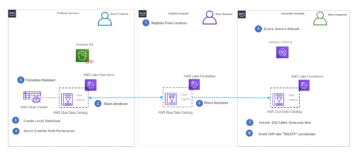
we hebben onlangs aangekondigd ondersteuning voor AWS Lake-formatie fijnmazig toegangscontrolebeleid in Amazone Athene query's voor gegevens die zijn opgeslagen in elk ondersteund bestandsformaat met behulp van tabelindelingen zoals Apache Iceberg, Apache Hudi en Apache Hive. Met AWS Lake Formation kunt u toegangsbeleid op database-, tabel- en kolomniveau definiëren en afdwingen om Iceberg-tabellen te doorzoeken die zijn opgeslagen in Amazon S3. Lake Formation biedt een autorisatie- en governancelaag voor gegevens die zijn opgeslagen in Amazon S3. Deze mogelijkheid vereist dat u upgradet naar Athena motorversie 3.
Grote organisaties hebben vaak bedrijfslijnen (LoB's) die autonoom opereren bij het beheer van hun bedrijfsgegevens. Het maakt het delen van gegevens tussen LoB's niet triviaal. Deze organisaties hebben een gefedereerd model aangenomen, waarbij elke LoB de autonomie heeft om beslissingen te nemen over hun gegevens. Ze gebruiken het uitgever/consument-model met een gecentraliseerde bestuurslaag die wordt gebruikt om toegangscontroles af te dwingen. Als u geïnteresseerd bent in meer informatie over datamesh-architectuur, gaat u naar Ontwerp een data mesh-architectuur met behulp van AWS Lake Formation en AWS Glue. Met Athena-engine versie 3 kunnen klanten dezelfde fijnmazige controles gebruiken voor open data-frameworks zoals Apache Iceberg, Apache Hudi en Apache Hive.
In dit bericht gaan we dieper in op een use-case waarbij je een producent/consument-model hebt waarbij het delen van gegevens is ingeschakeld om beperkte toegang te geven tot een Apache Iceberg-tabel die de consument kan opvragen. We bespreken kolomfiltering om bepaalde rijen te beperken, filtering om toegang op kolomniveau te beperken, schema-evolutie en tijdreizen.
Overzicht oplossingen
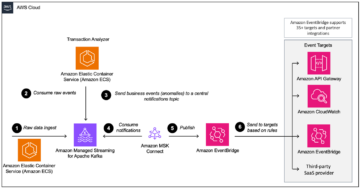
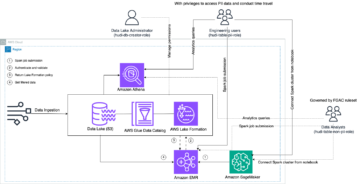
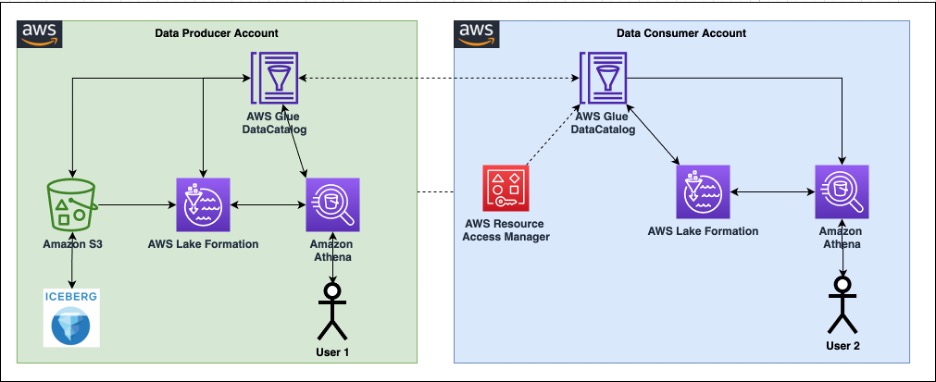
Om de functionaliteit van fijnmazige machtigingen voor Apache Iceberg-tabellen met Athena en Lake Formation te illustreren, hebben we de volgende componenten ingesteld:
- In het producentenaccount:
- An AWS lijm Data Catalog om het schema van een tabel in Apache Iceberg-formaat te registreren
- Lake Formation om fijnmazige toegang tot het consumentenaccount te bieden
- Athena om gegevens van het producentenaccount te verifiëren
- Op de consumentenrekening:
- AWS Resource Access Manager (AWS RAM) om een handdruk te creëren tussen de datacatalogus van de producent en de consument
- Lake Formation om fijnmazige toegang tot het consumentenaccount te bieden
- Athena om gegevens van producentenaccount te verifiëren
Het volgende diagram illustreert de architectuur.
Voorwaarden
Voordat u begint, moet u ervoor zorgen dat u over het volgende beschikt:
Installatie van gegevensproducent
In deze sectie presenteren we de stappen voor het instellen van de gegevensproducent.
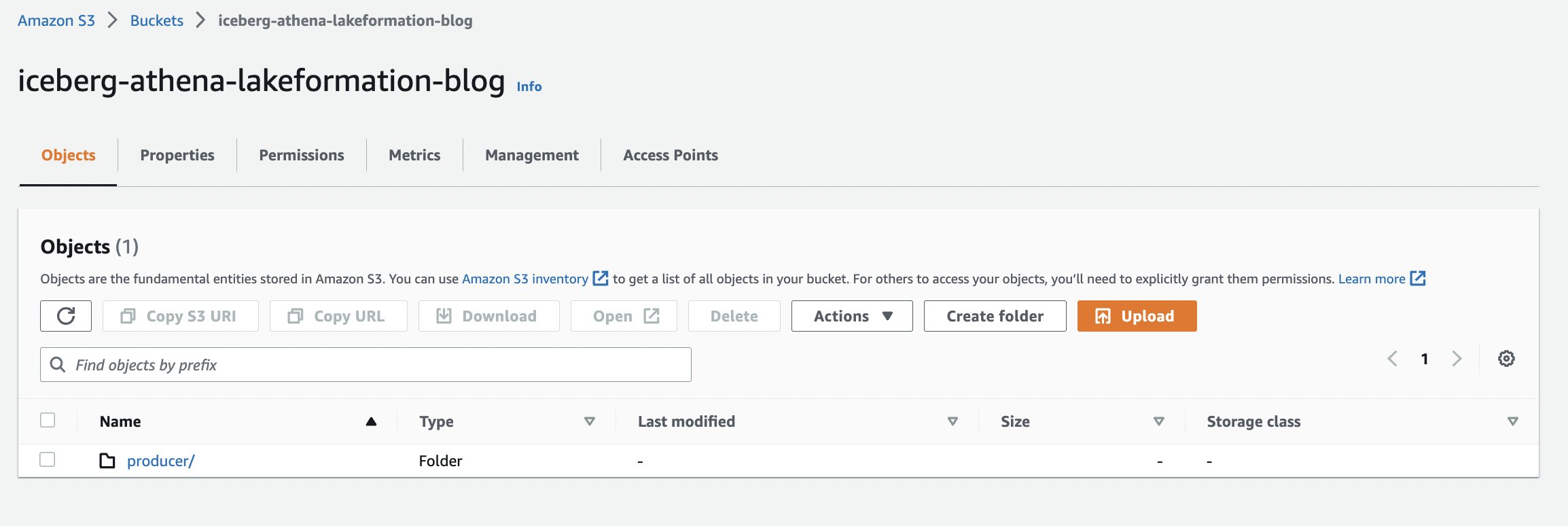
Maak een S3-bucket om de tabelgegevens op te slaan
We maken een nieuwe S3-bucket om de gegevens voor de tabel op te slaan:
- Op de Amazon S3-console, maak een S3-bucket met een unieke naam (voor dit bericht gebruiken we
iceberg-athena-lakeformation-blog). - Maak de producer-map in de bucket om voor de tabel te gebruiken.
Registreer het S3-pad waarin de tabel wordt opgeslagen met behulp van Lake Formation
We registreren het volledige pad van S3 in Lake Formation:
- Navigeer naar de Lake Formation-console.
- Als u zich voor de eerste keer aanmeldt, wordt u gevraagd een beheerder aan te maken.
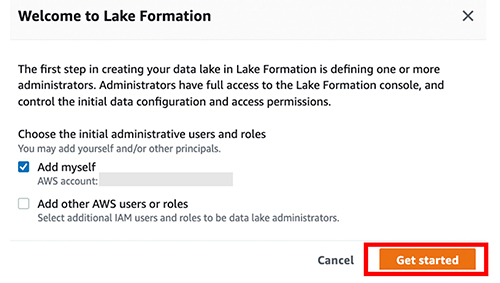
- In het navigatievenster, onder Registreer en neem in, kiezen Data Lake-locaties.
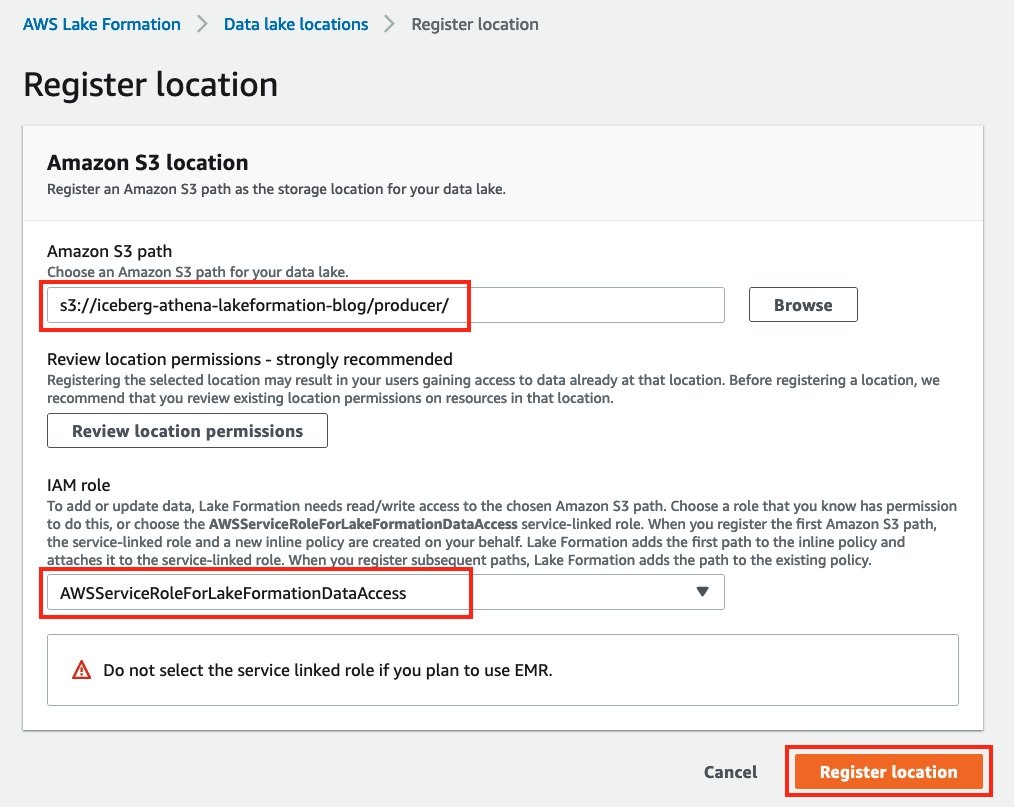
- Kies Registreer locatieen geef het S3-bucketpad op dat u eerder hebt gemaakt.
