
Bilde av Freepik
Store språkmodeller (LLM) som OpenAIs GPT og Mistrals Mixtral spiller i økende grad en viktig rolle i utviklingen av AI-drevne applikasjoner. Disse modellenes evne til å generere menneskelignende resultater gjør dem til de perfekte assistentene for innholdsoppretting, kodefeilsøking og andre tidkrevende oppgaver.
En vanlig utfordring man møter når man arbeider med LLM-er er imidlertid muligheten for å møte faktisk feilaktig informasjon, populært kjent som hallusinasjoner. Årsaken til disse hendelsene er ikke langsøkt. LLM-er er opplært til å gi tilfredsstillende svar på spørsmål; i tilfeller der de ikke kan skaffe en, tryller de frem en. Hallusinasjoner kan også påvirkes av typen input og skjevheter som brukes i trening av disse modellene.
I denne artikkelen vil vi utforske tre forskningsstøttede avanserte prompteteknikker som har dukket opp som lovende tilnærminger for å redusere forekomsten av hallusinasjoner og samtidig forbedre effektiviteten og hastigheten til resultater produsert av LLM-er.
For bedre å forstå forbedringene disse avanserte teknikkene gir, er det viktig at vi snakker om det grunnleggende om rask skriving. Forespørsler i sammenheng med AI (og i denne artikkelen LLM-er) refererer til en gruppe tegn, ord, tokens eller et sett med instruksjoner som veileder AI-modellen med hensyn til intensjonen til den menneskelige brukeren.
Rask engineering refererer til kunsten å lage ledetekster med mål om å bedre styre atferden og den resulterende produksjonen til den aktuelle LLM. Ved å bruke forskjellige teknikker for å formidle menneskelige intensjoner bedre, kan utviklere forbedre modellenes resultater når det gjelder nøyaktighet, relevans og sammenheng.
Her er noen viktige tips du bør følge når du lager en forespørsel:
- Vær kortfattet
- Gi struktur ved å spesifisere ønsket utdataformat
- Gi referanser eller eksempler hvis mulig.
Alle disse vil hjelpe modellen til å bedre forstå hva du trenger og øke sjansene for å få et tilfredsstillende svar.
Nedenfor er et godt eksempel som spør etter en AI-modell med en ledetekst ved å bruke alle tipsene nevnt ovenfor:
Prompt = “Du er en ekspert på AI-promptingeniør. Generer et 2-setningssammendrag av de siste fremskrittene innen promptgenerering, med fokus på utfordringene med hallusinasjoner og potensialet ved å bruke avanserte prompteteknikker for å møte disse utfordringene. Utdataene skal være i markdown-format."
Å følge disse essensielle tipsene som er diskutert tidligere, garanterer imidlertid ikke alltid optimale resultater, spesielt når du arbeider med komplekse oppgaver.
Ledende forskere fra fremtredende AI-institusjoner som Microsoft og Google har brukt mye ressurser på LLM-optimalisering, dvs. aktivt studere de vanlige årsakene til hallusinasjoner og finne effektive måter å håndtere dem på. Følgende tilskyndelsesteknikker har vist seg å gi bedre og kontekstbevisste instruksjoner til de studerte LLM-ene, og øker dermed sjansene for å få bedre relevante resultater og reduserer også sannsynligheten for å få unøyaktig eller useriøs informasjon.
Her er noen eksempler på forskningsdrevne avanserte spørreteknikker:
1. Emosjonell overtalelse
A 2023-studie av Microsoft-forskere funnet ut at bruk av emosjonelt språk og overbevisende spørsmål, kalt "EmotionPrompts", kan forbedre LLM-ytelsen med over 10 %.
Denne stilen legger til et personlig, emosjonelt element til den gitte forespørselen, og forvandler forespørselen til en som er svært viktig med betydelige konsekvenser for resultatene. Det er nesten som å snakke med et menneske; å bruke en følelsesmessig vinkel hjelper til med å kommunisere viktigheten av oppgaven, og stimulerer til dypere fokus og engasjement. Denne strategien kan være nyttig for oppgaver som krever høyere problemløsning og kreativitet.
