Dette innlegget er skrevet sammen med Mahima Agarwal, Machine Learning Engineer, og Deepak Mettem, Senior Engineering Manager, hos VMware Carbon Black
VMware Carbon Black er en kjent sikkerhetsløsning som tilbyr beskyttelse mot hele spekteret av moderne cyberangrep. Med terabyte med data generert av produktet, fokuserer sikkerhetsanalyseteamet på å bygge maskinlæringsløsninger (ML) for å synliggjøre kritiske angrep og sette søkelyset på nye trusler fra støy.
Det er avgjørende for VMware Carbon Black-teamet å designe og bygge en tilpasset ende-til-ende MLOps-pipeline som orkestrerer og automatiserer arbeidsflyter i ML-livssyklusen og muliggjør modellopplæring, evalueringer og distribusjoner.
Det er to hovedformål med å bygge denne rørledningen: støtte dataforskerne for modellutvikling på sent stadium, og overflatemodellprediksjoner i produktet ved å betjene modeller i høyt volum og i sanntids produksjonstrafikk. Derfor valgte VMware Carbon Black og AWS å bygge en tilpasset MLOps-pipeline ved hjelp av Amazon SageMaker for sin brukervennlighet, allsidighet og fullt administrerte infrastruktur. Vi orkestrerer våre ML-trenings- og distribusjonsrørledninger ved hjelp av Amazon administrerte arbeidsflyter for Apache Airflow (Amazon MWAA), som gjør oss i stand til å fokusere mer på programmatisk oppretting av arbeidsflyter og pipelines uten å måtte bekymre oss for automatisk skalering eller vedlikehold av infrastruktur.
Med denne pipelinen er det som en gang var Jupyter notebook-drevet ML-forskning nå en automatisert prosess som distribuerer modeller til produksjon med lite manuell intervensjon fra dataforskere. Tidligere kunne prosessen med å trene, evaluere og distribuere en modell ta over en dag; med denne implementeringen er alt bare en trigger unna og har redusert den totale tiden til noen få minutter.
I dette innlegget diskuterer VMware Carbon Black og AWS-arkitekter hvordan vi bygde og administrerte tilpassede ML-arbeidsflyter ved hjelp av gitlab, Amazon MWAA og SageMaker. Vi diskuterer hva vi har oppnådd så langt, ytterligere forbedringer av rørledningen og lærdom underveis.
Løsningsoversikt
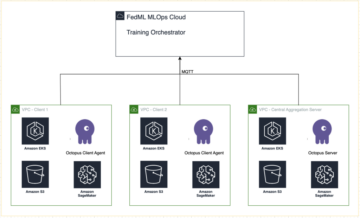
Følgende diagram illustrerer ML-plattformarkitekturen.

Løsningsdesign på høyt nivå
Denne ML-plattformen ble tenkt og designet for å bli konsumert av forskjellige modeller på tvers av forskjellige kodelagre. Teamet vårt bruker GitLab som et kildekodeadministrasjonsverktøy for å vedlikeholde alle kodelagrene. Eventuelle endringer i modelllagerets kildekode integreres kontinuerlig ved hjelp av Gitlab CI, som påkaller de påfølgende arbeidsflytene i pipelinen (modellopplæring, evaluering og distribusjon).
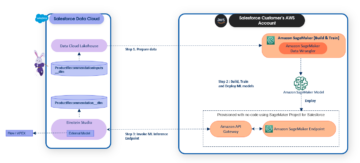
Følgende arkitekturdiagram illustrerer ende-til-ende-arbeidsflyten og komponentene som er involvert i vår MLOps-pipeline.

Ende-til-ende arbeidsflyt
ML-modellens opplærings-, evaluerings- og distribusjonsrørledninger er orkestrert ved hjelp av Amazon MWAA, referert til som en Regissert Acyclic Graph (DAG). En DAG er en samling oppgaver sammen, organisert med avhengigheter og relasjoner for å si hvordan de skal utføres.
