Datastyring er samlingen av retningslinjer, prosesser og systemer som organisasjoner bruker for å sikre kvaliteten og hensiktsmessig håndtering av dataene deres gjennom hele livssyklusen med det formål å generere forretningsverdi. Datastyring er i økende grad øverst i sinnet for kunder ettersom de anerkjenner data som en av deres viktigste eiendeler. Effektiv datastyring muliggjør bedre beslutningstaking ved å forbedre datakvaliteten, redusere dataadministrasjonskostnader og sikre sikker tilgang til data for interessenter. I tillegg kreves datastyring for å overholde et stadig mer komplekst reguleringsmiljø med personvern for personopplysninger (som GDPR og CCPA) og regelverk om dataopphold (som i EU, Russland og Kina).
For AWS-kunder forbedrer effektiv datastyring beslutningstaking, øker virksomhetens smidighet, gir et konkurransefortrinn og reduserer risikoen for bøter på grunn av manglende overholdelse av regulatoriske forpliktelser. Vi forstår den unike muligheten til å gi våre kunder en omfattende ende-til-ende datastyringsløsning som er sømløst integrert i vår portefølje av tjenester, og AWS Lake formasjon og AWS Lim Data Catalog er nøkkelen til å løse disse utfordringene.
I dette innlegget er vi glade for å oppsummere funksjonene som AWS Glue Data Catalog, AWS Glue crawler og Lake Formation-teamene leverte i 2022. Vi har samlet noen av nøkkelsamtalene og løsningene om datastyring, datanettverk og moderne data arkitektur publisert og presentert i AWS re:Invent 2022, og noen få datainnsjøløsninger bygget av kunder og AWS-partnere for enkel referanse. Enten du er en dataplattformbygger, dataingeniør, dataforsker eller en hvilken som helst teknologileder som er interessert i datainnsjøløsninger, er dette innlegget for deg.
For å lære mer om hvordan kunder sikrer og deler data med Lake Formation, anbefaler vi å gå dypere inn i GoDaddy's desentralisert datanettverk, Novo Nordisks moderne dataarkitektur, og JPMorgans forbedringer av deres Federated Data Lake, en styrt datanettimplementering ved bruk av Lake Formation. Du kan også lære hvordan AWS Partners integrerte med Lake Formation for å hjelpe kunder med å bygge unike datainnsjøer, i Starbursts datamaskeløsning, Informatica automatisert datadelingsløsning, Ahanas Presto-integrasjon med Lake Formation, Ascendings skikk datastyringssystem, hvordan PBS brukes maskinlæring på datainnsjøene deres, og hvordan hc1 gir personlig helseinnsikt for kunder.
Du kan se hvordan Lake Formation brukes av kunder til å bygge moderne dataarkitekturer i følgende re:Invent 2022 talks:
Lake Formation-teamet lyttet til tilbakemeldinger fra kunder og gjorde forbedringer innen områdene datastyring på tvers av kontoer, utvidet kilden til datainnsjøer, muliggjorde enhetlig datastyring av en forretningsdatakatalog, og gjorde sikker deling av data fra bedrift til bedrift mulig, og utvide dekningsområdet for finmaskede adgangskontroller til Amazon RedShift. I resten av dette innlegget deler vi gjerne fremgangen vi gjorde i 2022.
