Multi-label NLP verwijst naar de taak om meerdere labels toe te wijzen aan een bepaalde tekstinvoer, in plaats van slechts één label. Bij traditionele NLP-taken, zoals tekstclassificatie of sentimentanalyse, krijgt elke invoer doorgaans een enkel label toegewezen op basis van de inhoud ervan. In veel real-world scenario's kan een stuk tekst echter tot meerdere categorieën behoren of meerdere gevoelens tegelijkertijd uitdrukken.
Multi-label NLP is belangrijk omdat het ons in staat stelt om meer genuanceerde en complexere informatie uit tekstgegevens vast te leggen. Op het gebied van klantfeedbackanalyse kan een klantrecensie bijvoorbeeld zowel positieve als negatieve sentimenten tegelijkertijd uiten, of het kan meerdere aspecten van een product of dienst raken. Door meerdere labels toe te wijzen aan dergelijke invoer, kunnen we een beter begrip krijgen van de feedback van de klant en meer gerichte acties ondernemen om hun zorgen weg te nemen.
Dit artikel gaat in op een opmerkelijk geval van Provectus' gebruik van multi-label NLP.
Achtergrond:
Een klant benaderde ons met het verzoek hen te helpen automatiseer het labelen van documenten van een bepaald type. Op het eerste gezicht leek de taak eenvoudig en gemakkelijk op te lossen. Terwijl we aan de case werkten, kwamen we echter een dataset tegen met inconsistente annotaties. Hoewel onze klant in de loop van de tijd voor uitdagingen stond met variërende klasnummers en veranderingen in hun beoordelingsteam, hadden ze veel moeite gestoken in het creëren van een diverse dataset met een reeks annotaties. Hoewel er enkele onevenwichtigheden en onzekerheden in de labels bestonden, bood deze dataset een waardevolle gelegenheid voor analyse en verder onderzoek.
Laten we de dataset eens nader bekijken, de statistieken en onze aanpak verkennen en samenvatten hoe Provectus het probleem van tekstclassificatie met meerdere labels oploste.
De dataset heeft 14,354 waarnemingen, met 124 unieke klassen (labels). Onze taak is om aan elke waarneming een of meerdere klassen toe te kennen.
Tabel 1 geeft beschrijvende statistieken voor de dataset.
Gemiddeld hebben we ongeveer twee klassen per waarneming, met gemiddeld 261 verschillende teksten die één klasse beschrijven.

Tabel 1: gegevenssetstatistieken
In figuur 1 zien we de verdeling van klassen in de bovenste grafiek en we hebben een bepaald aantal HEAD-labels met de hoogste frequentie van voorkomen in de dataset. Merk ook op dat de meeste klassen een lage frequentie van voorkomen hebben.
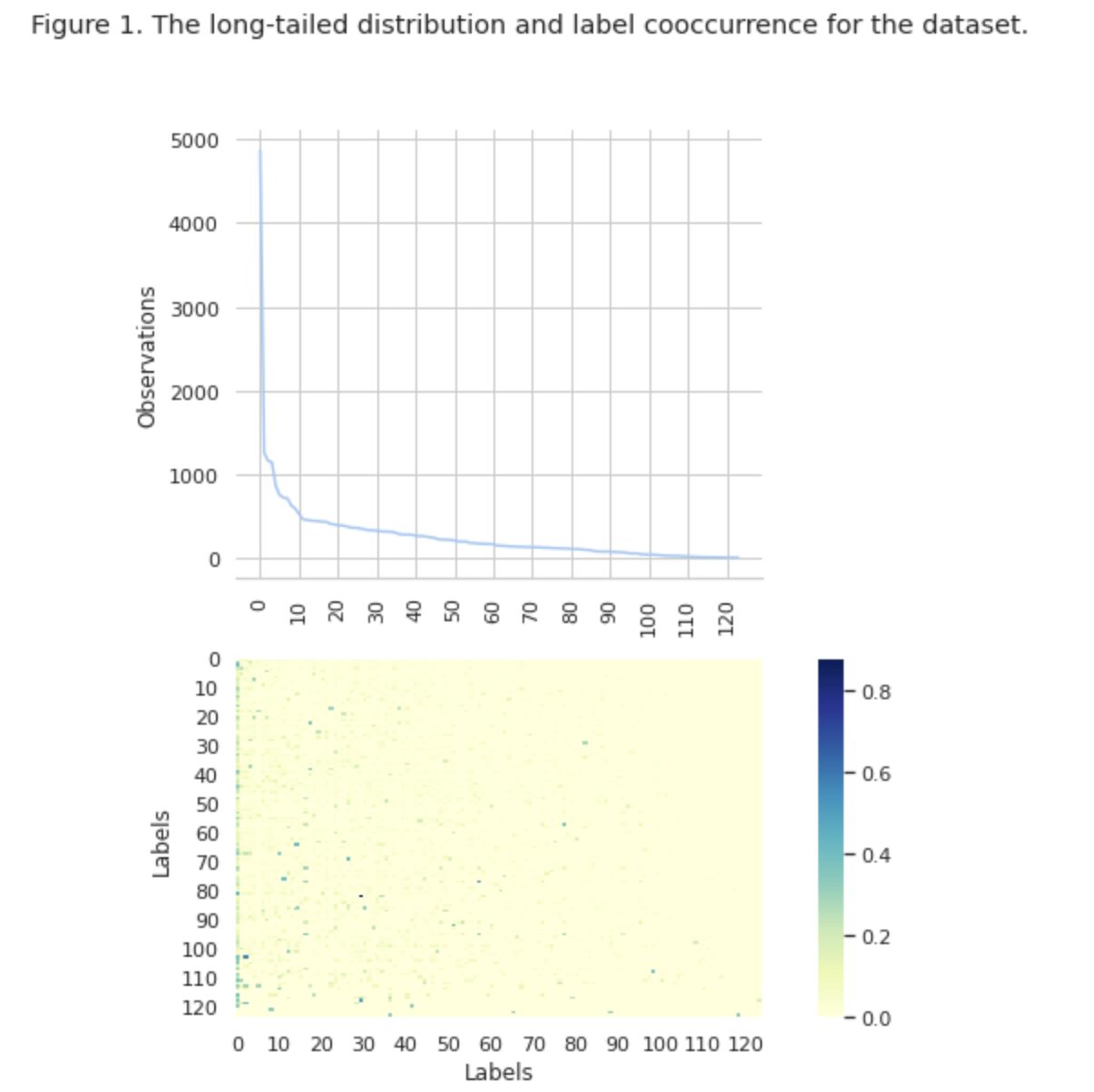
In de onderste grafiek zien we dat er vaak overlap is tussen de klassen die het best in de dataset worden weergegeven, en de klassen die een lage significantie hebben.
