Amazon roodverschuiving is een snel, schaalbaar, veilig en volledig beheerd datawarehouse waarmee u al uw gegevens eenvoudig en kosteneffectief kunt analyseren met behulp van standaard SQL. Amazone roodverschuiving Het delen van gegevens stelt klanten in staat om live, transactioneel consistente gegevens in één Amazon Redshift-cluster veilig te delen met een ander Amazon Redshift-cluster tussen accounts en regio's zonder gegevens van het ene cluster naar het andere te hoeven kopiëren of verplaatsen.
Amazon Redshift Data Sharing werd oorspronkelijk gelanceerd in maart 2021, en er is ondersteuning toegevoegd voor het delen van gegevens tussen verschillende accounts augustus 2021. De interregionale ondersteuning werd algemeen beschikbaar in februari 2022. Dit biedt volledige flexibiliteit en flexibiliteit om gegevens te delen tussen Redshift-clusters in hetzelfde AWS-account, verschillende accounts of verschillende regio's.
Amazon Redshift Data Sharing wordt gebruikt om Amazon Redshift-implementatie-architecturen fundamenteel te herdefiniëren in een hub-spoke, data mesh-model om beter te voldoen aan prestatie-SLA's, werklastisolatie te bieden, analyses over groepen uit te voeren, eenvoudig nieuwe use-cases in te voeren en vooral alle dit zonder de complexiteit van het verplaatsen van gegevens en het kopiëren van gegevens. Enkele van de meest gestelde vragen tijdens de implementatie van het delen van gegevens zijn: "Hoe groot moeten mijn consumentenclusters en producentenclusters zijn?", en "Hoe krijg ik de beste prijs-prestatieverhouding voor werklastisolatie?". Aangezien werkbelastingskenmerken zoals gegevensgrootte, opnamesnelheid, querypatroon en onderhoudsactiviteiten van invloed kunnen zijn op de prestaties van het delen van gegevens, moet een continue strategie worden geïmplementeerd om zowel consumenten- als producentenclusters te dimensioneren om de prestaties te maximaliseren en de kosten te minimaliseren. In dit bericht bieden we een stapsgewijze benadering om u te helpen bij het bepalen van de grootte van uw producenten- en consumentenclusters voor de beste prijs-prestatieverhouding op basis van uw specifieke werklast.
Algemene richtlijnen voor consumentenmaten
De volgende stappen laten de generieke strategie zien om de grootte van uw producenten- en consumentenclusters te bepalen. U kunt het als uitgangspunt gebruiken en dienovereenkomstig aanpassen aan uw specifieke use case-scenario.
Grootte van uw producentencluster
U moet er altijd voor zorgen dat u uw producentencluster de juiste grootte geeft om de prestaties te krijgen die u nodig hebt om aan uw SLA te voldoen. U kunt de maatcalculator van de Amazon Redshift-console gebruiken om een aanbeveling voor het producentencluster te krijgen op basis van de grootte van uw gegevens en zoekkarakteristiek. Zoeken Help me om te kiezen op de console in AWS-regio's die RA3-knooppunttypen ondersteunen om deze maatcalculator te gebruiken. Houd er rekening mee dat dit slechts een eerste aanbeveling is om aan de slag te gaan, en dat u uw volledige werklast moet testen op het cluster met de oorspronkelijke grootte en de grootte van het cluster dienovereenkomstig naar boven en beneden moet aanpassen om de beste prijs-prestatieverhouding te krijgen.