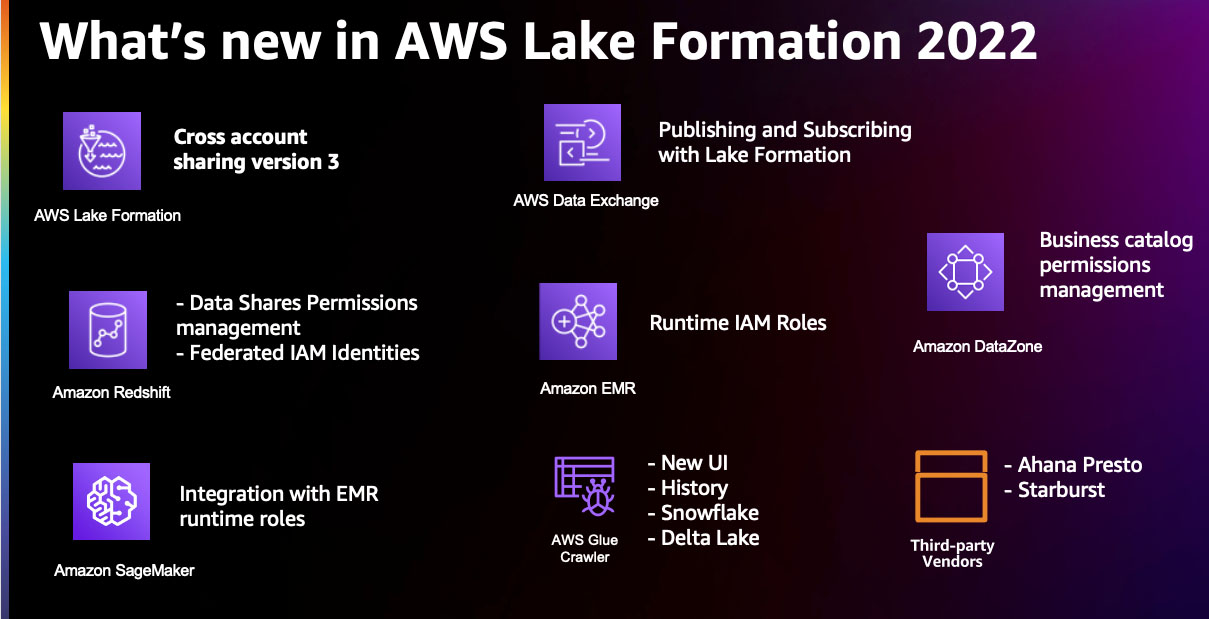
Forbedre styring på tvers av kontoer
Lake Formation gir grunnlaget for at kunder kan dele data på tvers av kontoer i organisasjonen deres. Du kan dele AWS Glue Data Catalog-ressurser til AWS identitets- og tilgangsadministrasjon (IAM) oppdragsgivere i en konto så vel som andre AWS-kontoer ved hjelp av to metoder. Den første kalles metoden med navngitt ressurs, der brukere kan velge navn på databaser og tabeller og velge typen tillatelser som skal deles. Den andre metoden bruker LF-tags, der brukere kan opprette og knytte LF-tags til databaser og tabeller og gi tillatelse til IAM-rektorer ved å bruke LF-Tag-policyer og uttrykk.
I november 2022 introduserte Lake Formation versjon 3 av sin funksjon for deling på tvers av kontoer. Med denne nye versjonen kan Lake Formation-brukere dele katalogressurser ved å bruke LF-tags på AWS organisasjoner nivå. Deling av data ved hjelp av LF-tags hjelper med å skalere tillatelser og reduserer administrasjonsarbeidet for datainnsjøbyggere. Deling på tvers av kontoer versjon 3 lar deg også dele ressurser til spesifikke IAM-oppdragsgivere i andre kontoer, og gir dataeiere kontroll over hvem som har tilgang til dataene deres i andre kontoer. Til slutt har vi fjernet overheaden med å skrive og vedlikeholde datakatalogressurspolicyer ved å introdusere AWS Resource Access Manager (AWS RAM)-invitasjoner med LF-tags-baserte retningslinjer i versjon 3 for deling på tvers av kontoer. Vi oppfordrer deg til å utforske nærmere deling på tvers av kontoer i Lake Formation.
Utvidelse av Lake Formation-tillatelser til nye data
Inntil re:Invent 2022 ga Lake Formation tillatelsesadministrasjon for IAM-rektorer på Data Catalog-ressurser med underliggende data primært på Amazon enkel lagringstjeneste (Amazon S3). På re:Invent 2022 introduserte vi Lake Formation-tillatelsesadministrasjon for Amazon Redshift-datadelinger i forhåndsvisningsmodus. Amazon Redshift er en fullstendig administrert, petabyte-skala datavarehustjeneste i AWS Cloud. De datadelingsfunksjon lar dataeiere gruppere databaser, tabeller og visninger i en Amazon Redshift-klynge og dele den med andre Amazon Redshift-klynger innenfor eller på tvers av AWS-kontoer. Datadeling reduserer behovet for å beholde flere kopier av de samme dataene i forskjellige datavarehus for å akselerere forretningsbeslutninger på tvers av en organisasjon. Lake Formation forbedrer deling av data i Amazon Redshift-datadeling ytterligere ved å gi finmasket tilgangskontroll på tabeller og visninger.
