Dette er et gjesteinnlegg skrevet sammen med Raghu Boppanna fra Vanguard.
At Vanguard, Enterprise Advice-bransjen forbedrer investorresultatene gjennom digital tilgang til overlegen, personlig og rimelig økonomisk rådgivning. De gjorde det mulig, delvis, ved å drive stordriftsfordeler over hele verden for investorer med en svært spenstig og effektiv teknisk plattform. Vanguard valgte en flerregionsarkitektur for denne arbeidsmengden for å beskytte mot svekkelser av regionale tjenester. For høy tilgjengelighetsformål er det behov for å gjøre dataene som brukes av arbeidsmengden tilgjengelige, ikke bare i primærregionen, men også i sekundærregionen med minimal replikeringsforsinkelse. Ved tjenestesvikt i primærregionen skal løsningen kunne svikte over til sekundærregion med minst mulig datatap og mulighet til å gjenoppta datainntak.
Vanguard Cloud Technology Office og AWS gikk sammen for å bygge en infrastrukturløsning på AWS som oppfylte deres krav til motstandskraft. Multi-Region-løsningen muliggjør en robust fail-over-mekanisme, med innebygd observerbarhet og gjenoppretting. Løsningen støtter også streaming av data fra flere kilder til forskjellige Kinesis-datastrømmer. Løsningen rulles for tiden ut til de forskjellige forretningsteamene for å forbedre motstandskraften til arbeidsbelastningene deres.
Brukstilfellet som diskuteres her krever Change Data Capture (CDC) for å strømme data fra en ekstern datakilde (mainframe DB2) til Amazon Kinesis datastrømmer, fordi forretningsevnen avhenger av disse dataene. Kinesis Data Streams er en fullt administrert, massivt skalerbar, holdbar og rimelig strømmetjeneste som kontinuerlig kan fange opp og streame store mengder data fra flere kilder, og gjør dataene tilgjengelige for forbruk i løpet av millisekunder. Tjenesten er bygget for å være svært robust og bruker flere tilgjengelighetssoner for å behandle og lagre data.
Løsningen diskutert i dette innlegget forklarer hvordan AWS og Vanguard innoverte for å bygge en spenstig arkitektur for å møte deres høye tilgjengelighetsmål.
Løsningsoversikt
Løsningen bruker AWS Lambda å replikere data fra Kinesis-datastrømmer i primærregionen til en sekundærregion. I tilfelle en tjenesteforringelse som påvirker CDC-rørledningen, fremmer failover-prosessen den sekundære regionen til primærregion for produsentene og forbrukerne. Vi bruker Amazon DynamoDB globale tabeller for replikeringssjekkpunkter som gjør det mulig å gjenoppta datastrømming fra sjekkpunktet og også opprettholder et primært regionkonfigurasjonsflagg som forhindrer en uendelig replikeringssløyfe av de samme dataene frem og tilbake.
Løsningen gir også fleksibiliteten for Kinesis Data Streams-forbrukere til å bruke den primære eller sekundære regionen innenfor samme AWS-konto.
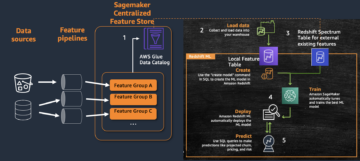
Følgende diagram illustrerer referansearkitekturen.
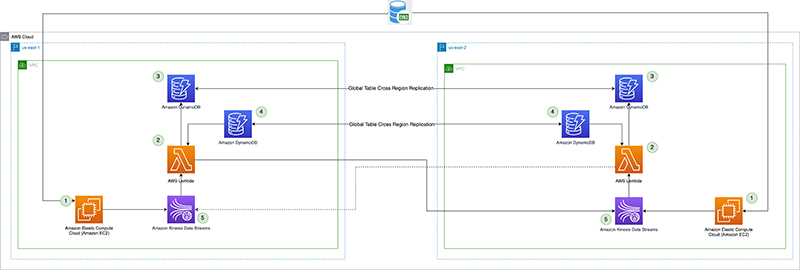
La oss se på hver komponent i detalj:
- CDC-prosessor (produsent) – I denne referansearkitekturen er produsenten utplassert på Amazon Elastic Compute Cloud (Amazon EC2) i både primær- og sekundærregionen, og er aktiv i primærregionen og i standby-modus i sekundærregionen. Den fanger opp CDC-data fra den eksterne datakilden (som en DB2-database som vist i arkitekturen ovenfor), og strømmer til Kinesis-datastrømmer i primærregionen. Vanguard bruker en 3rd partyverktøyet Qlik Replicate som deres CDC-prosessor. Den produserer en godt utformet nyttelast inkludert DB2-tidsstempelet til Kinesis-datastrømmen, i tillegg til de faktiske raddataene fra den eksterne datakilden. (