We hebben het proces van het splitsen van de dataset in trein/val/testsets gewijzigd. In plaats van een traditionele methode te gebruiken, hebben we iteratieve stratificatie gebruikt om een evenwichtige verdeling van bewijs van labelrelaties te bieden. Daarvoor gebruikten we Scikit Multi-leren
from skmultilearn.model_selection import iterative_train_test_split mlb = MultiLabelBinarizer() def balanced_split(df, mlb, test_size=0.5): ind = np.expand_dims(np.arange(len(df)), axis=1) mlb.fit_transform(df["tag"]) labels = mlb.transform(df["tag"]) ind_train, _, ind_test, _ = iterative_train_test_split( ind, labels, test_size ) return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]] df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
We hebben de volgende verdeling verkregen:
- De trainingsgegevensset bevat 60% van de gegevens en omvat alle 124 labels
- De validatiedataset bevat 20% van de gegevens en omvat alle 124 labels
- De testdataset bevat 20% van de data en omvat alle 124 labels
Multi-label classificatie is een type algoritme voor machinaal leren onder toezicht waarmee we meerdere labels kunnen toewijzen aan een enkel gegevensmonster. Het verschilt van binaire classificatie waarbij het model slechts twee categorieën voorspelt, en multi-class classificatie waarbij het model slechts één van de meerdere klassen voor een steekproef voorspelt.
Evaluatiestatistieken voor classificatieprestaties met meerdere labels zijn inherent verschillend van die welke worden gebruikt in classificatie met meerdere klassen (of binaire classificatie) vanwege de inherente verschillen van het classificatieprobleem. Meer gedetailleerde informatie is te vinden op Wikipedia.
We hebben statistieken geselecteerd die het meest geschikt zijn voor ons:
- precisie meet het aandeel van echt positieve voorspellingen onder de totale positieve voorspellingen van het model.
- Terugroepen meet het aandeel van echt positieve voorspellingen onder alle daadwerkelijk positieve steekproeven.
- F1-score is het harmonische gemiddelde van precisie en herinnering, dat helpt om de balans tussen de twee te herstellen.
- Hamming verlies is de fractie labels die onjuist wordt voorspeld
Wij volgen ook het aantal voorspelde labels in de set {gedefinieerd als telling voor labels, waarvoor we een F1-score > 0 behalen}.
Multi-label classificatie is een type leerprobleem onder toezicht waarbij een enkele instantie of voorbeeld kan worden geassocieerd met meerdere labels of classificaties, in tegenstelling tot de traditionele classificatie met één label, waarbij elke instantie slechts wordt geassocieerd met een enkel klasselabel.
Om classificatieproblemen met meerdere labels op te lossen, zijn er twee hoofdcategorieën technieken:
- Methoden voor probleemtransformatie
- Algoritme aanpassingsmethoden
Methoden voor probleemtransformatie stellen ons in staat om classificatietaken met meerdere labels om te zetten in meerdere classificatietaken met één label. De basislijnbenadering van Binary Relevance (BR) behandelt bijvoorbeeld elk label als een afzonderlijk binair classificatieprobleem. In dit geval wordt het multi-label probleem omgezet in meerdere enkel-label problemen.
Algoritme-aanpassingsmethoden passen de algoritmen zelf aan om gegevens met meerdere labels native te verwerken, zonder de taak om te zetten in meerdere classificatietaken met één label. Een voorbeeld van deze aanpak is het BERT-model, een vooraf getraind, op transformator gebaseerd taalmodel dat kan worden verfijnd voor verschillende NLP-taken, waaronder tekstclassificatie met meerdere labels. BERT is ontworpen om gegevens met meerdere labels rechtstreeks te verwerken, zonder dat er een probleemtransformatie nodig is.
In de context van het gebruik van BERT voor tekstclassificatie met meerdere labels, is de standaardbenadering het gebruik van Binary Cross-Entropy (BCE)-verlies als de verliesfunctie. BCE-verlies is een veelgebruikte verliesfunctie voor binaire classificatieproblemen en kan eenvoudig worden uitgebreid om classificatieproblemen met meerdere labels aan te pakken door het verlies voor elk label afzonderlijk te berekenen en vervolgens de verliezen op te tellen. In dit geval meet de BCE-verliesfunctie de fout tussen voorspelde kansen en echte labels, waarbij voorspelde kansen worden verkregen uit de laatste sigmoïde-activeringslaag in het BERT-model.
Laten we nu eens nader kijken naar figuur 2 hieronder.
