Dette blogginnlegget er medforfatter av Guillermo Ribeiro, Sr. Data Scientist ved Cepsa.
Maskinlæring (ML) har raskt utviklet seg fra å være en moteriktig trend som dukker opp fra akademiske miljøer og innovasjonsavdelinger til å bli et nøkkelmiddel for å levere verdi på tvers av virksomheter i alle bransjer. Denne overgangen fra eksperimenter i laboratorier til å løse virkelige problemer i produksjonsmiljøer går hånd i hånd med MLOps, eller tilpasningen av DevOps til ML-verdenen.
MLOps hjelper til med å strømlinjeforme og automatisere hele livssyklusen til en ML-modell, og fokuserer på kildedatasettene, eksperimentets reproduserbarhet, ML-algoritmekode og modellkvalitet.
At Cepsa, et globalt energiselskap, bruker vi ML til å takle komplekse problemer på tvers av våre virksomheter, fra å utføre prediktivt vedlikehold for industrielt utstyr til overvåking og forbedring av petrokjemiske prosesser ved våre raffinerier.
I dette innlegget diskuterer vi hvordan vi bygde referansearkitekturen vår for MLOps ved å bruke følgende viktige AWS-tjenester:
- Amazon SageMaker, en tjeneste for å bygge, trene og distribuere ML-modeller
- AWS trinnfunksjoner, en serverløs lavkode visuell arbeidsflyttjeneste som brukes til å orkestrere og automatisere prosesser
- Amazon EventBridge, en serverløs hendelsesbuss
- AWS Lambda, en serverløs datatjeneste som lar deg kjøre kode uten å klargjøre eller administrere servere
Vi forklarer også hvordan vi brukte denne referansearkitekturen for å starte opp nye ML-prosjekter i selskapet vårt.
Utfordringen
I løpet av de siste 4 årene har flere bransjer på tvers av Cepsa startet ML-prosjekter, men snart begynte visse problemer og begrensninger å dukke opp.
Vi hadde ikke en referansearkitektur for ML, så hvert prosjekt fulgte en annen implementeringsvei, og utførte ad hoc modellopplæring og distribusjon. Uten en felles metode for å håndtere prosjektkode og parametere og uten et ML-modellregister eller versjonssystem, mistet vi sporbarheten mellom datasett, kode og modeller.
Vi oppdaget også rom for forbedring i måten vi drev modeller i produksjonen, fordi vi ikke overvåket utplasserte modeller og derfor ikke hadde midler til å spore modellytelse. Som en konsekvens omskolerte vi vanligvis modeller basert på tidsplaner, fordi vi manglet de riktige beregningene for å ta informerte omskoleringsbeslutninger.
løsningen
Med utgangspunkt i utfordringene vi måtte overvinne, utviklet vi en generell løsning som hadde som mål å koble fra dataforberedelse, modelltrening, slutninger og modellovervåking, og inneholdt et sentralisert modellregister. På denne måten forenklet vi administrasjon av miljøer på tvers av flere AWS-kontoer, samtidig som vi introduserte sentralisert modellsporbarhet.
Våre dataforskere og utviklere bruker AWS Cloud9 (en sky-IDE for skriving, kjøring og feilsøking av kode) for datakrangel og ML-eksperimentering og GitHub som Git-kodelageret.
En automatisk treningsarbeidsflyt bruker koden bygget av datavitenskapsteamet til togmodeller på SageMaker og å registrere utdatamodeller i modellregisteret.
En annen arbeidsflyt administrerer modelldistribusjon: den henter referansen fra modellregisteret og oppretter et slutningsendepunkt ved å bruke SageMaker-modellvertsfunksjoner.
Vi implementerte både modelltrenings- og distribusjonsarbeidsflyter ved å bruke Step Functions, fordi det ga et fleksibelt rammeverk som muliggjør opprettelse av spesifikke arbeidsflyter for hvert prosjekt og orkestrerer forskjellige AWS-tjenester og -komponenter på en enkel måte.
Dataforbruksmodell
I Cepsa bruker vi en serie datainnsjøer for å dekke ulike forretningsbehov, og alle disse datasjøene deler en felles dataforbruksmodell som gjør det enklere for dataingeniører og dataforskere å finne og konsumere dataene de trenger.
For enkelt å håndtere kostnader og ansvar er datainnsjømiljøer fullstendig atskilt fra dataprodusent- og forbrukerapplikasjoner, og distribuert i forskjellige AWS-kontoer som tilhører en felles AWS-organisasjon.
