Organisasjoner har valgt å bygge datainnsjøer på toppen av Amazon enkel lagringstjeneste (Amazon S3) i mange år. En datainnsjø er det mest populære valget for organisasjoner for å lagre alle organisasjonsdata generert av forskjellige team, på tvers av forretningsdomener, fra alle forskjellige formater, og til og med gjennom historien. I følge en studie, ser gjennomsnittsbedriften volumet av dataene deres vokse med en hastighet som overstiger 50 % per år, og administrerer vanligvis et gjennomsnitt på 33 unike datakilder for analyse.
Team prøver ofte å replikere tusenvis av jobber fra relasjonsdatabaser med samme uttrekk, transformasjon og belastning (ETL) mønster. Det er mye innsats i å opprettholde jobbstatusene og planlegge disse individuelle jobbene. Denne tilnærmingen hjelper teamene med å legge til tabeller med få endringer og opprettholder også jobbstatusen med minimal innsats. Dette kan føre til en enorm forbedring i utviklingstidslinjen og sporing av jobbene med letthet.
I dette innlegget viser vi deg hvordan du enkelt kan replikere alle relasjonsdatalagrene dine til en transaksjonsdatainnsjø på en automatisert måte med en enkelt ETL-jobb ved å bruke Apache Iceberg og AWS Lim.
Løsningsarkitektur
Datainnsjøer er vanligvis organisert ved å bruke separate S3-bøtter for tre lag med data: rålaget som inneholder data i sin opprinnelige form, trinnlaget som inneholder mellomliggende behandlede data optimalisert for forbruk, og analyselaget som inneholder aggregerte data for spesifikke brukstilfeller. I rålaget er tabeller vanligvis organisert basert på datakildene, mens tabeller i trinnlaget er organisert basert på forretningsdomenene de tilhører.
Dette innlegget gir en AWS skyformasjon mal som distribuerer en AWS Glue-jobb som leser en Amazon S3-bane for én datakilde for datainnsjøens rålag, og inntar dataene i Apache Iceberg-tabeller på scenelaget ved å bruke AWS Glue-støtte for datainnsjø-rammeverk. Jobben forventer at tabeller i rålaget er strukturert på måten AWS Database Migration Service (AWS DMS) inntar dem: skjema, deretter tabell, deretter datafiler.
Denne løsningen bruker AWS Systems Manager Parameter Store for tabellkonfigurasjon. Du bør endre denne parameteren og spesifisere tabellene du vil behandle og hvordan, inkludert informasjon som primærnøkkel, partisjoner og forretningsdomenet som er tilknyttet. Jobben bruker denne informasjonen til automatisk å opprette en database (hvis den ikke allerede eksisterer) for hvert forretningsdomene, lage Iceberg-tabellene og utføre datainnlastingen.
Endelig kan vi bruke Amazonas Athena for å spørre etter dataene i Iceberg-tabellene.
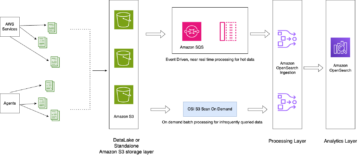
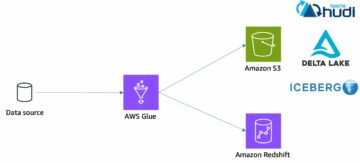
Følgende diagram illustrerer denne arkitekturen.

Denne implementeringen har følgende hensyn:
- Alle tabeller fra datakilden må ha en primærnøkkel for å kunne replikeres med denne løsningen. Primærnøkkelen kan være en enkelt kolonne eller en sammensatt nøkkel med mer enn én kolonne.
- Hvis datainnsjøen inneholder tabeller som ikke trenger upserts eller ikke har en primærnøkkel, kan du ekskludere dem fra parameterkonfigurasjonen og implementere tradisjonelle ETL-prosesser for å ta dem inn i datasjøen. Det er utenfor rammen av dette innlegget.
- Hvis det er flere datakilder som må inntas, kan du distribuere flere CloudFormation-stabler, en for å håndtere hver datakilde.
- AWS Glue-jobben er utformet for å behandle data i to faser: den første belastningen som kjører etter at AWS DMS fullfører full belastningsoppgaven, og den inkrementelle belastningen som kjører på en tidsplan som bruker endringsdatafangst-filer (CDC) som er fanget opp av AWS DMS. Inkrementell prosessering utføres ved hjelp av en AWS Lim jobb bokmerke.