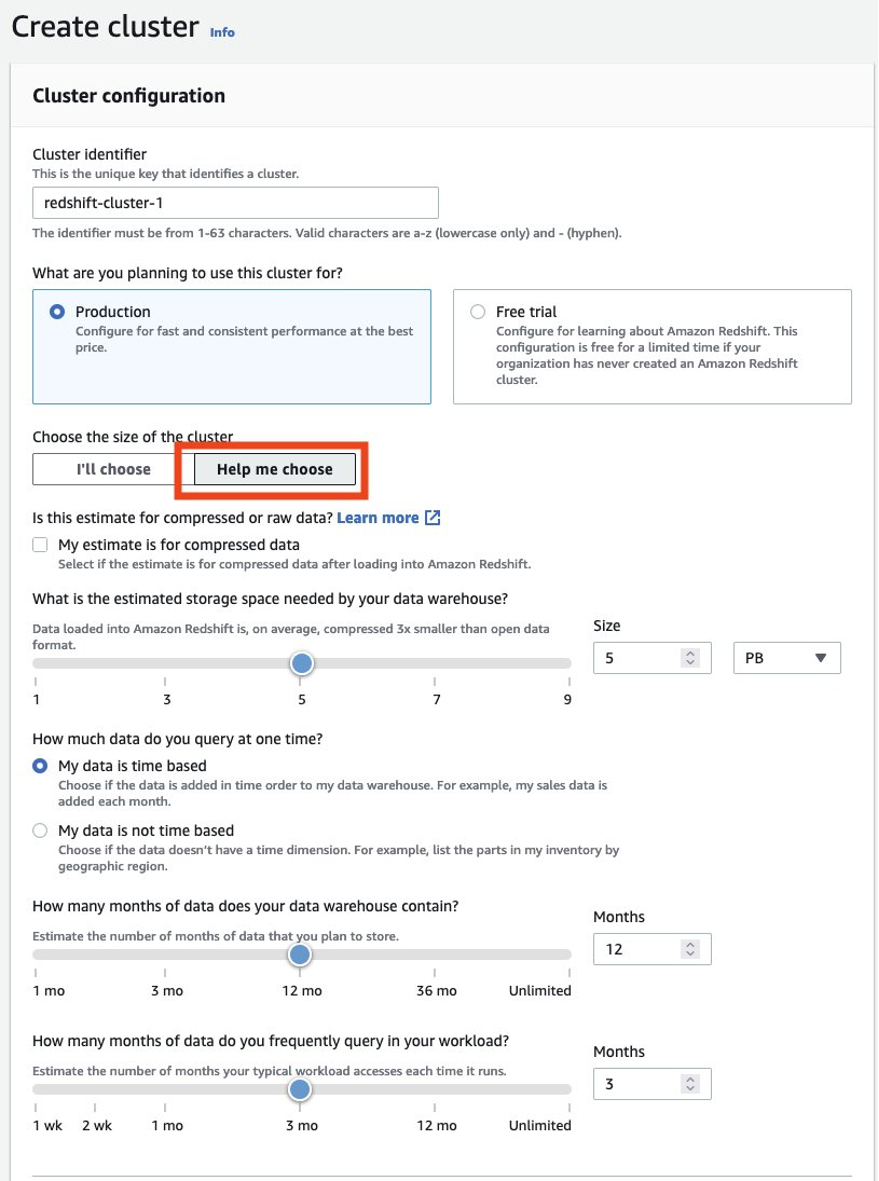
Grootte en configuratie van het initiële consumentencluster
U moet uw consumentencluster altijd aanpassen aan uw rekenbehoeften. Een manier om aan de slag te gaan, is door de generieke clustergroottegids te volgen, vergelijkbaar met het producentencluster hierboven.
Stel het delen van Amazon Redshift-gegevens in
Stel het delen van gegevens in van producent naar consument zodra u zowel het producenten- als het consumentencluster hebt ingesteld. Raadpleeg dit post voor hulp bij het instellen van het delen van gegevens.
Test alleen de werkbelasting van de consument op het initiële consumentencluster
Test alleen de werkbelasting van de consument op het nieuwe initiële consumentencluster. Dit kan worden gedaan door consumententoepassingen, bijvoorbeeld ETL-tools, BI-toepassingen en SQL-clients, naar het nieuwe consumentencluster te verwijzen en de werklast opnieuw uit te voeren om de prestaties te evalueren ten opzichte van uw vereisten.
Test alleen de werkbelasting voor consumenten op verschillende configuraties van consumentenclusters
Als het consumentencluster van initiële grootte voldoet aan of groter is dan de prestatievereisten van uw werkbelasting, kunt u deze clusterconfiguratie blijven gebruiken of u kunt testen op kleinere configuraties om te zien of u de kosten verder kunt verlagen en toch de prestaties kunt krijgen die u nodig hebt.