- Kies
AWSServiceRoleForLakeFormationDataAccessFor IAM-rol.
Voor meer informatie over rollen, zie Vereisten voor rollen die worden gebruikt om locaties te registreren.
Als u codering van uw S3-bucket hebt ingeschakeld, moet u Lake Formation toestemming geven om coderings- en decoderingsbewerkingen uit te voeren. Verwijzen naar Een versleutelde Amazon S3-locatie registreren voor begeleiding.
- Kies Registreer locatie.
Maak een ijsbergtafel met behulp van Athena
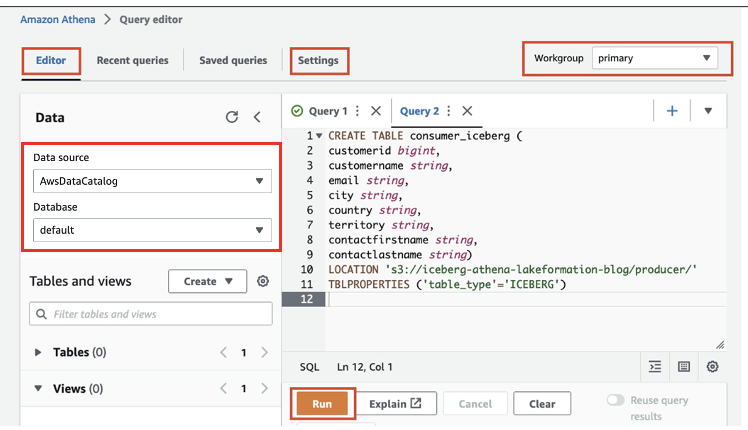
Laten we nu de tabel maken met behulp van Athena ondersteund door Apache Iceberg-indeling:
- Kies op de Athena-console Query-editor in het navigatievenster.
- Als je Athena voor het eerst gebruikt, onder Instellingen, kiezen Beheren en voer de S3-bucketlocatie in die u eerder hebt gemaakt (
iceberg-athena-lakeformation-blog/producer). - Kies Bespaar.
- Voer in de query-editor de volgende query in (vervang de locatie door de S3-bucket die u bij Lake Formation hebt geregistreerd). Merk op dat we de standaarddatabase gebruiken, maar u kunt elke andere database gebruiken.
- Kies lopen.
Deel de tafel met het consumentenaccount
Om de functionaliteit te illustreren, implementeren we de volgende scenario's:
- Geef toegang tot geselecteerde kolommen
- Geef toegang tot geselecteerde rijen op basis van een filter
Voer de volgende stappen uit:
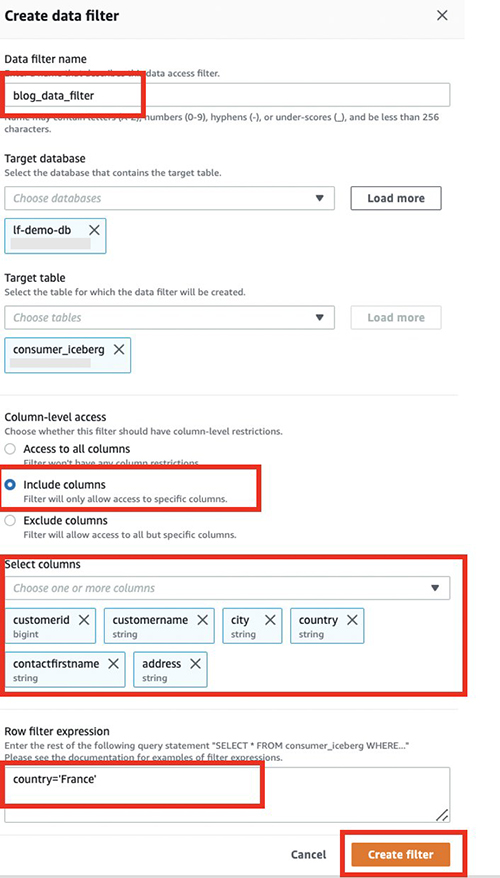
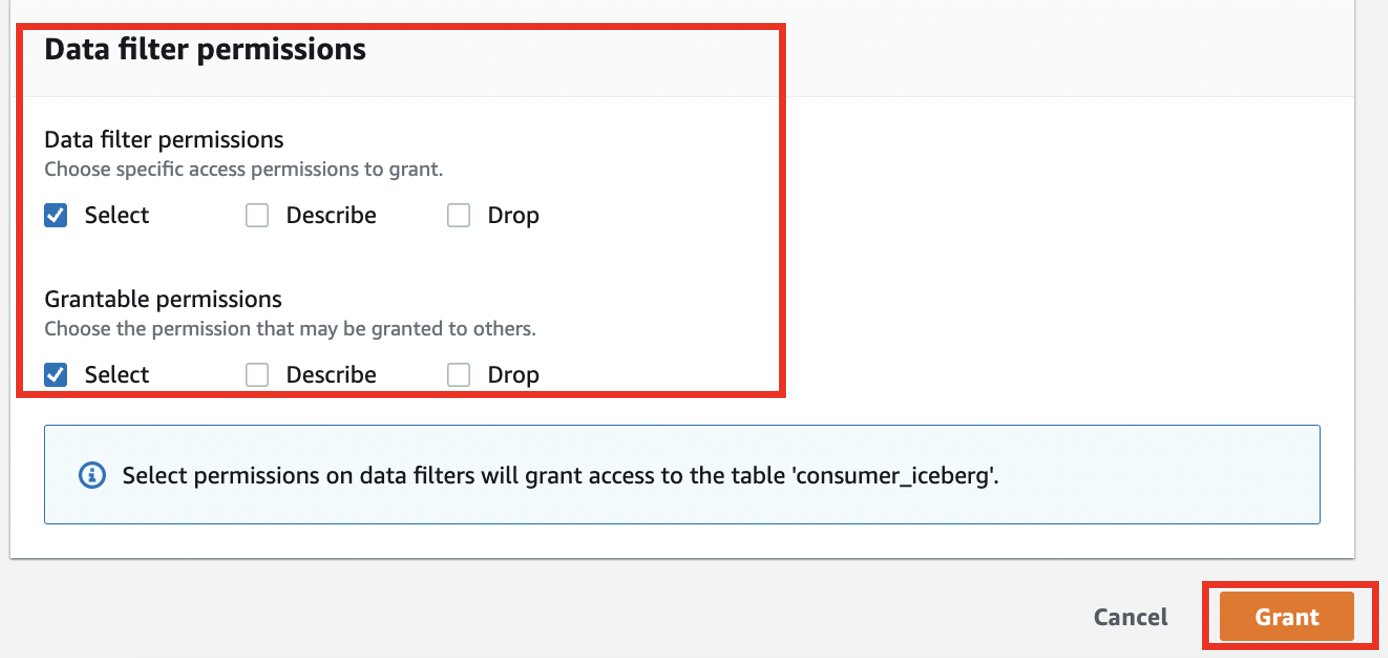
- Op de Lake Formation-console, in het navigatievenster eronder Data catalogus, kiezen Gegevensfilters.
- Kies Nieuw filter maken.
- Voor Naam gegevensfilter, ga naar binnen
blog_data_filter. - Voor Doeldatabase, ga naar binnen
lf-demo-db. - Voor Doeltabel, ga naar binnen
consumer_iceberg. - Voor Toegang op kolomniveauselecteer Voeg kolommen toe.
- Kies de kolommen die u wilt delen met de consument:
country, address, contactfirstname, city, customerid,encustomername. - Voor Uitdrukking rijfilter, voer het filter in
country='France'. - Kies Maak een filter.
Laten we nu toegang verlenen tot het consumentenaccount op de consumer_iceberg tafel.
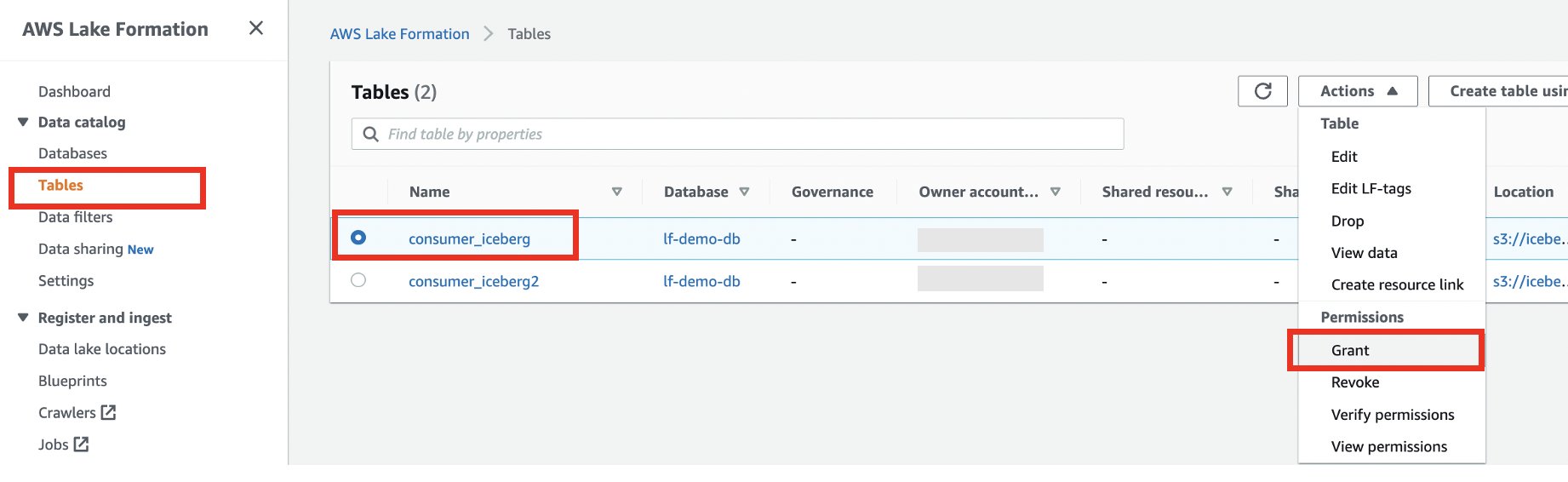
- Kies in het navigatievenster Tafels.
