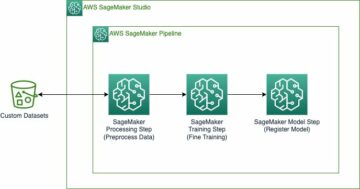
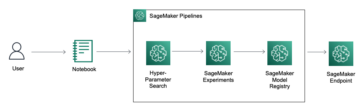
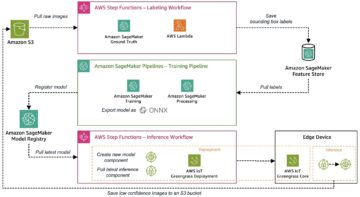
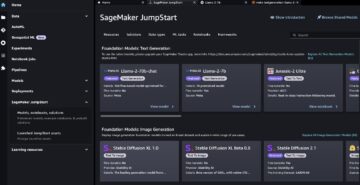
Amazon Sage Maker biedt een suite van ingebouwde algoritmen, voorgetrainde modellen en vooraf gebouwde oplossingssjablonen om datawetenschappers en machine learning (ML)-beoefenaars te helpen snel aan de slag te gaan met het trainen en implementeren van ML-modellen. U kunt deze algoritmen en modellen gebruiken voor zowel begeleid als niet-gesuperviseerd leren. Ze kunnen verschillende soorten invoergegevens verwerken, waaronder tabellen, afbeeldingen en tekst.
Vanaf vandaag biedt SageMaker vier nieuwe ingebouwde algoritmen voor gegevensmodellering in tabelvorm: LightGBM, CatBoost, AutoGluon-Tabular en TabTransformer. U kunt deze populaire, geavanceerde algoritmen gebruiken voor zowel tabellarische classificatie als regressietaken. Ze zijn verkrijgbaar via de ingebouwde algoritmen op de SageMaker-console en via de Amazon SageMaker JumpStart UI binnen Amazon SageMaker Studio.
Het volgende is de lijst van de vier nieuwe ingebouwde algoritmen, met links naar hun documentatie, voorbeeldnotitieblokken en bron.
| Documentatie | Voorbeeld notebooks | bron |
| LightGBM-algoritme | Regressie, Classificatie | LichtGBM |
| CatBoost-algoritme | Regressie, Classificatie | KatBoost |
| AutoGluon-Tabulaire Algoritme | Regressie, Classificatie | AutoGluon-tabel |
| TabTransformer-algoritme | Regressie, Classificatie | Tab Transformator |
In de volgende secties geven we een korte technische beschrijving van elk algoritme en voorbeelden van hoe een model te trainen via de SageMaker SDK of SageMaker Jumpstart.
LichtGBM
LichtGBM is een populaire en efficiënte open-source implementatie van het Gradient Boosting Decision Tree (GBDT) algoritme. GBDT is een gesuperviseerd leeralgoritme dat probeert een doelvariabele nauwkeurig te voorspellen door een ensemble van schattingen van een reeks eenvoudigere en zwakkere modellen te combineren. LightGBM gebruikt aanvullende technieken om de efficiëntie en schaalbaarheid van conventionele GBDT aanzienlijk te verbeteren.
KatBoost
KatBoost is een populaire en krachtige open-source implementatie van het GBDT-algoritme. In CatBoost worden twee cruciale algoritmische vooruitgangen geïntroduceerd: de implementatie van geordende boosting, een permutatie-gestuurd alternatief voor het klassieke algoritme, en een innovatief algoritme voor het verwerken van categorische kenmerken. Beide technieken zijn gemaakt om een voorspellingsverschuiving te bestrijden die wordt veroorzaakt door een speciaal soort lekkage van doelen die aanwezig is in alle momenteel bestaande implementaties van gradiëntverhogende algoritmen.
AutoGluon-tabel
AutoGluon-tabel is een open-source AutoML-project dat is ontwikkeld en onderhouden door Amazon en dat geavanceerde gegevensverwerking, diep leren en stapelen met meerdere lagen uitvoert. Het herkent automatisch het gegevenstype in elke kolom voor robuuste gegevensvoorverwerking, inclusief speciale verwerking van tekstvelden. AutoGluon past op verschillende modellen, variërend van kant-en-klare versterkte bomen tot aangepaste neurale netwerkmodellen. Deze modellen zijn op een nieuwe manier samengevoegd: modellen worden in meerdere lagen gestapeld en op een laaggewijze manier getraind, wat garandeert dat onbewerkte gegevens binnen een bepaalde tijdsdruk kunnen worden vertaald in hoogwaardige voorspellingen. Overfitting wordt tijdens dit proces beperkt door de gegevens op verschillende manieren te splitsen met zorgvuldige tracking van out-of-fold voorbeelden. AutoGluon is geoptimaliseerd voor prestaties en het out-of-the-box gebruik heeft verschillende top-3- en top-10-posities behaald in datawetenschapscompetities.