For ytterligere detaljer om denne funksjonen, se AWS Lake Formation-administrerte Redshift-datadelinger (forhåndsvisning) og Hvordan Redshift-datadeling kan administreres av Lake Formation.
Amazon EMR er en administrert klyngeplattform for å kjøre store dataapplikasjoner ved å bruke Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi og Presto i stor skala. Du kan bruke Amazon EMR til å kjøre batch- og strømbehandlingsanalysejobber på dine S3-datainnsjøer. Fra og med Amazon EMR utgivelse 6.7.0 introduserte vi Lake Formation-tillatelsesadministrasjon på en kjøretids-IAM-rolle brukes med EMR Steps API. Denne funksjonen lar deg sende inn Apache Spark- og Apache Hive-applikasjoner til en EMR-klynge gjennom EMR Steps API som håndhever tillatelser på tabellnivå og kolonnenivå ved å bruke Lake Formation til den IAM-rollen som sender søknaden. Denne Lake Formation-integrasjonen med Amazon EMR lar deg dele en EMR-klynge på tvers av flere brukere i en organisasjon med forskjellige tillatelser ved å isolere applikasjonene dine gjennom en kjøretids-IAM-rolle. Vi oppfordrer deg til å sjekke denne funksjonen i Lake Formation-verkstedet Integrasjon med Amazon EMR ved hjelp av Runtime Rolls. For å utforske en brukstilfelle, se Vi introduserer kjøretidsroller for Amazon EMR-trinn: Bruk IAM-roller og AWS Lake Formation for tilgangskontroll med Amazon EMR.
Amazon SageMaker Studio er et fullt integrert utviklingsmiljø (IDE) for maskinlæring (ML) som gjør det mulig for dataforskere og utviklere å forberede data for å bygge, trene, justere og distribuere modeller. Studio tilbyr en innebygd integrasjon med Amazon EMR slik at dataforskere og dataingeniører interaktivt kan forberede data i petabyte-skala ved å bruke åpen kildekode-rammeverk som Apache Spark, Presto og Hive ved hjelp av Studio-notatbøker. Med utgivelsen av Lake Formation-tillatelsesadministrasjon på en kjøretids-IAM-rolle, Studio støtter nå tilgang på tabellnivå og kolonnenivå med Lake Formation. Når brukere kobler til EMR-klynger fra Studio-notatbøker, kan de velge IAM-rollen (kalt runtime IAM-rolle) som de ønsker å komme i kontakt med. Hvis datatilgang administreres av Lake Formation, kan brukere håndheve tillatelser på tabellnivå og kolonnenivå ved å bruke policyer knyttet til kjøretidsrollen. For flere detaljer, se Bruk finkornede datatilgangskontroller med AWS Lake Formation og Amazon EMR fra Amazon SageMaker Studio.
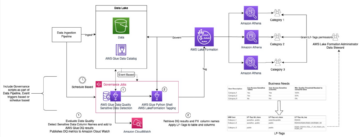
Innta og katalogisere varierte data
En robust datastyringsmodell inkluderer data fra en organisasjons mange datakilder og metoder for å oppdage og katalogisere disse varierte datamidlene. AWS Glue-crawlere gir muligheten til å oppdage data fra kilder inkludert Amazon S3, Amazon Redshift og NoSQL-databaser, og fylle ut AWS Glue Data Catalog.
I 2022 lanserte vi AWS Glue crawler-støtte for Snowflake og AWS Glue crawler-støtte for Delta Lake-bord. Disse integrasjonene lar AWS Glue-crawlere opprette og oppdatere datakatalogtabeller basert på disse populære datakildene. Dette gjør det enda enklere å lage uttrekk, transformere og laste (ETL)-jobber med AWS Glue basert på disse datakatalogtabellene som kilder og mål.
