Apache-ijsberg is een open tabelformaat voor zeer grote analytische datasets, dat metadata-informatie vastlegt over de status van datasets naarmate ze evolueren en in de loop van de tijd veranderen. Het voegt tabellen toe aan rekenengines, waaronder Spark, Trino, PrestoDB, Flink en Hive, met behulp van een krachtige tabelindeling die net als een SQL-tabel werkt. Iceberg is erg populair geworden vanwege de ondersteuning voor ACID-transacties in datameren en functies zoals schema- en partitie-evolutie, tijdreizen en terugdraaien.
Apache Iceberg-integratie wordt ondersteund door AWS-analyseservices, waaronder Amazon EMR, Amazone Athene en AWS lijm. Amazon EMR kan clusters inrichten met Spark, Hive, Trino en Flink waarop Iceberg kan draaien. Vanaf Amazon EMR versie 6.5.0 kan dat gebruik Iceberg met uw EMR-cluster zonder dat een bootstrap-actie nodig is. Begin 2022 kondigde AWS de algemene beschikbaarheid aan van Athena ACID-transacties, mogelijk gemaakt door Apache Iceberg. De onlangs uitgebrachte Athena-query-engine versie 3 zorgt voor een betere integratie met het Iceberg-tabelformaat. AWS Glue 3.0 en hoger ondersteunt het Apache Iceberg-framework voor datameren.
In dit bericht bespreken we wat klanten willen in moderne datalakes en hoe Apache Iceberg helpt om tegemoet te komen aan de behoeften van klanten. Vervolgens lopen we door een oplossing om een krachtig en evoluerend Iceberg-datameer op te bouwen Amazon eenvoudige opslagservice (Amazon S3) en verwerk incrementele gegevens door SQL-instructies in te voegen, bij te werken en te verwijderen. Ten slotte laten we u zien hoe u de prestaties van het proces kunt afstemmen om de lees- en schrijfprestaties te verbeteren.
Hoe Apache Iceberg inspeelt op wat klanten willen in moderne datameren
Steeds meer klanten bouwen datameren, met gestructureerde en ongestructureerde data, om veel gebruikers, applicaties en analysetools te ondersteunen. Er is een grotere behoefte aan data lakes ter ondersteuning van database-achtige functies zoals ACID-transacties, updates en verwijderingen op recordniveau, tijdreizen en rollback. Apache Iceberg is ontworpen om deze functies te ondersteunen op kosteneffectieve datameren op petabyte-schaal op Amazon S3.
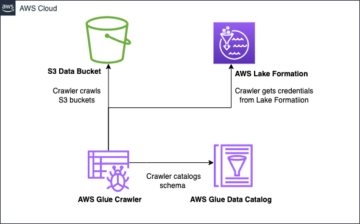
Apache Iceberg komt tegemoet aan de behoeften van de klant door rijke metadata-informatie over de dataset vast te leggen op het moment dat de individuele databestanden worden gemaakt. Er zijn drie lagen in de architectuur van een Iceberg-tabel: de Iceberg-catalogus, de metagegevenslaag en de gegevenslaag, zoals weergegeven in de volgende afbeelding ((bron)).

De Iceberg-catalogus slaat de metagegevenswijzer op naar het huidige metagegevensbestand van de tabel. Wanneer een geselecteerde query een Iceberg-tabel leest, gaat de query-engine eerst naar de Iceberg-catalogus en haalt vervolgens de locatie van het huidige metadatabestand op. Telkens wanneer er een update is voor de Iceberg-tabel, wordt er een nieuwe momentopname van de tabel gemaakt en wijst de metagegevensaanwijzer naar het huidige metagegevensbestand van de tabel.
Het volgende is een voorbeeld van een Iceberg-catalogus met AWS Glue-implementatie. U kunt de databasenaam, de locatie (S3-pad) van de Iceberg-tabel en de locatie van de metagegevens zien.

