
Regressiemodellen
RMSE is een goede maatstaf om te evalueren hoe a machine learning model presteert.
Als RMSE significant hoger is in de testset dan in de trainingsset, is de kans groot dat het model overfit is. (Zorg ervoor dat trein en testset van dezelfde/soortgelijke distributie zijn)
Raad eens, het evalueren van een classificatiemodel is niet zo eenvoudig
Maar waarom?
Je vraagt je vast af 'Kunnen we niet gewoon gebruiken nauwkeurigheid van het model als de heilige graal-metriek?'
Nauwkeurigheid is erg belangrijk, maar het is misschien niet altijd de beste maatstaf. Laten we eens kijken waarom met een voorbeeld -:
Laten we zeggen dat we een model bouwen dat voorspelt of een banklening in gebreke zal blijven of niet
(De S&P/Experian Consumer Credit Default Composite Index rapporteerde een wanbetalingspercentage van 0.91%)
Laten we een dummy-model hebben dat altijd voorspelt dat een lening niet in gebreke blijft. Raad eens wat de nauwkeurigheid van dit model zou zijn?
===> 99.10%
Indrukwekkend, toch? Welnu, de kans dat een bank dit model koopt, is absoluut nul. 😆
Hoewel ons model een verbluffende nauwkeurigheid heeft, is dit een treffend voorbeeld waarbij nauwkeurigheid absoluut niet de juiste maatstaf is.
Als het geen nauwkeurigheid is, wat nog meer?
Naast nauwkeurigheid zijn er nog een aantal andere methoden om de prestaties van een classificatiemodel te evalueren
- Verwarring Matrix,
- Precisie, herinneren
- ROC en AUC
Voordat we verder gaan, zullen we enkele termen bekijken die constant herhaald zullen worden en die het geheel tot een onbegrijpelijk doolhof kunnen maken als ze niet duidelijk begrepen worden.
Makkelijk toch?
Nou, niet hetzelfde gevoel nadat ik deze allemaal zag 🤔

Maar zoals ze zeggen: elke wolk heeft een zilveren randje
Laten we het een voor een begrijpen, te beginnen met de fundamentele termen.
De positieve en negatieve punten - TP, TN, FP, FN
Ik gebruik deze hack om de betekenis van elk van deze correct te onthouden.
(Binair classificatieprobleem. Bijv. - Voorspellen of een banklening in gebreke blijft)
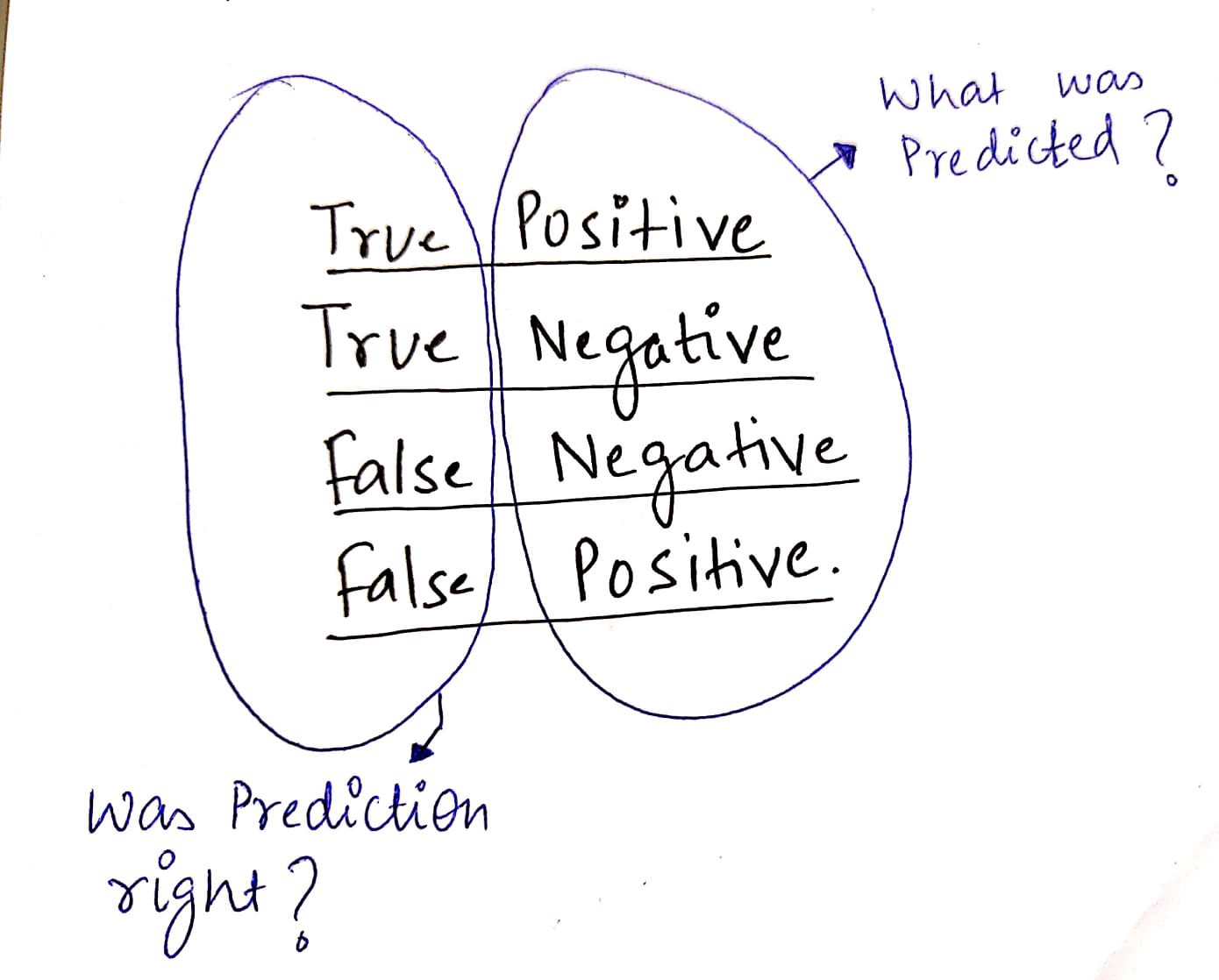
Dus wat is de betekenis van a Echt negatief?
Echt negatief: We hadden gelijk toen we voorspelden dat een lening niet in gebreke zou blijven.
vals positief: We hebben ten onrechte voorspeld dat een lening in gebreke zou blijven.
Laten we versterken wat we hebben geleerd