I 2022 ble AWS Glue Crawlers UI redesignet for å tilby en bedre brukeropplevelse. En av de viktigste forbedringene som ble levert som en del av denne revisjonen, er den større innsikten i AWS Glue-søkerobothistorien. Søkerobothistorikk-grensesnittet gir en enkel oversikt over søkerobotkjøringer, tidsplaner, datakilder og tagger. For hver gjennomgang gir robotsøkeloggen et sammendrag av endringer i databaseskjemaet eller Amazon S3-partisjonsendringer. Crawler-historikk gir også detaljert informasjon om DPU-timer og reduserer tiden brukt på å analysere og feilsøke crawler-operasjoner og -kostnader. For å utforske de nye funksjonalitetene som er lagt til søkerobotens brukergrensesnitt, se Konfigurer og overvåk AWS Glue-crawlere ved å bruke det forbedrede AWS Glue UI og crawler-historikken.
I 2022 utvidet vi også støtten for robotsøkeprogrammer basert på Amazon S3-hendelsesvarsler til å støtte katalogtabeller. Med denne funksjonen kan inkrementell gjennomgang overføres fra datapipelines til den planlagte AWS Glue-crawleren, noe som reduserer gjennomsøkingen til inkrementelle S3-hendelser. For mer informasjon, se Bygg inkrementelle gjennomganger av datainnsjøer med eksisterende Glue-katalogtabeller.
Flere måter å dele data på utenfor datasjøen
Under re:Invent 2022 annonserte vi en forhåndsvisning av AWS Data Exchange for AWS Lake Formation, en ny funksjon som gjør det mulig for dataabonnenter å finne og abonnere på tredjeparts datasett som administreres direkte gjennom Lake Formation. Inntil nå, AWS datautveksling abonnenter kunne få tilgang til tredjeparts datasett ved å eksportere leverandørens filer til sine egne S3-bøtter, kalle leverandørenes APIer gjennom Amazon API-gateway, eller spørre produsenters Amazon Redshift-dataandeler fra Amazon Redshift-klyngen deres. Med den nye Lake Formation-integrasjonen kuraterer dataleverandører AWS Data Exchange-datasett ved hjelp av Lake Formation-tagger. Dataabonnenter er i stand til å spørre og utforske databasene og tabellene knyttet til disse kodene, akkurat som alle andre AWS Glue Data Catalog-ressurser. Organisasjoner kan bruke ressursbaserte Lake Formation-tillatelser for å dele de lisensierte datasettene innenfor samme konto eller på tvers av kontoer ved å bruke AWS License Manager. AWS Data Exchange for Lake Formation effektiviserer datalisensiering og delingsoperasjoner ved å akselerere data onboarding, redusere mengden ETL som kreves for sluttbrukere for å få tilgang til tredjepartsdata, og sentralisere styring og tilgangskontroller for tredjepartsdata.
På re:Invent 2022 annonserte vi også Amazon DataZone, en ny dataadministrasjonstjeneste som gjør det raskere og enklere for deg å katalogisere, oppdage, dele og styre data som er lagret på tvers av AWS, lokale og tredjepartskilder. Amazon DataZone er en forretningsdatakatalogtjeneste som supplerer de tekniske metadataene i AWS Glue Data Catalog. Amazon DataZone er integrert med Lake Formation-tillatelsesadministrasjonen slik at du effektivt kan administrere og styre tilgangen til dataene dine, og kontrollere hvem som får tilgang til hvilke data og til hvilket formål. Med utgiver-abonnentmodellen til Amazon DataZone kan dataressurser deles og få tilgang til på tvers av regioner. For ytterligere detaljer om tjenesten og dens funksjoner, se Vanlige spørsmål om Amazon DataZone og re: Invent lansering.
konklusjonen
Data transformerer hvert felt og hver virksomhet. Men med data som vokser raskere enn de fleste bedrifter kan holde styr på, er det en utfordrende ting å samle inn, sikre og få verdi ut av disse dataene. En moderne datastrategi kan hjelpe deg med å skape bedre forretningsresultater med data. AWS tilbyr det mest komplette settet med tjenester for ende-til-ende-datareisen for å hjelpe deg med å låse opp verdi fra dataene dine og gjøre dem om til innsikt.
Hos AWS jobber vi baklengs fra kundenes krav. Fra Lake Formation-teamet jobbet vi hardt for å levere funksjonene beskrevet i dette innlegget, og vi inviterer deg til å sjekke dem ut. Med vårt fortsatte fokus på å finne opp, håper vi å spille en nøkkelrolle i å styrke organisasjoner til å bygge nye datastyringsmodeller som hjelper deg å oppnå mer forretningsverdi med lynets hastighet.
