I dag bruker hundretusenvis av kunder datainnsjøer for analyser og maskinlæring. Dataingeniører må imidlertid rense og forberede disse dataene før de kan brukes. De underliggende dataene må være nøyaktige og nye for at kunden skal kunne ta sikre forretningsbeslutninger. Ellers mister dataforbrukere tilliten til dataene og tar suboptimale eller feilaktige beslutninger. Det er en vanlig oppgave for dataingeniører å vurdere om dataene er nøyaktige og nyere eller ikke. I dag finnes det ulike datakvalitetsverktøy. Vanlige datakvalitetsverktøy krever imidlertid vanligvis manuelle prosesser for å overvåke datakvaliteten.
AWS Glue Data Quality er en forhåndsvisningsfunksjon av AWS Lim som måler og overvåker datakvaliteten på Amazon enkel lagringstjeneste (Amazon S3) datainnsjøer og i AWS Glue extract, transform and load (ETL) jobber. Dette er en åpen forhåndsvisningsfunksjon, så den er allerede aktivert i kontoen din i tilgjengelige regioner. Du kan enkelt definere og måle datakvalitetskontrollene i AWS Glue Studio-konsollen uten å skrive koder. Det forenkler opplevelsen din av å administrere datakvalitet.
Dette innlegget er del 2 av en firepostserie for å forklare hvordan AWS Glue Data Quality fungerer. Sjekk ut forrige innlegg i denne serien:
I dette innlegget viser vi hvordan du lager en AWS Glue-jobb som måler og overvåker datakvaliteten til en datapipeline. Vi viser også hvordan du kan iverksette tiltak basert på datakvalitetsresultatene.
Løsningsoversikt
La oss ta for oss et eksempel på bruk der en dataingeniør må bygge en datapipeline for å innta dataene fra en råsone til en kurert sone i en datainnsjø. Som dataingeniør er en av hovedoppgavene dine – sammen med å trekke ut, transformere og laste inn data – å validere datakvaliteten. Identifisering av datakvalitetsproblemer på forhånd hjelper deg med å forhindre å plassere dårlige data i den kurerte sonen og unngå vanskelige hendelser med datakorrupsjon.
I dette innlegget lærer du hvordan du enkelt setter opp innebygd og skikk datavalideringssjekker i AWS Glue-jobben din for å forhindre at dårlige data ødelegger nedstrøms data av høy kvalitet.
Datasettet som brukes for dette innlegget er syntetisk generert; følgende skjermbilde viser et eksempel på dataene.

Sett opp ressurser med AWS CloudFormation
Dette innlegget inkluderer en AWS skyformasjon mal for et raskt oppsett. Du kan se gjennom og tilpasse den for å passe dine behov.
CloudFormation-malen genererer følgende ressurser:
- En Amazon Simple Storage Service (Amazon S3) bøtte (
gluedataqualitystudio-*). - Følgende prefikser og objekter i S3-bøtten:
datalake/raw/customer/customer.csvdatalake/curated/customer/scripts/sparkHistoryLogs/temporary/
- AWS identitets- og tilgangsadministrasjon (IAM) brukere, roller og retningslinjer. IAM-rollen (
GlueDataQualityStudio-*) har tillatelse til å lese og skrive fra S3-bøtten. - AWS Lambda funksjoner og IAM-policyer som kreves av disse funksjonene for å opprette og slette denne stabelen.
Gjør følgende for å opprette ressursene dine:
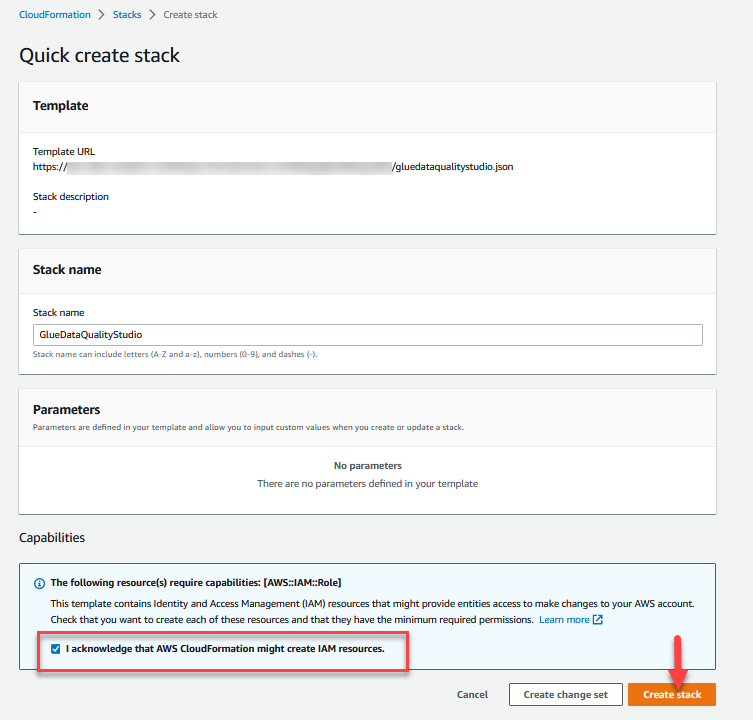
- Logg deg på AWS CloudFormation-konsoll i
us-east-1Region. - Velg Start Stack:

- Plukke ut Jeg erkjenner at AWS CloudFormation kan skape IAM-ressurser.
