I denne artikkelen vil du finne ut ulike metoder for å konvertere PDF til Google Sheets.
Du vil også lære hvordan nanonetter kan automatisere hele arbeidsflyten for konvertering av PDF til Google Sheets på nett.
Før vi ser på hvordan du konverterer PDF til Google Sheets, la oss ta en titt på hvorfor det er viktig å gjøre dette.
Hvorfor konvertere PDF-filer til Google Sheets?
Ifølge denne Google blogg innlegg fra den offisielle Google-bloggsiden, bruker mer enn 5 millioner bedrifter deres G Suite-løsning. Samtidig har et stort antall selskaper også tatt i bruk Google Sheets-integrasjoner for å automatisere oppgaver.
La oss vurdere et typisk brukstilfelle. Kreditorteamet ditt mottar en faktura i standard PDF-format. Noen går manuelt gjennom fakturaen og taster inn den nødvendige informasjonen til et Google Sheets-dokument før de videresender det til finansdelen. Økonomiseksjonen betaler din leverandør og fører en oppføring i selskapets reskontro.
Bortsett fra å være en langvarig prosess, er dette feilutsatt, og det ville være mye mer fornuftig å bare automatisere den.
Nå som behovet for å konvertere PDF-er til et Google-arkskjema er klart, la oss ta en titt på hvordan PDF-dokumenter er strukturert og hva utfordringene er ved å analysere dem.
Ønsker å konvertere PDF filer til Google Sheets ? Sjekk ut Nanonets ' gratis PDF til CSV-konvertering. Eller finn ut hvordan automatiser hele PDF-en til Google Sheets-arbeidsflyten med Nanonets.
Utfordringer med å analysere et PDF-dokument
Det bærbare dokumentformatet var et filformat som opprinnelig ble utviklet av Adobe og ble senere utgitt som en åpen standard. Det har siden blitt bredt adoptert ettersom det er agnostisk for det underliggende operativsystemet.
Så hvorfor er det så utfordrende å analysere en PDF og konvertere innholdet til et annet format? Følgende bilder sier mer enn tusen ord og vil føre poenget hjem.
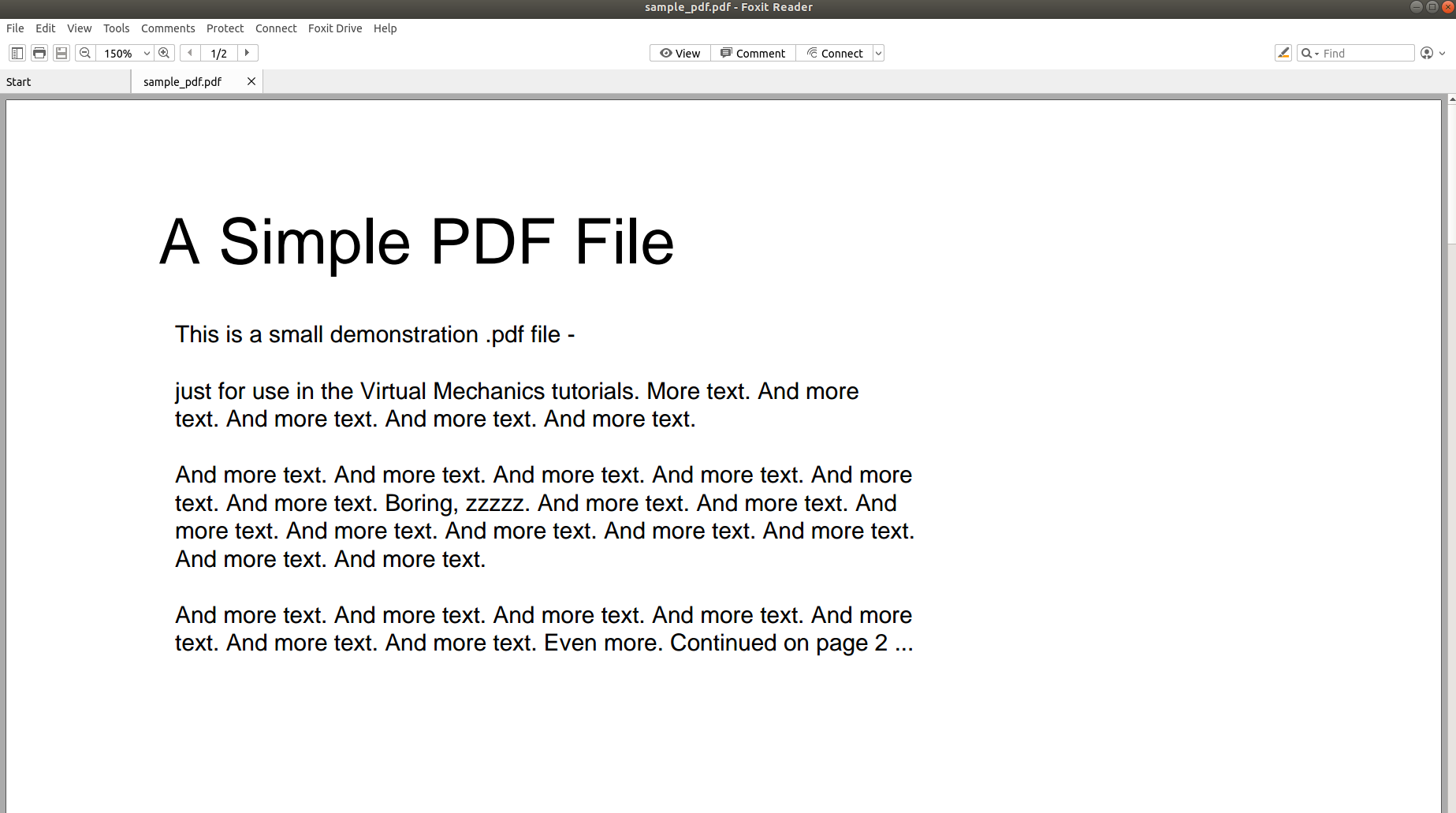
Bildet ovenfor viser skjermbildet av et PDF-dokument som åpnes ved hjelp av en PDF-leser. La oss prøve å åpne det samme PDF-dokumentet med et tekstredigeringsprogram.
