Deze driedelige serie demonstreert het gebruik van Graph Neural Networks (GNN's) en Amazone Neptunus om filmaanbevelingen te genereren met behulp van de IMDb en Box Office Mojo Movies/TV/OTT licentieerbaar datapakket, dat een breed scala aan entertainmentmetadata biedt, waaronder meer dan 1 miljard gebruikersbeoordelingen; credits voor meer dan 11 miljoen cast- en crewleden; 9 miljoen film-, tv- en amusementstitels; en wereldwijde box office-rapportagegegevens uit meer dan 60 landen. Veel AWS media- en entertainmentklanten geven licenties voor IMDb-gegevens via AWS-gegevensuitwisseling om de ontdekking van inhoud te verbeteren en de betrokkenheid en retentie van klanten te vergroten.
In Deel 1, bespraken we de toepassingen van GNN's en hoe we onze IMDb-gegevens kunnen transformeren en voorbereiden voor query's. In dit bericht bespreken we het proces van het gebruik van Neptune om inbeddingen te genereren die worden gebruikt om onze zoekopdracht buiten de catalogus in deel 3 uit te voeren. Wij gaan ook over Amazon Neptunus ML, de machine learning (ML)-functie van Neptune en de code die we gebruiken in ons ontwikkelingsproces. In deel 3 laten we zien hoe we onze inbedding van kennisgrafieken kunnen toepassen op een out-of-catalog search use case.
Overzicht oplossingen
Grote verbonden datasets bevatten vaak waardevolle informatie die moeilijk te extraheren is met behulp van query's die alleen op menselijke intuïtie zijn gebaseerd. ML-technieken kunnen helpen bij het vinden van verborgen correlaties in grafieken met miljarden relaties. Deze correlaties kunnen nuttig zijn voor het aanbevelen van producten, het voorspellen van kredietwaardigheid, het identificeren van fraude en vele andere use-cases.
Neptune ML maakt het mogelijk om in uren in plaats van weken bruikbare ML-modellen op grote grafieken te bouwen en te trainen. Om dit te bereiken, maakt Neptune ML gebruik van GNN-technologie aangedreven door Amazon Sage Maker en Diepe Grafiekbibliotheek (DGL) (dat is open source). GNN's zijn een opkomend gebied in kunstmatige intelligentie (zie voor een voorbeeld Een uitgebreid onderzoek naar neurale netwerken van grafieken). Zie voor een praktijkgerichte zelfstudie over het gebruik van GNN's met de DGL Grafische neurale netwerken leren met Deep Graph Library.
In dit bericht laten we zien hoe we Neptune in onze pijplijn kunnen gebruiken om inbeddingen te genereren.
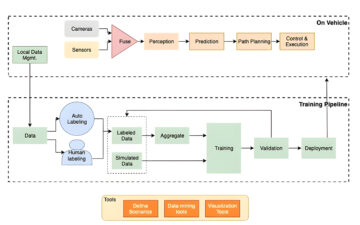
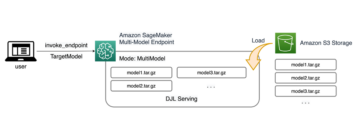
Het volgende diagram geeft de algehele stroom van IMDb-gegevens weer, van het downloaden tot het genereren van inbedding.