De metagegevenslaag heeft drie typen bestanden: het metagegevensbestand, de manifestlijst en het manifestbestand in een hiërarchie. Bovenaan de hiërarchie bevindt zich het metadatabestand, waarin informatie wordt opgeslagen over het schema van de tabel, partitie-informatie en snapshots. De momentopname verwijst naar de manifestlijst. De manifestlijst bevat de informatie over elk manifestbestand waaruit de momentopname bestaat, zoals de locatie van het manifestbestand, de partities waartoe het behoort en de onder- en bovengrenzen voor partitiekolommen voor de gegevensbestanden die het bijhoudt. Het manifestbestand houdt gegevensbestanden bij, evenals aanvullende details over elk bestand, zoals de bestandsindeling. Alle drie de bestanden werken in een hiërarchie om de snapshots, schema's, partitionering, eigenschappen en gegevensbestanden in een Iceberg-tabel bij te houden.
De gegevenslaag bevat de afzonderlijke gegevensbestanden van de ijsbergtabel. Iceberg ondersteunt een breed scala aan bestandsindelingen, waaronder Parquet, ORC en Avro. Omdat de Iceberg-tabel de individuele gegevensbestanden bijhoudt in plaats van alleen naar de partitielocatie met gegevensbestanden te wijzen, isoleert het de schrijfbewerkingen van leesbewerkingen. U kunt de gegevensbestanden op elk moment schrijven, maar de wijziging alleen expliciet doorvoeren, waardoor een nieuwe versie van de momentopname- en metagegevensbestanden wordt gemaakt.
Overzicht oplossingen
In dit bericht laten we je een oplossing zien voor het bouwen van een goed presterend Apache Iceberg-datameer op Amazon S3; incrementele gegevens verwerken met SQL-statements voor invoegen, bijwerken en verwijderen; en stem de Iceberg-tabel af om de lees- en schrijfprestaties te verbeteren. Het volgende diagram illustreert de oplossingsarchitectuur.

Om deze oplossing te demonstreren, gebruiken we de Amazon Klant recensies gegevensset in een S3-bucket (s3://amazon-reviews-pds/parquet/). In het echte gebruik zouden het onbewerkte gegevens zijn die zijn opgeslagen in uw S3-bucket. We kunnen de gegevensgrootte controleren met de volgende code in de AWS-opdrachtregelinterface (AWS-CLI):
Het totale aantal objecten is 430 en de totale grootte is 47.4 GiB.
Om deze oplossing in te stellen en te testen, doorlopen we de volgende stappen op hoog niveau:
- Stel een S3-bucket in de beheerde zone in om geconverteerde gegevens op te slaan in de indeling Iceberg-tabel.
- Start een EMR-cluster met de juiste configuraties voor Apache Iceberg.
- Maak een notitieboek in EMR Studio.
- Configureer de Spark-sessie voor Apache Iceberg.
- Converteer gegevens naar het Iceberg-tabelformaat en verplaats gegevens naar de beheerde zone.
- Voer insert-, update- en delete-query's uit in Athena om incrementele gegevens te verwerken.
- Prestatieafstemming uitvoeren.
Voorwaarden
Om deze walkthrough te volgen, moet u een AWS-account een AWS Identiteits- en toegangsbeheer (IAM) rol die voldoende toegang heeft om de vereiste resources in te richten.
Stel de S3-bucket in voor Iceberg-gegevens in de beheerde zone in uw data lake
Kies de regio waarin u de S3-bucket wilt maken en geef een unieke naam op:
Start een EMR-cluster om Iceberg-taken uit te voeren met Spark
U kunt een EMR-cluster maken vanuit de AWS-beheerconsole, Amazon EMR CLI, of AWS Cloud-ontwikkelingskit (AWS-CDK). Voor dit bericht laten we u zien hoe u een EMR-cluster maakt vanaf de console.
- Kies op de Amazon EMR-console: Cluster maken.
- Kies geavanceerde opties.
- Voor software Configuration, kies de nieuwste Amazon EMR-release. Vanaf januari 2023 is de nieuwste release 6.9.0. Iceberg vereist versie 6.5.0 en hoger.
- kies JupyterEnterpriseGateway en Vonk als de te installeren software.
- Voor Software-instellingen bewerkenselecteer Voer de configuratie in en ga naar binnen
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - Laat andere instellingen op hun standaard staan en kies Volgende.

- Voor Hardware, gebruik de standaardinstelling.
- Kies Volgende.
- Voor Clusternaam, voer een naam in. We gebruiken
iceberg-blog-cluster. - Laat de overige instellingen ongewijzigd en kies Volgende.
- Kies Cluster maken.
Maak een notitieboek in EMR Studio
We laten u nu zien hoe u een notitieblok kunt maken in EMR Studio vanaf de console.
