Organisasjoner bruker dataene sine til å løse komplekse problemer ved å starte små, kjøre iterative eksperimenter og avgrense løsningen. Selv om kraften til eksperimenter ikke kan ignoreres, må organisasjoner være forsiktige med kostnadseffektiviteten til slike eksperimenter. Hvis det brukes tid på å lage den underliggende infrastrukturen for å aktivere eksperimenter, øker det kostnadene ytterligere.
Utviklere trenger et integrert utviklingsmiljø (IDE) for datautforskning og feilsøking av arbeidsflyter, og forskjellige beregningsprofiler for å kjøre disse arbeidsflytene. Hvis du velger Amazon EMR for slike brukstilfeller kan du bruke en IDE kalt Amazon EMR Studio for datautforskning, transformasjon, versjonskontroll og feilsøking, og kjør Spark-jobber for å behandle store datamengder. Utplassering Amazon EMR på Amazon EKS forenkler administrasjonen, reduserer kostnader og forbedrer ytelsen. En dataingeniør eller IT-administrator må imidlertid bruke tid på å lage den underliggende infrastrukturen, konfigurere sikkerhet og opprette et administrert endepunkt som brukerne kan koble til. Dette betyr at slike prosjekter må vente til disse ekspertene oppretter infrastrukturen.
I dette innlegget viser vi hvordan en dataingeniør eller IT-administrator kan bruke AWS Analytics Referansearkitektur (ARA) for å akselerere utrulling av infrastruktur, og sparer organisasjonen din for både tid og penger brukt på disse dataanalyseeksperimentene. Vi bruker biblioteket til å distribuere en Amazon Elastic Kubernetes (Amazon EKS) klynge, konfigurer den til å bruke Amazon EMR på EKS, og distribuer en virtuell klynge og administrerte endepunkter og EMR Studio. Du kan da enten kjøre jobber på den virtuelle klyngen eller kjøre utforskende dataanalyse med Jupyter bærbare på Amazon EMR Studio og Amazon EMR på EKS. Arkitekturen nedenfor representerer infrastrukturen du vil distribuere med AWS Analytics Reference Architecture.

Forutsetninger
For å følge med, må du ha en AWS-konto som er oppstartet med AWS skyutviklingssett (AWS CDK). For instruksjoner, se bootstrapping. Følgende opplæring bruker TypeScript, og krever versjon 2 eller nyere av AWS CDK. Hvis du ikke har AWS CDK installert, se Installer AWS CDK.
Sett opp et AWS CDK-prosjekt
For å distribuere ressurser ved å bruke ARA, må du først sette opp et AWS CDK-prosjekt og installere ARA-biblioteket. Fullfør følgende trinn:
- Opprett en mappe som heter emr-eks-app:
- Initialiser et AWS CDK-prosjekt i en tom katalog og kjør følgende kommando:
- Installer ARA-biblioteket:
- I lib/emr-eks-app.ts importerer du ARA-biblioteket som følger. Den første linjen kaller ARA-biblioteket, den andre definerer AWS Identity and Access Management (IAM) policyer:
Opprett og definer en EKS-klynge og regnekapasitet
For å lage en EMR på EKS virtuell klynge, må du først distribuere en EKS-klynge. ARA-biblioteket definerer en konstruksjon kalt EmrEksCluster. Konstruksjonen gir en EKS-klynge, muliggjør IAM -roller for tjenestekontoer, og distribuerer et sett med støttekontrollere som sertifikatbehandlingskontroller (nødvendig av det administrerte endepunktet som brukes av Amazon EMR Studio) samt en cluster auto scaler for å ha en elastisk klynge og spare kostnader når ingen jobb sendes til klyngen .
