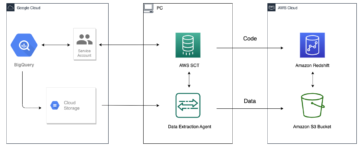
Amazon RedShift er et raskt, skalerbart, sikkert og fullt administrert datavarehus som lar deg analysere alle dataene dine ved hjelp av standard SQL enkelt og kostnadseffektivt. Amazon Redshift Datadeling lar kunder trygt dele live, transaksjonelt konsistente data i en Amazon Redshift-klynge med en annen Amazon Redshift-klynge på tvers av kontoer og regioner uten å måtte kopiere eller flytte data fra en klynge til en annen.
Amazon Redshift Data Sharing ble opprinnelig lansert i mars 2021, og lagt til støtte for datadeling på tvers av kontoer ble lagt til august 2021. Støtten på tvers av regioner ble generelt tilgjengelig i februar 2022. Dette gir full fleksibilitet og smidighet til å dele data på tvers av Redshift-klynger i samme AWS-konto, forskjellige kontoer eller forskjellige regioner.
Amazon Redshift Data Sharing brukes til å fundamentalt omdefinere Amazon Redshift-distribusjonsarkitekturer til en hub-eiker, datamaskeringsmodell for å bedre møte ytelses-SLAer, gi arbeidsbelastningsisolering, utføre analyser på tvers av grupper, enkelt ta med nye brukstilfeller, og viktigst av alt. dette uten kompleksiteten med dataflytting og datakopier. Noen av de vanligste spørsmålene som stilles under distribusjon av datadeling er: "Hvor store bør forbrukerklyngene og produsentklyngene mine være?", og "Hvordan får jeg best prisytelse for isolering av arbeidsbelastning?". Siden arbeidsbelastningsegenskaper som datastørrelse, inntakshastighet, spørringsmønster og vedlikeholdsaktiviteter kan påvirke ytelsen til datadeling, bør en kontinuerlig strategi for å dimensjonere både forbruker- og produsentklynger for å maksimere ytelsen og minimere kostnadene implementeres. I dette innlegget gir vi en trinnvis tilnærming for å hjelpe deg med å bestemme størrelsen på produsent- og forbrukerklynger for den beste prisytelsen basert på din spesifikke arbeidsmengde.
Generisk veiledning for forbrukerstørrelser