- Velg Lag stabel og vent til trinnet for å lage stabelen er fullført.
Implementer løsningen
For å begynne å konfigurere løsningen, fullfør følgende trinn:
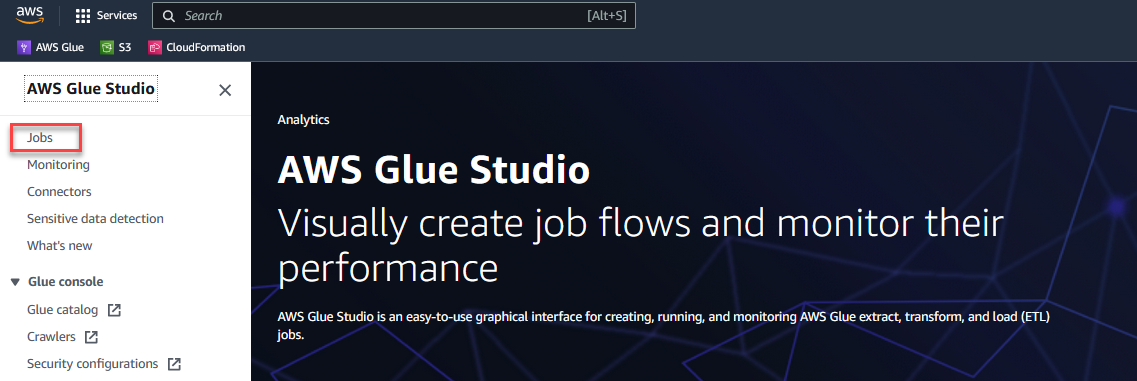
- På AWS Glue Studio-konsoll, velg Jobb i navigasjonsruten.
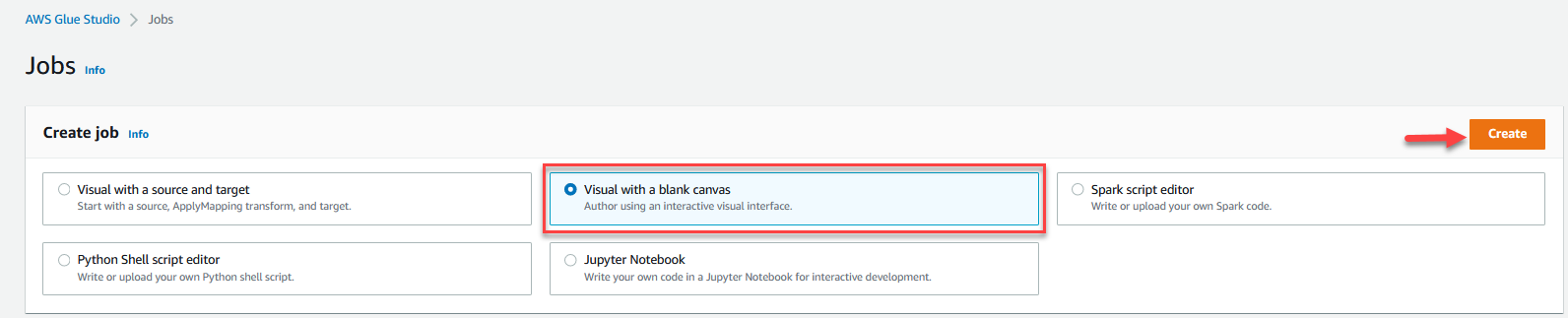
- Plukke ut Visuelt med et tomt lerret Og velg Opprett.
- Velg jobbdetaljer fanen for å konfigurere jobben.
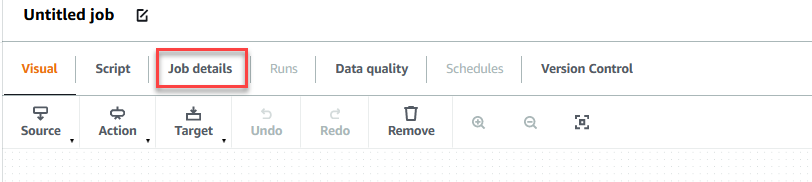
- Til Navn, Tast inn
GlueDataQualityStudio. - Til IAM-rolle, velg rollen som begynner med
GlueDataQualityStudio-*. - Til Lim versjon, velg Lim 3.0.