Det er ni trinn for å fullføre denne opplæringen:
- Sett opp et kildeendepunkt for AWS DMS.
- Distribuer løsningen ved å bruke AWS CloudFormation.
- Se gjennom AWS DMS-replikeringsoppgaven.
- Du kan eventuelt legge til tillatelser for kryptering og dekryptering eller AWS Lake formasjon.
- Se gjennom tabellkonfigurasjonen på Parameter Store.
- Utfør innledende datainnlasting.
- Utfør inkrementell datalasting.
- Overvåk inntak av bord.
- Planlegg inkrementell batchdatalasting.
Forutsetninger
Før du starter denne opplæringen, bør du allerede være kjent med Iceberg. Hvis du ikke er det, kan du komme i gang ved å replikere en enkelt tabell ved å følge instruksjonene i Implementer en CDC-basert UPSERT i en datainnsjø ved hjelp av Apache Iceberg og AWS Glue. Sett i tillegg opp følgende:
Sett opp et kildeendepunkt for AWS DMS
Før vi oppretter AWS DMS-oppgaven vår, må vi sette opp et kildeendepunkt for å koble til kildedatabasen:
- På AWS DMS-konsollen velger du endepunkter i navigasjonsruten.
- Velg Lag endepunkt.
- Hvis databasen din kjører på Amazon RDS, velg Velg RDS DB-forekomst, og velg deretter forekomsten fra listen. Ellers velger du kildemotoren og oppgir tilkoblingsinformasjonen enten gjennom AWS Secrets Manager eller manuelt.
- Til Endepunktidentifikator, skriv inn et navn for endepunktet; for eksempel source-postgresql.
- Velg Lag endepunkt.
Distribuere løsningen ved hjelp av AWS CloudFormation
Lag en CloudFormation-stabel ved å bruke den medfølgende malen. Fullfør følgende trinn:
- Velg Lanseringsstabel:

- Velg neste.
- Oppgi et stabelnavn, for eksempel
transactionaldl-postgresql. - Skriv inn de nødvendige parameterne:
- DMSS3EndpointIAMRoleARN – IAM-rollen ARN for AWS DMS for å skrive data inn i Amazon S3.
- ReplicationInstanceArn – AWS DMS-replikeringsinstansen ARN.
- S3BucketStage – Navnet på den eksisterende bøtten som brukes for scenelaget til datasjøen.
- S3BucketLim – Navnet på den eksisterende S3-bøtten for lagring av AWS Glue-skript.
- S3BucketRaw – Navnet på den eksisterende bøtten som brukes for rålaget til datasjøen.
- SourceEndpointArn – AWS DMS-endepunktet ARN som du opprettet tidligere.
- Kildenavn – Den vilkårlige identifikatoren til datakilden som skal replikeres (f.eks.
postgres). Dette brukes til å definere S3-banen til datasjøen (rålaget) der data skal lagres.
- Ikke modifiser følgende parametere:
- SourceS3BucketBlog – Bøttenavnet der det medfølgende AWS Glue-skriptet er lagret.
- SourceS3BucketPrefix – Navnet på bøtteprefikset der det medfølgende AWS Glue-skriptet er lagret.
- Velg neste to ganger.
- Plukke ut Jeg erkjenner at AWS CloudFormation kan lage IAM-ressurser med tilpassede navn.
- Velg Lag stabel.
Etter omtrent 5 minutter er CloudFormation-stakken distribuert.
Se gjennom AWS DMS-replikeringsoppgaven
AWS CloudFormation-distribusjonen opprettet et AWS DMS-målendepunkt for deg. På grunn av to spesifikke endepunktinnstillinger vil dataene bli inntatt etter hvert som vi trenger dem på Amazon S3.
- På AWS DMS-konsollen velger du endepunkter i navigasjonsruten.
- Søk etter og velg endepunktet som begynner med
dmsIcebergs3endpoint. - Se gjennom endepunktinnstillingene:
DataFormater spesifisert somparquet.TimestampColumnNamevil legge til kolonnenlast_update_timemed datoen for opprettelsen av postene på Amazon S3.

Utrullingen oppretter også en AWS DMS-replikeringsoppgave som begynner med dmsicebergtask.
- Velg Replikeringsoppgaver i navigasjonsruten og søk etter oppgaven.