De følgende trinnene viser den generiske strategien for å dimensjonere produsent- og forbrukerklyngene dine. Du kan bruke det som et utgangspunkt og endre tilsvarende for å imøtekomme ditt spesifikke bruksscenario.
Dimensjoner produsentklyngen din
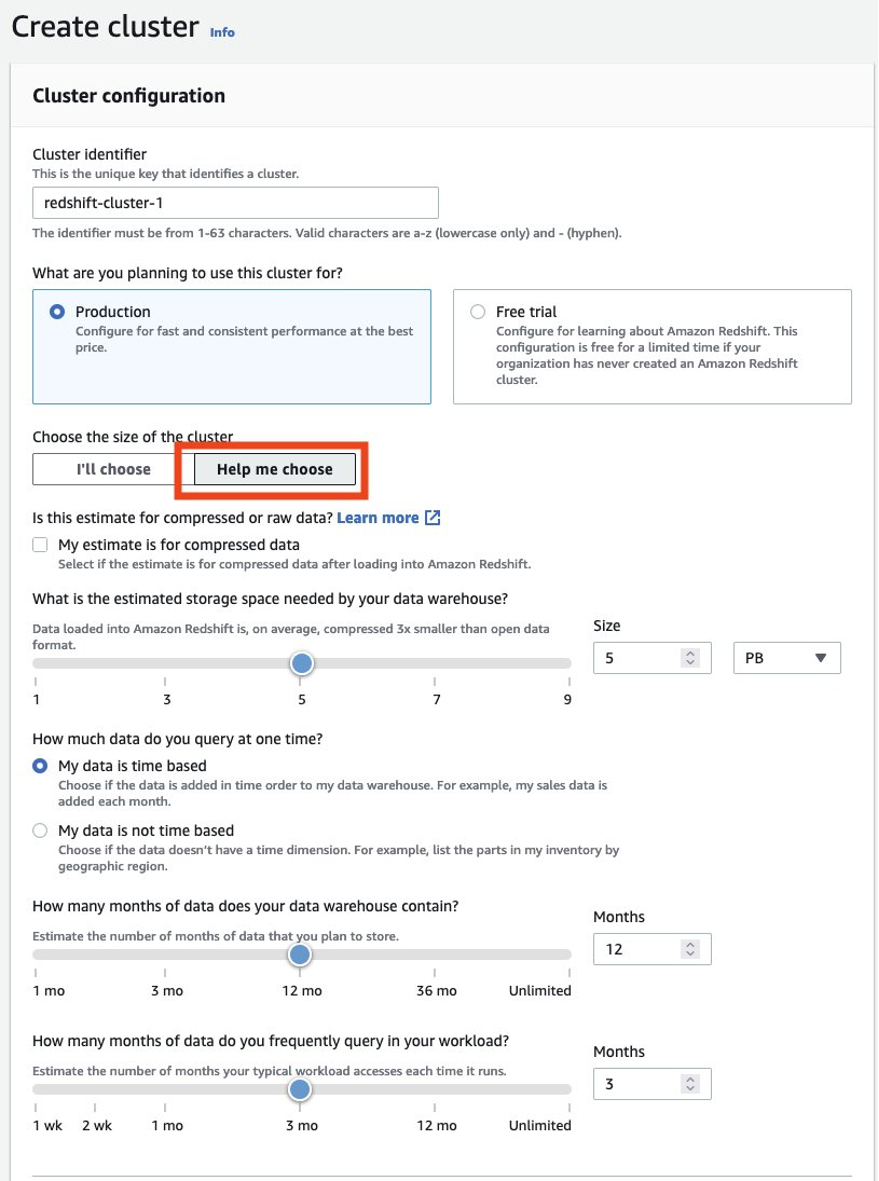
Du bør alltid sørge for at du dimensjonerer produsentklyngen riktig for å få ytelsen du trenger for å oppfylle SLA. Du kan bruke størrelseskalkulatoren fra Amazon Redshift-konsollen for å få en anbefaling for produsentklyngen basert på størrelsen på dataene dine og søkekarakteristikken. Se etter Hjelp meg å velge på konsollen i AWS-regioner som støtter RA3-nodetyper for å bruke denne størrelseskalkulatoren. Merk at dette bare er en innledende anbefaling for å komme i gang, og du bør teste å kjøre hele arbeidsmengden på den opprinnelige størrelsesklyngen og elastisk endre størrelsen på klyngen opp og ned tilsvarende for å få best prisytelse.
Størrelse og oppsett innledende forbrukerklynge
Du bør alltid dimensjonere forbrukerklyngen basert på dine databehov. En måte å komme i gang på er å følge den generelle veiledningen for klyngestørrelser som ligner på produsentklyngen ovenfor.
Konfigurer Amazon Redshift-datadeling
Sett opp datadeling fra produsent til forbruker når du har både produsent- og forbrukerklyngeoppsettet. Viser til dette poste for veiledning om hvordan du setter opp datadeling.
Test kun arbeidsbelastning for forbruker på den første forbrukerklyngen
Test kun arbeidsbelastning for forbruker på den nye første forbrukerklyngen. Dette kan gjøres ved å peke forbrukerapplikasjoner, for eksempel ETL-verktøy, BI-applikasjoner og SQL-klienter, til den nye forbrukerklyngen og kjøre arbeidsmengden på nytt for å evaluere ytelsen mot dine krav.
Test kun arbeidsbelastning for forbruker på forskjellige forbrukerklyngekonfigurasjoner
Hvis den opprinnelige størrelsen på forbrukerklyngen oppfyller eller overgår ytelseskravene dine for arbeidsbelastning, kan du enten fortsette å bruke denne klyngekonfigurasjonen eller du kan teste på mindre konfigurasjoner for å se om du kan redusere kostnadene ytterligere og fortsatt få ytelsen du trenger.
