Als je een liefhebber bent van machine learning en AI, ben je vast het woord perceptron tegengekomen. Perceptron wordt onderwezen in het eerste hoofdstuk van veel deep learning-cursussen. Dus wat is het precies? Wat is de inspiratie erachter? Hoe lost het het classificatieprobleem precies op? In dit artikel gaan we beginnen met de biologische inspiratie achter het perceptron en vervolgens dieper ingaan op de wiskundige technische details ervan, en uiteindelijk een geheel nieuwe binaire classificator bouwen met behulp van een perceptron-eenheid.
Biologische inspiratie van neurale netwerken
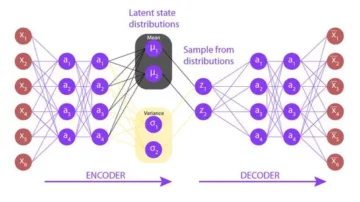
Een neuron (zenuwcel) is de fundamentele bouwsteen van het zenuwstelsel. Een menselijk brein bestaat uit miljarden neuronen die met elkaar verbonden zijn. Ze zijn verantwoordelijk voor het ontvangen en verzenden van signalen vanuit de hersenen. Zoals je in het onderstaande diagram kunt zien, bestaat een typisch neuron uit de drie hoofdonderdelen: dendrieten, een axon en een cellichaam of soma. Dendrieten zijn boomachtige takken die uit het cellichaam komen. Ze ontvangen informatie van de andere neuronen. Soma is de kern van een neuron. Het is verantwoordelijk voor het verwerken van de informatie die wordt ontvangen van dendrieten. Axon is als een kabel waardoor de neuronen de informatie verzenden. Tegen het einde splitst het axon zich op in vele takken die via hun dendrieten verbindingen maken met de andere neuronen. De De verbinding tussen het axon en andere neurondendrieten wordt synapsen genoemd.

Bron afbeelding: Willems, K. (2017, 2 mei). Keras-tutorial: diep leren in Python.
Omdat ANN zich laat inspireren door het functioneren van de hersenen, laten we eens kijken hoe de hersenen werken. De hersenen bestaan uit een netwerk van miljarden neuronen. Ze communiceren door middel van elektrische en chemische signalen via een synaps, waarin de informatie van het ene neuron wordt overgedragen naar andere neuronen. Het transmissieproces omvat een elektrische impuls die 'actiepotentiaal' wordt genoemd. Om de informatie te kunnen verzenden, moeten de ingangssignalen (impuls) sterk genoeg zijn om een bepaalde drempelbarrière te overschrijden, waarna alleen een neuron wordt geactiveerd en het signaal verder doorgeeft (output).
Geïnspireerd door de biologische werking van een neuron, bedacht de Amerikaanse wetenschapper Franck Rosenblatt in 1957 het concept van perceptron in het Cornell Aeronautical Laboratory.
- Een neuron ontvangt informatie van andere neuronen in de vorm van elektrische impulsen van verschillende sterkte.
- Neuron integreert alle impulsen die het ontvangt van de andere neuronen.
- Als de resulterende sommatie groter is dan een bepaalde drempelwaarde, 'vuurt' het neuron, waardoor een actiepotentiaal wordt geactiveerd dat wordt doorgegeven aan de andere verbonden neuronen.
Hoofdcomponenten van Perceptron
De perceptron van Rosenblatt is in feite een binaire classificator. De perceptron bestaat uit 3 hoofdonderdelen:
- Invoerknooppunten of invoerlaag: De invoerlaag neemt de initiële gegevens naar het systeem voor verdere verwerking. Elk invoerknooppunt is gekoppeld aan een numerieke waarde. Het kan elke echte waarde aannemen.
- Gewichten en bias: Gewichtsparameters vertegenwoordigen de sterkte van de verbinding tussen eenheden. Hoe hoger het gewicht, hoe sterker de invloed van het bijbehorende inputneuron om de output te bepalen. Bias speelt hetzelfde als het snijpunt in een lineaire vergelijking.
- Activeringsfunctie: De activeringsfunctie bepaalt of het neuron zal vuren of niet. In zijn eenvoudigste vorm is de activeringsfunctie een stapfunctie, maar op basis van het scenario kunnen verschillende activeringsfuncties worden gebruikt.
We zullen hierover meer zien in de volgende sectie.
Werking van een Perceptron
In de eerste stap worden alle invoerwaarden vermenigvuldigd met hun respectievelijke gewichten en bij elkaar opgeteld. Het verkregen resultaat wordt de gewogen som genoemd ∑wi*xi, of anders gezegd, x1*w1 + x2*w2 +…wn*xn. Deze som geeft een passende weergave van de inputs op basis van hun belang. Bovendien een bias-term b wordt bij deze som opgeteld ∑wi*xi + b. Bias dient als een andere modelparameter (naast gewichten) die kan worden afgestemd om de prestaties van het model te verbeteren.
In de tweede stap een activeringsfunctie f wordt toegepast op het bovenstaande bedrag ∑wi*xi + b om uitvoer Y = te verkrijgen f(∑wi*xi + b). Afhankelijk van het scenario en de gebruikte activeringsfunctie kan de uitgang is een van beide binair {1, 0} of een continue waarde.

