Siste oppdatering: januar 2021.
Denne bloggen er en omfattende oversikt over bruk av OCR med ethvert RPA-verktøy for å automatisere dokumentarbeidsflytene. Vi undersøker hvordan de nyeste maskinlæringsbaserte OCR-teknologiene ikke krever regler eller maloppsett.

RPAs eller Robotic Process automation er programvareverktøy rettet mot å eliminere repeterende forretningsoppgaver. Flere CIOs vender seg mot dem for å redusere kostnadene og hjelpe ansatte med å fokusere på mer verdifullt forretningsarbeid. Eksempler inkluderer å svare på kommentarer på nettsteder eller behandling av kundeordre. Litt mer komplekse oppgaver inkluderer håndtering av dokumenter som håndskrevne skjemaer og fakturaer – disse må vanligvis flyttes fra det ene eldre systemet til det andre – si e-postklienten din til SAP ERP-systemet hvor du må trekke ut data. Dette er den problematiske delen.
De fleste OCR-verktøy som fanger data fra disse dokumentene er malbaserte (f.eks Abbyy Flexicapture) og skalerer ikke godt på semistrukturerte dokumenter. Det er nyere generasjons maskinlæringsbaserte løsninger som vanligvis gir API
integrasjoner som kan fange nøkkelverdipar fra dokumenter - bedriftssystemer er vanligvis eldre og ikke åpne for integrering med eksterne API-er. På den andre siden er RPA-er bygget for å håndtere disse eldre systemarbeidsflytene som å innta dokumenter fra mapper og legge inn resultater i ERPer eller CRM-er.
Ettersom Robotic Process Automation (RPA) og ML utvikler seg mot hyperautomatisering, kan vi benytte oss av programvareboter i forbindelse med ML for å håndtere komplekse oppgaver som dokumentklassifisering, utvinning og optisk karaktergjenkjenning. I en nylig studie ble det sagt at ved å automatisere bare 29% av funksjonene for en oppgave ved bruk av RPA, sparer økonomiavdelinger mer enn 25,000 878,000 timer etterarbeid forårsaket av menneskelige feil til en pris av $ 40 1 per år for en organisasjon med XNUMX full- tidsregnskapsmedarbeidere [XNUMX]. I denne bloggen vil vi lære om bruk av OCR-er med RPA-er og dykke ned i arbeidsforløp for dokumentforståelse. Nedenfor er innholdsfortegnelsen.
Definisjoner og oversikt
RPA, generelt, er en teknologi som hjelper med å automatisere administrative oppgaver via programvare-hardware-roboter. Disse robotene drar nytte av brukergrensesnitt; å fange dataene og manipulere applikasjoner slik mennesker gjør. For eksempel kan en RPA se på en rekke oppgaver tatt i en GUI, for eksempel bevegelige markører, koble til APIer, kopiere og lime inn dataene og formulere den samme sekvensen av handlinger i en RPA wireframe som oversettes til kode. Videre kan disse oppgavene utføres uten menneskelig innblanding i fremtiden. Optical Character Recognition (OCR) er en avgjørende funksjon i enhver funksjonell robotprosessautomatisering (RPA)-løsning. Denne teknologien brukes til å lese og trekke ut tekst fra forskjellige kilder som bilder eller PDF -filer til et digitalt format uten å fange det manuelt.
På den annen side er dokumentforståelse begrepet som brukes til automatisk å lese, tolke og handle på dokumentdata. Det viktigste i denne prosessen er at programvareboter selv utfører alle oppgavene. Disse robotene utnytter kraften til kunstig intelligens og maskinlæring for å forstå dokumenter som digitale assistenter. På denne måten kan vi si at dokumentforståelse dukker opp i skjæringspunktet mellom dokumentbehandling, AI og RPA.