Du vil se at Oppgavetype er merket som Full belastning, pågående replikering. AWS DMS vil utføre en innledende full belastning av eksisterende data, og deretter opprette inkrementelle filer med endringer utført i kildedatabasen.
På Kartleggingsregler kategorien, er det to typer regler:
- En utvalgsregel med navnet på kildeskjemaet og tabeller som skal lagres fra kildedatabasen. Som standard bruker den prøvedatabasen som er gitt i forutsetningene,
dms_sample, og alle tabeller med søkeordet %. - To transformasjonsregler som inkluderer i målfilene på Amazon S3 skjemanavnet og tabellnavnet som kolonner. Dette brukes av vår AWS Glue-jobb for å vite hvilke tabeller filene i datasjøen tilsvarer.
For å lære mer om hvordan du tilpasser dette for dine egne datakilder, se Utvelgelsesregler og handlinger.

La oss endre noen konfigurasjoner for å fullføre oppgaveforberedelsen.
- På handlinger meny, velg endre.
- på Oppgaveinnstillinger delen, under Stopp oppgaven etter full lasting, velg Stopp etter å ha brukt bufrede endringer.
På denne måten kan vi kontrollere den første belastningen og inkrementell filgenerering som to forskjellige trinn. Vi bruker denne to-trinns tilnærmingen til å kjøre AWS Glue-jobben én gang for hvert trinn.
- Under Oppgavelogger, velg Slå på CloudWatch-logger.
- Velg Spar.
- Vent ca. 1 minutt til statusen for databasemigreringsoppgaven vises som Klar.
Legg til tillatelser for kryptering og dekryptering eller Lake Formation
Eventuelt kan du legge til tillatelser for kryptering og dekryptering eller Lake Formation.
Legg til kryptering og dekrypteringsrettigheter
Hvis S3-bøttene dine som brukes til rå- og scenelagene er kryptert med AWS nøkkelstyringstjeneste (AWS KMS) kundeadministrerte nøkler, må du legge til tillatelser for å gi AWS Glue-jobben tilgang til dataene:
Legg til Lake Formation-tillatelser
Hvis du administrerer tillatelser ved hjelp av Lake Formation, må du tillate at AWS Glue-jobben oppretter domenets databaser og tabeller gjennom IAM-rollen GlueJobRole.
- Gi tillatelser til å opprette databaser (for instruksjoner, se Opprette en database).
- Gi SUPER-tillatelser til
defaultdatabase. - Gi tillatelser for dataplassering.
- Hvis du oppretter databaser manuelt, gi alle databaser tillatelse til å lage tabeller. Referere til Gi tabelltillatelser ved å bruke Lake Formation-konsollen og den navngitte ressursmetoden or Tildeling av datakatalogtillatelser ved hjelp av LF-TBAC-metoden i henhold til din brukssituasjon.
Etter at du har fullført det senere trinnet med å utføre den første datainnlastingen, må du også legge til tillatelser for forbrukere til å spørre tabellene. Jobbrollen vil bli eier av alle tabellene som er opprettet, og datainnsjø-administratoren kan deretter utføre bevilgninger til flere brukere.
Gå gjennom tabellkonfigurasjonen i Parameter Store
AWS Glue-jobben som utfører datainntaket i Iceberg-tabeller, bruker tabellspesifikasjonen som er gitt i Parameter Store. Fullfør følgende trinn for å se parameterlageret som ble konfigurert automatisk for deg. Om nødvendig, modifiser etter dine egne behov.
- På Parameter Store-konsollen velger du Mine parametere i navigasjonsruten.
CloudFormation-stakken opprettet to parametere:
iceberg-configfor jobbkonfigurasjonericeberg-tablesfor tabellkonfigurasjon
- Velg parameteren isfjell-bord.
JSON-strukturen inneholder informasjon som AWS Glue bruker til å lese data og skrive Iceberg-tabellene på måldomenet:
- Ett objekt per bord – Navnet på objektet opprettes ved å bruke skjemanavnet, et punktum og tabellnavnet; for eksempel,
schema.table. - primærnøkkel – Dette bør spesifiseres for hver kildetabell. Du kan gi en enkelt kolonne eller en kommadelt liste over kolonner (uten mellomrom).