Aan de andere kant, als het consumentencluster van aanvankelijke grootte niet voldoet aan de prestatievereisten van uw werklast, kunt u grotere configuraties verder testen om de configuratie te krijgen die aan uw SLA voldoet.
Als vuistregel geldt dat u het consumentencluster met 2x de initiële clusterconfiguratie stapsgewijs vergroot totdat het voldoet aan uw werklastvereisten.
Nadat u hebt gepland welke configuratie u wilt testen, gebruikt u Elastic Resize om de grootte van het oorspronkelijke cluster aan te passen aan de configuratie van het doelcluster. Nadat het elastische formaat is gewijzigd, voert u dezelfde werklasttest uit en evalueert u de prestaties ten opzichte van uw SLA. Selecteer de configuratie die voldoet aan uw prijsprestatiedoel.
Test alleen de werkbelasting van de producent op verschillende configuraties van het producentencluster
Zodra u uw consumentenwerklast verplaatst naar het consumentencluster met de optimale prijs-prestatieverhouding, is er wellicht een mogelijkheid om de rekenresource van de producent te verminderen om kosten te besparen.
Om dit te bereiken, kunt u de werklast van alleen de producent opnieuw uitvoeren op 1/2x van de oorspronkelijke grootte van de producent en de prestaties van de werklast evalueren. Het aanpassen van de grootte van het cluster is afhankelijk van het resultaat en vervolgens selecteert u de minimale producerconfiguratie die voldoet aan de prestatievereisten van uw werkbelasting.
Evalueer opnieuw na een volledige werkbelasting in de loop van de tijd
Naarmate Amazon Redshift blijft evolueren en er releases voor continue verbetering van prestaties en schaalbaarheid zijn, zullen de prestaties voor het delen van gegevens blijven verbeteren. Bovendien kunnen talloze variabelen van invloed zijn op de prestaties van query's voor het delen van gegevens. De volgende zijn slechts enkele voorbeelden:
- Opnamesnelheid en hoeveelheid gegevens veranderen
- Vraagpatroon en kenmerk
- Werkdruk verandert
- samenloop
- Onderhoudswerkzaamheden, bijvoorbeeld vacuüm, analyseren en ATO
Daarom moet u af en toe de grootte van het producer- en consumercluster opnieuw evalueren met behulp van de bovenstaande strategie, vooral na een volledige implementatie van de werklast, om de nieuwe beste prijsprestaties uit de configuratie van uw cluster te halen.
Geautomatiseerde maatoplossingen
Als uw omgeving een meer complexe architectuur omvat, bijvoorbeeld met meerdere tools of applicaties (BI, opname of streaming, ETL, datawetenschap), dan is het misschien niet haalbaar om de handmatige methode uit de algemene richtlijnen hierboven te gebruiken. In plaats daarvan kunt u de oplossingen in deze sectie gebruiken om de werkbelasting van uw productiecluster automatisch opnieuw af te spelen op de testconsumenten- en producentenclusters om de prestaties te evalueren.
Eenvoudig Replay-hulpprogramma zal worden gebruikt als de geautomatiseerde oplossing om u te begeleiden bij het verkrijgen van de juiste grootte van de producenten- en consumentenclusters voor de beste prijs-prestatieverhouding.
Simple Replay is een hulpmiddel voor het uitvoeren van een wat-als-analyse en het evalueren van hoe uw werklast presteert in verschillende scenario's. U kunt de tool bijvoorbeeld gebruiken om uw werkelijke werklast te benchmarken op een nieuw instantietype zoals RA3, een nieuwe functie te evalueren of verschillende clusterconfiguraties te beoordelen. Het bevat ook verbeterde ondersteuning voor het opnieuw afspelen van gegevensopname en exportpijplijnen met COPY- en UNLOAD-instructies. Download de tool van de Amazon Redshift GitHub-repository.