Dataene som brukes til å trene ML-modeller og dataene som brukes som slutningsinndata for trenede modeller, gjøres tilgjengelig fra de forskjellige datainnsjøene gjennom et sett med veldefinerte APIer ved hjelp av Amazon API-gateway, en tjeneste for å opprette, publisere, vedlikeholde, overvåke og sikre API-er i stor skala. API-backend bruker Amazonas Athena (en interaktiv spørringstjeneste for å analysere data ved hjelp av standard SQL) for å få tilgang til data som allerede er lagret i Amazon enkel lagringstjeneste (Amazon S3) og katalogisert i AWS Lim Datakatalog.
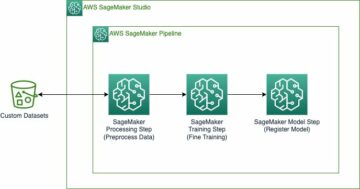
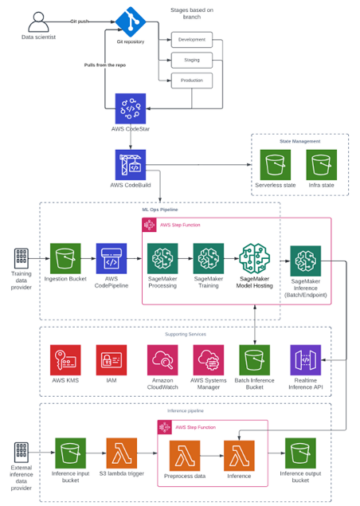
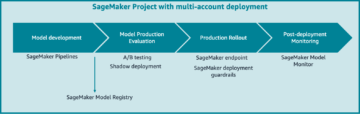
Følgende diagram gir en generell oversikt over Cepsas MLOps-arkitektur.

Modelltrening
Opplæringsprosessen er uavhengig for hver modell og håndteres av en Step Functions standard arbeidsflyt, som gir oss fleksibilitet til å modellere prosesser basert på ulike prosjektkrav. Vi har en definert en grunnmal som vi gjenbruker på de fleste prosjekter, og utfører mindre justeringer når det er nødvendig. For eksempel har noen prosjekteiere bestemt seg for å legge til manuelle porter for å godkjenne utplasseringer av nye produksjonsmodeller, mens andre prosjekteiere har implementert sine egne feildeteksjons- og prøvemekanismer.
Vi utfører også transformasjoner på input-datasettene som brukes til modelltrening. Til dette formålet bruker vi Lambda-funksjoner som er integrert i treningsarbeidsflytene. I noen scenarier der det kreves mer komplekse datatransformasjoner, kjører vi inn koden vår Amazon Elastic Container Service (Amazon ECS) på AWS Fargate, en serverløs beregningsmotor for å kjøre containere.
Datavitenskapsteamet vårt bruker tilpassede algoritmer ofte, så vi drar nytte av muligheten til bruke tilpassede beholdere i SageMaker modellopplæring, Avhenger av Amazon Elastic Container Registry (Amazon ECR), et fullstendig administrert containerregister som gjør det enkelt å lagre, administrere, dele og distribuere containerbilder.
De fleste av våre ML-prosjekter er basert på Scikit-learn-biblioteket, så vi har utvidet standarden SageMaker Scikit-læringsbeholder å inkludere miljøvariablene som kreves for prosjektet, for eksempel Git-depotinformasjon og distribusjonsalternativer.
Med denne tilnærmingen trenger dataforskerne våre bare å fokusere på å utvikle treningsalgoritmen og spesifisere bibliotekene som kreves av prosjektet. Når de sender kodeendringer til Git-lageret, vil CI/CD-systemet vårt (Jenkins hosted on AWS) bygger containeren med opplæringskoden og bibliotekene. Denne beholderen skyves til Amazon ECR og sendes til slutt som en parameter til SageMaker-oppfordringen.
Når treningsprosessen er fullført, lagres den resulterende modellen i Amazon S3, en referanse legges til i modellregisteret, og all innsamlet informasjon og beregninger lagres i eksperimentets katalog. Dette sikrer full reproduserbarhet fordi algoritmekoden og bibliotekene er koblet til den trente modellen sammen med dataene knyttet til eksperimentet.
Følgende diagram illustrerer modelltrenings- og omskoleringsprosessen.