På et høyt nivå inkluderer løsningsarkitekturen tre hovedkomponenter:
- ML-rørledningskodelager
- ML modell trening og evaluering pipeline
- ML-modellimplementeringspipeline
La oss diskutere hvordan disse forskjellige komponentene administreres og hvordan de samhandler med hverandre.
ML-rørledningskodelager
Etter at modellrepoen integrerer MLOps-repoen som deres nedstrøms pipeline, og en dataforsker forplikter kode i modellrepoen sin, utfører en GitLab-løper standard kodevalidering og testing definert i den repoen og utløser MLOps-rørledningen basert på kodeendringene. Vi bruker Gitlabs flerprosjekt-pipeline for å aktivere denne triggeren på tvers av forskjellige repoer.
MLOps GitLab-pipeline kjører et visst sett med stadier. Den utfører grunnleggende kodevalidering ved hjelp av pylint, pakker modellens opplærings- og slutningskode i Docker-bildet, og publiserer beholderbildet til Amazon Elastic Container Registry (Amazon ECR). Amazon ECR er et fullstendig administrert containerregister som tilbyr hosting med høy ytelse, slik at du pålitelig kan distribuere applikasjonsbilder og artefakter hvor som helst.
ML modell trening og evaluering pipeline
Etter at bildet er publisert, utløser det opplæringen og evalueringen Apache luftstrøm rørledning gjennom AWS Lambda funksjon. Lambda er en serverløs, hendelsesdrevet databehandlingstjeneste som lar deg kjøre kode for praktisk talt alle typer applikasjoner eller backend-tjenester uten å klargjøre eller administrere servere.
Etter at rørledningen er vellykket utløst, kjører den Training and Evaluation DAG, som igjen starter modellopplæringen i SageMaker. På slutten av denne opplæringspipelinen får den identifiserte brukergruppen et varsel med trenings- og modellevalueringsresultatene via e-post via Amazon enkel varslingstjeneste (Amazon SNS) og Slack. Amazon SNS er fullt administrert pub/subtjeneste for A2A- og A2P-meldinger.
Etter en grundig analyse av evalueringsresultatene, kan dataforskeren eller ML-ingeniøren implementere den nye modellen hvis ytelsen til den nylig trente modellen er bedre sammenlignet med den forrige versjonen. Ytelsen til modellene blir evaluert basert på modellspesifikke beregninger (som F1-score, MSE eller forvirringsmatrise).
ML-modellimplementeringspipeline
For å starte distribusjonen starter brukeren GitLab-jobben som utløser Deployment DAG gjennom den samme Lambda-funksjonen. Etter at rørledningen har kjørt vellykket, oppretter eller oppdaterer den SageMaker-endepunktet med den nye modellen. Dette sender også et varsel med endepunktdetaljene via e-post ved hjelp av Amazon SNS og Slack.
Ved svikt i en av rørledningene blir brukerne varslet over de samme kommunikasjonskanalene.
SageMaker tilbyr sanntidsslutning som er ideell for inferensarbeidsbelastninger med lav latens og høye gjennomstrømningskrav. Disse endepunktene er fullstendig administrert, belastningsbalansert og automatisk skalert, og kan distribueres på tvers av flere tilgjengelighetssoner for høy tilgjengelighet. Rørledningen vår oppretter et slikt endepunkt for en modell etter at den har kjørt vellykket.
I de følgende avsnittene utvider vi de forskjellige komponentene og dykker ned i detaljene.
GitLab: Pakke modeller og trigger pipelines
Vi bruker GitLab som vårt kodelager og for rørledningen for å pakke modellkoden og utløse nedstrøms Airflow DAGs.
Flerprosjektrørledning
Multi-prosjekt GitLab pipeline-funksjonen brukes der den overordnede pipeline (oppstrøms) er en modellrepo og underordnet pipeline (nedstrøms) er MLOps-repoen. Hver repo opprettholder en .gitlab-ci.yml, og følgende kodeblokk aktivert i oppstrøms pipeline utløser nedstrøms MLOps pipeline.