- partisjonCols – Dette partisjonerer eventuelt kolonner for måltabeller. Hvis du ikke vil lage partisjonerte tabeller, oppgi en tom streng. Ellers oppgi en enkelt kolonne eller en kommadelt liste over kolonner som skal brukes (uten mellomrom).
- Hvis du vil bruke din egen datakilde, bruk følgende JSON-kode og bytt ut teksten i CAPS fra malen som følger med. Hvis du bruker eksempeldatakilden som følger med, beholder du standardinnstillingene:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Velg lagre endringer.
Utfør innledende datainnlasting
Nå som den nødvendige konfigurasjonen er fullført, inntar vi de første dataene. Dette trinnet inkluderer tre deler: inntak av data fra kilderelasjonsdatabasen inn i rålaget til datainnsjøen, opprettelse av Iceberg-tabellene på scenelaget til datasjøen, og verifisering av resultater ved hjelp av Athena.
Ta inn data i rålaget til datainnsjøen
For å innta data fra den relasjonsdatakilden (PostgreSQL hvis du bruker prøven som følger med) til vår transaksjonsdatainnsjø ved hjelp av Iceberg, fullfør følgende trinn:
- På AWS DMS-konsollen velger du Database migreringsoppgaver i navigasjonsruten.
- Velg replikeringsoppgaven du opprettet og på handlinger meny, velg Start på nytt/gjenoppta.
- Vent ca. 5 minutter til replikeringsoppgaven er fullført. Du kan overvåke tabellene inntatt på Statistikk kategorien i replikeringsoppgaven.

Etter noen minutter avsluttes oppgaven med meldingen Full belastning fullført.
- På Amazon S3-konsollen velger du bøtten du definerte som rålaget.
Under S3-prefikset definert på AWS DMS (f.eks. postgres), bør du se et hierarki av mapper med følgende struktur:
- Skjema
- Tabellnavn
LOAD00000001.parquetLOAD0000000N.parquet
- Tabellnavn

Hvis S3-bøtten din er tom, se gjennom Feilsøking av migreringsoppgaver i AWS Database Migration Service før du kjører AWS Lim-jobben.
Opprett og innfør data i Iceberg-tabeller
Før du kjører jobben, la oss navigere i skriptet til AWS Glue-jobben som ble levert som en del av CloudFormation-stakken for å forstå dens oppførsel.
- På AWS Glue Studio-konsollen velger du Jobb i navigasjonsruten.
- Søk etter jobben som starter med
IcebergJob-og et suffiks av CloudFormation-stabelnavnet (f.eks.IcebergJob-transactionaldl-postgresql). - Velg jobben.

Jobbskriptet får konfigurasjonen det trenger fra Parameter Store. Funksjonen getConfigFromSSM() returnerer jobbrelaterte konfigurasjoner som kilde- og målblokker hvorfra dataene må leses og skrives. Variabelen ssmparam_table_values inneholder tabellrelatert informasjon som datadomenet, tabellnavnet, partisjonskolonner og primærnøkkelen til tabellene som må tas inn. Se følgende Python-kode:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']Skriptet bruker et vilkårlig katalognavn for Iceberg som er definert som min_katalog. Dette er implementert på AWS Glue Data Catalog ved hjelp av Spark-konfigurasjoner, så en SQL-operasjon som peker til my_catalog vil bli brukt på Data Catalog. Se følgende kode:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
Skriptet itererer over tabellene som er definert i Parameter Store og utfører logikken for å oppdage om tabellen eksisterer og om de innkommende dataene er en innledende belastning eller en upsert:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')De initialLoadRecordsSparkSQL() funksjon laster inn innledende data når ingen operasjonskolonne er til stede i S3-filene. AWS DMS legger kun denne kolonnen til Parkett-datafiler produsert av kontinuerlig replikering (CDC). Datainnlastingen utføres ved å bruke INSERT INTO-kommandoen med SparkSQL. Se følgende kode:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Nå kjører vi AWS Glue-jobben for å innta de første dataene i Iceberg-tabellene. CloudFormation-stakken legger til --datalake-formats parameter, legger de nødvendige Iceberg-bibliotekene til jobben.
- Velg Kjør jobb.
- Velg Jobben løper for å overvåke status. Vent til status er Kjør vellykket.
Bekreft dataene som er lastet inn
For å bekrefte at jobben behandlet dataene som forventet, fullfør følgende trinn:
- Velg på Athena-konsollen Query Editor i navigasjonsruten.