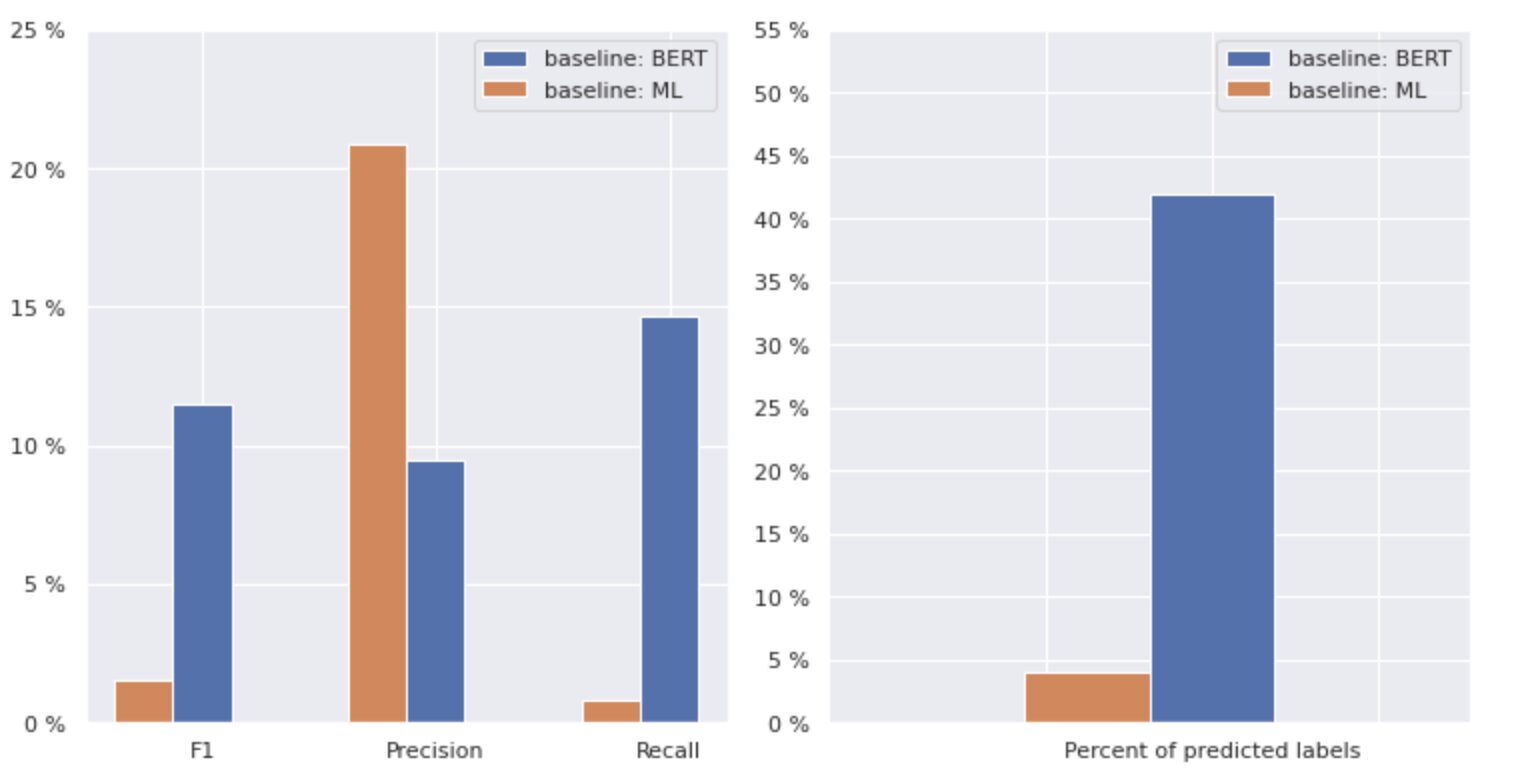
Figuur 2. Metrieken voor basismodellen
De grafiek aan de linkerkant toont een vergelijking van statistieken voor een "baseline: BERT" en "baseline: ML". Zo kan worden gezien dat voor "baseline: BERT" de F1- en Recall-scores ongeveer 1.5 keer hoger zijn, terwijl de Precision voor "baseline: ML" 2 keer hoger is dan die van model 1. Door het totale percentage van voorspelde klassen rechts weergegeven, zien we dat "baseline: BERT" klassen meer dan 10 keer voorspelde dan "baseline: ML".
Omdat het maximale resultaat voor de "baseline: BERT" minder dan 50% van alle klassen is, zijn de resultaten behoorlijk ontmoedigend. Laten we eens kijken hoe we deze resultaten kunnen verbeteren.
Gebaseerd op het uitstekende artikel "Balancingmethoden voor tekstclassificatie met meerdere labels met langstaartige klassendistributie", hebben we geleerd dat distributiegebalanceerd verlies voor ons de meest geschikte benadering kan zijn.
Distributie-evenwichtig verlies
Distributiegebalanceerd verlies is een techniek die wordt gebruikt bij problemen met tekstclassificatie met meerdere labels om onevenwichtigheden in klassendistributie aan te pakken. Bij deze problemen komen sommige klassen veel vaker voor in vergelijking met andere, wat resulteert in modelbias in de richting van deze meer frequente klassen.
Om dit probleem aan te pakken, heeft distributie-evenwichtig verlies tot doel de bijdrage van elke steekproef in de verliesfunctie in evenwicht te brengen. Dit wordt bereikt door het verlies van elk monster opnieuw te wegen op basis van het omgekeerde van de frequentie van voorkomen in de dataset. Door dit te doen, wordt de bijdrage van minder frequente lessen verhoogd en de bijdrage van meer frequente lessen verlaagd, waardoor de algehele klassenverdeling in evenwicht wordt gebracht.
