I dataanalyseområdet håndterer organisasjoner ofte mange tabeller i forskjellige databaser og filformater for å holde data for forskjellige forretningsfunksjoner. Bedriftsbehov driver ofte tabellstrukturen, slik som skjemautvikling (tillegg av nye kolonner, fjerning av eksisterende kolonner, oppdatering av kolonnenavn og så videre) for noen av disse tabellene i én forretningsfunksjon som krever at andre forretningsfunksjoner replikerer det samme. . Dette innlegget fokuserer på slike skjemaendringer i filbaserte tabeller og viser hvordan du automatisk kan replikere skjemautviklingen av strukturerte data fra tabellformater i databaser til tabellene lagret som filer på en kostnadseffektiv måte.
AWS Lim er en serverløs dataintegrasjonstjeneste som gjør det enkelt å oppdage, forberede og kombinere data for analyse, maskinlæring (ML) og applikasjonsutvikling. I dette innlegget viser vi hvordan du bruker Apache Hudi, et selvadministrerende databaselag på filbaserte datainnsjøer, i AWS Glue for å automatisk representere data i relasjonsform og administrere skjemautviklingen deres i skala ved hjelp av Amazon enkel lagringstjeneste (Amazon S3), AWS Database Migration Service (AWS DMS), AWS Lambda, AWS Lim, Amazon DynamoDB, Amazonas Auroraog Amazonas Athena for automatisk å identifisere skjemautvikling og bruke den til å administrere databelastning i petabyte-skala.
Apache Hudi støtter ACID-transaksjoner og CRUD-operasjoner på en datainnsjø. Dette legger grunnlaget for en datainnsjø-arkitektur ved å muliggjøre transaksjonsstøtte og skjemautvikling og -administrasjon, koble lagring fra databehandling og sikre støtte for tilgjengelighet gjennom BI-verktøy (business intelligence). I dette innlegget implementerer vi en arkitektur for å bygge en transaksjonsdatainnsjø bygget på de nevnte Hudi-funksjonene.
Løsningsoversikt
Dette innlegget forutsetter et scenario der flere tabeller er til stede i en kildedatabase, og vi ønsker å replikere eventuelle skjemaendringer i noen av disse tabellene i Apache Hudi-tabeller i datasjøen. Den bruker innfødt støtte for Apache Hudi på AWS Glue for Apache Spark.
I dette innlegget er skjemautviklingen av kildetabeller i Aurora-databasen fanget opp via AWS DMS inkrementell lasting eller endring av datafangst (CDC) mekanisme, og den samme skjemautviklingen er replikert i Apache Hudi-tabeller lagret i Amazon S3. Apache Hudi-tabeller oppdages av AWS Glue Data Catalog og spørres av Athena. En AWS Glue-jobb, støttet av en orkestreringspipeline som bruker Lambda og en DynamoDB-tabell, tar seg av den automatiserte replikeringen av skjemaevolusjon i Apache Hudi-tabellene.
Vi bruker Aurora som en eksempeldatakilde, men enhver datakilde som støtter Opprett, Les, Oppdater og Slett (CRUD) operasjoner kan erstatte Aurora i ditt brukstilfelle.
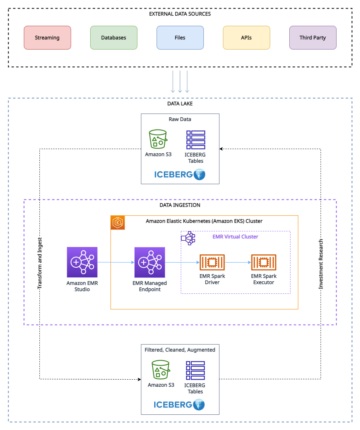
Følgende diagram illustrerer løsningsarkitekturen.

Flytingen av løsningen er som følger:
- Aurora, som en eksempeldatakilde, inneholder en RDBMS-tabell med flere rader, og AWS DMS laster hele dataen til en S3-bøtte (som vi kaller råbøtten). Vi forventer at du kan ha flere kildetabeller, men for demonstrasjonsformål bruker vi kun én kildetabell i dette innlegget.