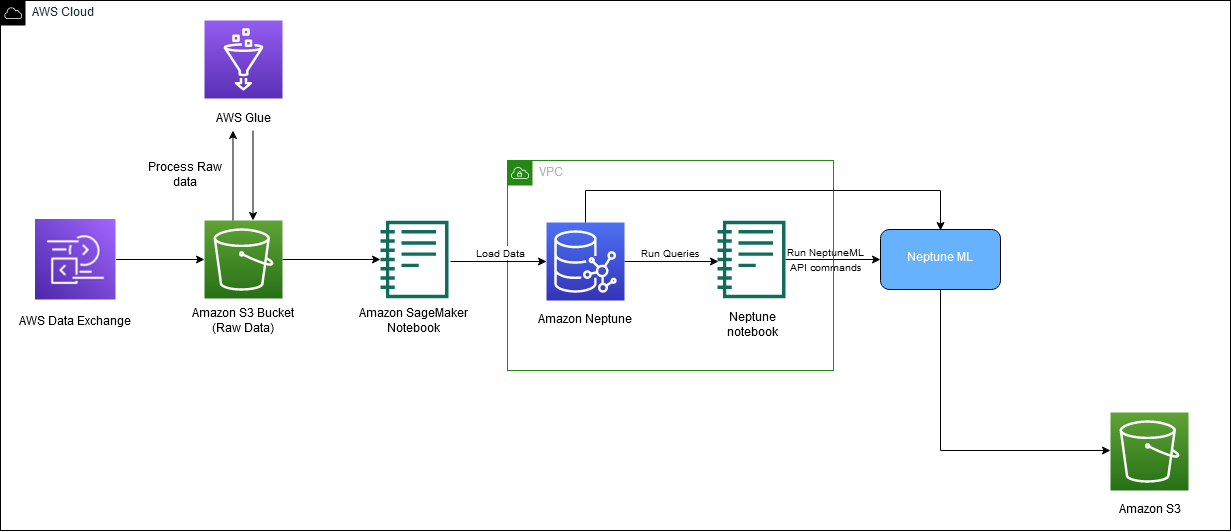
We gebruiken de volgende AWS-services om de oplossing te implementeren:
In dit bericht leiden we u door de volgende stappen op hoog niveau:
- Stel omgevingsvariabelen in
- Maak een exporttaak aan.
- Maak een gegevensverwerkingstaak aan.
- Dien een opleidingsopdracht in.
- Inbeddingen downloaden.
Code voor Neptune ML-commando's
We gebruiken de volgende opdrachten als onderdeel van het implementeren van deze oplossing:
Wij gebruiken neptune_ml export om de status te controleren of een Neptune ML-exportproces te starten, en neptune_ml training om de status van een Neptune ML-modeltrainingsopdracht te starten en te controleren.
Raadpleeg voor meer informatie over deze en andere opdrachten Neptune-werkbankmagie gebruiken in uw notitieboekjes.
Voorwaarden
Om dit bericht te volgen, zou je het volgende moeten hebben:
- An AWS-account
- Bekendheid met SageMaker, Amazon S3 en AWS CloudFormation
- Grafiekgegevens geladen in de Neptune-cluster (zie Deel 1 voor meer informatie)
Stel omgevingsvariabelen in
Voordat we beginnen, moet u uw omgeving instellen door de volgende variabelen in te stellen: s3_bucket_uri en processed_folder. s3_bucket_uri is de naam van de emmer die in deel 1 wordt gebruikt en processed_folder is de Amazon S3-locatie voor de uitvoer van de exporttaak.
Maak een exporttaak aan
In deel 1 hebben we een SageMaker-notebook en exportservice gemaakt om onze gegevens van het Neptune DB-cluster naar Amazon S3 in het vereiste formaat te exporteren.
Nu onze gegevens zijn geladen en de exportservice is gemaakt, moeten we een exporttaak maken om deze te starten. Hiervoor gebruiken we NeptuneExportApiUri en maak parameters voor de exporttaak. In de volgende code gebruiken we de variabelen expo en export_params. reeks expo aan jouw NeptuneExportApiUri waarde, die u kunt vinden op de Uitgangen tabblad van uw CloudFormation-stack. Voor export_params, gebruiken we het eindpunt van uw Neptune-cluster en geven we de waarde voor outputS3path, de Amazon S3-locatie voor de uitvoer van de exporttaak.
Gebruik de volgende opdracht om de exporttaak in te dienen:
Gebruik de volgende opdracht om de status van de exporttaak te controleren:
Nadat uw taak is voltooid, stelt u de processed_folder variabele om de Amazon S3-locatie van de verwerkte resultaten te geven:
Maak een gegevensverwerkingstaak aan
Nu de export is voltooid, maken we een gegevensverwerkingstaak om de gegevens voor te bereiden op het Neptune ML-trainingsproces. Dit kan op een aantal verschillende manieren. Voor deze stap kunt u de job_name en modelType variabelen, maar alle andere parameters moeten hetzelfde blijven. Het belangrijkste deel van deze code is de modelType parameter, die ofwel heterogene grafiekmodellen kunnen zijn (heterogeneous) of kennisgrafieken (kge).