På den annen side, hvis den opprinnelige størrelsen på forbrukerklyngen ikke oppfyller ytelseskravene dine for arbeidsbelastning, kan du teste større konfigurasjoner videre for å få konfigurasjonen som oppfyller SLAen din.
Som en tommelfingerregel kan du øke forbrukerklyngen med 2x den opprinnelige klyngekonfigurasjonen trinnvis til den oppfyller arbeidsbelastningskravene dine.
Når du planlegger hvilken konfigurasjon du vil teste, bruker du elastisk størrelse for å endre størrelsen på den opprinnelige klyngen til målklyngekonfigurasjonen. Etter at elastisk endring av størrelse er fullført, utfør den samme arbeidsbelastningstesten og evaluer ytelsen mot SLAen din. Velg konfigurasjonen som oppfyller prisytelsesmålet ditt.
Arbeidsbelastning kun for testprodusent på forskjellige produsentklyngekonfigurasjoner
Når du flytter forbrukerarbeidsmengden til forbrukerklyngen med optimal prisytelse, kan det være en mulighet for å redusere beregningsressursen på produsenten for å spare kostnader.
For å oppnå dette kan du kjøre arbeidsbelastningen for produsenten på nytt på 1/2x av den opprinnelige produsentens størrelse og evaluere arbeidsbelastningsytelsen. Endre størrelsen på klyngen opp og ned tilsvarende avhenger av resultatet, og deretter velger du minimum produsentkonfigurasjon som oppfyller ytelseskravene for arbeidsbelastning.
Reevaluer etter en full arbeidsbelastning over tid
Ettersom Amazon Redshift fortsetter å utvikle seg, og det er kontinuerlige utgivelser av ytelse og skalerbarhetsforbedring, vil ytelsen for datadeling fortsette å bli bedre. Videre kan en rekke variabler påvirke ytelsen til datadelingsspørringer. Følgende er bare noen eksempler:
- Inntakshastighet og datamengde endres
- Spørremønster og karakteristikk
- Arbeidsmengdeendringer
- samtidighet
- Vedlikeholdsaktiviteter, for eksempel vakuum, analyser og ATO
Dette er grunnen til at du må revurdere produsent- og forbrukerklyngestørrelsen ved å bruke strategien ovenfor av og til, spesielt etter en full arbeidsbelastning, for å oppnå den nye beste prisytelsen fra klyngens konfigurasjon.
Automatiserte dimensjoneringsløsninger
Hvis miljøet ditt involverte mer kompleks arkitektur, for eksempel med flere verktøy eller applikasjoner (BI, inntak eller streaming, ETL, datavitenskap), kan det hende at det ikke er mulig å bruke den manuelle metoden fra den generelle veiledningen ovenfor. I stedet kan du utnytte løsninger i denne delen for automatisk å spille av arbeidsbelastningen fra produksjonsklyngen på testforbruker- og produsentklyngene for å evaluere ytelsen.
Enkelt Replay-verktøy vil bli utnyttet som den automatiserte løsningen for å veilede deg gjennom prosessen med å få riktig produsent- og forbrukerklyngestørrelse for best prisytelse.
Simple Replay er et verktøy for å utføre en hva-hvis-analyse og evaluere hvordan arbeidsmengden din presterer i ulike scenarier. Du kan for eksempel bruke verktøyet til å måle den faktiske arbeidsbelastningen din på en ny forekomsttype som RA3, evaluere en ny funksjon eller vurdere forskjellige klyngekonfigurasjoner. Den inkluderer også forbedret støtte for avspilling av datainntak og eksportrørledninger med COPY- og UNLOAD-setninger. For å komme i gang og spille av arbeidsbelastningene dine, last ned verktøyet fra Amazon Redshift GitHub-depot.