(Vaak worden beide stappen weergegeven als een enkele stap in meerlaagse perceptrons, hier heb ik ze getoond als twee verschillende stappen voor een beter begrip)
Activeringsfuncties
Een biologisch neuron vuurt pas als een bepaalde drempel wordt overschreden. Op dezelfde manier zal het kunstmatige neuron alleen vuren als de som van de inputs (gewogen som) een bepaalde drempelwaarde overschrijdt, laten we zeggen 0. Intuïtief kunnen we een op regels gebaseerde aanpak als deze bedenken:
Als ∑wi*xi + b > 0: uitvoer = 1 anders: uitvoer = 0
De grafiek zal er ongeveer zo uitzien:

Dit is in feite de Unit Step (Threshold) activeringsfunctie die oorspronkelijk door Rosenblatt werd gebruikt. Maar zoals je kunt zien, is deze functie discontinu bij 0, en veroorzaakt dus problemen bij wiskundige berekeningen. Een vloeiendere versie van de bovenstaande functie is de sigmoïdefunctie. Het levert tussen 0 en 1. Een andere is de hyperbolische tangens (tanh) functie, die de uitvoer tussen -1 en 1 produceert. Zowel de sigmoïde- als de tanh-functies hebben last van verdwijnende gradiëntproblemen. Tegenwoordig zijn ReLU en Leaky ReLU de meest gebruikte activeringsfuncties. Ze zijn relatief stabiel over diepe netwerken.
Perceptron als binaire classificator
Tot nu toe hebben we de biologische inspiratie en de wiskunde van de perceptron gezien. In deze sectie zullen we zien hoe een perceptron een lineair classificatieprobleem oplost.
Sommige bibliotheken importeren –
van sklearn.datasets importeer make_blobs importeer matplotlib.pyplot als plt importeer numpy als np %matplotlib inline
Een dummy-gegevensset genereren met behulp van maak_blobs functionaliteit geboden door scikit learn –
# Genereer dataset X, Y = make_blobs (n_features = 2, centra = 2, n_samples = 1000, willekeurige_status = 12)
# Visualiseer dataset plt.figure(figsize = (6, 6)) plt.scatter(X[:, 0], X[:, 1], c = Y) plt.title('Ground Truth', fontsize = 18) plt.show()

Laten we zeggen dat de blauwe stippen 1-en zijn en de groene stippen 0-en. Met behulp van perceptronlogica kunnen we een beslissingsgrens creëren (hypervlak) voor classificatie die verschillende gegevenspunten in de grafiek scheidt.
Voordat we verder gaan, voegen we een bias-term (enen) toe aan de invoervector –
# Voeg een bias toe aan de invoervector X_bias = np.ones([X.shape[0], 3]) X_bias[:, 1:3] = X
De dataset zal er ongeveer zo uitzien -

