Novo Nordisk er et ledende globalt farmasøytisk selskap, ansvarlig for å produsere livreddende medisiner som når mer enn 34 millioner pasienter hver dag. De gjør dette etter sin tredobbelte bunnlinje - at de må strebe etter å være miljømessig bærekraftige, sosialt bærekraftige og økonomisk bærekraftige. Kombinasjonen av bruk av AWS og data støtter alle disse målene.
Data er gjennomgående gjennom hele verdikjeden til Novo Nordisk. Fra grunnleggende forskning, produksjonslinjer, salg og markedsføring, kliniske utprøvinger, legemiddelovervåking, gjennom pasientrettede datadrevne applikasjoner. Derfor er det å få grunnlaget rundt hvordan data lagres, ivaretas og brukes på en måte som gir mest verdi, en av de sentrale driverne for forbedrede forretningsresultater.
Sammen med AWS profesjonelle tjenester, bygger vi en data- og analyseløsning ved hjelp av en moderne dataarkitektur. Samarbeidet mellom Novo Nordisk og AWS Professional Services er et strategisk og langsiktig tett engasjement, hvor utviklere fra begge organisasjoner har jobbet tett sammen i årevis. Data- og analysemiljøene er bygget rundt kjerneprinsippene i datanettverket – desentralisert domeneeierskap av data, data som et produkt, selvbetjent datainfrastruktur og føderert beregningsstyring. Dette gjør det mulig for brukerne av miljøet å jobbe med data på den måten som gir de beste forretningsresultatene. Vi har kombinert dette med elementer fra evolusjonære arkitekturer som vil tillate oss å tilpasse ulike funksjoner ettersom AWS kontinuerlig utvikler nye tjenester og muligheter.
I denne serien med innlegg vil du lære hvordan Novo Nordisk og AWS Professional Services bygde et data- og analyseøkosystem for å fremskynde innovasjon i petabyte-skala:
- I dette første innlegget vil du lære hvordan det overordnede designet har gjort det mulig for de enkelte komponentene å komme sammen på en modulær måte. Vi dykker dypt inn i hvordan vi bygde en datahåndteringsløsning basert på datamaskeringsarkitekturen.
- Det andre innlegget diskuterer hvordan vi bygget et tillitsnettverk mellom systemene som utgjør hele løsningen. Vi viser hvordan vi bruker hendelsesdrevne arkitekturer, kombinert med bruk av attributtbaserte tilgangskontroller, for å sikre at tillatelsesgrenser blir respektert i stor skala.
- I det tredje innlegget viser vi hvordan sluttbrukere kan konsumere data fra deres foretrukne verktøy, uten å gå på bekostning av datastyring. Dette inkluderer hvordan du konfigurerer Okta, AWS Lake formasjon, og Microsoft Power BI for å aktivere SAML-basert forent bruk av Amazonas Athena for en Enterprise Business Intelligence (BI) aktivitet.
Pharma-kompatibelt miljø
Som en farmasøytisk industri er GxP-samsvar et mandat for Novo Nordisk. GxP er en generell forkortelse for "Good x Practice" kvalitetsretningslinjer og forskrifter definert av regulatorer som European Medicines Agency, US Food and Drug Administration og andre. Disse retningslinjene er utformet for å sikre at legemidler er trygge og effektive for den tiltenkte bruken. I sammenheng med et datamiljø involverer GxP-samsvar implementering av integritetskontroller for data som brukes i beslutningstaking og prosesser, og brukes til å veilede hvordan endringsstyringsprosesser implementeres for kontinuerlig å sikre samsvar over tid.
Fordi dette datamiljøet støtter team på tvers av hele organisasjonen, må hver enkelt dataeier beholde ansvaret for sine data. Funksjoner ble utviklet for å gi dataeiere autonomi og åpenhet når de administrerer dataene sine, slik at de kan ta dette ansvaret. Dette inkluderer muligheten til å håndtere personlig identifiserbar informasjon (PII) data og andre sensitive arbeidsbelastninger. For å gi sporbarhet på miljøet ble det lagt til revisjonsmuligheter, som vi beskriver mer i dette innlegget.
Løsningsoversikt
Den fullstendige løsningen er et vidstrakt landskap av uavhengige tjenester som jobber sammen for å muliggjøre data og analyser med en desentralisert datastyringsmodell i petabyte-skala. Skjematisk kan det representeres som i følgende figur.

Arkitekturen er delt inn i tre uavhengige lag: databehandling, virtualisering og forbruk. Sluttbrukeren sitter i forbrukslaget og jobber med sitt valgte verktøy. Det er ment å abstrahere så mye av de AWS-innfødte ressursene til applikasjonsprimitiver. Forbrukslaget er integrert i virtualiseringslaget, som abstraherer tilgangen til data. Formålet med virtualiseringslaget er å oversette mellom dataforbruk og datahåndteringsløsninger. Tilgangen til data administreres av det vi omtaler som datahåndteringsløsninger. Vi diskuterer en av våre allsidige datahåndteringsløsninger senere i dette innlegget. Hvert lag i denne arkitekturen er uavhengig av hverandre og er i stedet bare avhengig av veldefinerte grensesnitt.