In lib/emr-eks-app.ts, legg til følgende linje:
For å lære mer om egenskapene du kan tilpasse, se EmrEksClusterProps. Det er to obligatoriske parametere i EmrEksCluster konstruksjon: Den første er eksAdminRoleArn rollen er obligatorisk og er rollen du bruker til å samhandle med Kubernetes kontrollplan. Denne rollen må ha administrative tillatelser til opprette eller oppdatere klyngen. Den andre parameteren er autoscaling, lar denne parameteren deg velge autoskaleringsmekanismen, enten Snekker or innfødt Kubernetes Cluster Autoscaler. I denne bloggen vil vi bruke Karpenter og vi anbefaler bruken på grunn av raskere autoskalering, forenklet nodeadministrasjon og klargjøring. Nå er du klar til å definere beregningskapasiteten.
En måte å definere arbeidernoder i Amazon EKS er å bruke administrerte nodegrupper. Vi bruker én nodegruppe kalt tooling, som er vert for coredns, inntrengningskontroller, sertifikatleder, Snekker og enhver annen pod som er nødvendig for å kjøre EMR på EKS-jobber eller ManagedEndpoint. Vi definerer også standard Karpenter Proviantører som definerer kapasitet som skal brukes for jobber levert av EMR på EKS. Disse provisjonørene er optimalisert for forskjellige Spark-brukstilfeller (kritiske jobber, ikke-kritisk jobb, eksperimentering og interaktive økter). Konstruksjonen lar deg også sende inn din egen provisjoner definert av et Kubernetes-manifest gjennom en metode kalt addKarpenterProvisioner. La oss diskutere de forhåndsdefinerte provisjonørene.
Standard Provisioners-konfigurasjoner
Standard provisjonsprogrammer er satt for rask eksperimentering og er det alltid opprettet som standard. Men hvis du ikke vil bruke dem, kan du stille inn defaultNodeGroups parameter til false i EmrEksCluster eiendommer på opprettelsestidspunktet. Provisjonsleverandørene er definert som følger og opprettes i hvert av undernettene som brukes av Amazon EKS:
- Kritisk proviantør – Den er dedikert til å støtte jobber med aggressive SLAer og er tidssensitive. Provideren bruker On-Demand Instances, som ikke stoppes, i motsetning til Spot Instances, og deres livssyklus følger gjennom en av jobbene. Nodene bruker forekomstlagre, som er NVMe-disker som er fysisk koblet til verten, som tilbyr en høy I/O-gjennomstrømning som gir bedre Spark-ytelse, fordi den brukes som midlertidig lagring for disksøl og shuffle. Forekomsttypene som brukes i noden er av m6gd-familien. Forekomstene bruker AWS Graviton prosessor, som tilbyr bedre pris/ytelse enn x86-prosessorer. For å bruke denne klargjøringen i jobbene dine, kan du bruke følgende eksempelkonfigurasjon, som er referert til i konfigurasjonsoverstyring av EMR om EKS-jobbinnlevering.
- Ikke-kritisk proviantør – Denne leverandøren utnytter Spot Instances for å spare kostnader for jobber som ikke er tidssensitive eller jobber som brukes til eksperimenter. Denne noden bruker Spot Instances fordi jobbene ikke er kritiske og kan avbrytes. Disse forekomstene kan stoppes hvis forekomsten kreves tilbake. Forekomsttypene som brukes i noden er av m6gd-familien, driveren er On-Demand og eksekutører er på spot-forekomster.
- Provisor for bærbare datamaskiner – Provisioneren er for å kjøre administrerte endepunkter som brukes av Amazon EMR Studio for datautforskning ved å bruke Amazon EMR på EKS. Forekomstene er av t3-familien og er On-Demand for driver- og Spot-forekomster for utførende for å holde kostnadene lave. Dersom eksekutørinstansene stoppes, startes nye av Karpenter. Hvis executor-forekomstene stoppes for ofte, kan du definere dine egne som bruker On-Demand-forekomster.