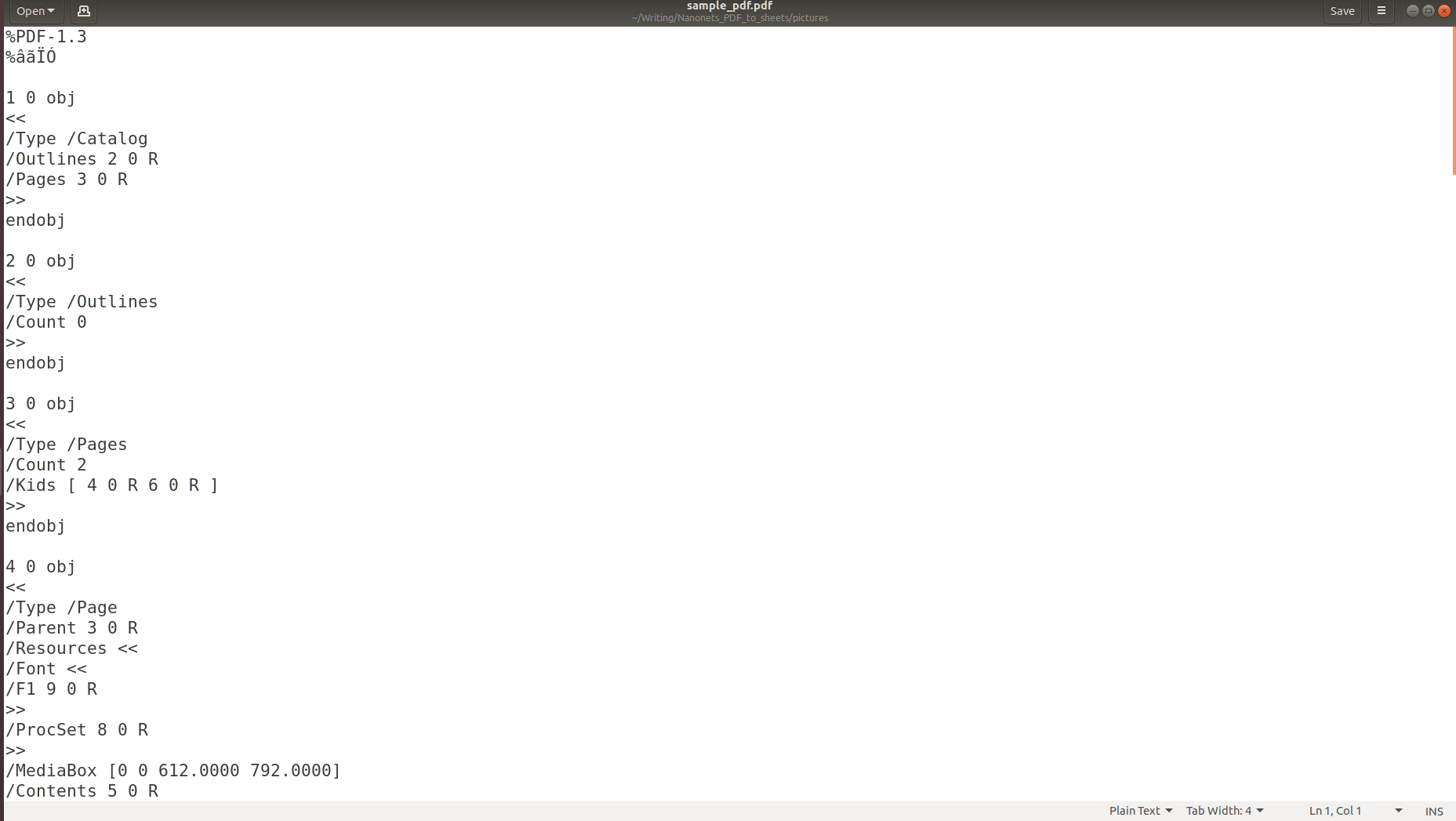
Bildene ovenfor gjør det klart at når informasjon lagres i en PDF, går den opprinnelige strukturen fullstendig tapt. Dette er fordi PDF-formatet ganske enkelt består av instruksjoner om hvordan du skriver ut/tegner en sekvens av tegn på en side.
Hvis du synes at tekstutvinning er vanskelig, er det enda mer utfordrende å trekke ut dataene i tabeller på grunn av vidt forskjellige tabellformater som brukes.
Forhåpentligvis er du overbevist om at å konvertere et PDF-dokument til et Google Sheets-skjema ikke er en tur i parken. Den neste delen snakker om tilnærmingen som brukes av de fleste moderne PDF-parsere for å gjenkjenne/tolke informasjon fra et PDF-dokument.