Hvordan roboter kan lære å forstå dokumentene med OCR og ML
Før vi dykker ned i dokumentforståelse først, la oss snakke om rollen som roboter for dokumentforståelse. Disse helt usynlige hjelperne gjør livet vårt mer komfortabelt. I motsetning til filmer og serier er ikke disse robotene fysiske enheter eller programmer for kunstig intelligens som sitter ved skrivebordet og trykker på knapper for å utføre oppgaver. Vi kan tenke på disse som digitale assistenter som er opplært til å behandle dokumenter ved å lese og bruke applikasjoner som vi gjør. På den funksjonelle siden er roboter flinke til å forbedre ytelsen og effektiviteten til en prosess. Likevel, de er en frittstående programvare, kan ikke evaluere prosessen og ta kognitive beslutninger. Imidlertid, hvis maskinlæring er vellykket integrert, vil robotikk bli mer dynamisk og tilpasningsdyktig. For eksempel vil roboter som brukes til dokumentbehandling, datahåndtering og andre funksjoner på tvers av front- og mellomkontoret, utføre mer intelligente handlinger, for eksempel å eliminere dupliserte oppføringer eller løse ukjente systemunngåelser i prosessen. Videre blir robotene trent i å lese, trekke ut, tolke og handle på data fra dokumentene ved hjelp av kunstig intelligens (AI).
Hvordan kan selskaper integrere intelligent OCR med RPA for å forbedre arbeidsflytene
Utpakking av dokumentdata er en viktig komponent for dokumentforståelse. I denne delen vil vi diskutere hvordan vi kan integrere OCR med RPA eller omvendt. For det første visste vi alle at det finnes forskjellige typer dokumenter når det gjelder maler, stil, formatering og noen ganger språk. Derfor kan vi ikke stole på en enkel OCR-teknikk for å hente ut dataene fra disse dokumentene. For å løse dette problemet bruker vi både regelbaserte tilnærminger og modellbaserte tilnærminger innen OCR for å håndtere data fra forskjellige dokumentstrukturer. Nå får vi se hvordan selskaper som gjør OCR kan integrere RPAer i sitt eksisterende system basert på dokumenttypen.
Strukturerte dokumenter: I denne typen dokumenter er layoutene og malene vanligvis faste og nesten konsistente. Tenk for eksempel på en organisasjon som gjør KYC med myndighetsutstedte ID-er som pass eller førerkort. Alle disse dokumentene vil være identiske og ha de samme feltene som ID-nummer, personens navn, alder og få andre på samme posisjoner. Men bare detaljene varierer. Det kan være få begrensninger som tabelloverfylte data eller ufylte data.
Vanligvis bruker den anbefalte tilnærmingen en mal eller regelbasert motor for å trekke ut informasjonen for strukturerte dokumenter. Disse kan inkludere vanlige uttrykk eller enkel posisjonskartlegging og OCR. Derfor, for å integrere programvareroboter for å automatisere informasjonsutvinning, kan vi enten bruke eksisterende maler eller lage regler for våre strukturerte data. Det er en ulempe ved å bruke den regelbaserte tilnærmingen, siden den er avhengig av faste deler, kan selv små endringer i formstrukturen føre til at regler brytes ned.
Semistrukturerte dokumenter: Disse dokumentene har samme informasjon, men er ordnet i forskjellige posisjoner. Tenk for eksempel fakturaer som inneholder 8-12 identiske felt. Om noen få fakturaer, selgeradressen kan være plassert øverst, og i andre kan den finnes nederst. Disse regelbaserte tilnærmingene gir vanligvis ikke høy nøyaktighet; derfor tar vi inn maskinlærings- og dyplæringsmodeller inn i bildet for informasjonsutvinning ved hjelp av OCR. Alternativt kan vi i noen tilfeller bruke hybridmodeller som involverer både regler og ML-modeller. Noen få populære forhåndstrente modeller er FastRCNN, Attention OCR, Graph Convolutions for informasjonsutvinning i dokumenter. Men igjen har disse modellene få ulemper; derfor måler vi algoritmeytelsen ved å bruke beregninger som nøyaktighet eller konfidenspoeng. Fordi modellen lærer mønstre, i stedet for å operere ut fra konkrete regler, kan den gjøre feil i utgangspunktet rett etter korrigeringer. Men løsningen på disse ulempene – jo flere prøver ML-modellen behandler, jo flere mønstre lærer den for å sikre nøyaktighet.