Hier doorlopen we de stappen om uw werklastlogboeken uit het bronproductiecluster te extraheren en opnieuw af te spelen in een geïsoleerde omgeving. Hierdoor kunt u naadloos een directe vergelijking maken tussen deze Amazon Redshift-clusters en de clusterconfiguratie selecteren die het beste voldoet aan uw prijs-prestatiedoelstelling.
Het volgende diagram toont de oplossingsarchitectuur.
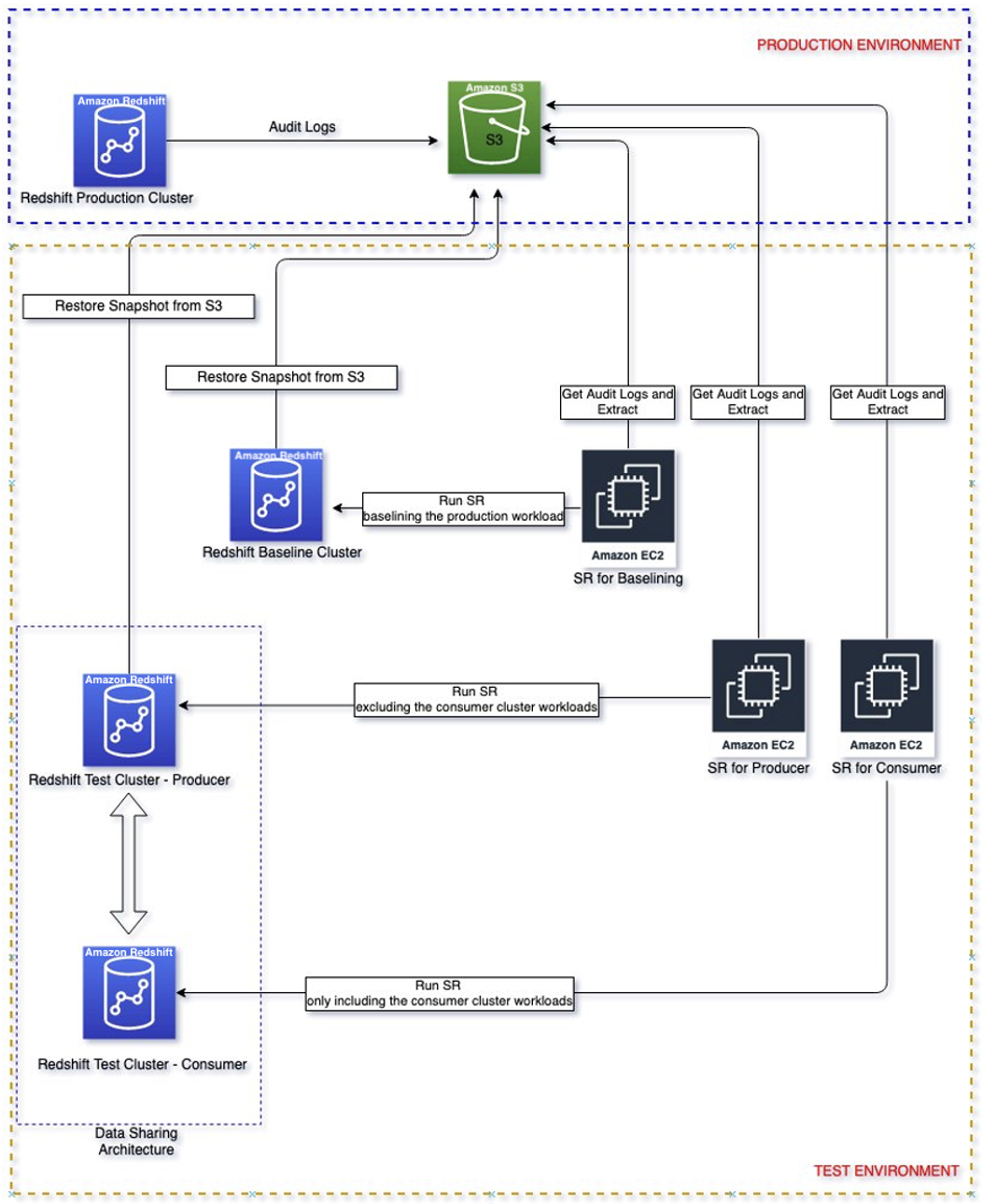
Oplossingsoverzicht
Volg deze stappen om de oplossing te doorlopen om de grootte van uw consumenten- en producentenclusters te bepalen.