De exporttaak omvat ook training-data-configuration.json. Gebruik dit bestand om knooppunten of randen toe te voegen of te verwijderen die u niet voor training wilt gebruiken (als u bijvoorbeeld de koppeling tussen twee knooppunten wilt voorspellen, kunt u die koppeling in dit configuratiebestand verwijderen). Voor deze blogpost gebruiken we het originele configuratiebestand. Voor meer informatie, zie Een trainingsconfiguratiebestand bewerken.
Maak uw gegevensverwerkingstaak aan met de volgende code:
Gebruik de volgende opdracht om de status van de exporttaak te controleren:
Dien een opleidingsopdracht in
Nadat de verwerkingstaak is voltooid, kunnen we beginnen met onze trainingstaak, waar we onze inbeddingen maken. We raden het instantietype ml.m5.24xlarge aan, maar u kunt dit aanpassen aan uw computerbehoeften. Zie de volgende code:
We drukken de variabele training_results af om de ID voor de trainingstaak te krijgen. Gebruik de volgende opdracht om de status van uw taak te controleren:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Inbeddingen downloaden
Nadat uw trainingstaak is voltooid, is de laatste stap het downloaden van uw onbewerkte inbeddingen. De volgende stappen laten zien hoe u insluitingen kunt downloaden die zijn gemaakt met KGE (u kunt hetzelfde proces gebruiken voor RGCN).
In de volgende code gebruiken we neptune_ml.get_mapping() en get_embeddings() om het toewijzingsbestand te downloaden (mapping.info) en het bestand met onbewerkte inbeddingen (entity.npy). Vervolgens moeten we de juiste inbeddingen toewijzen aan hun overeenkomstige ID's.
Om RGCN's te downloaden, volgt u hetzelfde proces met een nieuwe trainingstaaknaam door de gegevens te verwerken met de parameter modelType ingesteld op heterogeneous, en train vervolgens uw model met de parameter modelName ingesteld op rgcn zien hier voor meer details. Als dat klaar is, belt u de get_mapping en get_embeddings functies om uw nieuwe te downloaden mapping.info en entiteit.npy bestanden. Nadat u de entiteits- en toewijzingsbestanden hebt, is het proces voor het maken van het CSV-bestand identiek.
Upload ten slotte uw inbeddingen naar uw gewenste Amazon S3-locatie:
Zorg ervoor dat u deze S3-locatie onthoudt, u zult deze in deel 3 moeten gebruiken.
Opruimen
Wanneer u klaar bent met het gebruik van de oplossing, moet u alle bronnen opschonen om lopende kosten te voorkomen.
Conclusie
In dit bericht hebben we besproken hoe Neptune ML kan worden gebruikt om GNN-inbeddingen van IMDb-gegevens te trainen.
Sommige verwante toepassingen van inbedding van kennisgrafieken zijn concepten zoals zoeken buiten de catalogus, inhoudsaanbevelingen, gerichte advertenties, het voorspellen van ontbrekende links, algemeen zoeken en cohortanalyse. Zoeken buiten de catalogus is het zoeken naar inhoud die niet van u is, en het vinden of aanbevelen van inhoud in uw catalogus die zo dicht mogelijk aansluit bij wat de gebruiker zocht. In deel 3 gaan we dieper in op zoeken buiten de catalogus.
Over de auteurs
 Matthijs Rhodos is een datawetenschapper die ik werk in het Amazon ML Solutions Lab. Hij is gespecialiseerd in het bouwen van Machine Learning-pijplijnen met concepten als Natural Language Processing en Computer Vision.
Matthijs Rhodos is een datawetenschapper die ik werk in het Amazon ML Solutions Lab. Hij is gespecialiseerd in het bouwen van Machine Learning-pijplijnen met concepten als Natural Language Processing en Computer Vision.