Ustrukturerte dokumenter: RPA er i dag ikke i stand til å administrere ustrukturerte data direkte, og krever derfor at roboter først trekker ut og lager strukturerte data ved hjelp av OCR. I motsetning til strukturerte og semistrukturerte dokumenter, har ikke ustrukturerte data noen få nøkkelverdi-par. For eksempel i noen få fakturaer, ser vi en kjøpmannsadresse et sted uten noe nøkkelnavn; på samme måte observerer vi det samme for andre felt som dato, faktura-ID. For at ML-modeller skal behandle disse nøyaktig, må robotene lære å oversette skrevet tekst til handlingsbare data, som en e-post, telefonnummer, adresse osv. Modellen vil da lære at 7- eller 10-sifrede tallmønstre bør trekkes ut som telefonnumre og stor tekst som inneholder femsifrede koder og forskjellige substantiv som tekst. For å gjøre disse modellene mer nøyaktige kan vi også bruke teknikker fra Natural Language Processing (NLP) som Named Entity Recognition og Word Embedding.
Generelt for dokumentforståelse er det først viktig å forstå dataene og deretter implementere OCR med RPAer. Neste, i stedet for å kartlegge en prosess trinnvis, kan vi lære en robot å "gjøre som jeg gjør" ved å registrere prosessen slik den skjer med kraftige OCR-funksjoner som diskutert ovenfor, ved å integrere regler og maskinlæringsalgoritmer. Programvarroboten følger dine klikk og handlinger på skjermen og gjør dem deretter til en redigerbar arbeidsflyt. Hvis du jobber helt i lokale programmer, er det så mye du trenger å vite.
OCR-utfordringer som RPA-utviklere står overfor
Vi har sett hvordan vi kan integrere OCRR med RPA for forskjellige dokumenter, men det er noen få tilfeller av utfordringer der robotene trenger å håndtere godt. La oss diskutere dem nå!
- Svake eller inkonsekvente data: Data spiller en avgjørende rolle i dokumentforståelse. I de fleste tilfeller blir dokumentene skannet ved hjelp av kameraer der det er en sjanse for å miste dokumentformatering under tekstskanning (det vil si at fett, kursiv og understreking ikke alltid gjenkjennes). Noen ganger kan OCR trekke ut tekst på feil måte, noe som fører til stavefeil, uregelmessige avsnittbrudd, noe som reduserer den totale ytelsen til roboter. Derfor er det viktig å håndtere alle de manglende verdiene og fange data med høyere presisjon for å oppnå høyere nøyaktighet for OCR.
- Feil sideretning i dokumenter: Sideorientering og skjevhet er også et av de vanligste problemene som fører til feil tekstkorreksjon av OCR. Dette skjer vanligvis når dokumentene blir skannet feil i løpet av datainnsamlingsfasen. For å overvinne dette, må vi erklære noen funksjoner til roboter som automatisk tilpasning til siden, automatisk filtrering slik at de kan muliggjøre en økning i kvaliteten på det skannede dokumentet og motta riktige data på utdataene.
- Integreringsproblemer: Ikke alle RPA-verktøy fungerer bra på eksterne skrivebordsmiljøer - de forårsaker krasj og kritiske problemer i automatisering. I tillegg trenger RPA-utvikleren å vite hvilken OCR-løsning som vil være best for en bestemt sak. For å jobbe med spesifikke automatiseringsverktøy, må RPA-utvikleren bare velge begrenset OCR-teknologi opprettet av Microsoft, Google. Derfor er det noen ganger utfordrende å integrere våre tilpassede algoritmer og modeller.
- Hele teksten er kryptert tekst: I virkelighetsbruk er tekst som er fanget av en generisk OCR, kryptert og har ingen meningsfull informasjon som robotene kan bruke til å utføre betydelige operasjoner. RPA-utviklere trenger sterk ML-støtte for å kunne bygge nyttige applikasjoner.
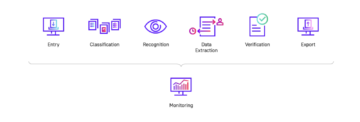
Rørledning for dokumentforståelse av arbeidsflyt
I de forrige avsnittene har vi sett hvordan roboter hjelper til med å utføre OCR for forskjellige typer dokumenter. Men OCR er bare en teknikk som konverterer bilder eller andre filer til teksten. Nå, i denne delen, vil vi se på arbeidsflyten Document Understanding helt fra begynnelsen av å samle inn dokumenter for til slutt å lagre dem meningsfull informasjon i ønsket format.