Sentralt i denne arkitekturen er at adkomsten er innkapslet i en AWS identitets- og tilgangsadministrasjon (IAM) rolleøkt. Databehandlingslaget fokuserer på å gi IAM-rollen de riktige tillatelsene og styringen, virtualiseringslaget gir tilgang til rollen, og forbrukslaget abstraherer bruken av rollene i de valgte verktøyene.
Teknisk arkitektur
Hvert av de tre lagene i den overordnede arkitekturen har et distinkt ansvar, men ingen enkel implementering. Tenk på dem som abstrakte klasser. De kan implementeres i konkrete klasser, og i vårt tilfelle er de avhengige av grunnleggende AWS-tjenester og -funksjoner. La oss gå gjennom hvert av de tre lagene.
Databehandlingslag
Databehandlingslaget er ansvarlig for å gi tilgang til og styring av data. Som illustrert i følgende diagram, er en minimal konstruksjon i databehandlingslaget kombinasjonen av en Amazon enkel lagringstjeneste (Amazon S3) bøtte og en IAM-rolle som gir tilgang til S3-bøtte. Denne konstruksjonen kan utvides til å inkludere granulær tillatelse med Lake Formation, revisjon med AWS CloudTrail, og sikkerhetsresponsfunksjoner fra AWS Security Hub. Det følgende diagrammet viser også at en enkelt databehandlingsløsning ikke har et enkelt spenn. Den kan krysse mange AWS-kontoer og bestå av et hvilket som helst antall IAM-rollekombinasjoner.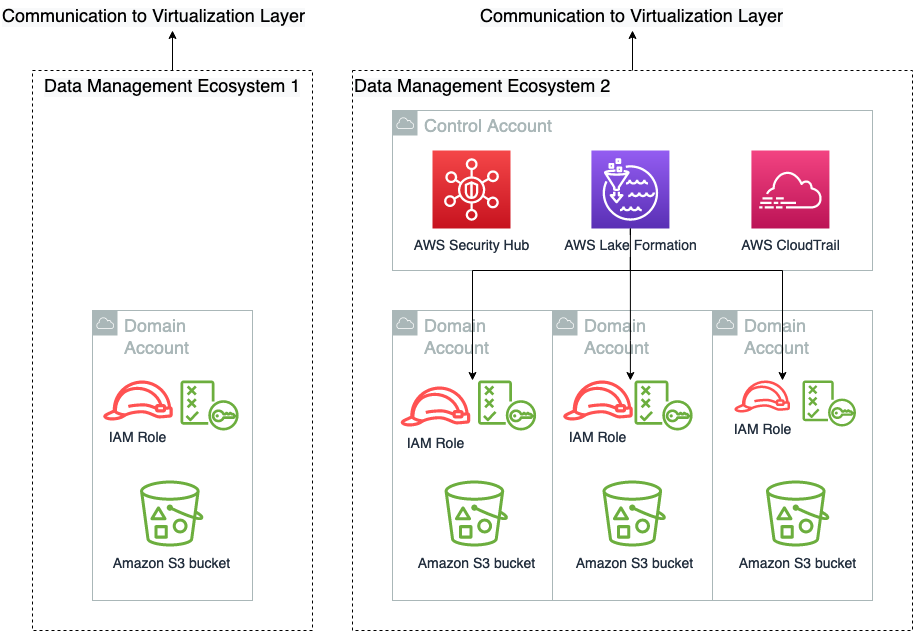
Vi har med hensikt ikke illustrert tillitspolitikken til disse rollene i denne figuren, fordi de er et samarbeidsansvar mellom virtualiseringslaget og databehandlingslaget. Vi går i detalj om hvordan det fungerer i neste innlegg i denne serien. Dataingeniører bruker ofte grensesnitt direkte med databehandlingslaget, hvor de kuraterer og forbereder data for forbruk.
Virtualiseringslag
Formålet med virtualiseringslaget er å holde styr på hvem som kan gjøre hva. Den har ingen muligheter i seg selv, men oversetter kravene fra datastyringsøkosystemene til forbrukslagene og omvendt. Den gjør det mulig for sluttbrukere på forbrukslaget å få tilgang til og manipulere data på ett eller flere dataadministrasjonsøkosystemer, i henhold til deres tillatelser. Dette laget abstraherer fra sluttbrukere de tekniske detaljene om datatilgang, som tillatelsesmodell, rolleantakelser og lagringsplassering. Den eier grensesnittene til de andre lagene og fremtvinger abstraksjonens logikk. I sammenheng med sekskantede arkitekturer (se Utvikle evolusjonær arkitektur med AWS Lambda), spiller grensesnittlaget rollen som domenelogikken, porter og adaptere. De to andre lagene er skuespillere. Databehandlingslaget kommuniserer tilstanden til laget til virtualiseringslaget og mottar omvendt informasjon om tjenestelandskapet å stole på. Virtualiseringslagsarkitekturen er vist i følgende diagram.