example-stream-1i dette eksemplet). Følgende kode er et eksempel på nyttelast som bare inneholder primærnøkkelen til posten som ble endret og tidsstempelet for forpliktelsen (for enkelhets skyld vises ikke resten av tabellraddataene nedenfor):{ "eventSource": "aws:kinesis", "kinesis": { "ApproximateArrivalTimestamp": "Mon July 18 20:00:00 UTC 2022", "SequenceNumber": "49544985256907370027570885864065577703022652638596431874", "PartitionKey": "12349999", "KinesisSchemaVersion": "1.0", "Data": "eyJLZXkiOiAxMjM0OTk5OSwiQ29tbWl0VGltZXN0YW1wIjogIjIwMjItMDctMThUMjA6MDA6MDAifQ==" }, "eventId": "shardId-000000000000:49629136582982516722891309362785181370337771525377097730", "invokeIdentityArn": "arn:aws:iam::6243876582:role/kds-crr-LambdaRole-1GZWP67437SD", "eventName": "aws:kinesis:record", "eventVersion": "1.0", "eventSourceARN": "arn:aws:kinesis:us-east-1:6243876582:stream/kds-stream-1/consumer/kds-crr:6243876582", "awsRegion": "us-east-1" }Den Base64-dekodede verdien på
Dataer som følgende. Den faktiske Kinesis-posten vil inneholde hele raddataene til tabellraden som ble endret, i tillegg til primærnøkkelen og tidsstemplet for forpliktelsen.{"Key": 12349999,"CommitTimestamp": "2022-07-18T20:00:00"}De
CommitTimestampiDatafeltet brukes i replikeringssjekkpunktet og er avgjørende for nøyaktig å spore hvor mye av strømdataene som er blitt replikert til den sekundære regionen. Sjekkpunktet kan deretter brukes til å lette en CDC-prosessor (produsent) failover og nøyaktig gjenoppta produksjon av data fra replikeringssjekkpunktets tidsstempel og utover.Alternativet til å bruke en ekstern datakilde
CommitTimestamp(hvis utilgjengelig) er å brukeApproximateArrivalTimestamp(som er tidsstemplet når posten faktisk skrives til datastrømmen). - Cross-Region replikering Lambda funksjon – Funksjonen er distribuert til både primære og sekundære regioner. Den er satt opp med en hendelseskildetilordning til datastrømmen som inneholder CDC-data. Den samme funksjonen kan brukes til å replikere data fra flere strømmer. Den påkalles med en gruppe poster fra Kinesis Data Streams og replikerer batchen til en målreplikeringsregion (som leveres via Lambda-konfigurasjonsmiljøet). Av kostnadshensyn, hvis CDC-dataene produseres aktivt kun i primærregionen, kan den reserverte samtidigheten til funksjonen i sekundærregionen settes til null og endres under regional failover. Funksjonen har AWS identitets- og tilgangsadministrasjon (IAM) rolletillatelser til å gjøre følgende:
- Les og skriv til de globale DynamoDB-tabellene som brukes i denne løsningen, innenfor samme konto.
- Les og skriv til Kinesis-datastrømmer i begge regioner innenfor samme konto.
- Publiser egendefinerte beregninger til Amazon CloudWatch i begge regioner innenfor samme konto.
- Replikeringssjekkpunkt – Replikeringssjekkpunktet bruker den globale DynamoDB-tabellen i både den primære og sekundære regionen. Den brukes av lambda-funksjonen for replikering på tvers av regioner for å opprettholde tidsstempelet for den siste replikeringsposten som replikeringssjekkpunktet for hver strøm som er konfigurert for replikering. For dette innlegget oppretter og bruker vi en global tabell kalt
kdsReplicationCheckpoint. - Aktiv region konfig – Den aktive regionen bruker den globale DynamoDB-tabellen i både primære og sekundære regioner. Den bruker den opprinnelige replikeringsevnen på tvers av regioner til den globale tabellen for å replikere konfigurasjonen. Den er forhåndsutfylt med data om hvilken som er den primære regionen for en strøm, for å forhindre replikering tilbake til den primære regionen av Lambda-funksjonen i standby-regionen. Denne konfigurasjonen er kanskje ikke nødvendig hvis Lambda-funksjonen i standby-regionen har en reservert samtidighet satt til null, men kan tjene som en sikkerhetssjekk for å unngå uendelig replikeringssløyfe av dataene. For dette innlegget lager vi en global tabell kalt
kdsActiveRegionConfigog legg inn et element med følgende data:{ "stream-name": "example-stream-1", "active-region" : "us-east-1" } - Kinesis datastrømmer – Strømmen som CDC-prosessoren produserer dataene til. For dette innlegget bruker vi en strøm kalt
example-stream-1i begge regionene, med samme shard-konfigurasjon og tilgangspolicyer.
