I dette innlegget presenterer vi en løsning for digitalisering av transaksjonsdokumenter ved hjelp av amazontekst og innlemme en menneskelig gjennomgang ved hjelp av Amazon Augmented AI (A2I). Du finner løsningskilden hos oss GitHub oppbevaringssted.
Organisasjoner må ofte behandle skannede transaksjonsdokumenter med strukturert tekst slik at de kan utføre operasjoner som svindeloppdagelse eller økonomiske godkjenninger. Noen vanlige eksempler på transaksjonsdokumenter som inneholder tabelldata inkluderer kontoutskrifter, fakturaer og styklister. Å trekke ut data manuelt fra slike dokumenter er dyrt, tidkrevende og krever ofte en betydelig investering i opplæring av spesialisert arbeidsstyrke. Med arkitekturen som er skissert i dette innlegget, kan du digitalisere tabelldata fra selv skannede dokumenter av lav kvalitet og oppnå en høy grad av nøyaktighet.
Det er gjort betydelige fremskritt med maskinlæring (ML)-baserte algoritmer for å øke nøyaktigheten og påliteligheten ved behandling av skannede tekstdokumenter. Disse algoritmene samsvarer ofte med ytelse på menneskelig nivå når det gjelder å gjenkjenne tekst og trekke ut innhold. Amazon Textract er en fullstendig administrert tjeneste som automatisk trekker ut trykt tekst, håndskrift og andre data fra skannede dokumenter. I tillegg kan Amazon Textract automatisk identifisere og trekke ut skjemaer og tabeller fra skannede dokumenter.
Selskaper som håndterer komplekse, varierende og sensitive dokumenter trenger ofte menneskelig tilsyn for å sikre nøyaktighet, konsistens og samsvar med de utpakkede dataene. Når menneskelige anmeldere gir innspill, kan du finjustere AI-modeller for å fange opp subtile nyanser av en bestemt forretningsprosess. Amazon A2I er en ML-tjeneste som gjør det enkelt å bygge arbeidsflytene som kreves for menneskelig vurdering. Amazon A2I fjerner de udifferensierte tunge løftene knyttet til å bygge menneskelige vurderingssystemer eller administrere et stort antall menneskelige anmeldere, og gir en enhetlig og sikker opplevelse til arbeidsstyrken din.
Å trekke ut transaksjonsdata fra skannede dokumenter, for eksempel en liste over debetkorttransaksjoner på en kontoutskrift, utgjør et unikt sett med utfordringer. Å kombinere kunstig intelligens med menneskelig vurdering gir en praktisk tilnærming for å overvinne disse hindringene. En integrert løsning som kombinerer Amazon Textract og Amazon A2I er et slikt overbevisende eksempel.
![]()
Forbrukere bruker rutinemessig smarttelefonene sine til å skanne og laste opp transaksjonsdokumenter. Avhengig av den generelle skannekvaliteten, inkludert lysforhold, skjevt perspektiv og mindre enn tilstrekkelig bildeoppløsning, er det ikke uvanlig å se suboptimal nøyaktighet når disse dokumentene behandles ved hjelp av datasynsteknikker (CV). Samtidig kan håndtering av skannede dokumenter ved hjelp av manuell arbeidskraft resultere i økte behandlingskostnader og behandlingstid, og kan begrense din evne til å skalere opp volumet av dokumenter en pipeline kan håndtere.
Løsningsoversikt
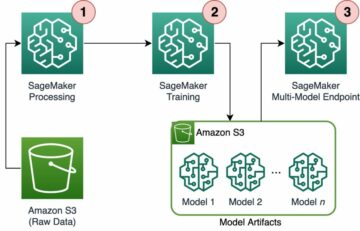
Følgende diagram illustrerer arbeidsflyten til løsningen vår:
![]()
Vår ende-til-ende arbeidsflyt utfører følgende trinn:
- Trekker ut tabeller fra skannede kildedokumenter.
- Bruker tilpassede forretningsregler når data trekkes ut fra tabellene.
- Eskalerer selektivt utfordrende dokumenter for menneskelig vurdering.
- Utfører etterbehandling av de utpakkede dataene.
- Lagrer resultatene.
Et tilpasset brukergrensesnitt bygget med ReactJS gis til menneskelige anmeldere for å intuitivt og effektivt gjennomgå og korrigere problemer i dokumentene når Amazon Textract gir en uttrekkspoeng med lav selvtillit, for eksempel når tekst er uklar, uklar eller på annen måte uklar.
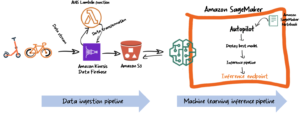
Vår referanseløsning bruker en svært spenstig rørledning, som beskrevet i følgende diagram, for å koordinere de ulike dokumentbehandlingsstadiene.