- Selecteer de consumer_iceberg-tabel en kies Grant op de Acties menu.
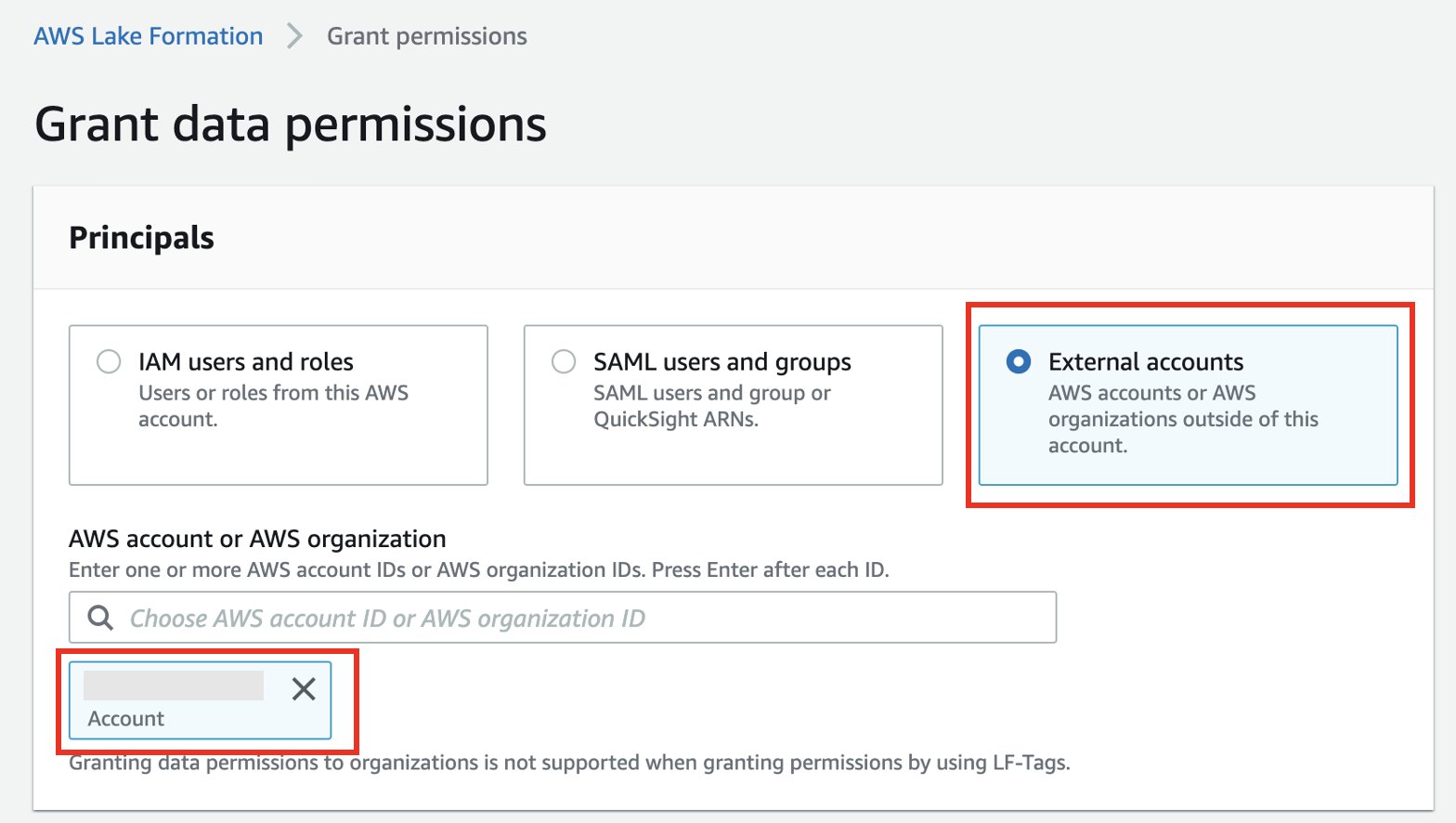
- kies Externe accounts.
- Voer de externe account-ID in.
- kies Benoemde gegevenscatalogusbronnen.
- Kies uw database en tabel.
- Voor Gegevensfilters, kies het gegevensfilter dat u hebt gemaakt.
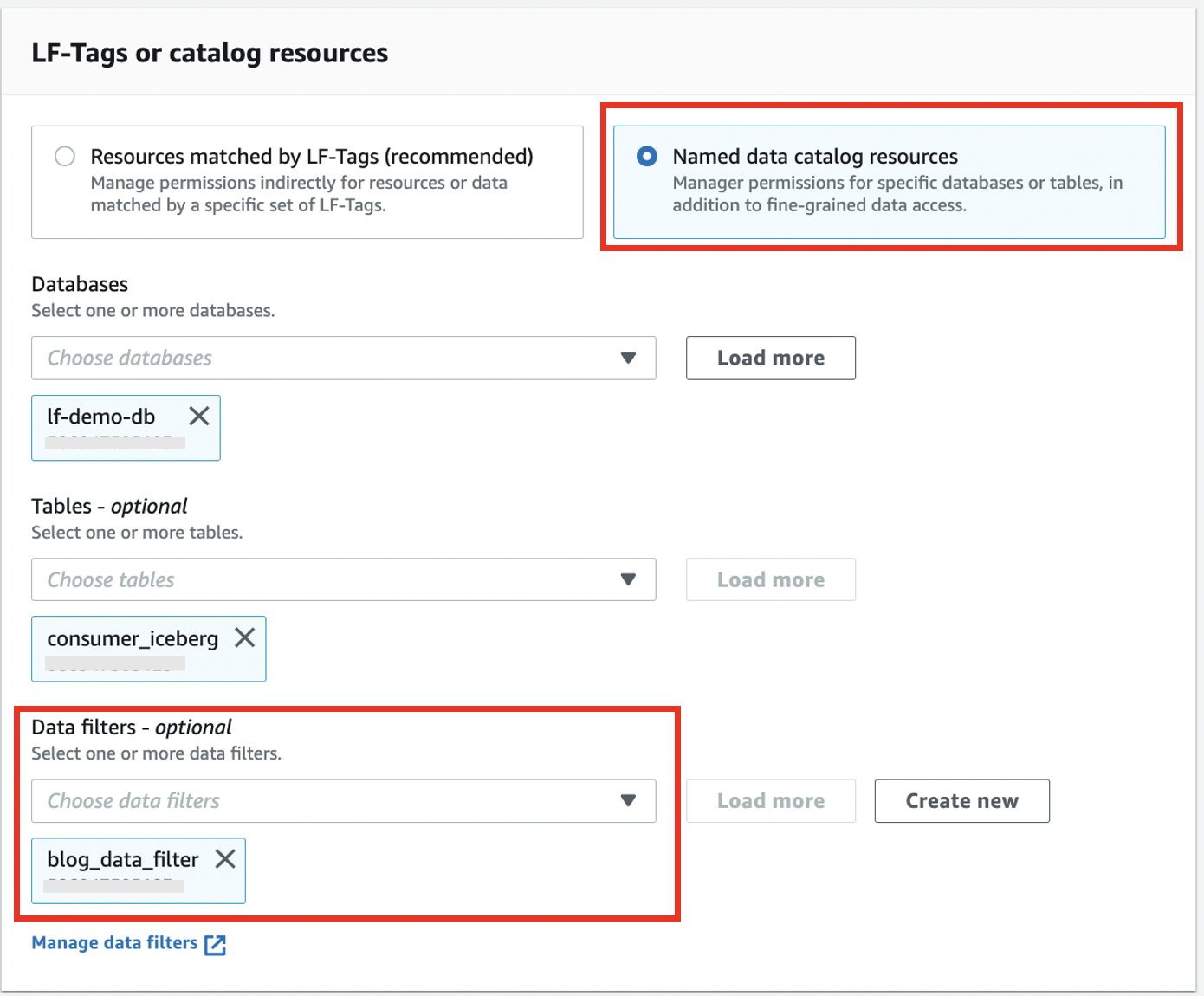
- Voor Gegevensfiltermachtigingen en Verleenbare machtigingenselecteer kies.
- Kies Grant.
Instellingen voor gegevensconsumenten
Om de dataconsument in te stellen, accepteren we de resourceshare en maken we een tabel met behulp van AWS RAM en Lake Formation. Voer de volgende stappen uit:
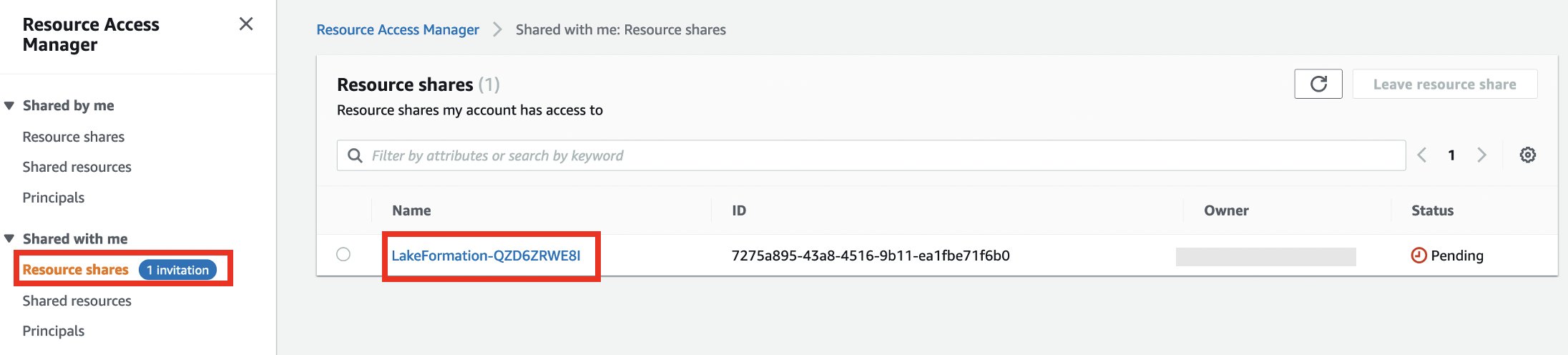
- Log in op het consumentenaccount en navigeer naar de AWS RAM-console.