Følgende link gir flere detaljer om hvordan hver av leverandørene er definert. En importegenskap som er definert i standard provisjoneringsprogrammer, er at det er en for hver A-Å. Dette er viktig fordi det lar deg redusere overføringskostnadene mellom AZ-nettverk når Spark kjører en shuffle.
For dette innlegget bruker vi standard Provisioners, så du trenger ikke legge til noen kodelinjer for denne delen. Hvis du vil legge til dine egne Provisioners, kan du utnytte metoden addKarpenterProvisioner å bruke dine egne manifester. Du kan bruke hjelpemetoder i Utils klasse som readYamlDocument å lese YAML-dokument og loadYaml last inn YAML-filer og send dem som argumenter til addKarpenterProvisioner metoden.
Distribuer den virtuelle klyngen og en utførelsesrolle
En virtuell klynge er et Kubernetes-navneområde som Amazon EMR er registrert med; når du sender inn en jobb, kjører driver- og eksekveringsputene i det tilknyttede navneområdet. De EmrEksCluster konstruksjon tilbyr en metode kalt addEmrVirtualCluster, som oppretter den virtuelle klyngen for deg. Metoden tar EmrVirtualClusterOptions som en parameter, som har følgende attributter:
- navn – Navnet på den virtuelle klyngen din.
- opprette navneområde – Et valgfritt felt som oppretter EKS-navneområdet. Dette er av typen boolsk og som standard oppretter det ikke et eget EKS-navneområde, så din virtuelle klynge opprettes i standardnavneområdet.
- eksNamespace – Navnet på EKS-navneområdet som skal kobles til den virtuelle EMR-klyngen. Hvis det ikke er oppgitt noe navneområde, bruker konstruksjonen standard navneområde.
- In
lib/emr-eks-app.ts, legg til følgende linje for å lage din virtuelle klynge:Nå oppretter vi utførelsesrollen, som er en IAM-rolle som brukes av sjåføren og utføreren for å samhandle med AWS-tjenester. Før vi kan opprette utførelsesrollen for Amazon EMR, må vi først opprette
ManagedPolicy. Merk at i den følgende koden oppretter vi en policy for å tillate tilgang til Amazon Simple Storage Service (Amazon S3) bøtte og Amazon CloudWatch-logger. - In
lib/emr-eks-app.ts, legg til følgende linje for å opprette policyen:Hvis du vil bruke AWS Glue Data Catalog, legg til tillatelsen i den foregående policyen.
Nå oppretter vi utførelsesrollen for Amazon EMR på EKS ved å bruke policyen definert i forrige trinn ved å bruke
createExecutionRoleinstansmetoden. Driver- og executor-podene kan deretter påta seg denne rollen for å få tilgang til og behandle data. Rollen er scoped på en slik måte at bare pods i det virtuelle klyngenavnet kan påta seg den. For å lære mer om betingelsen implementert av denne metoden for å begrense tilgangen til rollen til kun pods som er opprettet av Amazon EMR på EKS i navneområdet til den virtuelle klyngen, se Bruke jobbutførelsesroller med Amazon EMR på EKS. - In
lib/emr-eks-app.ts, legg til følgende linje for å opprette utførelsesrollen:Den foregående koden produserer en IAM-rolle kalt
execRoleJobmed IAM-policyen definert iemrekspolicyog scoped til navneområdetdataanalysis. - Til slutt gir vi ut parametere som er viktige for jobbkjøringen:
Distribuer Amazon EMR Studio og klargjør brukere
For å distribuere et EMR Studio for datautforskning og jobbredigering, har ARA-biblioteket en konstruksjon kalt NotebookPlatform. Denne konstruksjonen lar deg distribuere så mange EMR Studios du trenger (innenfor kontogrensen) og sette dem opp med autentiseringsmodusen som passer for deg og tilordne brukere til dem. For å lære mer om autentiseringsmodusene som er tilgjengelige i Amazon EMR Studio, se Velg en autentiseringsmodus for Amazon EMR Studio.