Sekvens av trinn i replikering på tvers av regioner
La oss kort se på hvordan arkitekturen utøves ved å bruke følgende sekvensdiagram.
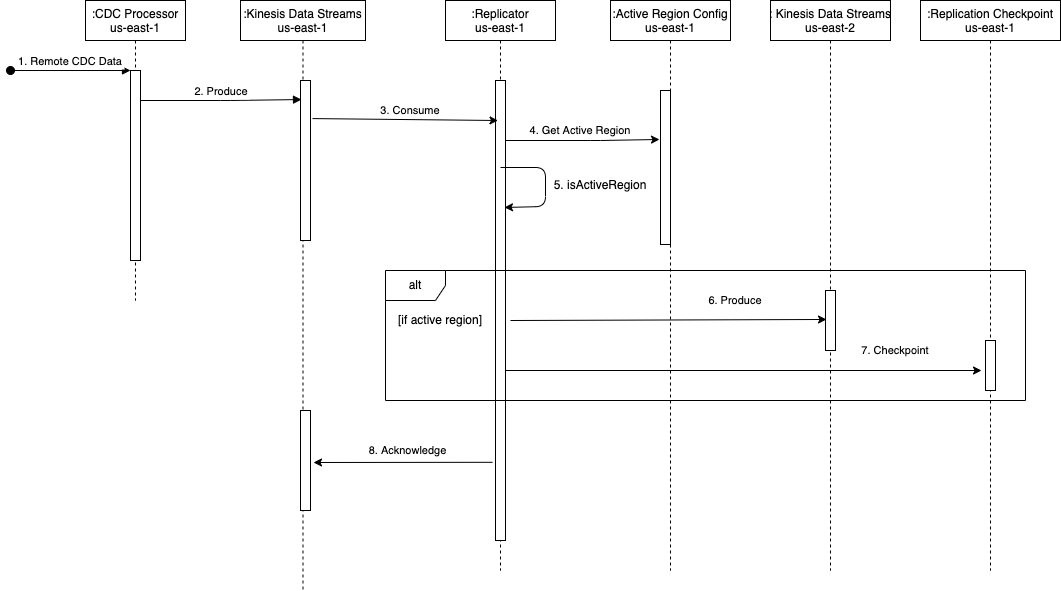
Sekvensen består av følgende trinn:
- CDC-prosessoren (in
us-east-1) leser CDC-dataene fra den eksterne datakilden. - CDC-prosessoren (in
us-east-1) strømmer CDC-dataene til Kinesis Data Streams (inus-east-1). - Lambda-funksjonen for replikering på tvers av regioner (i us-east-1) bruker dataene fra datastrømmen (i
us-east-1). Det forbedrede fan-out-mønsteret anbefales for dedikert og økt gjennomstrømning for replikering på tvers av regioner. - Replikator Lambda-funksjonen (i
us-east-1) validerer sin nåværende region med den aktive regionkonfigurasjonen for strømmen som forbrukes, ved hjelp avkdsActiveRegionConfigDynamoDB global tabell Følgende eksempelkode (i Java) kan bidra til å illustrere tilstanden som evalueres:// Fetch the current AWS Region from the Lambda function’s environment String currentAWSRegion = System.getenv(“AWS_REGION”); // Read the stream name from the first Kinesis Record once for the entire batch being processed. This is done because we are reusing the same Lambda function for replicating multiple streams. String currentStreamNameConsumed = kinesisRecord.getEventSourceARN().split(“:”)[5].split(“/”)[1]; // Build the DynamoDB query condition using the stream name Map<String, Condition> keyConditions = singletonMap(“streamName”, Condition.builder().comparisonOperator(EQ).attributeValueList(AttributeValue.builder().s(currentStreamNameConsumed).build()).build()); // Query the DynamoDB Global Table QueryResponse queryResponse = ddbClient.query(QueryRequest.builder().tableName("kdsActiveRegionConfig").keyConditions(keyConditions).attributesToGet(“ActiveRegion”).build()); - Funksjonen evaluerer svaret fra DynamoDB med følgende kode:
// Evaluate the response if (queryResponse.hasItems()) { AttributeValue activeRegionForStream = queryResponse.items().get(0).get(“ActiveRegion”); return currentAWSRegion.equalsIgnoreCase(activeRegionForStream.s()); } - Avhengig av svaret, utfører funksjonen følgende handlinger:
- Hvis svaret er
true, produserer replikatorfunksjonen postene til Kinesis Data Streams ius-east-2på en sekvensiell måte.- Hvis det er en feil, spores sekvensnummeret til posten og iterasjonen brytes. Funksjonen returnerer listen over mislykkede sekvensnumre. Ved å returnere det mislykkede sekvensnummeret bruker løsningen funksjonen til Lambda-sjekkpunkt for å kunne gjenoppta behandlingen av et parti med poster med delvis feil. Dette er nyttig når du håndterer eventuelle tjenestesvekkelser, der funksjonen prøver å replikere dataene på tvers av regioner for å sikre strømparitet og ikke tap av data.