- Onder Gedeeld met mij in het navigatievenster, kies Resource-aandelen.
- Kies uw resourceshare.
- Kies Accepteer het delen van bronnen.
- Noteer de naam van de bronshare die u in de volgende stappen wilt gebruiken.
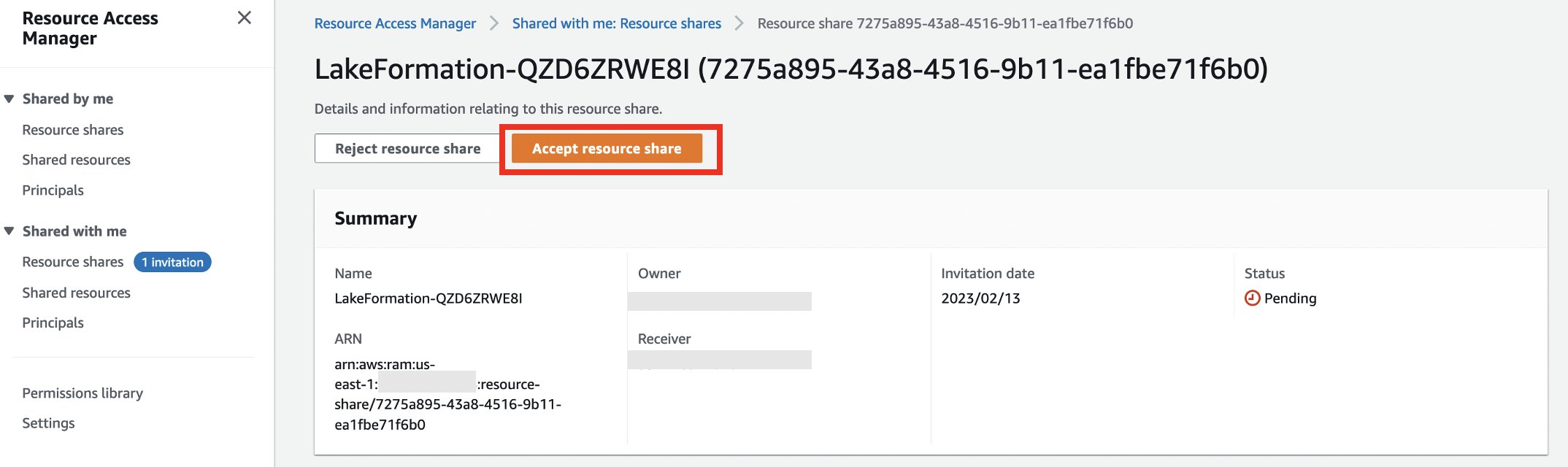
- Navigeer naar de Lake Formation-console.
- Als u zich voor de eerste keer aanmeldt, wordt u gevraagd een beheerder aan te maken.
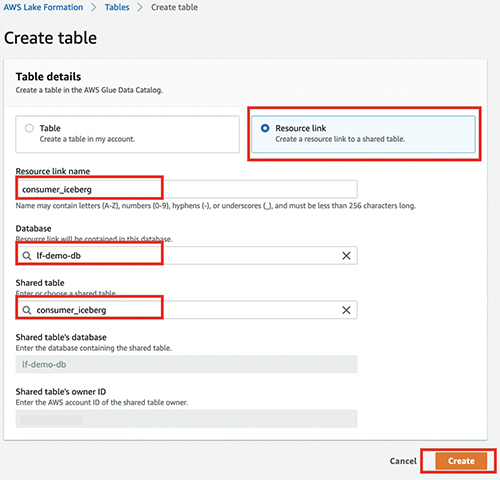
- Kies databases in het navigatievenster en kies vervolgens uw database.
- Op de Acties menu, kies Maak een resourcekoppeling.

- Voor Naam bronlink, voer de naam van uw bronlink in (bijvoorbeeld
consumer_iceberg). - Kies uw database en gedeelde tabel.
- Kies creëren.
Valideer de oplossing
Nu kunnen we verschillende bewerkingen op de tabellen uitvoeren om de fijnmazige toegangscontroles te valideren.
Bewerking invoegen
Laten we gegevens invoegen in de consumer_iceberg tabel in het producentenaccount en controleer of de gegevensfiltering werkt zoals verwacht in het consumentenaccount.
- Log in op het producentenaccount.
- Kies op de Athena-console Query-editor in het navigatievenster.
- Gebruik de volgende SQL om gegevens in de Iceberg-tabel te schrijven en in te voegen. Gebruik de Query-editor om één query tegelijk uit te voeren. U kunt één zoekopdracht per keer markeren/selecteren en klikken op "Uitvoeren"/"Opnieuw uitvoeren:

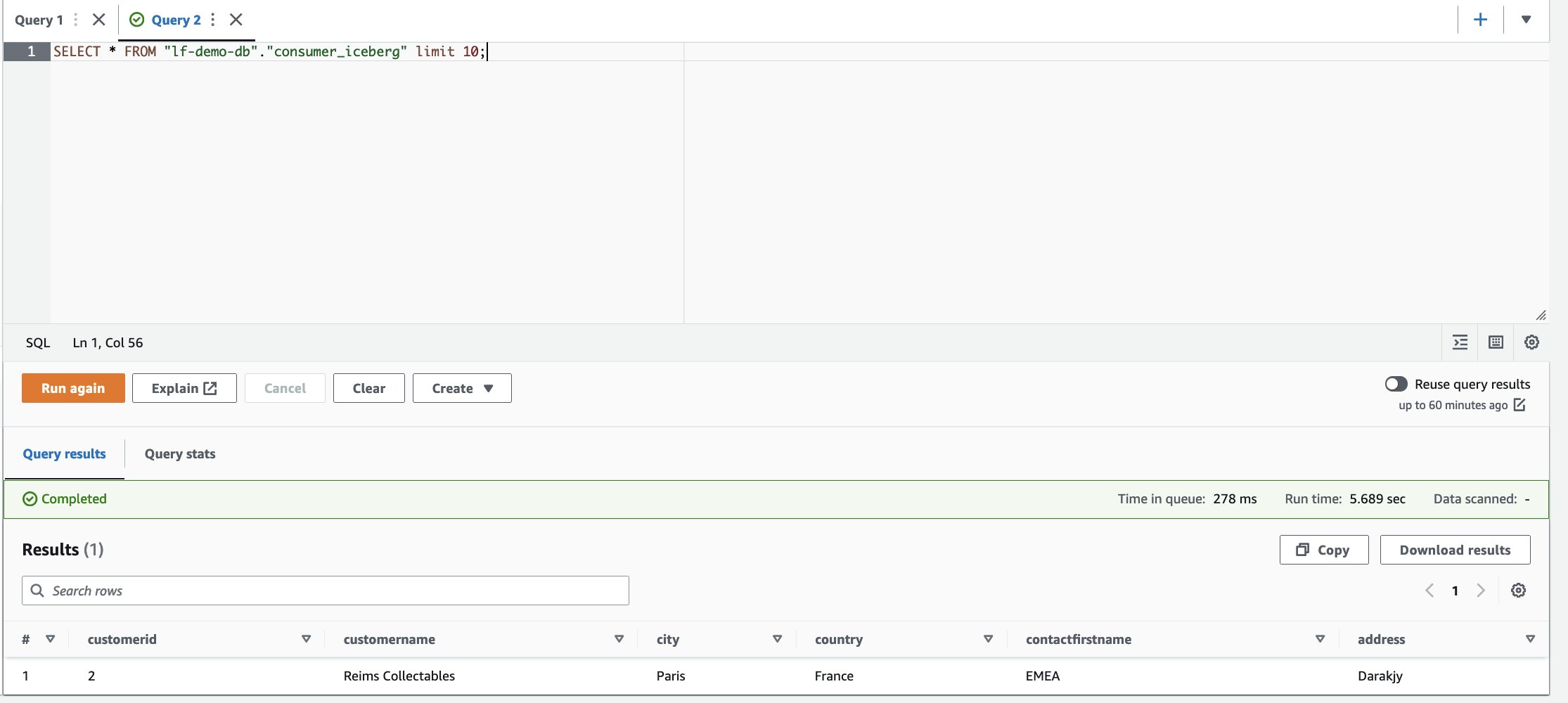
- Gebruik de volgende SQL om gegevens in de Iceberg-tabel te lezen en te selecteren:
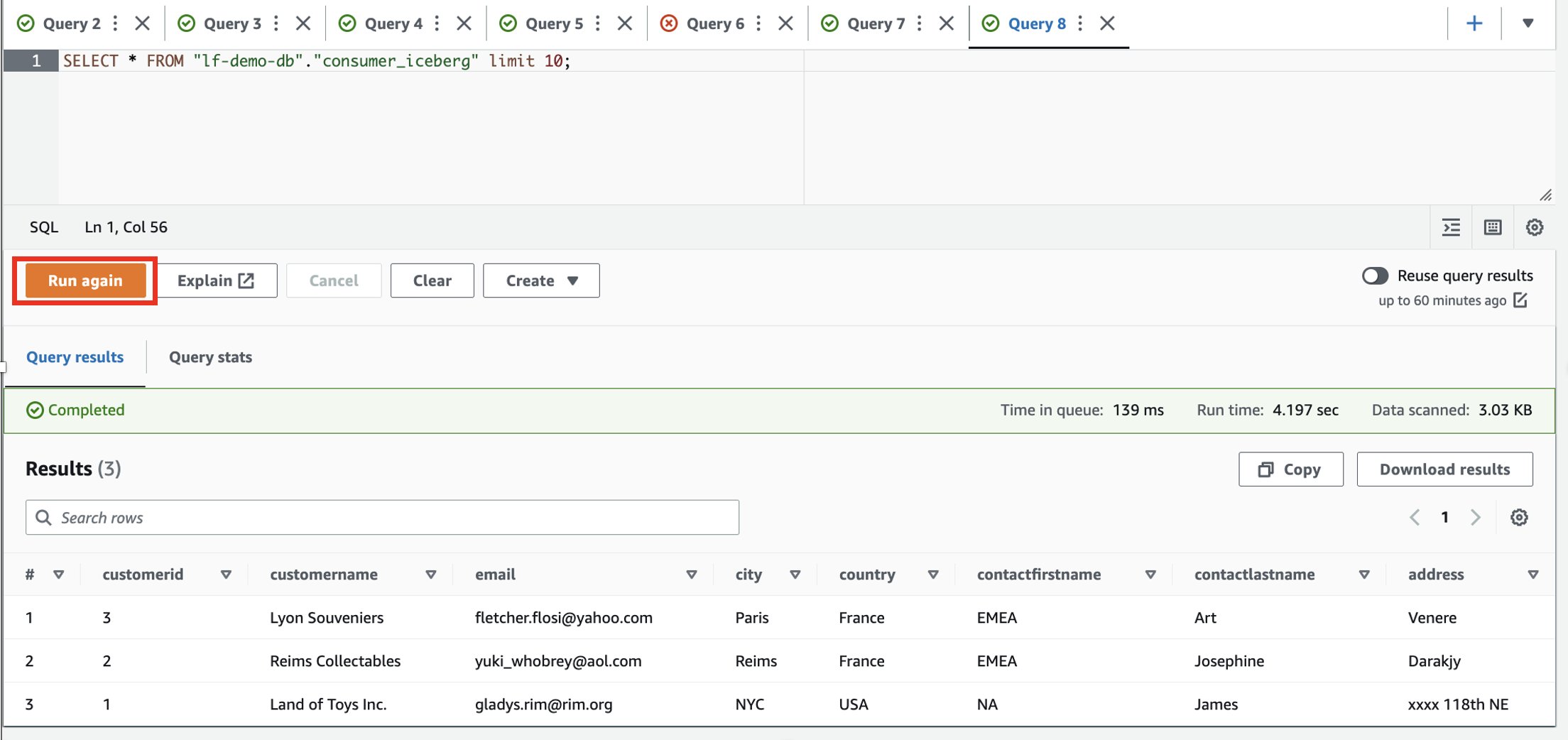
- Log in op het consumentenaccount.