Konstruksjonen skaper alle nødvendige IAM-roller og policyer som kreves av Amazon EMR Studio. Den lager også en S3-bøtte der alle bærbare PC-er lagres av Amazon EMR Studio. Bøtten er kryptert med en kundeadministrert nøkkel (CMK) generert av AWS CDK-stakken. Følgende trinn viser deg hvordan du lager ditt eget EMR-studio med konstruksjonen.
Konstruksjonen av den bærbare plattformen tar NotebookPlatformProps som en egenskap, som lar deg definere ditt EMR-studio, et navneområde, navnet på EMR-studioet og dets autentiseringsmodus.
- In
lib/emr-eks-app.ts, legg til følgende linje:For dette innlegget bruker vi IAM-brukere slik at du enkelt kan reprodusere det på din egen konto. Men hvis du allerede har IAM federation eller single sign-on (SSO) på plass, kan du bruke dem i stedet for IAM-brukere. For å lære mer om parametrene til
NotebookPlatformProps, referere til NotebookPlatformProps.Deretter må vi opprette og tilordne brukere til Amazon EMR Studio. For dette har konstruksjonen en metode kalt
addUsersom tar en liste over brukere og enten tildeler dem til Amazon EMR Studio i tilfelle SSO eller oppdaterer IAM-policyen for å gi tilgang til Amazon EMR Studio for de oppgitte IAM-brukerne. Brukeren kan også ha flere administrerte endepunkter, og hver bruker kan ha sin Amazon EMR-versjon definert. De kan bruke et annet sett med Amazon Elastic Compute Cloud (Amazon EC2)-forekomster og forskjellige tillatelser ved å bruke jobbutførelsesroller. - In
lib/emr-eks-app.ts, legg til følgende linje:I den foregående koden, for korthets skyld, gjenbruker vi den samme IAM-policyen som vi opprettet i utførelsesrollen.
Merk at konstruksjonen optimaliserer antallet administrerte endepunkter som opprettes. Hvis to endepunkter har samme navn, opprettes bare ett.
- Nå som vi har definert distribusjonen vår, kan vi distribuere den:
Du kan finne et eksempelprosjekt som inneholder alle trinnene i gjennomgangen i følgende GitHub Repository.
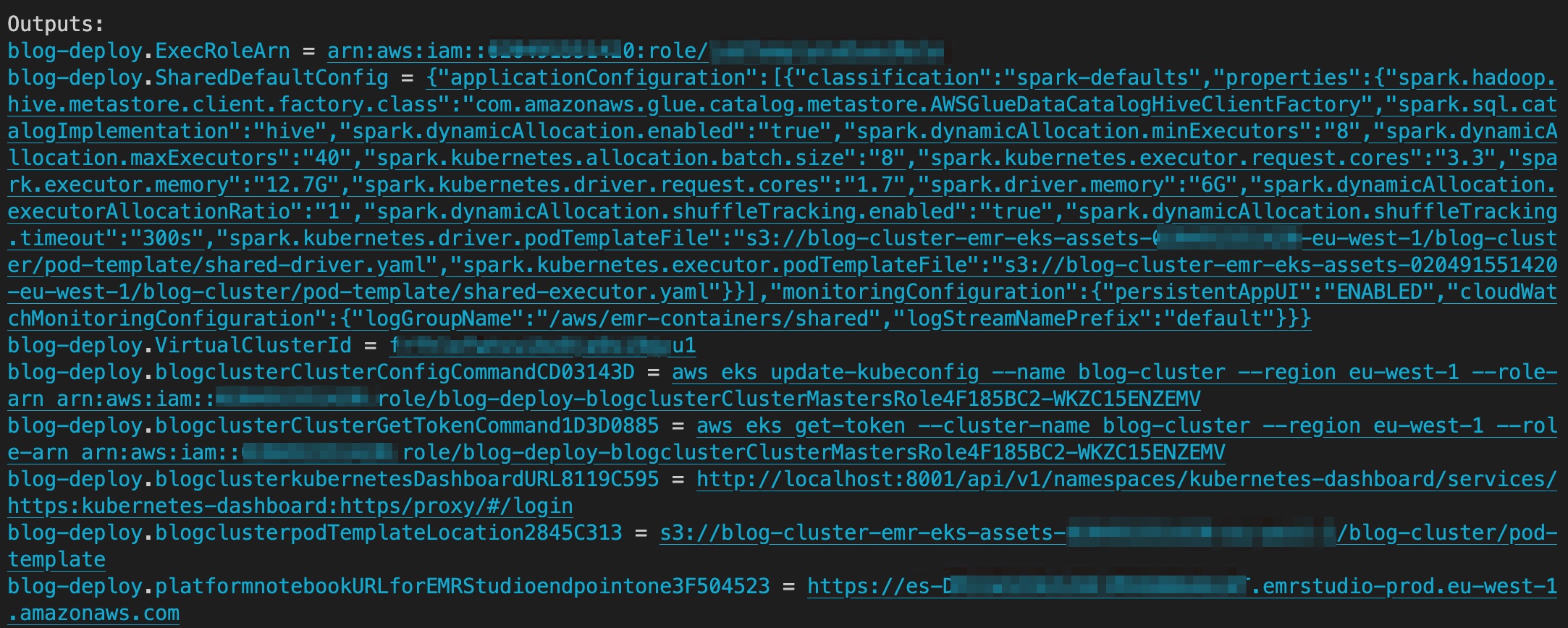
