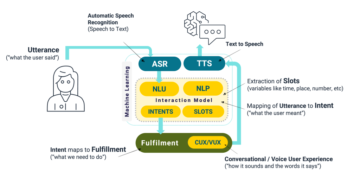
Organisasjoner bruker smidige prosjektstyringsplattformer som Atlassian Jira for å gjøre det mulig for team å samarbeide for å planlegge, spore og sende leveranser. Jira fanger opp organisasjonskunnskap om hvordan leveransene fungerer i problemene og kommentarene som logges under prosjektgjennomføringen. Det er imidlertid utfordrende å gjøre denne kunnskapen enkelt og sikkert tilgjengelig for brukere fordi den er fragmentert på tvers av problemstillinger som tilhører ulike prosjekter og sprints. I tillegg, fordi forskjellige interessenter som utviklere, testingeniører og prosjektledere bidrar til det samme problemet ved å logge det og deretter legge til vedlegg og kommentarer, blir tradisjonelle nøkkelordbaserte søk ineffektive når de søker etter informasjon i Jira-prosjekter.
Du kan nå bruke Amazon Kendra Jira skykobling for å indeksere problemer, kommentarer og vedlegg i Jira-prosjektene dine, og søke etter dette innholdet ved hjelp av Amazon Kendra intelligent søk, drevet av maskinlæring (ML).
Dette innlegget viser hvordan du bruker Amazon Kendra Jira-skykoblingen til å konfigurere en Jira-skyforekomst som en datakilde for en Amazon Kendra-indeks, og intelligent søke i innholdet i prosjektene i den. Vi bruker et eksempel på Jira-prosjekter der teammedlemmer samarbeider ved å lage problemer og legge til informasjon til dem i form av beskrivelser, kommentarer og vedlegg gjennom hele problemets livssyklus.
Løsningsoversikt
En Jira-forekomst har ett eller flere prosjekter, der hvert prosjekt har teammedlemmer som jobber med problemer i det prosjektet. Hvert teammedlem har sett med tillatelser om operasjonene de kan utføre med hensyn til ulike problemer i prosjektet de tilhører. Teammedlemmer kan opprette nye problemer, eller legge til mer informasjon til problemene i form av vedlegg og kommentarer, samt endre statusen til en sak fra åpning til lukking gjennom hele livssyklusen som er definert for det prosjektet. En prosjektleder lager sprints, tildeler problemer til spesifikke sprints, og tildeler eiere til problemer. I løpet av prosjektet fortsetter kunnskapen som er fanget i disse problemstillingene å utvikle seg.
I løsningen vår konfigurerer vi en Jira-skyforekomst som en datakilde til en Amazon Kendra-søkeindeks ved å bruke Amazon Kendra Jira-koblingen. Basert på konfigurasjonen, når datakilden er synkronisert, gjennomsøker og indekserer koblingen innholdet fra prosjektene i Jira-forekomsten. Eventuelt kan du konfigurere den til å indeksere innholdet basert på endringsloggen. Koblingen samler og inntar også informasjon om tilgangskontrollliste (ACL) for hvert problem, kommentar og vedlegg. ACL-informasjonen brukes til brukerkontekstfiltrering, der søkeresultater for et søk filtreres etter hva en bruker har autorisert tilgang til.
Forutsetninger
For å prøve ut Amazon Kendra-kontakten for Jira ved å bruke dette innlegget som referanse, trenger du følgende:
- An AWS-konto med rettigheter til å lage AWS identitets- og tilgangsadministrasjon (IAM) roller og retningslinjer. For mer informasjon, se Oversikt over tilgangsadministrasjon: Tillatelser og retningslinjer og retningslinjer for Jira-datakilder.
- Grunnleggende kunnskap om AWS og arbeidskunnskap om Jira-administrasjon.
- Administratortilgang til en Jira-skyforekomst.
Jira-forekomstkonfigurasjon
Denne delen beskriver Jira-konfigurasjonen som brukes til å demonstrere hvordan du konfigurerer en Amazon Kendra-datakilde ved hjelp av Jira-koblingen, tar inn dataene fra Jira-prosjektene i Amazon Kendra-indeksen og gjør søk. Du kan bruke din egen Jira-instans som du har administratortilgang til eller opprette et nytt prosjekt og utføre trinnene for å prøve ut Amazon Kendra-koblingen for Jira.
