Dette er et felles innlegg skrevet av AWS og Voxel51. Voxel51 er selskapet bak FiftyOne, åpen kildekode-verktøysettet for å bygge høykvalitets datasett og datasynsmodeller.
Et detaljhandelsselskap bygger en mobilapp for å hjelpe kunder med å kjøpe klær. For å lage denne appen trenger de et datasett av høy kvalitet som inneholder klesbilder, merket med forskjellige kategorier. I dette innlegget viser vi hvordan du kan gjenbruke et eksisterende datasett via datarensing, forbehandling og forhåndsmerking med en nullskuddsklassifiseringsmodell i Femtien, og justere disse etikettene med Amazon SageMaker Ground Truth.
Du kan bruke Ground Truth og FiftyOne for å fremskynde datamerkingsprosjektet. Vi illustrerer hvordan du sømløst bruker de to applikasjonene sammen for å lage merket datasett av høy kvalitet. For vårt eksempelbruk jobber vi med Fashion200K datasett, utgitt på ICCV 2017.
Løsningsoversikt
Ground Truth er en fullstendig selvbetjent og administrert datamerkingstjeneste som gir dataforskere, maskinlæringsingeniører (ML) og forskere mulighet til å bygge datasett av høy kvalitet. Femtien by voxel51 er et verktøysett med åpen kildekode for å kurere, visualisere og evaluere datasynsdatasett slik at du kan trene og analysere bedre modeller ved å akselerere brukstilfellene dine.
I de følgende delene viser vi hvordan du gjør følgende:
- Visualiser datasettet i FiftyOne
- Rengjør datasettet med filtrering og bildededuplisering i FiftyOne
- Forhåndsmerke de rensede dataene med nullskuddsklassifisering i FiftyOne
- Merk det mindre kurerte datasettet med Ground Truth
- Injiser merkede resultater fra Ground Truth i FiftyOne og se gjennom merkede resultater i FiftyOne
Bruk saksoversikt
Anta at du eier et detaljhandelsselskap og ønsker å bygge en mobilapplikasjon for å gi personlige anbefalinger for å hjelpe brukere med å bestemme hva de skal ha på seg. Dine potensielle brukere ser etter et program som forteller dem hvilke klesplagg i skapet deres som fungerer godt sammen. Du ser en mulighet her: Hvis du kan identifisere gode antrekk, kan du bruke dette til å anbefale nye plagg som komplementerer klærne en kunde allerede eier.
Du ønsker å gjøre ting så enkelt som mulig for sluttbrukeren. Ideelt sett trenger noen som bruker applikasjonen din bare å ta bilder av klærne i garderoben, og ML-modellene dine arbeider med sin magi bak kulissene. Du kan trene en generell modell eller finjustere en modell til hver brukers unike stil med en form for tilbakemelding.
Først må du imidlertid identifisere hvilken type klær brukeren fanger. Er det en skjorte? Et par bukser? Eller noe annet? Tross alt vil du sannsynligvis ikke anbefale et antrekk som har flere kjoler eller flere hatter.
For å løse denne første utfordringen, ønsker du å generere et treningsdatasett som består av bilder av ulike klesartikler med ulike mønstre og stiler. For å prototype med et begrenset budsjett, vil du starte opp med et eksisterende datasett.
For å illustrere og lede deg gjennom prosessen i dette innlegget bruker vi Fashion200K-datasettet som ble utgitt på ICCV 2017. Det er et etablert og godt sitert datasett, men det er ikke direkte egnet for din brukssituasjon.
Selv om klær er merket med kategorier (og underkategorier) og inneholder en rekke nyttige etiketter som er hentet fra de originale produktbeskrivelsene, er ikke dataene systematisk merket med mønster- eller stilinformasjon. Målet ditt er å gjøre dette eksisterende datasettet om til et robust treningsdatasett for klesklassifiseringsmodellene dine. Du må rense dataene, utvide merkeskjemaet med stiletiketter. Og du vil gjøre det raskt og med så lite forbruk som mulig.