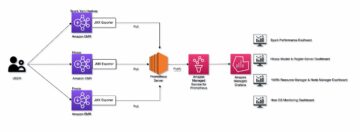
Her går vi gjennom trinnene for å trekke ut arbeidsbelastningsloggene fra kildeproduksjonsklyngen og spille dem på nytt i et isolert miljø. Dette lar deg utføre en direkte sammenligning mellom disse Amazon Redshift-klyngene sømløst og velge klyngekonfigurasjonen som best oppfyller prisytelsesmålet ditt.
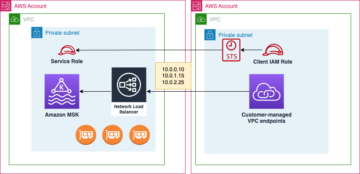
Følgende diagram viser løsningsarkitekturen.
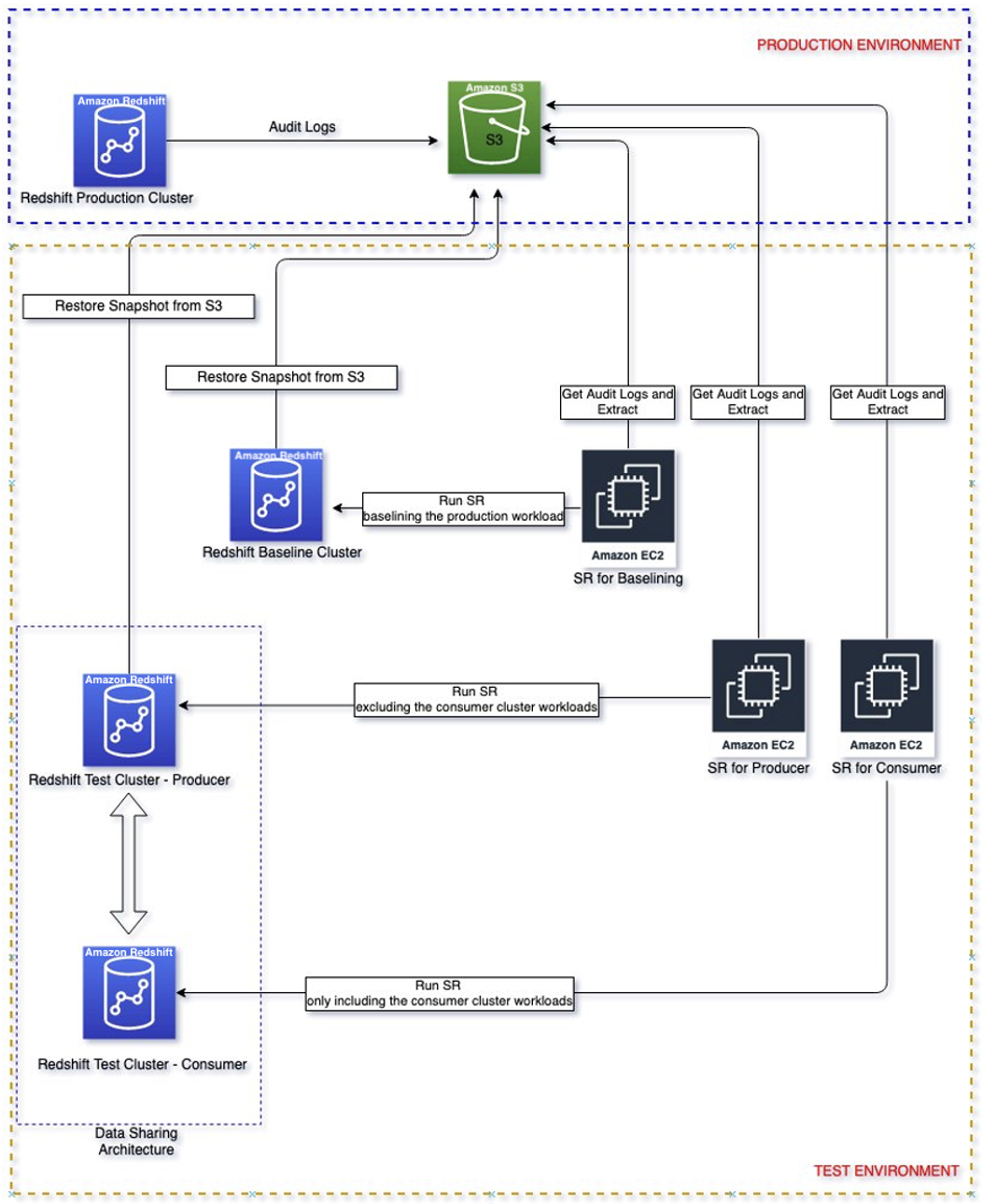
Gjennomgang av løsningen
Følg disse trinnene for å gå gjennom løsningen for å dimensjonere forbruker- og produsentklyngene dine.