- Svelg dokumentet fra en mappe ved hjelp av Bot: Dette er det første trinnet gjennom å oppnå dokumentforståelse gjennom bots. Her henter vi dokumentet som ligger enten på en skyplattform (ved hjelp av en API) eller fra en lokal maskin. I noen få tilfeller, hvis dokumentene våre er på websider, kan vi automatisere skrapeskripter gjennom bots der de kan hente dokumenter i tide.
- Dokumenttype: Etter at vi har hentet dataene, er det viktig å forstå dokumenttypen og formatet de lagres med i systemene våre, ettersom vi noen ganger mottar data fra forskjellige kilder i forskjellige filformater som f.eks. PDF, PNG og JPG. Ikke bare filtypene, noen ganger når dokumentene skannes med telefonkameraer, bør noen få utfordrende problemer som bildeskjevhet, rotasjon, lysstyrke eller lav oppløsning også håndteres. Dermed må vi sørge for at roboter klassifiserer disse dokumentene i den strukturerte, semi-strukturerte eller ustrukturerte kategorien, og dermed lagre dem i et generisk format. Klassifiseringsoppgaven oppnås ved å sammenligne dokumentene med maler og analysere funksjoner som fonter, språk, tilstedeværelse av nøkkelverdi-par, tabeller, etc.
- Pakke ut dataene med OCR: Nå som robotene ordnet dokumentene våre i et generisk format og klassifiserte dem, er det på tide for oss å digitalisere dem ved hjelp av OCR-teknikken. Med dette får vi teksten, plasseringen i koordinater fra bildene. Dette hjelper til med å standardisere dokumentene og dataene for de påfølgende trinnene. Vi møter også noen få når OCR-programvare ikke kunne skille riktig mellom tegn, for eksempel 't' versus 'i' eller '0' versus 'O.' Selve feilene du vil unngå å bruke OCR-programvare, kan bli ny hodepine når OCR-teknologi ikke er i stand til å analysere nyansene i et dokument basert på kvalitet eller originalform. Det er her maskinlæring kommer inn i bildet, som vi skal diskutere i neste trinn.
- Utnytte ML / DL for intelligent OCR ved hjelp av Bots: Etter at dataene er digitalisert, bør OCR-programvaren forstå hva slags dokument den jobber med og hva som er relevant. Men den tradisjonelle OCR-programvaren kan slite med å skalere dokumentklassifiseringsarbeidet. Derfor bør programvareboter trent med kognitive evner ved å utnytte maskinlæring og dyplæringsteknikker for å gjøre OCR-ene mer intelligente. ML-baserte OCR-løsninger kan identifisere en dokumenttype og matche den med en kjent dokumenttype som brukes av virksomheten din. De kan også analysere og forstå tekstblokker i ustrukturerte dokumenter. Når løsningen vet mer om selve dokumentet, kan den begynne å hente ut relevant informasjon basert på intensjon og mening.
- Bedre datautvinning og klassifisering: Datautvinning er kjernen i Document Understanding. Som diskutert i forrige avsnitt om integrering av RPA med OCR i dette trinnet, velg datautvinningsteknikken basert på dokumenttypen. Gjennom RPA kan vi enkelt konfigurere hvilken avtrekker vi skal bruke, enten en regelbasert eller ML-basert eller en hybrid OCR-teknikk. Basert på tillits- og ytelsesberegningene som returneres etter informasjonsutvinning, vil programvarrobotene lagre dem i ønsket format for videre analyse. Nedenfor er et bilde av hvordan vi kan konfigurere ekstraktorer og sette konfidensnivå i et RPA-verktøy av UIPath.

