Tegenwoordig gebruiken honderdduizenden klanten datameren voor analyse en machine learning. Data-engineers moeten deze gegevens echter opschonen en voorbereiden voordat ze kunnen worden gebruikt. De onderliggende gegevens moeten nauwkeurig en recent zijn, wil de klant zelfverzekerde zakelijke beslissingen kunnen nemen. Anders verliezen gegevensconsumenten het vertrouwen in de gegevens en nemen ze suboptimale of onjuiste beslissingen. Het is een gebruikelijke taak voor data-engineers om te evalueren of de data juist en recent zijn of niet. Tegenwoordig zijn er verschillende datakwaliteitstools. Veelgebruikte tools voor gegevenskwaliteit vereisen echter meestal handmatige processen om de gegevenskwaliteit te bewaken.
AWS Glue Data Quality is een voorbeeldfunctie van AWS lijm die de datakwaliteit van meet en bewaakt Amazon eenvoudige opslagservice (Amazon S3) data lakes en in AWS Glue extraheren, transformeren en laden (ETL) jobs. Dit is een open preview-functie, dus deze is al ingeschakeld in uw account in de beschikbare regio's. U kunt de controles van de gegevenskwaliteit eenvoudig definiëren en meten in de AWS Glue Studio-console zonder codes te schrijven. Het vereenvoudigt uw ervaring met het beheren van gegevenskwaliteit.
Dit bericht is deel 2 van een serie van vier berichten om uit te leggen hoe AWS Glue Data Quality werkt. Bekijk het vorige bericht in deze serie:
In dit bericht laten we zien hoe u een AWS Glue-taak kunt maken die de gegevenskwaliteit van een gegevenspijplijn meet en bewaakt. We laten ook zien hoe u actie kunt ondernemen op basis van de resultaten van de datakwaliteit.
Overzicht oplossingen
Laten we eens kijken naar een voorbeeld van een use-case waarin een data-engineer een datapijplijn moet bouwen om de gegevens van een onbewerkte zone op te nemen in een beheerde zone in een datameer. Als data-engineer is het valideren van de kwaliteit van data een van je belangrijkste verantwoordelijkheden, naast het extraheren, transformeren en laden van data. Door vooraf problemen met de gegevenskwaliteit te identificeren, kunt u voorkomen dat slechte gegevens in de beheerde zone worden geplaatst en lastige gegevenscorruptie-incidenten voorkomen.
In dit bericht leer je hoe je dit eenvoudig kunt instellen ingebouwd en gewoonte gegevensvalidatiecontroles in uw AWS Glue-taak om te voorkomen dat slechte gegevens de downstream-gegevens van hoge kwaliteit beschadigen.
De dataset die voor dit bericht wordt gebruikt, is synthetisch gegenereerd; de volgende schermafbeelding toont een voorbeeld van de gegevens.

Resources instellen met AWS CloudFormation
Dit bericht bevat een AWS CloudFormatie sjabloon voor een snelle installatie. U kunt het bekijken en aanpassen aan uw behoeften.
De CloudFormation-sjabloon genereert de volgende bronnen:
- Een Amazon Simple Storage Service (Amazon S3) bucket (
gluedataqualitystudio-*). - De volgende voorvoegsels en objecten in de S3-bucket:
datalake/raw/customer/customer.csvdatalake/curated/customer/scripts/sparkHistoryLogs/temporary/
- AWS Identiteits- en toegangsbeheer (IAM) gebruikers, rollen en beleid. De IAM-rol (
GlueDataQualityStudio-*) toestemming heeft om te lezen en te schrijven vanuit de S3-bucket. - AWS Lambda functies en IAM-beleid vereist door die functies om deze stapel te maken en te verwijderen.
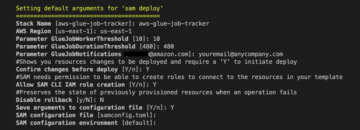
Voer de volgende stappen uit om uw bronnen te maken:
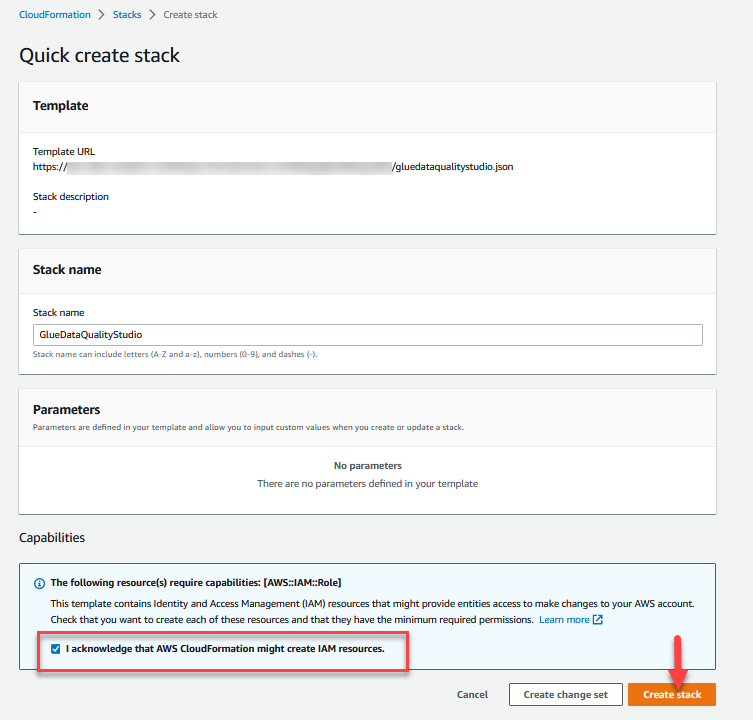
- Log in op AWS CloudFormation-console in de
us-east-1Regio. - Kies Start Stack:

- kies Ik erken dat AWS CloudFormation IAM-bronnen kan creëren.