Når distribusjonen er fullført, inneholder utdata S3-bøtten som inneholder ressursene for podTemplate, koblingen til EMR Studio og den virtuelle klynge-IDen for EMR Studio. Følgende skjermbilde viser utdataene fra AWS CDK etter at distribusjonen er fullført.
Send inn jobber

Fordi vi bruker standard Provisioners, vil vi bruke podTemplate som er definert av konstruksjonen tilgjengelig på ARA GitHub-depot. Disse lastes opp for deg av konstruksjonen til en S3-bøtte kalt <clustername>-emr-eks-assets; du trenger bare å referere til dem i Spark-jobben din. I denne jobben bruker du også jobbparametrene i utdataene på slutten av AWS CDK-distribusjonen. Disse parameterne lar deg bruke AWS Glue Data Catalog og implementere Spark på Kubernetes beste praksis som dynamicAllocation og podsamlokalisering. Ved slutten av cdk deploy ARA vil sende ut jobbeksempelkonfigurasjoner med de beste fremgangsmåtene oppført før som du kan bruke til å sende inn en jobb. Du kan sende inn en jobb som følger.
En jobbkjøring er en arbeidsenhet, for eksempel en Spark JAR-fil som sendes til EMR på EKS-klyngen. Vi starter en jobb ved å bruke start-job-run kommando. Merk du kan bruke SparkSubmitParameters for å spesifisere Amazon S3-banen til pod-malen, som vist i følgende kommando:
Koden har følgende verdier:
- – Den virtuelle EMR-klynge-IDen
- – Navnet på Spark-jobben din
- – Utførelsesrollen du opprettet
- – Amazon S3 URI for Spark-jobben din
- – Amazon S3 URI til driverpod-malen, som du får fra AWS CDK-utgangen
- – Amazon S3 URI for executor pod-malen
- – Ditt CloudWatch-logggruppenavn
- – Prefikset for CloudWatch-loggstrøm
Du kan gå til Amazon EMR-konsollen for å sjekke statusen til jobben din og for å se logger. Du kan også sjekke statusen ved å kjøre describe-job-run kommando:
Utforsk data ved hjelp av Amazon EMR Studio
I denne delen viser vi hvordan du kan opprette et arbeidsområde i Amazon EMR Studio og koble til det Amazon EKS-administrerte endepunktet fra arbeidsområdet. Fra utgangen, bruk koblingen til Amazon EMR Studio for å navigere til EMR Studio-distribusjonen. Du må logge på med IAM brukernavn du oppga i addUser metoden.
