Introduksjon
I dette prosjektet vil vi fokusere på data fra India. Og vårt mål er å skape en prediktiv modell, slik som Logistic Regression osv. slik at når vi gir egenskapene til en kandidat, kan modellen forutsi om de vil rekruttere.
De datasett dreier seg om plasseringssesongen til en Business School i India. Datasettet har ulike faktorer på kandidater, som arbeidserfaring, eksamensprosent osv. Til slutt inneholder det status for rekruttering og godtgjørelsesdetaljer.

Campusrekruttering er en strategi for å skaffe, engasjere og ansette unge talenter for praksisplasser og stillinger på startnivå. Det innebærer ofte å jobbe med karrieretjenester på universiteter og delta på karrieremesser for å møte personlig med studenter og nyutdannede.
Denne artikkelen ble publisert som en del av Data Science Blogathon.
Innholdsfortegnelse
- Trinn involvert i å løse problemet
- Forbered data
- Bygg en logistisk regresjonsmodell
- Resultater av den logistiske regresjonsmodellen
- konklusjonen
Trinn involvert i å løse problemet
I denne artikkelen vil vi importere det datasettet, rense det og deretter forberede det til å bygge en logistisk regresjonsmodell. Våre mål her er følgende:
Først skal vi forberede datasettet vårt for binær klassifisering. Nå, hva mener jeg? når vi prøver å forutsi en kontinuerlig verdi, som prisen på en leilighet, kan den være et hvilket som helst tall mellom null og mange millioner dollar. Vi kaller det et regresjonsproblem.
Men i dette prosjektet er ting litt annerledes. I stedet for å forutsi en kontinuerlig verdi, har vi diskrete grupper eller klasser vi prøver å forutsi mellom dem. Så dette kalles et klassifikasjonsproblem, og fordi vi i prosjektet vårt vil ha bare to grupper som vi prøver å velge mellom, noe som gjør det til en binær klassifisering.
Det andre målet er å lage en logistisk regresjonsmodell for å forutsi rekruttering. Og vårt tredje mål er å forklare modellens spådommer ved å bruke oddsforholdet.
Nå når det gjelder arbeidsflyten for maskinlæring, trinnene vi skal følge, og noen av de nye tingene, vil vi lære underveis. Så i importfasen vil vi forberede dataene våre til å jobbe med et binært mål. I utforskningsfasen vil vi se på klassebalansen. Så i utgangspunktet, hvor stor andel av kandidatene ble ansatt, og hvilke proporsjoner var det ikke? og i funksjonskodingsfasen vil vi gjøre koding til våre kategoriske funksjoner. I delt del skal vi gjøre en randomisert togtestsplitt.
For modellbyggingsfasen vil vi for det første sette vår grunnlinje, og fordi vi vil bruke nøyaktighetspoeng, snakker vi mer om hva en nøyaktighetsscore er og hvordan vi bygger en grunnlinje når det er beregningen vi er interessert i. For det andre skal vi gjøre logistisk regresjon. Og så sist, men ikke minst, skal vi ha evalueringsfasen. Vi vil igjen fokusere på nøyaktighetsscore. Til slutt, for å kommunisere resultater, vil vi se på oddsforholdet.
Til slutt, før vi dykker inn i arbeidet, la oss introdusere oss for bibliotekene vi skal bruke, kaste prosjektet. Først vil vi importere dataene våre til Google Colabe notatbok til io-biblioteket. Da vi bruker en logistisk regresjonsmodell, importerer vi den fra scikit-learn. Etter det, også fra scikit lære, vil vi importere ytelsesberegningene våre, nøyaktighetspoengene og tog-test-delingen.
Vi vil bruke Matplotlib og sjøfødt for vår visualisering, og nusset vil være bare for lite matematikk.
Vi trenger pandaer for å manipulere dataene våre, labelencoder for å kode våre kategoriske variabler, og standard scaler for å normalisere dataene. Det er bibliotekene vi trenger.
La oss hoppe inn i å forberede dataene.
#import libraries
import io
import warnings import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler warnings.simplefilter(action="ignore", category=FutureWarning)Forbered data
Import
For å begynne å forberede dataene, la oss få det viktige arbeidet vårt. Først laster vi datafilen vår, og deretter må vi sette dem inn i en DataFrame `df.`
from google.colab import files
uploaded = files.upload()# Read CSV file
df = pd.read_csv(io.BytesIO(uploaded["Placement_Data_Full_Class.csv"]))
print(df.shape)
df.head()
Vi kan se vår vakre DataFrame, og vi har 215 poster og 15 kolonner som inkluderer «status»-attributtet, målet vårt. Dette er beskrivelsen for alle funksjoner.

