Heb je ooit gewacht op dat ene dure pakket waarop 'verzonden' staat, maar je hebt geen idee waar het is? De trackinggeschiedenis is vijf dagen geleden gestopt met updaten en je hebt de hoop bijna verloren. Maar wacht, 11 dagen later heb je het voor de deur. U wenste dat de traceerbaarheid beter was geweest om u te verlossen van al het angstige wachten. Dit is waar "waarneembaarheid" in het spel komt.
In een technisch landschap wil je dit natuurlijk voorkomen met je software of datasystemen. En daarbij gebruikt u monitoringtools, die de logs en statistieken van uw systemen verzamelen en u informeren over hun interne status. Monitoring werkt het beste wanneer u wilt dat uw systemen u informeren over wat de fout is, waar en wanneer deze is opgetreden, maar u niet vertelt hoe u de fout kunt oplossen.
Meer dan tien jaar geleden misten monitoringtools de context en vooruitziende blik op onderliggende systeemproblemen en waren teams beperkt tot het opsporen van dagelijkse operationele fouten. Tegenwoordig werken en leven we in een gedistribueerde wereld van microservices en gegevenspijplijnen; zelfs het gebruik van meerdere monitoringtools zal u niet helpen uw zakelijke vragen te beantwoorden, zoals "Waarom is mijn applicatie altijd traag?" of "In welk stadium deed het probleem zich voor en hoe diep zit het in de stapel?" of "Hoe kan ik de algehele prestaties van de omgeving verbeteren?" Het wordt noodzakelijk om proactief te zijn bij het nemen van deze beslissingen en een algemeen inzicht te hebben in uw systemen, applicaties en gegevens.
Deze blogpost by Etsy werd tien jaar geleden gepubliceerd en het vermeldt het feit zelf in de tweede alinea:
“Applicatiestatistieken zijn meestal de moeilijkste, maar ook de belangrijkste van de drie. Ze zijn heel specifiek voor jouw bedrijf en ze veranderen als je applicaties veranderen (en Etsy verandert veel).”
Dus, hoe meten we alles en nog wat? We beginnen met waarneembaarheid.
Wat is waarneembaarheid?
De term "waarneembaarheid" was gemunt door Rudolf Emil Kálmán in 1960 in zijn technische paper om wiskundige regelsystemen te beschrijven. Hij definieerde het als een maatstaf voor hoe goed interne toestanden van een systeem kunnen worden afgeleid uit kennis van de externe output. Maar klinkt het niet als toezicht? Kortom, ja, het is toezicht.
Tegenwoordig is waarneembaarheid een behoorlijk hot topic geworden. Volgens verschillende marktonderzoeken is het een platform van een miljard dollar. Veel organisaties hebben het concept overgenomen en gebruikt als raamwerk voor end-to-end zichtbaarheid van hun gedistribueerde systemen en pijplijnen. Observeerbaarheid wordt echter verward met monitoring. Voor nu kan ik zeggen dat monitoring een subset is van waarneembaarheid, waarbij waarneembaarheid één grote overkoepelende term is.
Waarneembaarheid maakt gedistribueerde tracering mogelijk door traceringen, logboeken en statistieken te verzamelen en samen te voegen. Laten we eens kijken wat deze afleiden:
- Sporen: Wanneer een systeem een verzoek ontvangt, vertellen traceringen u hoe dat verzoek gedurende de hele levenscyclus van de bron naar de bestemming verloopt. Sporen worden weergegeven door "overspanningen". Een tracering is een boom van overspanningen en een overspanning is een enkele bewerking binnen een tracering. Ze helpen u bij het opsporen van fouten, latentie of knelpunten in het systeem.
- logs: Dit zijn door de machine gegenereerde gebeurtenissen met een tijdstempel die u vertellen over de bewerkingen of wijzigingen die in het systeem hebben plaatsgevonden. Logboeken worden vaak gebruikt om deze fouten of wijzigingen in het systeem op te vragen.
- metrics: Deze bieden kwantitatieve inzichten in CPU, geheugen, schijfgebruik en hoe het systeem over een bepaalde periode presteert.
