Afbeelding door auteur
Evaluatiestatistieken zijn vergelijkbaar met de meetinstrumenten die we gebruiken om te begrijpen hoe goed een machine learning-model zijn werk doet. Ze helpen ons verschillende modellen te vergelijken en erachter te komen welke het beste werkt voor een bepaalde taak. In de wereld van classificatieproblemen zijn er enkele veelgebruikte metrieken om te zien hoe goed een model is, en het is essentieel om te weten welke metriek geschikt is voor ons specifieke probleem. Wanneer we de details van elke metriek begrijpen, wordt het gemakkelijker om te beslissen welke overeenkomt met de behoeften van onze taak.
In dit artikel zullen we de basisevaluatiemetrieken onderzoeken die worden gebruikt bij classificatietaken en situaties onderzoeken waarin de ene metriek relevanter zou kunnen zijn dan de andere.
Voordat we diep in evaluatiestatistieken duiken, is het van cruciaal belang om de basisterminologie te begrijpen die verband houdt met een classificatieprobleem.
Ground Truth-labels: Deze verwijzen naar de daadwerkelijke labels die overeenkomen met elk voorbeeld in onze dataset. Deze vormen de basis van alle evaluaties en voorspellingen worden vergeleken met deze waarden.
Voorspelde labels: Dit zijn de klasselabels die zijn voorspeld met behulp van het machine learning-model voor elk voorbeeld in onze dataset. We vergelijken dergelijke voorspellingen met de ground-truth-labels met behulp van verschillende evaluatiestatistieken om te berekenen of het model de representaties in onze gegevens kan leren.
Laten we nu alleen een binair classificatieprobleem bekijken voor een beter begrip. Met slechts twee verschillende klassen in onze dataset kan het vergelijken van ground-truth-labels met voorspelde labels resulteren in een van de volgende vier uitkomsten, zoals geïllustreerd in het diagram.

Afbeelding door auteur: Als u 1 gebruikt om een positief label aan te duiden en 0 voor een negatief label, kunnen de voorspellingen in een van de vier categorieën vallen.
Echte positieve punten: Het model voorspelt een positief klassenlabel als de grondwaarheid ook positief is. Dit is het vereiste gedrag omdat het model met succes een positief label kan voorspellen.
Valse positieven: Het model voorspelt een positief klassenlabel wanneer het grondwaarheidslabel negatief is. Het model identificeert een gegevensmonster ten onrechte als positief.
Valse negatieven: Het model voorspelt een negatief klassenlabel voor een positief voorbeeld. Het model identificeert een gegevensmonster ten onrechte als negatief.
Echte minpunten: Ook het vereiste gedrag. Het model identificeert correct een negatief monster en voorspelt 0 voor een gegevensmonster met een grondwaarheidslabel van 0.
Nu kunnen we op deze termen voortbouwen om te begrijpen hoe algemene evaluatiestatistieken werken.
Dit is de meest eenvoudige maar toch intuïtieve manier om de prestaties van een model voor classificatieproblemen te beoordelen. Het meet het aandeel van het totale aantal labels dat het model correct heeft voorspeld.
Daarom kan de nauwkeurigheid als volgt worden berekend:
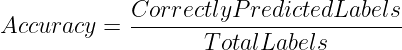
or
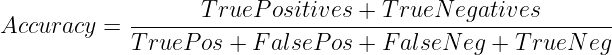
Wanneer te gebruiken
- Initiële modelbeoordeling
Gezien zijn eenvoud is nauwkeurigheid een veelgebruikte maatstaf. Het biedt een goed startpunt om te verifiëren of het model goed kan leren voordat we metrieken gebruiken die specifiek zijn voor ons probleemdomein.
- Evenwichtige datasets
Nauwkeurigheid is alleen geschikt voor gebalanceerde datasets waarbij alle klassenlabels in vergelijkbare verhoudingen staan. Als dat niet het geval is, en één klassenlabel aanzienlijk groter is dan de andere, kan het model nog steeds een hoge nauwkeurigheid bereiken door altijd de meerderheidsklasse te voorspellen. De nauwkeurigheidsmetriek bestraft in gelijke mate de verkeerde voorspellingen voor elke klasse, waardoor deze ongeschikt wordt voor onevenwichtige datasets.