Last ned dataene lokalt
Først laster du ned women.tar zip-filen og labels-mappen (med alle undermapper) ved å følge instruksjonene i Fashion200K datasett GitHub repository. Etter at du har pakket ut dem begge, lag en overordnet katalog fashion200k, og flytt etikettene og kvinnemappene inn i denne. Heldigvis er disse bildene allerede beskåret til avgrensningsboksene for objektdeteksjon, slik at vi kan fokusere på klassifisering i stedet for å bekymre oss for objektdeteksjon.
Til tross for "200K" i navnet, inneholder kvinnekatalogen vi hentet ut 338,339 200 bilder. For å generere det offisielle Fashion300,000K-datasettet, gjennomsøkte datasettets forfattere mer enn XNUMX XNUMX produkter på nettet, og bare produkter med beskrivelser som inneholder mer enn fire ord klarte seg. For våre formål, der produktbeskrivelsen ikke er avgjørende, kan vi bruke alle de gjennomsøkte bildene.
La oss se på hvordan disse dataene er organisert: i kvinnemappen er bildene ordnet etter artikkeltype på toppnivå (skjørt, topper, bukser, jakker og kjoler) og artikkeltype underkategori (bluser, t-skjorter, langermede) topper).
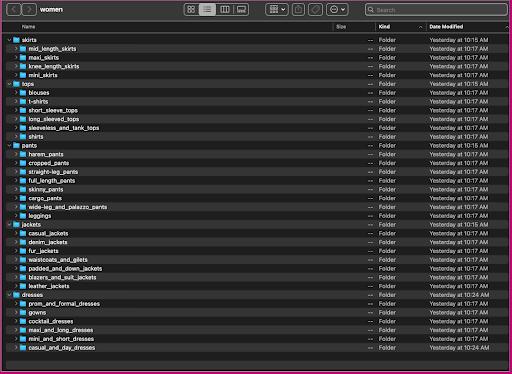
Innenfor underkategorikatalogene er det en underkatalog for hver produktoppføring. Hver av disse inneholder et variabelt antall bilder. Underkategorien cropped_pants inneholder for eksempel følgende produktoppføringer og tilhørende bilder.

Etikettmappen inneholder en tekstfil for hver artikkeltype på toppnivå, for både tog- og testdeling. Innenfor hver av disse tekstfilene er det en egen linje for hvert bilde, som spesifiserer den relative filbanen, en poengsum og tagger fra produktbeskrivelsen.

Fordi vi omformåler datasettet, kombinerer vi alle tog- og testbildene. Vi bruker disse til å generere et applikasjonsspesifikt datasett av høy kvalitet. Etter at vi har fullført denne prosessen, kan vi dele det resulterende datasettet tilfeldig i nye tog- og testdelinger.
Injiser, vis og kurater et datasett i FiftyOne
Hvis du ikke allerede har gjort det, installer åpen kildekode FiftyOne ved å bruke pip:
En beste praksis er å gjøre det i et nytt virtuelt (venv eller conda) miljø. Importer deretter de relevante modulene. Importer basisbiblioteket, fiftyone, FiftyOne Brain, som har innebygde ML-metoder, FiftyOne Zoo, hvorfra vi vil laste inn en modell som vil generere nullbildeetiketter for oss, og ViewField, som lar oss filtrere data i vårt datasett:
Du vil også importere glob- og os Python-modulene, som vil hjelpe oss å jobbe med baner og mønstermatch over kataloginnhold:
Nå er vi klare til å laste inn datasettet i FiftyOne. Først lager vi et datasett som heter fashion200k og gjør det vedvarende, som lar oss lagre resultatene av beregningsintensive operasjoner, så vi trenger bare å beregne nevnte mengder én gang.
Vi kan nå iterere gjennom alle underkategorikataloger og legge til alle bildene i produktkatalogene. Vi legger til en FiftyOne-klassifiseringsetikett til hver prøve med feltnavnet artikkeltype, fylt ut av bildets artikkelkategori på øverste nivå. Vi legger også til både kategori- og underkategoriinformasjon som tagger:
På dette tidspunktet kan vi visualisere datasettet vårt i FiftyOne-appen ved å starte en økt:

Vi kan også skrive ut et sammendrag av datasettet i Python ved å kjøre print(dataset):
Vi kan også legge til taggene fra labels katalog til prøvene i datasettet vårt:
Når du ser på dataene, blir et par ting klart:
- Noen av bildene er ganske kornete, med lav oppløsning. Dette er sannsynligvis fordi disse bildene ble generert ved å beskjære innledende bilder i avgrensningsbokser for objektdeteksjon.