- Bekreft
AwsDataCataloger valgt som datakilde. - Under Database, velg datadomenet du vil utforske, basert på konfigurasjonen du definerte i parameterlageret. Hvis du bruker prøvedatabasen som følger med, bruk
sports.
Under Tabeller og utsikt, kan vi se listen over tabeller som ble opprettet av AWS Glue-jobben.
- Velg alternativmenyen (tre prikker) ved siden av det første tabellnavnet, og velg deretter Forhåndsvisning av data.
Du kan se dataene lastet inn i Iceberg-tabeller. 
Utfør inkrementell datalasting
Nå begynner vi å fange opp endringer fra vår relasjonsdatabase og bruke dem på transaksjonsdatasjøen. Dette trinnet er også delt inn i tre deler: fange opp endringene, bruke dem på Iceberg-tabellene og verifisere resultatene.
Ta opp endringer fra relasjonsdatabasen
På grunn av konfigurasjonen vi spesifiserte, stoppet replikeringsoppgaven etter å ha kjørt hele innlastingsfasen. Nå starter vi oppgaven på nytt for å legge til inkrementelle filer med endringer i rålaget til datasjøen.
- På AWS DMS-konsollen velger du oppgaven vi opprettet og kjørte før.
- På handlinger meny, velg Fortsett.
- Velg Start oppgaven for å begynne å fange opp endringer.
- For å utløse ny filoppretting på datasjøen, utfør innsettinger, oppdateringer eller slettinger i tabellene i kildedatabasen ved å bruke det foretrukne databaseadministrasjonsverktøyet. Hvis du bruker eksempeldatabasen som følger med, kan du kjøre følgende SQL-kommandoer:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- På AWS DMS-oppgavedetaljer-siden velger du Tabellstatistikk fanen for å se endringene som er registrert.

- Åpne rålaget til datainnsjøen for å finne en ny fil som inneholder de inkrementelle endringene i hver tabells prefiks, for eksempel under
sporting_eventprefiks.
Posten med endringer for sporting_event tabellen ser ut som følgende skjermbilde.

Legg merke til Op kolonne i begynnelsen identifisert med en oppdatering (U). Den andre dato-/tidsverdien er også kontrollkolonnen lagt til av AWS DMS med tidspunktet endringen ble registrert.

Påfør endringer på Iceberg-bordene med AWS-lim
Nå kjører vi AWS Glue-jobben igjen, og den vil automatisk behandle bare de nye inkrementelle filene siden jobbbokmerket er aktivert. La oss se gjennom hvordan det fungerer.
De dedupCDCRecords() funksjonen utfører deduplisering av data fordi flere endringer i en enkelt post-ID kan fanges opp i samme datafil på Amazon S3. Deduplisering utføres basert på last_update_time kolonne lagt til av AWS DMS som indikerer tidsstemplet for når endringen ble fanget. Se følgende Python-kode:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFPå linje 99 er upsertRecordsSparkSQL() funksjonen utfører upsert på en lignende måte som den første belastningen, men denne gangen med en SQL MERGE-kommando.
Gjennomgå de anvendte endringene
Åpne Athena-konsollen og kjør en spørring som velger de endrede postene i kildedatabasen. Hvis du bruker den medfølgende eksempeldatabasen, bruk ett av følgende SQL-spørringer:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Overvåk inntak av bord
AWS Glue jobbskriptet er kodet med enkel Python unntakshåndtering for å fange opp feil under behandling av en bestemt tabell. Jobbbokmerket lagres etter at hver tabell er ferdig behandlet, for å unngå å behandle tabeller på nytt hvis jobbkjøringen prøves på nytt for tabellene med feil.
De AWS kommandolinjegrensesnitt (AWS CLI) gir en get-job-bookmark kommando for AWS Glue som gir innsikt i statusen til bokmerket for hver tabell som behandles.
- På AWS Glue Studio-konsollen velger du ETL-jobben.
- Velg Jobben løper fanen og kopier jobbkjørings-IDen.