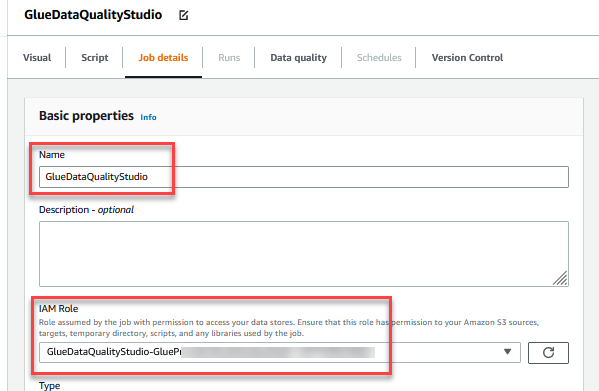
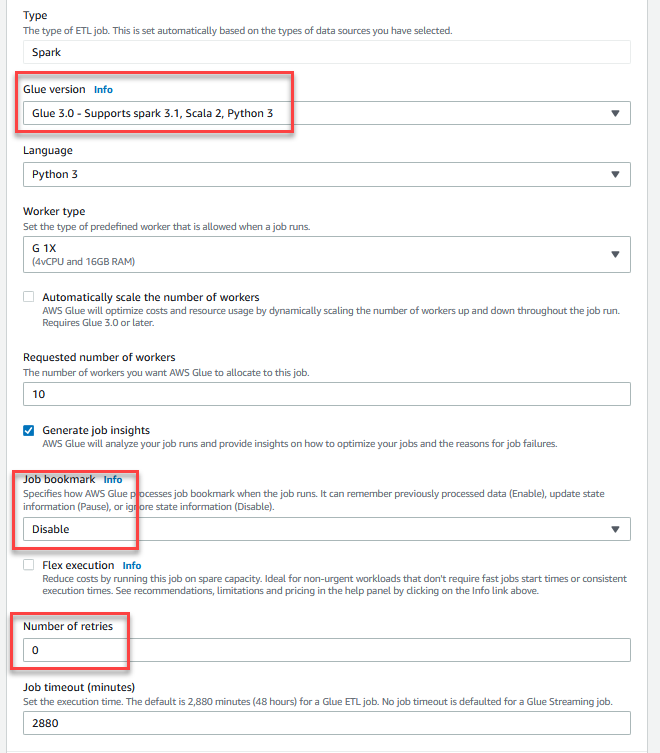
- Til Jobbmerke, velg Deaktiver. Dette lar deg kjøre denne jobben flere ganger med samme input-datasett.
- Til Antall nye forsøk, Tast inn
0.
- på Avanserte egenskaper seksjonen, oppgi S3-bøtten opprettet av CloudFormation-malen (starter med
gluedataqualitystudio-*).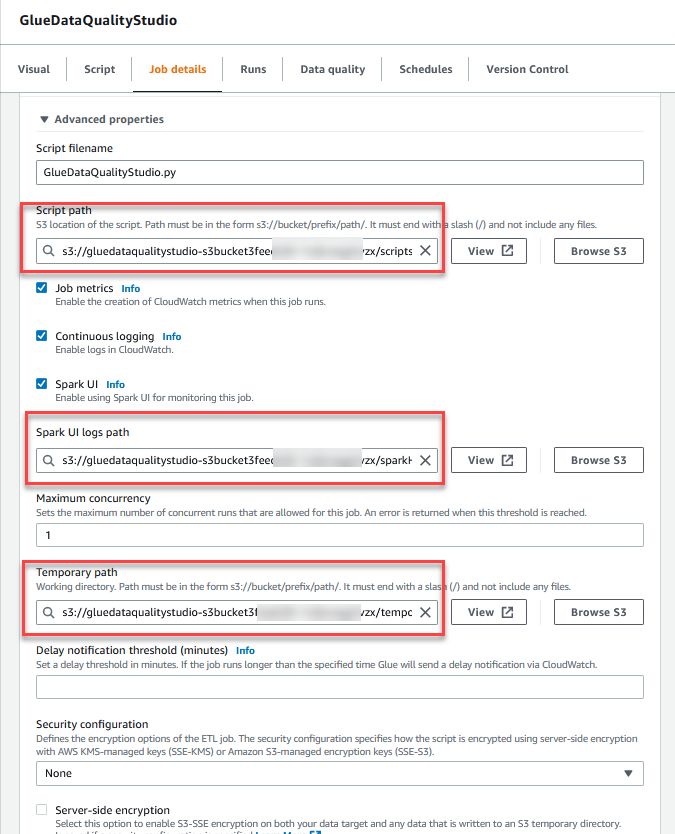
- Velg Spar.
- Etter at jobben er lagret, velg Visual fanen og på kilde meny, velg Amazon S3.