Dimensjoner produksjonsklyngen din
Du bør alltid sørge for å dimensjonere den eksisterende produksjonsklyngen riktig for å få ytelsen du trenger for å oppfylle kravene til arbeidsbelastningen. Du kan bruke størrelseskalkulatoren fra Amazon Redshift-konsollen for å få en anbefaling om produksjonsklyngen basert på størrelsen på dataene dine og søkekarakteristikken. Se etter Hjelp meg å velge på konsollen i AWS-regioner som støtter RA3-nodetyper for å bruke denne størrelseskalkulatoren. Merk at dette bare er en første anbefaling for å komme i gang. Du bør teste å kjøre hele arbeidsmengden på den opprinnelige størrelsesklyngen og elastisk endre størrelsen på klyngen opp og ned tilsvarende for å få best prisytelse.
Identifiser arbeidsbelastningen som skal isoleres
Du kan ha forskjellige arbeidsbelastninger som kjører på den opprinnelige klyngen, men det første trinnet er å identifisere den mest kritiske arbeidsbelastningen for virksomheten som vi ønsker å isolere. Dette er fordi vi ønsker å forsikre oss om at den nye arkitekturen kan møte dine arbeidsbelastningskrav. Dette poste er en god referanse til en brukscase for isolering av datadeling som kan hjelpe deg med å bestemme hvilken arbeidsbelastning som kan isoleres.
Sett opp Enkel Replay
Når du kjenner din kritiske arbeidsmengde, må du aktivere revisjonslogging i produksjonsklyngen din der den kritiske arbeidsbelastningen identifisert ovenfor kjører for å fange opp spørringsaktiviteter og lagre den Amazon Simple Storage Service (Amazon S3). Merk at det kan ta opptil tre timer før revisjonsloggene blir levert til Amazon S3. Når revisjonsloggen er tilgjengelig, fortsett til oppsett Enkel Replay og deretter trekke ut den kritiske arbeidsbelastningen fra revisjonsloggen. Merk at start_time og end_time kan brukes som parametere for å filtrere ut den kritiske arbeidsbelastningen hvis disse arbeidsbelastningene kjører i bestemte tidsperioder, for eksempel 9 til 11. Ellers vil den trekke ut alle de loggede aktivitetene.
Baseline arbeidsbelastning
Opprett en grunnlinjeklynge med samme konfigurasjon som produsentklyngen ved å gjenopprette fra produksjonsøyeblikksbildet. Hensikten med å starte med den samme konfigurasjonen er å baseline ytelsen med et isolert miljø.
Når grunnlinjeklyngen er tilgjengelig, spille den ekstraherte arbeidsmengden i grunnlinjeklyngen. Utdataene fra denne reprisen vil være grunnlinjen som brukes til å sammenligne med påfølgende replays på forskjellige forbrukerkonfigurasjoner.
Sett opp første produsent- og forbrukertestklynger
Opprett en produsentklynge med samme produksjonsklyngekonfigurasjon ved å gjenopprette fra produksjonsøyeblikksbildet. Opprett en forbrukerklynge med den anbefalte innledende forbrukerstørrelsen fra forrige veiledning. Videre sette opp datadeling mellom produsent og forbruker.