- Op de IAM-console, een EMR Studio-servicerol maken.
- Kies op de Amazon EMR-console: EMR-studio.
- Kies Start.
De Start pagina verschijnt in een nieuw tabblad.
- Kies Studio maken op het nieuwe tabblad.
- Voer een naam in. We gebruiken ijsberg-studio.
- Kies dezelfde VPC en hetzelfde subnet als die voor het EMR-cluster en de standaard beveiligingsgroep.
- Kies AWS identiteits- en toegangsbeheer (IAM) voor authenticatie en kies de EMR Studio-servicerol die u zojuist hebt gemaakt.
- Kies een S3-pad voor Back-up van werkruimten.
- Kies Studio maken.
- Nadat de Studio is gemaakt, kiest u de Studio-toegangs-URL.
- Kies op het EMR Studio-dashboard Werkruimte maken.
- Voer een naam in voor uw werkruimte. We gebruiken
iceberg-workspace. - Uitvouwen Geavanceerde configuratie En kies Koppel Workspace aan een EMR-cluster.
- Kies het EMR-cluster dat u eerder hebt gemaakt.
- Kies Werkruimte maken.
- Kies de Workspace-naam om een nieuw tabblad te openen.
In het navigatievenster bevindt zich een notitieblok met dezelfde naam als de werkruimte. In ons geval is het ijsberg-werkruimte.
- Open het notitieboek.
- Wanneer u wordt gevraagd een kernel te kiezen, kiest u Vonk.
Configureer een Spark-sessie voor Apache Iceberg
Gebruik de volgende code en geef uw eigen S3-bucketnaam op:
Hiermee worden de volgende Spark-sessieconfiguraties ingesteld:
- spark.sql.catalogus.demo – Registreert een Spark-catalogus met de naam demo, die de plug-in Iceberg Spark-catalogus gebruikt.
- spark.sql.catalog.demo.catalog-impl – De demo Spark-catalogus gebruikt AWS Glue als de fysieke catalogus om de Iceberg-database en tabelinformatie op te slaan.
- spark.sql.catalog.demo.warehouse – De demo Spark-catalogus slaat alle Iceberg-metagegevens en gegevensbestanden op onder het hoofdpad dat is gedefinieerd door deze eigenschap:
s3://iceberg-curated-blog-data. - spark.sql.extensies - Voegt ondersteuning toe aan Iceberg Spark SQL-extensies, waarmee u Iceberg Spark-procedures en enkele Iceberg-only SQL-opdrachten kunt uitvoeren (u gebruikt dit in een latere stap).
- spark.sql.catalog.demo.io-impl – Met Iceberg kunnen gebruikers gegevens naar Amazon S3 schrijven via S3FileIO. De AWS Glue-gegevenscatalogus gebruikt standaard deze FileIO en andere catalogi kunnen deze FileIO laden met behulp van de io-impl-cataloguseigenschap.
Converteer gegevens naar het Iceberg-tabelformaat
U kunt Spark op Amazon EMR of Athena gebruiken om de Iceberg-tabel te laden. Voer in de EMR Studio Workspace-notebook Spark-sessie de volgende opdrachten uit om de gegevens te laden:
Nadat u de code hebt uitgevoerd, zou u twee voorvoegsels moeten vinden die zijn gemaakt in uw datawarehouse S3-pad (s3://iceberg-curated-blog-data/reviews.db/all_reviews): gegevens en metagegevens.
Verwerk incrementele gegevens met behulp van SQL-instructies voor invoegen, bijwerken en verwijderen in Athena
Athena is een serverloze query-engine die u kunt gebruiken voor het uitvoeren van lees-, schrijf-, update- en optimalisatietaken voor Iceberg-tabellen. Om te demonstreren hoe de Apache Iceberg-datalake-indeling incrementele gegevensopname ondersteunt, voeren we insert-, update- en delete-SQL-instructies uit op de datalake.
Navigeer naar de Athena-console en kies Query-editor. Als dit de eerste keer is dat u de Athena-query-editor gebruikt, moet u dit doen configureer de locatie van het queryresultaat om de S3-bucket te zijn die u eerder hebt gemaakt. U zou moeten kunnen zien dat de tabel reviews.all_reviews beschikbaar is voor query's. Voer de volgende query uit om te controleren of u de Iceberg-tabel met succes hebt geladen:
Verwerk incrementele gegevens door insert-, update- en delete-SQL-statements uit te voeren:
Prestatieafstemming
In dit gedeelte bespreken we verschillende manieren om de lees- en schrijfprestaties van Apache Iceberg te verbeteren.