Het is aangetoond dat deze techniek effectief is bij het verbeteren van de prestaties van modellen op langstaartige klassenverdelingsproblemen. Door de impact van frequente klassen te verkleinen en de impact van niet-frequente klassen te vergroten, kan het model patronen in de gegevens beter vastleggen en evenwichtigere voorspellingen produceren.

Implementatie van Resample Class
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np class ResampleLoss(nn.Module): def __init__( self, use_sigmoid=True, partial=False, loss_weight=1.0, reduction="mean", reweight_func=None, weight_norm=None, focal=dict(focal=True, alpha=0.5, gamma=2), map_param=dict(alpha=10.0, beta=0.2, gamma=0.1), CB_loss=dict(CB_beta=0.9, CB_mode="average_w"), logit_reg=dict(neg_scale=5.0, init_bias=0.1), class_freq=None, train_num=None, ): super(ResampleLoss, self).__init__() assert (use_sigmoid is True) or (partial is False) self.use_sigmoid = use_sigmoid self.partial = partial self.loss_weight = loss_weight self.reduction = reduction if self.use_sigmoid: if self.partial: self.cls_criterion = partial_cross_entropy else: self.cls_criterion = binary_cross_entropy else: self.cls_criterion = cross_entropy # reweighting function self.reweight_func = reweight_func # normalization (optional) self.weight_norm = weight_norm # focal loss params self.focal = focal["focal"] self.gamma = focal["gamma"] self.alpha = focal["alpha"] # mapping function params self.map_alpha = map_param["alpha"] self.map_beta = map_param["beta"] self.map_gamma = map_param["gamma"] # CB loss params (optional) self.CB_beta = CB_loss["CB_beta"] self.CB_mode = CB_loss["CB_mode"] self.class_freq = ( torch.from_numpy(np.asarray(class_freq)).float().cuda() ) self.num_classes = self.class_freq.shape[0] self.train_num = train_num # only used to be divided by class_freq # regularization params self.logit_reg = logit_reg self.neg_scale = ( logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0 ) init_bias = ( logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0 ) self.init_bias = ( -torch.log(self.train_num / self.class_freq - 1) * init_bias ) self.freq_inv = ( torch.ones(self.class_freq.shape).cuda() / self.class_freq ) self.propotion_inv = self.train_num / self.class_freq def forward( self, cls_score, label, weight=None, avg_factor=None, reduction_override=None, **kwargs ): assert reduction_override in (None, "none", "mean", "sum") reduction = ( reduction_override if reduction_override else self.reduction ) weight = self.reweight_functions(label) cls_score, weight = self.logit_reg_functions( label.float(), cls_score, weight ) if self.focal: logpt = self.cls_criterion( cls_score.clone(), label, weight=None, reduction="none", avg_factor=avg_factor, ) # pt is sigmoid(logit) for pos or sigmoid(-logit) for neg pt = torch.exp(-logpt) wtloss = self.cls_criterion( cls_score, label.float(), weight=weight, reduction="none" ) alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha) loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss loss = reduce_loss(loss, reduction) else: loss = self.cls_criterion( cls_score, label.float(), weight, reduction=reduction ) loss = self.loss_weight * loss return loss def reweight_functions(self, label): if self.reweight_func is None: return None elif self.reweight_func in ["inv", "sqrt_inv"]: weight = self.RW_weight(label.float()) elif self.reweight_func in "rebalance": weight = self.rebalance_weight(label.float()) elif self.reweight_func in "CB": weight = self.CB_weight(label.float()) else: return None if self.weight_norm is not None: if "by_instance" in self.weight_norm: max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True) weight = weight / max_by_instance elif "by_batch" in self.weight_norm: weight = weight / torch.max(weight) return weight def logit_reg_functions(self, labels, logits, weight=None): if not self.logit_reg: return logits, weight if "init_bias" in self.logit_reg: logits += self.init_bias if "neg_scale" in self.logit_reg: logits = logits * (1 - labels) * self.neg_scale + logits * labels if weight is not None: weight = ( weight / self.neg_scale * (1 - labels) + weight * labels ) return logits, weight def rebalance_weight(self, gt_labels): repeat_rate = torch.sum( gt_labels.float() * self.freq_inv, dim=1, keepdim=True ) pos_weight = ( self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate ) # pos and neg are equally treated weight = ( torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma)) + self.map_alpha ) return weight def CB_weight(self, gt_labels): if "by_class" in self.CB_mode: weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) elif "average_n" in self.CB_mode: avg_n = torch.sum( gt_labels * self.class_freq, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, avg_n)).cuda() ) elif "average_w" in self.CB_mode: weight_ = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) weight = torch.sum( gt_labels * weight_, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) elif "min_n" in self.CB_mode: min_n, _ = torch.min( gt_labels * self.class_freq + (1 - gt_labels) * 