Grootte van uw productiecluster
U moet er altijd voor zorgen dat u uw bestaande productiecluster de juiste grootte geeft om de prestaties te krijgen die u nodig hebt om aan uw werklastvereisten te voldoen. U kunt de maatcalculator van de Amazon Redshift-console gebruiken om een aanbeveling over het productiecluster te krijgen op basis van de grootte van uw gegevens en querykenmerk. Zoeken Help me om te kiezen op de console in AWS-regio's die RA3-knooppunttypen ondersteunen om deze maatcalculator te gebruiken. Merk op dat dit slechts een eerste aanbeveling is om aan de slag te gaan. Test het uitvoeren van uw volledige werklast op het cluster met de oorspronkelijke grootte en pas de grootte van het cluster overeenkomstig aan naar boven en naar beneden om de beste prijs-prestatieverhouding te krijgen.
Identificeer de werk belasting die moet worden geïsoleerd
Mogelijk hebt u verschillende werk belastingen op uw oorspronkelijke cluster, maar de eerste stap is het identificeren van de meest kritieke werk belasting voor het bedrijf dat we willen isoleren. Dit komt omdat we ervoor willen zorgen dat de nieuwe architectuur kan voldoen aan uw workloadvereisten. Deze post is een goed naslagwerk over een use case voor het delen van werklastisolatie die u kan helpen beslissen welke werklast kan worden geïsoleerd.
Stel eenvoudig opnieuw afspelen in
Als u eenmaal weet wat uw kritieke werklast is, moet u dat doen auditregistratie inschakelen in uw productiecluster waar de hierboven geïdentificeerde kritieke werkbelasting wordt uitgevoerd om queryactiviteiten vast te leggen en op te slaan Amazon Simple Storage-service (Amazon S3). Houd er rekening mee dat het tot drie uur kan duren voordat de auditlogboeken worden afgeleverd bij Amazon S3. Zodra het auditlogboek beschikbaar is, gaat u verder met Stel eenvoudig opnieuw afspelen in en extract de kritieke werklast uit het auditlogboek. Merk op dat start_time en end_time kunnen worden gebruikt als parameters om de kritieke werklast uit te filteren als die werklasten in bepaalde tijdsperioden worden uitgevoerd, bijvoorbeeld van 9 tot 11 uur. Anders worden alle geregistreerde activiteiten uitgepakt.
Baseline-werklast
Maak een basislijncluster met dezelfde configuratie als het producentencluster door te herstellen vanuit de productiemomentopname. Het doel van het starten met dezelfde configuratie is om de prestaties te baseren op een geïsoleerde omgeving.
Zodra het basislijncluster beschikbaar is, af te spelen de geëxtraheerde werkbelasting in het basislijncluster. De uitvoer van deze herhaling zal de basislijn zijn die wordt gebruikt om te vergelijken met volgende herhalingen op verschillende consumentenconfiguraties.
Stel initiële testclusters voor producenten en consumenten in
Maak een producentencluster met dezelfde productieclusterconfiguratie door te herstellen vanuit de productiemomentopname. Maak een consumentencluster met de aanbevolen initiële consumentengrootte uit de vorige richt lijnen. Stel bovendien het delen van gegevens tussen de producent en de consument in.
Speel de werklast opnieuw af op de oorspronkelijke producent en consument
Replay de werkbelasting van de producent alleen op het producentencluster van initiële grootte. Dit kan worden bereikt met behulp van de filterparameter "Uitsluiten" om consumentenquery's uit te sluiten, bijvoorbeeld de gebruiker die consumentenquery's uitvoert.
Replay de werkbelasting voor alleen de consument op het consumentencluster van initiële grootte. Dit kan worden bereikt met behulp van de filterparameter "Include" om consumentenquery's uit te sluiten, bijvoorbeeld de gebruiker die consumentenquery's uitvoert.