- Noen klær bæres av en person, og noen er fotografert på egen hånd. Disse detaljene er innkapslet av
viewpointeiendom. - Mange av bildene av det samme produktet er veldig like, så i det minste til å begynne med, inkludert mer enn ett bilde per produkt, gir kanskje ikke mye prediktiv kraft. For det meste er det første bildet av hvert produkt (ender på
_0.jpeg) er den reneste.
Til å begynne med vil vi kanskje trene vår klesstilklassifiseringsmodell på en kontrollert undergruppe av disse bildene. For dette formål bruker vi høyoppløselige bilder av produktene våre, og begrenser vårt syn til ett representativt utvalg per produkt.
Først filtrerer vi ut bildene med lav oppløsning. Vi bruker compute_metadata() metode for å beregne og lagre bildebredde og høyde, i piksler, for hvert bilde i datasettet. Vi bruker deretter FiftyOne ViewField for å filtrere ut bilder basert på minimum tillatte bredde- og høydeverdier. Se følgende kode:

Denne høyoppløselige undergruppen har i underkant av 200,000 XNUMX prøver.
Fra denne visningen kan vi opprette en ny visning i datasettet vårt som inneholder kun ett representativt utvalg (høyst) for hvert produkt. Vi bruker ViewField nok en gang, mønstertilpasning for filstier som slutter med _0.jpeg:
La oss se en tilfeldig blandet rekkefølge av bilder i dette undersettet:

Fjern overflødige bilder i datasettet
Denne visningen inneholder 66,297 19 bilder, eller litt over XNUMX % av det originale datasettet. Når vi ser på utsikten ser vi imidlertid at det er mange veldig like produkter. Å beholde alle disse kopiene vil sannsynligvis bare øke kostnadene for merking og modellopplæring, uten merkbart forbedring av ytelsen. La oss i stedet kvitte oss med nesten duplikatene for å lage et mindre datasett som fortsatt pakker det samme trykket.
Fordi disse bildene ikke er eksakte duplikater, kan vi ikke sjekke for pikselmessig likhet. Heldigvis kan vi bruke FiftyOne-hjernen til å hjelpe oss med å rense datasettet vårt. Spesielt vil vi beregne en innebygging for hvert bilde - en lavere dimensjonal vektor som representerer bildet - og deretter se etter bilder hvis innebyggingsvektorer er nær hverandre. Jo nærmere vektorene er, jo mer like bildene.
Vi bruker en CLIP-modell for å generere en 512-dimensjonal innebyggingsvektor for hvert bilde, og lagrer disse innebyggingene i feltinnbyggingene på prøvene i datasettet vårt:
Deretter beregner vi nærheten mellom embeddings, ved hjelp av cosinus-likhet, og hevder at alle to vektorer hvis likhet er større enn en eller annen terskel sannsynligvis vil være nær duplikater. Cosinuslikhetsskårene ligger i området [0, 1], og ser på dataene, ser en terskelskåre på terskel=0.5 ut til å være omtrent riktig. Igjen, dette trenger ikke være perfekt. Noen få nesten dupliserte bilder vil sannsynligvis ikke ødelegge vår prediksjonsevne, og å kaste noen få ikke-dupliserte bilder påvirker ikke modellens ytelse vesentlig.
Vi kan se de påståtte duplikatene for å bekrefte at de faktisk er overflødige:

Når vi er fornøyd med resultatet og tror at disse bildene faktisk er nesten duplikater, kan vi velge én prøve fra hvert sett med lignende prøver å beholde, og ignorere de andre:
Nå har denne visningen 3,729 200 bilder. Ved å rense dataene og identifisere en høykvalitets undergruppe av Fashion300,000K-datasettet, lar FiftyOne oss begrense fokuset vårt fra mer enn 4,000 98 bilder til i underkant av 90, noe som representerer en reduksjon på XNUMX %. Å bruke innebygginger for å fjerne nesten dupliserte bilder alene førte til at vårt totale antall bilder ble vurdert med mer enn XNUMX %, med liten eller ingen effekt på noen modeller som skulle trenes på disse dataene.