La oss ta en titt på et enkelt eksempel der følelser brukes til å forbedre spørsmålet:
Grunnleggende ledetekst: "Skriv et Python-skript for å sortere en liste over tall."
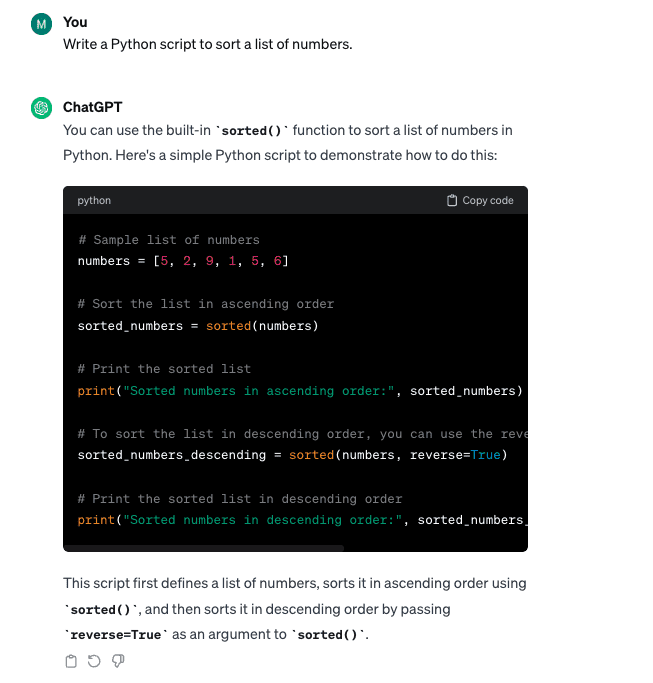
Spør med emosjonell Overtalelse: "Jeg er spent på å forbedre mine Python-ferdigheter, og jeg må skrive et skript for å sortere tall. Dette er et avgjørende skritt i min karriere som utvikler."
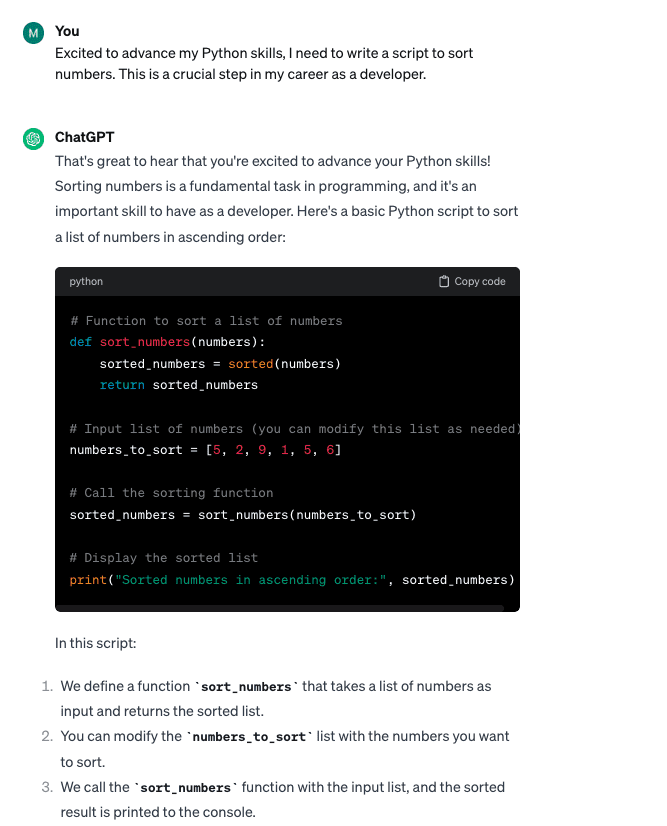
Mens begge promptvariantene ga lignende koderesultater, bidro "EmotionPrompts"-teknikken til å skape en renere kode og ga ytterligere forklaringer som en del av det genererte resultatet.

Nok et interessant eksperiment av Finxter fant ut at det å gi pengetips til LLM-ene også kan forbedre ytelsen deres – nesten som å appellere til et menneskes økonomiske insentiv.