Configureer Apache Iceberg-tabeleigenschappen
Apache Iceberg is een tabelindeling en ondersteunt tabeleigenschappen om tabelgedrag zoals lezen, schrijven en catalogiseren te configureren. U kunt de lees- en schrijfprestaties op Iceberg-tabellen verbeteren door de tabeleigenschappen aan te passen.
Als u bijvoorbeeld merkt dat u te veel kleine bestanden schrijft voor een Iceberg-tabel, kunt u de schrijfbestandsgrootte configureren om minder maar grotere bestanden te schrijven, om de queryprestaties te helpen verbeteren.
| Woning | Standaard | Omschrijving |
| schrijf.target-file-size-bytes | 536870912 (512 MB) | Bepaalt de grootte van bestanden die worden gegenereerd om ongeveer dit aantal bytes te targeten |
Gebruik de volgende code om de tabelopmaak te wijzigen:
Partitioneren en sorteren
Om een query snel te laten werken, geldt: hoe minder gegevens, hoe beter. Iceberg maakt gebruik van de rijke metadata die het vastlegt tijdens het schrijven en maakt technieken mogelijk zoals scanplanning, partitionering, snoeien en statistieken op kolomniveau, zoals min/max-waarden, om gegevensbestanden over te slaan die geen overeenkomstrecords hebben. We laten u zien hoe planning en partitionering van queryscans werken in Iceberg en hoe we ze gebruiken om de queryprestaties te verbeteren.
Query scan plannen
Voor een bepaalde query is de eerste stap in een query-engine scanplanning, het proces om de bestanden in een tabel te vinden die nodig zijn voor een query. Plannen in een Iceberg-tabel is zeer efficiënt, omdat de rijke metadata van Iceberg kan worden gebruikt om metadatabestanden die niet nodig zijn te verwijderen, naast het filteren van databestanden die geen overeenkomende data bevatten. In onze tests hebben we waargenomen dat Athena 50% of minder gegevens scande voor een bepaalde zoekopdracht op een Iceberg-tabel in vergelijking met de oorspronkelijke gegevens vóór conversie naar Iceberg-indeling.
Er zijn twee soorten filtering:
- Metadata filteren – Iceberg gebruikt twee niveaus van metadata om de bestanden in een momentopname te volgen: de manifestlijst en manifestbestanden. Het gebruikt eerst de manifestlijst, die fungeert als een index van de manifestbestanden. Tijdens het plannen filtert Iceberg manifesten met behulp van het partitiewaardebereik in de manifestlijst zonder alle manifestbestanden te lezen. Vervolgens gebruikt het geselecteerde manifestbestanden om gegevensbestanden op te halen.
- Gegevensfiltering – Na het selecteren van de lijst met manifestbestanden, gebruikt Iceberg de partitiegegevens en statistieken op kolomniveau voor elk gegevensbestand dat is opgeslagen in manifestbestanden om gegevensbestanden te filteren. Tijdens de planning worden querypredikaten geconverteerd naar predikaten op de partitiegegevens en eerst toegepast op filtergegevensbestanden. Vervolgens worden de kolomstatistieken, zoals waardetellingen op kolomniveau, null-tellingen, ondergrenzen en bovengrenzen, gebruikt om gegevensbestanden uit te filteren die niet kunnen overeenkomen met het querypredikaat. Door boven- en ondergrenzen te gebruiken om gegevensbestanden tijdens het plannen te filteren, verbetert Iceberg de queryprestaties aanzienlijk.
Partitioneren en sorteren
Partitioneren is een manier om records met dezelfde sleutelkolomwaarden schriftelijk te groeperen. Het voordeel van partitionering is snellere query's die slechts toegang hebben tot een deel van de gegevens, zoals eerder uitgelegd in queryscanplanning: gegevensfiltering. Iceberg maakt partitioneren eenvoudig door verborgen partitionering te ondersteunen, zoals Iceberg partitiewaarden produceert door een kolomwaarde te nemen en deze optioneel te transformeren.