Opprett et arbeidsområde
For å opprette et arbeidsområde, fullfør følgende trinn:
- Logg på EMR Studio opprettet av AWS CDK.
- Velg Opprett arbeidsområde.
- Skriv inn et arbeidsområdenavn og en valgfri beskrivelse.
- Plukke ut Allow Arbeidsområde Samarbeid hvis du vil jobbe med andre Studio-brukere i dette arbeidsområdet i sanntid.
- Velg Opprett arbeidsområde.

Etter at du har opprettet arbeidsområdet, velg det fra listen over arbeidsområder for å åpne JupyterLab-miljøet.
Følgende skjermbilde viser hvordan terminalen ser ut. For mer informasjon om brukergrensesnittet, se Forstå Workspace-brukergrensesnittet.
Koble til en EMR på EKS-administrert endepunkt
Du kan enkelt koble til EMR på EKS-administrert endepunkt fra arbeidsområdet.
- I navigasjonsruten, på klynger menyen, velg EMR-klynge på EKS forum Klyngetype.
De virtuelle klyngene vises på rullegardinmenyen EMR-klynge på EKS, og endepunktet vises på rullegardinmenyen Endpoint. Hvis det er flere endepunkter, vises de her, og du kan enkelt bytte mellom endepunkter fra arbeidsområdet. - Velg riktig endepunkt og velg Legg ved.

Arbeid med en notatbok
Du kan nå åpne en notatbok og koble til en foretrukket kjerne for å utføre oppgavene dine. For eksempel kan du velge en PySpark-kjerne, som vist i følgende skjermbilde.
Utforsk dataene dine
Det første trinnet i vår datautforskningsøvelse er å lage en Spark-økt og deretter laste ned New York taxi-datasettet fra S3-bøtten til en Dataramme. Bruk følgende kodeblokk for å laste dataene inn i en dataramme. Kopier Amazon S3 URI for stedet der datasettet ligger i Amazon S3.
Etter at vi har lastet dataene inn i en dataramme, erstatter vi dataene til current_date kolonne med den faktiske gjeldende datoen, tell antall rader og lagre dataene i en parkettfil:
Følgende skjermbilde viser resultatet av den bærbare datamaskinen vår som kjører på Amazon EMR Studio og med PySpark som kjører på Amazon EMR på EKS.
Rydd opp
For å rydde opp etter dette innlegget, kjør cdk destroy.
konklusjonen
I dette innlegget viste vi hvordan du kan bruke ARA til raskt å distribuere en dataanalyseinfrastruktur og begynne å eksperimentere med dataene dine. Du kan finne hele eksemplet referert til i dette innlegget i GitHub repository. AWS Analytics Reference Architecture implementerer vanlige Analytics-mønstre og AWS-beste praksiser for å gi deg klare til å bruke konstruksjoner for eksperimentene dine. Et av mønstrene er datanettet, som du kan se hvordan du kan bruke i dette blogginnlegg.
Du kan også utforske andre konstruksjoner som tilbys i dette biblioteket å eksperimentere med AWS Analytics-tjenester før du overfører arbeidsmengden til produksjon.
Om forfatterne
 Lotfi Mouhib er en senior løsningsarkitekt som jobber for teamet i offentlig sektor med Amazon Web Services. Han hjelper offentlige kunder i hele EMEA med å realisere ideene sine, bygge nye tjenester og innovere for innbyggerne. På fritiden liker Lotfi å sykle og løpe.
Lotfi Mouhib er en senior løsningsarkitekt som jobber for teamet i offentlig sektor med Amazon Web Services. Han hjelper offentlige kunder i hele EMEA med å realisere ideene sine, bygge nye tjenester og innovere for innbyggerne. På fritiden liker Lotfi å sykle og løpe.