- Hvis det ikke er noen feil, returneres en tom liste, som indikerer at batchen var vellykket.
- Hvis svaret er
false, returnerer replikatorfunksjonen uten å utføre replikering. For å redusere kostnadene for Lambda-anropene, kan du angi den reserverte samtidigheten til funksjonen i DR-regionen (us-east-2) til null. Dette vil forhindre at funksjonen aktiveres. Når du failover, kan du oppdatere denne verdien til et passende tall basert på CDC-gjennomstrømmingen og angi den reserverte samtidigheten til funksjonen ius-east-1til null for å forhindre at den kjøres unødvendig.
- Hvis svaret er
- Etter at alle postene er produsert til Kinesis Data Streams i
us-east-2, sjekkpunkter replikatorfunksjonen tilkdsReplicationCheckpointDynamoDB global tabell (inus-east-1) med følgende data:{ "streamName": "example-stream-1", "lastReplicatedTimestamp": "2022-07-18T20:00:00" } - Funksjonen returnerer etter vellykket behandling av bunken med poster.
Ytelseshensyn
Ytelsesforventningene til løsningen bør forstås med hensyn til følgende faktorer:
- Regionvalg – Replikeringsforsinkelsen er direkte proporsjonal med avstanden som tilbakelegges av dataene, så forstå ditt områdevalg
- Velocity – Innkommende hastighet til dataene eller volumet av data som blir replikert
- Nyttelaststørrelse – Størrelsen på nyttelasten som blir replikert
Overvåk replikeringen på tvers av regioner
Det anbefales å spore og observere replikeringen mens den skjer. Du kan skreddersy Lambda-funksjonen for å publisere tilpassede beregninger til CloudWatch med følgende beregninger på slutten av hver påkalling. Å publisere disse beregningene til både den primære og sekundære regionen bidrar til å beskytte deg selv mot svekkelser som påvirker observerbarheten i primærregionen.
- gjennomstrømming – Gjeldende lambda-påkallingsbatchstørrelse
- ReplicationLagSeconds – Forskjellen mellom gjeldende tidsstempel (etter å ha behandlet alle postene) og
ApproximateArrivalTimestampav den siste posten som ble replikert
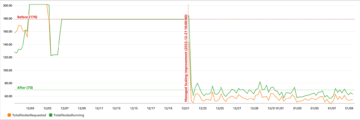
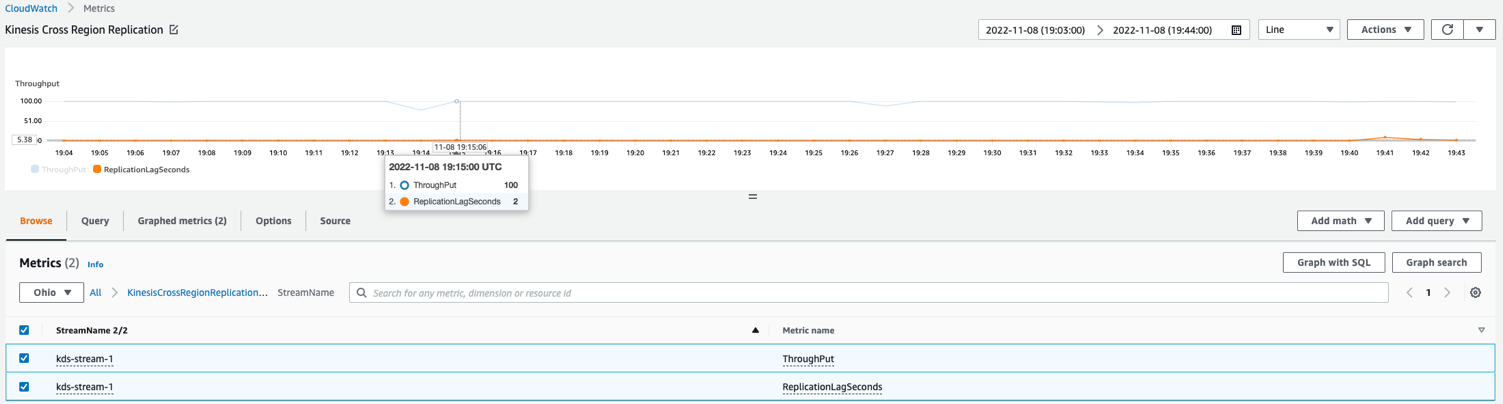
Følgende eksempel CloudWatch metrisk graf viser at gjennomsnittlig replikeringsforsinkelse var 2 sekunder med en gjennomstrømning på 100 poster replikert fra us-east-1 til us-east-2.