In onze use case voeren we eerst de volgende query uit op de niet-gepartitioneerde Iceberg-tabel. Vervolgens verdelen we de Iceberg-tabel op basis van de categorie van de beoordelingen, die zal worden gebruikt in de query WHERE-voorwaarde om records uit te filteren. Met partitionering kan de query veel minder gegevens scannen. Zie de volgende code:
Voer de volgende select-instructie uit op de niet-gepartitioneerde all_reviews-tabel versus de gepartitioneerde tabel om het prestatieverschil te zien:
De volgende tabel toont de prestatieverbetering van gegevenspartitionering, met ongeveer 50% prestatieverbetering en 70% minder gescande gegevens.
| Dataset naam | Niet-gepartitioneerde dataset | Gepartitioneerde gegevensset |
| Looptijd (seconden) | 8.20 | 4.25 |
| Gegevens gescand (MB) | 131.55 | 33.79 |
Merk op dat de runtime de gemiddelde runtime is met meerdere runs in onze test.
We zagen een goede prestatieverbetering na partitionering. Dit kan echter verder worden verbeterd door statistieken op kolomniveau uit Iceberg-manifestbestanden te gebruiken. Om de statistieken op kolomniveau effectief te gebruiken, wilt u uw records verder sorteren op basis van de querypatronen. Door de hele gegevensset te sorteren met behulp van de kolommen die vaak in query's worden gebruikt, worden de gegevens zodanig herschikt dat elk gegevensbestand een uniek waardenbereik voor de specifieke kolommen krijgt. Als deze kolommen worden gebruikt in de queryvoorwaarde, kunnen queryengines gegevensbestanden verder overslaan, waardoor nog snellere query's mogelijk worden.
Kopiëren bij schrijven versus lezen bij samenvoegen
Bij het implementeren van bijwerken en verwijderen op Iceberg-tabellen in het datameer, zijn er twee benaderingen die worden gedefinieerd door de Iceberg-tabeleigenschappen:
- Kopiëren bij schrijven – Met deze aanpak worden de gegevensbestanden die zijn gekoppeld aan de getroffen records gedupliceerd en bijgewerkt wanneer er wijzigingen zijn in de Iceberg-tabel, ofwel updates of verwijderingen. De records worden bijgewerkt of verwijderd uit de gedupliceerde gegevensbestanden. Er wordt een nieuwe snapshot van de Iceberg-tabel gemaakt die verwijst naar de nieuwere versie van gegevensbestanden. Dit maakt het schrijven in het algemeen langzamer. Er kunnen situaties zijn waarin gelijktijdig schrijven nodig is met conflicten, dus opnieuw proberen moet gebeuren, waardoor de schrijftijd nog meer toeneemt. Aan de andere kant is er bij het lezen van de gegevens geen extra proces nodig. De query haalt gegevens op uit de nieuwste versie van gegevensbestanden.
- Samenvoegen bij lezen – Met deze aanpak worden de bestaande gegevensbestanden niet herschreven wanneer er updates of verwijderingen zijn op de Iceberg-tabel; in plaats daarvan worden nieuwe verwijderbestanden gemaakt om de wijzigingen bij te houden. Voor verwijderingen wordt een nieuw verwijderingsbestand gemaakt met de verwijderde records. Bij het lezen van de Iceberg-tabel wordt het verwijderbestand toegepast op de opgehaalde gegevens om de verwijderrecords eruit te filteren. Voor updates wordt een nieuw verwijderbestand gemaakt om de bijgewerkte records als verwijderd te markeren. Vervolgens wordt er een nieuw bestand gemaakt voor die records, maar met bijgewerkte waarden. Bij het lezen van de Iceberg-tabel worden zowel de verwijderde als de nieuwe bestanden toegepast op de opgehaalde gegevens om de laatste wijzigingen weer te geven en de juiste resultaten te produceren. Dus voor eventuele volgende zoekopdrachten zal er een extra stap zijn om de gegevensbestanden samen te voegen met de verwijdering en nieuwe bestanden, wat meestal de querytijd zal verlengen. Aan de andere kant kan het schrijven sneller zijn omdat het niet nodig is om de bestaande gegevensbestanden te herschrijven.