Forbrukslag
Forbrukslaget er der sluttbrukerne av dataproduktene sitter. Dette kan være dataforskere, business intelligence-analytikere eller en tredjepart som genererer verdi ved å konsumere dataene. Det er viktig for denne typen arkitektur at forbrukslaget har en hook-basert påloggingsflyt, hvor autorisasjonen til applikasjonen kan endres ved pålogging. Dette er for å oversette det AWS-spesifikke kravet til målapplikasjonene. Etter at økten i klientsideapplikasjonen har blitt startet, er det opp til applikasjonen selv å instrumentere for datalagabstraksjon, fordi dette vil være applikasjonsspesifikt. Og dette er en ekstra viktig frakobling, der noe ansvar skyves til de desentraliserte enhetene. Mange moderne programvare som en tjeneste (SaaS)-applikasjoner støtter disse innebygde mekanismene, som f.eks Databaser or Domino Data Lab, mens mer tradisjonelle klientsideapplikasjoner som RStudio server har mer begrenset innfødt støtte for dette. I tilfellet der opprinnelig støtte mangler, kan en oversettelse ned til OS-brukerøkten gjøres for å aktivere abstraksjonen. Forbrukslaget er vist skjematisk i følgende diagram.
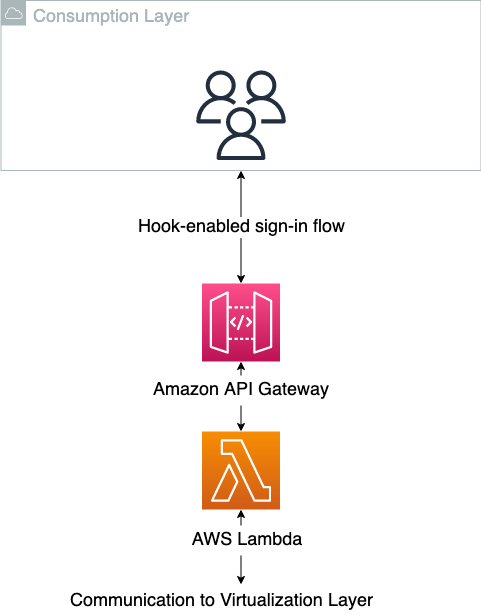
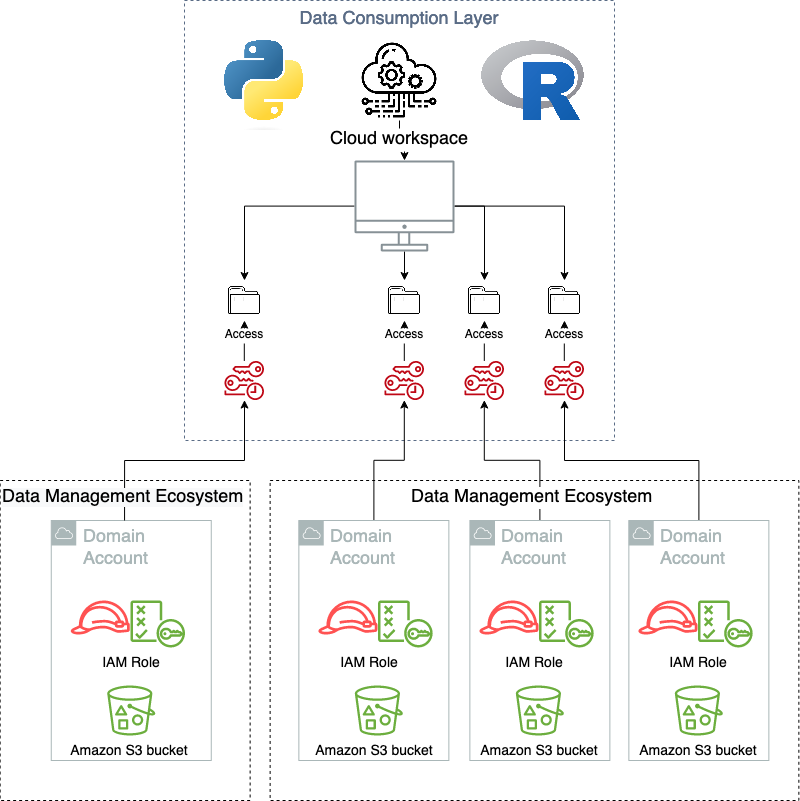
Når du bruker forbrukslaget etter hensikten, vet ikke brukerne at virtualiseringslaget eksisterer. Følgende diagram illustrerer datatilgangsmønstrene.
modularitet
En av hovedfordelene ved å ta i bruk det sekskantede arkitekturmønsteret, og delegere både det forbrukende laget og datahåndteringslaget til primære og sekundære aktører, betyr at de kan endres eller erstattes etter hvert som nye funksjonaliteter som krever nye løsninger frigjøres. Dette gir et nav-og-eiker type mønster, hvor mange forskjellige typer produsent/forbruker type systemer kan kobles sammen og fungere samtidig. Et eksempel på dette er at den nåværende løsningen som kjører i Novo Nordisk støtter flere, samtidige datahåndteringsløsninger og eksponeres på en homogen måte i det forbrukende laget. Dette inkluderer både en datainnsjø, datanettløsningen presentert i dette innlegget, og flere uavhengige datahåndteringsløsninger. Og disse er utsatt for flere typer forbrukende applikasjoner, fra tilpassede administrerte, selvvertsbaserte applikasjoner, til SaaS-tilbud.