- Kies Maak een stapel en wacht tot de stap voor het maken van de stapel is voltooid.
Implementeer de oplossing
Voer de volgende stappen uit om te beginnen met het configureren van uw oplossing:
- Op de AWS Glue Studio-console, kiezen Vacatures in het navigatievenster.
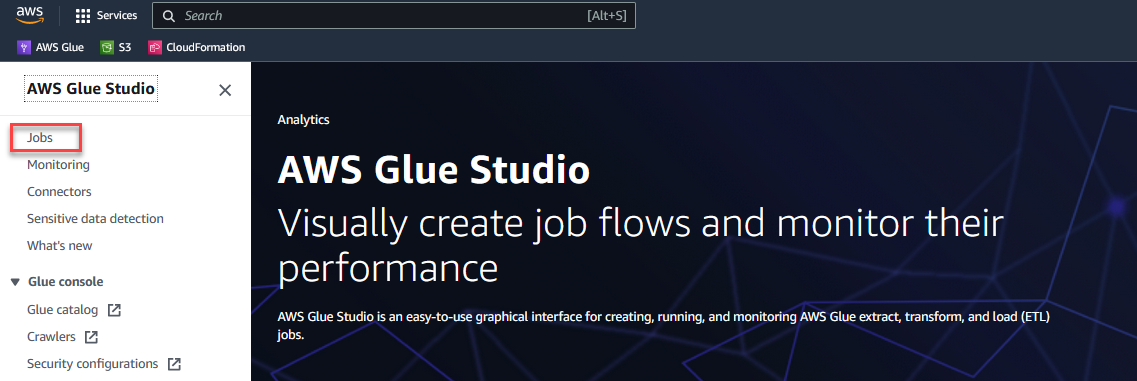
- kies Visueel met een leeg canvas En kies creëren.
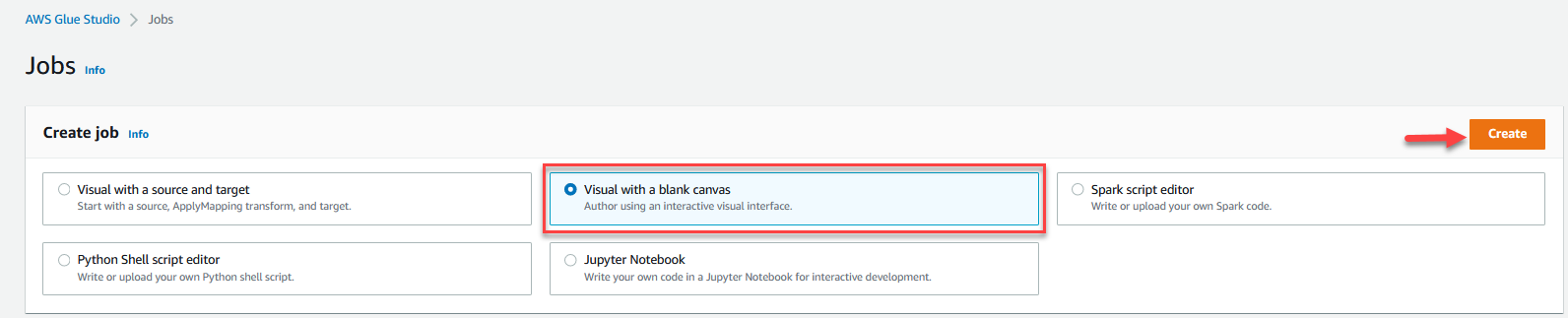
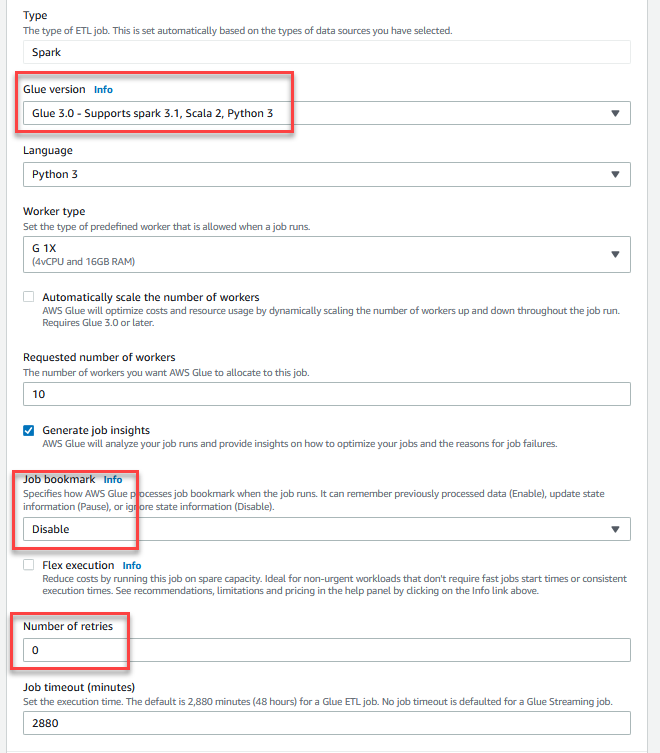
- Kies de Job Details tabblad om de taak te configureren.