Oppstrømsrørledningen sender over modellkoden til nedstrømsrørledningen der pakke- og publiserings-CI-jobbene utløses. Kode for å beholde modellkoden og publisere den til Amazon ECR vedlikeholdes og administreres av MLOps-rørledningen. Den sender variablene som ACCESS_TOKEN (kan opprettes under innstillinger, Adgang), JOB_ID (for å få tilgang til oppstrøms artefakter), og $CI_PROJECT_ID (prosjekt-IDen til modellrepo) variabler, slik at MLOps-rørledningen kan få tilgang til modellkodefilene. Med jobb artefakter funksjonen fra Gitlab, nedstrøms repoen får tilgang til de eksterne artefaktene ved å bruke følgende kommando:
Modellrepoen kan konsumere nedstrøms rørledninger for flere modeller fra samme repo ved å utvide stadiet som utløser den ved å bruke strekker nøkkelord fra GitLab, som lar deg gjenbruke den samme konfigurasjonen på tvers av forskjellige stadier.
Etter å ha publisert modellbildet til Amazon ECR, utløser MLOps-rørledningen Amazons MWAA-treningspipeline ved hjelp av Lambda. Etter brukergodkjenning utløser den også Amazon MWAA-pipeline for modellimplementering ved å bruke den samme Lambda-funksjonen.
Semantisk versjonering og overføring av versjoner nedstrøms
Vi utviklet tilpasset kode til versjon ECR-bilder og SageMaker-modeller. MLOps-rørledningen administrerer den semantiske versjonslogikken for bilder og modeller som en del av stadiet der modellkoden blir containerisert, og sender versjonene videre til senere stadier som artefakter.
Omskolering
Fordi omskolering er et avgjørende aspekt av en ML-livssyklus, har vi implementert omskoleringsmuligheter som en del av vår pipeline. Vi bruker SageMaker list-models API for å identifisere om det er omskolering basert på versjonsnummeret og tidsstempelet for modellomopplæring.
Vi styrer den daglige timeplanen for omskoleringsrørledningen ved hjelp av GitLabs tidsplan pipelines.
Terraform: Infrastrukturoppsett
I tillegg til en Amazon MWAA-klynge, ECR-depoter, Lambda-funksjoner og SNS-emne, bruker denne løsningen også AWS identitets- og tilgangsadministrasjon (IAM) roller, brukere og retningslinjer; Amazon enkel lagringstjeneste (Amazon S3) bøtter, og en Amazon CloudWatch log forwarder.
For å strømlinjeforme infrastrukturoppsettet og vedlikeholdet for tjenestene som er involvert gjennom hele rørledningen vår, bruker vi terra å implementere infrastrukturen som kode. Når det kreves infra-oppdateringer, utløser kodeendringene en GitLab CI-pipeline som vi setter opp, som validerer og distribuerer endringene i ulike miljøer (for eksempel ved å legge til en tillatelse til en IAM-policy i dev-, scene- og prod-kontoer).
Amazon ECR, Amazon S3 og Lambda: Rørledningstilrettelegging
Vi bruker følgende nøkkeltjenester for å lette vår pipeline:
- Amazon ECR – For å opprettholde og tillate praktiske henting av modellbeholderbildene, merker vi dem med semantiske versjoner og laster dem opp til ECR-depoter satt opp pr.
${project_name}/${model_name}gjennom Terraform. Dette muliggjør et godt lag med isolasjon mellom ulike modeller, og lar oss bruke tilpassede algoritmer og formatere slutningsforespørsler og svar for å inkludere ønsket modellmanifestinformasjon (modellnavn, versjon, treningsdatabane, og så videre). - Amazon S3 – Vi bruker S3-bøtter for å opprettholde modelltreningsdata, trente modellartefakter per modell, Airflow DAG-er og annen tilleggsinformasjon som kreves av rørledningene.