Utforsk
Nå har vi alle disse funksjonene som vi skal utforske. Så la oss starte vår undersøkende dataanalyse. Først, la oss ta en titt på informasjonen for denne datarammen og se om noen av dem vi kanskje må beholde eller om vi kanskje må droppe.
# Inspect DataFrame
df.info() <class 'pandas.core.frame.DataFrame'>
RangeIndex: 215 entries, 0 to 214
Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sl_no 215 non-null int64 1 gender 215 non-null object 2 ssc_p 215 non-null float64 3 ssc_b 215 non-null object 4 hsc_p 215 non-null float64 5 hsc_b 215 non-null object 6 hsc_s 215 non-null object 7 degree_p 215 non-null float64 8 degree_t 215 non-null object 9 workex 215 non-null object 10 etest_p 215 non-null float64 11 specialisation 215 non-null object 12 mba_p 215 non-null float64 13 status 215 non-null object 14 salary 148 non-null float64
dtypes: float64(6), int64(1), object(8)
memory usage: 25.3+ KBNå når vi ser på `df`-info, er det et par ting vi ser etter, vi har 215 rader i datarammen vår, og spørsmålet vi ønsker å stille oss selv er, er det data som mangler? Og hvis vi ser her, ser det ut til at vi ikke mangler data bortsett fra lønnskolonnen, som forventet, på grunn av kandidater som ikke har blitt ansatt.
En annen bekymring for oss her er, er det noen lekkende funksjoner som vil gi informasjon til modellen vår som den ikke ville hatt hvis den ble implementert i den virkelige verden? Husk at vi vil at modellen vår skal forutsi om en kandidat vil plassere seg eller ikke, og vi vil at modellen vår skal lage disse spådommene før rekrutteringen skjer. Så vi ønsker ikke å gi noen informasjon om disse kandidatene etter rekrutteringen.
Så det er ganske tydelig at denne "lønn"-funksjonen gir informasjon om lønnen som tilbys av bedriften. Og fordi denne lønnen er for de aksepterte, utgjør denne funksjonen her lekkasje, og vi må droppe den.
df.drop(columns="salary", inplace=True)Den andre tingen jeg vil se på er datatypene for disse forskjellige funksjonene. Så når vi ser på disse datatypene, har vi åtte kategoriske funksjoner med målet vårt og syv numeriske funksjoner, og alt er riktig. Så nå som vi har disse ideene, la oss ta litt tid til å utforske dem dypere.
Vi vet at målet vårt har to klasser. Vi har plasserte kandidater og ikke plasserte kandidater. Spørsmålet er, hva er den relative andelen av disse to klassene? Har de omtrent samme balanse? Eller er det ene mye mer enn det andre? Det er noe du må ta en titt på når du har klassifiseringsproblemer. Så dette er et viktig skritt i vår EDA.
# Plot class balance
df["status"].value_counts(normalize=True).plot( kind="bar", xlabel="Class", ylabel="Relative Frequency", title="Class Balance"
);
Vår positive klasse 'plassert' teller for mer enn 65 % av våre observasjoner, og vår negative klasse 'Ikke plassert' er rundt 30%. Nå, hvis disse var super ubalanserte, som, hvis det var mer som 80 eller enda mer enn det, ville jeg si at dette er ubalanserte klasser. Og vi må jobbe litt for å sikre at modellen vår kommer til å fungere på riktig måte. Men dette er en grei balanse.
La oss lage en annen visualisering for å legge merke til sammenhengen mellom funksjonene våre og målet. La oss starte med de numeriske funksjonene.
Først vil vi se den individuelle fordelingen av funksjonene ved hjelp av et distribusjonsplot, og vi vil også se forholdet mellom de numeriske funksjonene og målet vårt ved å bruke et boksplott.
fig,ax=plt.subplots(5,2,figsize=(15,35))
for index,i in enumerate(df.select_dtypes("number").drop(columns="sl_no")): plt.suptitle("Visualizing Distribution of Numerical Columns Indivualy and by Class",size=20) sns.histplot(data=df, x=i, kde=True, ax=ax[index,0]) sns.boxplot(data=df, x='status', y=i, ax=ax[index,1]);
I første kolonne fra plottet vårt kan vi se at alle fordelingene følger en normalfordeling, og de fleste av kandidatens utdanningsprestasjoner ligger på mellom 60-80 %.