- Vi utløser en Lambda-funksjon med kildetabellnavnet som en hendelse slik at de tilsvarende parameterne til kildetabellen leses fra DynamoDB. For å planlegge denne operasjonen for bestemte tidsintervaller, vi planlegge Amazon EventBridge for å utløse Lambdaen med tabellnavnet som parameter.
- Det er mange tabeller i kildedatabasen, og vi ønsker å kjøre én AWS Glue-jobb for hver kildetabell for enkelhet i operasjoner. Fordi vi bruker hver AWS Glue-jobb for å oppdatere hver Apache Hudi-tabell, bruker dette innlegget en DynamoDB-tabell for å holde konfigurasjonsparametrene som brukes av hver AWS Glue-jobb for hver Apache Hudi-tabell. DynamoDB-tabellen inneholder hvert Apache Hudi-tabellnavn, tilsvarende AWS Glue-jobbnavn, AWS Glue-jobbstatus, lastestatus (full eller delta), partisjonsnøkkel, postnøkkel og skjema for å overføre til den tilsvarende tabellens AWS Glue Job. Verdiene i DynamoDB-tabellen er statiske verdier.
- For å trigge hver AWS Glue-jobb (10 G.1X DPUer) parallelt for å kjøre en Apache Hudi-spesifikk kode for å sette inn data i de tilsvarende Hudi-tabellene, sender Lambda hver Apache Hudi-tabellspesifikke parameter lest fra DynamoDB til hver AWS Glue-jobb. Kildedataene kommer fra tabeller i Aurora-kildedatabasen via AWS DMS med full belastning og inkrementell belastning eller CDC.
Opprett ressurser med AWS CloudFormation
Vi tilbyr en AWS skyformasjon mal for å lage følgende ressurser:
- Lambda og DynamoDB som orkestratorer for databelastningsstyring
- S3-bøtter for den rå, raffinerte sonen og eiendeler for å holde kode for skjemautvikling
- En AWS Glue-jobb for å oppdatere Hudi-tabellene og utføre skjemaevolusjon, både forover- og bakoverkompatibel
Aurora-tabellen og AWS DMS-replikeringsforekomsten er ikke klargjort via denne stabelen. For instruksjoner for å sette opp Aurora, se Opprette en Amazon Aurora DB-klynge.
Start følgende stabel og oppgi stabelnavnet ditt.
eu-west-1 |
Skjema evolusjon
For å få tilgang til din Aurora-database, se Hvordan kobler jeg til min Amazon RDS for MySQL-forekomst ved å bruke MySQL Workbench. Fullfør deretter følgende trinn:
- Lag en tabell kalt objekt etter spørringene i Aurora-databasen og endre skjemaet slik at vi kan se skjemautviklingen reflekteres på datainnsjønivå:
Etter at du har opprettet stablene, er det nødvendig med noen manuelle trinn for å klargjøre løsningen fra ende til annen.
- Opprett et AWS DMS f.eks, AWS DMS endepunkter, og AWS DMS oppgave med følgende konfigurasjoner:
- Legg til dataFormat som parkett i målendepunktet.
- Pek målendepunktet til AWS DMS til råbøtten, som er formatert som
raw-bucket-<account_number>-<region_name>, og mappenavnet skal være POC.
- Start AWS DMS-oppgaven.
- Opprett en testhendelse i
HudiLambdaLambdafunksjon med innholdet i hendelsen JSON somPOC.dbog lagre det. - Kjør Lambda-funksjonen.
I dette innlegget reflekteres skjemautviklingen gjennom Hudi Hive-synkronisering i AWS Lim. Du endrer ikke søk separat i datasjøen.
Nå fullfører vi følgende trinn for å endre skjemaet ved kilden. Utløs Lambda-funksjonen etter hvert trinn for å generere en fil i POC/db/object mappe i råbøtta. AWS DMS fanger nesten umiddelbart opp skjemaendringene og rapporterer til råbøtten.