Om de impact van de twee benaderingen te testen, kunt u de volgende code uitvoeren om de eigenschappen van de Iceberg-tabel in te stellen:
Voer de update uit, verwijder en selecteer SQL-instructies in Athena om het runtime-verschil voor kopiëren-bij-schrijven versus samenvoegen bij lezen weer te geven:
De volgende tabel geeft een overzicht van de queryruntimes.
| Vraag | Kopiëren tijdens schrijven | Samenvoegen bij lezen | ||||
| UPDATE | VERWIJDEREN | SELECT | UPDATE | VERWIJDEREN | SELECT | |
| Looptijd (seconden) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| Gegevens gescand (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
Merk op dat de runtime de gemiddelde runtime is met meerdere runs in onze test.
Zoals onze testresultaten laten zien, zijn er altijd compromissen tussen de twee benaderingen. Welke benadering u moet gebruiken, hangt af van uw use cases. Samenvattend komen de overwegingen neer op latentie bij lezen versus schrijven. U kunt de volgende tabel raadplegen en de juiste keuze maken.
| . | Kopiëren tijdens schrijven | Samenvoegen bij lezen |
| VOORDELEN | Sneller leest | Sneller schrijft |
| NADELEN | Dure schrijft | Hogere latentie bij het lezen |
| Wanneer te gebruiken | Goed voor veelvuldig lezen, onregelmatige updates en verwijderingen of grote batchupdates | Goed voor tabellen met frequente updates en verwijderingen |
Gegevensverdichting
Als uw gegevensbestand klein is, kunt u duizenden of miljoenen bestanden in een ijsbergtabel krijgen. Dit verhoogt de I/O-werking aanzienlijk en vertraagt de query's. Bovendien volgt Iceberg elk gegevensbestand in een dataset. Meer databestanden leiden tot meer metadata. Dit verhoogt op zijn beurt de overhead en I/O-bewerking bij het lezen van metadatabestanden. Om de queryprestaties te verbeteren, wordt aanbevolen om kleine gegevensbestanden te comprimeren tot grotere gegevensbestanden.
Bij het bijwerken en verwijderen van records in de Iceberg-tabel, als de read-on-merge-benadering wordt gebruikt, kunt u eindigen met veel kleine verwijderingen of nieuwe gegevensbestanden. Als u verdichting uitvoert, worden al deze bestanden gecombineerd en wordt een nieuwere versie van het gegevensbestand gemaakt. Dit elimineert de noodzaak om ze tijdens het lezen met elkaar te verzoenen. Het wordt aanbevolen om regelmatige verdichtingstaken uit te voeren om het lezen zo min mogelijk te beïnvloeden en toch een hogere schrijfsnelheid te behouden.
Voer de volgende opdracht voor gegevensverdichting uit en voer vervolgens de selectiequery uit vanuit Athena:
In de volgende tabel wordt de runtime voor versus na datacompactie vergeleken. U kunt ongeveer 40% prestatieverbetering zien.
| Vraag | Vóór gegevensverdichting | Na gegevensverdichting |
| Looptijd (seconden) | 97.75 | 32.676 seconden |
| Gegevens gescand (MB) | 137.16 M | 189.19 M |
Merk op dat de selectiequery's werden uitgevoerd op de all_reviews tabel na update- en verwijderbewerkingen, voor en na gegevensverdichting. De runtime is de gemiddelde runtime met meerdere runs in onze test.
Opruimen
Nadat u de walkthrough van de oplossing hebt gevolgd om de use cases uit te voeren, voert u de volgende stappen uit om uw resources op te schonen en verdere kosten te voorkomen:
- Zet de AWS Glue-tabellen en database van Athena neer of voer de volgende code uit in uw notebook:
- Kies op de EMR Studio-console workspaces in het navigatievenster.
- Selecteer de werkruimte die u hebt gemaakt en kies Verwijder.
- Navigeer op de EMR-console naar de Studios pagina.
- Selecteer de Studio die je hebt gemaakt en kies Verwijder.
- Kies op de EMR-console Clusters in het navigatievenster.
- Selecteer het cluster en kies Beëindigen.
- Verwijder de S3-bucket en alle andere bronnen die u hebt gemaakt als onderdeel van de vereisten voor dit bericht.
Conclusie
In dit bericht hebben we het Apache Iceberg-framework geïntroduceerd en hoe het helpt bij het oplossen van enkele van de uitdagingen die we hebben in een modern datameer. Vervolgens hebben we u een oplossing laten zien om incrementele gegevens in een datameer te verwerken met behulp van Apache Iceberg. Ten slotte hebben we een diepe duik genomen in het afstemmen van prestaties om de lees- en schrijfprestaties voor onze use cases te verbeteren.