100000, dim=1, keepdim=True, ) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, min_n)).cuda() ) else: raise NameError return weight def RW_weight(self, gt_labels, by_class=True): if "sqrt" in self.reweight_func: weight = torch.sqrt(self.propotion_inv) else: weight = self.propotion_inv if not by_class: sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True) weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True) return weight def reduce_loss(loss, reduction): """Reduce loss as specified. Args: loss (Tensor): Elementwise loss tensor. reduction (str): Options are "none", "mean" and "sum". Return: Tensor: Reduced loss tensor. """ reduction_enum = F._Reduction.get_enum(reduction) # none: 0, elementwise_mean:1, sum: 2 if reduction_enum == 0: return loss elif reduction_enum == 1: return loss.mean() elif reduction_enum == 2: return loss.sum() def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None): """Apply element-wise weight and reduce loss. Args: loss (Tensor): Element-wise loss. weight (Tensor): Element-wise weights. reduction (str): Same as built-in losses of PyTorch. avg_factor (float): Avarage factor when computing the mean of losses. Returns: Tensor: Processed loss values. """ # if weight is specified, apply element-wise weight if weight is not None: loss = loss * weight # if avg_factor is not specified, just reduce the loss if avg_factor is None: loss = reduce_loss(loss, reduction) else: # if reduction is mean, then average the loss by avg_factor if reduction == "mean": loss = loss.sum() / avg_factor # if reduction is 'none', then do nothing, otherwise raise an error elif reduction != "none": raise ValueError( 'avg_factor can not be used with reduction="sum"' ) return loss def binary_cross_entropy( pred, label, weight=None, reduction="mean", avg_factor=None
): # weighted element-wise losses if weight is not None: weight = weight.float() loss = F.binary_cross_entropy_with_logits( pred, label.float(), weight, reduction="none" ) loss = weight_reduce_loss( loss, reduction=reduction, avg_factor=avg_factor ) return loss
DBloss
loss_func = ResampleLoss( reweight_func="rebalance", loss_weight=1.0, focal=dict(focal=True, alpha=0.5, gamma=2), logit_reg=dict(init_bias=0.05, neg_scale=2.0), map_param=dict(alpha=0.1, beta=10.0, gamma=0.405), class_freq=class_freq, train_num=train_num,
) """
class_freq - list of frequencies for each class,
train_num - size of train dataset """
Door de dataset nauwkeurig te onderzoeken, hebben we geconcludeerd dat de parameter
= 0.405.
Drempelafstemming
Een andere stap in het verbeteren van ons model was het afstemmen van de drempel, zowel in de trainingsfase als in de validatie- en testfase. We berekenden de afhankelijkheden van metrische gegevens zoals f1-score, precisie en herinnering op het drempelniveau en we selecteerden de drempel op basis van de hoogste metrische score. Hieronder ziet u de functie-implementatie van dit proces.
Optimalisatie van de F1-score door de drempel af te stemmen:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray): best_med_th = 0.5 true_bools = [tl == 1 for tl in true_labels] micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th f1_results, pre_results, recall_results = [], [], [] for th in micro_thresholds: pred_bools = [pl > th for pl in pred_labels] test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0) test_precision = precision_score( true_bools, pred_bools, average="micro", zero_division=0 ) test_recall = recall_score( true_bools, pred_bools, average="micro", zero_division=0 ) f1_results.append(test_f1) prec_results.append(test_precision) recall_results.append(test_recall) best_f1_idx = np.argmax(f1_results) return micro_thresholds[best_f1_idx]Evaluatie en vergelijking met baseline
Dankzij deze benaderingen konden we een nieuw model trainen en het volgende resultaat verkrijgen, dat wordt vergeleken met de basislijn: BERT in figuur 3 hieronder.

Afbeelding 3. Vergelijkingsstatistieken per basislijn en nieuwere benadering.
Door de statistieken te vergelijken die relevant zijn voor classificatie, zien we een significante toename van prestatiemetingen bijna 5-6 keer:
De F1-score steeg van 12% → 55%, terwijl Precision steeg van 9% → 59% en Recall steeg van 15% → 51%.
Met de veranderingen in de rechtergrafiek in figuur 3 kunnen we nu 80% van de klassen voorspellen.
Stukken klassen
We hebben onze labels onderverdeeld in vier groepen: HEAD, MEDIUM, TAIL en ZERO. Elke groep bevat labels met een vergelijkbare hoeveelheid ondersteunende gegevenswaarnemingen.
Zoals te zien is in figuur 4, zijn de verdelingen van de groepen verschillend. De rozendoos (HEAD) heeft een negatief scheve verdeling, de middelste doos (MEDIUM) heeft een positief scheve verdeling en de groene doos (TAIL) lijkt een normale verdeling te hebben.
Alle groepen hebben ook uitschieters, dit zijn punten buiten de snorharen in de boxplot. De HEAD-groep heeft een grote impact op een MAJOR-klas.
Daarnaast hebben we een aparte groep geïdentificeerd met de naam "ZERO", die labels bevat die het model niet kon leren en niet kan herkennen vanwege het minimale aantal voorkomens in de dataset (minder dan 3% van alle waarnemingen).