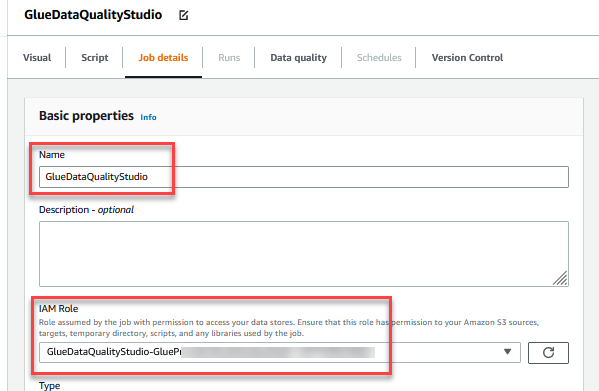
- Voor Naam, ga naar binnen
GlueDataQualityStudio. - Voor IAM-rol, kies de rol die begint met
GlueDataQualityStudio-*. - Voor Lijm versie, kiezen Lijm 3.0.
- Voor Job bladwijzer, kiezen onbruikbaar maken. Hierdoor kunt u deze taak meerdere keren uitvoeren met dezelfde invoergegevensset.
- Voor Aantal nieuwe pogingen, ga naar binnen
0.
- In het Geavanceerde eigenschappen sectie, geeft u de S3-bucket op die is gemaakt door de CloudFormation-sjabloon (beginnend met
gluedataqualitystudio-*).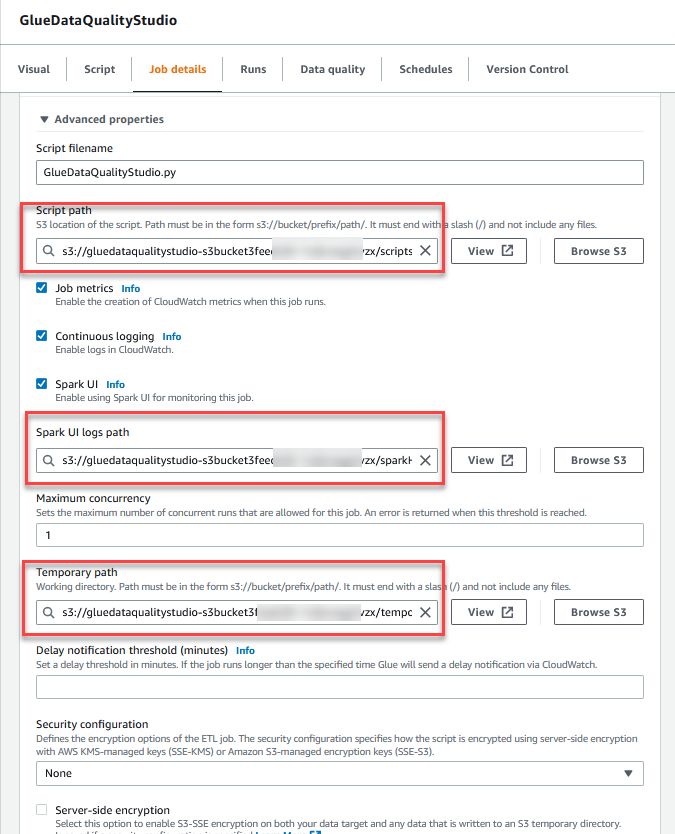
- Kies Bespaar.
- Nadat de taak is opgeslagen, kiest u de Visual tabblad en op de bron menu, kies Amazon S3.