Økosystem for datahåndtering
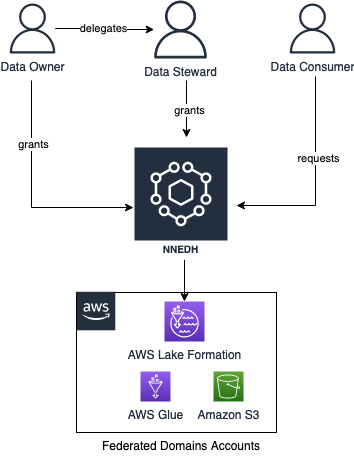
For å skalere bruken av dataene og øke friheten bygde Novo Nordisk, sammen med AWS Professional Services, et dataadministrasjons- og styringsmiljø, kalt Novo Nordisk Enterprise DataHub (NNEDH). NNEDH implementerer en desentralisert distribuert dataarkitektur og dataadministrasjonsfunksjoner som en bedriftsdatakatalog og arbeidsflyt for datadeling. NNEDH er et eksempel på et datahåndteringsøkosystem i det konseptuelle rammeverket introdusert tidligere.
Desentralisert arkitektur: Fra en sentralisert datainnsjø til en distribuert arkitektur
Novo Nordisks sentraliserte datainnsjø består av 2.3 PB med data fra mer enn 30 forretningsdatadomener over hele verden som betjener over 2000+ interne brukere gjennom hele verdikjeden. Den har kjørt med suksess i flere år. Det er et av dataadministrasjonsøkosystemene som for tiden støttes.
Innenfor den sentraliserte dataarkitekturen blir data fra hvert datadomene kopiert, lagret og behandlet på ett sentralt sted: en sentral datainnsjø som ligger i ett datalager. Dette mønsteret har utfordringer i stor skala fordi det beholder dataeierskapet med det sentrale teamet. I stor skala bremser denne modellen reisen mot en datadrevet organisasjon, fordi eierskapet til dataene ikke er tilstrekkelig forankret hos fagfolkene nærmest domenet.
Den monolittiske datainnsjøarkitekturen er vist i følgende diagram.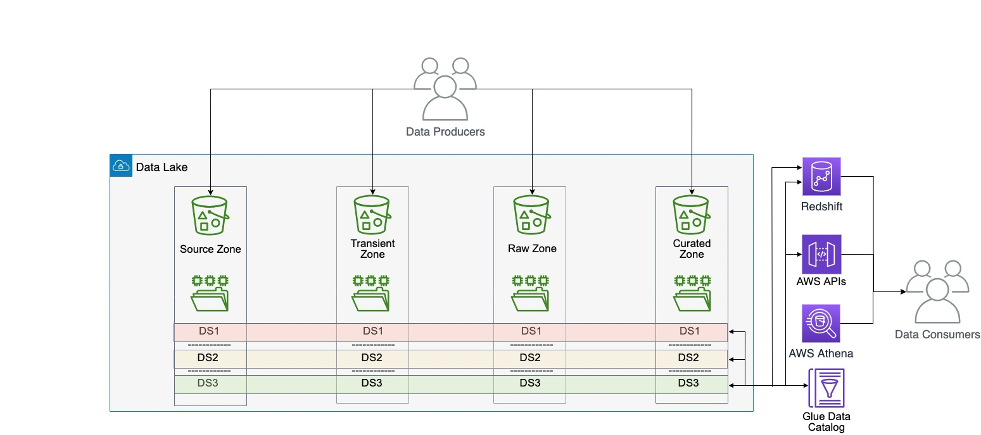
Innenfor den desentraliserte distribuerte dataarkitekturen holdes dataene fra hvert domene innenfor domenet på sin egen datalagrings- og beregningskonto. I dette tilfellet holdes dataene i nærheten av domeneeksperter, fordi det er de som kjenner sine egne data best og til syvende og sist eiere av alle dataprodukter bygget rundt dataene deres. De jobber ofte tett med forretningsanalytikere for å bygge dataproduktet og vet derfor hva god data betyr for forbrukere av dataproduktene deres. I dette tilfellet er dataansvaret også desentralisert, der hvert domene har sin egen dataeier, og legger ansvaret på de sanne eierne av dataene. Likevel kan det hende at denne modellen ikke fungerer i liten skala, for eksempel en organisasjon med bare én forretningsenhet og titalls brukere, fordi den vil introdusere mer overhead på IT-teamet for å administrere organisasjonsdataene. Det passer bedre for store organisasjoner, eller små og mellomstore som ønsker å vokse og skalere.
Novo Nordisks datanettarkitektur er vist i følgende diagram.

Datadomener og dataressurser
For å muliggjøre skalerbarhet av datadomener på tvers av organisasjonen, er det obligatorisk å ha en standard tillatelsesmodell og datatilgangsmønster. Denne standarden må ikke være for restriktiv på en slik måte at den kan være en blokkering for spesifikke brukstilfeller, men den bør standardiseres på en slik måte å bruke samme grensesnitt mellom databehandlings- og virtualiseringslagene.
Datadomenene på NNEDH er implementert av en konstruksjon kalt an miljø. Et miljø består av minst én AWS-konto og én AWS-region. Det er en arbeidsplass hvor datadomeneteam kan jobbe og samarbeide for å bygge dataprodukter. Den kobler NNEDH-kontrollplanet til AWS-kontoene der dataene og beregningene til domenet ligger. Tillatelsene for datatilgang er også definert på miljønivå, administrert av eieren av datadomenet. Miljøene har tre hovedkomponenter: et dataadministrasjons- og styringslag, dataressurser og valgfrie tegninger for databehandling.