- Voer in de Athena-query-editor de volgende SELECT-query uit op de gedeelde tabel:
Op basis van de filters heeft de consument zicht op een subset van kolommen en rijen waarbij het land Frankrijk is.
Bewerkingen bijwerken/verwijderen
Laten we nu een van de rijen bijwerken en er een verwijderen uit de dataset die met de consument wordt gedeeld.
- Log in op het producentenaccount.
- bijwerken
city='Paris' WHERE city='Reims'en verwijder de rijcustomerid = 3;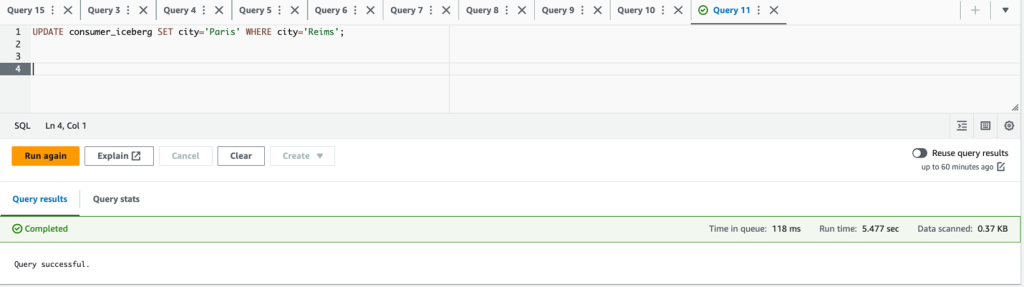

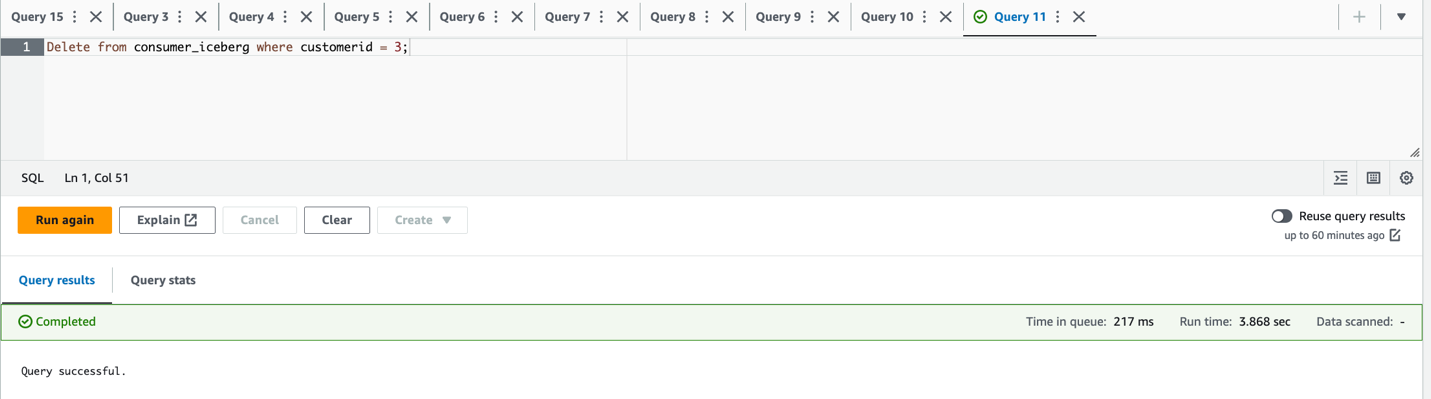
- Controleer de bijgewerkte en verwijderde dataset:
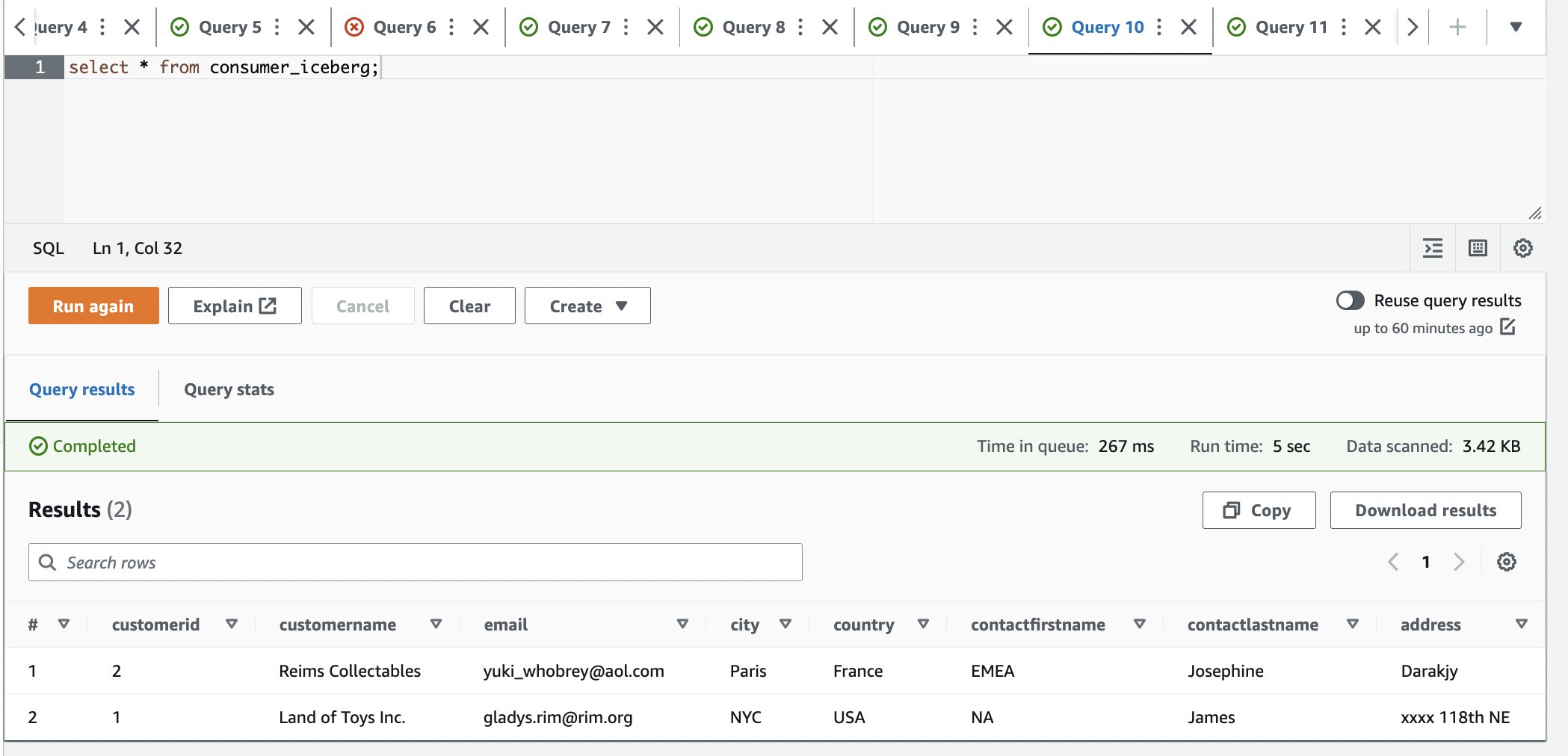
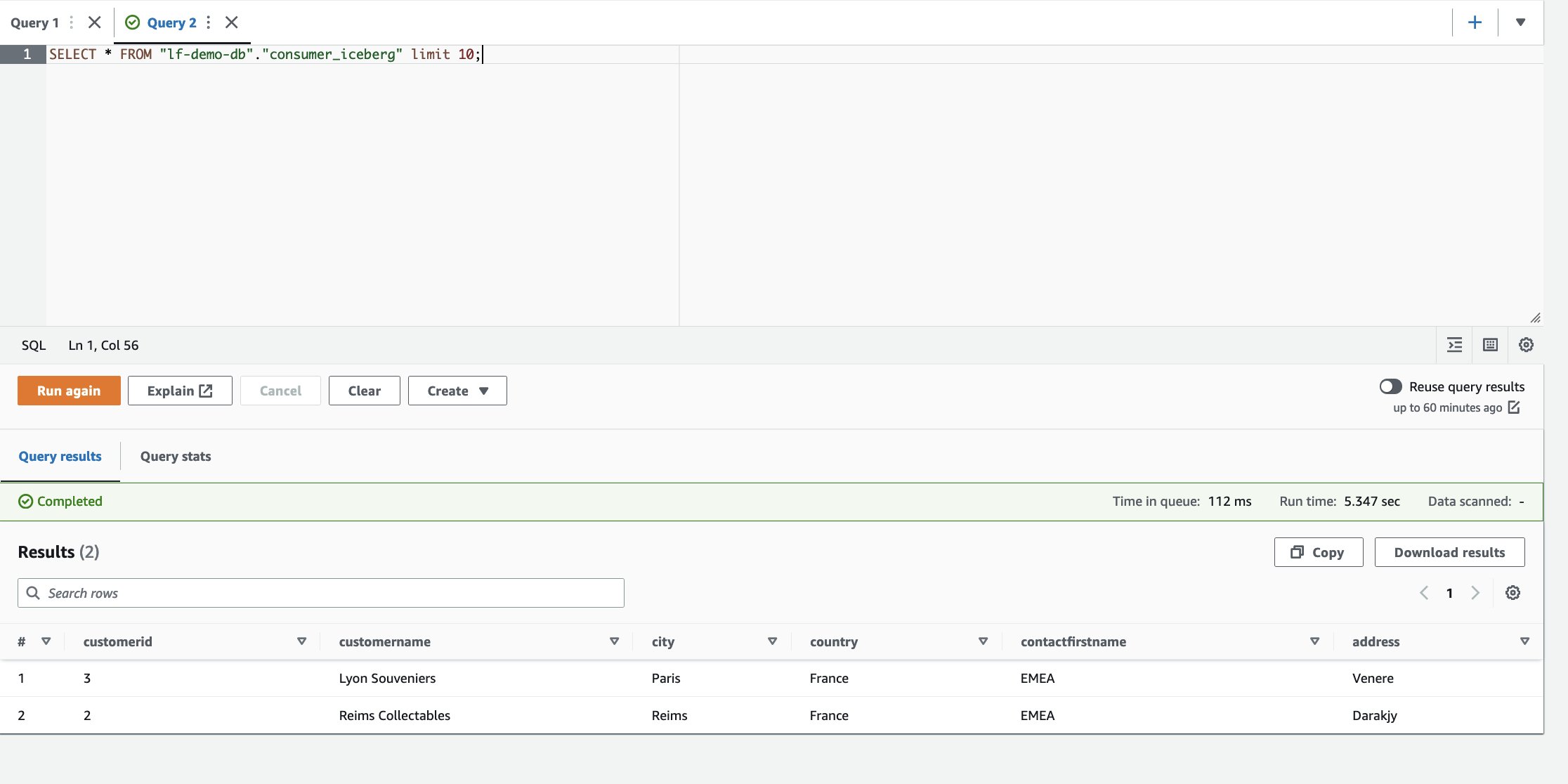
- Log in op het consumentenaccount.