 Sandipan Bhaumik er en Senior Analytics Specialist Solutions Architect basert i London. Han har jobbet med kunder i forskjellige bransjer som bank- og finanstjenester, helsevesen, kraft og verktøy, produksjon og detaljhandel og hjulpet dem med å løse komplekse utfordringer med storskala dataplattformer. Hos AWS fokuserer han på strategiske kontoer i Storbritannia og Irland og hjelper kunder med å akselerere reisen til skyen og innovere ved å bruke AWS-analyse og maskinlæringstjenester. Han elsker å spille badminton og lese bøker.
Sandipan Bhaumik er en Senior Analytics Specialist Solutions Architect basert i London. Han har jobbet med kunder i forskjellige bransjer som bank- og finanstjenester, helsevesen, kraft og verktøy, produksjon og detaljhandel og hjulpet dem med å løse komplekse utfordringer med storskala dataplattformer. Hos AWS fokuserer han på strategiske kontoer i Storbritannia og Irland og hjelper kunder med å akselerere reisen til skyen og innovere ved å bruke AWS-analyse og maskinlæringstjenester. Han elsker å spille badminton og lese bøker.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/accelerate-your-data-exploration-and-experimentation-with-the-aws-analytics-reference-architecture-library/
- 1
- 10
- 100
- 11
- 6G
- 7
- 9
- a
- Om oss
- akselerere
- adgang
- tilgangsstyring
- Logg inn
- kontoer
- tvers
- handlinger
- Legger
- administrativ
- Etter
- aggressiv
- Alle
- allokering
- tillater
- allerede
- Selv
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- analyse
- analytics
- og
- Apache
- app
- vises
- Påfør
- hensiktsmessig
- arkitektur
- argumenter
- Eiendeler
- assosiert
- feste
- attributter
- Autentisering
- forfatter
- auto
- tilgjengelig
- AWS
- AWS Lim
- AWS Identity and Access Management (IAM)
- Banking
- basert
- fordi
- før du
- under
- BEST
- beste praksis
- Bedre
- mellom
- Blokker
- Blogg
- bøker
- bygge
- bygger
- som heter
- Samtaler
- Kapasitet
- saken
- saker
- katalog
- forsiktige
- CD
- sertifikat
- utfordringer
- sjekk
- Velg
- Borgere
- klasse
- klassifisering
- kunde
- Cloud
- Cluster
- kode
- Kolonne
- COM
- Felles
- fullføre
- komplekse
- Beregn
- tilstand
- Koble
- Konsoll
- konstruere
- inneholder
- kontroll
- controller
- Kostnad
- Kostnader
- skape
- opprettet
- skaper
- Opprette
- skaperverket
- kritisk
- Gjeldende
- Kunder
- tilpasse
- dato
- dataanalyse
- Data Analytics
- dataingeniør
- Dato
- dato tid
- dedikert
- Misligholde
- definerer
- utplassere
- utplasserings
- distribusjon
- Distribueres
- beskrivelse
- detaljer
- Utvikling
- forskjellig
- diskutere
- dokument
- ikke
- ikke
- sjåfør
- hver enkelt
- lett
- effekt
- enten
- EMEA
- aktivert
- muliggjør
- muliggjør
- kryptert
- Endpoint
- ingeniør
- Miljø
- Eter (ETH)
- eksempel
- gjennomføring
- Øvelse
- eksperiment
- eksperter
- leting
- Utforskende dataanalyse
- utforske
- fabrikk
- familie
- raskere
- Føderasjon
- felt
- filet
- Filer
- finansiell
- finansielle tjenester
- Finn
- Først
- fokuserer
- følge
- etter
- følger
- RAMME
- fra
- fullt
- funksjoner
- videre
- generert
- få
- GitHub
- Go
- Gruppe
- Gruppens
- Hadoop
- helsetjenester
- hjelpe
- hjelper
- her.