For dataadministrasjon og -styring er datadomenene avhengige av Lake Formation, AWS Lim, og CloudTrail. Implementeringsmetoden og oppsettet av disse komponentene er standardisert på tvers av datadomener. På denne måten kan NNEDH-kontrollplanet gi tilkobling og administrasjon til datadomener på en standardisert måte.
Datamidlene til hvert domene som ligger i et miljø er organisert i et datasett, som er en samling av relaterte data som brukes til å bygge et dataprodukt. Den inkluderer tekniske metadata som dataformat, størrelse og opprettelsestid, og forretningsmetadata som produsent, dataklassifisering og forretningsdefinisjon. Et dataprodukt kan bruke ett eller flere datasett. Den implementeres gjennom administrerte S3-bøtter og AWS Glue Data Catalog.
Databehandling kan implementeres på ulike måter. NNEDH leverer tegninger for datarørledninger med forhåndsdefinert tilkobling til dataressurser for å fremskynde leveringen av dataprodukter. Datadomenebrukere har friheten til å bruke hvilken som helst annen beregningsevne på domenet deres, for eksempel ved å bruke AWS-tjenester som ikke er forhåndsdefinert på tegningene eller tilgang til datasettene fra andre analyseverktøy implementert i forbrukslaget, som nevnt tidligere i dette innlegget.
Datadomene personas og roller
På NNEDH administreres tillatelsesnivåene på datadomener gjennom forhåndsdefinerte personas, for eksempel dataeier, dataforvaltere, utviklere og lesere. Hver persona er knyttet til en IAM-rolle som har et forhåndsdefinert tillatelsesnivå. Disse tillatelsene er basert på de typiske behovene til brukere på disse rollene. Likevel, for å gi mer fleksibilitet til datadomener, kan disse tillatelsene tilpasses og utvides etter behov.
Tillatelsene knyttet til hver persona er kun relatert til handlinger som er tillatt på AWS-kontoen til datadomenet. For ansvarlighet for dataressurser, administreres datatilgangen til ressursene av spesifikke ressurspolicyer i stedet for IAM-roller. Bare eieren av hvert datasett, eller dataforvaltere delegert av eieren, kan gi eller tilbakekalle datatilgang.
På datasettnivå er en påkrevd persona dataeieren. Vanligvis jobber de tett med en eller flere dataansvarlige som dataproduktansvarlige. Dataansvarlig er datasubjekteksperten for dataproduktdomenet, ansvarlig for å tolke innsamlede data og metadata for å utlede dyp forretningsinnsikt og bygge produktet. Dataansvarlig bygger bro mellom forretningsbrukere og tekniske team på hvert datadomene.
Bedriftsdatakatalog
For å muliggjøre frihet og gjøre organisasjonens dataressurser synlige, implementeres en nettbasert portaldatakatalog. Den indekserer i ett enkelt depot metadata fra datasett bygget på datadomener, og bryter datasiloer på tvers av organisasjonen. Datakatalogen muliggjør datasøk og oppdagelse på tvers av forskjellige domener, samt automatisering og styring av datadeling.
Bedriftsdatakatalogen implementerer datastyringsprosesser i organisasjonen. Det sikrer dataeierskap – noen i organisasjonen er ansvarlig for dataopprinnelsen, definisjonen, forretningsattributtene, relasjonene og avhengighetene.
Den sentrale konstruksjonen av en forretningsdatakatalog er et datasett. Det er søkeenheten i bedriftskatalogen, som har både tekniske og forretningsmessige metadata. For å samle inn tekniske metadata fra strukturerte data, er den avhengig av AWS Glue-crawlere for å gjenkjenne og trekke ut datastrukturer fra de mest populære dataformatene, inkludert CSV, JSON, Avro og Apache Parquet. Den gir informasjon som datatype, opprettelsesdato og format. Metadataene kan berikes av forretningsbrukere ved å legge til en beskrivelse av forretningskonteksten, tagger og dataklassifisering.
Datasettdefinisjonen og relaterte metadata lagres i en Amazon Aurora Serverløs database og Amazon OpenSearch-tjeneste, slik at du kan kjøre tekstsøk på datakatalogen.
Datadeling
NNEDH implementerer en arbeidsflyt for datadeling, som muliggjør peer-to-peer datadeling på tvers av AWS-kontoer ved hjelp av Lake Formation. Arbeidsflyten er som følger:
- En dataforbruker ber om tilgang til datasettet.
- Dataeieren gir tilgang ved å godkjenne tilgangsforespørselen. De kan delegere godkjenning av tilgangsforespørsler til dataansvarlig.
- Ved godkjenning av en tilgangsforespørsel legges en ny tillatelse til det spesifikke datasettet i Lake Formation for produsentkontoen.
Arbeidsflyten for datadeling er vist skjematisk i følgende figur.
Sikkerhet og revisjon
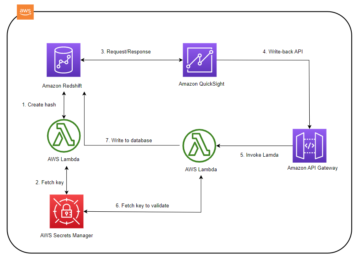
Dataene i Novo Nordisk-datanettverket ligger i AWS-kontoer som eies av Novo Nordisk-forretningskontoer. Konfigurasjonen og tilstandene til datanettverket er lagret i Amazon Relational Database Service (Amazon RDS). Novo Nordisks sikkerhetsarkitektur er vist i følgende figur.