I den andre kolonnen har vi en dobbel boksplott med 'Placert'-klassen til høyre og deretter 'Not Placed'-klassen til venstre. For funksjonene 'etest_p' og 'mba_p' er det ikke mye forskjell i disse to distribusjonene fra et modellbyggende perspektiv. Det er en betydelig overlapping i fordelingen over klassene, så disse funksjonene vil ikke være en god prediktor for målet vårt. Når det gjelder resten av funksjonene, er det distinkte nok til å ta dem som potensielle gode prediktorer for målet vårt. La oss gå videre til de kategoriske trekkene. Og for å utforske dem, vil vi bruke et telleplot.
fig,ax=plt.subplots(7,2,figsize=(15,35))
for index,i in enumerate(df.select_dtypes("object").drop(columns="status")): plt.suptitle("Visualizing Count of Categorical Columns",size=20) sns.countplot(data=df,x=i,ax=ax[index,0]) sns.countplot(data=df,x=i,ax=ax[index,1],hue="status")
Ser vi på handlingen ser vi at vi har flere mannlige kandidater enn kvinner. Og de fleste av våre kandidater har ingen arbeidserfaring, men disse kandidatene ble ansatt flere enn de som hadde. Vi har kandidater som tok handel som sitt 'hsc'-kurs, og i tillegg til en undergrad, er kandidatene med naturvitenskapelig bakgrunn de nest høyeste i begge tilfeller.
En liten merknad om logistiske regresjonsmodeller, selv om de er for klassifisering, er de i samme gruppe som andre lineære modeller som lineær regresjon, og av den grunn, siden de begge er lineære modeller. Vi må også bekymre oss for spørsmålet om multikollinearitet. Så vi må lage en korrelasjonsmatrise, og så må vi plotte den ut i et varmekart. Vi ønsker ikke å se på alle funksjonene her, vi vil bare se på de numeriske funksjonene, og vi ønsker ikke å inkludere målet vårt. Siden hvis målet vårt korrelerer med noen av funksjonene våre, er det veldig bra.
corr = df.select_dtypes("number").corr()
# Plot heatmap of `correlation`
plt.title('Correlation Matrix')
sns.heatmap(corr, vmax=1, square=True, annot=True, cmap='GnBu');
Her er den lyseblå, som betyr liten eller ingen korrelasjon, og den mørkeblå, som vi har en høyere korrelasjon med. Så vi ønsker å være på utkikk etter de mørkeblå. Vi kan se en mørkeblå linje, en diagonal linje som går nedover midten av denne plottet. Det er funksjonene som er korrelert med dem selv. Og så ser vi noen mørke firkanter. Det betyr at vi har en haug med korrelasjoner mellom funksjoner.
I det siste trinnet i vår EDA må vi se etter høy-lav kardinalitet i de kategoriske funksjonene. Kardinalitet refererer til antall unike verdier i en kategorisk variabel. Høy kardinalitet betyr at kategoriske trekk har et stort antall unike verdier. Det er ikke noe eksakt antall unike verdier som gjør en funksjon høy kardinalitet. Men hvis verdien av det kategoriske trekket er unikt for nesten alle observasjoner, kan det vanligvis droppes.
# Check for high- and low-cardinality categorical features
df.select_dtypes("object").nunique() gender 2
ssc_b 2
hsc_b 2
hsc_s 3
degree_t 3
workex 2
specialisation 2
status 2
dtype: int64Jeg ser ingen kolonner der antallet unike verdier er én eller noe superhøyt. Men jeg tror det er en kategorisk type kolonne som vi mangler her. Og grunnen er at det ikke er kodet som et objekt, men som et heltall. 'sl_no'-kolonnen er ikke et heltall i den forstand vi kjenner. Disse kandidatene er rangert i en eller annen rekkefølge. Bare en unik navnelapp, og navnet er som en kategori, ikke sant? Så dette er en kategorisk variabel. Og den har ingen informasjon, så vi må droppe den.
df.drop(columns="sl_no", inplace=True)Funksjoner koding
Vi fullførte analysen vår, og det neste vi må gjøre er å kode våre kategoriske funksjoner, jeg vil bruke 'LabelEncoder'. Etikettkoding er en populær kodeteknikk for håndtering av kategoriske variabler. Ved å bruke denne teknikken tildeles hver etikett et unikt heltall basert på alfabetisk rekkefølge.
lb = LabelEncoder () cat_data = ['gender', 'ssc_b', 'hsc_b', 'hsc_s', 'degree_t', 'workex', 'specialisation', 'status']
for i in cat_data: df[i] = lb.fit_transform(df[i]) df.head()
Dele
Vi importerte og renset dataene våre. Vi har gjort litt utforskende dataanalyse, og nå må vi dele dataene våre. Vi har to typer delt: vertikal delt eller funksjonsmål og horisontalt delt eller togtestsett. La oss starte med det vertikale. Vi vil lage vår funksjonsmatrise 'X' og målvektoren 'y'. Målet vårt er «status». Våre funksjoner bør være alle kolonnene som er igjen i 'df'en.