- Voer in de Athena-query-editor de volgende SELECT-query uit op de gedeelde tabel:
We kunnen zien dat er slechts één rij beschikbaar is en dat de stad is bijgewerkt naar Parijs.
Schema evolutie: Voeg een nieuwe kolom toe
Laten we een van de rijen bijwerken en er een verwijderen uit de dataset die met de consument wordt gedeeld.
- Log in op het producentenaccount.
- Voeg een nieuwe kolom toe met de naam
geo_locin de ijsbergtafel. Gebruik de Query-editor om één query tegelijk uit te voeren. U kunt één zoekopdracht per keer markeren/selecteren en klikken op "Uitvoeren"/"Opnieuw uitvoeren:
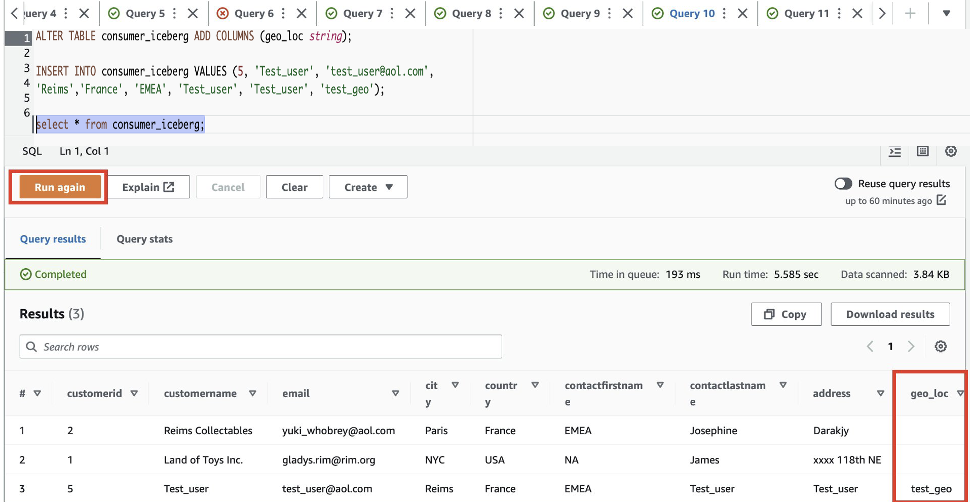
Om zichtbaarheid te geven aan de nieuw toegevoegde geo_loc kolom, moeten we het gegevensfilter van Lake Formation bijwerken.
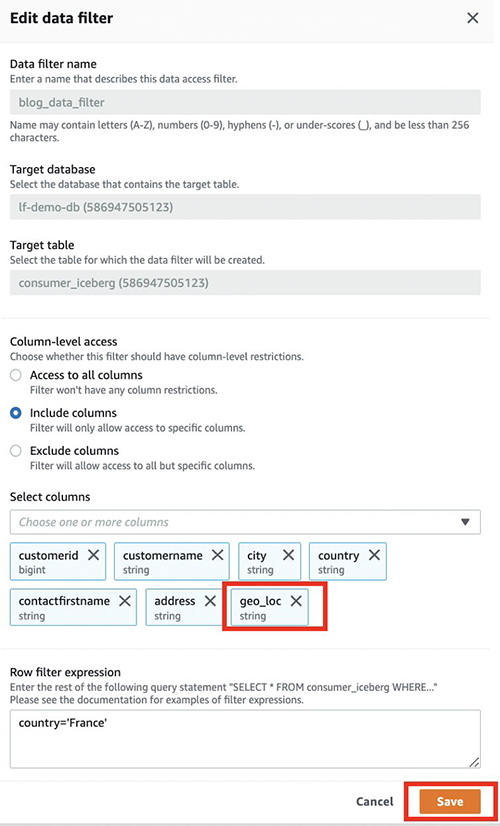
- Kies op de Lake Formation-console Gegevensfilters in het navigatievenster.
- Selecteer uw gegevensfilter en kies Edit.

- Onder Toegang op kolomniveau, voeg de nieuwe kolom toe (
geo_loc). - Kies Bespaar.
- Log in op het consumentenaccount.
- Voer het volgende uit in de Athena-query-editor
SELECTquery op de gedeelde tafel:
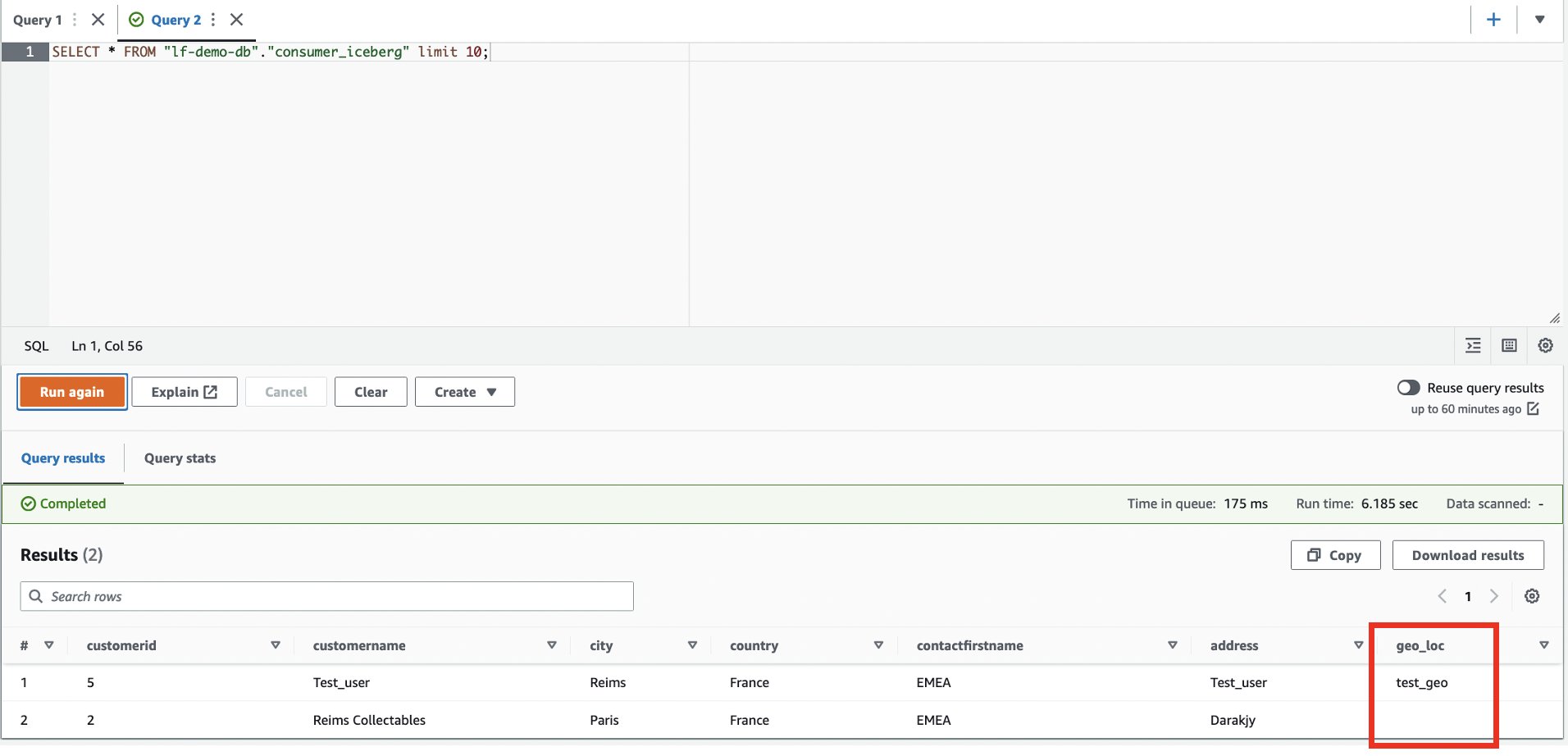
De nieuwe kolom geo_loc zichtbaar is en een extra rij.
Schema-evolutie: kolom verwijderen
Laten we een van de rijen bijwerken en er een verwijderen uit de dataset die met de consument wordt gedeeld.
- Log in op het producentenaccount.