Før vi forhåndsmerker dette undersettet, kan vi bedre forstå dataene ved å visualisere innbyggingene vi allerede har beregnet. Vi kan bruke FiftyOne-hjernens innebygde compute_visualization()-metoden, som bruker UMAP-teknikken (uniform manifold approksimation) for å projisere de 512-dimensjonale innebyggingsvektorene inn i todimensjonalt rom slik at vi kan visualisere dem:
Vi åpner en ny Innstøpningspanel i FiftyOne-appen og fargelegging etter artikkeltype, og vi kan se at disse innbyggingene grovt sett koder for en forestilling om artikkeltype (blant annet!).

Nå er vi klare til å forhåndsmerke disse dataene.
Ved å inspisere disse svært unike, høyoppløselige bildene, kan vi generere en anstendig innledende liste over stiler som skal brukes som klasser i vår pre-merking nullbildeklassifisering. Målet vårt med å forhåndsmerke disse bildene er ikke nødvendigvis å merke hvert bilde riktig. Målet vårt er heller å gi et godt utgangspunkt for menneskelige kommentatorer, slik at vi kan redusere merkingstid og -kostnader.
Vi kan deretter instansiere en nullskuddsklassifiseringsmodell for denne applikasjonen. Vi bruker en CLIP-modell, som er en generell modell trent på både bilder og naturlig språk. Vi instansierer en CLIP-modell med tekstmeldingen "Klær i stilen", slik at gitt et bilde, vil modellen vise klassen som "Klær i stilen [klasse]" passer best for. CLIP er ikke opplært på detaljhandel eller motespesifikke data, så dette vil ikke være perfekt, men det kan spare deg for merking og merknadskostnader.
Vi bruker deretter denne modellen på vår reduserte delmengde og lagrer resultatene i en article_style felt:
Ved å lansere FiftyOne-appen igjen, kan vi visualisere bildene med disse forutsagte stiletikettene. Vi sorterer etter prediksjonstillit, slik at vi ser de mest sikre stilspådommene først:

Vi kan se at de høyeste spådommene ser ut til å være for "jersey", "dyretrykk", "polkaprikker" og "bokstaver". Dette er fornuftig, fordi disse stilene er relativt forskjellige. Det virker også som for det meste, de spådde stiletikettene er nøyaktige.
Vi kan også se på stilspådommene med lavest tillit:

For noen av disse bildene er den passende stilkategorien i den oppgitte listen, og klesplagget er feil merket. Det første bildet i rutenettet, for eksempel, skal tydeligvis være "kamuflasje" og ikke "chevron". I andre tilfeller passer produktene imidlertid ikke pent inn i stilkategoriene. Kjolen i det andre bildet i andre rad, for eksempel, er ikke akkurat "stripete", men gitt de samme merkingsalternativene, kan en menneskelig annotator også ha vært i konflikt. Når vi bygger ut datasettet vårt, må vi bestemme om vi skal fjerne kanttilfeller som disse, legge til nye stilkategorier eller utvide datasettet.
Eksporter det endelige datasettet fra FiftyOne
Eksporter det endelige datasettet med følgende kode:
Vi kan eksportere et mindre datasett, for eksempel 16 bilder, til mappen 200kFashionDatasetExportResult-16Images. Vi lager en Ground Truth-justeringsjobb ved å bruke den:
Last opp det reviderte datasettet, konverter etikettformatet til Ground Truth, last opp til Amazon S3 og lag en manifestfil for justeringsjobben
Vi kan konvertere etikettene i datasettet for å matche utdatamanifestskjema av en Ground Truth bounding box-jobb, og last opp bildene til en Amazon enkel lagringstjeneste (Amazon S3) bøtte for å lansere en Justeringsjobb for Ground Truth:
Last opp manifestfilen til Amazon S3 med følgende kode:
Lag korrigerte etiketter med Ground Truth
For å kommentere dataene dine med stiletiketter ved å bruke Ground Truth, fullfør de nødvendige trinnene for å starte en markeringsboksmerkingsjobb ved å følge prosedyren som er skissert i Komme i gang med Ground Truth guide med datasettet i samme S3-bøtte.