Een ander beeld dat het in mijn gedachten stempelt.
Zoals we nu bekend zijn met TP, TN, FP, FN — Het zal heel gemakkelijk te begrijpen zijn wat de verwarringsmatrix is.
Het is een samenvattende tabel die laat zien hoe goed ons model is in het voorspellen van voorbeelden van verschillende klassen. Assen hier zijn voorspelde labels versus werkelijke labels.

Verwarringsmatrix voor een classificatiemodel dat voorspelt of een lening in gebreke zal blijven of niet.
Precisie — Ook wel positieve voorspellende waarde genoemd
De verhouding tussen correcte positieve voorspellingen en het totale aantal voorspelde positieven.

Herinneren - Ook wel gevoeligheid, waarschijnlijkheid van detectie, True Positive Rate genoemd
De verhouding tussen correcte positieve voorspellingen en het totale aantal positieve voorbeelden.
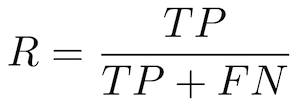
Begrip
Begrijpen precisie en Terugroepen, laten we een voorbeeld nemen van Zoeken. Denk aan het zoekvak op de startpagina van Amazon.

De nauwkeurigheid is het aandeel relevante resultaten in de lijst met alle geretourneerde zoekresultaten. De herinneren is de verhouding tussen de relevante resultaten die door de zoekmachine worden geretourneerd en het totale aantal relevante resultaten dat had kunnen worden geretourneerd.
In ons geval van voorspellen of een lening in gebreke zou blijven, zou het beter zijn om een hoge terugroepactie te hebben, aangezien de banken geen geld willen verliezen en het een goed idee zou zijn om de bank te alarmeren, zelfs als er enige twijfel bestaat over de wanbetaler.
Lage precisie kan in dit geval in orde zijn.
Note: Meestal moeten we de een boven de ander kiezen. Het is bijna onmogelijk om zowel High Precision als Recall te hebben.
Over nauwkeurigheid gesproken, onze favoriete statistiek!
Nauwkeurigheid wordt gedefinieerd als de verhouding tussen correct voorspelde voorbeelden en het totale aantal voorbeelden.

In termen van verwarringsmatrix wordt het gegeven door:

Onthoud dat nauwkeurigheid een zeer nuttige statistiek is wanneer alle klassen even belangrijk zijn. Maar dit is misschien niet het geval als we voorspellen of een patiënt kanker heeft. In dit voorbeeld kunnen we waarschijnlijk FP's tolereren, maar geen FN's.
Een ROC-curve (receiver operating Characteristic Curve) grafiek toont de prestaties van een classificatiemodel bij alle classificatiedrempels.
(Drempels gebruiken: Stel, als u TPR en FPR wilt berekenen voor de drempel gelijk aan 0.7, past u het model toe op elk voorbeeld, verkrijgt u de score en, als de score hoger is dan of gelijk is aan 0.7, voorspelt u de positieve klasse; anders voorspel je de negatieve klasse)
Het plot 2 parameters:
- Echt positief tarief (Herinneren)
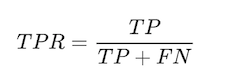
- Vals positief percentage
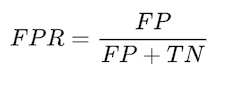
Geeft aan welk % van de mensen die geen wanbetaler waren, werd geïdentificeerd als wanbetaler.
voorspellingen tot de totale voorspelde positieven.
Een typische ROC-curve.
Het verlagen van de classificatiedrempel classificeert meer items als positief, waardoor zowel fout-positieven als terecht-positieven toenemen.
AUC staat voor Gebied onder de ROC-curve. Het biedt een geaggregeerde prestatiemaatstaf voor alle mogelijke classificatiedrempels.
Hoe hoger de gebied onder de ROC-curve (AUC), hoe beter de classificator. Een perfecte classificator zou een AUC van 1 hebben. Als uw model zich goed gedraagt, verkrijgt u gewoonlijk een goede classificator door de waarde van de drempel te selecteren die TPR dicht bij 1 geeft terwijl FPR dicht bij 0 blijft.
In dit bericht hebben we gezien hoe een classificatiemodel effectief kan worden geëvalueerd, vooral in situaties waarin kijken naar alleenstaande nauwkeurigheid niet voldoende is. We begrepen concepten als TP, TN, FP, FN, Precision, Recall, Confusion matrix, ROC en AUC. Ik hoop dat het dingen duidelijker heeft gemaakt!
ORIGINELE. Met toestemming opnieuw gepost.
Vipul Jaïn is een datawetenschapper met een focus op machine learning en heeft ervaring met het bouwen van end-to-end dataproducten, van ideevorming tot productie.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2020/01/guide-precision-recall-confusion-matrix.html?utm_source=rss&utm_medium=rss&utm_campaign=idiots-guide-to-precision-recall-and-confusion-matrix
- 1
- 7
- a
- Over
- absoluut
- nauwkeurigheid
- over
- Na
- alarm
- Alles
- altijd
- Amazone
- en
- Solliciteer
- APT
- ASSEN
- Bank
- Banken
- BEST
- Betere
- Box camera's
- Gebouw
- Bos
- Buying
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- Kanker
- geval
- kans
- karakteristiek
- klasse
- klassen
- classificatie
- duidelijk
- Sluiten
- Cloud
- Berekenen
- concepten
- verwarring
- permanent
- consument
- kon
- Credits
- kredietverzuim
- curve
- gegevens
- data scientist
- Standaard
- definitief
- Opsporing
- distributie
- Dont
- twijfelen
- elk
- effectief
- eind tot eind
- Motor
- genoeg
- even
- vooral
- schatten
- geëvalueerd
- evalueren
- Zelfs
- voorbeeld
- voorbeelden
- ervaring
- vertrouwd
- Focus
- Naar voren
- fps
- oppompen van
- fundamenteel
- krijgen
- gegeven
- geeft
- goed
- Graal
- diagram
- gids
- houwen
- hier
- Hoge
- hoger
- Home
- hoop
- Hoe
- HTTPS
- idee
- geïdentificeerd
- belangrijk
- onmogelijk
- in
- onbegrijpelijk
- meer
- index
- IT
- artikelen
- KDnuggets
- houden
- leren
- Lijst
- lening
- Kijk
- op zoek
- verliezen
- machine
- machine learning
- gemaakt
- maken
- Matrix
- betekenis
- maatregel
- Medium
- methoden
- metriek
- macht
- denken
- model
- geld
- meer
- bewegend
- Nabij
- negatief
- aantal
- Okay
- EEN
- werkzaam
- Overige
- anders-
- parameters
- patiënt
- Mensen
- prestatie
- uitvoerend
- toestemming
- kiezen
- beeld
- Plato
- Plato gegevensintelligentie
- PlatoData
- positief
- mogelijk
- Post
- precisie
- voorspellen
- voorspeld
- het voorspellen van
- Voorspellingen
- voorspelt
- waarschijnlijkheid
- waarschijnlijk
- probleem
- productie
- Producten
- biedt
- tarief
- verhouding
- versterken
- relevante
- niet vergeten
- herhaald
- gemeld
- Resultaten
- dezelfde
- Wetenschapper
- Ontdek
- zoekmachine
- selecteren
- Gevoeligheid
- reeks
- Shows
- aanzienlijk
- Zilver
- situaties
- sommige
- standalone
- staat
- Start
- OVERZICHT
- tafel
- Nemen
- termen
- proef
- De
- ding
- spullen
- drempel
- niet de tijd of
- naar
- Totaal
- TPR
- Trainen
- waar
- typisch
- voor
- begrijpen
- begrijpelijk
- .
- doorgaans
- waarde
- divers
- Wat
- Wat is
- welke
- en
- WIE
- wil
- zou
- Your
- zephyrnet
- nul