2. Chain-of-Thought Spørring
En annen oppfordringsteknikk oppdaget for sin effektivitet av en gruppe forskere fra University of Pittsburgh er Chain-of-Thought-stilen. Denne teknikken bruker en trinn-for-trinn-tilnærming som går modellen gjennom ønsket utdatastruktur. Denne logiske tilnærmingen hjelper modellen å lage en mer relevant og strukturert respons på en kompleks oppgave eller spørsmål.
Her er et eksempel på hvordan du oppretter en Chain-of-Thought-stilmelding basert på den gitte malen (ved å bruke OpenAIs ChatGPT med GPT-4):
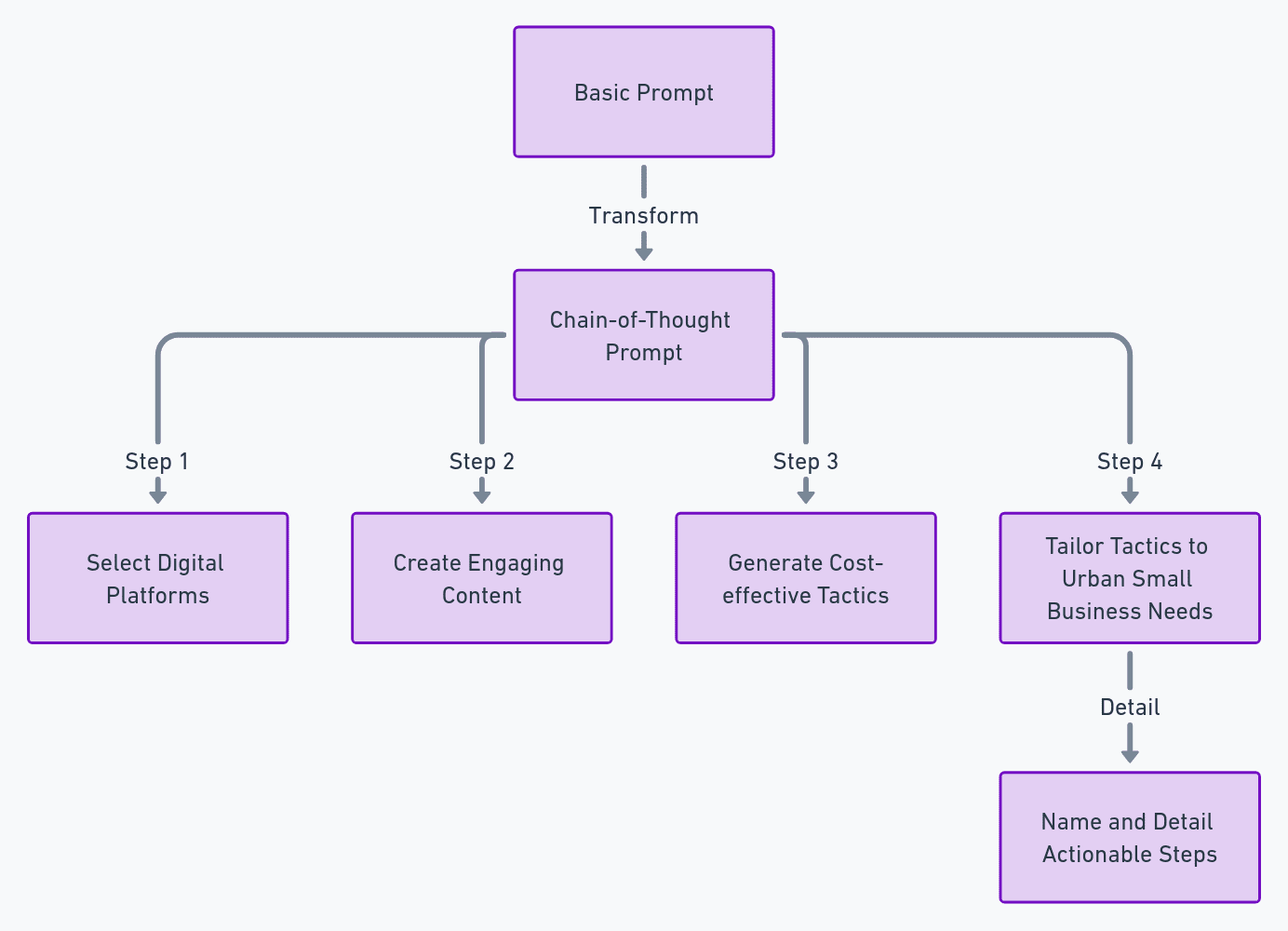
Grunnleggende ledetekst: "Utarbeid en digital markedsføringsplan for en finansapp rettet mot småbedriftseiere i store byer."