We hopen dat dit bericht u nuttige informatie biedt om te beslissen of u Apache Iceberg in uw data lake-oplossing wilt gebruiken.
Over de auteurs
 Flora Wu is Sr. Resident Architect bij AWS Data Lab. Ze helpt zakelijke klanten bij het creëren van data-analysestrategieën en het bouwen van oplossingen om hun bedrijfsresultaten te versnellen. In haar vrije tijd houdt ze van tennissen, salsadansen en reizen.
Flora Wu is Sr. Resident Architect bij AWS Data Lab. Ze helpt zakelijke klanten bij het creëren van data-analysestrategieën en het bouwen van oplossingen om hun bedrijfsresultaten te versnellen. In haar vrije tijd houdt ze van tennissen, salsadansen en reizen.
 Daniel Li is Sr. Solutions Architect bij Amazon Web Services. Hij richt zich op het helpen van klanten bij het ontwikkelen, adopteren en implementeren van cloudservices en -strategieën. Als hij niet aan het werk is, brengt hij graag tijd buitenshuis door met zijn gezin.
Daniel Li is Sr. Solutions Architect bij Amazon Web Services. Hij richt zich op het helpen van klanten bij het ontwikkelen, adopteren en implementeren van cloudservices en -strategieën. Als hij niet aan het werk is, brengt hij graag tijd buitenshuis door met zijn gezin.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- in staat
- Over
- boven
- versnellen
- toegang
- toegangsbeheer
- Actie
- Handelingen
- toevoeging
- Extra
- adres
- adressen
- Voegt
- adopteren
- Voordeel
- Na
- tegen
- Alles
- toestaat
- altijd
- Amazone
- Amazon EMR
- Amazon Web Services
- analytisch
- analytics
- en
- aangekondigd
- apache
- toepassingen
- toegepast
- nadering
- benaderingen
- passend
- architectuur
- geassocieerd
- authenticatie
- beschikbaarheid
- Beschikbaar
- gemiddelde
- vermijd
- AWS
- AWS lijm
- gebaseerde
- omdat
- worden
- vaardigheden
- voordeel
- Betere
- tussen
- groter
- Bootstrap
- bouw
- Gebouw
- ondernemingen
- captures
- Het vastleggen
- geval
- gevallen
- catalogus
- catalogi
- Categorie
- uitdagingen
- verandering
- Wijzigingen
- controle
- keuze
- Kies
- classificatie
- Cloud
- cloud-diensten
- TROS
- code
- Kolom
- columns
- combineren
- hoe
- plegen
- vergeleken
- compleet
- Berekenen
- gelijktijdig
- voorwaarde
- configuraties
- overwegingen
- troosten
- Camper ombouw
- geconverteerd
- kostenefficient
- Kosten
- kon
- en je merk te creëren
- aangemaakt
- creëert
- curated
- Actueel
- klant
- Klanten
- Dansen
- dashboards
- gegevens
- gegevens Analytics
- Datameer
- gegevensverwerking
- datawarehouse
- Database
- datasets
- deep
- diepe duik
- Standaard
- gedefinieerd
- Demo
- tonen
- afhankelijk
- ontworpen
- gegevens
- ontwikkelen
- Ontwikkeling
- verschil
- anders
- bespreken
- Dont
- beneden
- dramatisch
- Val
- gedurende
- elk
- Vroeger
- Vroeg
- editor
- effectief
- doeltreffend
- beide
- elimineert
- ingeschakeld
- waardoor
- eindigt
- Motor
- Motoren
- Enter
- Enterprise
- zakelijke klanten
- Ether (ETH)
- Zelfs
- Evolutie
- ontwikkelen
- evoluerende
- voorbeeld
- bestaand
- bestaat
- uitgelegd
- extensies
- extra
- vergemakkelijkt
- familie
- SNELLE
- sneller
- Voordelen
- Figuur
- Dien in
- Bestanden
- filter
- filtering
- filters
- Tot slot
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- eerste keer
- richt
- volgen
- volgend
- formaat
- Achtergrond
- veelvuldig
- oppompen van
- verder
- Bovendien
- Algemeen
- gegenereerde
- krijgen
- gegeven
- Goes
- goed
- sterk
- Groep
- hand
- gebeuren
- hulp
- het helpen van
- helpt
- verborgen
- hiërarchie
- high-level
- hoge performantie
- goed presterende
- Bijenkorf
- hoop
- Hoe
- How To
- Echter
- HTML
- HTTPS
- IAM
- Identiteit
- identiteits- en toegangsbeheer
- Impact
- beïnvloed
- uitvoeren
- uitvoering
- uitvoering
- verbeteren
- verbeterd
- verbetering
- verbetert
- in
- Inclusief
- Laat uw omzet
- meer
- Verhoogt
- index
- individueel
- informatie
- installeren
- verkrijgen in plaats daarvan
- integratie
- geïntroduceerd
- isolaten
- IT
- Januari
- Vacatures
- sleutel
- laboratorium
- meer
- Groot
- groter
- Wachttijd
- laatste
- nieuwste release
- lagen
- Legkippen
- leiden
- niveaus
- LIMIT
- Lijn
- Lijst
- Elke kleine stap levert grote resultaten op!