![]()
Løsningen inneholder flere arkitektoniske beste praksiser:
- Batchbehandling – Når det er mulig, bør løsningen samle flere dokumenter og utføre batchoperasjoner slik at vi kan optimere gjennomstrømmingen og bruke ressursene mer effektivt. For eksempel å kalle en tilpasset AI-modell for å kjøre inferens én gang for en gruppe dokumenter, i motsetning til å kalle modellen for hvert dokument individuelt. Utformingen av løsningen vår skal muliggjøre batching når det er hensiktsmessig.
- Prioritetsjustering – Når volumet av dokumenter i køen øker og løsningen ikke lenger er i stand til å behandle dem i tide, trenger vi en måte å indikere at enkelte dokumenter har høyere prioritet, og derfor må behandles foran andre dokumenter i køen .
- Automatisk skalering – Løsningen skal være i stand til å skalere opp og ned dynamisk. Mange arbeidsflyter for dokumentbehandling må støtte den sykliske naturen til etterspørselen. Vi bør utforme løsningen slik at den sømløst kan skaleres opp for å håndtere topper i belastningen og skalere ned igjen når belastningen avtar.
- Selvregulering – Løsningen bør være i stand til på en elegant måte å håndtere eksterne tjenesteavbrudd og takstbegrensninger.
Dokumentbehandlingsstadier
I denne delen leder vi deg gjennom detaljene for hvert trinn i arbeidsflyten for dokumentbehandling:
- Oppkjøp
- Konvertering
- Utvinning
- omforming
- Tilpasset forretningsdrift
- Forstørrelse
- Katalogise
Oppkjøp
Den første fasen av rørledningen henter inn innspillsdokumenter fra Amazon enkel lagringstjeneste (Amazon S3). På dette stadiet lagrer vi innledende dokumentinformasjon i en Amazon DynamoDB tabellen etter å ha mottatt et S3-hendelsesvarsel via Amazon enkel køtjeneste (Amazon SQS). Vi bruker denne tabellposten til å spore progresjonen til dette dokumentet over hele rørledningen.
Prioritetsrekkefølgen for hvert dokument bestemmes ved å sortere det alfanumeriske tasteprefikset i dokumentbanen. For eksempel et dokument lagret med nøkkel acquire/p0/doc.pdf resulterer i prioritet p0, og har forrang over et annet dokument lagret med nøkkel acquire/p1/doc.pdf (som resulterer i prioritet p1). Dokumenter uten prioritetsindikator i nøkkelen behandles på slutten.
Konvertering
Dokumenter hentet fra forrige trinn konverteres til PDF-format, slik at vi kan tilby et konsistent dataformat for resten av pipelinen. Dette lar oss gruppere flere sider av et relatert dokument.
Utvinning
PDF-dokumenter sendes til Amazon Textract for å utføre optisk tegngjenkjenning (OCR). Resultater fra Amazon Textract lagres som JSON i en mappe i Amazon S3.
omforming
Amazon Textract gir detaljert informasjon fra det behandlede dokumentet, inkludert råtekst, nøkkelverdi-par og tabeller. En betydelig mengde ekstra metadata identifiserer plasseringen og forholdet mellom de oppdagede enhetsblokkene. Transaksjonsdataene velges for videre behandling på dette stadiet.
Tilpasset forretningsdrift
Egendefinerte forretningsregler brukes på den omformede utgangen som inneholder informasjon om tabeller i dokumentet. Egendefinerte regler kan inkludere gjenkjenning av tabellformat (som å oppdage at en tabell inneholder sjekketransaksjoner) eller kolonnevalidering (som å bekrefte at en produktkodekolonne bare inneholder gyldige koder).
Forstørrelse
Menneskelige kommentatorer bruker Amazon A2I til å gjennomgå dokumentet og utvide det med all informasjon som ble savnet. Gjennomgangen inkluderer å analysere hver tabell i dokumentet for feil som feil tabelltyper, feltoverskrifter og individuell celletekst som ble feil forutsagt. Tillitspoeng fra utvinningsstadiet vises i brukergrensesnittet for å hjelpe menneskelige anmeldere med å finne mindre nøyaktige spådommer enkelt. Følgende skjermbilde viser det tilpassede brukergrensesnittet som brukes til dette formålet.
![]()
Løsningen vår bruker en privat arbeidsstyrke som består av interne annotatorer. Dette er et ideelt alternativ når du arbeider med sensitive dokumenter eller dokumenter som krever høyt spesialisert domenekunnskap. Amazon A2I støtter også menneskelige gjennomgangsarbeidere gjennom Amazon Mekanisk Turk og Amazons autoriserte partnere for datamerking.