#vertical split
target = "status"
X = df.drop(columns = target)
y = df[target]Modeller presterer generelt bedre når de har normaliserte data å trene med, så hva er normalisering? normalisering transformerer verdiene til flere variabler til et lignende område. Målet vårt er å normalisere variablene våre. Så deres verdiområder vil være fra 0 til 1. La oss gjøre det, og jeg vil bruke `StandardScaler.`
scaler = StandardScaler()
X = scaler.fit_transform(X)La oss nå gjøre de horisontale splitt- eller tog-testsettene. Vi må dele dataene våre (X og y) inn i trenings- og testsett ved hjelp av en randomisert tog-testdeling. testsettet vårt skal være 20 % av våre totale data. Og vi glemmer ikke å sette en random_state for reproduserbarhet.
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.2, random_state = 42 ) print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape) X_train shape: (172, 12)
y_train shape: (172,)
X_test shape: (43, 12)
y_test shape: (43,)Bygg en logistisk regresjonsmodell
Baseline
Så nå må vi begynne å bygge vår modell, og vi må begynne å bestille for å sette vår baseline. Husk at den typen problem vi har å gjøre med er et klassifiseringsproblem, og det er forskjellige beregninger for å evaluere klassifikasjonsmodeller. Den jeg vil fokusere på er nøyaktighetsscore.
Nå, hva er nøyaktighetspoengene? Nøyaktighetspoeng i maskinlæring er en evalueringsberegning som måler antall korrekte spådommer gjort av en modell til det totale antallet spådommer som er gjort. Vi beregner det ved å dele antall korrekte spådommer med det totale antallet spådommer. Så det betyr at nøyaktighetspoengene går mellom 0 og 1. Null er ikke bra. Det er der du ikke vil være, og en er perfekt. Så la oss ha det i bakhodet og husk at grunnlinjen er en modell som gir en prediksjon om og om igjen, uavhengig av hva observasjonen er, bare en gjetning for oss.
I vårt tilfelle har vi to klasser, plassert eller ikke. Så hvis vi bare kunne gi én spådom, hva ville vært vår eneste gjetning? Hvis du sa majoritetsklassen. Jeg synes det er fornuftig, ikke sant? Hvis vi bare kan ha én prediksjon, bør vi sannsynligvis velge den med de høyeste observasjonene i datasettet vårt. Så grunnlinjen vår vil bruke prosentandelen som majoritetsklassen viser seg i treningsdataene. Hvis modellen ikke slår denne grunnlinjen, tilfører ikke funksjonene verdifull informasjon for å klassifisere observasjonene våre.
Vi kan bruke 'value_counts'-metoden med 'normalize = True'-argumentet for å beregne grunnlinjenøyaktigheten:
acc_baseline = y_train.value_counts(normalize=True).max()
print("Baseline Accuracy:", round(acc_baseline, 2)) Baseline Accuracy: 0.68Vi kan se at vår grunnlinjenøyaktighet er 68 % eller 0.68 som en andel. Så for å legge til verdi for å være til nytte, ønsker vi å komme over dette tallet og komme nærmere en. Det er målet vårt, og la oss nå begynne å bygge vår modell.
Repetere
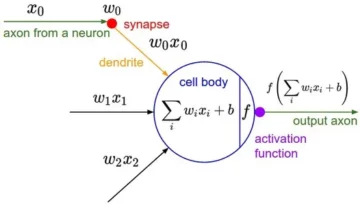
Nå er det på tide å bygge vår modell ved hjelp av logistisk regresjon. Vi skal bruke logistisk regresjon, men før vi gjør det, la oss snakke litt om hva logistisk regresjon er og hvordan det fungerer, og så kan vi gjøre kodetingene. Og for det, her har vi et lite rutenett.
Langs x-aksen, la oss si at jeg har p_grader til kandidater i datasettet vårt. Og når jeg beveger meg fra høyre til venstre, blir gradene høyere og høyere, og deretter langs Y-aksen har jeg de mulige klassene for plassering: null og én.

Så hvis vi skulle plotte ut datapunktene våre, hvordan ville det sett ut? Vår analyse viser at en kandidat med høy `p_degree` er mer sannsynlig å bli ansatt. Så, det vil sannsynligvis se omtrent slik ut, der kandidaten med en liten `p_degree` ville være nede på null. Og kandidaten med høy `p_degree` ville være oppe på en.

La oss nå si at vi ønsket å gjøre lineær regresjon med dette. La oss si at vi ønsket å tegne en linje.
Nå, hvis vi gjorde det, ville det skje at linjen ville bli plottet på en slik måte at den ville prøve å være så nær alle punktene som mulig. Og så ville vi nok ende opp med en linje som så omtrent slik ut. Vil dette være en god modell?

Ikke egentlig. Det som ville skje er uavhengig av p_graden til kandidaten, vi vil alltid få en slags verdi. Og det vil ikke hjelpe oss fordi tallene i denne sammenhengen ikke betyr noe. Dette klassifiseringsproblemet må enten være null eller én. Så det kommer ikke til å fungere på den måten.