Felles failover-strategi
Under eventuelle verdifall som påvirker CDC-rørledningen i den primære regionen, kan behov for forretningskontinuitet eller nødgjenoppretting diktere en pipeline-failover til den sekundære (standby-) regionen. Dette betyr at et par ting må gjøres som en del av denne failover-prosessen:
- Hvis mulig, stopp alle CDC-oppgavene i CDC-prosessorverktøyet i
us-east-1. - CDC-prosessoren må feiles over til den sekundære regionen, slik at den kan lese CDC-dataene fra den eksterne datakilden mens den opererer utenfor standby-regionen.
- De
kdsActiveRegionConfigDynamoDB global tabell må oppdateres. For eksempel for strømmenexample-stream-1brukt i vårt eksempel, endres den aktive regionen tilus-east-2:
{ "stream-name": "example-stream-1", "active-Region" : "us-east-2"
}- Alle strømsjekkpunktene må leses fra
kdsReplicationCheckpointDynamoDB global tabell (inus-east-2), og tidsstemplene fra hvert av sjekkpunktene brukes til å starte CDC-oppgavene i produsentverktøyet ius-east-2Region. Dette minimerer sjansene for tap av data og gjenopptar nøyaktig strømming av CDC-data fra den eksterne datakilden fra sjekkpunktets tidsstempel og utover. - Hvis du bruker reservert samtidighet for å kontrollere Lambda-anrop, sett verdien til null i primærregionen(
us-east-1) og til en passende verdi som ikke er null i den sekundære regionen(us-east-2).
Vanguards flertrinns failover-strategi
Noen av tredjepartsverktøyene som Vanguard bruker har en to-trinns CDC-prosess for å strømme data fra en ekstern datakilde til en destinasjon. Vanguards foretrukne verktøy for deres CDC-prosessor følger denne to-trinns tilnærmingen:
- Det første trinnet involverer å sette opp en loggstrømoppgave som leser dataene fra den eksterne datakilden og fortsetter på et sted.
- Det andre trinnet innebærer å sette opp individuelle forbrukeroppgaver som leser data fra oppsamlingsstedet – som kan være på Amazon elastisk filsystem (Amazon EFS) eller Amazon FSx, for eksempel – og stream den til destinasjonen. Fleksibiliteten her er at hver av disse forbrukeroppgavene kan utløses til å strømme fra forskjellige forpliktelsestidsstempler. Loggstrømoppgaven begynner vanligvis å lese data fra minimum av alle forpliktelsestidsstemplene som brukes av forbrukeroppgavene.
La oss se på et eksempel for å forklare scenariet:
- Forbrukeroppgave A strømmer data fra et tidsstempel 2022-07-19T20:00:00 og utover til
example-stream-1. - Forbrukeroppgave B strømmer data fra et tidsstempel 2022-07-19T21:00:00 og utover til
example-stream-2. - I denne situasjonen bør loggstrømmen lese data fra den eksterne datakilden fra minimum av tidsstemplene som brukes av forbrukeroppgavene, som er 2022-07-19T20:00:00.
Følgende sekvensdiagram viser de nøyaktige trinnene som skal kjøres under en failover us-east-2 (standby-regionen).
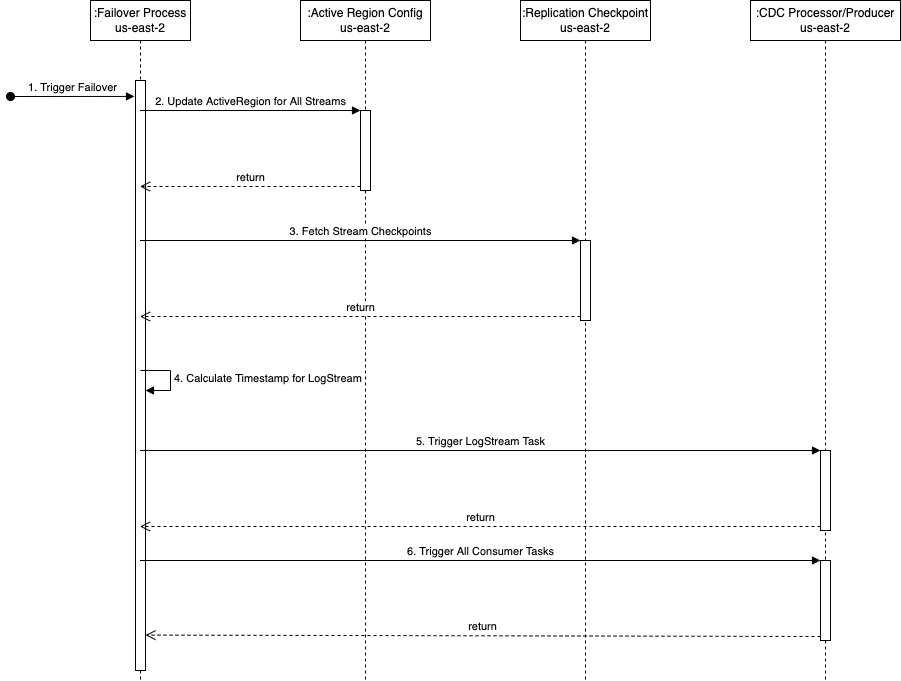
Trinnene er som følger:
- Failover-prosessen utløses i standby-regionen (
us-east-2i dette eksemplet) når det er nødvendig. Merk at utløseren kan automatiseres ved hjelp av omfattende helsesjekker av rørledningen i primærregionen. - Failover-prosessen oppdaterer den globale kdsActiveRegionConfig DynamoDB-tabellen med den nye verdien for regionen som
us-east-2for alle strømnavnene. - Det neste trinnet er å hente alle strømsjekkpunktene fra
kdsReplicationCheckpointDynamoDB global tabell (inus-east-2). - Etter at sjekkpunktinformasjonen er lest, finner failover-prosessen minimum av alle