Evalueer de prestaties van deze herhalingen ten opzichte van de prestatievereisten voor basislijn en werklast.
Speel de werkbelasting van de consument af op verschillende configuraties
Als het consumentencluster van initiële grootte voldoet aan of groter is dan de prestatievereisten van uw werkbelasting, kunt u deze clusterconfiguratie gebruiken of u kunt deze stappen volgen om te testen op kleinere configuraties om te zien of u de kosten verder kunt verlagen en toch de prestaties kunt krijgen die u nodig hebt.
Vergelijk de eerste resultaten van de consumentenprestaties met uw werklastvereisten:
- Als het resultaat de prestatievereisten van uw werkbelasting overtreft, kunt u de grootte van het consumentencluster stapsgewijs verkleinen, beginnend met 1/2x, de herhaling opnieuw proberen en de prestaties evalueren, en vervolgens het formaat naar boven of naar beneden aanpassen op basis van het resultaat totdat het aan uw werklast voldoet voorwaarden. Het doel is om een goede plek te krijgen waar u vertrouwd bent met de prestatie-eisen en om de laagst mogelijke prijs te krijgen.
- Als het resultaat niet voldoet aan de prestatievereisten voor uw werkbelasting, kunt u de grootte van het cluster stapsgewijs vergroten, te beginnen met 2x de oorspronkelijke grootte, de herhaling opnieuw proberen en de prestaties evalueren totdat deze voldoet aan de prestatievereisten voor uw werkbelasting.
Speel de productiewerklast opnieuw af op verschillende configuraties
Zodra u uw werkbelasting hebt opgesplitst in consumentenclusters, zou de belasting van het producentencluster moeten worden verminderd en zou u de werklastprestaties van uw producentencluster moeten evalueren om de mogelijkheid te zoeken om te verkleinen om kosten te besparen.
De stappen zijn vergelijkbaar met het opnieuw afspelen door consumenten. Elastisch wijzig de grootte van het producentencluster stapsgewijs, beginnend met 1/2x de oorspronkelijke grootte, speel de werkbelasting van alleen de producent opnieuw af en evalueer de prestaties, en wijzig vervolgens de grootte omhoog of omlaag totdat deze voldoet aan de prestatie-eisen van uw werkbelasting. Het doel is om een goede plek te krijgen waar u vertrouwd bent met de vereisten voor werklastprestaties en om de laagst mogelijke prijs te krijgen. Zodra u de gewenste configuratie van het producentencluster hebt, probeert u de werkbelasting van de consument opnieuw af te spelen op het consumentencluster om ervoor te zorgen dat de prestaties niet worden beïnvloed door wijzigingen in de configuratie van het producentencluster. Ten slotte moet u zowel producer- als consumer-workloads gelijktijdig opnieuw afspelen om ervoor te zorgen dat de prestaties worden bereikt in een scenario met volledige workload.
Evalueer opnieuw na een volledige werkbelasting in de loop van de tijd
Net als bij de generieke richt lijnen, moet u de grootte van de producer-en consumenten clusters af en toe opnieuw evalueren met behulp van de vorige strategie, met name na volledige implementatie van de werk belasting om de nieuwe beste prijs prestaties uit de configuratie van uw cluster te halen.
Opruimen
Het uitvoeren van deze dimensioneringstests in uw AWS-account kan enige kostenimplicaties hebben, omdat het nieuwe Amazon Redshift-clusters levert, die kunnen worden aangerekend als on-demand instanties als u geen gereserveerde instanties hebt. Wanneer u uw evaluaties voltooit, raden we u aan de Amazon Redshift-clusters te verwijderen om kosten te besparen. We raden u ook aan uw clusters te onderbreken wanneer ze niet in gebruik zijn.
Toepassen van Amazon Redshift en best practices voor het delen van gegevens
Een juiste dimensionering van zowel uw producenten- als consumentenclusters geeft u een goede start om de beste prijs-prestatieverhouding uit uw Amazon Redshift-implementatie te halen. Grootte is echter niet de enige factor die uw prestaties kan maximaliseren. In dit geval zijn het begrijpen en volgen van best practices net zo belangrijk.