- Pas de tabel aan om de adreskolom uit de Iceberg-tabel te verwijderen. Gebruik de Query-editor om één query tegelijk uit te voeren. U kunt één zoekopdracht per keer markeren/selecteren en klikken op "Uitvoeren"/"Opnieuw uitvoeren:

We kunnen zien dat het kolomadres niet aanwezig is in de tabel.
- Log in op het consumentenaccount.
- Voer in de Athena-query-editor de volgende SELECT-query uit op de gedeelde tabel:
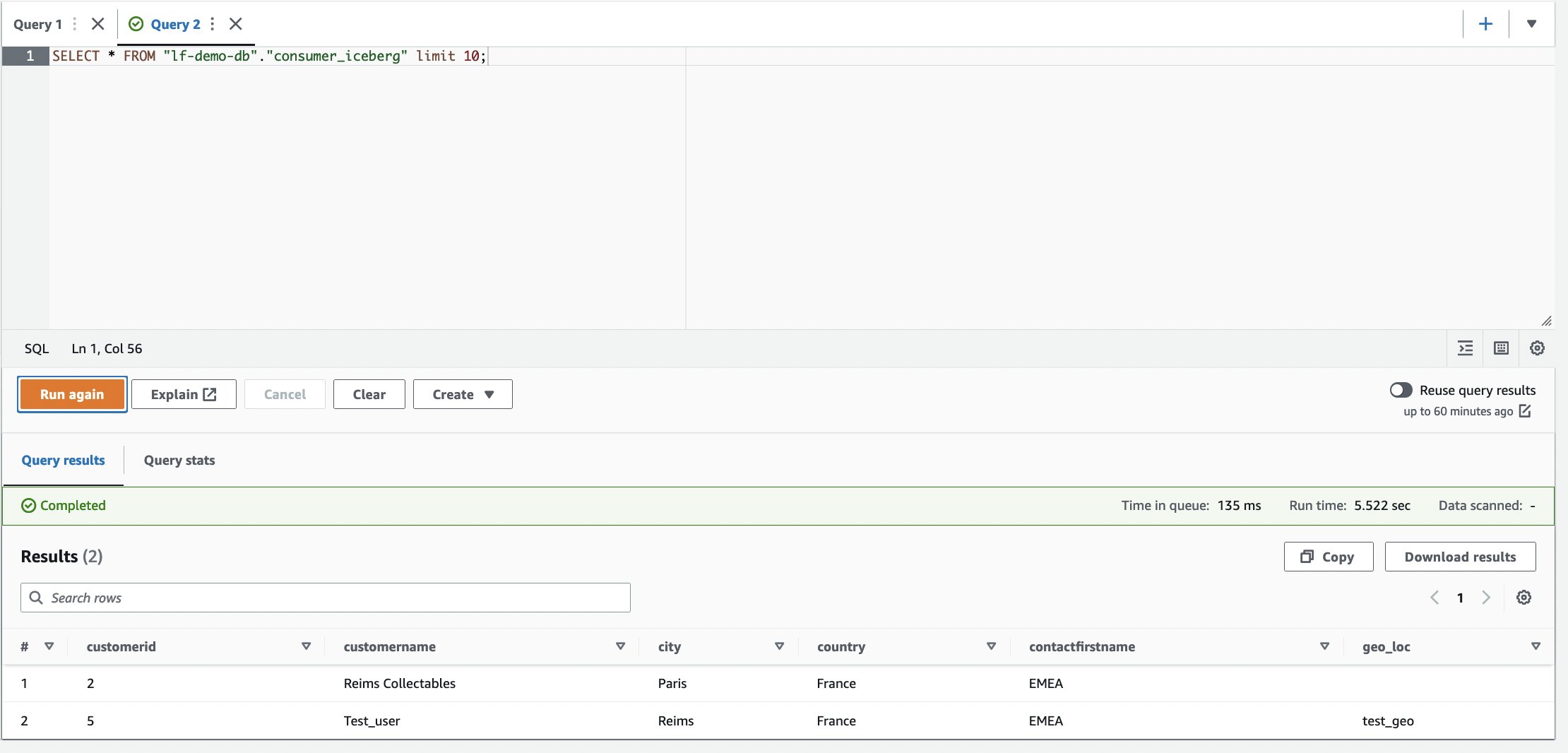
Het kolomadres is niet aanwezig in de tabel.
Tijdreizen
We hebben de Iceberg-tafel nu meerdere keren veranderd. De Iceberg table houdt de snapshots bij. Voer de volgende stappen uit om de functionaliteit voor tijdreizen te verkennen:
- Log in op het producentenaccount.
- Vraag de systeemtabel op:
We kunnen zien dat we meerdere snapshots hebben gegenereerd.
- Noteer een van de
committed_atwaarden die in de volgende stappen moeten worden gebruikt (voor dit voorbeeld2023-01-29 21:35:02.176 UTC).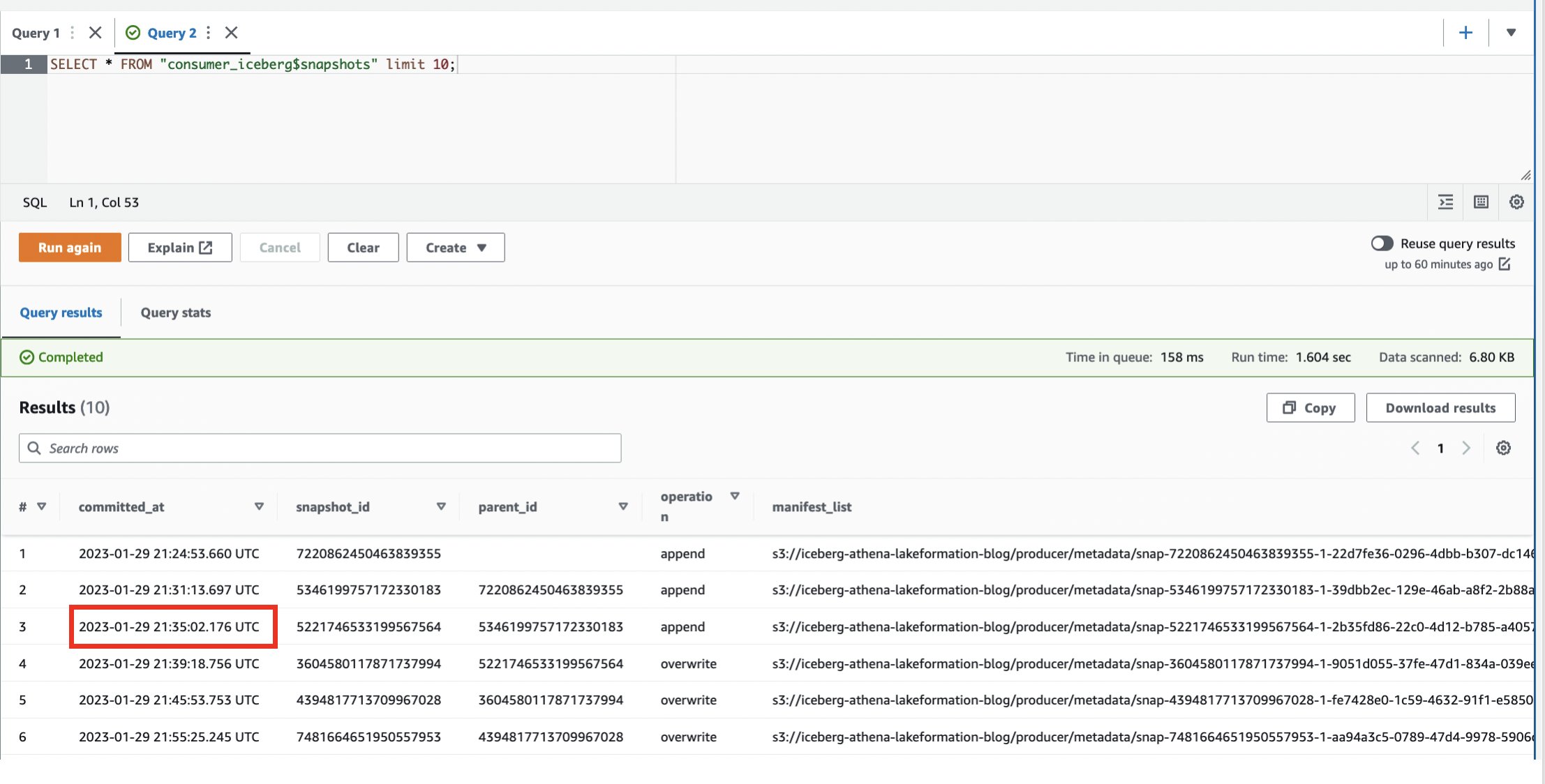
- Gebruik tijdreizen om de momentopname van de tabel te vinden. Gebruik de Query-editor om één query tegelijk uit te voeren. U kunt één zoekopdracht per keer markeren/selecteren en klikken op "Uitvoeren"/"Opnieuw uitvoeren:
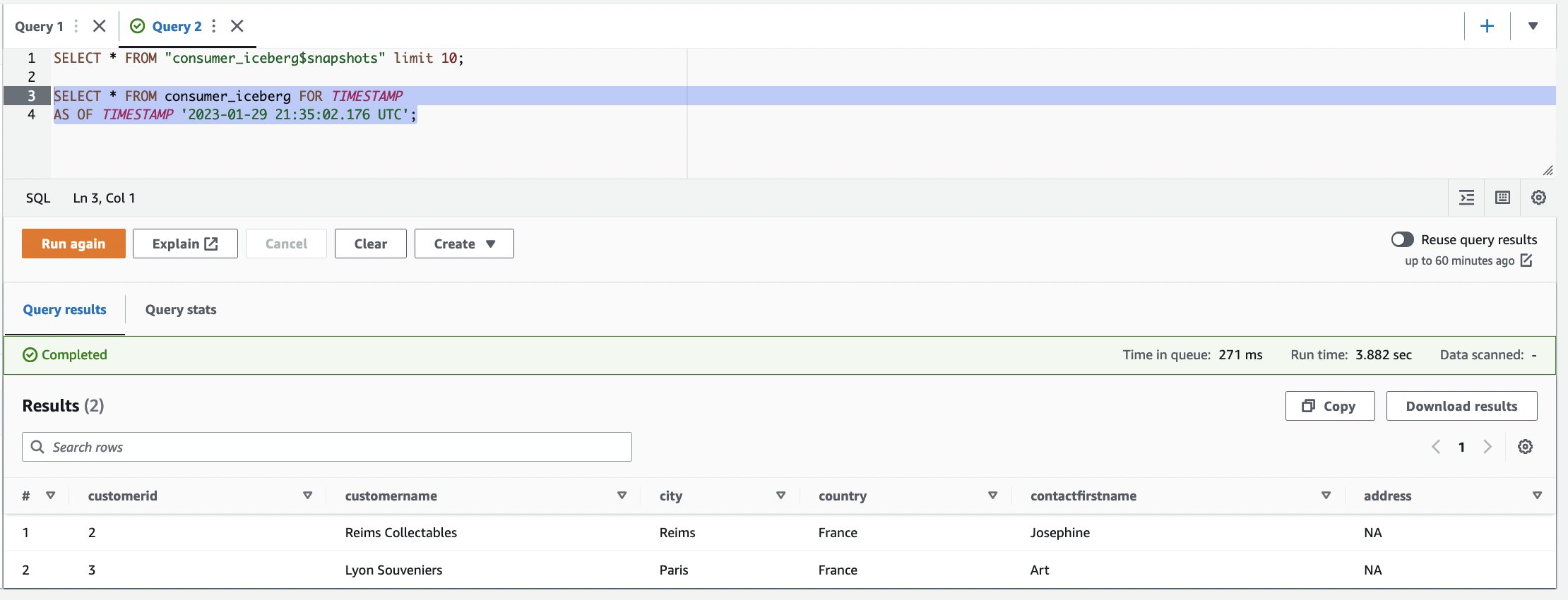
Opruimen
Voer de volgende stappen uit om toekomstige kosten te voorkomen:
- Verwijder op de Amazon S3-console de tabelopslagbucket (voor dit bericht, iceberg-athena-lakeformation-blog).