- Lambda – Fordi vår Airflow-klynge er distribuert i en egen VPC av sikkerhetshensyn, kan ikke DAG-ene nås direkte. Derfor bruker vi en Lambda-funksjon, også vedlikeholdt med Terraform, for å utløse eventuelle DAG-er spesifisert av DAG-navnet. Med riktig IAM-oppsett utløser GitLab CI-jobben Lambda-funksjonen, som går gjennom konfigurasjonene ned til de forespurte trenings- eller distribusjons-DAGene.
Amazon MWAA: Opplærings- og distribusjonsrørledninger
Som nevnt tidligere bruker vi Amazon MWAA til å orkestrere trenings- og distribusjonsrørledningene. Vi bruker SageMaker-operatører tilgjengelig i Amazon-leverandørpakke for Airflow å integrere med SageMaker (for å unngå jinja-maling).
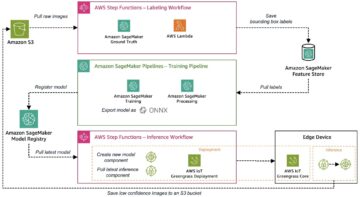
Vi bruker følgende operatører i denne opplæringspipelinen (vist i følgende arbeidsflytdiagram):

MWAA treningsrørledning
Vi bruker følgende operatører i distribusjonsrørledningen (vist i følgende arbeidsflytdiagram):

Modelldistribusjonsrørledning
Vi bruker Slack og Amazon SNS til å publisere feil/suksessmeldinger og evalueringsresultater i begge pipelines. Slack tilbyr et bredt spekter av alternativer for å tilpasse meldinger, inkludert følgende:
- SnsPublishOperator - Vi bruker SnsPublishOperator for å sende varsler om suksess/mislykket til brukerens e-post
- Slack API – Vi skapte innkommende webhook-URL for å få pipeline-varslene til ønsket kanal
CloudWatch og VMware Wavefront: Overvåking og logging
Vi bruker et CloudWatch-dashbord for å konfigurere endepunktovervåking og logging. Det hjelper med å visualisere og holde styr på ulike drifts- og modellytelsesmålinger som er spesifikke for hvert prosjekt. I tillegg til retningslinjene for automatisk skalering som er satt opp for å spore noen av dem, overvåker vi kontinuerlig endringene i CPU- og minnebruk, forespørsler per sekund, svarforsinkelser og modellberegninger.
CloudWatch er til og med integrert med et VMware Tanzu Wavefront-dashbord slik at det kan visualisere beregningene for modellendepunkter så vel som andre tjenester på prosjektnivå.
Forretningsfordeler og hva som skjer videre
ML-rørledninger er svært avgjørende for ML-tjenester og funksjoner. I dette innlegget diskuterte vi en ende-til-ende ML-brukssak ved å bruke funksjoner fra AWS. Vi bygde en tilpasset pipeline ved hjelp av SageMaker og Amazon MWAA, som vi kan gjenbruke på tvers av prosjekter og modeller, og automatiserte ML-livssyklusen, noe som reduserte tiden fra modellopplæring til produksjonsdistribusjon til så lite som 10 minutter.
Med flyttingen av ML-livssyklusbyrden til SageMaker, ga det optimalisert og skalerbar infrastruktur for modellopplæringen og -implementeringen. Modellservering med SageMaker hjalp oss med å lage sanntidsprediksjoner med millisekunders forsinkelser og overvåkingsmuligheter. Vi brukte Terraform for å lette oppsettet og for å administrere infrastruktur.
De neste trinnene for denne rørledningen vil være å forbedre modelltreningsrørledningen med omskoleringsmuligheter enten den er planlagt eller basert på modelldriftdeteksjon, støtte for skyggedistribusjon eller A/B-testing for raskere og kvalifisert modelldistribusjon, og ML-linjesporing. Vi planlegger også å evaluere Amazon SageMaker-rørledninger fordi GitLab-integrasjon nå støttes.