På den annen side, fordi dette er en linje, hva om vi har en kandidat med en veldig lav p_grad? Plutselig er anslaget vårt et negativt tall. Og igjen, dette gir ingen mening. Det er ikke noe negativt tall som enten må være null eller én. Og på samme måte, hvis vi har en kandidat med veldig høy p_grad, kan jeg ha en positiv, noe over én. Og igjen, det gir ingen mening. Vi må enten ha en null eller en.

Så det vi ser her er noen alvorlige begrensninger for å bruke lineær regresjon for klassifisering. Så hva må vi gjøre? Vi må lage en modell som nummer én: ikke går under null eller over én, så den må være bundet mellom null og én. Og nummer to, uansett hva som kommer ut av den funksjonen, den ligningen vi lager, bør vi kanskje ikke behandle det som prediksjonen i seg selv, men som et skritt mot å lage vår endelige prediksjon.
Nå, la meg pakke ut det jeg nettopp sa, og la oss minne oss selv på at når vi gjør våre lineære regresjonsmodeller, ender vi opp med denne lineære ligningen, som er den enkleste formen. Og dette er den ligningen eller funksjonen som gir oss den rette linjen.

Det er en måte å binde den linjen mellom 0 og 1. Og det vi kan gjøre er å ta denne funksjonen som vi nettopp har laget og omslutte den i en annen funksjon, det som kalles en sigmoid-funksjon.

Så jeg skal ta den lineære ligningen vi nettopp hadde, og jeg skal krympe den ned i sigmoidfunksjonen og sette den som eksponentiell.

Det som skjer er at i stedet for å få en rett linje, får vi en linje som ser sånn ut. Den sitter fast ved en. Den kommer inn og snirkler seg ned. Da sitter den fast på null.

Akkurat, det er slik linjen ser ut, og vi kan se at vi har løst vårt første problem. Uansett hva vi får ut av denne funksjonen vil være mellom 0 og 1. I det andre trinnet vil vi ikke behandle det som kommer ut av denne ligningen som den ultimate prediksjonen. I stedet vil vi behandle det som en sannsynlighet.

Hva mener jeg? Det betyr at når jeg gjør en prediksjon, vil jeg få en flyttallverdi mellom 0 og 1. Og det jeg vil gjøre er å behandle det som sannsynligheten for at prediksjonen min tilhører den positive klassen.
Så jeg får en verdi opp til 0.9999. Jeg vil si at sannsynligheten for at denne kandidaten tilhører vår positive, plasserte klasse er 99%. Så jeg er nesten sikker på at den tilhører den positive klassen. Omvendt, hvis det er nede ved punkt 0.001 eller hva som helst, vil jeg si at dette tallet er lavt. Sannsynligheten for at denne spesielle observasjonen tilhører den positive, den plasserte klassen er nesten null. Og så, jeg skal si at den tilhører klasse null.
Så det gir mening for tall som er nær én eller nær null. Men du kan spørre deg selv, hva gjør jeg med andre verdier i mellom? Måten det fungerer på er at vi setter en avskjæringslinje rett ved 0.5, så enhver verdi jeg får under den linjen, setter jeg den til null, så min prediksjon er nei, og hvis den er over den linjen, hvis den er over punkt fem , Jeg vil sette dette i den positive klassen, min spådom er en.

Så nå har jeg en funksjon som gir meg en prediksjon mellom null og én, og jeg behandler det som en sannsynlighet. Og hvis den sannsynligheten er over 0.5 eller 50 %, sier jeg, ok, positiv klasse én. Og hvis det er under 50%, sier jeg, er det negativ klasse, null. Så det er måten logistisk regresjon fungerer på. Og nå forstår vi det, la oss kode det opp og tilpasse det. Jeg vil sette hyperparameteren 'max_iter' til 1000. Denne parameteren refererer til maksimalt antall iterasjoner for løserne å konvergere.
# Build model
model = LogisticRegression(max_iter=1000) # Fit model to training data
model.fit(X_train, y_train) LogisticRegression(max_iter=1000)Evaluere
Nå er det på tide å se hvordan modellen vår gjør det. Det er på tide å evaluere den logistiske regresjonsmodellen. Så la oss huske at denne gangen er ytelsesberegningen vi er interessert i nøyaktighetspoengsummen, og vi vil ha en nøyaktig. Og vi ønsker å slå grunnlinjen på 0.68. Modellnøyaktighet kan beregnes ved hjelp av funksjonen accuracy_score. Funksjonen krever to argumenter, de sanne etikettene og de predikerte etikettene.
acc_train = accuracy_score(y_train, model.predict(X_train))
acc_test = model.score(X_test, y_test) print("Training Accuracy:", round(acc_train, 2))
print("Test Accuracy:", round(acc_test, 2)) Training Accuracy: 0.9
Test Accuracy: 0.88Vi kan se treningsnøyaktigheten vår på 90 %. Det slår grunnlinjen. Vår testnøyaktighet var litt lavere med 88 %. Den slo også grunnlinjen og var veldig nær treningsnøyaktigheten vår. Så det er gode nyheter fordi det betyr at modellen vår ikke er overfitt eller noe.
