Med Amazon Rekognition Egendefinerte etiketter, du kan ha Amazon-anerkjennelse trene opp en tilpasset modell for objektgjenkjenning eller bildeklassifisering som er spesifikk for bedriftens behov. For eksempel kan Rekognition Custom Labels finne logoen din i innlegg på sosiale medier, identifisere produktene dine i butikkhyllene, klassifisere maskindeler i et samlebånd, skille mellom sunne og infiserte planter eller oppdage animerte figurer i videoer.
Å utvikle en Rekognition Custom Labels-modell for å analysere bilder er en betydelig oppgave som krever tid, ekspertise og ressurser, som ofte tar måneder å fullføre. I tillegg krever det ofte tusenvis eller titusenvis av håndmerkede bilder for å gi modellen nok data til å ta avgjørelser nøyaktig. Generering av disse dataene kan ta måneder å samle inn, og det kreves at store team med merkevare klargjør dem for bruk i maskinlæring (ML).
Med Rekognition Custom Labels tar vi oss av de tunge løftene for deg. Anerkjennelse Egendefinerte etiketter bygger på de eksisterende egenskapene til Amazon Rekognition, som allerede er trent på titalls millioner bilder i mange kategorier. I stedet for tusenvis av bilder, trenger du ganske enkelt å laste opp et lite sett med treningsbilder (vanligvis noen få hundre bilder eller mindre) som er spesifikke for din brukssituasjon via vår brukervennlige konsoll. Hvis bildene dine allerede er merket, kan Amazon Rekognition begynne treningen med bare noen få klikk. Hvis ikke, kan du merke dem direkte i Amazon Rekognition-merkingsgrensesnittet, eller bruke Amazon SageMaker Ground Truth for å merke dem for deg. Etter at Amazon Rekognition begynner å trene fra bildesettet ditt, produserer det en tilpasset bildeanalysemodell for deg på bare noen få timer. Bak kulissene laster og inspiserer Rekognition Custom Labels automatisk treningsdataene, velger de riktige ML-algoritmene, trener en modell og gir modellytelsesmålinger. Du kan deretter bruke din egendefinerte modell via Rekognition Custom Labels API og integrere den i applikasjonene dine.
Å bygge en Rekognition Custom Labels-modell og hoste den for sanntidsprediksjoner innebærer imidlertid flere trinn: å lage et prosjekt, lage opplærings- og valideringsdatasettene, trene modellen, evaluere modellen og deretter opprette et endepunkt. Etter at modellen er distribuert for slutning, må du kanskje trene modellen på nytt når nye data blir tilgjengelige eller hvis tilbakemelding mottas fra slutninger fra den virkelige verden. Automatisering av hele arbeidsflyten kan bidra til å redusere manuelt arbeid.
I dette innlegget viser vi hvordan du kan bruke AWS trinnfunksjoner å bygge og automatisere arbeidsflyten. Step Functions er en visuell arbeidsflyttjeneste som hjelper utviklere å bruke AWS-tjenester til å bygge distribuerte applikasjoner, automatisere prosesser, orkestrere mikrotjenester og lage data- og ML-pipelines.
Løsningsoversikt
Arbeidsflyten for trinnfunksjoner er som følger:
- Vi oppretter først et Amazon Rekognition-prosjekt.
- Parallelt lager vi opplæringen og valideringsdatasettene ved å bruke eksisterende datasett. Vi kan bruke følgende metoder:
- Importer en mappestruktur fra Amazon enkel lagringstjeneste (Amazon S3) med mappene som representerer etikettene.
- Bruk en lokal datamaskin.
- Bruk Ground Truth.
- Opprett et datasett ved å bruke et eksisterende datasett med AWS SDK.
- Opprett et datasett med en manifestfil med AWS SDK.
- Etter at datasettene er opprettet, trener vi en Custom Labels-modell ved å bruke CreateProjectVersion API. Dette kan ta fra minutter til timer å fullføre.
- Etter at modellen er trent, evaluerer vi modellen ved å bruke F1-poengsummen fra forrige trinn. Vi bruker F1-poengsummen som vår evalueringsberegning fordi den gir en balanse mellom presisjon og tilbakekalling. Du kan også bruke presisjon eller tilbakekalling som modellevalueringsberegninger. For mer informasjon om egendefinerte etikettevalueringsberegninger, se Beregninger for å evaluere modellen din.
- Vi begynner så å bruke modellen for spådommer hvis vi er fornøyd med F1-poengsummen.