Algemene best practices voor prestatieafstemming van Amazon Redshift zijn van toepassing op de implementatie van het delen van gegevens. Zorg ervoor dat uw implementatie deze volgt 'best practices'.
Er zijn talloze specifieke best practices voor het delen van gegevens die u moet volgen om ervoor te zorgen dat u de prestaties maximaliseert. Raadpleeg dit post voor meer details.
Samengevat
Er is geen eenduidige aanbeveling voor clustergroottes van producenten en consumenten. Het varieert per workload en uw prestatie-SLA. Het doel van dit bericht is om u te begeleiden bij het evalueren van uw specifieke werklastprestaties voor het delen van gegevens om de clustergroottes van zowel consumenten als producenten te bepalen om de beste prijs-prestatieverhouding te krijgen. Overweeg om uw workloads op producer en consument te testen met eenvoudige herhaling voordat u deze in productie neemt om de beste prijs-prestatieverhouding te krijgen.
Over de auteurs
 BP ja is Senior Product Manager bij AWS. Hij is gepassioneerd in het helpen van klanten bij het ontwerpen van big data-oplossingen om data op grote schaal te verwerken. Voordat hij bij AWS kwam, hielp hij Amazon.com Supply Chain Optimization Technologies bij het migreren van zijn Oracle-datawarehouse naar Amazon Redshift en bij het bouwen van zijn volgende generatie big data-analyseplatform met behulp van AWS-technologieën.
BP ja is Senior Product Manager bij AWS. Hij is gepassioneerd in het helpen van klanten bij het ontwerpen van big data-oplossingen om data op grote schaal te verwerken. Voordat hij bij AWS kwam, hielp hij Amazon.com Supply Chain Optimization Technologies bij het migreren van zijn Oracle-datawarehouse naar Amazon Redshift en bij het bouwen van zijn volgende generatie big data-analyseplatform met behulp van AWS-technologieën.
 Sidhanth Muralidhar is Principal Technical Account Manager bij AWS. Hij werkt met grote zakelijke klanten die hun workloads op AWS uitvoeren. Hij is gepassioneerd door het werken met klanten en hen te helpen bij het ontwerpen van workloads voor kosten, betrouwbaarheid, prestaties en operationele uitmuntendheid op schaal in hun cloudreis. Hij heeft ook een grote interesse in data-analyse.
Sidhanth Muralidhar is Principal Technical Account Manager bij AWS. Hij werkt met grote zakelijke klanten die hun workloads op AWS uitvoeren. Hij is gepassioneerd door het werken met klanten en hen te helpen bij het ontwerpen van workloads voor kosten, betrouwbaarheid, prestaties en operationele uitmuntendheid op schaal in hun cloudreis. Hij heeft ook een grote interesse in data-analyse.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/how-to-get-best-price-performance-from-your-amazon-redshift-data-sharing-deployment/
- 100
- a
- Over
- boven
- dienovereenkomstig
- Account
- accounts
- Bereiken
- bereikt
- over
- activiteiten
- toegevoegd
- De goedkeuring van
- Na
- tegen
- Alles
- toestaat
- altijd
- Amazone
- Amazon.com
- bedragen
- analyse
- analytics
- analyseren
- en
- Nog een
- toepasselijk
- toepassingen
- nadering
- architectuur
- controleren
- geautomatiseerde
- webmaster.