I vårt eksempel på Jira opprettet vi to prosjekter for å demonstrere at søkene fra brukere bare returnerer resultater fra prosjektene de har tilgang til. Vi brukte data fra følgende offentlige domene-prosjekter for å simulere bruken av virkelige programvareutviklingsprosjekter:
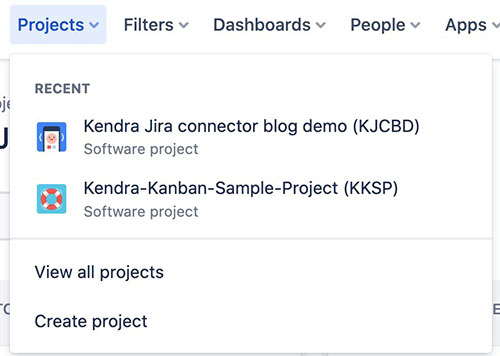
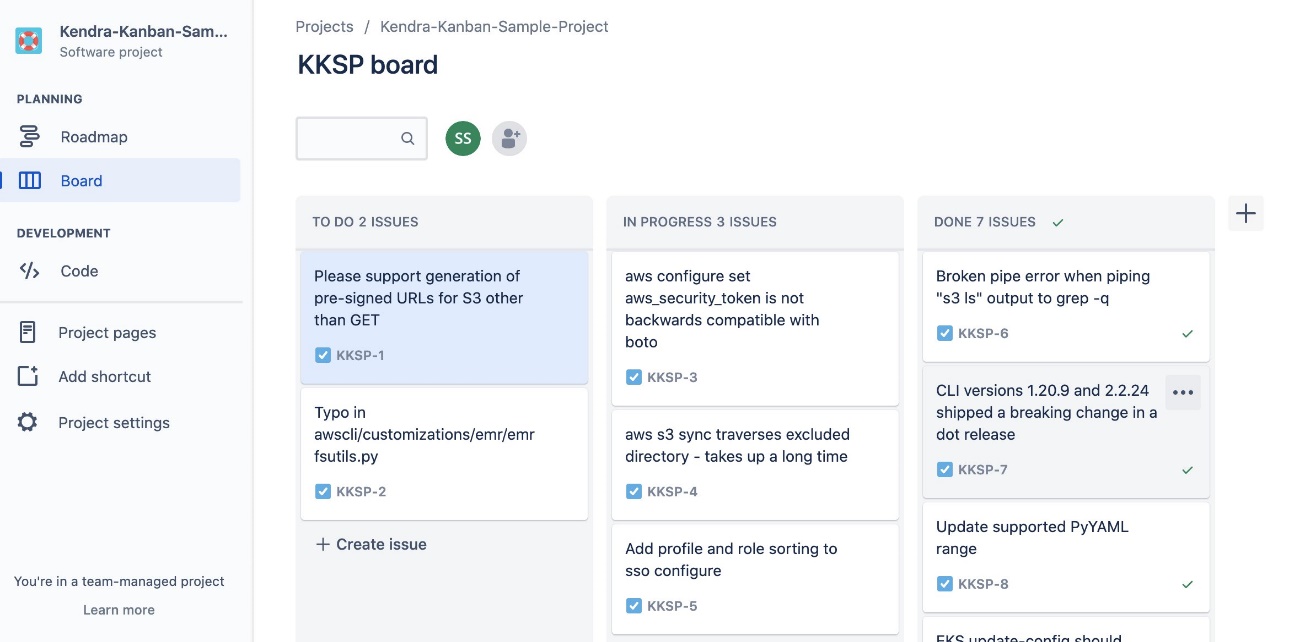
Følgende er et skjermbilde av styret i Kanban-stil for prosjekt 1.
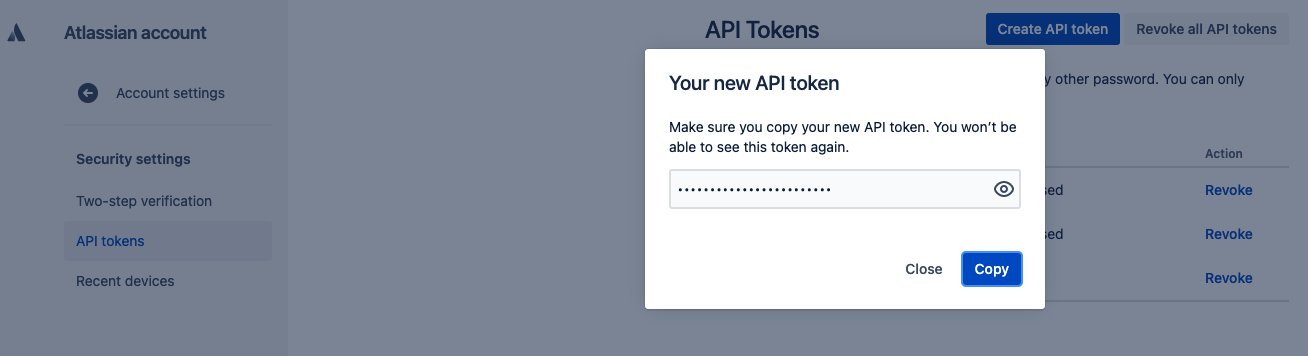
Opprett et API-token for Jira-forekomsten
For å få API-tokenet som trengs for å konfigurere Amazon Kendra Jira-koblingen, fullfør følgende trinn:
- Logg på https://id.atlassian.com/manage/api-tokens.
- Velg Opprett API-token.
- I dialogboksen som vises, skriv inn en etikett for tokenet ditt og velg Opprett.
- Velg Kopier og skriv inn tokenet på en midlertidig notisblokk.
Du kan ikke kopiere dette tokenet igjen, og du trenger det for å konfigurere Amazon Kendra Jira-kontakten.
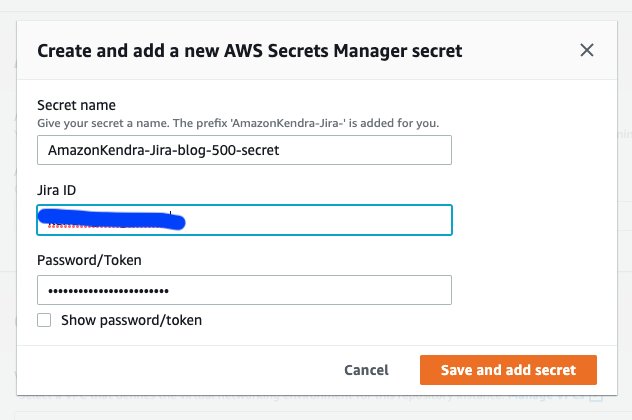
Konfigurer datakilden ved å bruke Amazon Kendra-kontakten for Jira
For å legge til en datakilde til Amazon Kendra-indeksen din ved å bruke Jira-koblingen, kan du bruke en eksisterende indeks eller opprette en ny indeks. Fullfør deretter følgende trinn. For mer informasjon om dette emnet, se Amazon Kendra utviklerveiledning.
- På Amazon Kendra-konsollen åpner du indeksen og velger Datakilder i navigasjonsruten.
- Velg Legg til datakilde.
- Under Jira, velg Legg til kontakt.