Replay arbeidsmengde på opprinnelig produsent og forbruker
Replay arbeidsbelastningen kun for produsenten på den opprinnelige størrelsen på produsentklyngen. Dette kan oppnås ved å bruke filterparameteren "Ekskluder" for å ekskludere forbrukerspørringer, for eksempel brukeren som kjører forbrukerspørringer.
Replay forbrukerarbeidsbelastningen på den opprinnelige størrelsen på forbrukerklyngen. Dette kan oppnås ved å bruke filterparameteren «Inkluder» for å ekskludere forbrukerspørringer, for eksempel brukeren som kjører forbrukerspørringer.
Evaluer ytelsen til disse reprisene i forhold til grunnlinjen og ytelseskravene for arbeidsbelastning.
Spill av forbrukerarbeidsmengde på forskjellige konfigurasjoner
Hvis den opprinnelige størrelsen på forbrukerklyngen oppfyller eller overgår ytelseskravene for arbeidsbelastning, kan du enten bruke denne klyngekonfigurasjonen eller du kan følge disse trinnene for å teste på mindre konfigurasjoner for å se om du kan redusere kostnadene ytterligere og fortsatt få ytelsen du trenger.
Sammenlign innledende resultater for forbrukerytelse med arbeidsbelastningskravene dine:
- Hvis resultatet overstiger ytelseskravene dine for arbeidsbelastning, kan du redusere størrelsen på forbrukerklyngen trinnvis, starte med 1/2x, prøve avspillingen på nytt og evaluere ytelsen, og deretter endre størrelsen opp eller ned tilsvarende basert på resultatet til det oppfyller arbeidsbelastningen din krav. Hensikten er å få en sweet spot hvor du er komfortabel med ytelseskravene og få lavest mulig pris.
- Hvis resultatet ikke oppfyller ytelseskravene for arbeidsbelastning, kan du øke størrelsen på klyngen trinnvis, og starte med 2x den opprinnelige størrelsen, prøve avspillingen på nytt og evaluere ytelsen til den oppfyller ytelseskravene for arbeidsbelastningen.
Spill av produsentarbeidsmengde på forskjellige konfigurasjoner
Når du deler arbeidsmengdene dine ut til forbrukerklynger, bør belastningen på produsentklyngen reduseres, og du bør evaluere produsentklyngens arbeidsbelastningsytelse for å søke muligheten til å redusere for å spare kostnader.
Trinnene ligner på forbrukerreplay. Elastisk endre størrelsen på produsentklyngen trinnvis, start med 1/2x den opprinnelige størrelsen, spill av arbeidsbelastningen på bare produsenten og evaluer ytelsen, og endre størrelsen ytterligere opp eller ned til den oppfyller ytelseskravene for arbeidsbelastningen. Hensikten er å få et godt sted hvor du er komfortabel med ytelseskravene til arbeidsbelastningen og få lavest mulig pris. Når du har ønsket produsentklyngekonfigurasjon, kan du prøve å spille av forbrukerarbeidsbelastninger på nytt på forbrukerklyngen for å sikre at ytelsen ikke ble påvirket av endringer i produsentklyngekonfigurasjonen. Til slutt bør du spille av både produsent- og forbrukerarbeidsbelastninger samtidig for å sikre at ytelsen oppnås i et scenario med full arbeidsbelastning.
Reevaluer etter en full arbeidsbelastning over tid
I likhet med den generiske veiledningen bør du av og til revurdere størrelsen på produsent- og forbrukerklyngene ved å bruke den forrige strategien, spesielt etter full arbeidsbelastning for å oppnå den beste prisytelsen fra klyngens konfigurasjon.
Rydd opp
Å kjøre disse størrelsestestene i AWS-kontoen din kan ha noen kostnadsimplikasjoner fordi det sørger for nye Amazon Redshift-klynger, som kan belastes som on-demand-forekomster hvis du ikke har reserverte forekomster. Når du har fullført evalueringene, anbefaler vi å slette Amazon Redshift-klyngene for å spare kostnader. Vi anbefaler også å sette klynger på pause når de ikke er i bruk.