lastReplicatedTimestamp. - Loggstrømoppgaven i CDC-prosessorverktøyet startes i
us-east-2med tidsstemplet som ble funnet i trinn 4. Den begynner å lese CDC-data fra den eksterne datakilden fra dette tidsstemplet og utover og fortsetter dem i oppsamlingsstedet på AWS. - Det neste trinnet er å starte alle forbrukeroppgavene for å lese data fra oppsamlingsstedet og strømme til destinasjonsdatastrømmen. Det er her hver forbrukeroppgave leveres med passende tidsstempel fra
kdsReplicationCheckpointtabell i henhold tilstreamNamesom oppgaven strømmer dataene til.
Etter at alle forbrukeroppgavene er startet, produseres data til Kinesis-datastrømmene i us-east-2. Derfra er prosessen med replikering på tvers av regioner den samme som beskrevet tidligere - lambda-replikasjonsfunksjonen i us-east-2 begynner å replikere data til datastrømmen inn us-east-1.
Forbrukerapplikasjonene som leser data fra strømmene forventes å være idempotente til å kunne håndtere duplikater. Duplikater kan introduseres i strømmen på grunn av mange årsaker, noen av dem er kalt opp nedenfor.
- Produsenten eller CDC-prosessoren introduserer duplikater i strømmen mens de spiller av CDC-dataene under en failover
- DynamoDB Global Table bruker asynkron replikering av data på tvers av regioner og hvis
kdsReplicationCheckpointtabelldata har en replikeringsforsinkelse, kan failover-prosessen potensielt bruke et eldre sjekkpunkttidsstempel for å spille av CDC-dataene på nytt.
Forbrukerapplikasjoner bør også kontrollere CommitTimestamp for den siste posten som ble konsumert. Dette for å legge til rette for bedre overvåking og gjenoppretting.
Veien til modenhet: Automatisert gjenoppretting
Den ideelle tilstanden er å fullautomatisere failover-prosessen, redusere tid til gjenoppretting og møte resilience Service Level Objective (SLO). Men i de fleste organisasjoner krever beslutningen om å mislykkes, feile tilbake og utløse failover manuell intervensjon for å vurdere situasjonen og bestemme utfallet. Å lage skriptet automatisering for å utføre failover som kan kjøres av et menneske er et godt sted å starte.
Vanguard har automatisert alle trinnene i failover, men har fortsatt mennesker til å ta avgjørelsen om når de skal påkalle den. Du kan tilpasse løsningen for å møte dine behov og avhengig av CDC-prosessorverktøyet du bruker i ditt miljø.
konklusjonen
I dette innlegget beskrev vi hvordan Vanguard innoverte og bygde en løsning for å replikere data på tvers av regioner i Kinesis Data Streams for å gjøre dataene svært tilgjengelige. Vi demonstrerte også en robust sjekkpunktstrategi for å lette en regional failover av replikeringsprosessen ved behov. Løsningen illustrerte også hvordan du bruker DynamoDB globale tabeller for å spore replikeringssjekkpunktene og konfigurasjonen. Med denne arkitekturen var Vanguard i stand til å distribuere arbeidsbelastninger avhengig av CDC-dataene til flere regioner for å møte forretningsbehov med høy tilgjengelighet i møte med svekkelser av tjenester som påvirker CDC-rørledninger i primærregionen.
Hvis du har tilbakemeldinger, vennligst legg igjen en kommentar i kommentarfeltet nedenfor.
Om forfatterne
 Raghu Boppanna jobber som Enterprise Architect ved Vanguards Chief Technology Office. Raghu spesialiserer seg på dataanalyse, datamigrering/replikering inkludert CDC Pipelines, Disaster Recovery og databaser. Han har oppnådd flere AWS-sertifiseringer, inkludert AWS-sertifisert sikkerhet – spesialitet og AWS-sertifisert dataanalyse – spesialitet.