Følgende diagram illustrerer arbeidsflyten for trinnfunksjoner.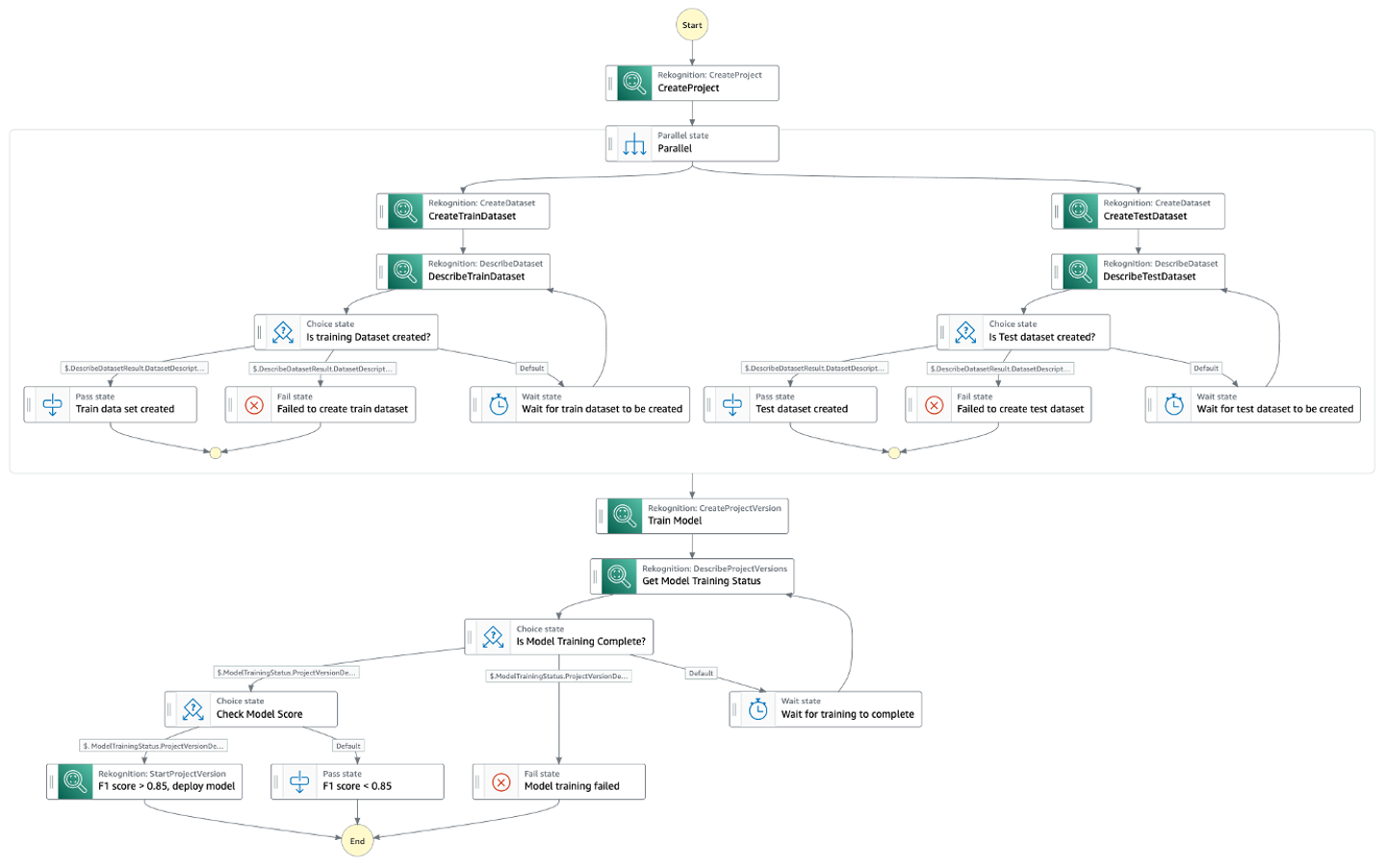
Forutsetninger
Før vi distribuerer arbeidsflyten, må vi opprette eksisterende opplærings- og valideringsdatasett. Fullfør følgende trinn:
- Først opprette et Amazon Rekognition-prosjekt.
- Deretter, lage opplærings- og valideringsdatasettene.
- Endelig, installer AWS SAM CLI.
Distribuer arbeidsflyten
For å distribuere arbeidsflyten, klone GitHub repository:
Disse kommandoene bygger, pakker og distribuerer applikasjonen din til AWS, med en rekke ledetekster som forklart i depotet.
Kjør arbeidsflyten
For å teste arbeidsflyten, naviger til den distribuerte arbeidsflyten på Step Functions-konsollen, og velg deretter Start utførelse.