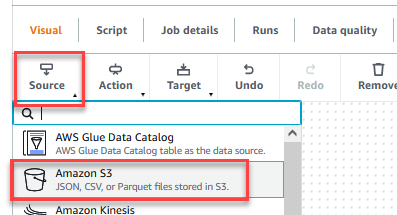
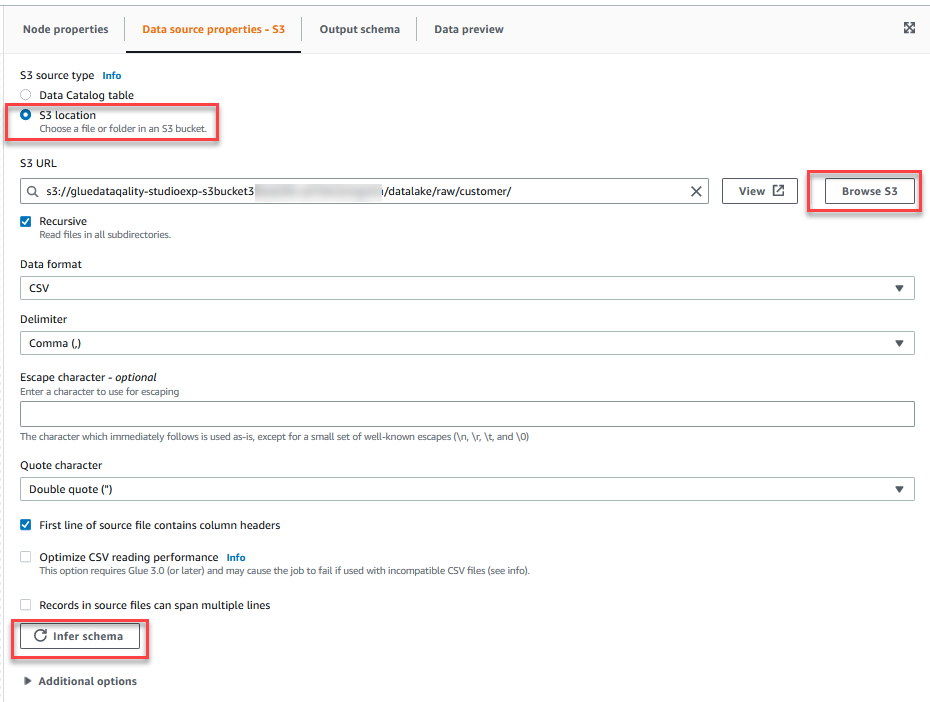
- Op de Eigenschappen gegevensbron - S3 tabblad, voor S3-brontypeselecteer S3 locatie.
- Kies Blader door S3 en navigeer naar voorvoegsel
/datalake/raw/customer/in de S3-bucket beginnend metgluedataqualitystudio-*. - Kies Schema afleiden.
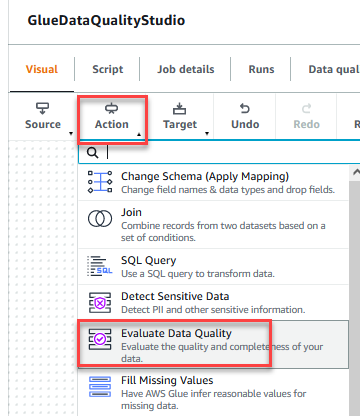
- Op de Actie menu, kies Evalueer de gegevenskwaliteit.
- Kies de Evalueer de gegevenskwaliteit knooppunt.
Op de Transformeren tabblad kunt u nu beginnen met het opstellen van regels voor gegevenskwaliteit. De eerste regel die u maakt, is om te controleren ofCustomer_IDis uniek en niet null met behulp van deisPrimaryKeyregel. - Op de Regel typen tabblad van de DQDL-regelbouwer, zoeken
isprimarykeyen kies het plusteken.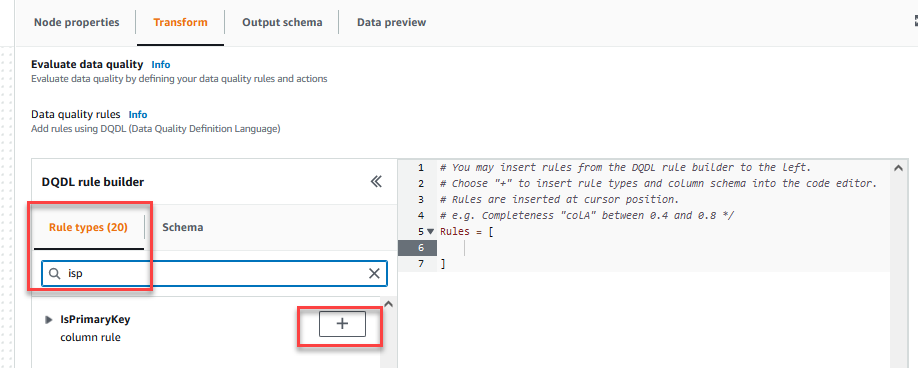
- Op de Schema tabblad van de DQDL-regelbouwer, kies het plusteken naast
Customer_ID. - Verwijder in de regeleditor
id.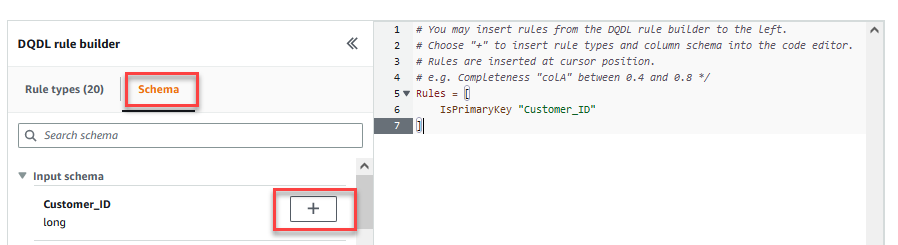
De volgende regel die we toevoegen controleert dat deFirst_Namekolomwaarde is aanwezig voor alle rijen. - U kunt de gegevenskwaliteitsregels ook rechtstreeks in de regeleditor invoeren. Voeg een komma (,) toe en voer in
IsComplete "First_Name",na de eerste regel.