Raghu Boppanna jobber som Enterprise Architect ved Vanguards Chief Technology Office. Raghu spesialiserer seg på dataanalyse, datamigrering/replikering inkludert CDC Pipelines, Disaster Recovery og databaser. Han har oppnådd flere AWS-sertifiseringer, inkludert AWS-sertifisert sikkerhet – spesialitet og AWS-sertifisert dataanalyse – spesialitet.
 Parameswaran V Vaidyanathan er en Senior Cloud Resilience Architect med Amazon Web Services. Han hjelper store bedrifter med å nå forretningsmålene ved å bygge og bygge skalerbare og motstandsdyktige løsninger på AWS Cloud.
Parameswaran V Vaidyanathan er en Senior Cloud Resilience Architect med Amazon Web Services. Han hjelper store bedrifter med å nå forretningsmålene ved å bygge og bygge skalerbare og motstandsdyktige løsninger på AWS Cloud.
 Richa Kaul er en seniorleder innen kundeløsninger som betjener Financial Services-kunder. Hun er basert i New York. Hun har lang erfaring innen storskala skytransformasjon, medarbeiderfortreffelighet og neste generasjons digitale løsninger. Hun og teamet hennes fokuserer på å optimalisere verdien av skyen ved å bygge effektive, spenstige og smidige løsninger. Richa liker multisporter som triatlon, musikk og å lære om nye teknologier.
Richa Kaul er en seniorleder innen kundeløsninger som betjener Financial Services-kunder. Hun er basert i New York. Hun har lang erfaring innen storskala skytransformasjon, medarbeiderfortreffelighet og neste generasjons digitale løsninger. Hun og teamet hennes fokuserer på å optimalisere verdien av skyen ved å bygge effektive, spenstige og smidige løsninger. Richa liker multisporter som triatlon, musikk og å lære om nye teknologier.
 Mithil Prasad er hovedansvarlig for kundeløsninger hos Amazon Web Services. I sin rolle jobber Mithil med kunder for å drive realisering av skyverdier, gi tankelederskap for å hjelpe bedrifter med å oppnå hastighet, smidighet og innovasjon.
Mithil Prasad er hovedansvarlig for kundeløsninger hos Amazon Web Services. I sin rolle jobber Mithil med kunder for å drive realisering av skyverdier, gi tankelederskap for å hjelpe bedrifter med å oppnå hastighet, smidighet og innovasjon.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/how-vanguard-made-their-technology-platform-resilient-and-efficient-by-building-cross-region-replication-for-amazon-kinesis-data-streams/
- 1
- 100
- 2022
- 28
- a
- evne
- I stand
- Om oss
- ovenfor
- adgang
- Ifølge
- Logg inn
- nøyaktig
- Oppnå
- tvers
- handlinger
- aktiv
- aktivt
- faktisk
- tillegg
- råd
- påvirker
- rimelig
- Etter
- mot
- smidig
- Alle
- tillater
- alternativ
- Amazon
- Amazon EC2
- Amazon Kinesis
- Amazon Web Services
- beløp
- analytics
- og
- søknader
- tilnærming
- hensiktsmessig
- arkitektur
- automatisere
- Automatisert
- Automatisering
- tilgjengelighet
- tilgjengelig
- gjennomsnittlig
- unngå
- AWS
- AWS-sertifisert
- tilbake
- basert
- fordi
- være
- under
- Bedre
- mellom
- kort
- Brutt
- bygge
- Bygning
- bygget
- innebygd
- virksomhet
- Forretnings kontinuitet
- bedrifter
- som heter
- fangst
- fanger
- saken
- CDC
- sertifiseringer
- Sertifisert
- sjansene
- endring
- sjekk
- Sjekker
- sjef
- valg
- Cloud
- SKYETEKNOLOGI
- kode
- kommentere
- kommentarer
- forplikte
- komponent
- omfattende
- Beregn
- tilstand
- Konfigurasjon
- betraktninger
- forbrukes
- forbruker
- Forbrukere
- forbruk
- kontinuerlig
- kontroll
- Kostnad
- kunne
- Par
- skape
- Opprette
- kritisk
- Gjeldende
- I dag
- skikk
- kunde
- Kundeløsninger
- Kunder
- tilpasse
- dato
- Data Analytics
- Data Loss
- Database
- databaser
- Avgjør
- avgjørelse
- dedikert
- demonstrert
- demonstrerer
- avhengig
- avhenger
- utplassere
- utplassert
- beskrevet
- destinasjonen
- detalj
- forskjell
- forskjellig
- digitalt
- direkte
- katastrofe
- diskutert
- avstand
- stasjonen
- kjøring
- duplikater
- under
- hver enkelt
- Tidligere
- opptjent
- økonomier
- Stordriftsfordeler
- effektiv
- Ansatt
- muliggjør
- forbedret
- sikre
- Enterprise
- bedrifter
- Hele
- Miljø
- Eter (ETH)
- evaluere
- evaluert
- Event
- Hver
- eksempel
- Excellence
- utførende
- forventninger
- forventet
- erfaring
- Forklar
- forklarer
- omfattende
- utvendig
- Face
- legge til rette
- faktorer
- FAIL
- Mislyktes
- Failure
- Trekk
- tilbakemelding
- felt
- filet
- finansiell
- finansielle tjenester
- funn
- Først
- fleksibilitet
- Fokus
- etter
- følger
- For investorer
- funnet
- fra
- fullt
- funksjon
- generasjonen
- Global
- globus
- Mål
- god
- graf
- Gjest
- gjest innlegg
- håndtere
- Håndtering
- skjer
- Helse
- hjelpe
- hjelper
- her.