Den moderne tilnærmingen til å analysere PDF-dokumenter
De fleste moderne PDF-parsere bruker flyten beskrevet nedenfor for å analysere ustrukturerte data fra PDF-dokumenter.
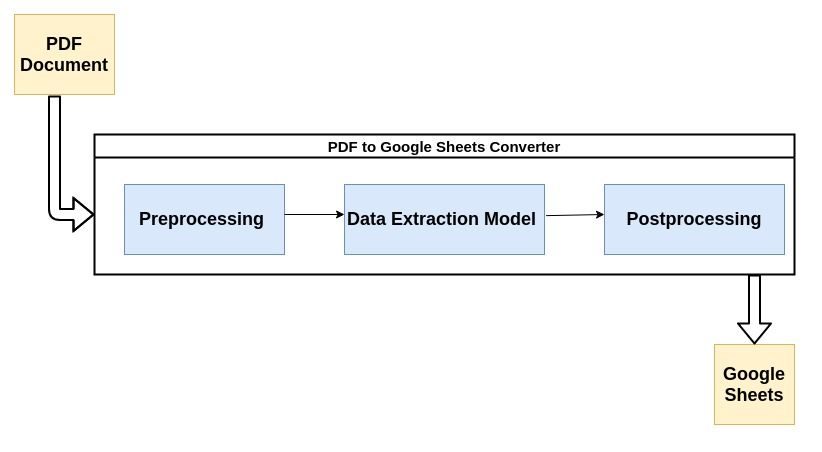
La oss kort ta en titt på hvert trinn i prosessen:
1. Forbehandling eller datarensing:
Jo bedre PDF-en din ser ut, jo lettere blir det for Machine Learning-modellen din å trekke ut eller fange data fra det. For eksempel, hvis PDF-dokumentet har blitt skannet, er det bundet til å inneholde noen skanneartefakter som kan påvirke ytelsen til konverteringsprogrammet.
Fjerning av støy ved å bruke passende filtre, binarisering, skjevkorrigering osv. er noen av de vanligste forbehandlingstrinnene. Følgende Nanonets-innlegg Nanonets Tesseract Post inneholder noen gode eksempler på hvordan dokumenter kan forhåndsbehandles før Optical Character Recognition(OCR) kjøres på dem.
Det er her det meste av magien skjer. Datautvinning utføres vanligvis av en maskinlæringsmodell (ML). De fleste ML-modeller som brukes for datautvinning fra PDF-er inneholder en kombinasjon av optiske tegngjenkjenningsverktøy, tekst- og mønstergjenkjenningsverktøy etc.
For formålet med dette innlegget kan vi behandle modellen som en svart boks som tar PDF-dokumentet ditt som input og spytter ut den analyserte informasjonen. Siden den bruker ML i kjernen, kan den også omskoles med tilpassede data for å passe bedriftens brukssituasjon.
3. Etterbehandling:
I dette trinnet konverteres de utpakkede dataene til det nødvendige formatet som CSV, XML, JSON osv. I tillegg legges flere brukerdefinerte regler på toppen av spådommene laget av AI. Dette kan inkludere regler for formatering av utdata, ytterligere begrensninger på informasjon som trekkes ut osv.
Den følgende delen ser på noen beregninger som vi kan bruke for å måle ytelsen til en PDF-parser.
Ønsker å konvertere PDF filer til Google Sheets ? Sjekk ut Nanonets ' gratis PDF til CSV-konvertering. Finn ut hvordan du automatiserer hele PDF-en til Google Sheets-arbeidsflyten med Nanonets.

Beregninger for å måle ytelsen til en PDF-konvertering
Siden de fleste PDF-konverterere vil bli brukt til fakturabehandling eller relaterte oppgaver, er nøyaktigheten og hastigheten på tabelluttak fra et PDF-dokument en kritisk faktor for å bedømme ytelsen til PDF-konverteringen.
2. Flerspråklig evne:
De fleste store bedrifter er forpliktet til å motta fakturaer på en rekke forskjellige språk. PDF-parseren skal enten støtte flerspråklig parsing ut av esken, eller den skal gi et alternativ der brukere kan trene modellen ved å bruke tilpassede data.
3. Integrasjon med regnskapsprogramvare:
Den ideelle PDF-konvertereren bør være en plug and play-modul som enkelt kan legges til din eksisterende dokumentarbeidsflyt. Den skal støtte integrasjon med populær regnskapsprogramvare som QuickBooks, Xero, Wave etc.
4. Enkelt og intuitivt:
Verktøyet vil mest sannsynlig bli betjent av ikke-tekniske brukere. Det vil være en fordel om det kan betjenes med minimal teknisk kunnskap.