Deze attributen versterken het monitoringkader met traceerbaarheid. Traceerbaarheid biedt u de lenzen om een verzoek te traceren dat een oproep naar uw systeem doet, hoe lang het duurt om van het ene onderdeel naar het andere te gaan, welke andere services het aanroept, veroorzaakt het een fout, welke logboeken het produceert, welke status het heeft is in, wanneer is het begonnen en geëindigd, wat is de tijdlijn waarin het in uw systeem is gebleven, enz. Wanneer u deze sporen verzamelt, aggregeert en analyseert, kunt u waardevolle weloverwogen beslissingen nemen, zoals de tijdlijn van de klant op een e-commerce website , hoe lang ze erover deden om naar een product te zoeken, hoe lang ze het product bekeken, laadde de HTML-pagina alle details zoals afbeeldingen of ingesloten video's, hoe lang het systeem erover deed om de betaling te verifiëren en te verwerken, enz.
Wat bereiken we met waarneembaarheid in een gedistribueerde omgeving?
De evolutie van gedistribueerde systemen begon toen organisaties begonnen af te stappen van hun gecentraliseerde monolietarchitectuur naar een gedistribueerde en gedecentraliseerde microservice-architectuur. En dit is nog steeds een work in progress waarbij veel organisaties de microservice-aard van systemen en applicaties omarmen. En dit alles kan worden toegeschreven aan big data en schaalvergroting. Het beheer van een gedistribueerde omgeving vereist continu leren, extra personeel, wijzigingen in kaders en beleid, IT-beheer, enzovoort. Het is inderdaad een grote verandering.
Vroeger, in de beperkte monolithische omgeving, woonden de hardware, software, gegevens en databases allemaal onder één dak. Met de komst van big data in de jaren 2000 begonnen monitoring- en schaalsystemen een grote zorg te worden. Vaak gebruikten organisaties verschillende monitoringtools om tegemoet te komen aan de behoeften van hun verschillende applicaties. Als gevolg hiervan werd het al snel een operationele overhead met slechte veerkracht, zichtbaarheid en betrouwbaarheid.
Al deze kwesties leidden tot de invoering van waarneembaarheid. Tegenwoordig bestaan er meerdere observatietools voor beveiligings-, netwerk-, applicatie- en datapijplijnen voor gedistribueerde tracering in een complexe omgeving. Ze bestaan naast hun neef, de monitoringtools, en maken gebruik van het verzamelen van de informatie van hun neef en aggregeren met aanvullende informatie uit zijn eigen traceergegevens.
Er zijn veel bewegende componenten in al deze systemen, waarvan de sporen, wanneer ze worden vastgelegd, het verhaal van de 5 W's kunnen illustreren: wanneer, waar, waarom, wat en hoe. U gaat bijvoorbeeld om 1:43 uur naar de website van DATAVERSITY om enkele blogposts te lezen. Wanneer u op dataversity.net klikt, wordt het HTTP-verzoek aangemeld bij het systeem. Je begint te zoeken naar een blogpost en gaat naar een Data Governance-post, waar je 17 minuten besteedt aan het lezen van die post en dan sluit je je tabblad om 2:00 uur
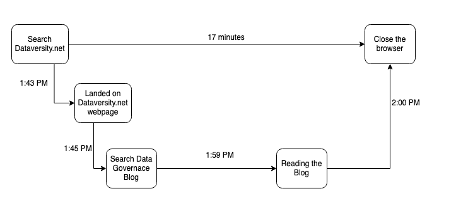
Er zullen ook andere oproepen naar het netwerksysteem worden gedaan voor het vastleggen van netwerkpakketten. Waarneembaarheidstools verzamelen alle overspanningen en verenigen ze in een spoor of sporen, zodat u het pad kunt zien dat het tijdens zijn levenscyclus heeft gevormd. Als je een probleem hebt zoals netwerklatentie of een systeemdefect, is het nu gemakkelijker om het probleem te ontleden (de ui te schillen) en te debuggen (fout in welke laag).