Bruk av Amazon Redshift og beste praksis for datadeling
Riktig dimensjonering av både produsent- og forbrukerklynger vil gi deg en god start for å få den beste prisytelsen fra Amazon Redshift-distribusjonen. Størrelse er imidlertid ikke den eneste faktoren som kan maksimere ytelsen din. I dette tilfellet er det like viktig å forstå og følge beste praksis.
Generell Amazon Redshift ytelsesjustering av beste praksis gjelder for distribusjon av datadeling. Sørg for at distribusjonen din følger disse beste praksis.
Det finnes en rekke spesifikke beste praksiser for datadeling som du bør følge for å sikre at du maksimerer ytelsen. Viser til dette poste for mer informasjon.
Oppsummering
Det er ingen entydig anbefaling om produsent- og forbrukerklyngestørrelser. Det varierer etter arbeidsbelastning og ytelses-SLA. Formålet med dette innlegget er å gi deg veiledning for hvordan du kan evaluere din spesifikke datadelingsytelse for å bestemme både forbruker- og produsentklyngestørrelser for å få best prisytelse. Vurder å teste arbeidsmengdene dine på produsent og forbruker ved å bruke enkel avspilling før du tar den i bruk for å få den beste prisytelsen.
Om forfatterne
 BP Yau er Sr Product Manager hos AWS. Han brenner for å hjelpe kunder med å bygge store dataløsninger for å behandle data i stor skala. Før AWS hjalp han Amazon.com Supply Chain Optimization Technologies med å migrere Oracle-datavarehuset til Amazon Redshift og bygge neste generasjons big data-analyseplattform ved hjelp av AWS-teknologier.
BP Yau er Sr Product Manager hos AWS. Han brenner for å hjelpe kunder med å bygge store dataløsninger for å behandle data i stor skala. Før AWS hjalp han Amazon.com Supply Chain Optimization Technologies med å migrere Oracle-datavarehuset til Amazon Redshift og bygge neste generasjons big data-analyseplattform ved hjelp av AWS-teknologier.
 Sidhanth Muralidhar er en Principal Technical Account Manager hos AWS. Han jobber med store bedriftskunder som kjører arbeidsmengdene sine på AWS. Han brenner for å jobbe med kunder og hjelpe dem med å planlegge arbeidsbelastninger for kostnader, pålitelighet, ytelse og operasjonell fortreffelighet i stor skala i deres skyreise. Han har også en stor interesse for Data Analytics.
Sidhanth Muralidhar er en Principal Technical Account Manager hos AWS. Han jobber med store bedriftskunder som kjører arbeidsmengdene sine på AWS. Han brenner for å jobbe med kunder og hjelpe dem med å planlegge arbeidsbelastninger for kostnader, pålitelighet, ytelse og operasjonell fortreffelighet i stor skala i deres skyreise. Han har også en stor interesse for Data Analytics.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/how-to-get-best-price-performance-from-your-amazon-redshift-data-sharing-deployment/
- 100
- a
- Om oss
- ovenfor
- tilsvar
- Logg inn
- kontoer
- Oppnå
- oppnådd
- tvers
- Aktiviteter
- la til
- vedta
- Etter
- mot
- Alle
- tillater
- alltid
- Amazon
- Amazon.com
- beløp
- analyse
- analytics
- analysere
- og
- En annen
- aktuelt
- søknader
- tilnærming
- arkitektur
- revisjon
- Automatisert
- automatisk
- tilgjengelig
- AWS
- basert
- Baseline
- fordi