Vervolgens voegt u een aangepaste regel toe om te valideren dat er geen rij zonder bestaatTelephoneorEmail. - Voer de volgende aangepaste regel in de regeleditor in:

De functie Gegevenskwaliteit evalueren biedt acties om de uitkomst van een taak te beheren op basis van de resultaten van de taakkwaliteit. - Selecteer voor dit bericht Mislukte taak wanneer de gegevenskwaliteit faalt En kies Mislukte taak zonder doel te laden gegevens acties. In de Uitvoerinstelling gegevenskwaliteit sectie, kies Blader door S3 en navigeer naar voorvoegsel
dqresultsin de S3-bucket beginnend metgluedataqualitystudio-*.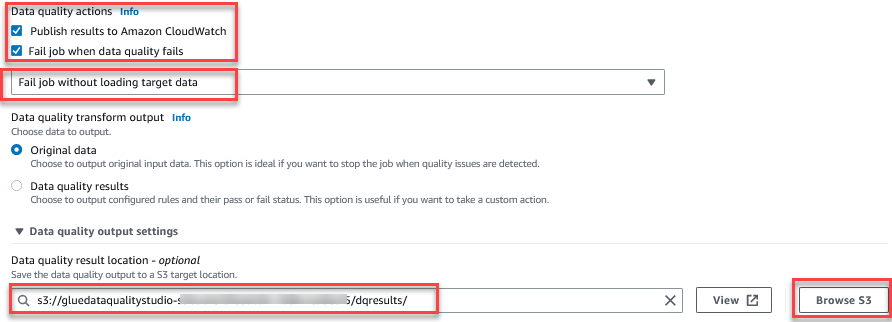
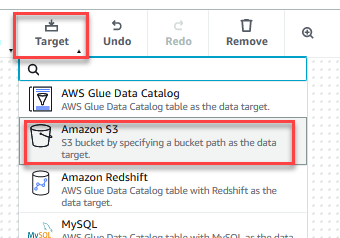
- Op de doelwit menu, kies Amazon S3.
- Kies de Gegevensdoel – S3-bucket knooppunt.
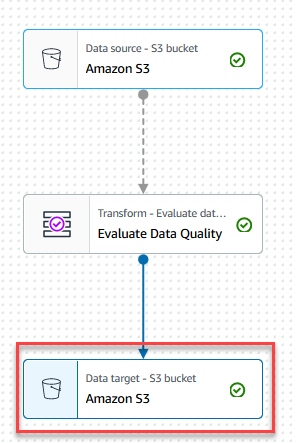
- Op de Eigenschappen van datadoelen - S3 tabblad, voor Formaat, kiezen ParketEn voor Compressietype, kiezen pittig.
- Voor S3 doellocatie, kiezen Blader door S3 en navigeer naar het voorvoegsel
/datalake/curated/customer/in de S3-bucket beginnend metgluedataqualitystudio-*.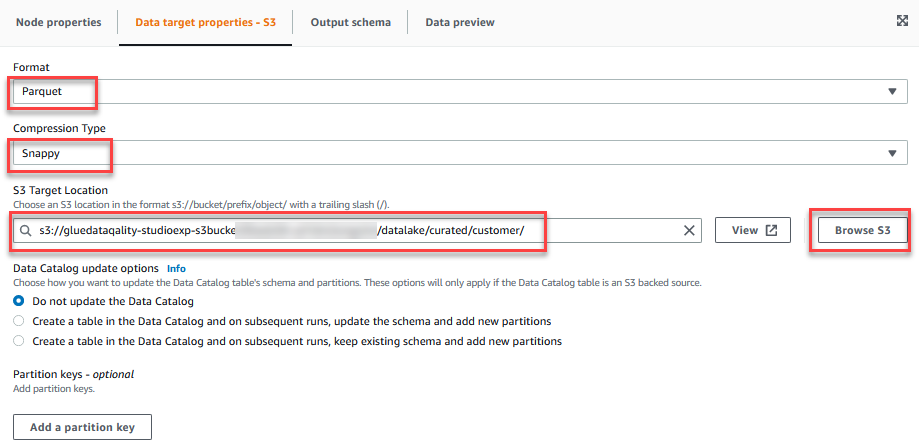
- Kies Bespaar, kies dan lopen.
 U kunt de uitvoeringsdetails van de taak bekijken op het tabblad Uitvoeringen. In ons voorbeeld mislukt de taak met de foutmelding "AssertionError: de taak is mislukt vanwege falende DQ-regels voor knooppunt: .”