- Wanneer de kosten voor verkeerde classificatie gelijk zijn
Nauwkeurigheid is geschikt voor gevallen waarin valse positieven of valse negatieven even slecht zijn. Voor een sentimentanalyseprobleem is het bijvoorbeeld even slecht als we een negatieve tekst als positief of een positieve tekst als negatief classificeren. Voor dergelijke scenario's is nauwkeurigheid een goede maatstaf.
Precisie is erop gericht ervoor te zorgen dat alle positieve voorspellingen correct zijn. Het meet welk deel van de positieve voorspellingen daadwerkelijk positief was.
Wiskundig wordt het weergegeven als

Wanneer te gebruiken
- Hoge kosten van valse positieven
Beschouw een scenario waarin we een model trainen om kanker te detecteren. Het zal voor ons belangrijker zijn dat we een patiënt die geen kanker heeft, niet verkeerd classificeren, d.w.z. Vals-positief. We willen met vertrouwen een positieve voorspelling doen, omdat het ten onrechte classificeren van een persoon als kankerpositief kan leiden tot onnodige stress en kosten. Daarom hechten we er veel waarde aan dat we alleen een positief label voorspellen als het daadwerkelijke label positief is.
- Kwaliteit boven kwantiteit
Overweeg een ander scenario waarin we een zoekmachine bouwen die zoekopdrachten van gebruikers koppelt aan een dataset. In dergelijke gevallen hechten wij er waarde aan dat de zoekresultaten nauw aansluiten bij de zoekopdracht van de gebruiker. We willen geen enkel document retourneren dat niet relevant is voor de gebruiker, d.w.z. False Positive. Daarom voorspellen we alleen positief voor documenten die nauw aansluiten bij de zoekopdracht van de gebruiker. We waarderen kwaliteit boven kwantiteit, omdat we de voorkeur geven aan een klein aantal nauw verwante resultaten in plaats van een groot aantal resultaten die wel of niet relevant zijn voor de gebruiker. Voor dergelijke scenario's willen we hoge precisie.
Recall, ook bekend als Sensitivity, meet hoe goed een model de positieve labels in de dataset kan onthouden. Het meet welk deel van de positieve labels in onze dataset door het model als positief wordt voorspeld.
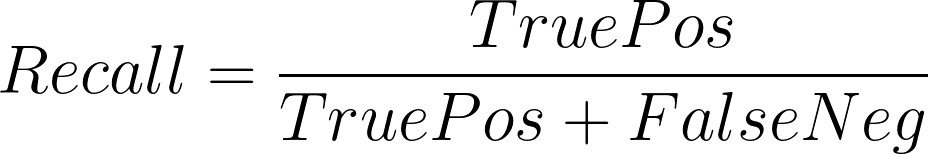
Een hogere terugroepactie betekent dat het model beter kan onthouden welke gegevensmonsters positieve labels hebben.
Wanneer te gebruiken
- Hoge kosten van valse negatieven
We gebruiken Recall wanneer het missen van een positief label ernstige gevolgen kan hebben. Overweeg een scenario waarin we een Machine Learning-model gebruiken om creditcardfraude op te sporen. In dergelijke gevallen is het vroegtijdig opsporen van problemen essentieel. We willen een frauduleuze transactie niet missen, omdat deze de verliezen kan vergroten. Daarom waarderen we Recall boven precisie, waarbij de verkeerde classificatie van een transactie als bedrieglijk gemakkelijk te verifiëren is en we ons een paar valse positieven kunnen veroorloven in plaats van valse negatieven.
Het is het harmonische gemiddelde van Precision en Recall. Het bestraft modellen die een aanzienlijke onevenwichtigheid tussen beide metrieken hebben.
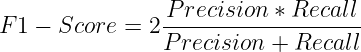
Het wordt veel gebruikt in scenario's waarin zowel precisie als herinnering belangrijk zijn en het mogelijk maakt een evenwicht tussen beide te bereiken.