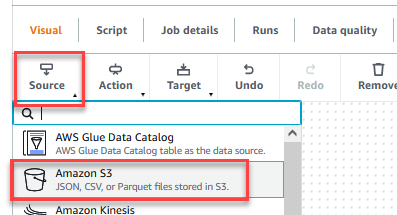
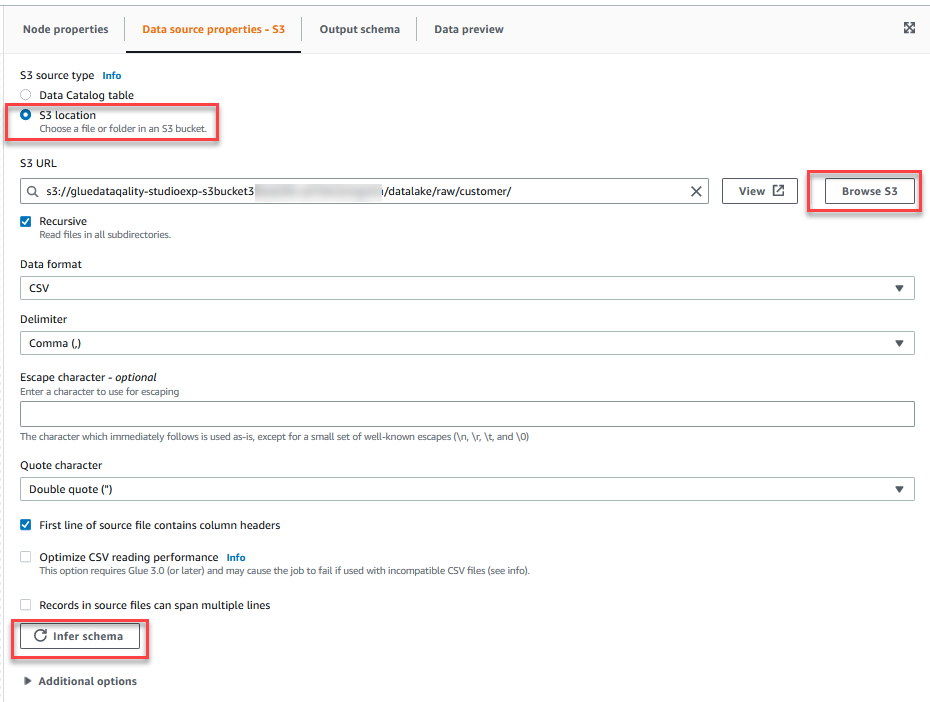
- På Datakildeegenskaper - S3 fanen, for S3 kildetype, plukke ut S3 beliggenhet.
- Velg Bla gjennom S3 og naviger til prefiks
/datalake/raw/customer/i S3-bøtta som starter medgluedataqualitystudio-*. - Velg Utlede skjema.
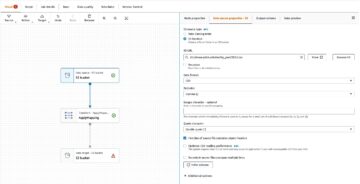
- På Handling meny, velg Evaluer datakvalitet.
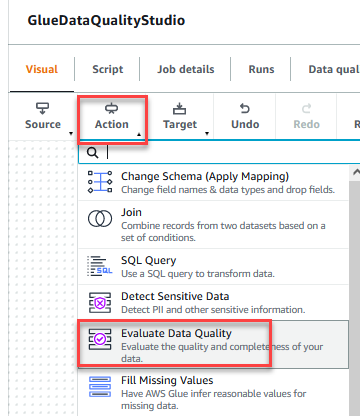
- Velg Evaluer datakvalitet node.
På Transform fanen, kan du nå begynne å bygge datakvalitetsregler. Den første regelen du oppretter er å sjekke omCustomer_IDer unik og ikke null ved å brukeisPrimaryKeyregel. - På Regeltyper fanen av DQDL-regelbygger, søk etter
isprimarykeyog velg plusstegnet.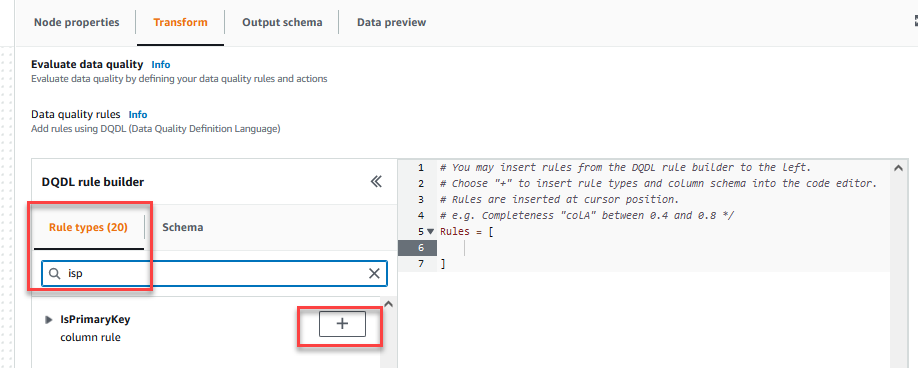
- På Skjema fanen av DQDL-regelbygger, velg plusstegnet ved siden av
Customer_ID. - Slett i regeleditoren
id.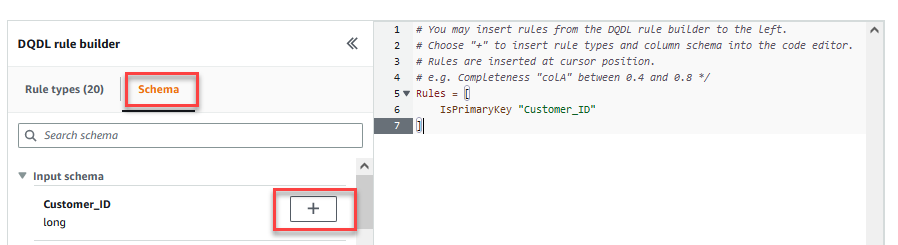
Den neste regelen vi legger til kontrollerer atFirst_Namekolonneverdien er tilstede for alle radene. - Du kan også legge inn datakvalitetsreglene direkte i regeleditoren. Legg til et komma (,) og skriv inn
IsComplete "First_Name",etter den første regelen.