Katalogise
Dokumenter som passerer menneskelig vurdering, katalogiseres i en Excel-arbeidsbok slik at bedriftsteamene dine enkelt kan konsumere dem. Arbeidsboken inneholder hver tabell som er oppdaget og behandlet i kildedokumentet i deres respektive ark, som er merket med tabelltype og sidenummer. Disse Excel-filene er lagret i en mappe i Amazon S3 for forbruk av forretningsapplikasjoner, for eksempel som utfører svindeloppdagelse ved hjelp av ML-teknikker.
Distribuere løsningen
Denne referanseløsningen er tilgjengelig på GitHub, og du kan distribuere den med AWS skyutviklingssett (AWS CDK). AWS CDK bruker kjennskapen og uttrykkskraften til programmeringsspråk for å modellere applikasjonene dine. Det gir komponenter på høyt nivå kalt konstruerer som forhåndskonfigurerer skyressurser med påviste standardinnstillinger, slik at du enkelt kan bygge skyapplikasjoner.
For instruksjoner om distribusjon av skyapplikasjonen, se README-filen i GitHub hvile.
Løsningsdemonstrasjon
Følgende video leder deg gjennom en demonstrasjon av løsningen.
konklusjonen
Dette innlegget viste hvordan du kan bygge en tilpasset digitaliseringsløsning for å behandle transaksjonsdokumenter med Amazon Textract og Amazon A2I. Vi automatiserte og utvidede inndatamanifester og håndhevet tilpassede forretningsregler. Vi ga også et intuitivt brukergrensesnitt for menneskelige arbeidsstyrker for å gjennomgå data med lav konfidenscore, foreta nødvendige justeringer og bruke tilbakemeldinger for å forbedre de underliggende ML-modellene. Muligheten til å bruke et tilpasset frontend-rammeverk som ReactJS lar oss lage moderne nettapplikasjoner som dekker våre presise behov, spesielt når vi bruker offentlige, private eller tredjeparts datamerkingsarbeidere.
For mer informasjon om Amazon Textract og Amazon A2I, se Bruker Amazon Augmented AI for å legge til Human Review til Amazon Textract-utdata. For videopresentasjoner, eksempler på Jupyter-notatbøker eller informasjon om brukstilfeller som dokumentbehandling, innholdsmoderering, sentimentanalyse, tekstoversettelse og mer, se Amazon utvidede AI-ressurser.
Om Teamet
Amazon ML Solutions Lab sammenkobler organisasjonen din med ML-eksperter for å hjelpe deg med å identifisere og bygge ML-løsninger for å møte organisasjonens høyeste avkastning på investering ML-muligheter. Gjennom oppdagelsesworkshops og idéøkter «arbeider ML Solutions Lab baklengs» fra forretningsproblemene dine for å levere et veikart over prioriterte ML-brukstilfeller med en implementeringsplan for å løse dem. Våre ML-forskere designer og utvikler avanserte ML-modeller innen områder som datasyn, talebehandling og naturlig språkbehandling for å løse kundenes problemer, inkludert løsninger som krever menneskelig vurdering.
Om forfatterne
![]() Pri Nonis er en Deep Learning Architect ved Amazon ML Solutions Lab, hvor han jobber med kunder på tvers av ulike vertikaler, og hjelper dem med å akselerere deres skymigrasjonsreise, og å løse ML-problemene deres ved hjelp av toppmoderne løsninger og teknologier.
Pri Nonis er en Deep Learning Architect ved Amazon ML Solutions Lab, hvor han jobber med kunder på tvers av ulike vertikaler, og hjelper dem med å akselerere deres skymigrasjonsreise, og å løse ML-problemene deres ved hjelp av toppmoderne løsninger og teknologier.
![]() Dan Noble er en programvareutviklingsingeniør hos Amazon hvor han hjelper til med å bygge herlige brukeropplevelser. På fritiden liker han å lese, trene og oppleve eventyr med familien.
Dan Noble er en programvareutviklingsingeniør hos Amazon hvor han hjelper til med å bygge herlige brukeropplevelser. På fritiden liker han å lese, trene og oppleve eventyr med familien.
![]() Jae Sung Jang er programvareutvikler. Hans lidenskap ligger i å automatisere manuell prosess ved hjelp av AI Solutions og Orchestration-teknologier for å sikre forretningsutførelse.
Jae Sung Jang er programvareutvikler. Hans lidenskap ligger i å automatisere manuell prosess ved hjelp av AI Solutions og Orchestration-teknologier for å sikre forretningsutførelse.
![]() Jeremy Feltracco er en programvareutviklingsingeniør med Amazon ML Solutions Lab hos Amazon Web Services. Han bruker sin bakgrunn innen datasyn, robotteknologi og maskinlæring for å hjelpe AWS-kunder med å få fart på AI-adopsjonen.
Jeremy Feltracco er en programvareutviklingsingeniør med Amazon ML Solutions Lab hos Amazon Web Services. Han bruker sin bakgrunn innen datasyn, robotteknologi og maskinlæring for å hjelpe AWS-kunder med å få fart på AI-adopsjonen.