Tilgang og redigering av dataene i NNEDH må logges for revisjonsformål. Vi må kunne fortelle hvem som endret data, når endringen skjedde og hvilke modifikasjoner som ble brukt. I tillegg må vi kunne svare på hvorfor endringen ble tillatt av denne personen på det tidspunktet.
For å oppfylle disse kravene bruker vi følgende komponenter:
- CloudTrail for å logge API-anrop. Vi aktiverer spesifikt CloudTrail-datahendelseslogging for S3-bøtter og objekter. Ved å aktivere loggingen kan vi spore tilbake eventuelle modifikasjoner til eventuelle filer i datasjøen til personen som gjorde endringen. Vi håndhever bruk av kildeidentitet for IAM-rolleøkter for å sikre brukersporbarhet.
- Vi bruker Amazon RDS til å lagre konfigurasjonen av datanettverket. Vi logger spørringer mot RDS-databasen. Sammen med CloudTrail lar denne loggen oss svare på spørsmålet om hvorfor en endring av en fil i Amazon S3 på et bestemt tidspunkt av en bestemt person er mulig.
- Amazon CloudWatch for å logge aktiviteter over nettet.
I tillegg til disse loggingsmekanismene, lages S3-bøttene ved å bruke følgende egenskaper:
- Bøtten er kryptert ved hjelp av server-side kryptering med AWS nøkkelstyringstjeneste (AWS KMS) og kundeadministrerte nøkler
- Amazon S3-versjon er aktivert som standard
Tilgang til dataene i NNEDH styres på gruppenivå i stedet for individuelle brukere. Gruppen tilsvarer gruppen som er definert i Novo Nordisk-kataloggruppen. For å holde styr på personen som endret dataene i datasjøene, bruker vi kildeidentitetsmekanismen som er forklart i innlegget Hvordan relatere IAM-rolleaktivitet til bedriftsidentitet.
konklusjonen
I dette innlegget viste vi hvordan Novo Nordisk bygde en moderne dataarkitektur for å fremskynde leveringen av datadrevne use cases. Den inkluderer en distribuert dataarkitektur, for å skalere bruken til petabyte-skala for over 2,000 interne brukere gjennom hele verdikjeden, samt en distribuert sikkerhets- og revisjonsarkitektur som håndterer dataansvar og sporbarhet på miljøet for å oppfylle deres samsvarskrav.
Det neste innlegget i denne serien beskriver implementeringen av distribuert datastyring og -kontroll i skala av Novo Nordisks moderne dataarkitektur.
Om forfatterne
 Jonatan Selsing er tidligere forsker med doktorgrad i astrofysikk som har vendt seg til skyen. Han er for tiden Lead Cloud Engineer hos Novo Nordisk, hvor han muliggjør data- og analysearbeidsmengder i stor skala. Med vekt på å redusere de totale eierkostnadene for skybaserte arbeidsbelastninger, samtidig som han får fullt utbytte av fordelene med skyen, designer, bygger og vedlikeholder han løsninger som muliggjør forskning for fremtidige medisiner.
Jonatan Selsing er tidligere forsker med doktorgrad i astrofysikk som har vendt seg til skyen. Han er for tiden Lead Cloud Engineer hos Novo Nordisk, hvor han muliggjør data- og analysearbeidsmengder i stor skala. Med vekt på å redusere de totale eierkostnadene for skybaserte arbeidsbelastninger, samtidig som han får fullt utbytte av fordelene med skyen, designer, bygger og vedlikeholder han løsninger som muliggjør forskning for fremtidige medisiner.
 Hassen Riahi er Sr. Data Architect ved AWS Professional Services. Han har en doktorgrad i matematikk og informatikk om datahåndtering i stor skala. Han jobber med AWS-kunder om å bygge datadrevne løsninger.
Hassen Riahi er Sr. Data Architect ved AWS Professional Services. Han har en doktorgrad i matematikk og informatikk om datahåndtering i stor skala. Han jobber med AWS-kunder om å bygge datadrevne løsninger.
 Anwar Rizal er en senior maskinlæringskonsulent basert i Paris. Han jobber med AWS-kunder for å utvikle data- og AI-løsninger for bærekraftig vekst i virksomheten deres.
Anwar Rizal er en senior maskinlæringskonsulent basert i Paris. Han jobber med AWS-kunder for å utvikle data- og AI-løsninger for bærekraftig vekst i virksomheten deres.
 Moses Arthur kommer fra en matematikk- og beregningsforskningsbakgrunn og har en doktorgrad i Computational Intelligence spesialisert i Graph Mining. Han er for tiden Cloud Product Engineer hos Novo Nordisk og bygger GxP-kompatible datainnsjøer og analyseplattformer for Novo Nordisks globale fabrikker som produserer digitaliserte medisinske produkter.
Moses Arthur kommer fra en matematikk- og beregningsforskningsbakgrunn og har en doktorgrad i Computational Intelligence spesialisert i Graph Mining. Han er for tiden Cloud Product Engineer hos Novo Nordisk og bygger GxP-kompatible datainnsjøer og analyseplattformer for Novo Nordisks globale fabrikker som produserer digitaliserte medisinske produkter.