Deretter legger du til en egendefinert regel for å bekrefte at ingen rad eksisterer utenTelephoneorEmail. - Skriv inn følgende egendefinerte regel i regelredigeringsprogrammet:

Evaluer datakvalitet-funksjonen gir handlinger for å administrere resultatet av en jobb basert på jobbkvalitetsresultatene. - Velg dette innlegget Feil jobb når datakvaliteten svikter Og velg Mislykket jobb uten å laste inn mål dato handlinger. I Utdatainnstilling for datakvalitet delen velger Bla gjennom S3 og naviger til prefiks
dqresultsi S3-bøtta som starter medgluedataqualitystudio-*.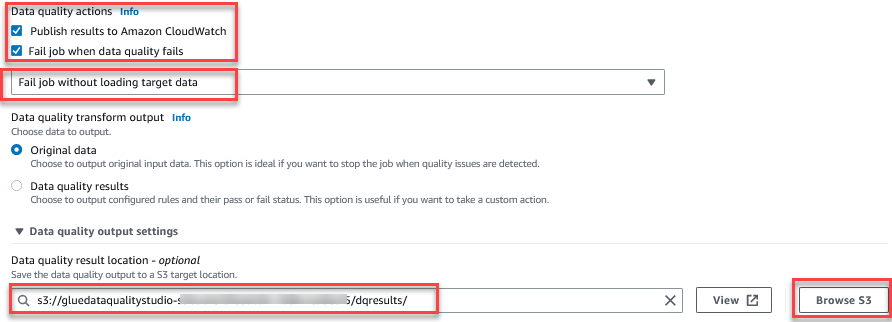
- På Target meny, velg Amazon S3.
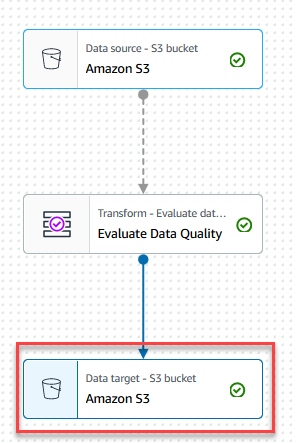
- Velg Datamål – S3-bøtte node.
- På Egenskaper for datamål - S3 fanen, for dannet, velg parkett, Og for Komprimeringstype, velg Snappy.
- Til S3 Målplassering, velg Bla gjennom S3 og naviger til prefikset
/datalake/curated/customer/i S3-bøtta som starter medgluedataqualitystudio-*.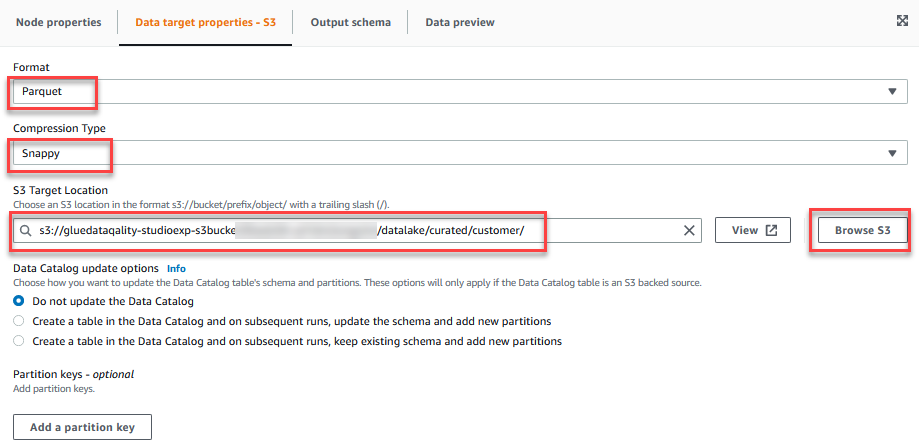
- Velg Spar, velg deretter Kjør.