![]() David Dasari er leder ved Amazon ML Solutions Lab, hvor han hjelper AWS-kunder med å akselerere sin AI og skyadopsjon i Human-In-The-Loop-løsningene på tvers av ulike industrivertikaler. Med ERP og betalingstjenester som bakgrunn, var han besatt av at ML/AI tok skritt for å glede kunder som drev ham til dette feltet.
David Dasari er leder ved Amazon ML Solutions Lab, hvor han hjelper AWS-kunder med å akselerere sin AI og skyadopsjon i Human-In-The-Loop-løsningene på tvers av ulike industrivertikaler. Med ERP og betalingstjenester som bakgrunn, var han besatt av at ML/AI tok skritt for å glede kunder som drev ham til dette feltet.
- Myntsmart. Europas beste Bitcoin og Crypto Exchange.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. FRI TILGANG.
- CryptoHawk. Altcoin Radar. Gratis prøveperiode.
- Kilde: https://aws.amazon.com/blogs/machine-learning/automate-digitization-of-transactional-documents-with-human-oversight-using-amazon-textract-and-amazon-a2i/
- "
- 100
- Om oss
- akselerere
- nøyaktig
- ervervet
- kjøper
- tvers
- Ytterligere
- adresse
- Adopsjon
- avansert
- AI
- algoritmer
- Amazon
- Amazon Web Services
- beløp
- analyse
- En annen
- Søknad
- søknader
- tilnærming
- arkitektonisk
- arkitektur
- kunstig
- kunstig intelligens
- augmented
- Automatisert
- tilgjengelig
- AWS
- bakgrunn
- Bank
- BEST
- beste praksis
- Sedler
- bygge
- Bygning
- virksomhet
- Business Applications
- saker
- utfordringer
- kontroll
- Cloud
- kode
- samle
- Kolonne
- Felles
- overbevisende
- komplekse
- samsvar
- selvtillit
- forbruke
- forbruk
- inneholder
- innhold
- koordinere
- Kostnader
- Kunder
- dato
- håndtering
- Bankkort
- Etterspørsel
- utplassere
- utplasserings
- utforming
- oppdaget
- Gjenkjenning
- utvikle
- Utvikling
- digitalisering
- Digitize
- Funnet
- dokumenter
- domene
- ned
- lett
- ingeniør
- spesielt
- Event
- eksempel
- Excel
- gjennomføring
- erfaring
- Erfaringer
- eksperter
- uttrykks
- ekstrakter
- familie
- tilbakemelding
- finansiell
- Først
- etter
- format
- skjemaer
- Rammeverk
- svindel
- GitHub
- Gruppe
- Håndtering
- å ha
- hjelpe
- hjelper
- Høy
- svært
- Hvordan
- HTTPS
- hekk
- identifisere
- bilde
- forbedre
- inkludere
- Inkludert
- Øke
- økt
- individuelt
- industri
- informasjon
- integrert
- Intelligens
- Interface
- intuitiv
- investering
- saker
- IT
- nøkkel
- kunnskap
- lab
- merking
- arbeidskraft
- Språk
- språk
- stor
- læring
- Liste
- laste
- plassering
- maskin
- maskinlæring
- fikk til
- leder
- administrerende
- håndbok
- manuelt
- Match
- materialer
- ML
- modell
- modeller
- Naturlig
- Natur
- varsling
- Antall
- Drift
- Muligheter
- Alternativ
- orkestre
- rekkefølge
- organisasjon
- Annen
- ellers
- partnere
- betaling
- Betalingstjenester
- ytelse
- perspektiv
- mulig
- makt
- Spådommer
- presentere
- Presentasjoner
- prioritet
- privat
- problemer
- prosess
- Produkt
- Programmering
- programmerings språk
- gi
- gir
- offentlig
- formål
- kvalitet
- Raw
- Lesning
- rekord
- forholdet
- Repository
- krever
- påkrevd
- Ressurser
- REST
- Resultater
- anmeldelse
- veikart
- robotikk
- regler
- Kjør
- Skala
- skalering
- skanne
- forskere
- sikre
- valgt
- sentiment
- tjeneste
- Tjenester
- sett
- signifikant
- Enkelt
- smartphones
- So
- Software
- programvareutvikling
- Solutions
- LØSE
- spesialisert
- Scene
- state-of-the-art
- Uttalelse
- uttalelser
- lagring
- oppbevare
- støtte
- Støtter
- Systemer
- teknikker
- Technologies
- Kilden
- tredjeparts
- Gjennom
- tid
- tidkrevende
- spor
- Kurs
- Transaksjoner
- Oversettelse
- ui
- unik
- us
- bruke
- video
- syn
- volum
- web
- nettapplikasjoner
- webtjenester
- arbeidsstyrke
- virker