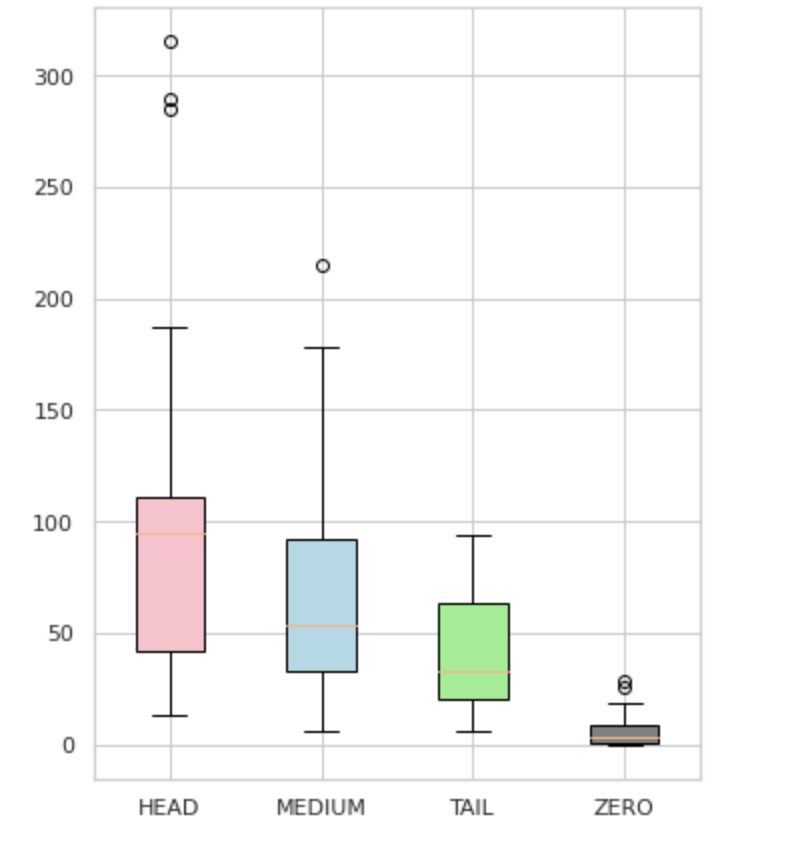
Figuur 4. Labeltellingen vs. groepen
Tabel 2 geeft informatie over metrische gegevens per groep labels voor de testsubset van gegevens.
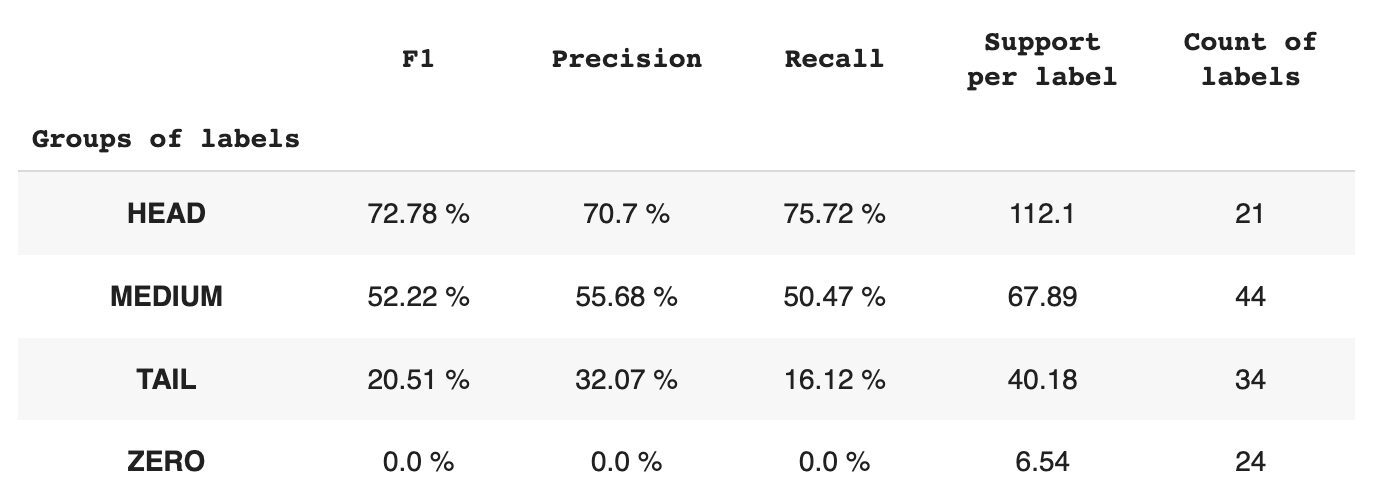
Tabel 2. Metrieken per groep.
- De HEAD-groep bevat 21 labels met gemiddeld 112 ondersteuningswaarnemingen per label. Deze groep wordt beïnvloed door uitschieters en vanwege de hoge vertegenwoordiging in de dataset zijn de statistieken hoog: F1 – 73%, Precision – 71%, Recall – 75%.
- De MEDIUM-groep bestaat uit 44 labels met een gemiddelde ondersteuning van 67 waarnemingen, wat ongeveer twee keer lager is dan de HEAD-groep. De statistieken voor deze groep zullen naar verwachting met 50% dalen: F1 - 52%, Precision - 56%, Recall - 51%.
- De TAIL-groep heeft het grootste aantal klassen, maar ze zijn allemaal slecht vertegenwoordigd in de dataset, met gemiddeld 40 ondersteuningswaarnemingen per label. Als gevolg hiervan dalen de statistieken aanzienlijk: F1 - 21%, Precision - 32%, Recall - 16%.
- De ZERO-groep bevat klassen die het model helemaal niet kan herkennen, mogelijk vanwege hun lage voorkomen in de dataset. Elk van de 24 labels in deze groep heeft gemiddeld 7 ondersteuningswaarnemingen.
Figuur 5 visualiseert de informatie gepresenteerd in tabel 2 en geeft een visuele weergave van de metrieken per groep labels.