Ulike metoder for å konvertere PDF-filer til Google Sheets
1. Bruke Google Dokumenter til å konvertere PDF til Google Sheets
Google Disk har innebygd evne til å gjenkjenne tabeller og tekst i enkle PDF-dokumenter. Du trenger bare å:
-
Last opp PDF-filen til Google Disk
-
Klikk "Åpne med Google Dokumenter"
-
Kopier dataene du ønsker og lim inn i Google Regneark
Selv om det ser ut til å fungere bra, la oss prøve noe mer praktisk. Tenk på denne enkle fakturaen.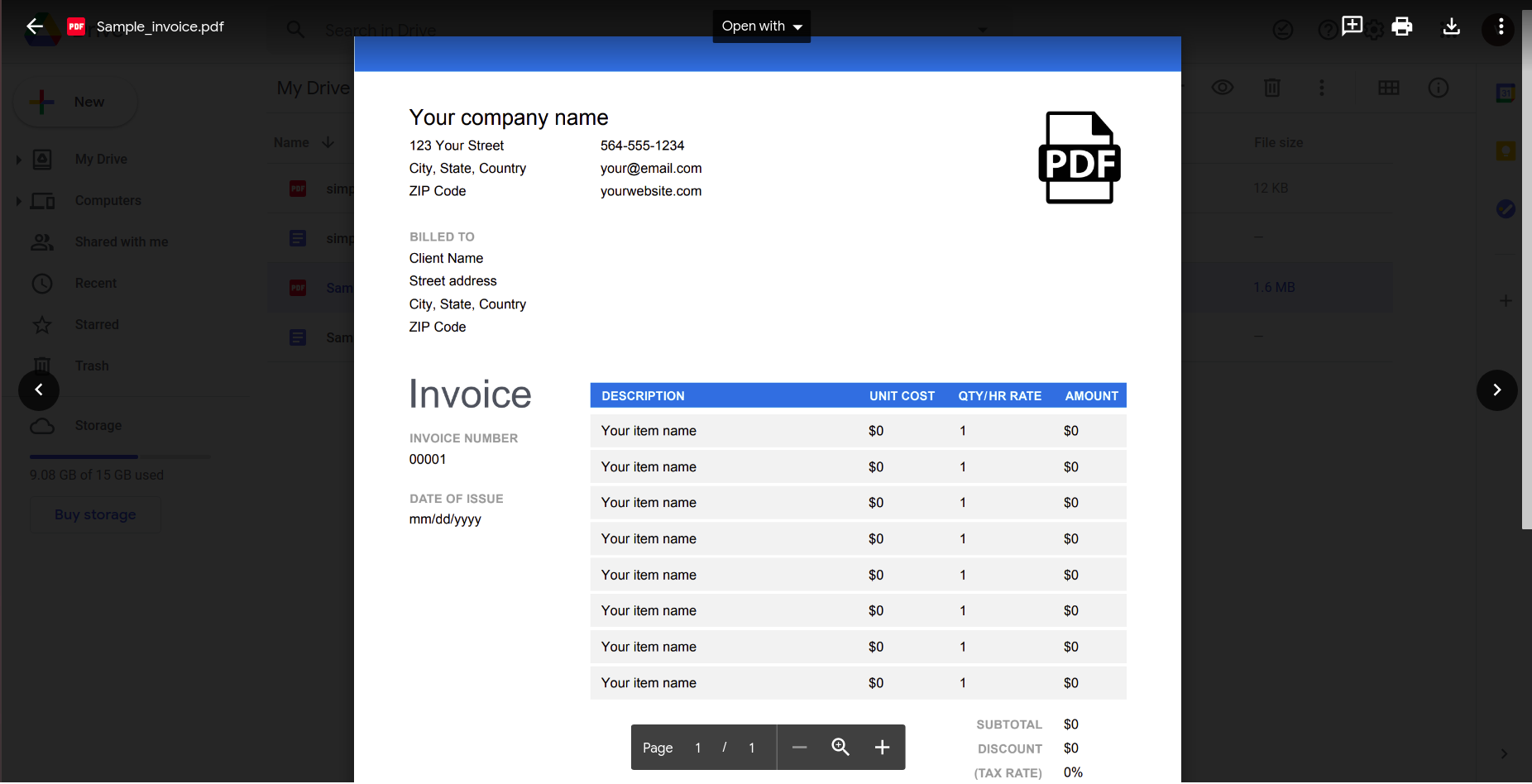
Åpning av denne ved hjelp av Google docs-applikasjonen gir følgende resultat.
Når kompleksiteten til dokumentet øker, må vi tydeligvis stole på mer sofistikerte verktøy for å gjenkjenne data.
2. Bruke nettbaserte verktøy:
Flere nettbaserte verktøy som PDF-tabelluttrekker, Online2PDF osv., integreres direkte med Google Disk og gir mulighet til å konvertere PDF-dokumenter til Google Sheets.
Men da disse verktøyene ble testet ved hjelp av eksempelfaktura-PDFen vist ovenfor, ble ikke tabellene oppdaget i de fleste tilfellene.
Ønsker å konvertere PDF filer til Google Sheets ? Sjekk ut Nanonets ' gratis PDF til CSV-konvertering. Finn ut hvordan du automatiserer hele PDF-en til Google Sheets-arbeidsflyten med Nanonets som vist nedenfor.
Automatisering av konverteringsprosessen fra PDF til Google Sheets
Vi kan fullstendig automatisere prosessen med å analysere PDF-en og trekke ut dataene til et Google Sheets-skjema ved å bruke følgende verktøy.
1. Bruke Webhooks:
Webhooks er egendefinerte HTTP-forespørsler. De utløses vanligvis på en hendelse, dvs. når en hendelse inntreffer, sender applikasjonen informasjon til en forhåndsdefinert URL.