 Alessandro Fior er Sr. Data Architect ved AWS Professional Services. Med over 10 års erfaring med å levere data- og analyseløsninger, brenner han for å designe og bygge moderne og skalerbare dataplattformer som akselererer bedrifter til å få verdi fra dataene sine.
Alessandro Fior er Sr. Data Architect ved AWS Professional Services. Med over 10 års erfaring med å levere data- og analyseløsninger, brenner han for å designe og bygge moderne og skalerbare dataplattformer som akselererer bedrifter til å få verdi fra dataene sine.
 Kumari Ramar er en Agile-sertifisert og PMP-sertifisert Senior Engagement Manager hos AWS Professional Services. Hun leverer data- og AI/ML-løsninger som øker hastigheten på analyse og maskinlæringsmodeller på tvers av systemer, som gjør det mulig for bedrifter å ta datadrevne beslutninger og drive nye innovasjoner.
Kumari Ramar er en Agile-sertifisert og PMP-sertifisert Senior Engagement Manager hos AWS Professional Services. Hun leverer data- og AI/ML-løsninger som øker hastigheten på analyse og maskinlæringsmodeller på tvers av systemer, som gjør det mulig for bedrifter å ta datadrevne beslutninger og drive nye innovasjoner.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/how-novo-nordisk-built-a-modern-data-architecture-on-aws/
- 000
- 10
- 100
- a
- I stand
- Om oss
- ABSTRACT
- sammendrag
- akselerere
- adgang
- Tilgang til data
- Tilgang
- Ifølge
- Logg inn
- ansvarlighet
- kontoer
- tvers
- handlinger
- aktive
- Aktiviteter
- aktivitet
- tilpasse
- la til
- tillegg
- Ytterligere
- administrasjon
- vedta
- fordeler
- Etter
- mot
- byrå
- smidig
- AI
- AI / ML
- Alle
- tillater
- Amazon
- Amazon RDS
- analytikere
- analytics
- og
- besvare
- Apache
- api
- Søknad
- applikasjonsspesifikk
- søknader
- anvendt
- godkjenning
- arkitektur
- rundt
- Eiendeler
- assosiert
- astrofysikk
- attributter
- revisjon
- revisjon
- Aurora
- autorisasjon
- Automatisering
- AWS
- AWS Lim
- AWS profesjonelle tjenester
- tilbake
- bakgrunn
- basert
- fordi
- nytte
- BEST
- Bedre
- mellom
- Bunn
- grenser
- Breaking
- broer
- bygge
- Bygning
- bygger
- bygget
- innebygd
- virksomhet
- business intelligence
- som heter
- Samtaler
- evner
- saken
- saker
- katalog
- sentral
- sentralisert
- Sertifisert
- kjede
- utfordringer
- endring
- valg
- klasser
- klassifisering
- Klinisk
- kliniske studier
- Lukke
- tett
- Cloud
- samarbeide
- samarbeid
- samarbeids
- samle
- samling
- kombinasjon
- kombinasjoner
- kombinert
- Kom
- Selskaper
- Selskapet
- samsvar
- komponenter
- komponert
- Omfattet
- kompromittere
- Beregn
- datamaskin
- informatikk
- konseptuelle
- Konfigurasjon
- tilkoblet
- Tilkobling
- konstruere
- konsulent
- forbruke
- forbruker
- Forbrukere
- forbruk
- kontekst
- kontroll
- kontrolleres
- kontroller
- Kjerne
- Bedriftens
- tilsvarer
- Kostnad
- kombinert
- opprettet
- skaperverket
- Kryss
- Gjeldende
- I dag
- skikk
- kunde
- Kunder
- dato
- data tilgang
- datainfrastruktur
- Data Lake
- Dataledelse
- databehandling
- datadeling
- datalagring
- data-drevet
- Database
- Databaser
- datasett
- Dato
- dag
- desentralisert
- avgjørelse
- Beslutningstaking
- avgjørelser
- dyp
- levere
- leverer
- levering
- distribusjon
- beskrive
- beskrivelse
- utforming
- designet
- utforme
- design
- detalj
- detaljer
- utvikle
- utviklere
- utvikler
- forskjellig
- direkte
- Funnet
- diskutere
- distinkt
- distribueres
- ikke
- domene
- domener
- ikke
- ned
- stasjonen
- drivere
- medikament
- hver enkelt
- Tidligere
- økosystem
- økosystemer
- Effektiv
- elementer
- vekt
- muliggjøre
- aktivert
- muliggjør
- muliggjør
- innkapslet
- kryptert
- kryptering
- engasjement
- ingeniør
- Ingeniørarbeid
- anriket
- sikre
- sikrer
- Enterprise
- bedrifter
- Hele
- Miljø
- miljø
- miljøer
- Eter (ETH)
- europeisk
- Event
- eksempel
- finnes
- utvidet
- erfaring
- Expert
- eksperter
- forklarte
- utsatt
- trekke ut
- fabrikker
- Egenskaper
- Figur
- filet
- Filer
- økonomisk
- Først
- fleksibilitet
- flyten
- fokuserer
- etter
- følger