- Voer in het producentenaccount op de Athena-console de volgende opdrachten uit om de tabellen die u hebt gemaakt te verwijderen:
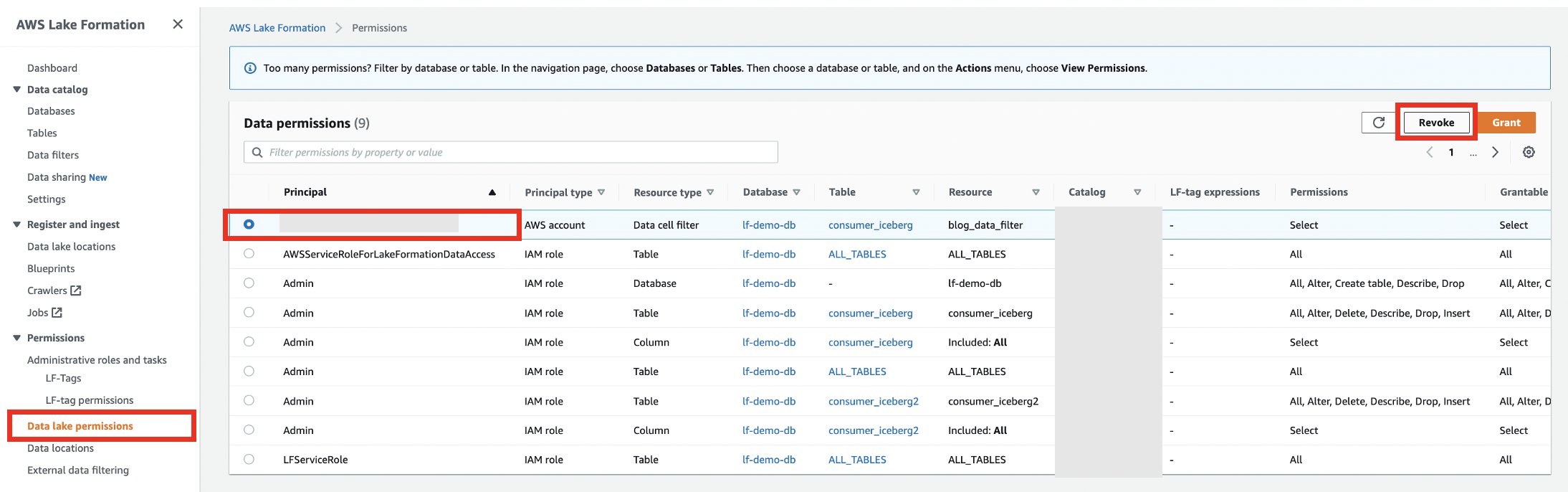
- Trek in het producentenaccount op de Lake Formation-console de machtigingen voor het consumentenaccount in.
- Verwijder de S3-bucket die wordt gebruikt voor de locatie van het Athena-queryresultaat uit het consumentenaccount.
Conclusie
Met de ondersteuning voor cross-account, fijnmazig toegangscontrolebeleid voor formaten zoals Iceberg, heb je de flexibiliteit om met elk formaat te werken dat door Athena wordt ondersteund. De mogelijkheid om CRUD-bewerkingen uit te voeren op de gegevens in uw S3-datalake in combinatie met Lake Formation fijnmazige toegangscontroles voor alle tabellen en formaten die door Athena worden ondersteund, biedt mogelijkheden om uw datastrategie te innoveren en te vereenvoudigen. We horen graag uw feedback!
Over de auteurs
 Kishore Dhamodaran is Senior Solutions Architect bij AWS. Kishore helpt strategische klanten met hun cloud enterprise-strategie en migratietraject, gebruikmakend van zijn jarenlange ervaring in de industrie en cloud.
Kishore Dhamodaran is Senior Solutions Architect bij AWS. Kishore helpt strategische klanten met hun cloud enterprise-strategie en migratietraject, gebruikmakend van zijn jarenlange ervaring in de industrie en cloud.
 Jack Gij is een software-engineer van het Athena Data Lake- en Storage-team bij AWS. Hij is een Apache Iceberg Committer en PMC-lid.
Jack Gij is een software-engineer van het Athena Data Lake- en Storage-team bij AWS. Hij is een Apache Iceberg Committer en PMC-lid.
 Chris Olson is Software Development Engineer bij AWS.
Chris Olson is Software Development Engineer bij AWS.
 Xiaoxuan Li is Software Development Engineer bij AWS.
Xiaoxuan Li is Software Development Engineer bij AWS.
 Rahul Sonawane is een Principal Analytics Solutions Architect bij AWS met AI/ML en Analytics als zijn specialiteit.
Rahul Sonawane is een Principal Analytics Solutions Architect bij AWS met AI/ML en Analytics als zijn specialiteit.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/interact-with-apache-iceberg-tables-using-amazon-athena-and-cross-account-fine-grained-permissions-using-aws-lake-formation/
- :is
- $UP
- 1
- 10
- 100
- 7
- a
- vermogen
- Over
- ACCEPTEREN
- toegang
- Account
- over
- toegevoegd
- Extra
- Extra informatie
- adres
- beheerder
- aangenomen
- tegen
- AI / ML
- Alles
- toestaat
- Amazone
- Amazone Athene
- analytics
- en
- apache
- architectuur
- ZIJN
- GEBIED
- Kunst
- AS
- At
- machtiging
- Beschikbaar
- vermijd
- AWS
- AWS Lake-formatie
- met een rug
- gebaseerde
- tussen
- bedrijfsdeskundigen
- ondernemingen
- by
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- CAN
- catalogus
- gecentraliseerde
- zeker
- verandering
- lasten
- Kies
- Plaats
- Klik
- Cloud
- Kolom
- columns
- COM
- gecombineerde
- compleet
- componenten
- troosten
- consument
- onder controle te houden
- controles
- Land
- en je merk te creëren
- aangemaakt
- Wij creëren
- het aanmaken
- Cross
- Klanten
- gegevens
- Datameer
- het delen van gegevens
- gegevensstrategie
- Database
- beslissingen
- deep
- diepe duik
- Standaard
- Ontwikkeling
- anders
- bespreken
- beneden
- Val
- elk
- Vroeger
- editor
- EMEA
- ingeschakeld
- versleutelde
- encryptie
- Motor
- ingenieur
- Enter
- Enterprise
- Ether (ETH)
- Evolutie
- voorbeeld
- verwacht
- ervaring
- Verken
- extern
- Dien in
- filter
- filtering
- filters
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- eerste keer
- Flexibiliteit
- volgend
- Voor
- formaat
- vorming
- frameworks
- Frankrijk
- oppompen van
- vol
- functionaliteit
- toekomst
- gegenereerde
- krijgen
- Geven
- bestuur
- toe te kennen
- leiding
- Hebben
- met
- horen
- helpt
- Bijenkorf
- HTML
- http
- HTTPS
- ID
- uitvoeren
- in
- Inc
- -industrie
- informatie
- innoveren
- interactie
- geïnteresseerd
- IT
- jpg
- meer
- Land
- lagen
- leren
- Niveau
- leveraging
- LIMIT
- lijnen
- LINK
- plaats
- liefde
- Lyon
- maken
- MERKEN
- beheren
- lid
- Menu
- migratie
- model
- meer
- meervoudig
- naam
- OP DEZE WEBSITE VIND JE
- Navigatie
- Noodzaak
- New
- volgende
- NYC
- waarnemen
- of
- on
- EEN
- open
- open data
- besturen
- Operations
- Kansen
- organisaties
- Overige
- brood
- Parijs
- pad
- uitvoeren
- permissies
- Plato
- Plato gegevensintelligentie
- PlatoData
- beleidsmaatregelen door te lezen.
- Post
- presenteren
- Principal
- producent
- zorgen voor
- biedt
- RAM
- Lees
- onlangs
- weerspiegeld
- registreren
- geregistreerd
- vervangen
- vereist
- hulpbron
- beperken
- begrensd
- resultaat
- Rol
- rollen
- RIJ
- lopen
- dezelfde
- Bespaar
- scenario's
- sectie
- gekozen
- senior
- reeks
- Delen
- gedeeld
- delen
- vereenvoudigen
- Momentopname
- Software
- software development
- Software Engineer
- Oplossingen
- Specialiteit
- SQL
- gestart
- Stappen
- mediaopslag
- shop
- opgeslagen
- strategisch
- Strategie
- Draad
- dergelijk
- ondersteuning
- ondersteunde
- system
- tafel
- team
- dat
- De
- hun
- Deze
- niet de tijd of
- Tijdreizen
- keer
- tijdstempel
- naar
- spoor
- reizen
- voor
- unieke
- bijwerken
- bijgewerkt
- upgrade
- USA
- .
- Gebruiker
- GMT
- BEVESTIG
- Values
- controleren
- versie
- zichtbaarheid
- zichtbaar
- Bezoek
- Met
- Mijn werk
- Bedrijven
- schrijven
- jaar
- Your
- zephyrnet