 Du kan se jobbkjøringsdetaljene på fanen Kjøringer. I vårt eksempel mislykkes jobben med feilmeldingen "AssertionError: Jobben mislyktes på grunn av sviktende DQ-regler for node: ."
Du kan se jobbkjøringsdetaljene på fanen Kjøringer. I vårt eksempel mislykkes jobben med feilmeldingen "AssertionError: Jobben mislyktes på grunn av sviktende DQ-regler for node: ."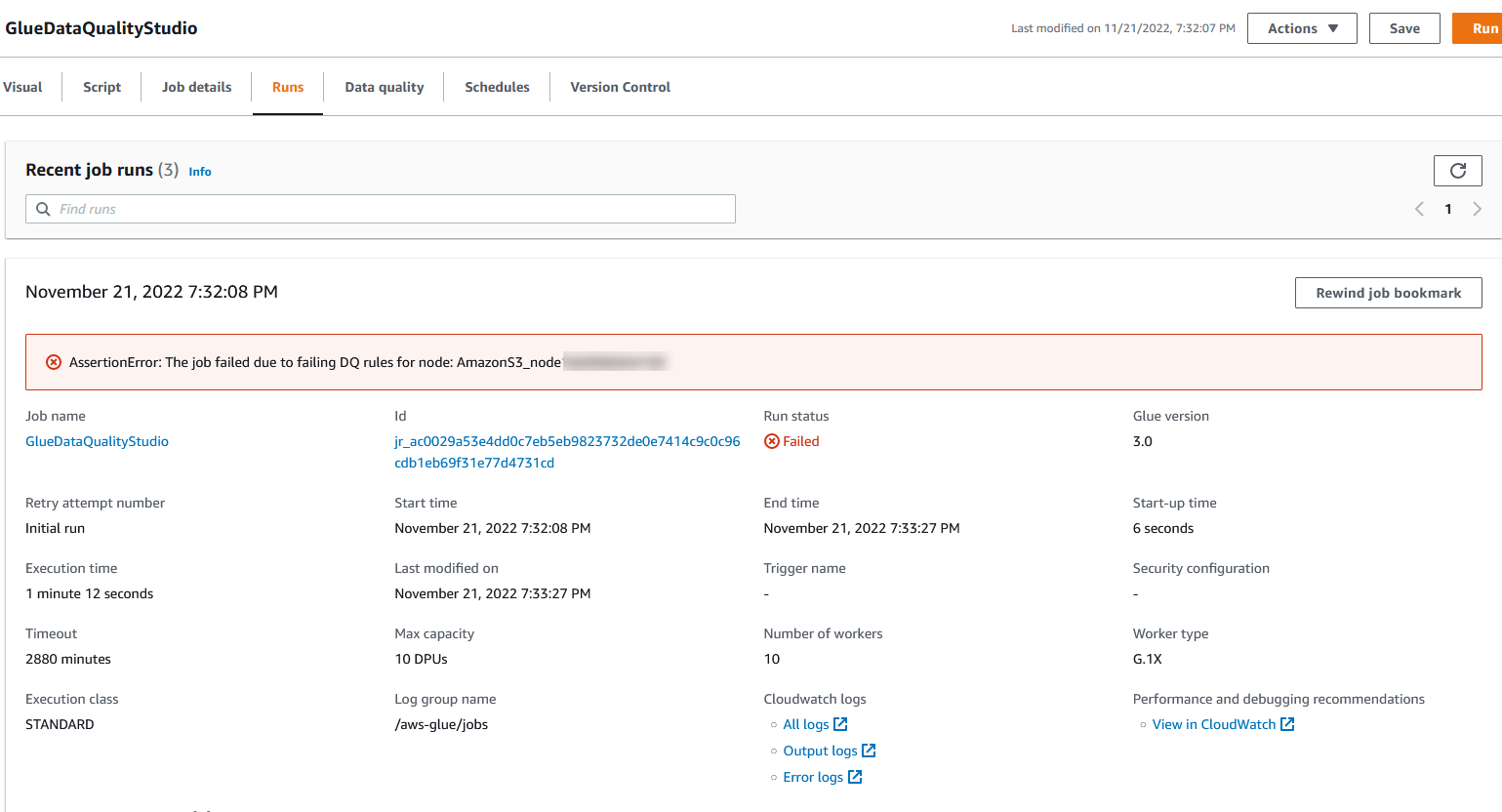 Du kan se gjennom datakvalitetsresultatet på Datakvalitet-fanen. I vårt eksempel mislyktes den tilpassede datakvalitetsvalideringen fordi en av radene i datasettet hadde nr
Du kan se gjennom datakvalitetsresultatet på Datakvalitet-fanen. I vårt eksempel mislyktes den tilpassede datakvalitetsvalideringen fordi en av radene i datasettet hadde nr TelephoneorEmailverdi. Evaluere datakvalitetsresultater skrives også til S3-bøtten i JSON-format basert på datakvalitetsresultatplasseringsparameteren til noden.