6. Validering og styrkende innsikt: OCR- og maskinlæringsmodeller er ikke hundre prosent nøyaktige når det gjelder informasjonsutvinning, og dermed kan du legge til et lag med menneskelig inngripen ved hjelp av roboter for å løse problemet. Måten denne valideringen fungerer på er at når robotene håndterer lav nøyaktighet og unntak, gir det umiddelbart et varsel til handlingssenteret der en ansatt kan motta en forespørsel om å validere data eller håndtere unntak og kan løse eventuelle usikkerheter i løpet av klikk. Videre kan vi låse opp potensialet for kunstig intelligens for å dokumentere data over tid for å komme med spådommer, og identifisere potensielle avvik som kan indikere svindel, duplisering og andre feil.
Fordeler med å integrere roboter med Document Understanding
- Automatiser prosessen: Hovedårsaken til å integrere bots for dokumentforståelse er å automatisere hele prosessen fra start til slutt. Alt vi trenger å gjøre er å lage en arbeidsflyt for bots å lære, lene seg tilbake og slappe av. I løpet av valideringsprosessen kan det hende vi trenger å løse problemene som blir varslet av robotene der feil eller svindel blir identifisert.
- Bots med maskinlæring: Under automatiseringsprosessen kan vi gjøre roboter motstandsdyktige mot maskinlæring. Dette betyr at robotene også kan lære hvordan maskinlæringsmodellene fungerer og dermed forbedre modellene for å oppnå høyere nøyaktighet og ytelse for tekst- og informasjonsutvinning av dokumenter.
- Behandle bredt utvalg av dokumentbehandling: For generelle oppgaver som tabell- og informasjonsutvinning, må vi lage forskjellige dyplæringsrørledninger for forskjellige typer dokumenter. Dette fører til å bygge flere applikasjoner og distribuere forskjellige modeller på forskjellige servere, noe som krever mye krefter og tid. Når robotene er på bildet for et bredt spekter av dokumenter, kan vi bare ha en enkelt rørledning der robotene kan klassifisere dem og deretter bruke riktig modell for forskjellige oppgaver. Vi kan også integrere ulike tjenester gjennom APIer og kommunisere med andre organisasjoner når det gjelder å hente dataene.
- Lett å distribuere: For dokumentforståelse etter at rørledningene er opprettet, er distribusjonsprosessen bare et minutt. Vi kan enten få APIer eksportert av roboter etter opplæring, ellers kan vi lage en tilpasset RPA-løsning som kan brukes i våre lokale systemer. Denne typen utrulling kan også optimalisere bedriftene og kan redusere utgiftene med svært minimale risikoer.
Gå inn i Nanonets
NanoNets er en maskinlæringsplattform som lar brukere fange data fra fakturaer, kvitteringer og andre dokumenter uten maloppsett. Vi har toppmoderne dyplærings- og datasynsalgoritmer som kjører på baksiden som kan håndtere alle typer dokumentforståelsesoppgaver som OCR, tabellekstraksjon, nøkkelverdi-parekstraksjon. De eksporteres vanligvis som APIer eller kan distribueres lokalt basert på forskjellige brukstilfeller. Her er noen eksempler,
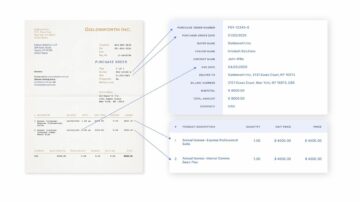
- Fakturamodell: Identifiser nøkkelfelt fra Fakturaer som kjøpers navn, faktura-ID, dato, beløp osv.
- Kvitteringsmodell: Identifiser nøkkelfelt fra kvitteringer som selgernavn, nummer, dato, beløp etc.
- Førerkort (USA): Identifiser nøkkelfelt som lisensnummer, DOB, utløpsdato, utstedelsesdato etc.
- CV: Utdrag erfaring, utdanning, ferdighetssett, kandidatinfo etc.
For å gjøre disse arbeidsflytene raskere og robuste bruker vi UiPath, et RPA-verktøy for sømløs automatisering av dokumentene dine uten noen mal. I neste avsnitt skal vi gå gjennom hvordan du kan bruke UiPath Connect med Nanonets for dokumentforståelse. De 3 største aktørene i RPA-markedet er UiPath, Automation Anywhere og Blå prisme. Denne bloggen fokuserer på Uipath.
NanoNets med UiPath
Vi har lært å lage en dokumentforståelsesrørledning i våre tidligere seksjoner. Det krever grunnleggende kunnskap om OCR, RPA og Machine learning, da det er forskjellige tilnærminger og algoritmer for forskjellige oppgaver på forskjellige punkter. Vi må også bruke mye krefter på å bygge nevrale nettverk som forstår malene våre, opplæring og distribusjon av dem. For å være komfortabel og automatisere alt rett fra å laste opp dokumenter, klassifisere dem, bygge OCR, integrere ML-modeller, jobber vi i Nanonets med Ui Path for å lage en sømløs rørledning for dokumentforståelse. Nedenfor er et bilde av hvordan dette fungerer.