Erfaringer
Som en del av å bygge denne løsningen lærte vi at du bør generalisere tidlig, men ikke overgeneralisere. Da vi først var ferdig med arkitekturdesignet, prøvde vi å lage og håndheve kodemaler for modellkoden som en beste praksis. Det var imidlertid så tidlig i utviklingsprosessen at malene enten var for generaliserte eller for detaljerte til å kunne gjenbrukes for fremtidige modeller.
Etter å ha levert den første modellen gjennom pipeline, kom malene ut naturlig basert på innsikten fra vårt tidligere arbeid. En rørledning kan ikke gjøre alt fra dag én.
Modelleksperimentering og produksjon har ofte svært forskjellige (eller noen ganger til og med motstridende) krav. Det er avgjørende å balansere disse kravene fra begynnelsen som et team og prioritere deretter.
I tillegg trenger du kanskje ikke alle funksjonene i en tjeneste. Å bruke essensielle funksjoner fra en tjeneste og ha en modularisert design er nøkkelen til mer effektiv utvikling og en fleksibel pipeline.
konklusjonen
I dette innlegget viste vi hvordan vi bygde en MLOps-løsning ved hjelp av SageMaker og Amazon MWAA som automatiserte prosessen med å distribuere modeller til produksjon, med lite manuell intervensjon fra dataforskere. Vi oppfordrer deg til å vurdere ulike AWS-tjenester som SageMaker, Amazon MWAA, Amazon S3 og Amazon ECR for å bygge en komplett MLOps-løsning.
*Apache, Apache Airflow og Airflow er enten registrerte varemerker eller varemerker tilhørende Apache Software Foundation i USA og / eller andre land.
Om forfatterne
 Deepak Mettem er Senior Engineering Manager i VMware, Carbon Black Unit. Han og teamet hans jobber med å bygge streamingbaserte applikasjoner og tjenester som er svært tilgjengelige, skalerbare og spenstige for å gi kundene maskinlæringsbaserte løsninger i sanntid. Han og teamet hans er også ansvarlige for å lage verktøy som er nødvendige for dataforskere for å bygge, trene, distribuere og validere deres ML-modeller i produksjon.
Deepak Mettem er Senior Engineering Manager i VMware, Carbon Black Unit. Han og teamet hans jobber med å bygge streamingbaserte applikasjoner og tjenester som er svært tilgjengelige, skalerbare og spenstige for å gi kundene maskinlæringsbaserte løsninger i sanntid. Han og teamet hans er også ansvarlige for å lage verktøy som er nødvendige for dataforskere for å bygge, trene, distribuere og validere deres ML-modeller i produksjon.
 Mahima Agarwal er en maskinlæringsingeniør i VMware, Carbon Black Unit.
Mahima Agarwal er en maskinlæringsingeniør i VMware, Carbon Black Unit.
Hun jobber med å designe, bygge og utvikle kjernekomponentene og arkitekturen til maskinlæringsplattformen for VMware CB SBU.
 Vamshi Krishna Enabothala er en Sr. Applied AI Specialist Architect ved AWS. Han jobber med kunder fra forskjellige sektorer for å akselerere effektive data, analyser og maskinlæringsinitiativer. Han brenner for anbefalingssystemer, NLP og datasyn innen AI og ML. Utenom jobben er Vamshi en RC-entusiast, og bygger RC-utstyr (fly, biler og droner), og liker også hagearbeid.
Vamshi Krishna Enabothala er en Sr. Applied AI Specialist Architect ved AWS. Han jobber med kunder fra forskjellige sektorer for å akselerere effektive data, analyser og maskinlæringsinitiativer. Han brenner for anbefalingssystemer, NLP og datasyn innen AI og ML. Utenom jobben er Vamshi en RC-entusiast, og bygger RC-utstyr (fly, biler og droner), og liker også hagearbeid.
 Sahil Thapar er en Enterprise Solutions Architect. Han jobber med kunder for å hjelpe dem med å bygge svært tilgjengelige, skalerbare og spenstige applikasjoner på AWS Cloud. Han er for tiden fokusert på containere og maskinlæringsløsninger.