Evaluere datakvalitetsresultater skrives også til S3-bøtten i JSON-format basert på datakvalitetsresultatplasseringsparameteren til noden. - naviger til
dqresultsprefiks under S3-skuffen startergluedataqualitystudio-*. Du vil se at datakvalitetsresultatet er partisjonert etter dato.
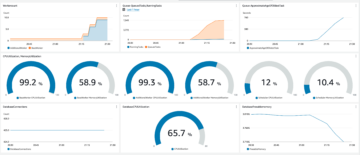
Følgende er utdataene til JSON-filen. Du kan bruke denne filutgangen til å bygge egendefinerte dashbord for datakvalitetsvisualisering.

Du kan også overvåke Evaluer datakvalitet node gjennom Amazon CloudWatch beregninger og angi alarmer for å sende varsler om datakvalitetsresultater. For å lære mer om hvordan du setter opp CloudWatch-alarmer, se Bruker Amazon CloudWatch-alarmer.
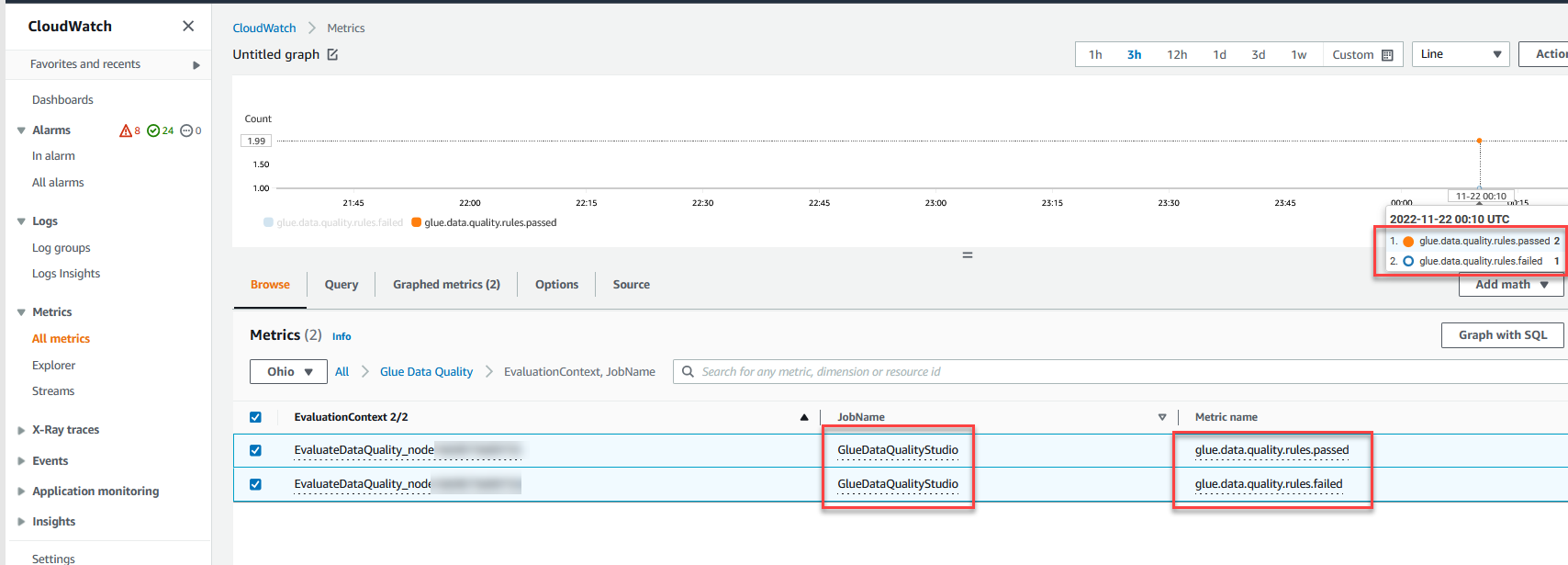
Rydd opp
For å unngå fremtidige kostnader og for å rydde opp i ubrukte roller og retningslinjer, slett ressursene du opprettet:
- Slett
GlueDataQualityStudiojobben du opprettet som en del av dette innlegget. - På AWS CloudFormation-konsollen sletter du
GlueDataQualityStudiostable.
konklusjonen
AWS Glue Data Quality tilbyr en enkel måte å måle og overvåke datakvaliteten til din ETL-pipeline. I dette innlegget lærte du hvordan du tar nødvendige handlinger basert på datakvalitetsresultatene, noe som hjelper deg å opprettholde høye datastandarder og ta sikre forretningsbeslutninger.