La oss nå gjennomgå hver av disse og lære hvordan vi kan integrere Nanonets med UiPath.
Trinn 1: Registrer deg på UiPath og last ned UiPath Studio
For å opprette en arbeidsflyt, må vi først opprette en konto i UiPath. Hvis du er en eksisterende bruker, kan du logge deg direkte på kontoen din og omdirigere UiPath-dashbordet ditt. Deretter må du laste ned og installere UiPath Studio (Community Edition), som er gratis.
Trinn 2: Last ned Nanonets Component
Deretter for å sette opp din fakturabehandling rørledning, må du laste ned Nanonets Connector fra lenken nedenfor.
-> NanoNets OCR - RPA-komponent
Nedenfor er et skjermbilde av UiPath Marketplace og Nanonets Component. For å laste ned dette, sørg også for at du har logget på UiPath fra et Windows-operativsystem.

De nedlastede filene dine skal inneholde filene som er oppført nedenfor,
UiPath OCR Predict ├── Main.xaml
└── project.json
Trinn 3: Åpne filen Main.xaml Nanonets Component
For å sjekke om Nanonets UiPath fungerer eller ikke, kan du åpne Main.xml-filen fra den nedlastede Nanonets-komponenten ved hjelp av Ui Path Studio. Da kan du se at rørledningen din allerede er opprettet for deg for dokumentbehandling.

Trinn 4: Samle modell-ID, API-nøkkel og API-endepunkt fra Nanonets APP
Deretter kan du bruke noen av de trente OCR-modellene fra Nanonets APP og samle modell-ID, API-nøkkel og endepunkt. Nedenfor er flere detaljer for å finne dem raskt.
Modell-ID: Logg deg på Nanonets-kontoen din og naviger til "Mine modeller." Du kan trene en ny modell eller kopiere applikasjons-ID-en til en eksisterende modell.

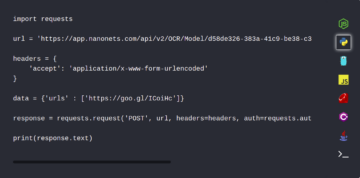
API-endepunkt: Du kan velge hvilken som helst eksisterende modell og klikke på Integrer for å finne API-endepunktet ditt. Nedenfor er et eksempel på hvordan endepunktene dine ser ut.
https://app.nanonets.com/api/v2/OCR/Model/XXXXXXX-4840-4c27-8940-d3add200779e/LabelUrls/

3. API-nøkkel: Naviger til fanen API-nøkkel, og du kan kopiere hvilken som helst eksisterende API-nøkkel eller opprette en ny.

Trinn 5: Legg til HTTP-forespørsel for å få metoden og variablene til UI-banen
Nå for å integrere modellen din fra Nanonets til UI-banen, har du det første klikket på HTTP-forespørsel og legg til EndPoint, som du finner ved venstre navigering under Inndataseksjonen. Nedenfor er et skjermbilde.

Senere, legg til alle variablene dine for å opprette en forbindelse fra UiPath-studioet ditt til Nanonets API. Du finner denne delen nederst i fanen "Variabler". Nedenfor er skjermbildet, du må oppdatere / kopiere API-nøkkelen, sluttpunktet og modell-ID-en til modellen din her.

Trinn 6: Legg til filplassering for spådommer
Til slutt kan du legge til filplasseringen din under attributtfanen, som vist på skjermbildet nedenfor, og trykke på avspillingsknappen på toppnavigasjonen for å forutsi utdataene dine.

Voila! Her er våre utganger for dokumentet vi ba om i skjermbildet nedenfor. For å behandle mer, kan du bare legge til filstedene og trykke på Run-knappen.

Trinn 7 - Skyv utdata til CSV / ERP
Til slutt, for å tilpasse utgangen til ønsket format, kan vi legge til nye blokker i rørledningen din i Main.XML-filen. Vi kan også skyve dette inn i eksisterende ERP-systemer gjennom frakoblede filer eller API-samtaler.