- På SageMaker-konsollen oppretter du en Ground Truth-merkejobb.
- Sett Angi datasettplassering å være manifestet som vi skapte i de foregående trinnene.

- Angi en S3-bane for Output datasettplassering.
- Til IAM-rolle, velg Angi en egendefinert IAM-rolle ARN, skriv deretter inn rollen ARN.

- Til Oppgavekategori, velg Bilde og velg Avgrensende boks.
- Velg neste.
- på Arbeidere seksjon, velg typen arbeidsstyrke du vil bruke.
Du kan velge en arbeidsstyrke gjennom Amazon Mekanisk Turk, tredjepartsleverandører eller din egen private arbeidsstyrke. For mer informasjon om arbeidsstyrkealternativene dine, se Opprett og administrer arbeidsstyrker. - Expand Visningsalternativer for eksisterende etiketter og velg Jeg vil vise eksisterende etiketter fra datasettet for denne jobben.
- Til Etikettattributt navn, velg navnet fra manifestet som tilsvarer etikettene du vil vise for justering.
Du vil bare se etikettattributtnavn for etiketter som samsvarer med oppgavetypen du valgte i de foregående trinnene. - Angi etikettene manuelt for Merkeverktøy for avgrensningsboks.
 Etikettene må inneholde de samme etikettene som brukes i det offentlige datasettet. Du kan legge til nye etiketter. Følgende skjermbilde viser hvordan du kan velge arbeidere og konfigurere verktøyet for merkejobben din.
Etikettene må inneholde de samme etikettene som brukes i det offentlige datasettet. Du kan legge til nye etiketter. Følgende skjermbilde viser hvordan du kan velge arbeidere og konfigurere verktøyet for merkejobben din.
- Velg Forhåndsvisning for å forhåndsvise bildet og originale merknader.
Vi har nå opprettet en merkejobb i Ground Truth. Etter at jobben vår er fullført, kan vi laste de nylig genererte merkede dataene inn i FiftyOne. Ground Truth produserer utdata i et Ground Truth-utdatamanifest. For mer informasjon om utdatamanifestfilen, se Bounding Box Job Output. Følgende kode viser et eksempel på dette utdatamanifestformatet:
Gjennomgå merkede resultater fra Ground Truth i FiftyOne
Etter at jobben er fullført, last ned utdatamanifestet for merkejobben fra Amazon S3.

Les utdatamanifestfilen:
Opprett et FiftyOne-datasett og konverter manifestlinjene til prøver i datasettet:
Du kan nå se merket data av høy kvalitet fra Ground Truth i FiftyOne.

konklusjonen
I dette innlegget viste vi hvordan du kan bygge datasett av høy kvalitet ved å kombinere kraften til Femtien by voxel51, et åpen kildekodeverktøy som lar deg administrere, spore, visualisere og kuratere datasettet ditt, og Ground Truth, en datamerkingstjeneste som lar deg effektivt og nøyaktig merke datasettene som kreves for opplæring av ML-systemer ved å gi tilgang til flere bygde -i oppgavemaler og tilgang til en mangfoldig arbeidsstyrke gjennom Mechanical Turk, tredjepartsleverandører eller din egen private arbeidsstyrke.
Vi oppfordrer deg til å prøve ut denne nye funksjonaliteten ved å installere en FiftyOne-forekomst og bruke Ground Truth-konsollen for å komme i gang. For å lære mer om Ground Truth, se Etikettdata, Vanlige spørsmål om Amazon SageMaker-datamerking, og AWS maskinlæringsblogg.
Koble til Maskinlæring og AI-fellesskap hvis du har spørsmål eller tilbakemeldinger!
Bli med i FiftyOne-fellesskapet!