- Beschikbaar
- AWS
- gebaseerde
- Baseline
- omdat
- vaardigheden
- criterium
- BEST
- 'best practices'
- Betere
- tussen
- Groot
- Big data
- bouw
- bedrijfsdeskundigen
- vangen
- geval
- gevallen
- zeker
- keten
- Wijzigingen
- karakteristiek
- kenmerken
- opgeladen
- klanten
- Cloud
- TROS
- COM
- comfortabel
- Gemeen
- vergelijken
- vergelijking
- compleet
- Voltooid
- complex
- ingewikkeldheid
- Berekenen
- uitvoeren
- Configuratie
- Overwegen
- consequent
- troosten
- consument
- voortzetten
- blijft
- doorlopend
- Kosten
- Kosten
- kon
- en je merk te creëren
- kritisch
- Klanten
- gegevens
- gegevens Analytics
- data science
- het delen van gegevens
- geleverd
- afhankelijk
- inzet
- gegevens
- Bepalen
- anders
- directe
- Dont
- beneden
- Download
- gedurende
- gemakkelijk
- beide
- maakt
- verbeterde
- Enterprise
- Milieu
- even
- vooral
- Ether (ETH)
- schatten
- evaluaties
- evoluerende
- voorbeeld
- voorbeelden
- overschrijdt
- Uitmuntendheid
- bestaand
- exporteren
- extract
- mislukt
- SNELLE
- uitvoerbaar
- Kenmerk
- filter
- Tot slot
- Voornaam*
- Flexibiliteit
- volgen
- volgend
- volgt
- oppompen van
- vol
- fundamenteel
- verder
- Bovendien
- Krijgen
- algemeen
- generatie
- krijgen
- het krijgen van
- GitHub
- Geven
- Go
- goed
- Kopen Google Reviews
- gids
- hulp
- geholpen
- het helpen van
- HOURS
- Hoe
- How To
- Echter
- HTTPS
- geïdentificeerd
- identificeren
- Impact
- beïnvloed
- geïmplementeerd
- implicaties
- belangrijk
- verbetering
- het verbeteren van
- in
- omvat
- Laat uw omzet
- eerste
- eerste
- instantie
- verkrijgen in plaats daarvan
- belang
- betrokken zijn
- geïsoleerd
- isolatie
- IT
- Keen
- blijven
- Groot
- groter
- gelanceerd
- Laten we
- Hefboomwerking
- leven
- laden
- Kijk
- onderhoud
- maken
- manager
- handboek
- Maximaliseren
- Maak kennis met
- Meets
- methode
- macht
- trekken
- minimum
- model
- meer
- meest
- beweging
- beweging
- meervoudig
- Noodzaak
- nodig
- behoeften
- New
- volgende
- knooppunt
- vele
- per gelegenheid
- Aan boord
- EEN
- operationele
- kansen
- optimalisatie
- optimum
- orakel
- origineel
- Overige
- anders-
- parameter
- parameters
- hartstochtelijk
- Patronen
- uitvoeren
- prestatie
- presteert
- periodes
- plan
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- mogelijk
- Post
- praktijken
- vorig
- prijs
- Principal
- producent
- Product
- product manager
- Productie
- naar behoren
- zorgen voor
- biedt
- doel
- Contact
- tarief
- adviseren
- Aanbeveling
- aanbevolen
- verminderen
- Gereduceerd
- regio
- Releases
- betrouwbaarheid
- Voorwaarden
- gereserveerd
- hulpbron
- het herstellen van
- resultaat
- Resultaten
- Regel
- lopen
- lopend
- dezelfde
- Bespaar
- Schaalbaarheid
- schaalbare
- Scale
- scenario's
- Wetenschap
- naadloos
- sectie
- beveiligen
- vast
- Zoeken
- service
- setup
- Delen
- delen
- moet
- tonen
- Shows
- gelijk
- Eenvoudig
- Maat
- maten
- kleinere
- Momentopname
- oplossing
- Oplossingen
- sommige
- bron
- specifiek
- spleet
- Spot
- standaard
- begin
- gestart
- Start
- verklaringen
- Stap voor
- Stappen
- Still
- mediaopslag
- shop
- Strategie
- streaming
- volgend
- leveren
- toeleveringsketen
- Optimalisatie van de toeleveringsketen
- ondersteuning
- zoet
- Nemen
- doelwit
- Technisch
- Technologies
- proef
- Testen
- testen
- De
- De Bron
- hun
- drie
- Door
- niet de tijd of
- naar
- tools
- tools
- types
- begrip
- .
- use case
- Gebruiker
- Vacuüm
- Wat
- welke
- WIE
- wil
- zonder
- werkzaam
- Bedrijven
- Your
- zephyrnet