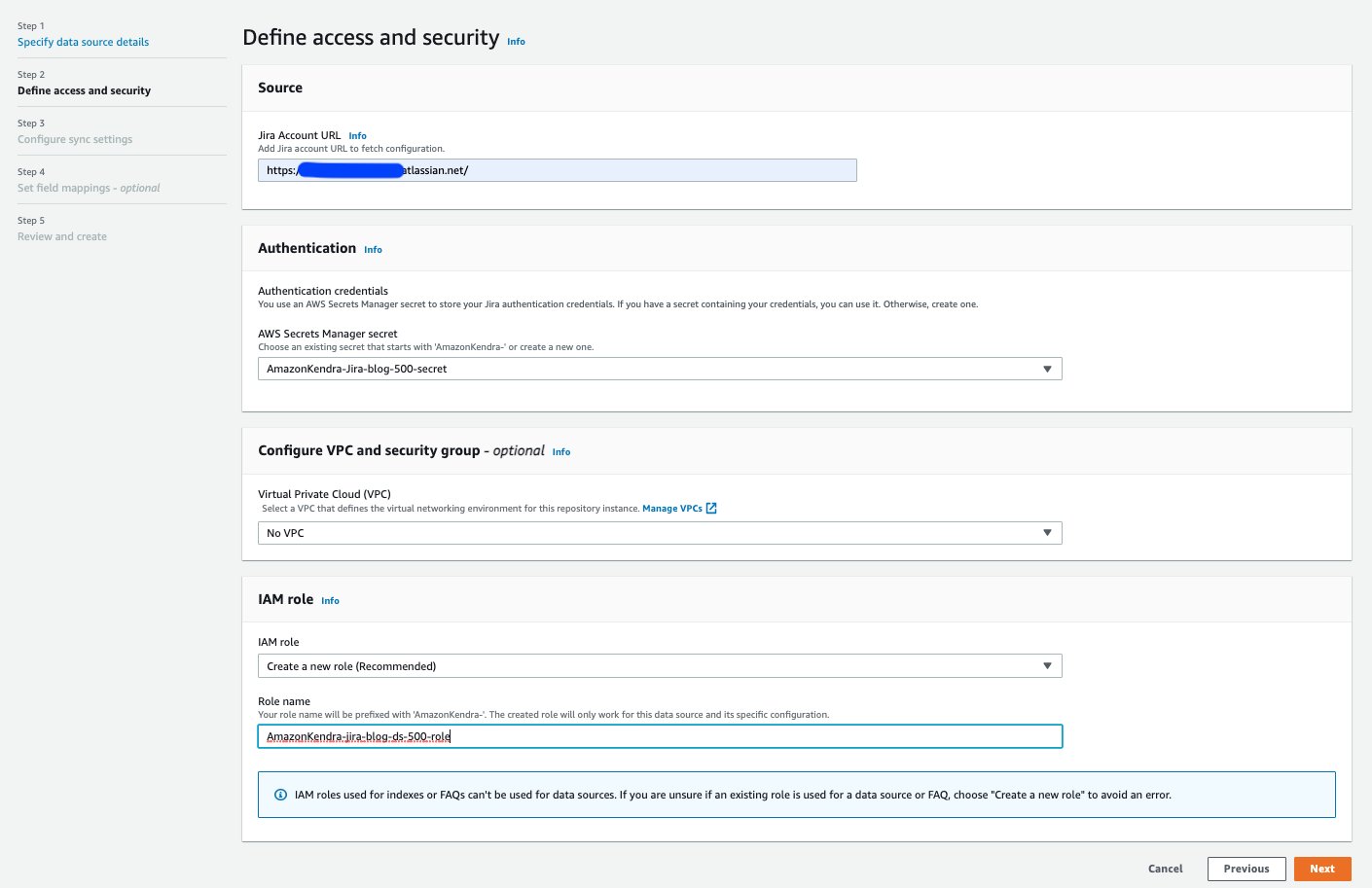
- på Spesifiser datakildedetaljer seksjon, skriv inn detaljene for datakilden og velg neste.
- på Definer tilgang og sikkerhet seksjon, for Jira-konto-URL, skriv inn URL-en til Jira-skyforekomsten din.
- Under Autentisering, har du to alternativer:
- Velg Opprett for å legge til en ny hemmelighet ved å bruke Jira API-tokenet du kopierte fra Jira-forekomsten og bruke e-postadressen som ble brukt til å logge på Jira som Jira-ID. (Dette er alternativet vi velger for dette innlegget.)
- Bruk en eksisterende AWS Secrets Manager hemmelighet som har API-tokenet for Jira-forekomsten du vil at koblingen skal få tilgang til.
- Til IAM-rolle, velg Lag en ny rolle eller velg en eksisterende IAM-rolle konfigurert med passende IAM-policyer for å få tilgang til Secrets Manager-hemmeligheten, Amazon Kendra-indeksen og datakilden.
- Velg neste.
- på Konfigurer synkroniseringsinnstillinger oppgi informasjon om synkroniseringsomfanget og kjøreplanen.
- Velg neste.