Wanneer te gebruiken
- Ongebalanceerde datasets
In tegenstelling tot nauwkeurigheid is de F1-Score geschikt voor het beoordelen van onevenwichtige datasets, omdat we de prestaties evalueren op basis van het vermogen van het model om de minderheidsklasse te herinneren, terwijl we over het algemeen een hoge precisie behouden.
- Afweging tussen precisie en terugroepen
Beide maatstaven zijn tegengesteld aan elkaar. Empirisch gezien kan het verbeteren van het ene vaak leiden tot verslechtering van het andere. F1-Score helpt bij het balanceren van beide statistieken en is nuttig in scenario's waarin zowel Recall als Precision even belangrijk zijn. Als we bij de berekening rekening houden met beide statistieken, is de F1-Score een veelgebruikte maatstaf voor het evalueren van classificatiemodellen.
We hebben geleerd dat verschillende evaluatiestatistieken specifieke taken hebben. Als we deze statistieken kennen, kunnen we de juiste kiezen voor onze taak. In het echte leven gaat het niet alleen om het hebben van goede modellen; het gaat erom dat we modellen hebben die perfect bij onze zakelijke behoeften passen. Het kiezen van de juiste maatstaf is dus hetzelfde als het kiezen van de juiste tool om ervoor te zorgen dat ons model het goed doet waar het er het meest toe doet.
Weet u nog steeds niet welke statistiek u moet gebruiken? Beginnen met nauwkeurigheid is een goede eerste stap. Het biedt basiskennis van de prestaties van uw model. Van daaruit kunt u uw evaluatie afstemmen op uw specifieke vereisten. U kunt ook de F1-Score overwegen, die dient als een veelzijdige maatstaf die een balans vindt tussen precisie en herinnering, waardoor deze geschikt is voor verschillende scenario's. Het kan uw favoriete hulpmiddel zijn voor uitgebreide classificatie-evaluatie.
Mohammed Arham is een Deep Learning Engineer die werkt in Computer Vision en Natural Language Processing. Hij heeft gewerkt aan de implementatie en optimalisatie van verschillende generatieve AI-applicaties die de wereldwijde toplijsten bereikten bij Vyro.AI. Hij is geïnteresseerd in het bouwen en optimaliseren van machine learning-modellen voor intelligente systemen en gelooft in continue verbetering.
Mohammed Arham is een Deep Learning Engineer die werkt in Computer Vision en Natural Language Processing. Hij heeft gewerkt aan de implementatie en optimalisatie van verschillende generatieve AI-applicaties die de wereldwijde toplijsten bereikten bij Vyro.AI. Hij is geïnteresseerd in het bouwen en optimaliseren van machine learning-modellen voor intelligente systemen en gelooft in continue verbetering.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/understanding-classification-metrics-your-guide-to-assessing-model-accuracy?utm_source=rss&utm_medium=rss&utm_campaign=understanding-classification-metrics-your-guide-to-assessing-model-accuracy
- : heeft
- :is
- :niet
- :waar
- 1
- a
- vermogen
- Over
- Account
- nauwkeurigheid
- Bereiken
- het bereiken van
- daadwerkelijk
- werkelijk
- veroorloven
- AI
- AIDS
- Alles
- toestaat
- ook
- altijd
- an
- analyse
- en
- Nog een
- elke
- toepassingen
- ZIJN
- dit artikel
- AS
- Het beoordelen
- geassocieerd
- At
- auteur
- slecht
- Balance
- evenwichtige
- balancing
- gebaseerde
- basis-
- basis
- BE
- wordt
- vaardigheden
- gedrag
- gelooft
- BEST
- Betere
- tussen
- zowel
- bouw
- Gebouw
- bedrijfsdeskundigen
- by
- berekenen