U kunt de uitvoeringsdetails van de taak bekijken op het tabblad Uitvoeringen. In ons voorbeeld mislukt de taak met de foutmelding "AssertionError: de taak is mislukt vanwege falende DQ-regels voor knooppunt: .”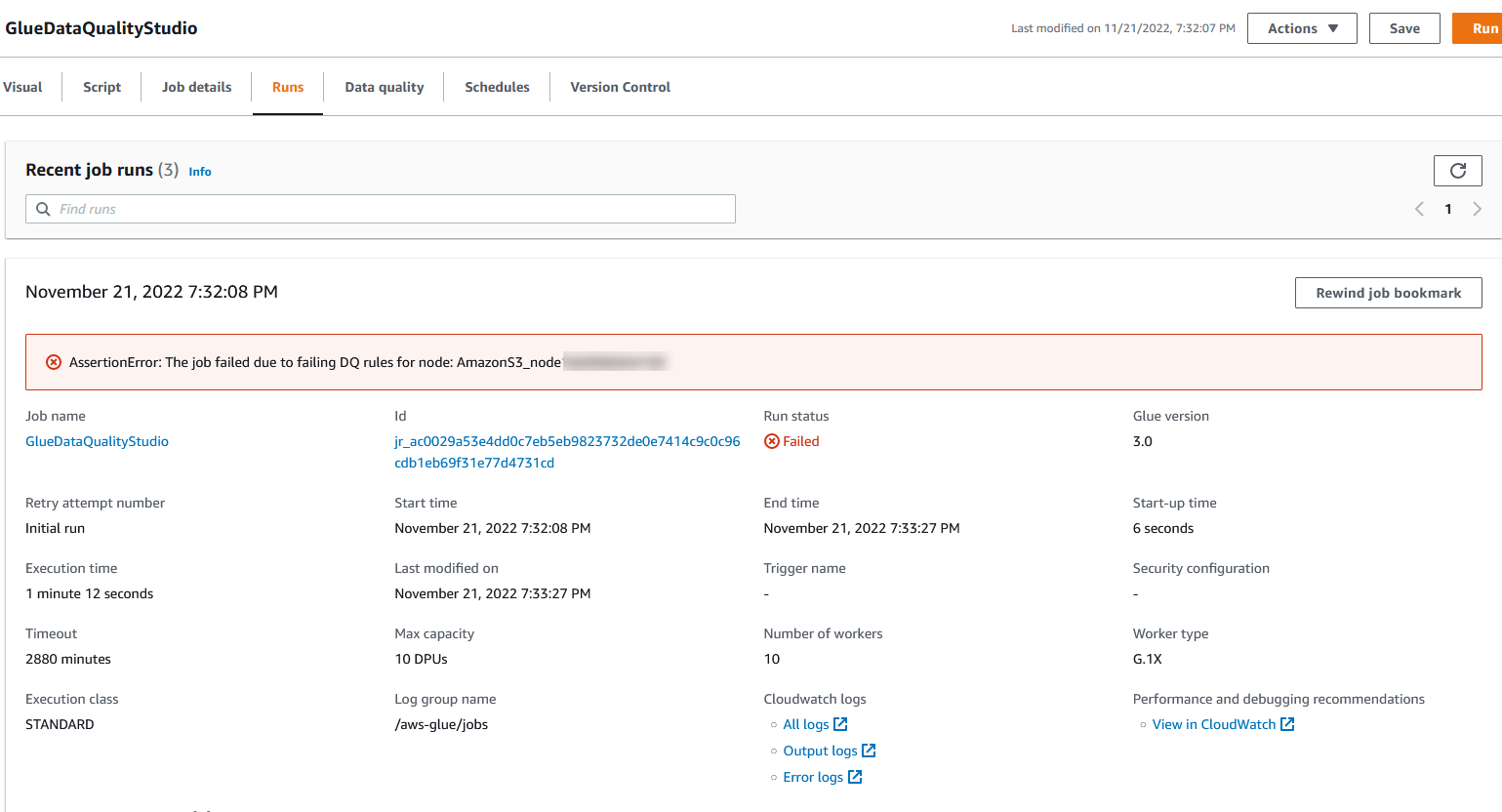 U kunt het resultaat van de gegevenskwaliteit bekijken op het tabblad Gegevenskwaliteit. In ons voorbeeld is de validatie van de aangepaste gegevenskwaliteit mislukt omdat een van de rijen in de dataset geen
U kunt het resultaat van de gegevenskwaliteit bekijken op het tabblad Gegevenskwaliteit. In ons voorbeeld is de validatie van de aangepaste gegevenskwaliteit mislukt omdat een van de rijen in de dataset geen TelephoneorEmailwaarde. De resultaten van Evaluate Data Quality worden ook naar de S3-bucket geschreven in JSON-indeling op basis van de locatieparameter voor de gegevenskwaliteit van het knooppunt.