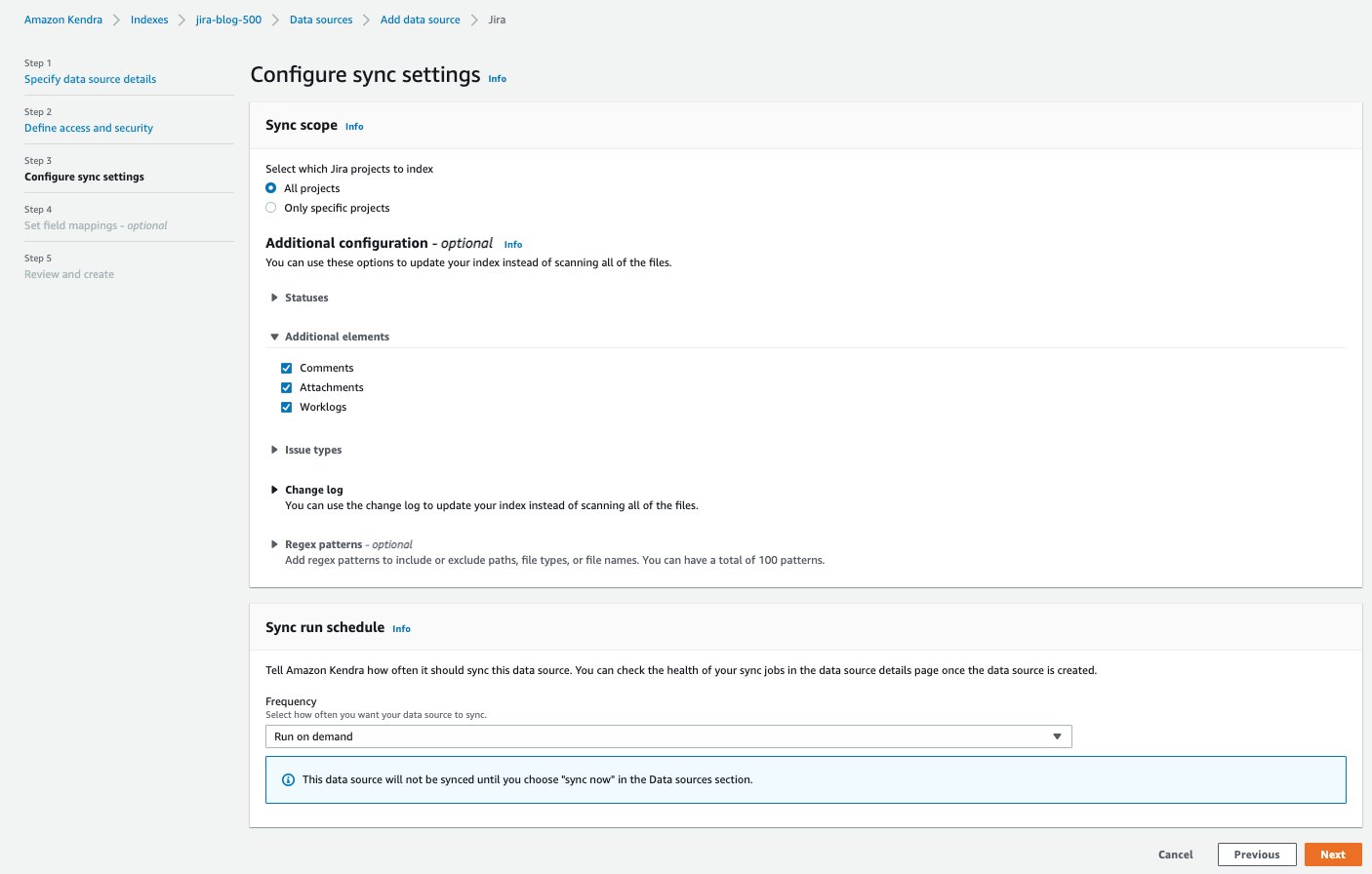
- på Angi feltkartlegginger seksjonen, kan du valgfritt konfigurere felttilordningene, eller hvordan Jira-feltnavnene tilordnes til Amazon Kendra-attributter eller fasetter.
- Velg neste.
- Se gjennom innstillingene og bekreft å legge til datakilden.
- Etter at datakilden er lagt til, velg Datakilder i navigasjonsruten, velg den nylig lagt til datakilden, og velg Synkroniser nå for å starte datakildesynkronisering med Amazon Kendra-indeksen.
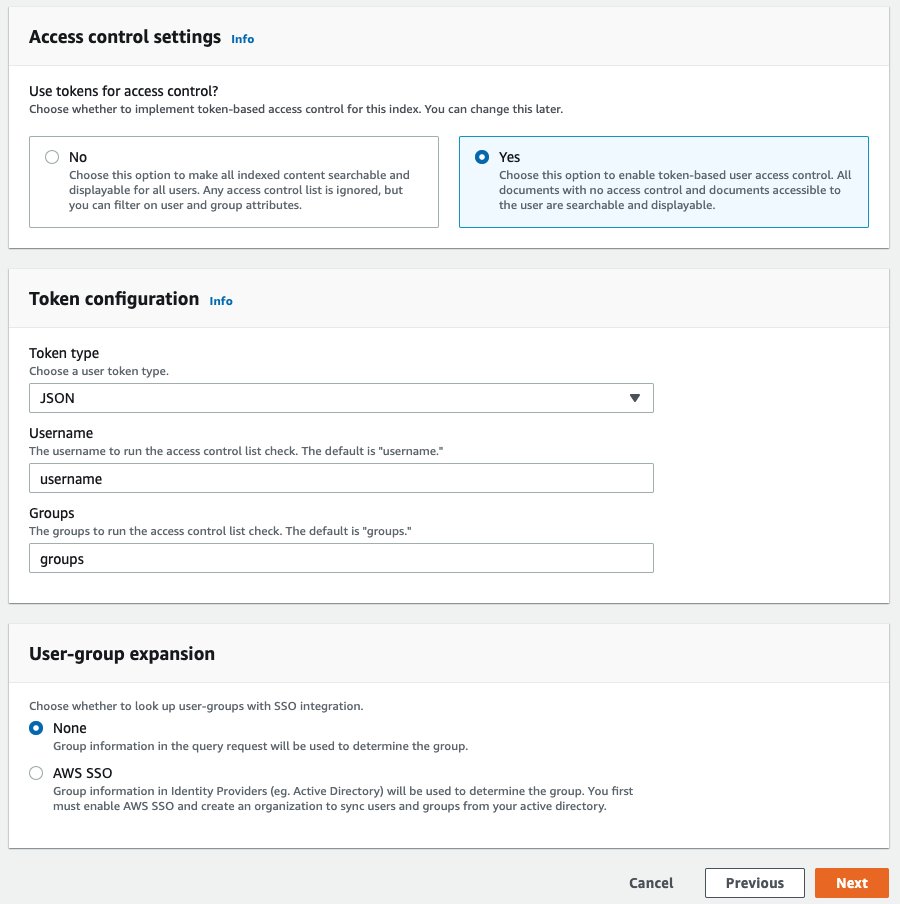
Synkroniseringsprosessen kan ta omtrent 10–15 minutter. La oss nå aktivere tilgangskontroll for Amazon Kendra-indeksen. - Velg indeksen din i navigasjonsruten.