Hvordan kan du bruke dette til å automatisere arbeidsflyten din? La oss vurdere den typiske brukssaken for fakturabehandling. Du mottar en rekke fakturaer fra leverandørene dine og mater dem inn i PDF-til-Google Sheets-konverteringsprogrammet som ligger i skyen. Hvordan vet du når modellen er ferdig med å behandle dokumentene?
I stedet for manuelt å sjekke om konverteringen er fullført, kan du ganske enkelt bruke en webhook som varsler deg når dataene i PDF-en er trukket ut til et Google Sheets-dokument.
2. Bruke APIer
API står for Application Programming Interface. Ved å bruke de riktige API-kallene kan det vise seg å være like enkelt å konvertere PDF-dokumenter til Google Sheets som å skrive følgende kodelinjer:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Hvis bedriften din allerede har satt opp integrasjonen med Webhooks, vil du motta et varsel når PDF-dokumentene dine har blitt konvertert. Du kan deretter laste ned Google Sheets-skjemaet ved å bruke API-en vist nedenfor.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF til Google Sheets med nanonetter
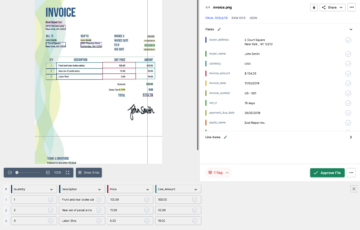
Nanonets PDF-parser gjør analysering og konvertering enkel og nøyaktig. PDF-parseren ble brukt til å analysere en eksempelfaktura. Denne delen viser brukervennligheten og nøyaktigheten til verktøyet. I stedet for å snakke om hvor flott det er, illustrerer de følgende bildene poenget.
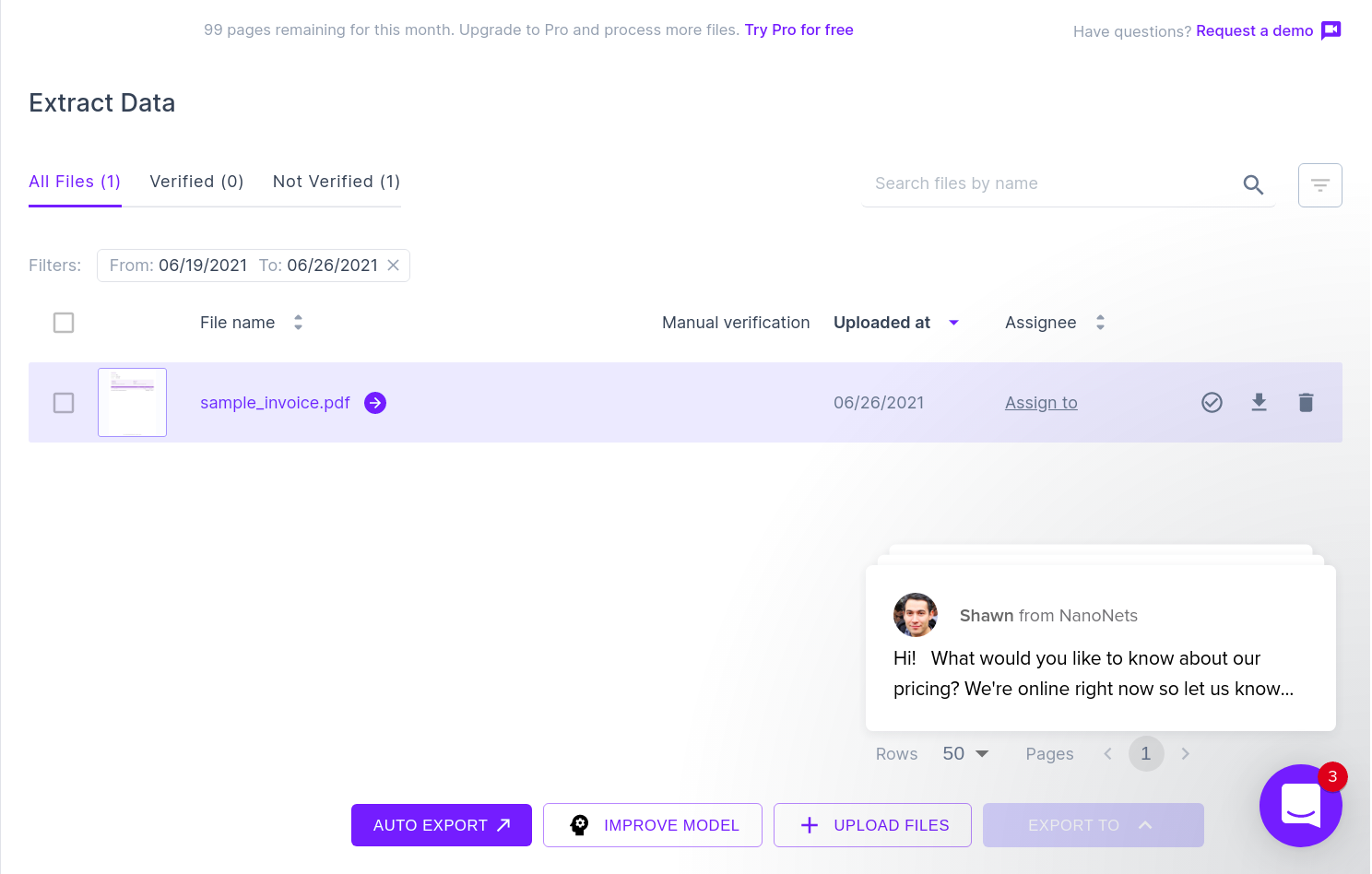
Bildet nedenfor er et skjermbilde av eksempelfakturaen som ble matet til Nanonets PDF-parser.