Sahil Thapar er en Enterprise Solutions Architect. Han jobber med kunder for å hjelpe dem med å bygge svært tilgjengelige, skalerbare og spenstige applikasjoner på AWS Cloud. Han er for tiden fokusert på containere og maskinlæringsløsninger.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :er
- $OPP
- 1
- 10
- 100
- 7
- 8
- a
- Om oss
- akselerere
- adgang
- aksesseres
- tilsvar
- kontoer
- oppnådd
- tvers
- asyklisk
- tillegg
- Ytterligere
- Tilleggsinformasjon
- Etter
- mot
- AI
- algoritmer
- Alle
- tillater
- Amazon
- Amazon SageMaker
- analyse
- analytics
- og
- hvor som helst
- Apache
- api
- Søknad
- søknader
- anvendt
- Anvendt AI
- godkjenning
- arkitektur
- ER
- områder
- AS
- aspektet
- At
- Angrep
- forfatter
- auto
- Automatisert
- automatiserer
- tilgjengelighet
- tilgjengelig
- unngå
- AWS
- Backend
- Balansere
- basert
- grunnleggende
- BE
- fordi
- Begynnelsen
- Fordeler
- BEST
- Bedre
- mellom
- Svart
- Blokker
- Branch
- bringe
- bygge
- Bygning
- bygget
- byrde
- by
- CAN
- kan ikke
- evner
- karbon
- biler
- saken
- CB
- viss
- Endringer
- kanaler
- barn
- valgte
- Cloud
- Cluster
- kode
- samling
- Kommunikasjon
- sammenlignet
- fullføre
- komponenter
- Beregn
- datamaskin
- Datamaskin syn
- dirigerer
- Konfigurasjon
- konfigurasjoner
- Motstrid
- forvirring
- betraktninger
- forbruke
- forbrukes
- Container
- Containere
- kontinuerlig
- Praktisk
- Kjerne
- kunne
- land
- prosessor
- skape
- opprettet
- skaper
- Opprette
- kritisk
- avgjørende
- I dag
- skikk
- Kunder
- tilpasse
- cyberattacks
- DAG
- daglig
- dashbord
- dato
- dataforsker
- dag
- definert
- levere
- utplassere
- utplassert
- utplasserings
- distribusjon
- distribusjoner
- Distribueres
- utforming
- designet
- utforme
- detaljert
- detaljer
- Gjenkjenning
- dev
- utviklet
- utvikle
- Utvikling
- forskjellig
- direkte
- diskutere
- diskutert
- Docker
- ikke
- ned
- Droner
- hver enkelt
- Tidligere
- Tidlig
- brukervennlighet
- effektiv
- enten
- emalje
- Emery
- muliggjøre
- aktivert
- muliggjør
- oppmuntre
- ende til ende
- Endpoint
- ingeniør
- Ingeniørarbeid
- Enterprise
- Enterprise Solutions
- entusiast
- miljøer
- utstyr
- avgjørende
- Eter (ETH)
- evaluere
- evaluert
- evaluere
- evaluering
- evalueringer
- Selv
- Event
- Hver
- alt
- eksempel
- Expand
- strekker
- f1
- legge til rette
- Failure
- langt
- raskere
- Trekk
- Egenskaper
- Noen få
- Filer
- Først
- fleksibel
- Fokus
- fokuserte
- fokuserer
- etter
- Til
- format
- fra
- fullt
- hele spekteret
- fullt
- funksjon
- funksjoner
- videre
- framtid
- generert
- få
- god
- Gruppe
- Ha
- å ha
- hjelpe
- hjulpet
- hjelper
- Høy
- høy ytelse
- svært
- Hosting
- Hvordan
- Men
- HTML
- http
- HTTPS
- IAM
- ID
- ideell
- identifisert
- identifisere
- Identitet
- bilde
- bilder
- iverksette
- gjennomføring
- implementert
- in
- inkludere
- inkluderer
- Inkludert
- informasjon
- Infrastruktur
- initiativer
- innsikt