- Legg til en kolonne kalt
test_columntil kildetabellenobjecti din Aurora-database:
- Gi nytt navn til kolonnen
new_field_1tilnew_field_2i kildetabellobjektet:
Kolonnen new_field_1 forventes å forbli i Hudi-tabellen, men uten at noen nye verdier blir fylt inn i den lenger.
- Slett kolonnen
new_field_2fra kildetabellobjektet:
I likhet med forrige operasjon, kolonnen new_field_2 forventes å forbli i Hudi-tabellen, men uten at noen nye verdier blir fylt inn i den lenger.
Hvis du allerede har AWS Lake formasjon datatillatelser som er satt opp i kontoen din, kan det oppstå tillatelsesproblemer. Gi i så fall full tillatelse (Super) til standarddatabasen (før du utløser Lambda-funksjonen) og alle tabeller i POC.db database (etter at lastingen er fullført).
Gjennomgå resultatene
Når den nevnte kjøringen skjer etter skjemaendringer, genereres følgende resultater i den raffinerte bøtten. Vi kan se Apache Hudi-tabellene med innholdet i Athena. For å sette opp Athena, se Komme i gang.
Tabellen og databasen er tilgjengelig i AWS Glue Data Catalog og klar til å bla gjennom skjemaet.
Før skjemaendringen ser Athena-resultatene ut som følgende skjermbilde.
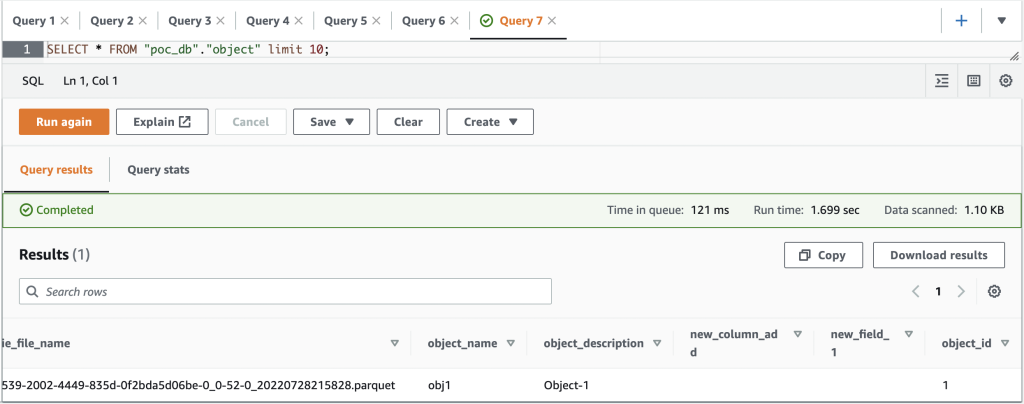
Etter at du har lagt til kolonnen test_column og sett inn en verdi i test_column feltet i objekttabellen i Aurora-databasen, den nye kolonnen (test_column) gjenspeiles i den tilsvarende Apache Hudi-tabellen i datasjøen.
Følgende skjermbilde viser resultatene i Athena.

Etter at du gir nytt navn til kolonnen new_field_1 til new_field_2 og sett inn en verdi i new_field_2 feltet i objekttabellen, den omdøpte kolonnen (new_field_2) gjenspeiles i den tilsvarende Apache Hudi-tabellen i datasjøen, og new_field_1 forblir i skjemaet, og har ingen ny verdi fylt ut i kolonnen.
Følgende skjermbilde viser resultatene i Athena.