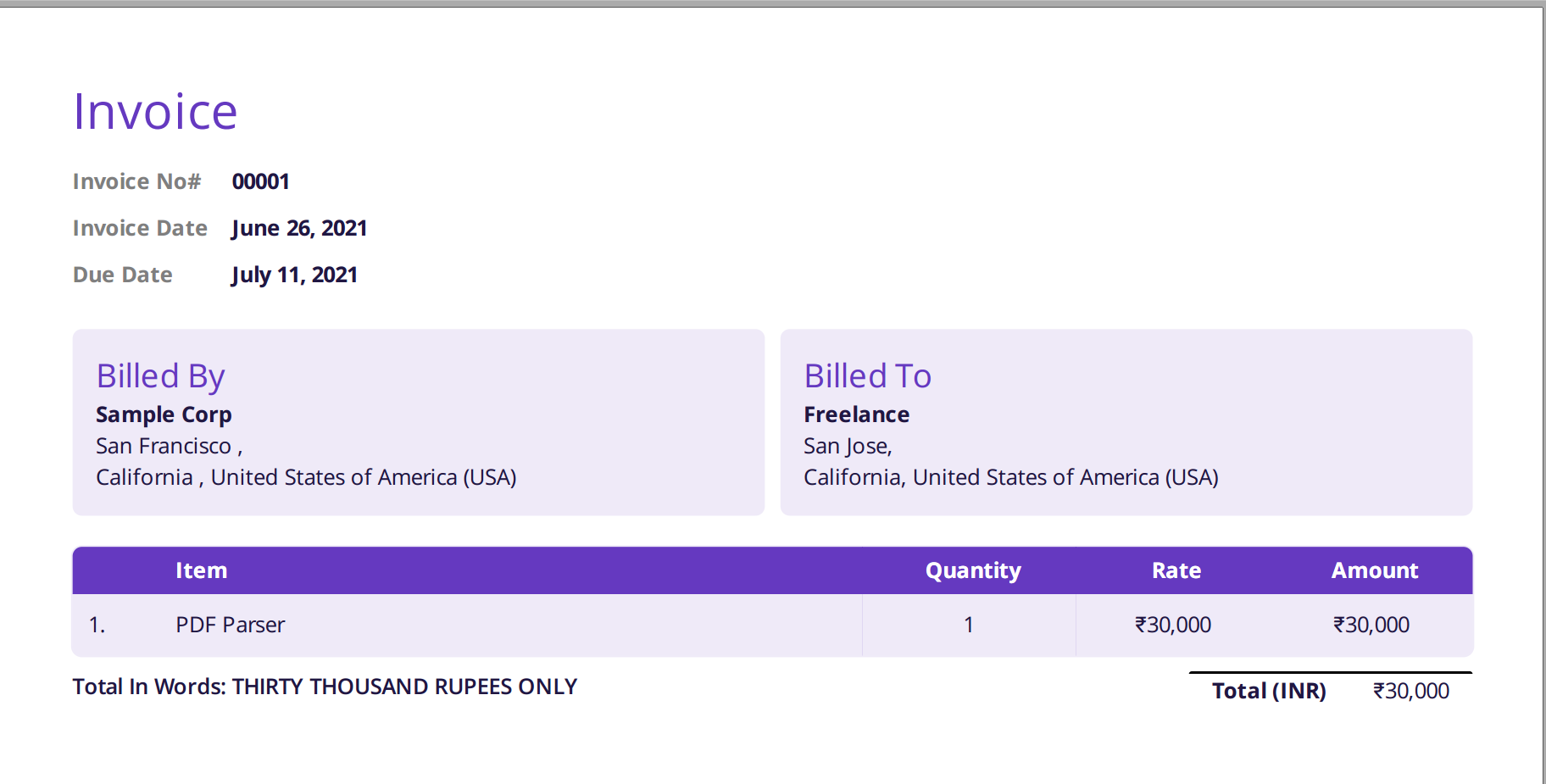
Bare naviger til Nanonets-nettstedet og last opp fakturaen. Konverteringen tar bare noen få sekunder, og deretter kan de analyserte dataene lastes ned i en rekke formater, for eksempel CSV, XLSX osv. (sjekk ut Nanonets' PDF til CSV-konvertering)
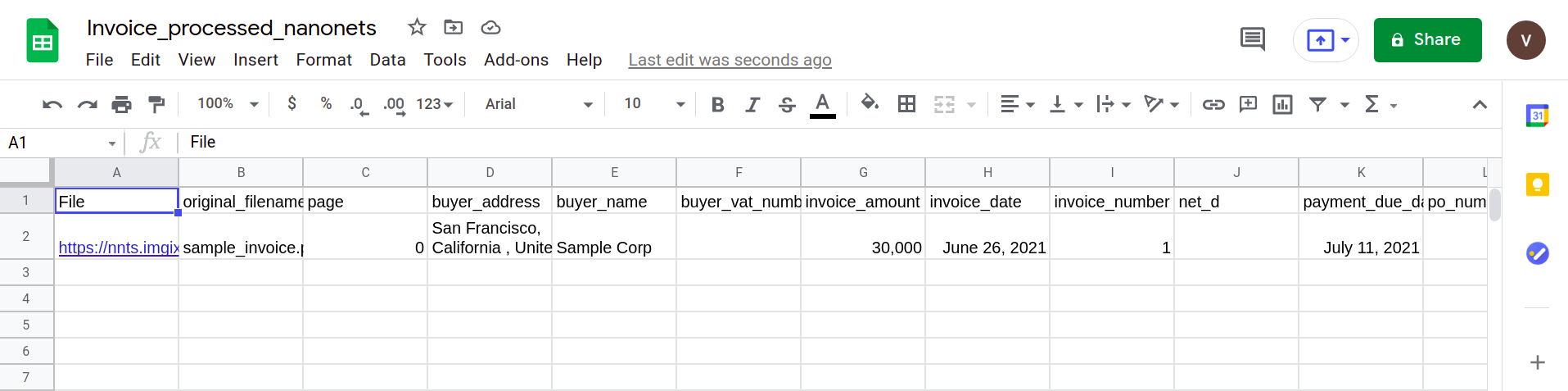
Det neste bildet viser et skjermbilde av CSV-filen som inneholder de analyserte dataene fra PDF-dokumentet.