Du kan komme i gang med Lake Formation ved å utforske vår praktisk verksted moduler og Komme i gang veiledninger. Vi ser frem til å høre fra dere, våre kunder, om datainnsjø og brukssaker for datastyring. Ta kontakt gjennom AWS-kontoteamet ditt og del kommentarene dine.
Om forfatterne
 Jason Berkowitz er senior produktsjef med AWS Lake Formation. Han kommer fra en bakgrunn innen maskinlæring og datainnsjøarkitekturer. Han hjelper kundene med å bli datadrevne.
Jason Berkowitz er senior produktsjef med AWS Lake Formation. Han kommer fra en bakgrunn innen maskinlæring og datainnsjøarkitekturer. Han hjelper kundene med å bli datadrevne.
 Aarthi Srinivasan er en senior Big Data Architect med AWS Lake Formation. Hun liker å bygge datainnsjøløsninger for AWS-kunder og partnere. Når hun ikke er på tastaturet, utforsker hun de siste vitenskapelige og teknologiske trendene og tilbringer tid med familien.
Aarthi Srinivasan er en senior Big Data Architect med AWS Lake Formation. Hun liker å bygge datainnsjøløsninger for AWS-kunder og partnere. Når hun ikke er på tastaturet, utforsker hun de siste vitenskapelige og teknologiske trendene og tilbringer tid med familien.
 Leonardo Gomez er Senior Analytics Specialist Solutions Architect hos AWS. Basert i Toronto, Canada, har han over et tiår med erfaring innen dataadministrasjon, og hjelper kunder over hele verden med å møte deres forretningsbehov og tekniske behov.
Leonardo Gomez er Senior Analytics Specialist Solutions Architect hos AWS. Basert i Toronto, Canada, har han over et tiår med erfaring innen dataadministrasjon, og hjelper kunder over hele verden med å møte deres forretningsbehov og tekniske behov.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/aws-lake-formation-2022-year-in-review/
- 100
- 116
- 2022
- 7
- a
- evne
- I stand
- Om oss
- akselerere
- akselerer
- adgang
- Tilgang til data
- aksesseres
- Tilgang
- Logg inn
- kontoer
- tvers
- la til
- tillegg
- Ytterligere
- adresse
- admin
- Fordel
- tillater
- Amazon
- Amazon EMR
- Amazon SageMaker
- beløp
- analytics
- analyserer
- og
- annonsert
- Apache
- Apache Spark
- api
- APIer
- Søknad
- søknader
- Påfør
- hensiktsmessig
- arkitektur
- AREA
- områder
- rundt
- Eiendeler
- Førsteamanuensis
- assosiert
- revisjon
- AWS
- AWS Lim
- AWS Lake formasjon
- AWS re: Oppfinne
- bakgrunn
- basert
- bli
- Bedre
- Beyond
- Stor
- Store data
- bygge
- bygger
- utbyggere
- Bygning
- bygget
- virksomhet
- forretning til forretning
- som heter
- ringer
- Kan få
- Canada
- evner
- saken
- saker
- katalog
- CCPA
- utfordringer
- utfordrende
- Endringer
- sjekk
- Kina
- Velg
- Cloud
- Cluster
- Samle
- samling
- kommentarer
- Selskaper
- konkurranse
- fullføre
- komplekse
- omfattende
- Koble
- fortsatte
- kontroll
- kontroller
- Kostnader
- kunne
- dekning
- crawler
- skape
- skikk
- kunde
- Kunder
- dato
- data tilgang
- dataingeniør
- Datautveksling
- Data Lake
- Dataledelse
- Dataplattform
- personvern
- datakvalitet
- dataforsker
- datadeling
- datastrategi
- datalager
- datavarehus
- data-drevet
- Database
- databaser
- datasett
- tiår
- Beslutningstaking
- dypere
- leverer
- levert
- Delta
- utplasserings
- beskrevet
- detaljert
- detaljer
- utviklere
- Utvikling
- forskjellig
- direkte
- oppdage
- hver enkelt
- enklere
- Effektiv