N
Tankekjedemelding:
"Skiss en digital markedsføringsstrategi for en finansapp for småbedriftseiere i store byer. Fokuser på:
- Velge digitale plattformer som er populære blant denne bedriftsdemografien.
- Lag engasjerende innhold som webinarer eller andre relevante verktøy.
- Generer kostnadseffektive taktikker som er unike fra tradisjonelle annonser.
- Skreddersy disse taktikkene til urbane småbedrifters behov på en måte som øker kundenes konverteringsfrekvens.
Navngi og detaljer hver del av planen med unike, handlingsrettede trinn."
Chain of prompt-teknikken genererte et mer presist og handlingsdyktig resultat fra et overfladisk utseende.
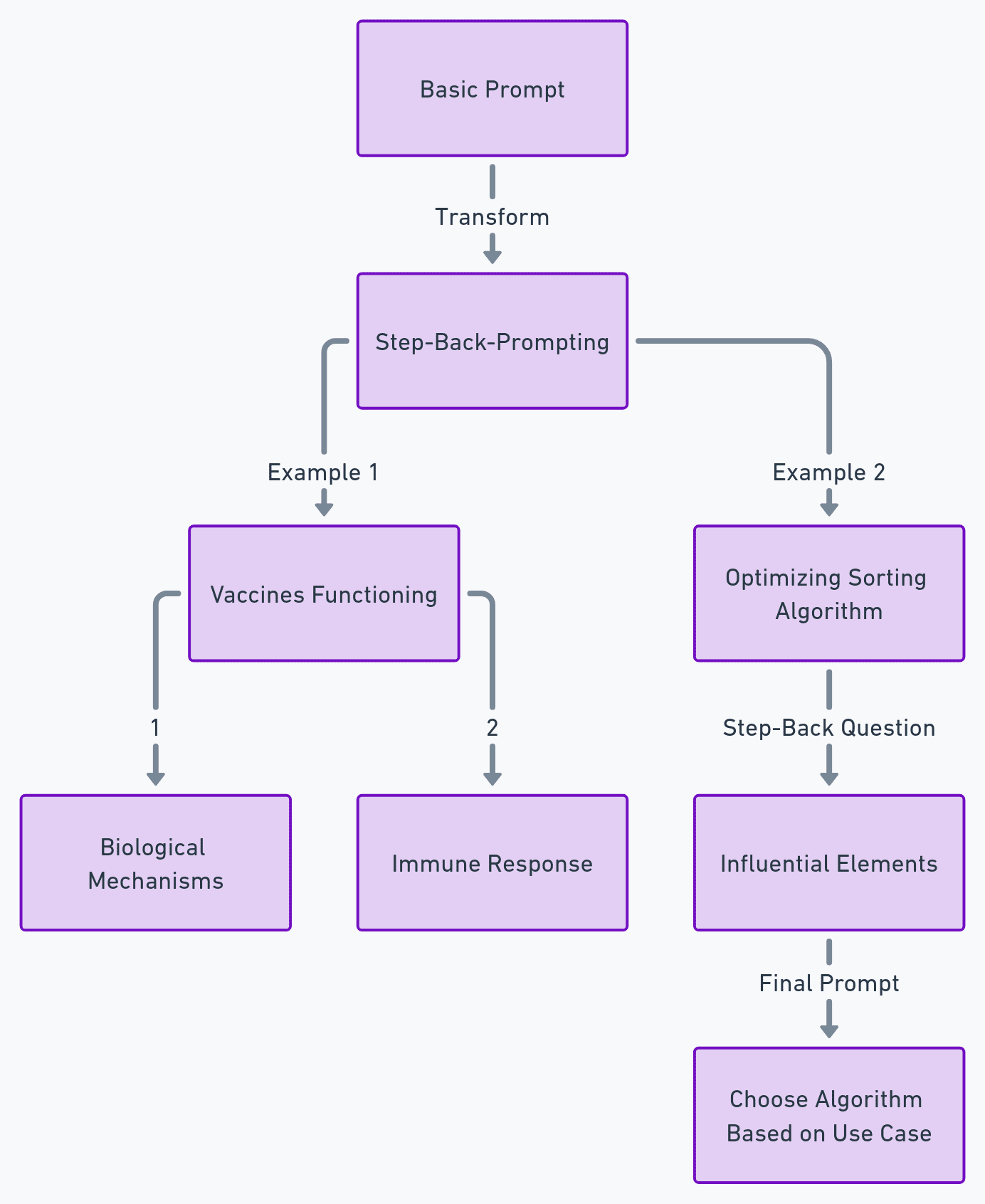
Step-back-Prompting-teknikken, presentert av syv av Googles Deepmind-forskere, er designet for å simulere resonnement når du arbeider med LLM. Dette ligner på å lære en student de underliggende prinsippene for et konsept før de løser et komplekst problem.