Nu in een grote gedistribueerde omgeving, wanneer uw applicaties miljoenen verzoeken ontvangen, groeien de traceergegevens enorm. Het verzamelen en analyseren van deze sporen is duur voor opslagverbruik en gegevensoverdracht. Om kosten te besparen, worden er dus steekproeven genomen van de traceergegevens, omdat technische teams in de meeste gevallen slechts enkele stukjes nodig hebben om te onderzoeken wat er fout is gegaan of wat het foutenpatroon is.
Met dat kleine voorbeeld begrijpen we dat we veel diepere inzichten in onze systemen krijgen. Dus, rekening houdend met een grotere schaal van systemen, kunnen technische teams de bemonsterde gegevens vastleggen en bewerken om de huidige structuur van het systeem te verbeteren, nieuwe componenten toe te passen of buiten gebruik te stellen, een extra beveiligingslaag toe te voegen, knelpunten te verwijderen, enzovoort.
Moeten organisaties kiezen voor waarneembaarheid?
We moeten allemaal begrijpen dat de einddoelen een betere gebruikerservaring en grotere gebruikerstevredenheid zijn. En het pad naar het bereiken van deze doelen kan gemakkelijker worden gemaakt met een geautomatiseerd en proactief observatiekader. Het tot stand brengen van een cultuur van continue verbetering en optimalisatie wordt beschouwd als de optimale bedrijfs- en leiderschapsbenadering.
In dit tijdperk van digitale transformatie is waarneembaarheid een must-have geworden voor een bedrijf om succesvol te zijn in zijn digitale reis. Waarneembaarheid biedt u inzichtelijke sporen en manoeuvreert u ook om data-geïnformeerd te zijn in plaats van alleen data-gedreven.
Conclusie
Hoewel we de termen monitoring en waarneembaarheid door elkaar hebben gebruikt, hebben we gezien dat terwijl monitoring u helpt met informatie over de gezondheid van het systeem en gebeurtenissen die erop plaatsvinden, waarneembaarheid u helpt om gevolgtrekkingen te maken op basis van bewijs dat is verzameld uit diepere lagen van een eind- eindige omgeving.
Waarneembaarheid is en kan ook worden gezien als een onderdeel van het Data Governance-raamwerk. In deze generatie, waar het steeds groter wordende datavolume zich op een netwerk van basishardware bevindt, is het essentieel om de architecturen zo eenvoudig mogelijk te houden. En het is duidelijk dat het een onmogelijke taak wordt om het milieu in de toekomst te beheren. Het implementeren van passend en geautomatiseerd governancebeleid en -regels om uw grote netwerk van systemen, pijplijnen en gegevens overzichtelijk te houden, vereist daarom eerder dan later actie.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.dataversity.net/observability-traceability-for-distributed-systems/
- 1
- 11
- a
- in staat
- Over
- Volgens
- Bereiken
- het bereiken van
- Actie
- Extra
- Extra informatie
- adopteren
- aangenomen
- Adoptie
- komst
- Alles
- toestaat
- altijd
- analyseren
- het analyseren van
- en
- Nog een
- beantwoorden
- Aanvraag
- toepassingen
- Solliciteer
- nadering
- passend
- architectuur
- attributen
- waarmerken
- geautomatiseerde
- vermijd
- gebaseerde
- Eigenlijk
- omdat
- worden
- wordt
- begon
- BEST
- Betere
- Groot
- Big data
- Blog
- Blog Posts
- knelpunten
- bedrijfsdeskundigen
- Bellen
- oproepen
- vangen
- gevallen
- gecentraliseerde
- verandering
- Wijzigingen
- Kies
- Sluiten
- verzamelen
- Het verzamelen van
- koopwaar
- compleet
- complex
- bestanddeel
- componenten
- concept
- Bezorgdheid
- verward
- beschouwd
- aangezien