 Divya Bhargavi is Data Scientist en Media and Entertainment Vertical Lead bij het Amazon ML Solutions Lab, waar ze hoogwaardige zakelijke problemen voor AWS-klanten oplost met behulp van Machine Learning. Ze werkt aan het begrijpen van afbeeldingen/video's, aanbevelingssystemen voor kennisgrafieken en gebruiksscenario's voor voorspellende advertenties.
Divya Bhargavi is Data Scientist en Media and Entertainment Vertical Lead bij het Amazon ML Solutions Lab, waar ze hoogwaardige zakelijke problemen voor AWS-klanten oplost met behulp van Machine Learning. Ze werkt aan het begrijpen van afbeeldingen/video's, aanbevelingssystemen voor kennisgrafieken en gebruiksscenario's voor voorspellende advertenties.
 Gaurav Rele is een datawetenschapper bij het Amazon ML Solution Lab, waar hij samenwerkt met AWS-klanten in verschillende branches om hun gebruik van machine learning en AWS Cloud-services te versnellen om hun zakelijke uitdagingen op te lossen.
Gaurav Rele is een datawetenschapper bij het Amazon ML Solution Lab, waar hij samenwerkt met AWS-klanten in verschillende branches om hun gebruik van machine learning en AWS Cloud-services te versnellen om hun zakelijke uitdagingen op te lossen.
 Karan Sindwani is een Data Scientist bij Amazon ML Solutions Lab, waar hij deep learning-modellen bouwt en implementeert. Hij is gespecialiseerd op het gebied van computervisie. In zijn vrije tijd houdt hij van wandelen.
Karan Sindwani is een Data Scientist bij Amazon ML Solutions Lab, waar hij deep learning-modellen bouwt en implementeert. Hij is gespecialiseerd op het gebied van computervisie. In zijn vrije tijd houdt hij van wandelen.
 Soji Adeshin is een toegepaste wetenschapper bij AWS, waar hij op grafische neurale netwerken gebaseerde modellen ontwikkelt voor machine learning op grafische taken met toepassingen voor fraude en misbruik, kennisgrafieken, aanbevelingssystemen en levenswetenschappen. In zijn vrije tijd houdt hij van lezen en koken.
Soji Adeshin is een toegepaste wetenschapper bij AWS, waar hij op grafische neurale netwerken gebaseerde modellen ontwikkelt voor machine learning op grafische taken met toepassingen voor fraude en misbruik, kennisgrafieken, aanbevelingssystemen en levenswetenschappen. In zijn vrije tijd houdt hij van lezen en koken.
 Vidya Sagar Ravipati is een manager bij het Amazon ML Solutions Lab, waar hij zijn enorme ervaring in grootschalige gedistribueerde systemen en zijn passie voor machine learning gebruikt om AWS-klanten in verschillende branches te helpen hun AI- en cloud-adoptie te versnellen.