- effektivt
- myndiggjøring
- muliggjør
- muliggjør
- oppmuntre
- ende til ende
- ingeniør
- Ingeniører
- forbedret
- Forbedrer
- sikre
- sikrer
- Miljø
- Eter (ETH)
- EU
- Selv
- Event
- hendelser
- Hver
- utveksling
- opphisset
- eksisterende
- ekspanderende
- erfaring
- utforske
- Utforske
- uttrykkene
- trekke ut
- familie
- raskere
- Trekk
- Egenskaper
- tilbakemelding
- Noen få
- felt
- Filer
- Finn
- bøter
- Først
- Fokus
- etter
- formasjon
- Forward
- Fundament
- rammer
- fra
- fullt
- funksjonalitet
- videre
- GDPR
- genererer
- få
- få
- globus
- skal
- styresett
- innvilge
- større
- Gruppe
- Økende
- Håndtering
- lykkelig
- Hard
- Helse
- hørsel
- hjelpe
- hjelpe
- hjelper
- historie
- Hive
- håp
- TIMER
- Hvordan
- Men
- HTML
- HTTPS
- IAM
- Identitet
- gjennomføring
- viktig
- forbedringer
- forbedrer
- bedre
- in
- I andre
- inkluderer
- Inkludert
- øker
- stadig
- info
- informasjon
- innsikt
- innsikt
- integrert
- integrering
- integrasjoner
- interessert
- introdusert
- innføre
- invitere
- IT
- Jobb
- reise
- Hold
- nøkkel
- innsjø
- siste
- lansert
- leder
- LÆRE
- læring
- Nivå
- Tillatelse
- Licensed
- Lisensiering
- Lyn
- Lysets hastighet
- laste
- Se
- maskin
- maskinlæring
- laget
- Hoved
- GJØR AT
- Making
- administrer
- fikk til
- ledelse
- leder
- mange
- metadata
- metode
- metoder
- ML
- Mote
- modell
- modeller
- Moderne
- Moduler
- Overvåke
- mer
- mest
- flere
- navn
- innfødt
- Trenger
- behov
- Ny
- ny funksjon
- notatbøker
- varslinger
- November
- Ny
- bindinger
- tilby
- Tilbud
- onboarding
- ONE
- åpen kildekode
- Drift
- Opportunity
- organisasjon
- organisasjoner
- Annen
- egen
- eiere
- del
- partnere
- PBS
- tillatelse
- tillatelser
- petabyte
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Spille
- vær så snill
- Politikk
- Populær
- portefølje
- mulig
- Post
- Forbered
- presentert
- Forhåndsvisning
- primært
- privatliv
- Prosesser
- prosessering
- Produkt
- Produktsjef
- Progress
- gi
- forutsatt
- tilbydere
- gir
- gi
- publisert
- formål
- kvalitet
- RAM
- RE
- gjenkjenne
- anbefaler
- reduserer
- redusere
- regioner
- forskrifter
- regulatorer
- slipp
- fjernet
- påkrevd
- Krav
- ressurs
- Ressurser
- REST
- anmeldelse
- Risiko
- robust
- Rolle
- roller
- Kjør
- Russland
- sagemaker
- samme
- Skala
- planlagt
- Vitenskap
- Vitenskap og teknologi
- Forsker
- forskere
- sømløst
- Sekund
- sikre
- sikring
- senior
- tjeneste
- Tjenester
- sett
- Del
- delt
- Aksjer
- deling
- Enkelt
- So
- løsning
- Solutions
- løse
- noen
- kilde
- Kilder
- Spark
- spesialist
- spesifikk
- fart
- brukt
- interessenter
- starburst
- startet
- Start
- Steps
- lagring
- lagret
- Strategi
- stream
- studio
- send
- abonnere
- abonnenter
- slik
- oppsummere
- SAMMENDRAG
- støtte
- Støtter
- Systemer
- Snakker
- mål
- lag
- lag
- Teknisk
- Teknologi
- De
- Kilden
- deres
- ting
- tredjeparts
- Gjennom
- hele
- tid
- til
- toronto
- berøre
- spor
- Kurs
- Transform
- transformere
- Trender
- SVING
- ui
- underliggende
- forstå
- enhetlig
- unik
- låse opp
- Oppdater
- bruke
- bruk sak
- Bruker
- Brukererfaring
- Brukere
- verdi
- versjon
- Se
- visninger
- Warehouse
- måter
- Hva
- om
- HVEM
- innenfor
- Arbeid
- arbeidet
- verksted
- Verksteder
- skriving
- år
- Din
- youtube
- zephyrnet