Tab Transformator
Tab Transformator is een nieuwe architectuur voor diepgaande gegevensmodellering in tabellen voor begeleid leren. De TabTransformer is gebouwd op op zelf-aandacht gebaseerde Transformers. De Transformer-lagen transformeren de inbedding van categorische kenmerken in robuuste contextuele inbeddingen om een hogere voorspellingsnauwkeurigheid te bereiken. Bovendien zijn de contextuele inbeddingen die van TabTransformer zijn geleerd, zeer robuust tegen zowel ontbrekende als ruisrijke gegevensfuncties en bieden ze een betere interpreteerbaarheid. Dit model is het product van recente Amazone-wetenschap Onderzoek (papier en officieel blogpost hier) en is op grote schaal overgenomen door de ML-gemeenschap, met verschillende implementaties van derden (Keras, AutoGluon,) en functies voor sociale media zoals tweets, richting datawetenschap, gemiddeld, en Kaggle.
Voordelen van ingebouwde algoritmen van SageMaker
Wanneer u een algoritme selecteert voor uw specifieke type probleem en gegevens, is het gebruik van een ingebouwd SageMaker-algoritme de gemakkelijkste optie, omdat dit de volgende grote voordelen met zich meebrengt:
- De ingebouwde algoritmen vereisen geen codering om experimenten uit te voeren. De enige invoer die u hoeft te verstrekken, zijn de gegevens, hyperparameters en rekenresources. Hierdoor kunt u experimenten sneller uitvoeren, met minder overhead voor het bijhouden van resultaten en codewijzigingen.
- De ingebouwde algoritmen worden geleverd met parallellisatie over meerdere rekeninstances en GPU-ondersteuning direct uit de doos voor alle toepasselijke algoritmen (sommige algoritmen zijn mogelijk niet inbegrepen vanwege inherente beperkingen). Als u veel gegevens heeft om uw model mee te trainen, kunnen de meeste ingebouwde algoritmen eenvoudig worden geschaald om aan de vraag te voldoen. Zelfs als je al een vooraf getraind model hebt, kan het nog steeds gemakkelijker zijn om het uitvloeisel ervan in SageMaker te gebruiken en de hyperparameters die je al kent in te voeren in plaats van het over te dragen en zelf een trainingsscript te schrijven.
- U bent de eigenaar van de resulterende modelartefacten. Je kunt dat model nemen en het op SageMaker inzetten voor verschillende inferentiepatronen (bekijk alle beschikbare implementatietypes) en eenvoudig schalen en beheren van eindpunten, of u kunt het implementeren waar u het ook maar nodig hebt.
Laten we nu kijken hoe we een van deze ingebouwde algoritmen kunnen trainen.
Train een ingebouwd algoritme met behulp van de SageMaker SDK
Om een geselecteerd model te trainen, moeten we de URI van dat model ophalen, evenals die van het trainingsscript en de containerafbeelding die voor de training wordt gebruikt. Gelukkig zijn deze drie ingangen uitsluitend afhankelijk van de modelnaam, versie (voor een lijst van de beschikbare modellen, zie Tabel met beschikbare JumpStart-modellen), en het type instantie waarop u wilt trainen. Dit wordt gedemonstreerd in het volgende codefragment:
De train_model_id veranderd naar lightgbm-regression-model als we te maken hebben met een regressieprobleem. De ID's voor alle andere modellen die in dit bericht zijn geïntroduceerd, worden vermeld in de volgende tabel.
| Model | Probleemtype | Model ID |
| LichtGBM | Classificatie | lightgbm-classification-model |
| . | Regressie | lightgbm-regression-model |
| KatBoost | Classificatie | catboost-classification-model |
| . | Regressie | catboost-regression-model |
| AutoGluon-tabel | Classificatie | autogluon-classification-ensemble |
| . | Regressie | autogluon-regression-ensemble |
| Tab Transformator | Classificatie | pytorch-tabtransformerclassification-model |
| . | Regressie | pytorch-tabtransformerregression-model |
We definiëren dan waar onze input aan staat Amazon eenvoudige opslagservice (Amazon S3). Voor dit voorbeeld gebruiken we een openbare voorbeeldgegevensset. We definiëren ook waar we onze uitvoer willen hebben en halen de standaardlijst met hyperparameters op die nodig zijn om het geselecteerde model te trainen. U kunt hun waarde naar wens wijzigen.