- Høy
- svært
- Hvordan
- Hvordan
- Men
- HTTPS
- menneskelig
- Mennesker
- IAM
- ideell
- Identitet
- svekkelse
- forbedre
- forbedrer
- in
- Inkludert
- Innkommende
- økt
- indikerer
- individuelt
- informasjon
- Infrastruktur
- Innovasjon
- f.eks
- intervensjon
- introdusert
- Introduserer
- investor
- Investorer
- innebærer
- IT
- køyring
- Java
- Juli
- nøkkel
- Kinesis datastrømmer
- stor
- Siste
- Ventetid
- leder
- Ledelse
- læring
- Permisjon
- Nivå
- linje
- linjer
- Liste
- lite
- plassering
- Se
- tap
- laget
- opprettholder
- gjøre
- GJØR AT
- fikk til
- leder
- måte
- håndbok
- mange
- kartlegging
- massivt
- modenhet
- midler
- mekanisme
- Møt
- møte
- metrisk
- Metrics
- minimal
- minimum
- Mote
- modifisert
- overvåking
- mest
- multi
- flere
- musikk
- navn
- navn
- innfødt
- Trenger
- nødvendig
- behov
- Ny
- Ny teknologi
- New York
- neste
- Antall
- tall
- Målet
- observere
- Office
- drift
- optimalisere
- organisasjoner
- Utfallet
- paritet
- del
- samarbeid
- parti
- Mønster
- utføre
- ytelse
- utfører
- tillatelser
- vedvarer
- Personlig
- rørledning
- Sted
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- vær så snill
- Politikk
- mulig
- Post
- potensielt
- forebygge
- primære
- Principal
- prosess
- prosessering
- prosessor
- produsert
- produsent
- Produsentene
- fremmer
- beskytte
- gi
- forutsatt
- gir
- publisere
- Publisering
- formål
- sette
- Lese
- Lesning
- realisering
- grunner
- anbefales
- rekord
- poster
- Gjenopprette
- utvinning
- redusere
- redusere
- region
- regional
- regioner
- fjernkontroll
- replikert
- replikerer
- replikering
- påkrevd
- Krav
- Krever
- reservert
- resiliens
- spenstig
- svar
- REST
- gjenoppta
- retur
- retur
- avkastning
- robust
- Rolle
- Valsede
- RAD
- Kjør
- Sikkerhet
- samme
- skalerbar
- Skala
- scenario
- Sekund
- sekundær
- sekunder
- Seksjon
- sikkerhet
- senior
- Sequence
- betjene
- tjeneste
- Tjenester
- servering
- sett
- innstilling
- flere
- bør
- vist
- Viser
- enkelhet
- situasjon
- Størrelse
- So
- løsning
- Solutions
- noen
- kilde
- Kilder
- spesialisert
- Spesialitet
- fart
- Sports
- iscenesettelse
- Begynn
- startet
- starter
- Tilstand
- Trinn
- Steps
- Still
- Stopp
- oppbevare
- Strategi
- stream
- streaming
- streaming tjeneste
- bekker
- vellykket
- vellykket
- egnet
- overlegen
- medfølgende
- Støtter
- system
- bord
- tar
- Target
- Oppgave
- oppgaver
- lag
- lag
- Teknisk
- Technologies
- Teknologi
- De
- deres
- ting
- tredjeparts
- trodde
- tenkte ledelse
- Gjennom
- gjennomstrømning
- tid
- tidsstempel
- til
- verktøy
- verktøy
- spor
- Sporing
- Transformation
- reiste
- utløse
- utløst
- forstå
- forstås
- unødvendig
- Oppdater
- oppdatert
- oppdateringer
- bruke
- bruk sak
- vanligvis
- UTC
- verdi
- Vanguard
- Hastighet
- av
- volum
- web
- webtjenester
- hvilken
- mens
- vil
- innenfor
- uten
- virker
- ville
- skrive
- skrevet
- Din
- deg selv
- zephyrnet
- null
- soner