Hier vertegenwoordigt elke rij van de bovenstaande dataset de invoervector (een datapunt). Om een beslissingsgrens te creëren, moeten we de juiste gewichten vinden. De gewichten worden uit de training 'geleerd' met behulp van de onderstaande regel:
w = w + (verwacht – voorspeld) * x
![]()
Het betekent dat je de geschatte uitkomst aftrekt van de grondwaarheid en deze vervolgens vermenigvuldigt met de huidige invoervector en er oude gewichten aan toevoegt om de nieuwe waarde van de gewichten te verkrijgen. Als onze uitvoer hetzelfde is als de werkelijke klasse, veranderen de gewichten niet. Maar als onze schatting afwijkt van de grondwaarheid, dan nemen de gewichten dienovereenkomstig toe of af. Op deze manier worden de gewichten in elke iteratie geleidelijk aangepast.
We beginnen met het toewijzen van willekeurige waarden aan de gewichtsvector, en passen deze vervolgens in elke iteratie geleidelijk aan met behulp van de fout en de beschikbare gegevens –
# initialiseer gewichten met willekeurige waarden w = np.random.rand(3, 1) print(w)
Output:
[[0.37547448] [0.00239401] [0.18640939]]
Definieer de activeringsfunctie van perceptron –
def activatie_func(z): als z >= 1: retourneer 1 anders: retourneer 0
Vervolgens passen we de perceptron-leerregel toe:
for _ binnen bereik(100): for i binnen bereik(X_bias.shape[0]): y = activation_func(w.transpose().dot(X_bias[i, :])) # Update gewichten w = w + (( Y[i] - y) * X_bias[i, :]).reshape(w.shape[0], 1)
Het is niet gegarandeerd dat de gewichten in één keer zullen convergeren, dus voeren we alle trainingsgegevens 100 keer in het perceptron-algoritme terwijl we voortdurend de leerregel toepassen, zodat we er uiteindelijk in slagen de optimale gewichten te verkrijgen.
Nu we de optimale gewichten hebben verkregen, kunnen we voorspel de klasse voor elk datapunt met behulp van Y = f(∑wi*xi + b) of Y = wT.x in vectorvorm.
# voorspellen van de klasse van de datapunten result_class = [activation_func(w.transpose().dot(x)) voor x in X_bias]
Visualiseer de beslissingsgrens en de voorspelde klassenlabels –
# converteren naar eenheidsvector w = w/np.sqrt(w.transpose().dot(w))
# Resultaten visualiseren plt.figure(figsize = (6, 6)) plt.scatter(X[:, 0], X[:, 1], c = result_class) plt.plot([-10, -1], hyperplane ([-10, -1], w), lw = 3, c = 'rood') plt.title('Perceptron-classificatie met beslissingsgrens') plt.show()

U kunt het beeld van de grondwaarheid vergelijken met het beeld van de voorspelde uitkomst en enkele punten zien die verkeerd zijn geclassificeerd. Als we de nauwkeurigheid berekenen, komt deze op ongeveer 98% (ik laat dit als oefening aan de lezers over).
Zie je, hier waren onze oorspronkelijke gegevens redelijk gescheiden, dus we kunnen zo'n goede nauwkeurigheid verkrijgen. Maar dit is niet het geval met gegevens uit de echte wereld. Met behulp van een enkele perceptron kunnen we alleen een lineaire beslissingsgrens construeren, dus als de gegevens met elkaar worden gemengd, zal het perceptronalgoritme slecht presteren. Dit is een van de beperkingen van het enkele perceptronmodel.
eindnoten
We begonnen met het begrijpen van de biologische inspiratie achter Rosenblatts perceptron. Daarna gingen we verder met de wiskunde van perceptron en de activeringsfuncties. Ten slotte hebben we met behulp van een speelgoeddataset gezien hoe perceptron basisclassificatie kan uitvoeren door een lineaire beslissingsgrens te bouwen die de datapunten van verschillende klassen scheidt.
Over de auteur
Pratik Nabriya is een ervaren datawetenschapper die momenteel werkt bij een analyse- en AI-bedrijf in Noida. Hij is bedreven in Machine learning, Deep learning, NLP, Time-Series Analysis, Datamanipulatie, SQL, Python en is bekend met het werken in een Cloud-omgeving. In zijn vrije tijd doet hij graag mee aan Hackathons en schrijft hij graag technische artikelen.
- "
- &
- 100
- Actie
- AI
- algoritme
- Alles
- Amerikaans
- analyse
- analytics
- dit artikel
- artikelen
- lichaam
- takken
- bouw
- Gebouw
- verandering
- chemisch
- classificatie
- Cloud
- versterken
- aansluitingen
- Actueel
- gegevens
- data scientist
- diepgaand leren
- Milieu
- Oefening
- Tot slot
- Brand
- Stevig
- Voornaam*
- formulier
- functie
- goed
- Groen
- hier
- Hoe
- HTTPS
- beeld
- Laat uw omzet
- beïnvloeden
- informatie
- Inspiratie
- IT
- Keras
- labels
- LEARN
- leren
- machine learning
- Manipulatie
- wiskunde
- Media
- Medium
- model
- netwerk
- netwerken
- Neural
- neuraal netwerk
- nlp
- knooppunten
- bestellen
- Overige
- prestatie
- Python
- lezers
- Resultaten
- So
- SQL
- begin
- gestart
- system
- Technisch
- De grafiek
- niet de tijd of
- speelgoed-
- Trainingen
- zelfstudie
- bijwerken
- us
- waarde
- Tegen
- W
- Wat is
- Bedrijven
- X