Modellutplassering
Arkitekturen er fleksibel og tillater både automatiske og manuelle utplasseringer av de trente modellene. Arbeidsflyten for modelldeployer aktiveres automatisk ved hjelp av en hendelse som SageMaker-opplæringen publiserer i EventBridge etter at opplæringen er fullført, men den kan også startes manuelt ved behov, ved å sende riktig modellversjon fra modellregisteret. For mer informasjon om automatisk påkalling, se Automatisering av Amazon SageMaker med Amazon EventBridge.
Arbeidsflyten for modelldistribusjon henter modellinformasjonen fra modellregisteret og bruker AWS skyformasjon, en administrert infrastruktur som kodetjeneste, for enten å distribuere modellen til et sanntidsslutningsendepunkt eller utføre batch-inferens med et lagret input-datasett, avhengig av prosjektkravene.
Når en modell er vellykket distribuert i et hvilket som helst miljø, oppdateres modellregisteret med en ny kode som indikerer hvilke miljøer modellen kjører for øyeblikket. Hver gang et endepunkt fjernes, slettes også taggen fra modellregisteret.
Følgende diagram viser arbeidsflyten for modelldistribusjon og inferens.

Eksperimenter og modellregister
Lagring av hvert eksperiment og modellversjon på ett enkelt sted og å ha et sentralisert kodelager gjør det mulig for oss å koble fra modelltrening og distribusjon og bruke forskjellige AWS-kontoer for hvert prosjekt og miljø.
Alle eksperimentoppføringer lagrer commit-IDen til trenings- og slutningskoden, slik at vi har fullstendig sporbarhet av hele eksperimenteringsprosessen og enkelt kan sammenligne forskjellige eksperimenter. Dette hindrer oss i å utføre duplikatarbeid på den vitenskapelige utforskningsfasen for algoritmer og modeller, og gjør oss i stand til å distribuere modellene våre hvor som helst, uavhengig av kontoen og miljøet der modellen ble opplært. Dette gjelder også for modeller som er trent i vårt AWS Cloud9-eksperimentmiljø.
Alt i alt har vi helautomatiserte modellopplærings- og distribusjonspipelines og har fleksibiliteten til å utføre raske manuelle modelldistribusjoner når noe ikke fungerer som det skal eller når et team trenger en modell distribuert til et annet miljø for eksperimenteringsformål.
En detaljert brukssak: YET Dragon-prosjektet
YET Dragon-prosjektet har som mål å forbedre produksjonsytelsen til Cepsas petrokjemiske anlegg i Shanghai. For å nå dette målet studerte vi produksjonsprosessen grundig, og lette etter de mindre effektive trinnene. Målet vårt var å øke utbytteeffektiviteten til prosessene ved å holde komponentkonsentrasjonen nøyaktig under en terskel.
For å simulere denne prosessen bygde vi fire generaliserte additivmodeller eller GAM, lineære modeller hvis respons avhenger av jevne funksjoner til prediktorvariabler, for å forutsi resultatene av to oksidasjonsprosesser, en konsentrasjonsprosess og det nevnte utbyttet. Vi bygde også en optimizer for å behandle resultatene fra de fire GAM-modellene og finne de beste optimaliseringene som kunne brukes i anlegget.
Selv om modellene våre er trent med historiske data, kan anlegget noen ganger operere under omstendigheter som ikke var registrert i opplæringsdatasettet; vi forventer at simuleringsmodellene våre ikke vil fungere godt under disse scenariene, så vi bygde også to anomalideteksjonsmodeller ved hjelp av Isolation Forests-algoritmer, som bestemmer hvor langt datapunkter er til resten av dataene for å oppdage uregelmessighetene. Disse modellene hjelper oss med å oppdage slike situasjoner for å deaktivere de automatiserte optimaliseringsprosessene når dette skjer.
Industrielle kjemiske prosesser er svært varierende og ML-modellene må være godt tilpasset anleggsdriften, så hyppig omskolering er nødvendig samt sporbarhet av modellene som brukes i hver situasjon. YET Dragon var vårt første ML-optimaliseringsprosjekt som inneholdt et modellregister, full reproduserbarhet av eksperimentene og en fullt administrert automatisert treningsprosess.
Nå er den komplette pipelinen som bringer en modell i produksjon (datatransformasjon, modelltrening, eksperimentsporing, modellregister og modelldistribusjon) uavhengig for hver ML-modell. Dette gjør oss i stand til å forbedre modeller iterativt (for eksempel å legge til nye variabler eller teste nye algoritmer) og koble trenings- og distribusjonsstadiene til forskjellige triggere.