- integrere
- integrert
- Integrerer
- integrering
- samhandle
- intervensjon
- påkaller
- involvert
- isolasjon
- IT
- DET ER
- Jobb
- Jobb
- jpg
- Hold
- nøkkel
- nøkler
- Ventetid
- lag
- lært
- læring
- Lessons
- Lessons Learned
- Lar
- Nivå
- Livssyklus
- i likhet med
- lite
- laste
- Lav
- maskin
- maskinlæring
- Hoved
- vedlikeholde
- opprettholder
- vedlikehold
- gjøre
- administrer
- fikk til
- ledelse
- leder
- forvalter
- administrerende
- håndbok
- Matrix
- Minne
- nevnt
- meldinger
- meldinger
- Metrics
- kunne
- millisekund
- minutter
- ML
- MLOps
- modell
- modeller
- Moderne
- Overvåke
- overvåking
- mer
- mer effektivt
- flere
- navn
- naturlig
- nødvendig
- Trenger
- Ny
- neste
- nlp
- Bråk
- varsling
- varslinger
- Antall
- of
- tilby
- Tilbud
- on
- ONE
- operasjonell
- operatører
- optimalisert
- alternativer
- orkestrert
- Organisert
- Annen
- utenfor
- samlet
- pakke
- pakker
- emballasje
- del
- passerer
- Passerer
- lidenskapelig
- banen
- ytelse
- tillatelse
- rørledning
- fly
- Planes
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Politikk
- politikk
- Post
- praksis
- Spådommer
- forrige
- Prioriter
- prosess
- Produkt
- Produksjon
- prosjekt
- prosjekter
- ordentlig
- beskyttelse
- forutsatt
- leverandør
- gir
- publisere
- publisert
- utgir
- Publisering
- formål
- kvalifisert
- område
- sanntids
- Anbefaling
- Redusert
- referert
- registrert
- registret
- Relasjoner
- fjernkontroll
- Kjent
- Repository
- Forespurt
- forespørsler
- påkrevd
- Krav
- forskning
- spenstig
- svar
- ansvarlig
- Resultater
- omskolering
- gjenbruk
- roller
- Kjør
- runner
- sagemaker
- samme
- skalerbar
- skalering
- planlegge
- planlagt
- Forsker
- forskere
- Sekund
- seksjoner
- sektorer
- sikkerhet
- senior
- separat
- server~~POS=TRUNC
- Servere
- tjeneste
- Tjenester
- servering
- sett
- oppsett
- Shadow
- SKIFTENDE
- bør
- vist
- Enkelt
- slakk
- So
- så langt
- Software
- løsning
- Solutions
- noen
- kilde
- kildekoden
- spesialist
- spesifikk
- spesifisert
- Spectrum
- Spotlight
- Scene
- stadier
- Standard
- Begynn
- starter
- Stater
- Steps
- lagring
- Strategi
- streaming
- effektivisere
- senere
- vellykket
- slik
- støtte
- Støttes
- overflaten
- Systemer
- TAG
- Ta
- oppgaver
- lag
- maler
- terra
- Testing
- Det
- De
- deres
- Dem
- derfor
- Disse
- trusler
- tre
- Gjennom
- hele
- gjennomstrømning
- tid
- tidsstempel
- til
- sammen
- også
- verktøy
- verktøy
- topp
- Tema
- spor
- Sporing
- varemerker
- trafikk
- Tog
- trent
- Kurs
- utløse
- utløst
- SVING
- etter
- enhet
- forent
- Forente Stater
- oppdateringer
- us
- bruk
- bruke
- bruk sak
- Bruker
- Brukere
- VALIDERE
- validering
- variabler
- ulike
- versjon
- nesten
- syn
- visualisere
- VMware
- volum
- Vei..
- VI VIL
- Hva
- om
- hvilken
- bred
- Bred rekkevidde
- med
- innenfor
- uten
- Arbeid
- arbeidsflyt
- arbeidsflyt
- virker
- ville
- zephyrnet
- Zip
- soner