- før du
- benchmark
- BEST
- beste praksis
- Bedre
- mellom
- Stor
- Store data
- bygge
- virksomhet
- fangst
- saken
- saker
- viss
- kjede
- Endringer
- karakteristisk
- egenskaper
- ladet
- klienter
- Cloud
- Cluster
- COM
- komfortabel
- Felles
- sammenligne
- sammenligning
- fullføre
- Terminado
- komplekse
- kompleksitet
- Beregn
- gjennomføre
- Konfigurasjon
- Vurder
- konsistent
- Konsoll
- forbruker
- fortsette
- fortsetter
- kontinuerlig
- Kostnad
- Kostnader
- kunne
- skape
- kritisk
- Kunder
- dato
- Data Analytics
- datavitenskap
- datadeling
- levert
- avhenger
- distribusjon
- detaljer
- Bestem
- forskjellig
- direkte
- ikke
- ned
- nedlasting
- under
- lett
- enten
- muliggjør
- forbedret
- Enterprise
- Miljø
- like
- spesielt
- Eter (ETH)
- evaluere
- evalueringer
- utvikling
- eksempel
- eksempler
- stiger
- Excellence
- eksisterende
- eksportere
- trekke ut
- mislykkes
- FAST
- gjennomførbart
- Trekk
- filtrere
- Endelig
- Først
- fleksibilitet
- følge
- etter
- følger
- fra
- fullt
- fundamentalt
- videre
- Dess
- Gevinst
- generelt
- generasjonen
- få
- få
- GitHub
- Gi
- Go
- god
- veilede
- hjelpe
- hjulpet
- hjelpe
- TIMER
- Hvordan
- Hvordan
- Men
- HTTPS
- identifisert
- identifisere
- Påvirkning
- påvirket
- implementert
- implikasjoner
- viktig
- forbedring
- bedre
- in
- inkluderer
- Øke
- innledende
- i utgangspunktet
- f.eks
- i stedet
- interesse
- involvert
- isolert
- isolasjon
- IT
- reise
- Keen
- Vet
- stor
- større
- lansert
- Lar
- Leverage
- leve
- laste
- Se
- vedlikehold
- gjøre
- leder
- håndbok
- Maksimer
- Møt
- møter
- metode
- kunne
- migrere
- minimum
- modell
- mer
- mest
- flytte
- bevegelse
- flere
- Trenger
- trenger
- behov
- Ny
- neste
- node
- mange
- anledning
- Ombord
- ONE
- operasjonell
- Opportunity
- optimalisering
- optimal
- orakel
- original
- Annen
- ellers
- parameter
- parametere
- lidenskapelig
- Mønster
- utføre
- ytelse
- utfører
- perioder
- fly
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Point
- mulig
- Post
- praksis
- forrige
- pris
- Principal
- prosess
- produsent
- Produkt
- Produktsjef
- Produksjon
- riktig
- gi
- gir
- formål
- spørsmål
- Sats
- anbefaler
- Anbefaling
- anbefales
- redusere
- Redusert
- regioner
- Utgivelser
- pålitelighet
- Krav
- reservert
- ressurs
- gjenopprette
- resultere
- Resultater
- Regel
- Kjør
- rennende
- samme
- Spar
- skalerbarhet
- skalerbar
- Skala
- scenarier
- Vitenskap
- sømløst
- Seksjon
- sikre
- sikkert
- Søke
- tjeneste
- oppsett
- Del
- deling
- bør
- Vis
- Viser
- lignende
- Enkelt
- Størrelse
- størrelser
- mindre
- Snapshot
- løsning
- Solutions
- noen
- kilde
- spesifikk
- splittet
- Spot
- Standard
- Begynn
- startet
- Start
- uttalelser
- Trinn
- Steps
- Still
- lagring
- oppbevare
- Strategi
- streaming
- senere
- levere
- forsyningskjeden
- Optimalisering av forsyningskjede
- støtte
- søt
- Ta
- Target
- Teknisk
- Technologies
- test
- Testing
- tester
- De
- Kilden
- deres
- tre
- Gjennom
- tid
- til
- verktøy
- verktøy
- typer
- forståelse
- bruke
- bruk sak
- Bruker
- Vakuum
- Hva
- hvilken
- HVEM
- vil
- uten
- arbeid
- virker
- Din
- zephyrnet