Til slutt, for å konvertere CSV-filen til et Google Sheets-skjema, er det ganske enkelt et spørsmål om å laste opp XLSX/CSV-filen til Google Drive. Dette trinnet kan automatiseres ved å bruke Google Drive API-er.
Den følgende delen viser hvordan en enkel pipeline kan lages ved å bruke Nanonets PDF-parser.
Vil du trekke ut informasjon fra PDF-dokumenter og konvertere/legge dem til et Google Sheets-dokument? Sjekk ut Nanonetter™ for å automatisere eksport av all informasjon fra et PDF-dokument til Google Sheets!
Opprette en enkel rørledning
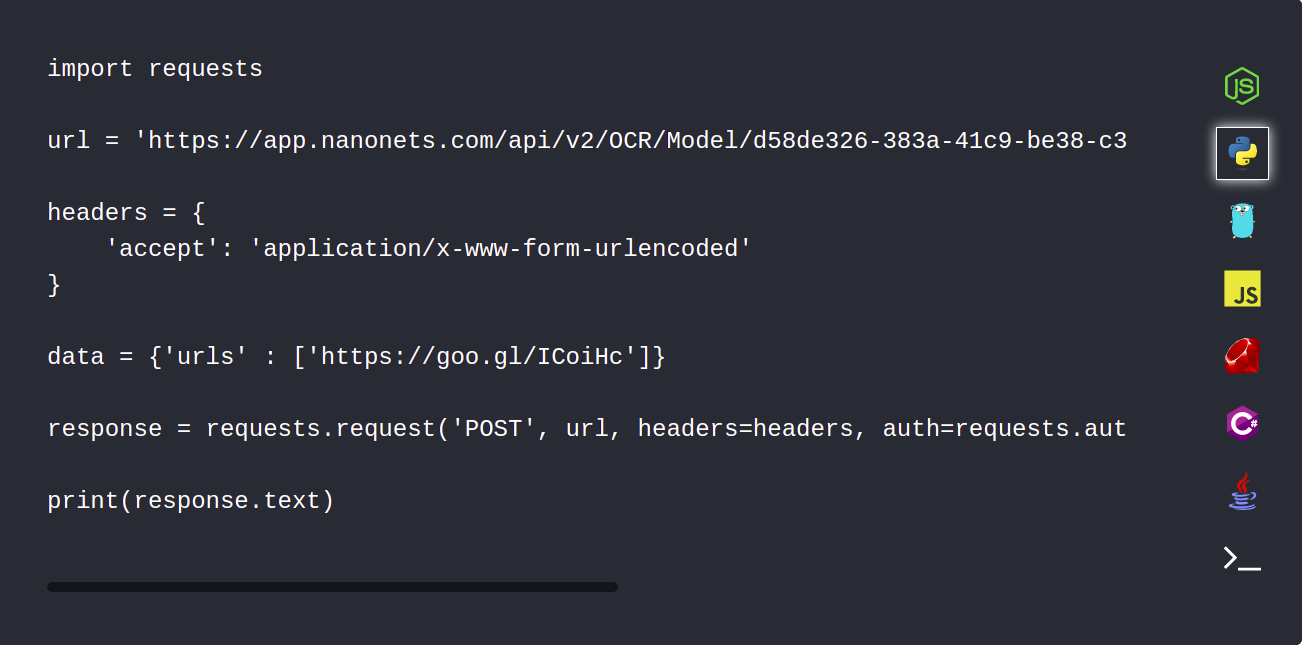
1. Last opp PDF-dokumentene dine automatisk ved hjelp av Nanonets API
Nanonets API lar deg automatisk laste opp dokumentene dine som må analyseres. Følgende kodebit viser hvordan dette kan gjøres ved hjelp av python.
2. Bruk webhooks-integrasjon for å motta et varsel når parsingen er fullført
Webhooks kan konfigureres til å varsle deg automatisk når dokumentene har blitt analysert.
3. Se gjennom og last opp til Google Regneark
Last ned og se gjennom CSV-filene for å sikre at alt er i orden, og last opp dataene til Google Sheets ved hjelp av Google Drive API.
The Nanonets Edge
Her er noen funksjoner i Nanonets PDF Parser som gjør den til det ideelle verktøyet for virksomheten din.