Resultater av den logistiske regresjonsmodellen
Husk at med logistisk regresjon ender vi opp med disse endelige spådommene på null eller én. Men under den forutsigelsen er det en sannsynlighet for et flyttall mellom null eller én, og noen ganger kan det være nyttig å se hva disse sannsynlighetsestimatene er. La oss se på treningsspådommene våre, og la oss se på de fem første. 'Forutsi'-metoden forutsier målet for en umerket observasjon.
model.predict(X_train)[:5] array([0, 1, 1, 1, 1])Så det var de endelige spådommene, men hva er sannsynligheten bak dem? For å få dem må vi gjøre en litt annen kode. I stedet for å bruke 'prediksjonsmetoden' med modellen vår, vil jeg bruke 'predict_proba' med treningsdataene våre.
y_train_pred_proba = model.predict_proba(X_train)
print(y_train_pred_proba[:5]) [[0.92003219 0.07996781] [0.03202019 0.96797981] [0.00678421 0.99321579] [0.03889446 0.96110554] [0.00245525 0.99754475]]Vi kan se en slags nestet liste med to forskjellige kolonner i den. Kolonnen til venstre representerer sannsynligheten for at en kandidat ikke blir plassert eller vår negative klasse 'Ikke plassert'. Den andre kolonnen representerer den positive klassen 'Placert' eller sannsynligheten for at en kandidat blir plassert. Vi vil fokusere på den andre kolonnen. Hvis vi ser på det første sannsynlighetsestimatet riktig, kan vi se at dette er 0.07. Så siden det er under 50 %, sier modellen vår, er min prediksjon null. Og for de følgende spådommene kan vi se at alle er over 0.5, og det er derfor vår modell spådde en til slutt.
Nå ønsker vi å trekke ut funksjonsnavnene og viktigheten og sette dem i en serie. Og fordi vi trenger å vise funksjonens betydning som oddsforhold, må vi bare gjøre en liten matematisk transformasjon ved å ta eksponentiell av betydningen vår.
# Features names
features = ['gender', 'ssc_p', 'ssc_b', 'hsc_p', 'hsc_b', 'hsc_s', 'degree_p' ,'degree_t', 'workex', 'etest_p', 'specialisation', 'mba_p']
# Get importances
importances = model.coef_[0]
# Put importances into a Series
odds_ratios = pd.Series(np.exp(importances), index= features).sort_values()
# Review odds_ratios.head() mba_p 0.406590
degree_t 0.706021
specialisation 0.850301
hsc_b 0.876864
etest_p 0.877831
dtype: float64Før vi diskuterer oddsratioene og hva de er, la oss få dem på et horisontalt stolpediagram. La oss bruke pandaer til å lage plottet, og husk at vi skal se etter de fem største koeffisientene. Og vi ønsker ikke å bruke alle oddsratene. Så vi ønsker å bruke halen.
# Horizontal bar chart, five largest coefficients
odds_ratios.tail().plot(kind="barh")
plt.xlabel("Odds Ratio")
plt.ylabel("Feature")
plt.title("High Importance Features");
Nå vil jeg at du skal forestille deg en vertikal linje rett ved 5, og jeg vil begynne med å se på den. La oss snakke om hver av disse individuelt eller bare det første paret. Så la oss starte her med 'ssc_p', som refererer til 'videregående utdanningsprosent – 10. klasse'. Og vi kan se at oddsratioen er på 30. Nå, hva betyr det? Det betyr at hvis en kandidat har en høy 'ssc_p', er oddsen for plassering seks ganger større enn andre kandidater, alt annet likt. Så en annen måte å tenke på det er når kandidaten har `ssc_p`, øker sjansen for kandidatens rekruttering seks ganger.