Arbeidsflyten kan ta noen minutter til noen timer å fullføre. Hvis modellen består evalueringskriteriene, opprettes et endepunkt for modellen i Amazon Rekognition. Hvis modellen ikke består evalueringskriteriene eller opplæringen mislyktes, mislykkes arbeidsflyten. Du kan sjekke statusen til arbeidsflyten på Step Functions-konsollen. For mer informasjon, se Vise og feilsøke kjøringer på Step Functions-konsollen.
Utfør modellspådommer
For å utføre spådommer mot modellen, kan du ringe Amazon Rekognition DetectCustomLabels API. For å starte denne API-en, må den som ringer ha det nødvendige AWS identitets- og tilgangsadministrasjon (IAM) tillatelser. For mer informasjon om hvordan du utfører spådommer ved å bruke denne API-en, se Analysere et bilde med en trent modell.
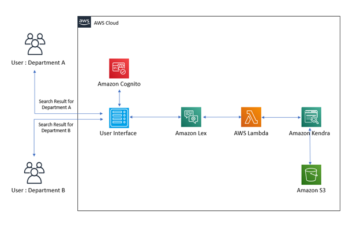
Men hvis du trenger å eksponere DetectCustomLabels API offentlig, kan du fronte DetectCustomLabels API med Amazon API-gateway. API Gateway er en fullstendig administrert tjeneste som gjør det enkelt for utviklere å opprette, publisere, vedlikeholde, overvåke og sikre APIer i alle skalaer. API-gateway fungerer som inngangsdør for DetectCustomLabels API, som vist i følgende arkitekturdiagram.
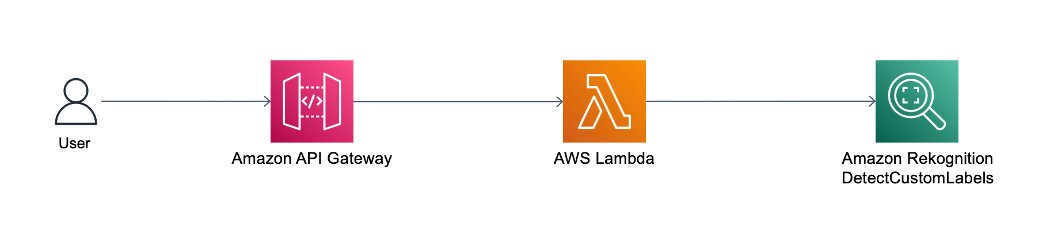
API Gateway videresender brukerens slutningsforespørsel til AWS Lambda. Lambda er en serverløs, hendelsesdrevet databehandlingstjeneste som lar deg kjøre kode for praktisk talt alle typer applikasjoner eller backend-tjenester uten å klargjøre eller administrere servere. Lambda mottar API-forespørselen og kaller Amazon Rekognition DetectCustomLabels API med de nødvendige IAM-tillatelsene. For mer informasjon om hvordan du setter opp API Gateway med Lambda-integrasjon, se Sett opp Lambda-proxy-integrasjoner i API Gateway.
Følgende er et eksempel på en Lambda-funksjonskode for å kalle DetectCustomLabels API:
Rydd opp
For å slette arbeidsflyten, bruk AWS SAM CLI:
For å slette Rekognition Custom Labels-modellen kan du enten bruke Amazon Rekognition-konsollen eller AWS SDK. For mer informasjon, se Sletter en Amazon Rekognition Custom Labels-modell.
konklusjonen
I dette innlegget gikk vi gjennom en Step Functions-arbeidsflyt for å lage et datasett og deretter trene, evaluere og bruke en Rekognition Custom Labels-modell. Arbeidsflyten lar applikasjonsutviklere og ML-ingeniører automatisere trinnene for tilpasset etikettklassifisering for enhver brukssituasjon for datasyn. Koden for arbeidsflyten er åpen kildekode.
For mer serverløse læringsressurser, besøk Serverløst land. For å finne ut mer om egendefinerte etiketter for Rekognition, besøk Amazon Rekognition Egendefinerte etiketter.
om forfatteren
 Veda Raman er en senior spesialistløsningsarkitekt for maskinlæring basert i Maryland. Veda samarbeider med kunder for å hjelpe dem med å bygge effektive, sikre og skalerbare maskinlæringsapplikasjoner. Veda er interessert i å hjelpe kunder med å utnytte serverløse teknologier for maskinlæring.