- mat
- Food and Drug Administration
- format
- formasjon
- Tidligere
- Fundament
- Rammeverk
- Frihet
- fra
- fullt
- funksjonalitet
- framtid
- general
- genererer
- få
- få
- Gi
- gir
- Giving
- Global
- Go
- god
- styresett
- innvilge
- tilskudd
- graf
- Gruppe
- Grow
- veilede
- retningslinjer
- håndtere
- Håndtering
- skjedde
- å ha
- holder
- vert
- Hvordan
- Hvordan
- HTML
- HTTPS
- IAM
- Identitet
- gjennomføring
- implementert
- implementere
- redskaper
- viktig
- forbedret
- in
- inkludere
- inkluderer
- Inkludert
- Øke
- uavhengig
- indekser
- individuelt
- industri
- informasjon
- Infrastruktur
- Innovasjon
- innovasjoner
- innsikt
- i stedet
- instrument
- integrert
- integritet
- Intelligens
- Interface
- grensesnitt
- intern
- introdusere
- introdusert
- IT
- selv
- reise
- JSON
- Hold
- nøkkel
- Vet
- innsjø
- landskap
- stor
- storskala
- lag
- lag
- føre
- ledende
- LÆRE
- læring
- Nivå
- nivåer
- Begrenset
- linjer
- lenker
- plassering
- langsiktig
- maskin
- maskinlæring
- laget
- Hoved
- opprettholder
- gjøre
- Making
- administrer
- fikk til
- ledelse
- Management Solution
- leder
- Ledere
- administrerende
- Mandat
- obligatorisk
- produksjon
- mange
- Marketing
- matematikk
- Saken
- midler
- mekanisme
- medisinsk
- legemiddel
- medium
- Møt
- nevnt
- metadata
- metode
- Microsoft
- kunne
- millioner
- minimal
- Gruvedrift
- mangler
- modell
- modeller
- Moderne
- modifikasjoner
- modifisert
- modulære
- mer
- mest
- Mest populær
- flere
- oppkalt
- innfødt
- Trenger
- nødvendig
- behov
- nettverk
- likevel
- Ny
- nye løsninger
- neste
- Ny
- Novo Nordisk
- Antall
- gjenstander
- tilbud
- OKTA
- ONE
- organisasjon
- organisasjoner
- Organisert
- Origin
- OS
- Annen
- andre
- samlet
- egen
- eide
- eieren
- eiere
- eierskap
- eier
- paris
- parti
- lidenskapelig
- pasienter
- Mønster
- mønstre
- Likemann til likemann
- tillatelse
- tillatelser
- person
- personlig
- petabyte
- Pharmaceutical
- PII
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- Politikk
- politikk
- Populær
- Portal
- porter
- mulig
- Post
- innlegg
- makt
- Power BI
- Forbered
- presentert
- primære
- Prosesser
- prosessering
- produsent
- Produkt
- Produkter
- profesjonell
- fagfolk
- egenskaper
- gi
- gir
- gi
- formål
- formål
- presset
- Sette
- kvalitet
- spørsmål
- å nå
- lesere
- mottar
- gjenkjenne
- redusere
- region
- forskrifter
- Regulatorer
- i slekt
- Relasjoner
- utgitt
- erstattet
- Repository
- representert
- anmode
- forespørsler
- krever
- påkrevd
- behov
- Krav
- forskning
- ressurs
- Ressurser
- respektert
- svar
- ansvar
- ansvarlig
- restriktiv
- Rolle
- roller
- Kjør
- rennende
- SaaS
- trygge
- salg
- samme
- skalerbarhet
- skalerbar
- Skala
- Vitenskap
- Forsker
- forskere
- Søk
- Sekund
- sekundær
- sikkerhet
- Selvbetjening
- sensitive
- Serien
- tjeneste
- Tjenester
- servering
- Session
- sesjoner
- oppsett
- flere
- deling
- bør
- Vis
- vist
- Viser
- Enkelt
- samtidig
- enkelt
- entall
- Sittende
- Størrelse
- bremser
- liten
- sosialt
- Software
- programvare som en tjeneste
- løsning
- Solutions
- noen
- kilde
- spesialisert
- spesifikk
- spesielt
- fart
- splittet
- Standard
- startet
- Tilstand
- Stater
- lagring
- oppbevare
- lagret
- Strategisk
- streber
- strukturert
- emne
- vellykket
- slik
- støtte
- Støttes
- Støtter
- bærekraftig
- Systemer
- Ta
- Target
- mål
- lag
- lag
- Teknisk
- prinsipper
- De
- Kilden
- Staten
- deres
- derfor
- Tredje
- tre
- Gjennom
- hele
- tid
- til
- sammen
- også
- verktøy
- verktøy
- Totalt
- mot
- spore
- Sporbarhet
- spor
- tradisjonelle
- oversette
- Oversettelse
- Åpenhet
- forsøk
- Triple
- sant
- Stol
- snudde
- typer
- typisk
- typisk
- oss
- Til syvende og sist
- union
- enhet
- lomper
- us
- bruk
- bruke
- Bruker
- Brukere
- verdi
- allsidig
- måter
- Web-basert
- veldefinerte
- Hva
- hvilken
- mens
- HVEM
- vil
- innenfor
- uten
- Arbeid
- arbeide sammen
- arbeidet
- arbeidsflyt
- Arbeidsplassen
- virker
- verdensomspennende
- ville
- X
- år
- zephyrnet