Så ethvert oddsforhold over fem øker oddsen for at kandidater blir plassert. Og det er derfor vi har den vertikale linjen på fem. Og disse fem typene funksjoner er egenskaper som er mest forbundet med økt rekruttering. Så, det er hva oddsforholdet vårt er. Nå har vi sett på funksjonene som er mest forbundet med en økning i rekruttering. La oss se på funksjonene som er knyttet til det, nedgangen i rekruttering. Så nå er det på tide å se på de minste. Så i stedet for å se på halen, vil vi se på den.
odds_ratios.head().plot(kind="barh")
plt.xlabel("Odds Ratio")
plt.xlabel("Odds Ratio")
plt.ylabel("Feature")
plt.title("Low Importance Features");
Det første vi må se her er at merknaden på x-aksen er en eller under. Nå, hva betyr det? Så la oss ta en titt på vårt minste oddsforhold her. Det er mba_p som refererer til MBA-prosenten. Vi kan se at den er klar på ca 0.45. Nå, hva betyr det? Vel, forskjellen mellom 0.45 og 1 er 0.55. Greit? Og hva betyr det tallet? Det er mindre sannsynlighet for at kandidater med MBA rekrutteres med 55 %, alt annet likt. Greit? Så det reduserte sjansene for rekruttering med en faktor på 0.55 eller 55%. Og det er sant for alt her.
konklusjonen
Så hva lærte vi? Først, i den forberedte datafasen, lærte vi at vi jobber med klassifisering, nærmere bestemt binær klassifisering, ved hjelp av logistisk regresjon. Når det gjelder å utforske dataene, gjorde vi massevis av ting, men når det gjelder høydepunkter, så vi på klassebalansen, ikke sant? Andelen av våre positive og negative klasser. Så deler vi dataene våre.
Siden logistisk regresjon er en klassifiseringsmodell, lærte vi om en ny ytelsesmåling, nøyaktighetsscore. Nå går nøyaktighetspoengene mellom 0 og 1. Null er dårlig, og én er bra. Da vi itererte, lærte vi om logistisk regresjon. Det er en magisk måte, hvor du kan ta en lineær ligning, en rett linje, og sette den inn i en annen funksjon, en sigmoidfunksjon og en aktiveringsfunksjon, og få et sannsynlighetsestimat ut av det og gjøre det sannsynlighetsestimatet til prediksjon.
Til slutt lærte vi om oddsforholdet og måten vi kan tolke koeffisientene på for å se om en gitt funksjon vil øke oddsen for at vi har rekruttert en kandidat eller ikke.
Prosjektkildekode: https://github.com/SawsanYusuf/Campus-Recruitment.git
Mediene vist i denne artikkelen eies ikke av Analytics Vidhya og brukes etter forfatterens skjønn.
I slekt
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://www.analyticsvidhya.com/blog/2023/03/campus-recruitment-a-classification-problem-with-logistic-regression/
- :er
- $OPP
- 1
- 10
- 11
- 214
- 7
- 8
- 9
- a
- Om oss
- ovenfor
- akseptert
- nøyaktighet
- nøyaktig
- Aktivering
- Etter
- Alle
- Selv
- alltid
- analyse
- analytics
- Analytics Vidhya
- og
- En annen
- Leilighet
- ER
- argument
- argumenter
- rundt
- Artikkel
- AS
- assosiert
- At
- delta
- Axis
- bakgrunn
- dårlig
- Balansere
- Bar
- Baseline
- I utgangspunktet
- BE
- vakker
- fordi
- før du
- begynne
- bak
- være
- under
- Bedre
- mellom
- binde
- Bit
- bloggathon
- Blå
- bundet
- Eske
- bygge
- Bygning
- Bunch
- virksomhet
- Handelshøyskole
- by
- beregne
- beregnet
- ring
- som heter
- Campus
- CAN
- kandidat
- kandidater
- Karriere
- saken
- saker
- Kategori
- Sentre
- sjanse
- egenskaper
- Figur
- sjekk
- Velg
- klasse
- klasser
- klassifisering
- Klassifisere
- fjerne
- Lukke
- nærmere
- kode
- Koding
- Høyskole
- Kolonne
- kolonner
- Handel
- kommunisere
- Bekymring
- konklusjon
- tilkobling
- inneholder
- kontekst
- kontinuerlig
- konvergerer
- Kjerne
- Bedriftens
- Korrelasjon
- korrelasjoner
- kunne
- Par
- kurs
- skape
- opprettet
- Kutt
- mørk
- dato
- dataanalyse
- datapunkter
- datavitenskap
- datasett
- håndtering
- redusere
- utplassert
- beskrivelse
- detaljer
- gJORDE
- forskjell
- forskjellig
- skjønn
- diskutere
- Vise
- distinkt
- distribusjon
- Distribusjoner
- ikke
- gjør
- dollar
- ikke
- dobbelt
- ned
- Drop
- droppet
- hver enkelt
- Kunnskap
- pedagogisk
- enten
- engasjerende
- nok
- entry-level
- anslag
- estimater
- etc
- Eter (ETH)
- evaluere
- evaluering
- Selv
- alt
- eksamen
- Unntatt
- forventet
- erfaring
- Forklar
- leting
- Utforskende dataanalyse
- utforske
- Utforske
- eksponentiell
- trekke ut
- faktorer
- Trekk
- Egenskaper
- hunner
- filet
- Filer
- slutt~~POS=TRUNC
- Endelig
- Først
- passer
- flytende
- Fokus
- fokusering
- følge
- etter
- Til
- skjema
- RAMME
- Frekvens
- fra
- funksjon
- Kjønn
- generelt
- få
- få
- gå
- Gi
- gir
- Go
- mål
- Mål
- Går
- skal
- god
- graf
- større
- Grid
- Gruppe
- Gruppens
- hånd
- Håndtering
- skje
- skjer
- Ha
- hjelpe
- nyttig
- her.