- Høy
- Hive
- vert
- Hvordan
- Hvordan
- Men
- HTML
- HTTPS
- IAM
- Ideer
- Identitet
- styring av identitet og tilgang
- Identitets- og tilgangsstyring (IAM)
- iverksette
- implementert
- redskaper
- importere
- viktig
- forbedrer
- in
- bransjer
- informasjon
- Infrastruktur
- innovere
- installere
- f.eks
- i stedet
- instruksjoner
- integrert
- samhandle
- interaktiv
- Interface
- avbrutt
- Irland
- IT
- Jobb
- Jobb
- reise
- JSON
- Hold
- Kubernetes
- stor
- storskala
- LÆRE
- læring
- Leverage
- Bibliotek
- BEGRENSE
- linje
- linjer
- LINK
- knyttet
- Liste
- oppført
- laste
- plassering
- London
- UTSEENDE
- Lav
- maskin
- maskinlæring
- fikk til
- ledelse
- leder
- obligatorisk
- produksjon
- mange
- midler
- mekanisme
- Minne
- Meny
- metode
- metoder
- Mote
- penger
- mer
- flere
- navn
- oppkalt
- Naviger
- Navigasjon
- nødvendig
- Trenger
- nødvendig
- behov
- nettverk
- Ny
- New York
- node
- noder
- bærbare
- notatbøker
- Antall
- tilby
- tilbudt
- Tilbud
- ONE
- åpen
- optimalisert
- Optimaliserer
- organisasjon
- organisasjoner
- Annen
- egen
- brød
- parameter
- parametere
- banen
- Mønster
- mønstre
- ytelse
- tillatelse
- tillatelser
- fysisk
- Sted
- plattform
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- pods
- Politikk
- politikk
- Post
- makt
- praksis
- trekkes
- forrige
- problemer
- prosess
- prosessor
- Produksjon
- Profiler
- prosjekt
- prosjekter
- egenskaper
- eiendom
- forutsatt
- gir
- forsyning
- offentlig
- raskt
- rask
- Lese
- Lesning
- klar
- ekte
- sanntids
- realisere
- anbefaler
- poster
- redusere
- reduserer
- registrert
- erstatte
- representere
- anmode
- Krever
- Ressurser
- begrense
- resultere
- detaljhandel
- Rolle
- roller
- Kjør
- rennende
- sake
- samme
- Spar
- besparende
- Sekund
- Seksjon
- sektor
- sikkerhet
- senior
- sensitive
- tjeneste
- Tjenester
- Session
- sett
- Vis
- vist
- Viser
- shuffle
- undertegne
- Enkelt
- forenklet
- enkelt
- Størrelse
- liten
- So
- løsning
- Solutions
- LØSE
- Spark
- spesialist
- bruke
- brukt
- Spot
- SQL
- stable
- Begynn
- startet
- Start
- uttalelser
- status
- Trinn
- Steps
- stoppet
- lagring
- lagret
- butikker
- Strategisk
- stream
- studio
- studioer
- innsending
- send
- innsendt
- subnett
- slik
- egnet
- medfølgende
- Støtte
- Bytte om
- tar
- oppgaver
- lag
- mal
- midlertidig
- terminal
- De
- Storbritannia
- deres
- Gjennom
- gjennomstrømning
- tid
- til
- også
- Totalt
- overføre
- Transformation
- overgangen
- sant
- tutorial
- typer
- Loggfila
- Uk
- underliggende
- enhet
- Oppdater
- oppdateringer
- lastet opp
- URI
- bruke
- Bruker
- Brukergrensesnitt
- Brukere
- verktøy
- verdi
- Verdier
- versjon
- versjonskontroll
- Se
- virtuelle
- volum
- vente
- web
- webtjenester
- Hva
- hvilken
- vil
- innenfor
- Arbeid
- arbeidet
- arbeidstaker
- arbeidsflyt
- arbeid
- skrive
- yaml
- Din
- zephyrnet