- I midtruten velger du Brukertilgangskontroll fanen.
- Velg Endre innstillinger og endre innstillingene slik at de ser ut som følgende skjermbilde.
- Velg neste og velg deretter Oppdater.
Utfør intelligent søk med Amazon Kendra
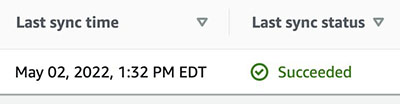
Før du prøver å søke på Amazon Kendra-konsollen eller bruker API, må du kontrollere at datakildesynkroniseringen er fullført. For å sjekke, se datakildene og kontroller om den siste synkroniseringen var vellykket.
- For å starte søket, velg på Amazon Kendra-konsollen Søk etter indeksert innhold i navigasjonsruten.
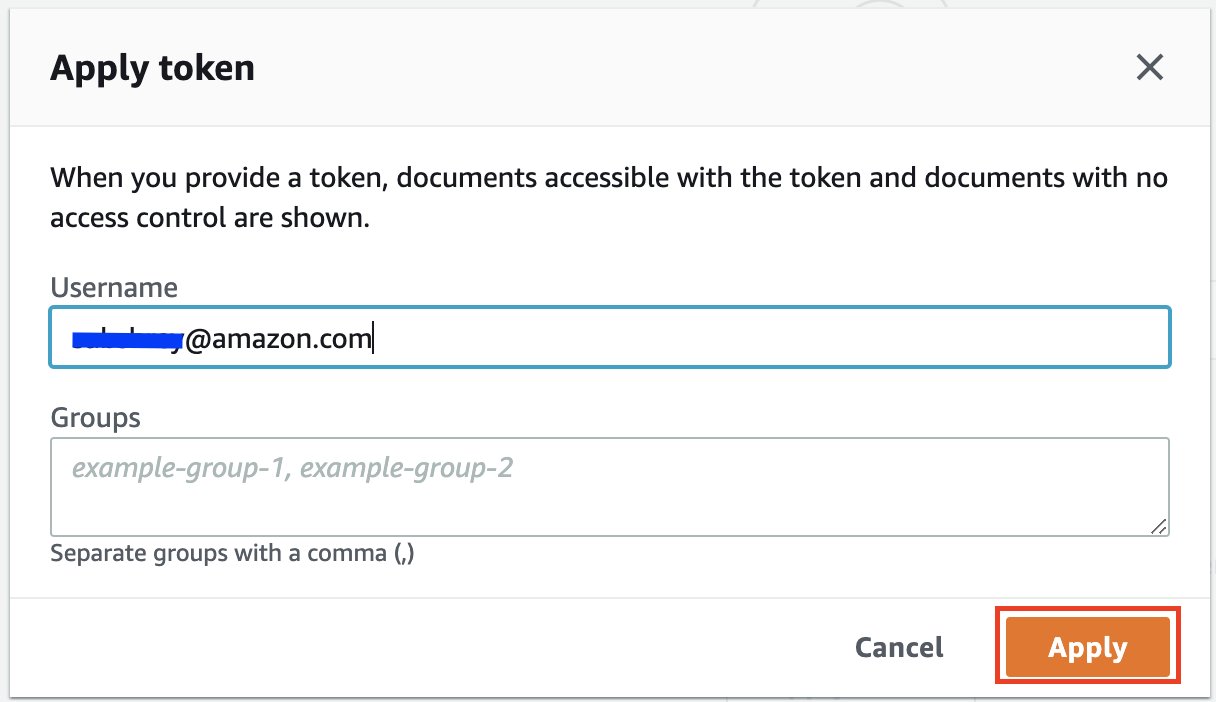
Du blir omdirigert til Amazon Kendra Search-konsollen. - Expand Testsøk med et tilgangstoken Og velg Bruk token.