Bli med de tusenvis av ingeniører og dataforskere som allerede bruker FiftyOne for å løse noen av de mest utfordrende problemene innen datasyn i dag!
Om forfatterne
Shalendra Chhabra er for tiden sjef for produktadministrasjon for Amazon SageMaker Human-in-the-Loop (HIL) Services. Tidligere inkuberte og ledet Shalendra Language and Conversational Intelligence for Microsoft Teams Meetings, var EIR hos Amazon Alexa Techstars Startup Accelerator, VP of Product and Marketing hos Diskuter.io, leder for produkt og markedsføring hos Clipboard (kjøpt av Salesforce), og Lead Product Manager hos Swype (kjøpt av Nuance). Totalt har Shalendra bidratt til å bygge, sende og markedsføre produkter som har berørt mer enn en milliard liv.
Jacob Marks er en maskinlæringsingeniør og utviklerevangelist hos Voxel51, hvor han hjelper til med å bringe åpenhet og klarhet til verdens data. Før han begynte i Voxel51, grunnla Jacob en oppstart for å hjelpe nye musikere med å koble sammen og dele kreativt innhold med fans. Før det jobbet han hos Google X, Samsung Research og Wolfram Research. I et tidligere liv var Jacob en teoretisk fysiker, og fullførte sin doktorgrad ved Stanford, hvor han undersøkte kvantefaser av materie. På fritiden liker Jacob å klatre, løpe og lese science fiction-romaner.
Jason Corso er medgründer og administrerende direktør for Voxel51, hvor han styrer strategien for å bidra til å bringe åpenhet og klarhet til verdens data gjennom avansert fleksibel programvare. Han er også professor i robotikk, elektroteknikk og informatikk ved University of Michigan, hvor han fokuserer på banebrytende problemer i skjæringspunktet mellom datasyn, naturlig språk og fysiske plattformer. På fritiden liker Jason å tilbringe tid med familien, lese, være i naturen, spille brettspill og alle slags kreative aktiviteter.
Brian Moore er medgründer og CTO for Voxel51, hvor han leder teknisk strategi og visjon. Han har en doktorgrad i elektroteknikk fra University of Michigan, hvor forskningen hans var fokusert på effektive algoritmer for maskinlæringsproblemer i stor skala, med spesiell vekt på datasynsapplikasjoner. På fritiden liker han badminton, golf, fotturer og lek med tvillingene sine Yorkshire Terrier.
Zhuling Bai er programvareutviklingsingeniør hos Amazon Web Services. Hun jobber med å utvikle distribuerte systemer i stor skala for å løse maskinlæringsproblemer.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- Minting the Future med Adryenn Ashley. Tilgang her.
- Kjøp og selg aksjer i PRE-IPO-selskaper med PREIPO®. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Om oss
- akselerere
- akselerer
- akselerator
- adgang
- nøyaktig
- nøyaktig
- ervervet
- Aktiviteter
- legge til
- legge
- adresse
- justert
- Justering
- Etter
- en gang til
- AI
- Alexa
- algoritmer
- Alle
- tillater
- alene
- allerede
- også
- Amazon
- amazon alexa
- Amazon SageMaker
- Amazon SageMaker Ground Truth
- Amazon Web Services
- blant
- an
- analysere
- og
- dyr
- noen
- app
- Søknad
- søknader
- Påfør
- hensiktsmessig
- ER
- anordnet
- Artikkel
- artikler
- AS
- assosiert
- At
- forfattere
- borte
- AWS
- basen
- basert
- BE
- fordi