- berekening
- CAN
- Kanker
- kaart
- geval
- gevallen
- categorieën
- Grafieken
- Kies
- het kiezen van
- klasse
- klassen
- classificatie
- classificeren
- van nabij
- Gemeen
- algemeen
- vergelijken
- vergelijk anders
- vergeleken
- vergelijken
- uitgebreid
- computer
- Computer visie
- zeker
- verward
- Gevolgen
- Overwegen
- te corrigeren
- correct
- Overeenkomend
- Kosten
- Kosten
- kon
- Credits
- creditkaart
- kritisch
- gegevens
- datasets
- beslissen
- deep
- diepgaand leren
- inzet
- gegevens
- opsporen
- Opsporing
- anders
- duiken
- do
- document
- documenten
- doet
- doen
- domein
- e
- elk
- Vroeg
- gemakkelijker
- En het is heel gemakkelijk
- beide
- Motor
- ingenieur
- zorgen
- even
- essentieel
- evalueren
- evaluatie
- onderzoeken
- voorbeeld
- kosten
- Verken
- Vallen
- vals
- weinig
- Figuur
- geschikt
- richt
- volgend
- volgt
- Voor
- vier
- fractie
- bedrog
- frauduleus
- oppompen van
- generatief
- generatieve AI
- krijgen
- Globaal
- goed
- grijpen
- Ground
- gids
- Hebben
- met
- he
- hulp
- helpt
- Vandaar
- Hoge
- hoger
- zeer
- Hoe
- HTTPS
- i
- identificeert
- if
- onbalans
- belangrijk
- verbetering
- het verbeteren van
- in
- Laat uw omzet
- eerste
- verkrijgen in plaats daarvan
- Intelligent
- geïnteresseerd
- in
- intuïtief
- problemen
- IT
- HAAR
- Jobomschrijving:
- Vacatures
- voor slechts
- KDnuggets
- blijven
- Weten
- bekend
- label
- labels
- taal
- leiden
- LEARN
- geleerd
- leren
- laten
- Life
- als
- verliezen
- machine
- machine learning
- behoud van
- Meerderheid
- maken
- maken
- Match
- lucifers
- matching
- Zaken
- Mei..
- gemiddelde
- middel
- maatregelen
- het meten van
- metriek
- Metriek
- macht
- minderheid
- missen
- vermist
- model
- modellen
- meer
- meest
- Naturel
- Natuurlijke taal
- Natural Language Processing
- behoeften
- negatief
- negatieven
- aantal
- of
- vaak
- on
- EEN
- Slechts
- tegenover
- optimaliseren
- or
- Overige
- Overig
- onze
- uit
- resultaten
- over
- totaal
- bijzonder
- patiënt
- volmaakt
- prestatie
- persoon
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- positief
- precisie
- voorspellen
- voorspeld
- het voorspellen van
- voorspelling
- Voorspellingen
- voorspelt
- de voorkeur geven
- probleem
- problemen
- verwerking
- proportie
- biedt
- kwaliteit
- hoeveelheid
- queries
- bereikt
- vast
- echte leven
- verwijzen
- verwant
- relevante
- niet vergeten
- herinneren
- vertegenwoordigd
- nodig
- Voorwaarden
- resultaat
- Resultaten
- terugkeer
- rechts
- s
- scenario
- scenario's
- Ontdek
- zoekmachine
- zien
- Gevoeligheid
- sentiment
- bedient
- verscheidene
- streng
- aanzienlijke
- aanzienlijk
- gelijk
- Eenvoudig
- eenvoud
- situaties
- Klein
- So
- sommige
- specifiek
- Start
- Stap voor
- Still
- spanning
- Met goed gevolg
- dergelijk
- geschikt
- zeker
- Systems
- het nemen
- Taak
- taken
- terminologie
- termen
- tekst
- neem contact
- dat
- De
- de wereld
- Er.
- daarom
- Deze
- ze
- dit
- naar
- tools
- tools
- top
- Totaal
- Trainingen
- transactie
- waarheid
- twee
- begrijpen
- begrip
- onnodig
- op
- us
- .
- gebruikt
- nuttig
- Gebruiker
- gebruik
- waarde
- Values
- divers
- Ve
- controleren
- het verifiëren
- veelzijdig
- visie
- willen
- Manier..
- we
- GOED
- waren
- Wat
- wanneer
- welke
- en
- WIE
- wijd
- wil
- Met
- Mijn werk
- werkte
- werkzaam
- Bedrijven
- wereld
- Verkeerd
- nog
- u
- Your
- zephyrnet