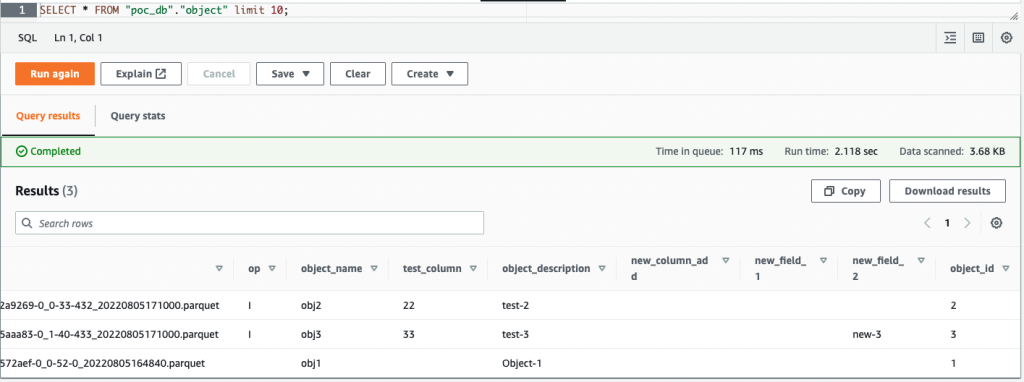
Etter at du har slettet kolonnen new_field_2 i objekttabellen og sett inn eller oppdater eventuelle verdier under noen kolonner i objekttabellen, den slettede kolonnen (new_field_2) forblir i det tilsvarende Apache Hudi-tabellskjemaet, og har ingen ny verdi fylt ut i kolonnen.
Følgende skjermbilde viser resultatene i Athena.

Rydd opp
Når du er ferdig med denne løsningen, sletter du prøvedataene i de rå og raffinerte S3-bøttene og sletter bøttene.
Slett også CloudFormation-stakken for å fjerne alle tjenesteressursene som brukes i denne løsningen.
konklusjonen
Dette innlegget viste hvordan man implementerer skjemaevolusjon med en åpen kildekode-løsning ved å bruke Apache Hudi i et AWS-miljø med en orkestreringspipeline.
Du kan utforske de forskjellige konfigurasjoner av AWS Glue for å endre AWS Glue-jobbstrukturene og implementere det for dataanalyse og andre brukstilfeller.
Om forfatterne
 Subhro Bose er en senior dataarkitekt i Emergent Technologies and Intelligence Platform i Amazon. Han elsker å løse vitenskapelige problemer med nye teknologier som AI/ML, big data, quantum og mer for å hjelpe bedrifter på tvers av ulike industrivertikaler med å lykkes i innovasjonsreisen. På fritiden liker han å spille bordtennis, lære teorier om miljøøkonomi og utforske de beste muffinsene over hele byen.
Subhro Bose er en senior dataarkitekt i Emergent Technologies and Intelligence Platform i Amazon. Han elsker å løse vitenskapelige problemer med nye teknologier som AI/ML, big data, quantum og mer for å hjelpe bedrifter på tvers av ulike industrivertikaler med å lykkes i innovasjonsreisen. På fritiden liker han å spille bordtennis, lære teorier om miljøøkonomi og utforske de beste muffinsene over hele byen.
 Ketan Karalkar er Big Data Solutions Consultant hos AWS. Han har nesten to tiår med erfaring med å hjelpe kunder med å designe og bygge dataanalyse og databaseløsninger. Han tror på å bruke teknologi som en muliggjører for å løse virkelige forretningsproblemer.
Ketan Karalkar er Big Data Solutions Consultant hos AWS. Han har nesten to tiår med erfaring med å hjelpe kunder med å designe og bygge dataanalyse og databaseløsninger. Han tror på å bruke teknologi som en muliggjører for å løse virkelige forretningsproblemer.
 Eva Fang er en dataforsker innen profesjonelle tjenester i AWS. Hun brenner for å bruke teknologien for å gi verdi til kundene og oppnå forretningsresultater. Hun er basert i London, på fritiden liker hun å se filmer og musikaler.