- bli
- vært
- før du
- bak
- Bak scenen
- være
- tro
- BEST
- Bedre
- mellom
- Milliarder
- borde
- Board Games
- BEIN
- Bootstrap
- både
- Eske
- bokser
- Brain
- Break
- bringe
- brakte
- budsjett
- bygge
- Bygning
- innebygd
- men
- kjøpe
- by
- CAN
- fange
- saken
- saker
- kategorier
- Kategori
- konsernsjef
- utfordre
- utfordrende
- sjekk
- Velg
- klarhet
- klasse
- klasser
- klassifisering
- Rengjøring
- fjerne
- klart
- kunde
- klatring
- Lukke
- nærmere
- klær
- Klær
- Med-grunnlegger
- kode
- kombinere
- kombinere
- Selskapet
- Kompletter
- fullføre
- fullført
- Beregn
- datamaskin
- informatikk
- Datamaskin syn
- Datasynsapplikasjoner
- selvtillit
- trygg
- Koble
- hensyn
- Består
- Konsoll
- inneholder
- innhold
- innhold
- kontrolleres
- conversational
- konvertere
- Kjerne
- Korrigert
- riktig
- tilsvarer
- Kostnad
- Kostnader
- skape
- opprettet
- Kreativ
- Credentials
- CTO
- kuratert
- kuratering
- I dag
- skikk
- kunde
- Kunder
- Kutt
- skjærekant
- dato
- datasett
- bestemme
- demonstrere
- Denim
- dybde
- beskrivelse
- detaljer
- Gjenkjenning
- Utvikler
- utvikle
- Utvikling
- forskjellig
- direkte
- kataloger
- Vise
- distinkt
- distribueres
- distribuerte systemer
- diverse
- do
- ikke
- Hund
- gjør
- gjort
- ikke
- DOT
- ned
- nedlasting
- duplikater
- e
- hver enkelt
- lett
- Edge
- effekt
- effektiv
- effektivt
- elektroteknikk
- embedding
- Emery
- vekt
- anvender
- bemyndiger
- innkapslet
- oppmuntre
- slutt
- ingeniør
- Ingeniørarbeid
- Ingeniører
- Enter
- Miljø
- likestilling
- avgjørende
- etablert
- Eter (ETH)
- evaluere
- evangelist
- nøyaktig
- eksempel
- eksisterende
- eksportere
- ganske
- familie
- fans
- tilbakemelding
- Noen få
- Fiction
- felt
- Felt
- filet
- Filer
- filtrere
- filtrering
- slutt~~POS=TRUNC
- Først
- passer
- fleksibel
- Fokus
- fokuserte
- fokuserer
- etter
- Til
- skjema
- format
- Heldigvis
- Stiftet
- fire
- Gratis
- fra
- fullt
- funksjonalitet
- Games
- generell
- generere
- generert
- få
- GitHub
- Gi
- gitt
- mål
- golf
- god
- større
- Grid
- Ground
- Gruppe
- veilede
- lykkelig
- Ha
- he
- hode
- høyde
- hjelpe
- hjulpet
- nyttig
- hjelper
- her.
- høykvalitets
- høy oppløsning
- høyest
- svært
- vandreturer
- hans
- holder
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- menneskelig
- i
- IAM
- ID
- identifisere
- identifisering
- ids
- if
- bilde
- bilder
- Påvirkning
- importere
- bedre
- in
- I andre
- Inkludert
- feil
- inkubert
- informasjon
- innledende
- i utgangspunktet
- installere
- installere
- f.eks
- i stedet
- instruksjoner
- Intelligens
- kryss
- inn
- IT
- DET ER
- jersey
- Jobb
- sammenføyning
- ledd
- JSON
- bare
- Hold
- holde
- Etiketten
- merking
- etiketter
- Språk
- storskala
- lansere
- lansere
- føre
- Fører
- LÆRE
- læring
- minst
- Led
- venstre
- Lar
- Bibliotek
- Life
- i likhet med
- Sannsynlig
- BEGRENSE
- Begrenset
- linje
- linjer
- Liste
- oppføring
- oppføringer
- lite
- Bor
- laste
- Se
- ser
- Lot
- Lav
- maskin
- maskinlæring
- laget
- magi
- gjøre
- GJØR AT
- administrer
- fikk til
- ledelse
- leder
- mange
- kart
- marked
- Marketing
- Match
- matchende
- materielt
- Saken
- Kan..