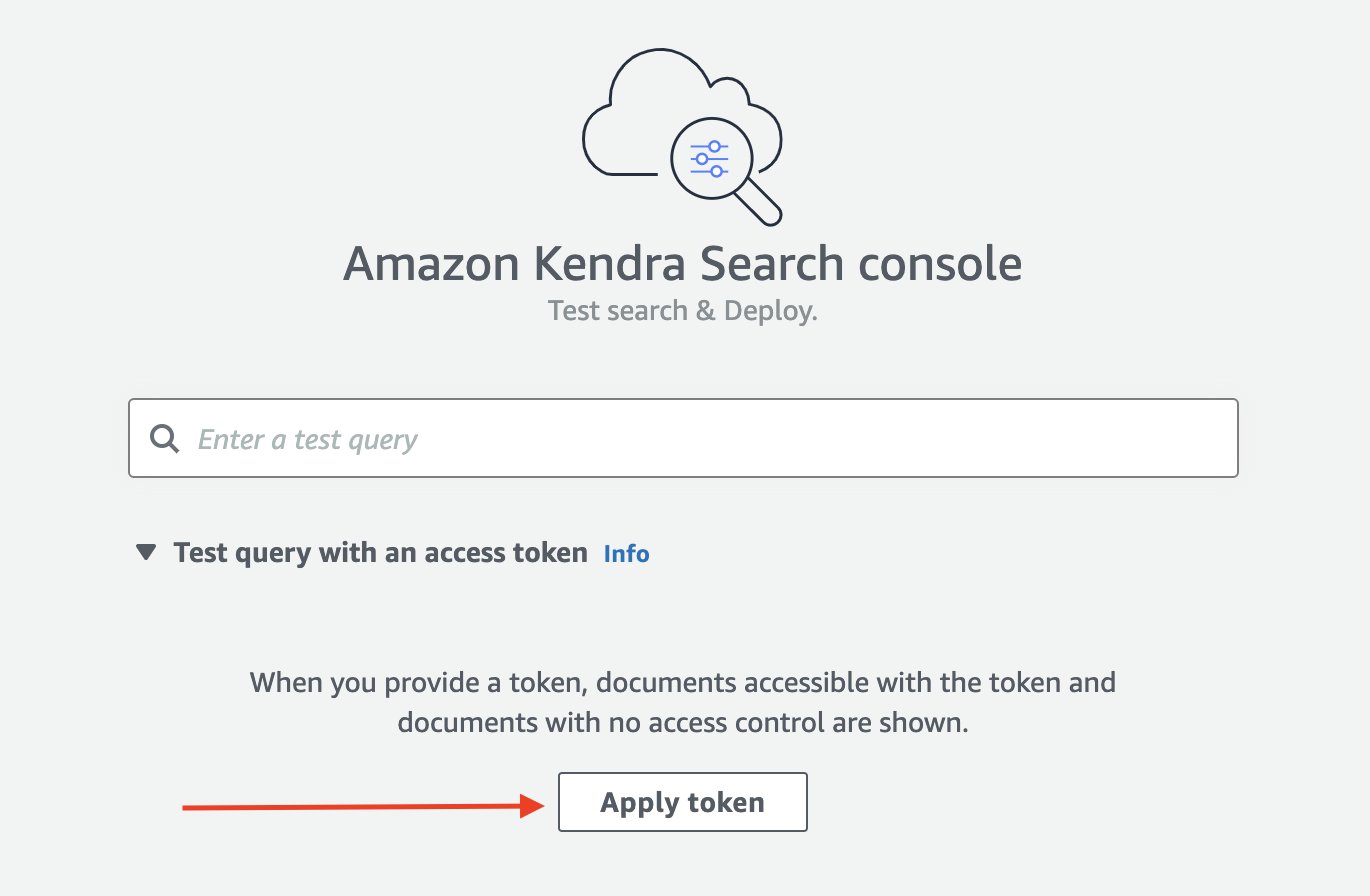
- Til Brukernavn, skriv inn e-postadressen knyttet til Jira-kontoen din.
- Velg Påfør.
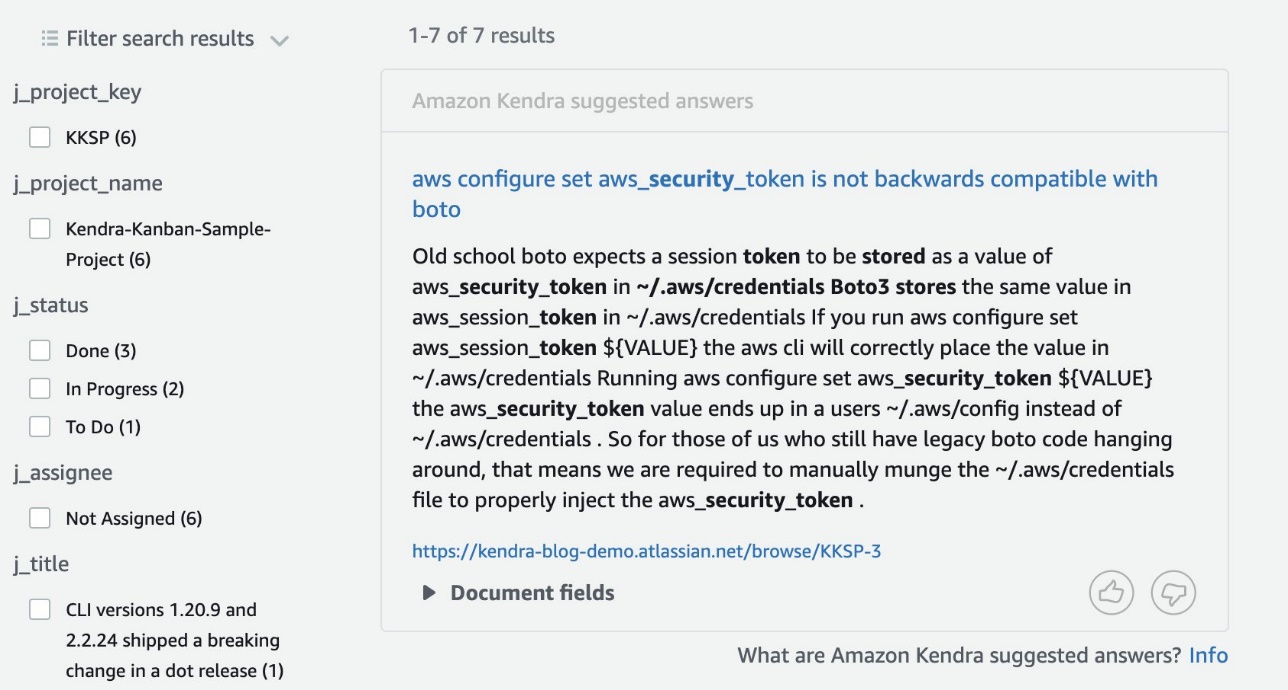
Nå er vi klare til å søke i indeksen vår. La oss bruke spørringen "hvor lagrer boto3 sikkerhetstokens?"

I dette tilfellet gir Kendra et forslag til svar fra et av kortene i vårt Kanban-prosjekt på Jira.
