral
- in wezen
- schattingen
- etc
- evaluatie
- EVENTS
- voorbeeld
- Behalve
- experiment
- Verken
- uitgebreid
- extracten
- familie
- Kenmerk
- Voordelen
- feedback
- Velden
- het vinden van
- Voornaam*
- Flexibiliteit
- stroom
- Focus
- gericht
- richt
- gericht
- volgend
- Voorhoede
- formulier
- formaat
- formulieren
- Gratis
- Frans
- vervullen
- vol
- verder
- doel
- goed
- Kopen Google Reviews
- meer
- sterk
- Behandeling
- hands-on
- hoofd
- gezondheidszorg
- gezondheidszorg
- nuttig
- hier
- Hoge
- hoger
- zeer
- geschiedenis
- ziekenhuizen
- Hoe
- How To
- Echter
- HTTPS
- menselijk
- Personeelszaken
- Mensen
- beeld
- belang
- belangrijk
- verbeteren
- omvatten
- Inclusief
- Inkomen
- Laat uw omzet
- individueel
- individuen
- industrieën
- -industrie
- informatie
- invoer
- geinspireerd
- Intelligentie
- kwestie
- IT
- Jobomschrijving:
- sleutel
- toetsen
- Labs
- taal
- Talen
- Groot
- leidend
- LEARN
- leren
- Lijn
- Lijst
- lang
- machine
- machine learning
- groot
- Meerderheid
- man
- manier
- Markt
- Match
- matching
- medisch
- methoden
- meer
- meest
- Meest populair
- bewegend
- meervoudig
- namelijk
- Naturel
- behoeften
- netwerk
- netwerken
- een
- nummers
- vele
- bieden
- aangeboden
- het aanbieden van
- aanbod
- Aanbod
- officieel
- lopend
- online.
- operatie
- Opties
- bestellen
- organisaties
- Georganiseerd
- Overige
- eigenaren
- deelnemers
- betaling
- uitvoerend
- periode
- persoonlijk
- baanbrekende
- Populair
- potentieel
- energie
- voorspellen
- voorspelling
- presenteren
- mooi
- vorig
- prijs
- processen
- verwerking
- Producten
- Programma
- Programma's
- veelbelovend
- zorgen voor
- het verstrekken van
- doeleinden
- snel
- RE
- Lezer
- lezing
- ontvangen
- verzoening
- archief
- verminderen
- met betrekking tot
- verwantschap
- te vragen
- vereisen
- nodig
- vereist
- onderzoek
- Resources
- antwoord
- Resultaten
- terugkeer
- risico's
- het scannen
- seconden
- service
- Diensten
- reeks
- verscheidene
- Bermuda's
- korte termijn
- gelijk
- Eenvoudig
- sinds
- Maat
- Software
- solide
- Oplossingen
- sommige
- gespecialiseerde
- spinnen
- state-of-the-art
- verklaringen
- statistisch
- mediaopslag
- stream
- sterke
- gestructureerde
- wezenlijk
- geslaagd
- ondersteunde
- Enquête
- doelgerichte
- taken
- team
- technieken
- Technologies
- Technologie
- proef
- de wereld
- daarom
- duizenden kosten
- Door
- niet de tijd of
- keer
- samen
- ton
- in de richting van
- traditioneel
- Trainingen
- tutorials
- types
- begrijpen
- unieke
- .
- doorgaans
- waarde
- divers
- Verificatie
- Bekijk
- visie
- of
- en
- binnen
- zonder
- woorden
- Mijn werk
- werknemers
- wereld
- zou
- XML
- jaar