De resultaten van Evaluate Data Quality worden ook naar de S3-bucket geschreven in JSON-indeling op basis van de locatieparameter voor de gegevenskwaliteit van het knooppunt. - Navigeer naar
dqresultsvoorvoegsel onder de start van de S3-bucketgluedataqualitystudio-*. U zult zien dat het resultaat van de gegevenskwaliteit is gepartitioneerd op datum.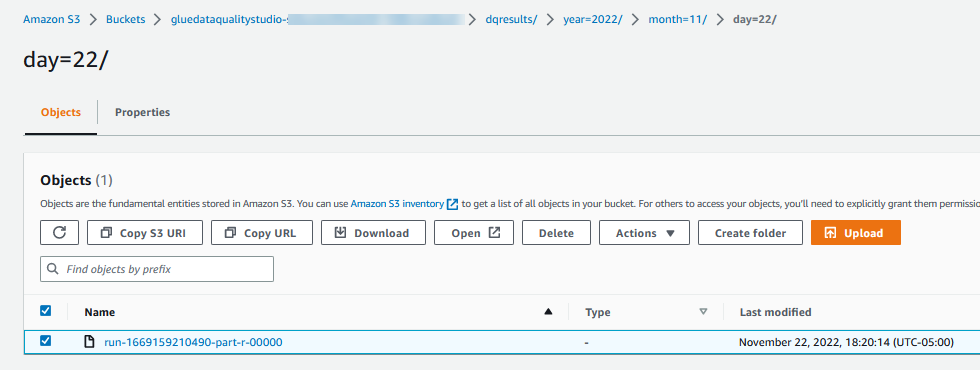
Het volgende is de uitvoer van het JSON-bestand. U kunt deze bestandsuitvoer gebruiken om aangepaste dashboards voor visualisatie van gegevenskwaliteit te bouwen.

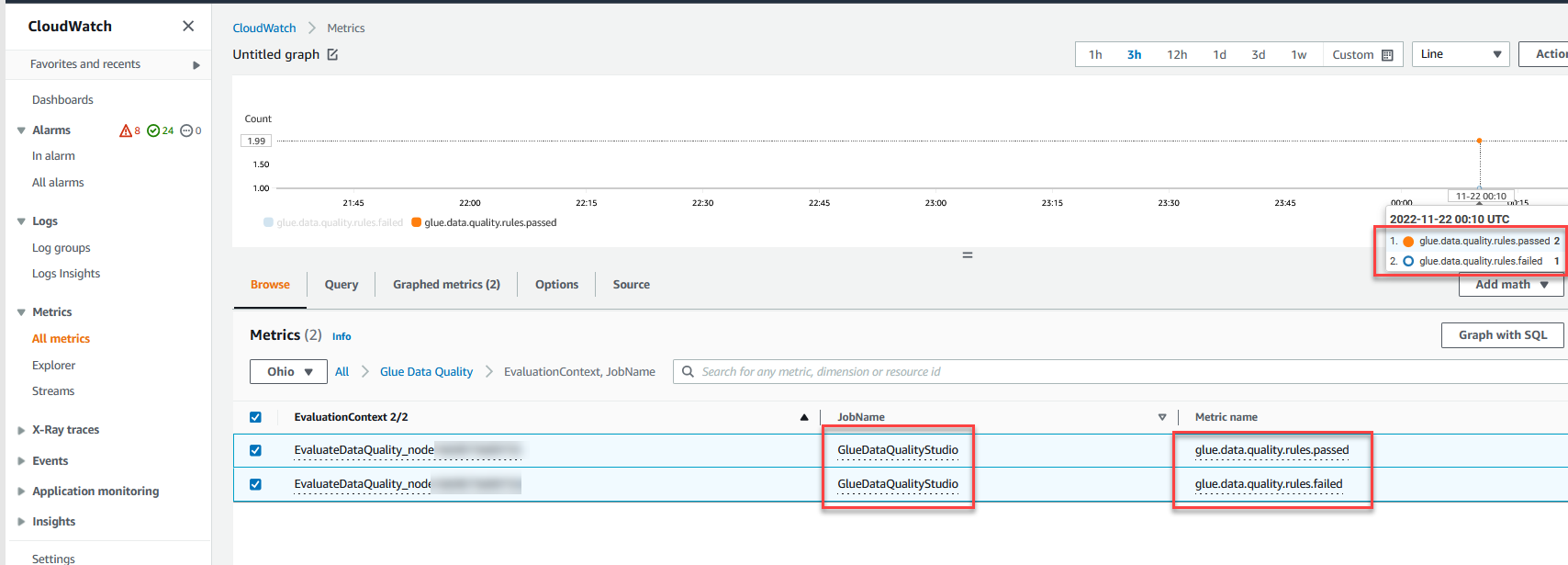
U kunt ook toezicht houden op de Evalueer de gegevenskwaliteit knooppunt door Amazon Cloud Watch statistieken en stel alarmen in om meldingen over resultaten van gegevenskwaliteit te verzenden. Raadpleeg voor meer informatie over het instellen van CloudWatch-alarmen Amazon CloudWatch-alarmen gebruiken.
Opruimen
Verwijder de resources die u hebt gemaakt om te voorkomen dat er in de toekomst kosten in rekening worden gebracht en om ongebruikte rollen en beleidsregels op te ruimen:
- Verwijder de
GlueDataQualityStudiovacature die je hebt gemaakt als onderdeel van dit bericht. - Verwijder op de AWS CloudFormation-console het
GlueDataQualityStudiostack.
Conclusie
AWS Glue Data Quality biedt een eenvoudige manier om de datakwaliteit van uw ETL-pijplijn te meten en te bewaken. In dit bericht hebt u geleerd hoe u de nodige acties kunt ondernemen op basis van de resultaten van de gegevenskwaliteit, waardoor u hoge gegevensnormen kunt handhaven en zelfverzekerde zakelijke beslissingen kunt nemen.