Ten slotte instantiëren we een SageMaker Estimator met alle opgehaalde invoer en start de trainingstaak met .fit, door het door te geven aan onze trainingsdataset-URI. De entry_point het opgegeven script heeft een naam transfer_learning.py (hetzelfde voor andere taken en algoritmen), en het invoergegevenskanaal dat wordt doorgegeven aan .fit moet worden genoemd training.
Merk op dat u ingebouwde algoritmen kunt trainen met: Automatische afstemming van SageMaker-modellen om de optimale hyperparameters te selecteren en de modelprestaties verder te verbeteren.
Train een ingebouwd algoritme met SageMaker JumpStart
U kunt deze ingebouwde algoritmen ook met een paar klikken trainen via de SageMaker JumpStart UI. JumpStart is een SageMaker-functie waarmee u ingebouwde algoritmen en vooraf getrainde modellen uit verschillende ML-frameworks en modelhubs kunt trainen en implementeren via een grafische interface. Het stelt u ook in staat om volwaardige ML-oplossingen te implementeren die ML-modellen en verschillende andere AWS-services aan elkaar rijgen om een gerichte use case op te lossen.
Raadpleeg voor meer informatie Voer tekstclassificatie uit met Amazon SageMaker JumpStart met behulp van TensorFlow Hub en Hugging Face-modellen.
Conclusie
In dit bericht hebben we de lancering aangekondigd van vier krachtige nieuwe ingebouwde algoritmen voor ML op tabelgegevenssets die nu beschikbaar zijn op SageMaker. We hebben een technische beschrijving gegeven van wat deze algoritmen zijn, evenals een voorbeeld van een trainingstaak voor LightGBM met behulp van de SageMaker SDK.
Breng uw eigen dataset mee en probeer deze nieuwe algoritmen op SageMaker, en bekijk de voorbeeldnotitieblokken om ingebouwde algoritmen te gebruiken die beschikbaar zijn op GitHub.
Over de auteurs
![]() Dr Xin Huang is een toegepast wetenschapper voor de ingebouwde algoritmen van Amazon SageMaker JumpStart en Amazon SageMaker. Hij richt zich op het ontwikkelen van schaalbare algoritmen voor machine learning. Zijn onderzoeksinteresses liggen op het gebied van natuurlijke taalverwerking, verklaarbaar diep leren op tabelgegevens en robuuste analyse van niet-parametrische ruimte-tijdclustering. Hij heeft veel artikelen gepubliceerd in ACL, ICDM, KDD-conferenties en het tijdschrift Royal Statistical Society: Series A.
Dr Xin Huang is een toegepast wetenschapper voor de ingebouwde algoritmen van Amazon SageMaker JumpStart en Amazon SageMaker. Hij richt zich op het ontwikkelen van schaalbare algoritmen voor machine learning. Zijn onderzoeksinteresses liggen op het gebied van natuurlijke taalverwerking, verklaarbaar diep leren op tabelgegevens en robuuste analyse van niet-parametrische ruimte-tijdclustering. Hij heeft veel artikelen gepubliceerd in ACL, ICDM, KDD-conferenties en het tijdschrift Royal Statistical Society: Series A.
![]() Dr Ashish Khetan is een Senior Applied Scientist met ingebouwde algoritmen van Amazon SageMaker JumpStart en Amazon SageMaker en helpt bij het ontwikkelen van algoritmen voor machine learning. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
Dr Ashish Khetan is een Senior Applied Scientist met ingebouwde algoritmen van Amazon SageMaker JumpStart en Amazon SageMaker en helpt bij het ontwikkelen van algoritmen voor machine learning. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
 Joao Moura is een AI/ML Specialist Solutions Architect bij Amazon Web Services. Hij is vooral gericht op NLP-use-cases en helpt klanten bij het optimaliseren van de training en implementatie van Deep Learning-modellen. Hij is ook een actief voorstander van low-code ML-oplossingen en ML-gespecialiseerde hardware.