Eva Fang er en dataforsker innen profesjonelle tjenester i AWS. Hun brenner for å bruke teknologien for å gi verdi til kundene og oppnå forretningsresultater. Hun er basert i London, på fritiden liker hun å se filmer og musikaler.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/automate-schema-evolution-at-scale-with-apache-hudi-in-aws-glue/
- 1
- 10
- 100
- 107
- 11
- 7
- a
- Om oss
- adgang
- tilgjengelighet
- Logg inn
- Oppnå
- tvers
- tillegg
- Etter
- AI / ML
- Alle
- allerede
- Amazon
- Amazon RDS
- amp
- analytics
- og
- Apache
- Søknad
- Applikasjonutvikling
- Påfør
- arkitektur
- Eiendeler
- Aurora
- automatisere
- Automatisert
- automatisk
- tilgjengelig
- AWS
- AWS Lim
- basert
- fordi
- før du
- være
- mener
- BEST
- Stor
- Store data
- Surfer
- bygge
- bygget
- virksomhet
- forretningsfunksjoner
- business intelligence
- bedrifter
- ring
- som heter
- fangst
- hvilken
- saken
- saker
- katalog
- CDC
- endring
- Endringer
- City
- kode
- Kolonne
- kolonner
- kombinere
- fullføre
- Beregn
- Konfigurasjon
- konfigurasjoner
- Koble
- konsulent
- inneholder
- innhold
- innhold
- Tilsvarende
- kostnadseffektiv
- skape
- Opprette
- Kunder
- dato
- Data Analytics
- dataintegrasjon
- Data Lake
- dataforsker
- Database
- databaser
- avtale
- tiår
- Misligholde
- Delta
- utforming
- Utvikling
- forskjellig
- oppdage
- oppdaget
- ikke
- stasjonen
- Drop
- hver enkelt
- Økonomi
- muliggjør
- møte
- Endpoint
- sikrer
- Miljø
- miljømessige
- Eter (ETH)
- Event
- evolusjon
- eksisterende
- forvente
- forventet
- erfaring
- utforske
- Egenskaper
- felt
- filet
- Filer
- flyten
- fokuserer
- etter
- følger
- skjema
- Fundament
- fra
- fullt
- funksjon
- funksjoner
- generere
- generert
- innvilge
- skjer
- å ha
- hjelpe
- hjelpe
- Hive
- hold
- holder
- Hvordan
- Hvordan
- HTML
- HTTPS
- identifisere
- iverksette
- in
- industri
- Innovasjon
- f.eks
- instruksjoner
- integrering
- Intelligens
- saker
- IT
- Jobb
- reise
- JSON
- nøkkel
- innsjø
- lag
- Lays
- LÆRE
- læring
- Nivå
- Life
- laste
- London
- Se
- ser ut som
- maskin
- maskinlæring
- GJØR AT
- administrer
- ledelse
- håndbok
- mange
- mekanisme
- migrasjon
- ML
- mer
- Filmer
- flere
- MySQL
- navn
- oppkalt
- navn
- nesten
- nødvendig
- behov
- Ny
- objekt
- ONE
- åpen kildekode
- drift
- Drift
- orkestre
- organisasjoner
- Annen
- Parallel
- parameter
- parametere
- passerer
- lidenskapelig
- utføre
- tillatelse
- tillatelser
- petabyte
- Picks
- rørledning
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- PoC
- befolket
- Post
- Forbered
- presentere
- forrige
- problemer
- profesjonell
- gi
- formål
- Quantum
- Raw
- Lese
- klar
- ekte
- ekte liv
- rekord
- raffinert
- reflektert
- forblir
- fjerning
- fjerne
- erstatte
- replikert
- replikering
- Rapporter
- representere
- Krever
- Ressurser
- Resultater
- Kjør
- samme
- Spar
- Skala
- scenario
- planlegge
- Vitenskap
- Forsker
- senior
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- bør
- Vis
- Viser
- Enkelt
- enkelhet
- So
- løsning
- Solutions
- LØSE
- løse
- noen
- kilde
- Rom
- spesifikk
- stable
- Stabler
- status
- opphold
- Trinn
- Steps
- lagring
- lagret
- struktur
- strukturert
- lykkes
- slik
- Super
- støtte
- Støttes
- Støtter
- bord
- tar
- Target
- Oppgave
- Technologies
- Teknologi
- mal
- tennis
- test
- De
- Kilden
- deres
- Gjennom
- tid
- til
- verktøy
- Transaksjonen
- transaksjonell
- Transaksjoner
- utløse
- utløsende
- etter
- Oppdater
- bruke
- bruk sak
- verdi
- Verdier
- vertikaler
- av
- Se
- Se
- hvilken
- innenfor
- uten
- Din
- zephyrnet