Raadpleeg de documentatie voor meer informatie over AWS Glue Data Quality:
Over de auteurs
 Deenbandhu Prasad is een Senior Analytics Specialist bij AWS, gespecialiseerd in big data services. Hij is gepassioneerd om klanten te helpen bij het bouwen van moderne data-architectuur op de AWS Cloud. Hij heeft klanten van elke omvang geholpen bij het implementeren van datamanagement-, datawarehouse- en datalake-oplossingen.
Deenbandhu Prasad is een Senior Analytics Specialist bij AWS, gespecialiseerd in big data services. Hij is gepassioneerd om klanten te helpen bij het bouwen van moderne data-architectuur op de AWS Cloud. Hij heeft klanten van elke omvang geholpen bij het implementeren van datamanagement-, datawarehouse- en datalake-oplossingen.
 Yannis Mentekidis is een Senior Software Development Engineer in het AWS Glue-team.
Yannis Mentekidis is een Senior Software Development Engineer in het AWS Glue-team.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/getting-started-with-aws-glue-data-quality-for-etl-pipelines/
- 1
- 100
- 7
- a
- Over
- toegang
- Account
- accuraat
- erkennen
- Actie
- acties
- Na
- Alles
- toestaat
- al
- Amazone
- analytics
- en
- architectuur
- AWS
- AWS CloudFormatie
- AWS lijm
- slecht
- slechte gegevens
- gebaseerde
- omdat
- vaardigheden
- Groot
- Big data
- bouw
- Gebouw
- bedrijfsdeskundigen
- geval
- lasten
- controle
- Controles
- Kies
- Cloud
- Kolom
- Gemeen
- compleet
- zeker
- Overwegen
- troosten
- Consumenten
- Corruptie
- en je merk te creëren
- aangemaakt
- het aanmaken
- curated
- gewoonte
- klant
- Klanten
- aan te passen
- gegevens
- Datameer
- gegevensbeheer
- Datum
- beslissingen
- gegevens
- Ontwikkeling
- direct
- documentatie
- gemakkelijk
- editor
- ingenieur
- Ingenieurs
- Enter
- fout
- Ether (ETH)
- schatten
- voorbeeld
- bestaat
- ervaring
- Verklaren
- extract
- Mislukt
- mislukt
- Kenmerk
- Dien in
- Voornaam*
- volgend
- formaat
- oppompen van
- functies
- toekomst
- gegenereerde
- genereert
- het krijgen van
- geholpen
- het helpen van
- helpt
- Hoge
- hoogwaardige
- Hoe
- How To
- Echter
- HTML
- HTTPS
- Honderden
- het identificeren van
- Identiteit
- uitvoeren
- in
- omvat
- invoer
- problemen
- IT
- Jobomschrijving:
- Vacatures
- json
- sleutel
- meer
- LEARN
- geleerd
- leren
- laden
- het laden
- plaats
- verliezen
- machine
- machine learning
- onderhouden
- maken
- beheer
- management
- beheren
- handboek
- maatregel
- maatregelen
- Menu
- Bericht
- Metriek
- macht
- Modern
- monitor
- monitors
- meer
- meervoudig
- OP DEZE WEBSITE VIND JE
- Navigatie
- noodzakelijk
- behoeften
- volgende
- knooppunt
- meldingen
- objecten
- Aanbod
- EEN
- open
- anders-
- brood
- parameter
- deel
- hartstochtelijk
- toestemming
- pijpleiding
- plaatsing
- Plato
- Plato gegevensintelligentie
- PlatoData
- plus
- beleidsmaatregelen door te lezen.
- Post
- Voorbereiden
- presenteren
- voorkomen
- Voorbeschouwing
- vorig
- primair
- processen
- vastgoed
- zorgen voor
- biedt
- kwaliteit
- Quick
- Rauw
- Lees
- recent
- regio
- vereisen
- nodig
- Resources
- resultaat
- Resultaten
- beoordelen
- Rol
- rollen
- RIJ
- Regel
- reglement
- lopen
- dezelfde
- Ontdek
- sectie
- -Series
- service
- Diensten
- reeks
- het instellen van
- setup
- tonen
- Shows
- teken
- Eenvoudig
- maten
- So
- Software
- software development
- oplossing
- Oplossingen
- bron
- specialist
- gespecialiseerd
- stack
- normen
- begin
- gestart
- Start
- Stap voor
- Stappen
- mediaopslag
- studio
- Pak
- synthetisch
- Nemen
- doelwit
- Taak
- team
- sjabloon
- De
- duizenden kosten
- Door
- keer
- naar
- vandaag
- tools
- Transformeren
- transformeren
- Trust
- voor
- die ten grondslag liggen
- unieke
- ongebruikt
- .
- use case
- gebruikers
- doorgaans
- BEVESTIG
- bevestiging
- waarde
- divers
- Bekijk
- visualisatie
- wachten
- of
- welke
- wil
- zonder
- Bedrijven
- schrijven
- het schrijven van
- geschreven
- Your
- zephyrnet