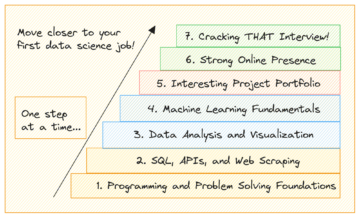
Datarensing er et veldig viktig og kritisk trinn i ditt datavitenskapelige prosjekt. Suksessen til maskinmodellen avhenger av hvordan du forhåndsbehandler dataene. Hvis du undervurderer og hopper over forbehandlingen av datasettet ditt, vil modellen ikke fungere godt, og du vil miste mye tid på å søke for å forstå hvorfor den ikke fungerer så bra som du forventer.
I det siste begynte jeg å lage jukseark for å få fart på mine datavitenskapelige aktiviteter, spesielt et sammendrag med det grunnleggende om datarensing. I dette innlegget og jukse ark, skal jeg vise fem forskjellige aspekter som kjennetegner forbehandlingstrinnene i ditt datavitenskapelige prosjekt.

I dette juksearket, går vi fra å oppdage og håndtere manglende data, håndtere duplikater og finne løsninger på duplikater, uteliggerdeteksjon, etikettkoding og one-hot-encoding av kategoriske funksjoner, til transformasjoner, som MinMax-normalisering og standardnormalisering. Dessuten utnytter denne guiden metodene som tilbys av tre av de mest populære Python-bibliotekene, Pandas, Scikit-Learn og Seaborn for å vise plott.
Å lære disse python-triksene vil hjelpe deg med å trekke ut mer informasjon som mulig fra datasettet, og følgelig vil maskinlæringsmodellen kunne yte bedre ved å lære fra en ren og forhåndsbehandlet input.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://www.kdnuggets.com/2023/02/data-cleaning-python-cheat-sheet.html?utm_source=rss&utm_medium=rss&utm_campaign=data-cleaning-with-python-cheat-sheet
- a
- I stand
- Aktiviteter
- og
- aspekter
- Grunnleggende
- begynte
- Bedre
- karakter
- Rengjøring
- Følgelig
- skape
- kritisk
- dato
- datavitenskap
- håndtering
- avhenger
- Gjenkjenning
- forskjellig
- visning
- ikke
- duplikater
- forvente
- exploits
- trekke ut
- Egenskaper
- finne
- fra
- Go
- skal
- veilede
- Håndtering
- hjelpe
- Hvordan
- HTTPS
- viktig
- in
- informasjon
- inngang
- IT
- KDnuggets
- Etiketten
- læring
- bibliotekene
- taper
- Lot
- maskin
- maskinlæring
- metoder
- mangler
- modell
- mer
- mest
- Mest populær
- pandaer
- Spesielt
- utføre
- plato
- Platon Data Intelligence
- PlatonData
- Populær
- mulig
- Post
- prosjekt
- forutsatt
- Python
- Vitenskap
- scikit lære
- sjøfødt
- søker
- Vis
- Solutions
- fart
- Standard
- Trinn
- Steps
- suksess
- slik
- SAMMENDRAG
- De
- Grunnleggende
- tre
- tid
- til
- transformasjoner
- triks
- forstå
- vil
- Arbeid
- ville
- Din
- zephyrnet