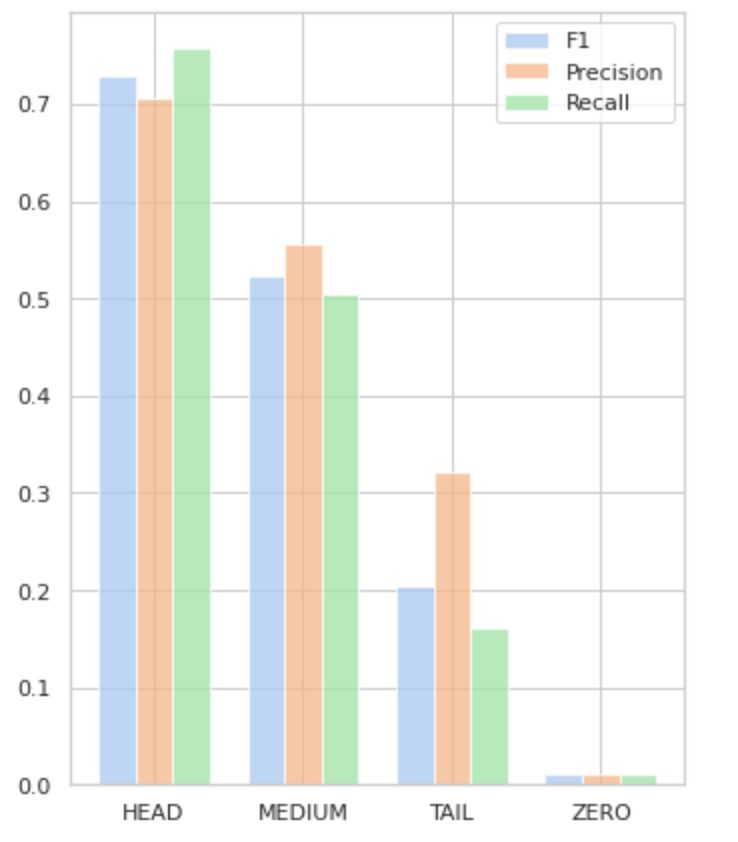
Afbeelding 5. Statistieken versus labelgroepen. Alle NUL-waarden = 0.
In dit uitgebreide artikel hebben we aangetoond dat een ogenschijnlijk eenvoudige taak van tekstclassificatie met meerdere labels een uitdaging kan zijn wanneer traditionele methoden worden toegepast. We hebben het gebruik van distributie-balancerende verliesfuncties voorgesteld om het probleem van klassenonevenwichtigheid aan te pakken.
We hebben de prestaties van onze voorgestelde aanpak vergeleken met de klassieke methode en geëvalueerd met behulp van real-world business metrics. De resultaten tonen aan dat het gebruik van verliesfuncties om klassenonevenwichtigheden en gelijktijdig voorkomen van labels aan te pakken, een haalbare oplossing biedt voor tekstclassificatie met meerdere labels.
De voorgestelde use case benadrukt het belang van het overwegen van verschillende benaderingen en technieken bij het omgaan met tekstclassificatie met meerdere labels, en de potentiële voordelen van distributie-balancerende verliesfuncties bij het aanpakken van klassenonevenwichtigheden.
Als u met een soortgelijk probleem wordt geconfronteerd en dit probeert documentverwerking stroomlijnen binnen uw organisatie kunt u contact opnemen met mij of het Provectus-team. Wij helpen u graag bij het vinden van efficiëntere methoden om uw processen te automatiseren.
Oleksii Babych is een Machine Learning Engineer bij Provectus. Met een achtergrond in natuurkunde beschikt hij over uitstekende analytische en wiskundige vaardigheden en heeft hij waardevolle ervaring opgedaan door wetenschappelijk onderzoek en internationale conferentiepresentaties, waaronder SPIE Photonics West. Oleksii is gespecialiseerd in het creëren van end-to-end, grootschalige AI/ML-oplossingen voor de gezondheidszorg en fintech-industrieën. Hij is betrokken bij elke fase van de levenscyclus van ML-ontwikkeling, van het identificeren van bedrijfsproblemen tot het implementeren en uitvoeren van productie-ML-modellen.
Rinat Akhmetov is de ML Solution Architect bij Provectus. Met een solide praktische achtergrond in Machine Learning (vooral in Computer Vision), is Rinat een nerd, data-enthousiasteling, software-engineer en workaholic wiens op een na grootste passie programmeren is. Bij Provectus is Rinat verantwoordelijk voor de fasen Discovery en Proof of Concept, en leidt hij de uitvoering van complexe AI-projecten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-label-nlp-an-analysis-of-class-imbalance-and-loss-function-approaches
- :is
- 1
- 10
- 100
- 15%
- 67
- 7
- 9
- a
- in staat
- Over
- Bereiken
- bereikt
- acties
- Activering
- aanpassing
- adres
- aanpakken
- AI
- AI / ML
- wil
- algoritme
- algoritmen
- Alles
- toestaat
- Alpha
- onder
- bedragen
- analyse
- Analytisch
- het analyseren van
- en
- verscheen
- toegepast
- Solliciteer
- nadering
- benaderingen
- ongeveer
- ZIJN
- dit artikel
- AS
- aspecten
- toegewezen
- helpen
- geassocieerd
- At
- automatiseren
- gemiddelde
- achtergrond
- Balance
- gebaseerde
- Baseline
- BE
- omdat
- onder
- betekent
- BEST
- beta
- Betere
- tussen
- vooringenomenheid
- Grootste
- Onder
- Box camera's
- ingebouwd
- bedrijfsdeskundigen
- by
- berekend
- CAN
- kan niet
- vangen
- geval
- categorieën
- CB
- zeker
- uitdagingen
- uitdagend
- Wijzigingen
- lading
- klasse
- klassen
- klassiek
- classificatie
- klant
- van nabij
- dichterbij
- algemeen
- vergeleken
- vergelijken
- vergelijking
- complex
- uitgebreid
- computer
- Computer visie
- computergebruik
- concept
- Zorgen
- gesloten
- Conferentie
- aangezien
- contact
- bevat
- content
- verband
- bijdrage
- heeft betrekking op
- Wij creëren
- klant
- cyclus
- gegevens
- omgang
- verlagen
- gedefinieerd
- tonen
- gedemonstreerd
- het inzetten
- ontworpen
- gedetailleerd
- Ontwikkeling
- verschillen
- anders
- direct
- ontdekking
- onderscheiden
- distributie
- Uitkeringen
- diversen
- Verdeeld
- document