Resultatene og fremtidige forbedringer
Vi er for øyeblikket i stand til å automatisk trene, distribuere og spore de seks ML-modellene som brukes i YET Dragon-prosjektet, og vi har allerede distribuert over 30 versjoner for hver av produksjonsmodellene. Denne MLOps-arkitekturen har blitt utvidet til hundrevis av ML-modeller i andre prosjekter over hele selskapet.
Vi planlegger å fortsette å lansere nye YET-prosjekter basert på denne arkitekturen, som har redusert prosjektets gjennomsnittlige varighet med 25 %, takket være reduksjonen av bootstrapping-tiden og automatiseringen av ML-rørledninger. Vi har også estimert besparelser på rundt €300,000 XNUMX per år takket være økningen i utbytte og konsentrasjon som er et direkte resultat av YET Dragon-prosjektet.
Den kortsiktige utviklingen av denne MLOps-arkitekturen går mot modellovervåking og automatisert testing. Vi planlegger å automatisk teste modelleffektivitet mot tidligere distribuerte modeller før en ny modell distribueres. Vi jobber også med implementering av modellovervåking og slutningsdatadriftsovervåking med Amazon SageMaker modellmonitor, for å automatisere modellomskolering.
konklusjonen
Bedrifter står overfor utfordringen med å bringe sine ML-prosjekter til produksjon på en automatisert og effektiv måte. Automatisering av hele ML-modellens livssyklus bidrar til å redusere prosjekttidene og sikrer bedre modellkvalitet og raskere og hyppigere distribusjoner til produksjon.
Ved å utvikle en standardisert MLOps-arkitektur som har blitt tatt i bruk av ulike virksomheter på tvers av selskapet, var vi i Cepsa i stand til å øke hastigheten på oppstart av ML-prosjekter og forbedre ML-modellkvaliteten, og tilby et pålitelig og automatisert rammeverk som datavitenskapsteamene våre kan innovere raskere på. .
For mer informasjon om MLOps på SageMaker, besøk Amazon SageMaker for MLOps og sjekk ut andre kundebrukstilfeller i AWS maskinlæringsblogg.
Om forfatterne
 Guillermo Ribeiro Jiménez er en Sr Data Scientist ved Cepsa med en PhD. i kjernefysikk. Han har 6 års erfaring med datavitenskapelige prosjekter, hovedsakelig innen telekom- og energibransjen. Han leder for tiden dataforskerteam i Cepsas avdeling for digital transformasjon, med fokus på skalering og produktisering av maskinlæringsprosjekter.
Guillermo Ribeiro Jiménez er en Sr Data Scientist ved Cepsa med en PhD. i kjernefysikk. Han har 6 års erfaring med datavitenskapelige prosjekter, hovedsakelig innen telekom- og energibransjen. Han leder for tiden dataforskerteam i Cepsas avdeling for digital transformasjon, med fokus på skalering og produktisering av maskinlæringsprosjekter.
 Guillermo Menéndez Corral er løsningsarkitekt hos AWS Energy and Utilities. Han har over 15 års erfaring med å designe og bygge SW-applikasjoner, og gir for tiden arkitektonisk veiledning til AWS-kunder i energibransjen, med fokus på analyse og maskinlæring.
Guillermo Menéndez Corral er løsningsarkitekt hos AWS Energy and Utilities. Han har over 15 års erfaring med å designe og bygge SW-applikasjoner, og gir for tiden arkitektonisk veiledning til AWS-kunder i energibransjen, med fokus på analyse og maskinlæring.
- Myntsmart. Europas beste Bitcoin og Crypto Exchange.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. FRI TILGANG.
- CryptoHawk. Altcoin Radar. Gratis prøveperiode.