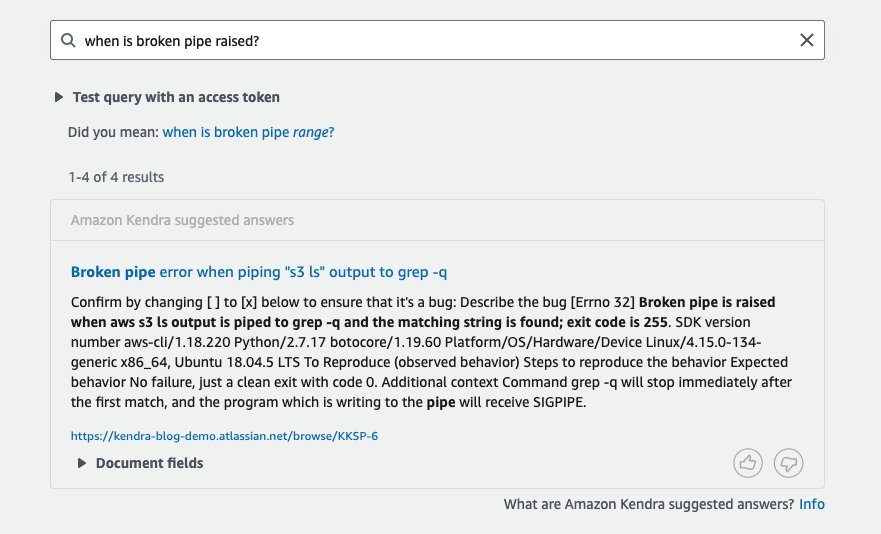
Merk at dette også er et foreslått svar som peker på et problem som diskuterer AWS-sikkerhetstokener og Boto3. Du kan også bygge søkeopplevelse med flere datakilder, inkludert SDK-dokumentasjon og wikier med Amazon Kendra, og presentere resultater og relaterte lenker deretter. Følgende skjermbilde viser et annet søk gjort mot samme indeks.
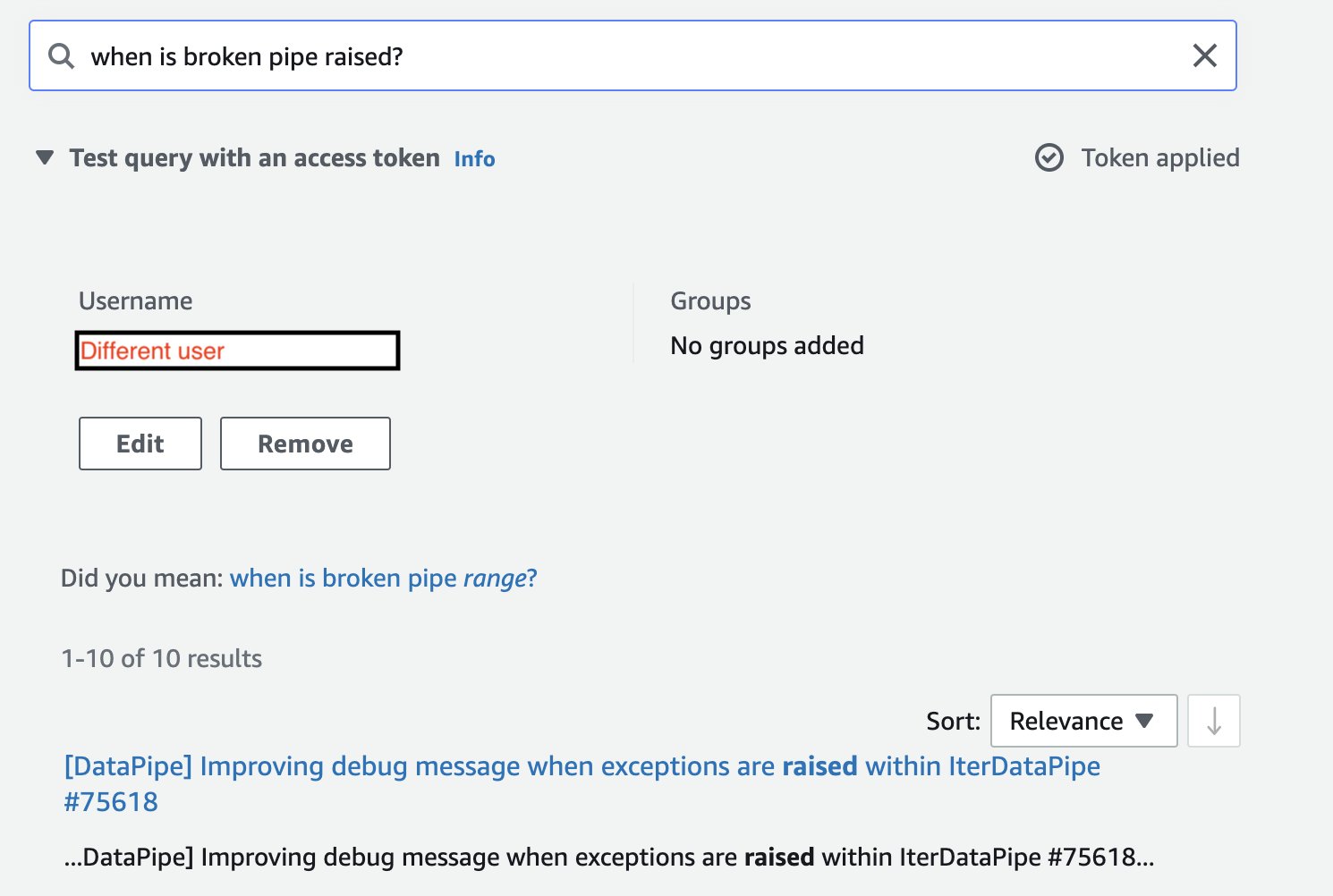
Merk at når vi bruker et annet tilgangstoken (knytter søket til en annen bruker), er søkeresultatene begrenset til prosjekter som denne brukeren har tilgang til.