For å lære mer om AWS Glue Data Quality, sjekk ut dokumentasjonen:
Om forfatterne
 Deenbandhu Prasad er senior analytiker hos AWS, og spesialiserer seg på big data-tjenester. Han brenner for å hjelpe kunder med å bygge moderne dataarkitektur på AWS Cloud. Han har hjulpet kunder i alle størrelser med å implementere løsninger for dataadministrasjon, datavarehus og datainnsjø.
Deenbandhu Prasad er senior analytiker hos AWS, og spesialiserer seg på big data-tjenester. Han brenner for å hjelpe kunder med å bygge moderne dataarkitektur på AWS Cloud. Han har hjulpet kunder i alle størrelser med å implementere løsninger for dataadministrasjon, datavarehus og datainnsjø.
 Yannis Mentekidis er en Senior Software Development Engineer i AWS Glue-teamet.
Yannis Mentekidis er en Senior Software Development Engineer i AWS Glue-teamet.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/getting-started-with-aws-glue-data-quality-for-etl-pipelines/
- 1
- 100
- 7
- a
- Om oss
- adgang
- Logg inn
- nøyaktig
- anerkjenne
- Handling
- handlinger
- Etter
- Alle
- tillater
- allerede
- Amazon
- analytics
- og
- arkitektur
- AWS
- AWS skyformasjon
- AWS Lim
- dårlig
- dårlige data
- basert
- fordi
- før du
- Stor
- Store data
- bygge
- Bygning
- virksomhet
- saken
- avgifter
- sjekk
- Sjekker
- Velg
- Cloud
- Kolonne
- Felles
- fullføre
- trygg
- Vurder
- Konsoll
- Forbrukere
- Korrupsjon
- skape
- opprettet
- skaperverket
- kuratert
- skikk
- kunde
- Kunder
- tilpasse
- dato
- Data Lake
- Dataledelse
- Dato
- avgjørelser
- detaljer
- Utvikling
- direkte
- dokumentasjon
- lett
- redaktør
- emalje
- ingeniør
- Ingeniører
- Enter
- feil
- Eter (ETH)
- evaluere
- eksempel
- finnes
- erfaring
- Forklar
- trekke ut
- Mislyktes
- mislykkes
- Trekk
- filet
- Først
- etter
- format
- fra
- funksjoner
- framtid
- generert
- genererer
- få
- hjulpet
- hjelpe
- hjelper
- Høy
- høykvalitets
- Hvordan
- Hvordan
- Men
- HTML
- HTTPS
- Hundrevis
- identifisering
- Identitet
- iverksette
- in
- inkluderer
- inngang
- saker
- IT
- Jobb
- Jobb
- JSON
- nøkkel
- innsjø
- LÆRE
- lært
- læring
- laste
- lasting
- plassering
- taper
- maskin
- maskinlæring
- vedlikeholde
- gjøre
- administrer
- ledelse
- administrerende
- håndbok
- måle
- målinger
- Meny
- melding
- Metrics
- kunne
- Moderne
- Overvåke
- skjermer
- mer
- flere
- Naviger
- Navigasjon
- nødvendig
- behov
- neste
- node
- varslinger
- gjenstander
- Tilbud
- ONE
- åpen
- ellers
- brød
- parameter
- del
- lidenskapelig
- tillatelse
- rørledning
- plassering
- plato
- Platon Data Intelligence
- PlatonData
- i tillegg til
- Politikk
- Post
- Forbered
- presentere
- forebygge
- Forhåndsvisning
- forrige
- primære
- Prosesser
- egenskaper
- gi
- gir
- kvalitet
- Rask
- Raw
- Lese
- nylig
- region
- krever
- påkrevd
- Ressurser
- resultere
- Resultater
- anmeldelse
- Rolle
- roller
- RAD
- Regel
- regler
- Kjør
- samme
- Søk
- Seksjon
- Serien
- tjeneste
- Tjenester
- sett
- innstilling
- oppsett
- Vis
- Viser
- undertegne
- Enkelt
- størrelser
- So
- Software
- programvareutvikling
- løsning
- Solutions
- kilde
- spesialist
- spesialisert
- stable
- standarder
- Begynn
- startet
- Start
- Trinn
- Steps
- lagring
- studio
- Dress
- syntetisk
- Ta
- Target
- Oppgave
- lag
- mal
- De
- tusener
- Gjennom
- ganger
- til
- i dag
- verktøy
- Transform
- transformere
- Stol
- etter
- underliggende
- unik
- ubrukt
- bruke
- bruk sak
- Brukere
- vanligvis
- VALIDERE
- validering
- verdi
- ulike
- Se
- visualisering
- vente
- om
- hvilken
- vil
- uten
- virker
- skrive
- skriving
- skrevet
- Din
- zephyrnet