For å bruke denne teknikken må du påpeke det underliggende prinsippet bak et spørsmål før du ber modellen om å gi et svar. Dette sikrer at modellen får en robust kontekst, som vil hjelpe den til å gi et teknisk riktig og relevant svar.
La oss undersøke to eksempler (ved å bruke OpenAIs ChatGPT med GPT-4):
Eksempel 1:
Grunnleggende ledetekst: "Hvordan virker vaksiner?"

Forespørsler ved hjelp av Step-back-teknikken
- "Hvilke biologiske mekanismer lar vaksiner beskytte mot sykdommer?"

- "Kan du forklare kroppens immunrespons utløst av vaksinasjon?"
Mens den grunnleggende spørsmålet ga et tilfredsstillende svar, ga bruk av Step-Back-teknikken et dyptgående, mer teknisk svar. Dette vil være spesielt nyttig for tekniske spørsmål du måtte ha.
Ettersom utviklere fortsetter å bygge nye applikasjoner for eksisterende AI-modeller, er det et økende behov for avanserte spørreteknikker som kan forbedre mulighetene til store språkmodeller til å forstå ikke bare ordene våre, men intensjonen og følelsene bak dem for å generere mer nøyaktige og kontekstuelt relevante utganger.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/3-research-driven-advanced-prompting-techniques-for-llm-efficiency-and-speed-optimization?utm_source=rss&utm_medium=rss&utm_campaign=3-research-driven-advanced-prompting-techniques-for-llm-efficiency-and-speed-optimization
- :er
- :ikke
- :hvor
- $OPP
- 1
- 2%
- 9
- a
- evner
- evne
- Om oss
- ovenfor
- nøyaktighet
- nøyaktig
- handlings
- aktivt
- Ytterligere
- adresse
- Legger
- annonser
- avansere
- avansert
- fremskritt
- mot
- AI
- AI-modeller
- AI-drevet
- sikte
- Alle
- tillate
- nesten
- også
- alltid
- blant
- an
- og
- vinkel
- besvare
- svar
- app
- tiltrekkende
- søknader
- Påfør
- tilnærming
- tilnærminger
- ER
- Kunst
- Artikkel
- AS
- assistenter
- At
- basert
- grunnleggende
- Grunnleggende
- BE
- vært
- før du
- atferd
- bak
- Bedre
- skjevheter
- både
- bringe
- bygge
- virksomhet
- bedriftseiere
- men
- by
- som heter
- CAN
- Karriere
- saker
- kjede
- utfordre
- utfordringer
- sjansene
- tegn
- ChatGPT
- Byer
- renere
- kode
- engasjement
- Felles
- kommunisere
- komplekse
- fatte
- konsept
- konsis
- Konsekvenser
- innhold
- innholdsskaping
- kontekst
- fortsette
- Konvertering
- korrigere
- kostnadseffektiv
- lage
- skape
- Opprette
- skaperverket
- kreativitet
- avgjørende
- kunde
- håndtering
- dypere
- demografiske
- designet
- ønsket
- detalj
- Utvikler
- utviklere
- Utvikling
- forskjellig
- digitalt
- digital markedsføring
- digitale plattformer
- regi
- oppdaget
- diskutert
- sykdommer
- do
- gjør
- Utkast
- e
- hver enkelt
- Tidligere
- Effektiv
- effektivitet
- effektivitet
- element
- dukket
- følelser
- emosjonelle
- ansatt
- anvender