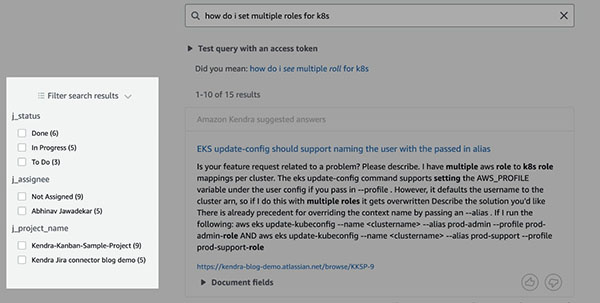
Til slutt kan vi også bruke filtre som er relevante for Jira i søket vårt. Først navigerer vi til indeksen vår Fasetdefinisjon side og sjekk Fasettabel forum j_status, j_assigneeog j_project_name. For hvert søk kan vi deretter filtrere etter disse feltene, som vist i følgende skjermbilde.
Rydd opp
For å unngå å pådra seg fremtidige kostnader, ryd opp i ressursene du opprettet som en del av denne løsningen. Hvis du opprettet en ny Amazon Kendra-indeks mens du testet denne løsningen, slett den. Hvis du bare har lagt til en ny datakilde ved å bruke Amazon Kendra-koblingen for Jira, slett den datakilden.
konklusjonen
Med Amazon Kendra Jira-koblingen kan organisasjonen din gjøre uvurderlig kunnskap i Jira-prosjektene dine tilgjengelig for brukerne på en sikker måte ved hjelp av intelligent søk drevet av Amazon Kendra.
For å lære mer om Amazon Kendra Jira-kontakten, se Amazon Kendra Jira-kontakt delen av Amazon Kendra Developer Guide.
For mer informasjon om andre Amazon Kendra innebygde koblinger til populære datakilder, se Løsne opp kunnskapen i Slack-arbeidsområder med intelligent søk ved å bruke Amazon Kendra Slack-kontakten og Søk etter kunnskap i Quip-dokumenter med intelligent søk ved hjelp av Quip-kontakten for Amazon Kendra.
Om forfatterne
 Shreyas Subramanian er en AI/ML-spesialist Solutions Architect, og hjelper kunder ved å bruke Machine Learning til å løse forretningsutfordringene deres på AWS Cloud.
Shreyas Subramanian er en AI/ML-spesialist Solutions Architect, og hjelper kunder ved å bruke Machine Learning til å løse forretningsutfordringene deres på AWS Cloud.
 Abhinav Jawadekar er en hovedløsningsarkitekt med fokus på Amazon Kendra i AI/ML-språktjenesteteamet hos AWS. Abhinav jobber med AWS-kunder og partnere for å hjelpe dem med å bygge intelligente søkeløsninger på AWS.
Abhinav Jawadekar er en hovedløsningsarkitekt med fokus på Amazon Kendra i AI/ML-språktjenesteteamet hos AWS. Abhinav jobber med AWS-kunder og partnere for å hjelpe dem med å bygge intelligente søkeløsninger på AWS.
- Myntsmart. Europas beste Bitcoin og Crypto Exchange.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. FRI TILGANG.
- CryptoHawk. Altcoin Radar. Gratis prøveperiode.
- Kilde: https://aws.amazon.com/blogs/machine-learning/intelligently-search-your-jira-projects-with-amazon-kendra-jira-cloud-connector/
- "
- 100
- 420
- Om oss
- adgang
- tilsvar
- Logg inn
- tvers
- adresse
- admin
- administrasjon
- smidig
- Amazon
- En annen
- besvare
- api
- hensiktsmessig
- Førsteamanuensis
- attributter
- tilgjengelig
- AWS
- være
- borde
- grensen
- Eske
- bygge
- innebygd
- virksomhet
- fanger
- Kort
- bære
- utfordringer
- utfordrende
- endring
- Velg
- nedleggelse
- Cloud
- samarbeide
- kommentarer
- samfunnet
- Konfigurasjon
- Konsoll
- innhold
- innhold
- bidra
- kontroll
- Kostnader
- skape
- opprettet
- skaper
- Opprette
- Kunder
- dato
- demonstrere
- detaljer
- Utvikler
- utviklere
- Utvikling
- forskjellig
- dokumenter
- domene
- under
- lett
- emalje
- muliggjøre
- Ingeniører
- Enter
- utvikling
- eksempel
- eksisterende
- erfaring
- Felt
- filtrering
- filtre
- Først
- fokuserte
- etter
- skjema
- framtid
- GitHub
- hjelpe
- hjelper
- Hvordan
- Hvordan
- Men
- HTTPS
- Identitet
- gjennomføring
- Inkludert
- indeks
- informasjon
- Intelligent
- utstedelse
- saker
- IT
- kunnskap
- Språk
- LÆRE
- læring
- Bibliotek
- lenker
- Liste
- maskin
- maskinlæring
- laget
- Making
- ledelse
- leder
- Ledere
- medlem
- medlemmer
- ML
- mer
- flere
- navn
- Navigasjon
- åpen
- åpning
- Drift
- Alternativ
- alternativer
- organisasjon
- organisasjons
- Annen
- egen
- eiere
- del
- partnere
- Plattformer
- Politikk
- Populær
- presentere
- Principal
- prosess
- prosjekt
- prosjektledelse
- prosjekter
- gi
- gir
- offentlig
- relevant
- Ressurser
- Resultater
- retur
- Kjør
- SDK
- Søk
- sikkert
- sikkerhet
- Sikkerhetstegn
- Tjenester
- sett
- vist
- slakk
- Software
- programvareutvikling
- solid
- løsning
- Solutions
- LØSE
- spesialist
- Begynn
- status
- oppbevare
- vellykket
- lag
- midlertidig
- test
- Testing
- hele
- token
- tokens
- spor
- tradisjonelle
- bruke
- Brukere
- verifisere
- Se
- Hva
- mens
- arbeid
- virker