- Kilde: https://aws.amazon.com/blogs/machine-learning/how-cepsa-used-amazon-sagemaker-and-aws-step-functions-to-industrialize-their-ml-projects-and-operate- deres-modeller-i-skala/
- "
- 000
- 100
- 15 år
- a
- evne
- Om oss
- adgang
- Logg inn
- Oppnå
- tvers
- Ad
- la til
- Fordel
- mot
- algoritme
- algoritmer
- Alle
- tillater
- allerede
- Amazon
- blant
- analytics
- analysere
- hvor som helst
- api
- APIer
- søknader
- anvendt
- tilnærming
- godkjenne
- arkitektonisk
- arkitektur
- rundt
- assosiert
- automatisere
- Automatisert
- Automatisk
- automatisk
- Automatisere
- Automatisering
- tilgjengelig
- AWS
- fordi
- bli
- før du
- være
- under
- BEST
- Blogg
- bygge
- Bygning
- bygger
- virksomhet
- bedrifter
- saken
- saker
- sentralisert
- viss
- utfordre
- utfordringer
- kjemisk
- Cloud
- kode
- forplikte
- Felles
- Selskapet
- fullføre
- helt
- komplekse
- komponent
- komponenter
- Beregn
- konsentrasjon
- Koble
- forbruke
- forbruker
- forbruk
- Container
- Containere
- Kostnader
- kunne
- dekke
- skape
- skaper
- skaperverket
- I dag
- skikk
- kunde
- Kunder
- dato
- datavitenskap
- dataforsker
- besluttet
- avgjørelser
- avhengig
- avhenger
- utplassere
- utplassert
- distribusjon
- distribusjoner
- designet
- utforme
- detaljert
- oppdaget
- Gjenkjenning
- Bestem
- utviklere
- utvikle
- forskjellig
- digitalt
- Digital Transformation
- direkte
- diskutere
- Drage
- hver enkelt
- lett
- effektivitet
- effektiv
- Emery
- muliggjør
- Endpoint
- energi
- Motor
- Ingeniører
- Miljø
- utstyr
- anslått
- Event
- evolusjon
- nøyaktig
- eksempel
- forvente
- erfaring
- eksperiment
- leting
- vendt
- FAST
- raskere
- Trekk
- kjennetegnet
- Endelig
- Først
- fleksibilitet
- fleksibel
- Fokus
- etter
- Rammeverk
- fra
- fullt
- funksjoner
- framtid
- Gates
- general
- gå
- GitHub
- Global
- mål
- håndtere
- å ha
- hjelpe
- hjelper
- svært
- historisk
- holder
- vert
- Hosting
- Hvordan
- HTTPS
- Hundrevis
- bilder
- gjennomføring
- implementert
- forbedre
- forbedring
- bedre
- I andre
- inkludere
- Øke
- uavhengig
- uavhengig av hverandre
- industriell
- industri
- informasjon
- informert
- Infrastruktur
- Innovasjon
- inngang
- integrert
- interaktiv
- innføre
- isolasjon
- saker
- IT
- Hold
- holde
- nøkkel
- lansere
- ledende
- læring
- Bibliotek
- linjer
- plassering
- ser
- maskin
- maskinlæring
- laget
- vedlikeholde
- vedlikehold
- gjøre
- GJØR AT
- administrer
- fikk til
- administrerende
- måte
- håndbok
- manuelt
- midler
- Metrics
- ML
- modell
- modeller
- Overvåke
- overvåking
- mer
- mest
- flere
- behov
- betjene
- drift
- optimalisering
- alternativer
- rekkefølge
- organisasjon
- Annen
- egen
- eiere
- Passerer
- ytelse
- utfører
- fase
- Fysikk
- poeng
- forutsi
- problemer
- prosess
- Prosesser
- produsent
- Produksjon
- prosjekt
- prosjekter
- forutsatt
- gir
- gi
- publisere
- formål
- formål
- presset
- kvalitet
- sanntids
- redusere
- registrere
- registrert
- pålitelig
- Repository
- påkrevd
- Krav
- svar
- ansvar
- REST
- resulterende
- Resultater
- Kjør
- rennende
- Skala
- skalering
- Vitenskap
- Forsker
- forskere
- sikre
- Serien
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- Shanghai
- Del
- kortsiktig
- Enkelt
- simulering
- enkelt
- situasjon
- SIX
- So
- løsning
- Solutions
- noen
- noe
- spesifikk
- fart
- stadier
- Standard
- startet
- lagring
- oppbevare
- effektivisere
- vellykket
- system
- Target
- lag
- lag
- Telco
- test
- Testing
- De
- Kilden
- derfor
- grundig
- terskel
- Gjennom
- tid
- ganger
- mot
- Sporbarhet
- spor
- Sporing
- Kurs
- Transformation
- transformasjoner
- overgang
- etter
- us
- bruke
- vanligvis
- verktøy
- verdi
- versjon
- veldefinerte
- mens
- uten
- Arbeid
- arbeidsflyt
- arbeid
- verden
- skriving
- år
- år
- Utbytte