Kontakt oss på support@nanonets.com for hjelp
Webinar

Bli med på et webinar neste tirsdag på OCR med RPA, Registrer her.
Referanser
[2] Dokumentforståelse - AI-dokumentbehandling
[3] RPA OCR - løftende prosessautomatisering | HYGGELIG
[4] Hvordan bruke AI for å optimalisere dokumentforståelse
[5] https://www.uipath.com/product/document-understanding
[6] Bruke NanoNets i UiPath Workflow for OCR for Invoice
Videre Reading
Du kan være interessert i de siste innleggene våre på:
Oppdatering:
Lagt til mer lesestoff om bruken og virkningen av OCR, RPA i dokumentforståelse.
Kilde: https://nanonets.com/blog/ocr-with-rpa-and-document-understanding-uipath/
- '
- &
- 000
- 2021
- 7
- Logg inn
- regnskap
- Handling
- Fordel
- AI
- algoritme
- algoritmer
- Alle
- analyse
- api
- APIer
- app
- Søknad
- søknader
- Kunst
- kunstig intelligens
- Kunstig intelligens (AI)
- Kunstig intelligens og maskinlæring
- Automatisering
- automatisering hvor som helst
- BEST
- Biggest
- Blogg
- Bot
- roboter
- bygge
- Bygning
- virksomhet
- kameraer
- saker
- Årsak
- forårsaket
- karaktergjenkjenning
- klassifisering
- Cloud
- Skyplattform
- kode
- kognitiv
- Samle
- kommentarer
- Felles
- samfunnet
- Selskaper
- komponent
- Datamaskin syn
- selvtillit
- innhold
- Korreksjoner
- Kostnader
- dashbord
- dato
- Dataledelse
- avtale
- dyp læring
- Utvikler
- utviklere
- Enheter
- digitalt
- dokumenter
- Dodge
- kjøring
- Kunnskap
- effektivitet
- emalje
- ansatte
- Endpoint
- Enterprise
- etc
- trekke ut dataene
- utdrag
- Trekk
- Egenskaper
- Felt
- Endelig
- finansiere
- Først
- Fokus
- skjema
- format
- svindel
- Gratis
- framtid
- Gartner
- general
- gif
- god
- veilede
- Håndtering
- hodepine
- her.
- Høy
- Hvordan
- Hvordan
- HTTPS
- stort
- Mennesker
- Hybrid
- identifisere
- bilde
- Påvirkning
- Øke
- info
- informasjon
- informasjonsutvinning
- Intelligens
- hensikt
- saker
- IT
- nøkkel
- kunnskap
- KYC
- Språk
- siste
- føre
- ledende
- LÆRE
- lært
- læring
- Nivå
- Leverage
- Tillatelse
- Begrenset
- LINK
- lokal
- plassering
- maskinlæring
- ledelse
- marked
- markedsplass
- Match
- måle
- Kjøpmann
- Metrics
- Microsoft
- ML
- modell
- Filmer
- Naturlig språk
- Natural Language Processing
- Navigasjon
- nettverk
- neural
- nevrale nettverk
- nlp
- varsling
- tall
- OCR
- åpen
- drift
- operativsystem
- Drift
- Optisk karaktergjenkjennelse
- rekkefølge
- Annen
- andre
- pass
- ytelse
- bilde
- plattform
- Populær
- innlegg
- makt
- Precision
- Spådommer
- Prosessautomatisering
- programmer
- prosjekt
- kvalitet
- hever
- område
- RE
- Lesning
- redusere
- Resultater
- anmeldelse
- robot
- Robot prosessautomatisering
- robotikk
- roboter
- Sør-Afrika
- regler
- Kjør
- rennende
- sap
- besparende
- Skala
- skanning
- skraping
- Skjerm
- sømløs
- selgere
- Serien
- Tjenester
- sett
- Enkelt
- So
- Software
- Programvarebots
- Solutions
- LØSE
- bruke
- Begynn
- Tilstand
- Studer
- støtte
- system
- Systemer
- utvinning av bordet
- Technologies
- Teknologi
- Fremtiden
- tid
- topp
- Kurs
- ui
- UiPath
- Oppdater
- us
- USA
- bruk-tilfeller
- Brukere
- verdi
- Versus
- syn
- web
- webinar
- nettsteder
- HVEM
- vinduer
- innenfor
- Arbeid
- arbeidsflyt
- virker
- XML
- år
- youtube