Vidya Sagar Ravipati is een manager bij het Amazon ML Solutions Lab, waar hij zijn enorme ervaring in grootschalige gedistribueerde systemen en zijn passie voor machine learning gebruikt om AWS-klanten in verschillende branches te helpen hun AI- en cloud-adoptie te versnellen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Over
- misbruik
- versnellen
- over
- Extra
- Extra informatie
- Adoptie
- Advertising
- Na
- AI
- Alles
- alleen
- Amazone
- Amazon ML Solutions-lab
- analyse
- en
- toepassingen
- toegepast
- Solliciteer
- passend
- GEBIED
- kunstmatig
- kunstmatige intelligentie
- AWS
- gebaseerde
- tussen
- Miljard
- miljarden
- Blog
- Box camera's
- box office
- bouw
- Gebouw
- bouwt
- bedrijfsdeskundigen
- Bellen
- geval
- gevallen
- catalogus
- uitdagingen
- verandering
- lasten
- controle
- Sluiten
- Cloud
- cloud adoptie
- cloud-diensten
- TROS
- code
- cohorte
- compleet
- uitgebreid
- computer
- Computer visie
- computergebruik
- concepten
- Gedrag
- Configuratie
- gekoppeld blijven
- content
- Overeenkomend
- landen
- en je merk te creëren
- aangemaakt
- Credits
- credits
- klant
- Klantbinding
- Klanten
- gegevens
- gegevensverwerking
- data scientist
- datasets
- deep
- diepgaand leren
- diepere
- ontplooit
- gegevens
- Ontwikkeling
- ontwikkelt
- Leuk vinden
- anders
- ontdekking
- bespreken
- besproken
- verdeeld
- gedistribueerde systemen
- Dont
- Download
- beide
- opkomende
- Endpoint
- engagement
- Onstpanning
- entiteit
- Milieu
- Ether (ETH)
- voorbeeld
- ervaring
- exporteren
- extract
- Kenmerk
- weinig
- veld-
- Dien in
- Bestanden
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- het vinden van
- stroom
- volgen
- volgend
- formaat
- bedrog
- oppompen van
- vol
- functies
- Algemeen
- voortbrengen
- generatie
- krijgen
- Globaal
- Go
- diagram
- grafieken
- hands-on
- Hard
- hulp
- nuttig
- verborgen
- high-level
- HOURS
- Hoe
- How To
- HTML
- HTTPS
- menselijk
- identiek
- het identificeren van
- uitvoeren
- uitvoering
- verbeteren
- in
- omvat
- Inclusief
- Laat uw omzet
- index
- -industrie
- info
- informatie
- instantie
- verkrijgen in plaats daarvan
- Intelligentie
- betrekken
- IT
- Jobomschrijving:
- json
- sleutel
- kennis
- laboratorium
- taal
- Groot
- grootschalig
- Achternaam*
- leiden
- leren
- hefbomen
- Bibliotheek
- Vergunning
- Life
- Bio
- LINK
- links
- plaats
- machine
- machine learning
- Hoofd
- MERKEN
- manager
- veel
- kaart
- in kaart brengen
- Media
- Medium
- Leden
- Metadata
- miljoen
- vermist
- ML
- model
- modellen
- meer
- filmpje
- naam
- Naturel
- Natural Language Processing
- Noodzaak
- behoeften
- Neptunus
- netwerkgebaseerd
- netwerken
- neurale netwerken
- New
- knooppunten
- notitieboekje
- Kantoor
- lopend
- origineel
- Overige
- totaal
- het te bezitten.
- pakket
- parameter
- parameters
- deel
- passie
- pijpleiding
- Plato
- Plato gegevensintelligentie
- PlatoData
- mogelijk
- Post
- energie
- aangedreven
- voorspellen
- het voorspellen van
- Voorbereiden
- problemen
- verwerking
- Producten
- Profiel
- zorgen voor
- biedt
- reeks
- waarderingen
- Rauw
- lezing
- adviseren
- Aanbeveling
- aanbevelingen
- bevelen
- verwant
- Relaties
- blijven
- niet vergeten
- verwijderen
- Rapportage
- nodig
- Resources
- Resultaten
- behoud
- sagemaker
- dezelfde
- WETENSCHAPPEN
- Wetenschapper
- Ontdek
- zoeken
- -Series
- service
- Diensten
- reeks
- het instellen van
- moet
- tonen
- oplossing
- Oplossingen
- OPLOSSEN
- Lost op
- specialiseert
- stack
- begin
- Status
- Stap voor
- Stappen
- shop
- voorleggen
- dergelijk
- Pak
- Enquête
- Systems
- doelgerichte
- taken
- technieken
- Technologie
- De
- De omgeving
- hun
- Door
- niet de tijd of
- titels
- naar
- Trainen
- Trainingen
- Transformeren
- waar
- zelfstudie
- tv
- begrip
- .
- use case
- Gebruiker
- waardevol
- waarde
- groot
- versie
- verticals
- visie
- manieren
- weken
- Wat
- welke
- breed
- Grote range
- wil
- werkzaam
- Bedrijven
- Your
- zephyrnet