Joao Moura is een AI/ML Specialist Solutions Architect bij Amazon Web Services. Hij is vooral gericht op NLP-use-cases en helpt klanten bij het optimaliseren van de training en implementatie van Deep Learning-modellen. Hij is ook een actief voorstander van low-code ML-oplossingen en ML-gespecialiseerde hardware.
- Coinsmart. Europa's beste Bitcoin- en crypto-uitwisseling.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. GRATIS TOEGANG.
- CryptoHawk. Altcoin-radar. Gratis proefversie.
- Bron: https://aws.amazon.com/blogs/machine-learning/new-built-in-amazon-sagemaker-algorithms-for-tabular-data-modeling-lightgbm-catboost-autogluon-tabular-and-tabtransformer/
- "
- 100
- a
- Bereiken
- bereikt
- over
- actieve
- Extra
- vergevorderd
- voorschotten
- tegen
- algoritme
- algoritmische
- algoritmen
- Alles
- toestaat
- al
- alternatief
- Amazone
- Amazon Web Services
- analyse
- aangekondigd
- toepasselijk
- toegepast
- architectuur
- GEBIED
- Automatisch
- webmaster.
- Beschikbaar
- AWS
- omdat
- betekent
- Betere
- Boosted
- het stimuleren
- Box camera's
- ingebouwd
- voorzichtig
- geval
- veroorzaakt
- verandering
- klassiek
- classificatie
- code
- codering
- Kolom
- hoe
- gemeenschap
- Wedstrijden
- Berekenen
- conferenties
- troosten
- Containers
- en je merk te creëren
- aangemaakt
- kritisch
- Op dit moment
- gewoonte
- Klanten
- gegevens
- gegevensverwerking
- data science
- omgang
- beslissing
- deep
- Vraag
- gedemonstreerd
- implementeren
- het inzetten
- inzet
- beschrijving
- ontwikkelen
- ontwikkelde
- het ontwikkelen van
- anders
- havenarbeider
- elk
- gemakkelijk
- doeltreffendheid
- doeltreffend
- Endpoint
- schattingen
- voorbeeld
- voorbeelden
- bestaand
- Gezicht
- Kenmerk
- Voordelen
- Velden
- gericht
- richt
- volgend
- frameworks
- oppompen van
- verder
- Bovendien
- GPU
- Behandeling
- Hardware
- Hoogte
- hulp
- het helpen van
- helpt
- hier
- hoogwaardige
- hoger
- zeer
- Hoe
- How To
- HTTPS
- Naaf
- beeld
- uitvoering
- verbeteren
- inclusief
- Inclusief
- informatie
- inherent
- innovatieve
- invoer
- instantie
- belangen
- Interface
- IT
- Jobomschrijving:
- tijdschrift
- blijven
- taal
- lancering
- geleerd
- leren
- links
- Lijst
- opgesomd
- machine
- machine learning
- groot
- management
- manier
- Media
- Medium
- ML
- model
- modellen
- meer
- meest
- meervoudig
- Naturel
- netwerk
- Optimaliseer
- geoptimaliseerde
- Keuze
- Overige
- het te bezitten.
- eigenaar
- bijzonder
- Voorbijgaand
- prestatie
- Populair
- krachtige
- voorspellen
- voorspelling
- Voorspellingen
- presenteren
- probleem
- verwerking
- Product
- project
- zorgen voor
- mits
- biedt
- publiek
- gepubliceerde
- snel
- variërend
- Rauw
- erkent
- regio
- vereisen
- onderzoek
- Resources
- verkregen
- Resultaten
- lopen
- lopend
- dezelfde
- Schaalbaarheid
- schaalbare
- Scale
- scaling
- Wetenschap
- Wetenschapper
- wetenschappers
- sdk
- gekozen
- -Series
- Serie A
- Diensten
- reeks
- verscheidene
- verschuiving
- Eenvoudig
- So
- Social
- social media
- Maatschappij
- oplossing
- Oplossingen
- OPLOSSEN
- sommige
- special
- specialist
- stack
- begin
- gestart
- state-of-the-art
- statistisch
- Still
- mediaopslag
- ondersteuning
- doelwit
- doelgerichte
- taken
- Technisch
- technieken
- De
- van derden
- drie
- Door
- overal
- niet de tijd of
- vandaag
- samen
- Tracking
- Trainen
- Trainingen
- Transformeren
- types
- ui
- unieke
- .
- gebruiksgevallen
- waarde
- divers
- versie
- manieren
- web
- webservices
- Wat
- binnen
- Your