- mekanisk
- Media
- møter
- Meta
- metadata
- metode
- metoder
- Michigan
- Microsoft
- Microsoft-team
- kunne
- minimum
- ML
- Mobil
- Mobilapp
- modell
- modeller
- Moduler
- mer
- mest
- flytte
- mye
- flere
- musikere
- må
- navn
- oppkalt
- navn
- Naturlig
- Naturlig språk
- Natur
- Nær
- nødvendigvis
- nødvendig
- Trenger
- behov
- Ny
- merkbart
- Forestilling
- nå
- Nuance
- Antall
- objekt
- Objektdeteksjon
- gjenstander
- of
- offisiell
- on
- gang
- ONE
- på nett
- bare
- åpen
- åpen kildekode
- Drift
- Opportunity
- alternativer
- or
- Organisert
- original
- OS
- Annen
- andre
- vår
- ut
- skissert
- produksjon
- enn
- egen
- eier
- Pakninger
- sammen
- del
- Spesielt
- Past
- banen
- Mønster
- mønstre
- perfekt
- ytelse
- person
- Personlig
- Faser av saken
- fysisk
- plukke
- Bilder
- PLEID
- Plain
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- Point
- befolket
- mulig
- Post
- makt
- praksis
- spådd
- prediksjon
- Spådommer
- Forhåndsvisning
- forrige
- tidligere
- Skrive ut
- Før
- privat
- sannsynligvis
- problemer
- prosess
- Produkt
- produktledelse
- Produktsjef
- Produkter
- Professor
- prosjekt
- eiendom
- prospektive
- prototype
- gi
- forutsatt
- gi
- offentlig
- punsj
- formål
- Python
- Quantum
- spørsmål
- raskt
- område
- heller
- Lesning
- klar
- anbefaler
- anbefalinger
- redusere
- Redusert
- reduksjon
- relativt
- utgitt
- relevant
- fjerne
- representant
- representerer
- påkrevd
- forskning
- forskere
- oppløsning
- begrense
- resultere
- resulterende
- Resultater
- detaljhandel
- retur
- anmeldelse
- Kvitt
- ikke sant
- robotikk
- robust
- Rolle
- omtrent
- RAD
- ødelegge
- rennende
- sagemaker
- Sa
- Salesforce
- samme
- Samsung
- Spar
- Scener
- Vitenskap
- Science Fiction
- forskere
- Resultat
- sømløst
- Sekund
- Seksjon
- seksjoner
- se
- synes
- synes
- valgt
- forstand
- separat
- tjeneste
- Tjenester
- Session
- sett
- Del
- hun
- bør
- Vis
- Viser
- JA
- lignende
- Enkelt
- mindre
- So
- Software
- programvareutvikling
- LØSE
- noen
- Noen
- noe
- Rom
- bruke
- utgifter
- splittet
- spagaten
- stanford
- Begynn
- startet
- Start
- oppstart
- oppstartsakselerator
- state-of-the-art
- Steps
- Still
- lagring
- oppbevare
- Strategi
- stil
- SAMMENDRAG
- Støttes
- sikker
- Systemer
- Ta
- Oppgave
- lag
- Teknisk
- Techstars
- forteller
- maler
- test
- enn
- Det
- De
- deres
- Dem
- deretter
- teoretiske
- Der.
- Disse
- de
- ting
- Tenk
- tredjeparts
- denne
- tusener
- terskel
- Gjennom
- Kaster
- tid
- til
- sammen
- verktøy
- verktøykasse
- topp
- øverste nivå
- Topper
- Totalt
- berørt
- spor
- Tog
- trent
- Kurs
- Transform
- Åpenhet
- sant
- Sannhet
- SVING
- to
- typen
- typer
- etter
- forstå
- unik
- universitet
- University of Michigan
- Oppdater
- us
- bruke
- bruk sak
- brukt
- Bruker
- Brukere
- ved hjelp av
- Verdier
- variasjon
- ulike
- leverandører
- verifisere
- veldig
- av
- Se
- virtuelle
- syn
- visualisere
- ønsker
- var
- we
- web
- webtjenester
- VI VIL
- var
- Hva
- når
- om
- hvilken
- Wikipedia
- vil
- med
- innenfor
- uten
- Dame
- ord
- Arbeid
- arbeidet
- arbeidere
- arbeidsstyrke
- virker
- Verdens
- bekymring
- ville
- skrive
- X
- du
- Din
- zephyrnet
- Zip
- ZOO