- støte på
- engasjerende
- ingeniør
- Ingeniørarbeid
- forbedre
- sikrer
- spesielt
- avgjørende
- Eter (ETH)
- undersøke
- eksempel
- eksempler
- opphisset
- eksisterende
- eksperiment
- Expert
- Forklar
- forklaringer
- utforske
- møtt
- finansiere
- finansiell
- finne
- Fokus
- fokusering
- følge
- etter
- Til
- format
- funnet
- fra
- generere
- generert
- generasjonen
- blir
- få
- Gi
- gitt
- mål
- god
- Gruppe
- garantere
- veilede
- Ha
- hjelpe
- hjulpet
- hjelper
- høyere
- svært
- Hvordan
- Hvordan
- HTTPS
- menneskelig
- i
- if
- immun
- betydning
- viktig
- forbedre
- forbedringer
- bedre
- in
- dyptgående
- unøyaktig
- Incentive
- feil
- Øke
- øker
- økende
- stadig
- påvirket
- informasjon
- innganger
- institusjoner
- instruksjoner
- hensikt
- interessant
- inn
- IT
- DET ER
- jpg
- bare
- KDnuggets
- kjent
- Språk
- stor
- siste
- i likhet med
- sannsynligheten
- Liste
- llm
- logisk
- Se
- Lot
- GJØR AT
- Marketing
- markedsføringsstrategi
- mekanismer
- nevnt
- Microsoft
- kunne
- modell
- modeller
- Monetære
- mer
- my
- Trenger
- behov
- roman
- tall
- forekomst
- of
- on
- ONE
- OpenAI
- optimal
- optimalisering
- or
- Annen
- vår
- ut
- omriss
- produksjon
- utganger
- enn
- eiere
- del
- perfekt
- ytelse
- personlig
- Pittsburgh
- fly
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- vær så snill
- Point
- Populær
- mulighet
- mulig
- potensiell
- presis
- presentert
- prinsipp
- prinsipper
- Problem
- problemløsning
- produsert
- fremtredende
- lovende
- ledetekster
- beskytte
- gi
- forutsatt
- gi
- Python
- spørsmål
- spørsmål
- spørsmål
- priser
- RE
- grunnen til
- resonnement
- grunner
- redusere
- referere
- referanser
- refererer
- relevans
- relevant
- anmode
- forskere
- Ressurser
- svar
- resultere
- resulterende
- Resultater
- robust
- Rolle
- s
- script
- dømme
- sett
- syv
- bør
- signifikant
- lignende
- Enkelt
- simulere
- ferdigheter
- liten
- småbedrifter
- Eiere av små bedrifter
- løse
- noen
- spesifiserer
- fart
- Trinn
- Steps
- Strategi
- struktur
- strukturert
- Student
- studert
- Studer
- Studerer
- stil
- SAMMENDRAG
- taktikk
- Ta
- Snakk
- snakker
- Oppgave
- oppgaver
- Undervisning
- Teknisk
- teknisk sett
- teknikk
- teknikker
- mal
- vilkår
- Det
- De
- Grunnleggende
- deres
- Dem
- Der.
- derved
- Disse
- de
- denne
- trodde
- tre
- Gjennom
- tips
- til
- tokens
- verktøy
- tradisjonelle
- trent
- Kurs
- transformere
- utløst
- to
- typen
- underliggende
- forstå
- unik
- universitet
- Urban
- brukt
- nyttig
- Bruker
- ved hjelp av
- vaksiner
- variasjoner
- vandringer
- Vei..
- måter
- we
- Webinarer
- Hva
- når
- hvilken
- mens
- vil
- med
- ord
- Arbeid
- arbeid
- skrive
- skriving
- du
- zephyrnet