- consumptie
- verband
- doorlopend
- onder controle te houden
- Kosten
- kon
- CPU
- Culture
- Actueel
- klant
- gegevens
- Gegevensgestuurde
- databanken
- DATAVERSITEIT
- dagelijks
- dagen
- decennium
- gedecentraliseerde
- beslissingen
- deep
- diepere
- gedefinieerd
- beschrijven
- bestemming
- gegevens
- DEED
- anders
- digitaal
- Digitale Transformatie
- verdeeld
- gedistribueerde systemen
- Nee
- beneden
- gedurende
- e-commerce
- gemakkelijker
- ingebed
- omarmen
- waardoor
- eind tot eind
- Engineering
- Milieu
- fout
- fouten
- oprichting
- etc
- Zelfs
- EVENTS
- OOIT
- steeds groter
- alles
- bewijzen
- Evolutie
- voorbeeld
- duur
- ervaring
- extern
- vergemakkelijkt
- Stromen
- gevormd
- Achtergrond
- frameworks
- oppompen van
- generatie
- krijgen
- Go
- Doelen
- bestuur
- meer
- Groeit
- gebeurd
- Happening
- Hardware
- Gezondheid
- hulp
- helpt
- geschiedenis
- Hit
- hoop
- Populair
- Hoe
- How To
- Echter
- HTML
- HTTPS
- reusachtig
- afbeeldingen
- uitvoering
- belangrijk
- onmogelijk
- verbeteren
- verbetering
- in
- informatie
- op de hoogte
- inzichten
- intern
- onderzoeken
- oproept
- kwestie
- problemen
- IT
- IT management
- Houden
- kennis
- Landschap
- Groot
- groter
- Wachttijd
- lagen
- Legkippen
- Leadership
- leren
- lenzen
- Hefboomwerking
- levenscyclus van uw product
- Beperkt
- Lijn
- leven
- laden
- lang
- lot
- gemaakt
- maken
- MERKEN
- maken
- beheer
- management
- beheren
- veel
- Markt
- wiskundig
- max-width
- maatregel
- Geheugen
- Metriek
- microservices
- miljoenen
- minuten
- Grensverkeer
- monolitisch
- meest
- beweging
- bewegend
- meervoudig
- Must-have
- NATUUR
- noodzakelijk
- Noodzaak
- behoeften
- netto
- netwerk
- netwerk systeem
- New
- EEN
- operatie
- operationele
- Operations
- optimale
- optimalisatie
- organisaties
- Overige
- totaal
- het te bezitten.
- Papier
- pad
- Patronen
- betaling
- waargenomen
- prestatie
- uitvoerend
- periode
- stukken
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- Spelen
- beleidsmaatregelen door te lezen.
- arm
- mogelijk
- Post
- Berichten
- Proactieve
- probleem
- Product
- Voortgang
- zorgen voor
- biedt
- het verstrekken van
- gepubliceerde
- kwantitatief
- Contact
- liever
- Lees
- lezing
- ontvangen
- ontvangt
- betrouwbaarheid
- verwijderen
- vertegenwoordigd
- te vragen
- verzoeken
- vereist
- veerkracht
- begrensd
- resultaat
- Stijgen
- dak
- reglement
- tevredenheid
- Bespaar
- Scale
- scaling
- Ontdek
- zoeken
- Tweede
- veiligheid
- Diensten
- verscheidene
- moet
- Shows
- Eenvoudig
- single
- traag
- Klein
- So
- Software
- OPLOSSEN
- sommige
- Spoedig
- Geluid
- bron
- overspanningen
- specifiek
- besteden
- stack
- Stadium
- begin
- gestart
- Land
- Staten
- verbleef
- Still
- gestopt
- mediaopslag
- Verhaal
- structuur
- geslaagd
- system
- Systems
- Nemen
- neemt
- Taak
- teams
- Technisch
- termen
- De
- de informatie
- De Bron
- hun
- daarbij
- drie
- Door
- overal
- niet de tijd of
- tijdlijn
- naar
- vandaag
- tools
- onderwerp
- opsporen
- Traceerbaarheid
- Tracing
- Tracking
- overdracht
- Transformatie
- paraplu
- voor
- die ten grondslag liggen
- begrijpen
- bijwerken
- Gebruik
- Gebruiker
- Gebruikerservaring
- doorgaans
- waardevol
- divers
- Video's
- zichtbaarheid
- vitaal
- volume
- wachten
- Het wachten
- Website
- Wat
- Wat is
- welke
- en
- wil
- binnen
- Mijn werk
- Workforce
- Bedrijven
- wereld
- zou
- Verkeerd
- Your
- zephyrnet