- Kjør følgende kommando på en terminal som er autentisert for AWS CLI, og erstatt
<GLUE_JOB_RUN_ID>på linje 1 med verdien du kopierte. Hvis CloudFormation-stakken din ikke er navngitttransactionaldl-postgresql, oppgi navnet på jobben din på linje 2 i skriptet:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunI denne løsningen, når en tabellbehandling forårsaker et unntak, vil ikke AWS Glue-jobben mislykkes i henhold til denne logikken. I stedet legges tabellen til i en matrise som skrives ut etter at jobben er fullført. I et slikt scenario vil jobben bli merket som mislykket etter at den prøver å behandle resten av tabellene som er oppdaget på rådatakilden. På denne måten trenger ikke tabeller uten feil å vente til brukeren identifiserer og løser problemet på de motstridende tabellene. Brukeren kan raskt oppdage jobbkjøringer som hadde problemer ved å bruke AWS Glue-jobbkjøringsstatusen, og identifisere hvilke spesifikke tabeller som forårsaker problemet ved å bruke CloudWatch-loggene for jobbkjøringen.
- Jobbskriptet implementerer denne funksjonen med følgende Python-kode:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')Følgende skjermbilde viser hvordan CloudWatch-loggene ser ut for tabeller som forårsaker feil ved behandling.

På linje med AWS velarkitektert rammeverksdataanalyseobjektiv praksis, kan du tilpasse mer sofistikerte kontrollmekanismer for å identifisere og varsle interessenter når det oppstår feil på datarørledningene. For eksempel kan du bruke en Amazon DynamoDB kontrolltabell for å lagre alle tabeller og jobbkjøringer med feil, eller bruk Amazon enkel varslingstjeneste (Amazon SNS) til sende varsler til operatører når visse kriterier er oppfylt.
Planlegg inkrementell batchdatalasting
CloudFormation-stakken distribuerer en Amazon EventBridge regel (deaktivert som standard) som kan utløse AWS Glue-jobben til å kjøre på en tidsplan. For å oppgi din egen tidsplan og aktivere regelen, fullfør følgende trinn:
- På EventBridge-konsollen velger du Regler i navigasjonsruten.
- Søk etter regelen prefikset med navnet på CloudFormation-stabelen din etterfulgt av
JobTrigger(for eksempel,transactionaldl-postgresql-JobTrigger-randomvalue). - Velg regelen.
- Under Arrangementsplan, velg Rediger.
Standardplanen er konfigurert til å utløses hver time.
- Oppgi tidsplanen du ønsker for å kjøre jobben.
- I tillegg kan du bruke en EventBridge cron uttrykk ved å velge En finmasket timeplan.

- Når du er ferdig med å sette opp cron-uttrykket, velg neste tre ganger, og til slutt velge Oppdater regel for å lagre endringer.
Regelen er opprettet deaktivert som standard for å tillate deg å kjøre den første datainnlastingen først.
- Aktiver regelen ved å velge aktiver.
Du kan også bruke det Overvåking fanen for å se regelpåkallelser, eller direkte på AWS-limet Job Run detaljer.
konklusjonen
Etter å ha implementert denne løsningen, har du automatisert innføringen av tabellene dine på én enkelt relasjonsdatakilde. Organisasjoner som bruker en datainnsjø som sin sentrale dataplattform, trenger vanligvis å håndtere flere, noen ganger til og med titalls datakilder. Flere og flere brukstilfeller krever også at organisasjoner implementerer transaksjonsmuligheter til datasjøen. Du kan bruke denne løsningen til å akselerere bruken av slike evner på tvers av alle relasjonsdatakildene dine for å muliggjøre nye forretningsbruk, automatisere implementeringsprosessen for å få mer verdi fra dataene dine.
Om forfatterne
 Luis Gerardo Baeza er en Big Data Architect i Amazon Web Services (AWS) Data Lab. Han har 12 års erfaring med å hjelpe organisasjoner innen helse-, finans- og utdanningssektorene med å ta i bruk bedriftsarkitekturprogrammer, cloud computing og dataanalysefunksjoner. Luis hjelper for tiden organisasjoner over hele Latin-Amerika med å akselerere strategiske datainitiativer.
Luis Gerardo Baeza er en Big Data Architect i Amazon Web Services (AWS) Data Lab. Han har 12 års erfaring med å hjelpe organisasjoner innen helse-, finans- og utdanningssektorene med å ta i bruk bedriftsarkitekturprogrammer, cloud computing og dataanalysefunksjoner. Luis hjelper for tiden organisasjoner over hele Latin-Amerika med å akselerere strategiske datainitiativer.