- Høy
- høyere
- høyest
- striper
- Ansetter
- Horisontal
- Hvordan
- Hvordan
- HTTPS
- i
- JEG VIL
- Ideer
- ubalanse
- importere
- betydning
- viktig
- in
- inkludere
- Øke
- økt
- øker
- indeks
- india
- individuelt
- individuelt
- info
- informasjon
- i stedet
- interessert
- introdusere
- Introduksjon
- involvert
- innebærer
- utstedelse
- IT
- gjentakelser
- Hold
- Type
- Vet
- Etiketten
- etiketter
- stor
- største
- Siste
- LÆRE
- lært
- læring
- bibliotekene
- Bibliotek
- lett
- i likhet med
- Sannsynlig
- begrensninger
- linje
- Liste
- lite
- laste
- Se
- ser ut som
- så
- ser
- UTSEENDE
- Lot
- Lav
- maskin
- maskinlæring
- laget
- Flertall
- gjøre
- GJØR AT
- Making
- mange
- math
- matematiske
- matplotlib
- Matrix
- maksimal
- MBA
- midler
- målinger
- Media
- Møt
- Minne
- metode
- metrisk
- Metrics
- Middle
- kunne
- millioner
- millioner dollar
- tankene
- mangler
- modell
- modeller
- mer
- mest
- flytte
- navn
- navn
- Trenger
- behov
- negativ
- Ny
- nyheter
- neste
- normal
- bærbare
- Antall
- tall
- følelsesløs
- objekt
- odds
- of
- tilbudt
- Okay
- on
- ONE
- rekkefølge
- Annen
- eide
- pandaer
- parameter
- del
- Spesielt
- prosent
- perfekt
- utføre
- ytelse
- forestillinger
- person
- perspektiv
- fase
- Sted
- plato
- Platon Data Intelligence
- PlatonData
- Point
- poeng
- Populær
- stillinger
- positiv
- mulig
- potensiell
- forutsi
- spådd
- forutsi
- prediksjon
- Spådommer
- Predictor
- spår
- Forbered
- forberedt
- forbereder
- pen
- pris
- sannsynlighet
- sannsynligvis
- Problem
- problemer
- prosjekt
- publisert
- sette
- spørsmål
- randomisert
- område
- rangert
- ratio
- Lese
- klar
- ekte
- virkelige verden
- grunnen til
- nylig
- poster
- rekruttering
- refererer
- Uansett
- regresjon
- forholdet
- forbli
- husker
- godtgjørelse
- representerer
- Krever
- REST
- Resultater
- anmeldelse
- Sa
- lønn
- samme
- sier
- Skole
- Vitenskap
- scikit lære
- sjøfødt
- Årstid
- Sekund
- synes
- forstand
- Serien
- alvorlig
- Tjenester
- sett
- sett
- syv
- flere
- Form
- bør
- vist
- Viser
- signifikant
- siden
- SIX
- litt annerledes
- liten
- minste
- So
- løse
- noen
- noe
- kilde
- kildekoden
- Sourcing
- spesielt
- splittet
- firkanter
- Standard
- Begynn
- status
- Trinn
- Steps
- rett
- Strategi
- Studenter
- slik
- plutselig
- Super
- TAG
- Ta
- ta
- Talent
- Snakk
- Target
- vilkår
- test
- Det
- De
- deres
- Dem
- seg
- Disse
- ting
- ting
- Tenk
- Tredje
- tid
- ganger
- til
- ton
- Totalt
- mot
- Tog
- Kurs
- Transformation
- transformere
- behandle
- sant
- SVING
- typer
- ultimate
- forstå
- unik
- universitet
- lastet opp
- us
- bruk
- bruke
- vanligvis
- Verdifull
- Verdifull informasjon
- verdi
- Verdier
- variabler
- ulike
- visualisering
- ønsket
- Vei..
- VI VIL
- Hva
- Hva er
- om
- hvilken
- HVEM
- vil
- med
- Arbeid
- arbeidsflyt
- arbeid
- virker
- verden
- ville
- ville gitt
- X
- Young
- deg selv
- zephyrnet
- null