1. Eksterne integrasjoner:
Nanonettmodellen kan enkelt integreres med MySql, Quickbooks, Salesforce etc. Dette betyr at din nåværende arbeidsflyt forblir uforstyrret og nanonettkonverteren kan enkelt plugges inn som en tilleggsmodul.
2. Høy nøyaktighet og lave behandlingstider:
Nanonets PDF-parserverktøyet har en nøyaktighet på over 95%+ som er mye høyere sammenlignet med konkurrentene.
3. Kule etterbehandlingsfunksjoner:
Anta at databasen din er integrert med nanonnettmodellen. Modellen fyller automatisk ut noen felt (med data fra databasen din) basert på dataene som er hentet ut fra dokumentet. For eksempel:
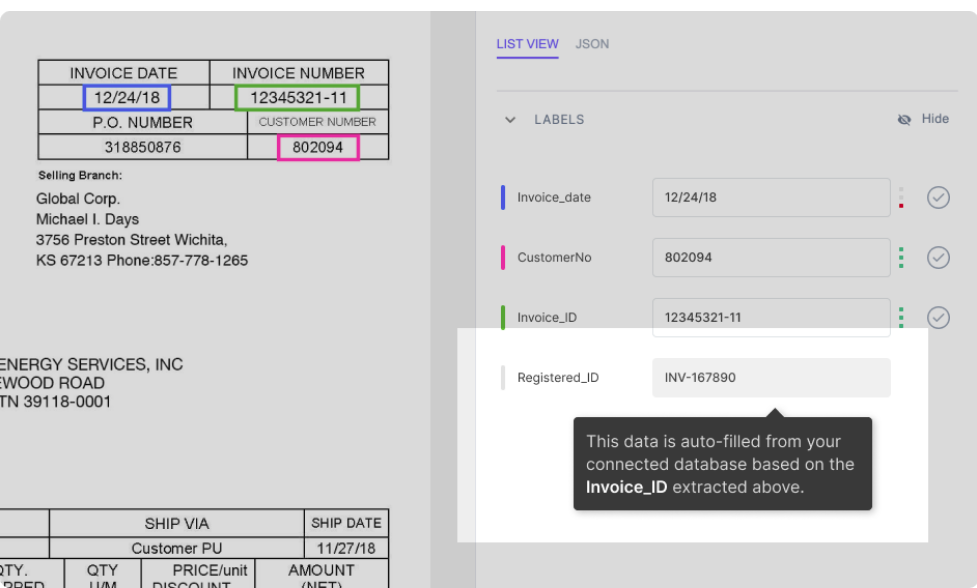
Som vist i figuren fylles feltet Registered_ID automatisk (ved et databaseoppslag) basert på Invoice_ID som trekkes ut fra PDF-en.
4. Enkelt og intuitivt grensesnitt
Selv om denne funksjonen er undervurdert, syntes jeg at brukergrensesnittet og UX var perfekt. Hele prosessen med å registrere seg, laste opp dokumentet og analysere dataene tok mindre enn 5 minutter. Det er nesten lik tiden min bærbare datamaskin bruker på å starte opp!
5. Stor kundebase
Hvis du fortsatt har forbehold om å bruke Nanonets for å automatisere arbeidsflyten din, er det bare å ta en titt på noen av selskapene som bruker tjenestene deres.
- Deloitte
- Sherwin Williams
- DoorDash
- P&G
Vil du trekke ut informasjon fra PDF-dokumenter og konvertere/legge dem til et Google Sheets-dokument? Sjekk ut Nanonetter™ for å automatisere eksport av all informasjon fra et PDF-dokument til Google Sheets!
konklusjonen
I dette innlegget tok vi en titt på hvordan du kan automatisere arbeidsflyten din ved å bruke en PDF til Google Sheets-konvertering. Til å begynne med lærte vi om behovet for å konvertere PDF-dokumenter til Google Sheets, etterfulgt av utfordringene i denne prosessen. Vi dykket deretter ned i tilnærmingene brukt av moderne parsere for å analysere PDF-dokumenter og implementerte også noen av de vanlige tilnærmingene. Vi lærte også hvordan vi kan fullstendig automatisere konverteringen ved hjelp av eksterne integrasjoner som webhooks og APIer. Til slutt brukte vi Nanonets-verktøyet for å analysere en eksempelfaktura, trekke ut dataene til et Google Sheets-skjema og også utforsket noen av de kule etterbehandlingsfunksjonene.
Har du gitt Nanonets-modellen en sjanse? I så fall, legg igjen en kommentar nedenfor angående din erfaring med verktøyet. Hvis ikke, fortsett og prøv det. Det kan bare gjøre dagen din!
- AI
- AI og maskinlæring
- ai kunst
- ai art generator
- du har en robot
- kunstig intelligens
- sertifisering av kunstig intelligens
- kunstig intelligens i bankvirksomhet
- kunstig intelligens robot
- kunstig intelligens roboter
- programvare for kunstig intelligens
- blockchain
- blockchain konferanse ai
- coingenius
- samtale kunstig intelligens
- kryptokonferanse ai
- dall sin
- dyp læring
- google det
- maskinlæring
- pdf til google sheets
- plato
- plato ai
- Platon Data Intelligence
- Platon spill
- PlatonData
- platogaming
- skala ai
- syntaks
- zephyrnet