- laden
- plaats
- maken
- MERKEN
- management
- veel
- Mark
- markt
- Match
- matching
- gaan
- Metadata
- macht
- miljoenen
- Modern
- meer
- beweging
- meervoudig
- naam
- Genoemd
- OP DEZE WEBSITE VIND JE
- Navigatie
- Noodzaak
- nodig
- behoeften
- New
- notitieboekje
- object
- open
- operatie
- Operations
- optimalisatie
- Optimaliseer
- bestellen
- origineel
- Overige
- buiten
- totaal
- het te bezitten.
- brood
- deel
- pad
- patronen
- uitvoeren
- prestatie
- Fysiek
- planning
- Plato
- Plato gegevensintelligentie
- PlatoData
- spelen
- inpluggen
- punten
- Populair
- mogelijk
- Post
- aangedreven
- vereisten
- procedures
- verwerking
- produceren
- vastgoed
- eigendom
- zorgen voor
- biedt
- het verstrekken van
- voorziening
- reeks
- Rauw
- ruwe data
- Lees
- lezing
- vast
- onlangs
- aanbevolen
- archief
- reflecteren
- regio
- register
- regelmatig
- los
- uitgebracht
- resterende
- nodig
- vereist
- Resources
- resultaat
- Resultaten
- Recensies
- Rijk
- Rol
- wortel
- lopen
- lopend
- dezelfde
- aftasten
- seconden
- sectie
- veiligheid
- gekozen
- selecteren
- Serverless
- service
- Diensten
- Sessie
- reeks
- Sets
- het instellen van
- settings
- moet
- tonen
- Shows
- Eenvoudig
- situaties
- Maat
- vertraagt
- Klein
- Momentopname
- So
- Software
- oplossing
- Oplossingen
- sommige
- Vonk
- specifiek
- snelheid
- Uitgaven
- SQL
- Start
- Land
- Statement
- verklaringen
- stats
- Stap voor
- Stappen
- Still
- mediaopslag
- shop
- opgeslagen
- winkels
- strategieën
- Strategie
- gestructureerde
- gestructureerde en ongestructureerde data
- studio
- subnet
- volgend
- Met goed gevolg
- dergelijk
- voldoende
- OVERZICHT
- ondersteuning
- ondersteunde
- Ondersteuning
- steunen
- tafel
- neemt
- het nemen
- doelwit
- taken
- technieken
- tennis
- proef
- Testen
- testen
- De
- de informatie
- De Staat
- hun
- daarbij
- duizenden kosten
- drie
- Door
- niet de tijd of
- Tijdreizen
- naar
- samen
- ook
- tools
- top
- Totaal
- spoor
- Transacties
- transformeren
- reizen
- Reizend
- BEURT
- types
- voor
- unieke
- bijwerken
- bijgewerkt
- updates
- bijwerken
- URL
- .
- use case
- gebruikers
- doorgaans
- VAL
- waarde
- Values
- controleren
- versie
- wandelde
- walkthrough
- Magazijn
- horloges
- manieren
- web
- webservices
- Wat
- of
- welke
- en
- breed
- Grote range
- wil
- zonder
- Mijn werk
- werkzaam
- Bedrijven
- zou
- schrijven
- het schrijven van
- Your
- zephyrnet