 SaiKiran Reddy Aenugu er en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 10 års erfaring med implementering av datainnlasting, transformasjon og visualiseringsprosesser. SaiKiran hjelper for tiden organisasjoner i Nord-Amerika med å ta i bruk moderne dataarkitekturer som datainnsjøer og datanettverk. Han har erfaring fra detaljhandel, flyselskap og finans.
SaiKiran Reddy Aenugu er en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 10 års erfaring med implementering av datainnlasting, transformasjon og visualiseringsprosesser. SaiKiran hjelper for tiden organisasjoner i Nord-Amerika med å ta i bruk moderne dataarkitekturer som datainnsjøer og datanettverk. Han har erfaring fra detaljhandel, flyselskap og finans.
 Narendra Merla er en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 12 års erfaring med å designe og produksjonalisere både sanntids- og batch-orienterte datapipelines og bygge datainnsjøer i både sky- og lokale miljøer. Narendra hjelper for tiden organisasjoner i Nord-Amerika med å bygge og designe robuste dataarkitekturer, og har erfaring fra telekom- og finanssektorene.
Narendra Merla er en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 12 års erfaring med å designe og produksjonalisere både sanntids- og batch-orienterte datapipelines og bygge datainnsjøer i både sky- og lokale miljøer. Narendra hjelper for tiden organisasjoner i Nord-Amerika med å bygge og designe robuste dataarkitekturer, og har erfaring fra telekom- og finanssektorene.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Om oss
- akselerere
- adgang
- Ifølge
- anerkjenne
- tvers
- tilpasse
- la til
- Ytterligere
- I tillegg
- Legger
- admin
- administrasjon
- adoptere
- Adopsjon
- Etter
- Flyselskapet
- Alle
- allerede
- Amazon
- Amazonas Athena
- Amazon RDS
- Amazon Web Services
- Amazon Web Services (AWS)
- america
- analyse
- analytics
- og
- Angeles
- Apache
- vises
- Søknad
- anvendt
- påføring
- tilnærming
- ca
- arkitektur
- Array
- assosiert
- autentisert
- automatisere
- Automatisert
- automatisk
- Automatisere
- gjennomsnittlig
- unngå
- AWS
- AWS skyformasjon
- AWS Lim
- basert
- flaggermus
- fordi
- bli
- før du
- Begynnelsen
- Stor
- Store data
- bygge
- bygger
- Bygning
- virksomhet
- Kan få
- evner
- caps
- fangst
- fange
- saken
- saker
- katalog
- Catch
- Årsak
- årsaker
- forårsaker
- CDC
- sentral
- viss
- endring
- Endringer
- valg
- Velg
- velge
- valgt ut
- Cloud
- cloud computing
- kode
- Kolonne
- kolonner
- Selskapet
- fullføre
- databehandling
- Konfigurasjon
- konfigurasjoner
- Bekrefte
- Motstrid
- Koble
- tilkobling
- betraktninger
- Konsoll
- Forbrukere
- forbruk
- inneholder
- fortsette
- kontinuerlig
- kontroll
- kunne
- skape
- opprettet
- skaper
- Opprette
- skaperverket
- kriterier
- I dag
- skikk
- kunde
- tilpasse
- dato
- Data Analytics
- Data Lake
- Dataplattform
- Database
- databaser
- Dato
- Misligholde
- definert
- utplassere
- utplassert
- utplasserings
- distribusjon
- Distribueres
- utforming
- designet
- utforme
- detaljer
- oppdaget
- Utvikling
- forskjellig
- direkte
- deaktivert
- Divided
- ikke
- domene
- domener
- ikke
- under
- hver enkelt
- Tidligere
- lett
- Kunnskap
- innsats
- enten
- muliggjøre
- aktivert
- kryptert
- kryptering
- Endpoint
- Motor
- Enter
- Enterprise
- miljøer
- feil
- Eter (ETH)
- Selv
- Hver
- eksempel
- stiger
- Unntatt
- unntak
- eksisterende
- finnes
- forventet
- forventer
- erfaring
- utforske
- utvidelser
- trekke ut