- documenten
- doen
- domein
- Val
- elk
- gemakkelijk
- effectief
- doeltreffend
- inspanningen
- in staat stellen
- eind tot eind
- ingenieur
- enthousiast
- even
- fout
- vooral
- Ether (ETH)
- geëvalueerd
- Alle
- bewijzen
- voorbeeld
- uitstekend
- uitvoering
- verwacht
- ervaring
- exploratie
- Verken
- uitdrukkelijk
- f1
- geconfronteerd
- naar
- feedback
- Figuur
- finale
- het vinden van
- FinTech
- Voornaam*
- Vlotter
- volgend
- Voor
- gevonden
- fractie
- Frequentie
- veelvuldig
- oppompen van
- functie
- functioneel
- functies
- verder
- Krijgen
- gegeven
- oogopslag
- diagram
- Groen
- Groep
- Groep
- handvat
- gelukkig
- Hebben
- hoofd
- gezondheidszorg
- hulp
- helpt
- Hoge
- hoger
- hoogst
- highlights
- Hoe
- How To
- Echter
- HTML
- http
- HTTPS
- geïdentificeerd
- het identificeren van
- onbalans
- Impact
- beïnvloed
- uitvoering
- importeren
- belang
- belangrijk
- verbeteren
- het verbeteren van
- in
- omvat
- Inclusief
- onjuist
- Laat uw omzet
- meer
- meer
- onafhankelijk
- industrieën
- informatie
- inherent
- invoer
- instantie
- verkrijgen in plaats daarvan
- Internationale
- investeerde
- betrokken zijn
- kwestie
- IT
- HAAR
- jpg
- eentje maar
- KDnuggets
- label
- etikettering
- labels
- taal
- grootschalig
- grootste
- lagen
- Leads
- LEARN
- geleerd
- leren
- Niveau
- Life
- Lijst
- Kijk
- uit
- verliezen
- Laag
- machine
- machine learning
- gemaakt
- Hoofd
- groot
- Meerderheid
- veel
- in kaart brengen
- wiskunde
- maximaal
- maatregelen
- Medium
- methode
- methoden
- metriek
- Metriek
- minimaal
- ML
- MLB
- model
- modellen
- wijzigen
- module
- meer
- efficiënter
- meest
- meervoudig
- Genoemd
- Noodzaak
- negatief
- negatief
- New
- nlp
- een
- opmerkelijk
- aantal
- nummers
- numpy
- verkrijgen
- verkregen
- of
- bieden
- on
- EEN
- kansen
- gekant tegen
- Opties
- organisatie
- Overig
- anders-
- buiten
- uitstekend
- totaal
- parameter
- passie
- patronen
- percentage
- prestatie
- Fysica
- stuk
- Plato
- Plato gegevensintelligentie
- PlatoData
- dan
- punten
- PoS
- positief
- potentieel
- mogelijk
- PRAKTISCH
- precisie
- voorspellen
- voorspeld
- Voorspellingen
- voorspelt
- Presentaties
- gepresenteerd
- probleem
- problemen
- processen
- verwerking
- produceren
- Product
- productie
- Programming
- projecten
- bewijs
- proof of concept voor
- voorgestelde
- zorgen voor
- mits
- biedt
- het verstrekken van
- pytorch
- verhogen
- reeks
- liever
- echte wereld
- herbalanceren
- samenvatting
- herkennen
- verminderen
- Gereduceerd
- vermindering
- verwijst
- betrekkingen
- relevantie
- relevante
- vertegenwoordiging
- vertegenwoordigd
- te vragen
- onderzoek
- resultaat
- verkregen
- Resultaten
- terugkeer
- Retourneren
- beoordelen
- ROSE
- lopend
- s
- dezelfde
- scenario's
- Wetenschappelijk onderzoek
- Tweede
- op zoek naar
- gekozen
- ZELF
- sentiment
- apart
- service
- reeks
- Sets
- Vorm
- getoond
- Shows
- betekenis
- aanzienlijke
- aanzienlijk
- gelijk
- Eenvoudig
- gelijktijdig
- single
- Maat
- vaardigheden
- So
- Software
- Software Engineer
- solide
- oplossing
- Oplossingen
- OPLOSSEN
- sommige
- specialiseert
- gespecificeerd
- Stadium
- stadia
- standaard
- statistiek
- Stap voor
- eenvoudig
- dergelijk
- geschikt
- leren onder toezicht
- ondersteuning
- Ondersteuning
- tafel
- TAG
- Nemen
- doelgerichte
- Taak
- taken
- team
- technieken
- proef
- Testen
- Tekstclassificatie
- dat
- De
- de informatie
- hun
- Ze
- zich
- Deze
- drempel
- Door
- niet de tijd of
- keer
- naar
- top
- fakkel
- Totaal
- in de richting van
- spoor
- traditioneel
- Trainen
- Trainingen
- Transformeren
- Transformatie
- getransformeerd
- transformeren
- behandelt
- waar
- typisch
- onzekerheden
- begrip
- unieke
- us
- .
- use case
- Gebruik makend
- bevestiging
- waardevol
- Values
- divers
- rendabel
- visie
- vs
- gewicht
- West
- welke
- en
- Wikipedia
- wil
- Met
- binnen
- zonder
- werkte
- Your
- zephyrnet
- nul