Veda Raman er en senior spesialistløsningsarkitekt for maskinlæring basert i Maryland. Veda samarbeider med kunder for å hjelpe dem med å bygge effektive, sikre og skalerbare maskinlæringsapplikasjoner. Veda er interessert i å hjelpe kunder med å utnytte serverløse teknologier for maskinlæring.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/automate-amazon-rekognition-custom-labels-model-training-and-deployment-using-aws-step-functions/
- :er
- $OPP
- 100
- 7
- 8
- a
- Om oss
- adgang
- nøyaktig
- tvers
- handlinger
- I tillegg
- Etter
- mot
- algoritmer
- tillater
- allerede
- Amazon
- Amazon-anerkjennelse
- analyse
- analysere
- og
- api
- APIer
- Søknad
- søknader
- arkitektur
- ER
- AS
- Montering
- At
- automatisere
- automatisk
- Automatisere
- tilgjengelig
- AWS
- AWS trinnfunksjoner
- Backend
- Balansere
- basert
- fordi
- blir
- begynne
- bak
- Bak scenen
- mellom
- kroppen
- bygge
- Bygning
- bygger
- virksomhet
- ring
- Caller
- Samtaler
- CAN
- evner
- hvilken
- saken
- kategorier
- CD
- tegn
- sjekk
- Velg
- klassifisering
- Klassifisere
- kunde
- kode
- fullføre
- Beregn
- datamaskin
- Datamaskin syn
- Konsoll
- kontekst
- kunne
- skape
- opprettet
- Opprette
- kriterier
- skikk
- Kunder
- dato
- datasett
- avgjørelser
- utplassere
- utplassert
- utplasserings
- distribusjon
- detaljer
- Gjenkjenning
- utviklere
- direkte
- skille
- distribueres
- ikke
- Av
- lett
- lett-å-bruke
- effektiv
- enten
- Endpoint
- Ingeniører
- nok
- Eter (ETH)
- evaluere
- evaluere
- evaluering
- Event
- eksempel
- eksisterende
- ekspertise
- forklarte
- f1
- Mislyktes
- mislykkes
- tilbakemelding
- Noen få
- filet
- Finn
- Først
- etter
- følger
- Til
- fra
- foran
- fullt
- funksjon
- funksjoner
- gateway
- genererer
- gå
- Ground
- Ha
- sunt
- tung
- tung løfting
- hjelpe
- hjelpe
- hjelper
- Hosting
- TIMER
- Hvordan
- Hvordan
- HTML
- HTTPS
- IAM
- identifisere
- Identitet
- bilde
- bildeanalyse
- Bildeklassifisering
- bilder
- in
- informasjon
- i stedet
- integrere
- integrering
- integrasjoner
- interessert
- Interface
- innebærer
- IT
- JSON
- Etiketten
- merking
- etiketter
- stor
- LÆRE
- læring
- Lar
- Leverage
- løfte
- linje
- laster
- lokal
- logo
- maskin
- maskinlæring
- vedlikeholde
- gjøre
- GJØR AT
- fikk til
- administrerende
- håndbok
- manuelt arbeid
- mange
- Maryland
- Media
- metoder
- metrisk
- Metrics
- microservices
- kunne
- millioner
- minutter
- ML
- ML-algoritmer
- modell
- Overvåke
- måneder
- mer
- Naviger
- nødvendig
- Trenger
- behov
- Ny
- objekt
- Objektdeteksjon
- of
- on
- OS
- produksjon
- pakke
- Parallel
- deler
- passerer
- utføre
- ytelse
- utfører
- tillatelser
- planter
- plato
- Platon Data Intelligence
- PlatonData
- Post
- innlegg
- Precision
- Spådommer
- Forbered
- forrige
- Prosesser
- Produkter
- prosjekt
- gi
- gir
- proxy
- offentlig
- publisere
- virkelige verden
- sanntids
- mottatt
- mottar
- redusere
- Repository
- representerer
- anmode
- krever
- Krever
- Ressurser
- svar
- retur
- Kjør
- s
- sagemaker
- Sam
- fornøyd
- fornøyd med
- skalerbar
- Skala
- Scener
- Resultat
- SDK
- sikre
- senior
- Serien
- server~~POS=TRUNC
- Servere
- tjeneste
- Tjenester
- sett
- flere
- hyller
- Vis
- vist
- signifikant
- Enkelt
- ganske enkelt
- siden
- liten
- selskap
- sosiale medier
- Sosiale medier innlegg
- Solutions
- spesialist
- spesifikk
- Begynn
- status
- Trinn
- Steps
- lagring
- oppbevare
- struktur
- Ta
- ta
- lag
- Technologies
- test
- Det
- De
- Dem
- tusener
- Gjennom
- tid
- til
- Tog
- trent
- Kurs
- Togene
- typisk
- bruke
- bruk sak
- validering
- av
- videoer
- nesten
- syn
- Besøk
- gikk
- hvilken
- med
- innenfor
- uten
- Arbeid
- arbeidsflyt
- virker
- Din
- zephyrnet