- Mislyktes
- kjent
- Mote
- Trekk
- Noen få
- filet
- Filer
- Endelig
- finansiere
- finansiell
- Finn
- ferdig
- Først
- fulgt
- etter
- For forbrukere
- skjema
- formasjon
- Rammeverk
- fra
- fullt
- funksjon
- generert
- generasjonen
- få
- innvilge
- tilskudd
- Økende
- håndtere
- helsetjenester
- hjelpe
- hjelper
- hierarki
- historie
- holder
- Hvordan
- Hvordan
- HTML
- HTTPS
- stort
- IAM
- identifisert
- identifikator
- identifiserer
- identifisere
- iverksette
- gjennomføring
- implementert
- implementere
- redskaper
- forbedring
- in
- inkludere
- inkluderer
- Inkludert
- Innkommende
- indikerer
- individuelt
- informasjon
- innledende
- initiativer
- Setter inn
- innsikt
- f.eks
- i stedet
- instruksjoner
- Mellom
- utstedelse
- saker
- IT
- køyring
- Jobb
- Jobb
- JSON
- Hold
- nøkkel
- nøkler
- Vet
- lab
- innsjø
- Latin
- latin amerika
- lag
- lag
- føre
- LÆRE
- bibliotekene
- BEGRENSE
- linje
- Liste
- laste
- lasting
- laster
- plassering
- Se
- UTSEENDE
- den
- Los Angeles
- Lot
- Hoved
- opprettholder
- gjøre
- fikk til
- ledelse
- leder
- administrerende
- manuelt
- mange
- kartlegging
- merket
- Meny
- Flett
- melding
- kunne
- migrasjon
- minimum
- minutt
- minutter
- Moderne
- modifisere
- Overvåke
- overvåking
- mer
- mest
- Mest populær
- flere
- navn
- oppkalt
- navn
- Naviger
- Navigasjon
- Trenger
- nødvendig
- behov
- Ny
- neste
- nord
- nord amerika
- varsling
- Antall
- objekt
- gjenstander
- ONE
- pågående
- OP
- drift
- optimalisert
- alternativer
- organisasjons
- organisasjoner
- Organisert
- original
- ellers
- utenfor
- egen
- eieren
- brød
- parameter
- parametere
- del
- deler
- banen
- Mønster
- utføre
- utfører
- utfører
- perioden
- tillatelser
- fase
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Populær
- Post
- postgresql
- praksis
- trekkes
- forutsetninger
- presentere
- primære
- Problem
- prosess
- Prosesser
- prosessering
- produsert
- programmer
- gi
- forutsatt
- gir
- Python
- raskt
- heve
- Sats
- Raw
- rådata
- Lese
- sanntids
- rekord
- poster
- erstatte
- replikert
- replikering
- krever
- påkrevd
- ressurs
- Ressurser
- REST
- Resultater
- detaljhandel
- retur
- avkastning
- anmeldelse
- robust
- Rolle
- Regel
- regler
- Kjør
- rennende
- samme
- Spar
- scenario
- planlegge
- omfang
- skript
- Søk
- Sekund
- sektorer
- se
- valgt
- velge
- utvalg
- separat
- Tjenester
- sett
- innstilling
- innstillinger
- bør
- Vis
- Viser
- lignende
- Enkelt
- siden
- enkelt
- So
- løsning
- løser
- noen
- sofistikert
- kilde
- Kilder
- mellomrom
- Spark
- spesifikk
- spesifikasjon
- spesifisert
- Sports
- SQL
- stable
- Stabler
- Scene
- interessenter
- Begynn
- startet
- Start
- starter
- Stater
- statistikk
- status
- Trinn
- Steps
- stoppet
- lagring
- oppbevare
- lagret
- butikker
- Strategisk
- struktur
- strukturert
- studio
- vellykket
- slik
- Super
- støtte
- Systemer
- bord
- Target
- Oppgave
- oppgaver
- lag
- lag
- telekom
- mal
- terminal
- De
- Kilden
- deres
- tusener
- tre
- Gjennom
- tid
- tidslinje
- ganger
- tidsstempel
- til
- verktøy
- topp
- Totalt
- Sporing
- tradisjonelle
- transaksjonell
- Transform
- Transformation
- utløse
- tutorial
- typer
- etter
- forstå
- unik
- Oppdater
- oppdateringer
- bruke
- bruk sak
- Bruker
- Brukere
- vanligvis
- verdi
- verifisere
- Se
- visualisering
- volum
- vente
- Warehouse
- web
- webtjenester
- hvilken
- vil
- innenfor
- uten
- virker
- skrive
- skrevet
- yaml
- år
- år
- Din
- zephyrnet