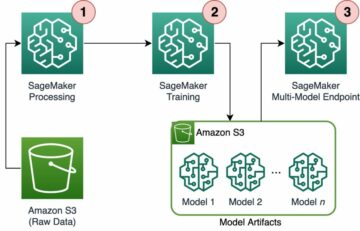
Amazon SageMaker Autopilot er en automatisert maskinlæringsløsning (AutoML) som utfører alle oppgavene du trenger for å fullføre en ende-til-ende maskinlæring (ML) arbeidsflyt. Den utforsker og forbereder dataene dine, bruker forskjellige algoritmer for å generere en modell, og gir på en transparent måte modellinnsikt og forklaringsrapporter for å hjelpe deg med å tolke resultatene. Autopilot kan også lage et endepunkt i sanntid for online inferens. Du kan få tilgang til autopilotens ett-klikks funksjoner i Amazon SageMaker Studio eller ved å bruke AWS SDK for Python (Boto3) eller SageMaker Python SDK.
I dette innlegget viser vi hvordan du lager batch-prediksjoner på et umerket datasett ved hjelp av en autopilot-trent modell. Vi bruker et syntetisk generert datasett som er en indikasjon på hvilke typer funksjoner du vanligvis ser når du forutsier kundefragang.
Løsningsoversikt
Batch slutning, eller offline inferens, er prosessen med å generere spådommer på en gruppe observasjoner. Batch-inferens forutsetter at du ikke trenger et øyeblikkelig svar på en modellforutsigelsesforespørsel, slik du ville gjort når du bruker et online, sanntidsmodellendepunkt. Offline spådommer er egnet for større datasett og i tilfeller der du har råd til å vente flere minutter eller timer på svar. I motsetning, på nett inferens genererer ML-spådommer i sanntid, og er passende referert til som sanntids slutning eller dynamisk slutning. Vanligvis genereres disse spådommene på en enkelt observasjon av data under kjøring.
Å miste kunder er kostbart for enhver bedrift. Å identifisere misfornøyde kunder tidlig gir deg en sjanse til å tilby dem insentiver til å bli. Mobiloperatører har historiske kundedata som viser de som har churnet og de som har opprettholdt tjenesten. Vi kan bruke denne historiske informasjonen til å konstruere en modell for å forutsi om en kunde vil churne ved å bruke ML.
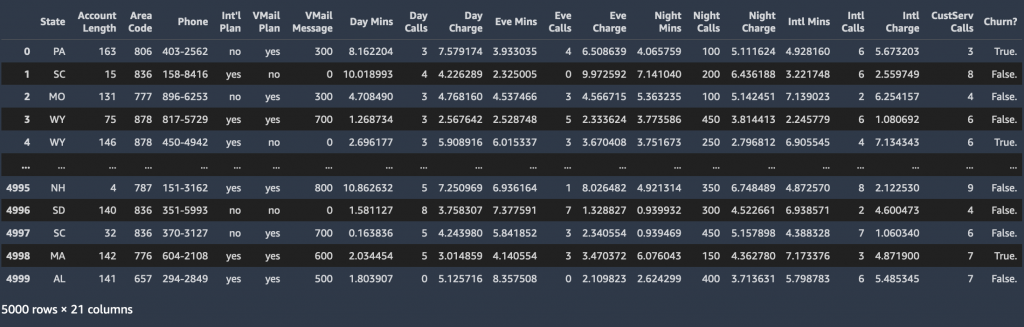
Etter at vi har trent en ML-modell, kan vi sende profilinformasjonen til en vilkårlig kunde (den samme profilinformasjonen som vi brukte til opplæring) til modellen, og få modellen til å forutsi om kunden vil churne eller ikke. Datasettet som brukes for dette innlegget ligger under mappen sagemaker-sample-files i en Amazon enkel lagringstjeneste (Amazon S3) offentlig bøtte, som du kan laste ned. Den består av 5,000 poster, der hver post bruker 21 attributter for å beskrive profilen til en kunde for en ukjent amerikansk mobiloperatør. Attributtene er som følger:
- Tilstand – USAs stat hvor kunden er bosatt, angitt med en forkortelse på to bokstaver; for eksempel TX eller CA
- Kontolengde – Antall dager denne kontoen har vært aktiv
- Retningsnummer – Tresifret retningsnummer for den tilsvarende kundens telefonnummer
- Telefon – Gjenværende sjusifrede telefonnummer
- Internasjonal plan – Har en internasjonal ringeplan: Ja/Nei
- VMail-plan – Har en talepostfunksjon: Ja/Nei
- VMail -melding – Gjennomsnittlig antall talepostmeldinger per måned
- Dagmins – Totalt antall ringeminutter brukt i løpet av dagen
- Dagsamtaler – Totalt antall anrop i løpet av dagen
- Dagsavgift – Fakturert kostnad for samtaler på dagtid
- Eve Mins, Eve Calls, Eve Charge – Fakturert kostnad for samtaler på kveldstid
- Nattminer, nattsamtaler, nattladning – Fakturert kostnad for samtaler om natten
- Internasjonale minutter, internasjonale samtaler, internasjonale gebyrer – Fakturert kostnad for internasjonale samtaler
- CustServ-samtaler – Antall anrop til kundeservice
- Churn? – Kunden forlot tjenesten: True/False
Det siste attributtet, Churn?, er målattributtet som vi vil at ML-modellen skal forutsi. Fordi målattributtet er binært, utfører modellen vår binær prediksjon, også kjent som binær klassifisering.
Forutsetninger
Last ned datasettet til ditt lokale utviklingsmiljø og utforsk det ved å kjøre følgende S3-kopikommando med AWS kommandolinjegrensesnitt (AWS CLI):
Du kan deretter kopiere datasettet til en S3-bøtte i din egen AWS-konto. Dette er inngangsstedet for autopilot. Du kan kopiere datasettet til Amazon S3 ved enten å laste opp til bøtte manuelt eller ved å kjøre følgende kommando ved å bruke AWS CLI:
Lag et autopiloteksperiment
Når datasettet er klart, kan du initialisere et autopiloteksperiment i SageMaker Studio. For fullstendige instruksjoner, se Lag et Amazon SageMaker Autopilot-eksperiment.
Under Grunnleggende innstillinger, kan du enkelt opprette et autopiloteksperiment ved å oppgi et eksperimentnavn, datainndata- og utdataplasseringene og spesifisere måldataene som skal forutsi. Eventuelt kan du spesifisere typen ML-problem du vil løse. Ellers, bruk Auto innstilling, og autopilot bestemmer automatisk modellen basert på dataene du oppgir.

Du kan også kjøre et autopiloteksperiment med kode ved å bruke enten AWS SDK for Python (Boto3) eller SageMaker Python SDK. Følgende kodebit viser hvordan du initialiserer et autopiloteksperiment ved å bruke SageMaker Python SDK. Vi bruker AutoML-klassen fra SageMaker Python SDK.
Etter at Autopilot starter et eksperiment, inspiserer tjenesten automatisk de rå inndataene, bruker funksjonsprosessorer og velger det beste settet med algoritmer. Etter at den har valgt en algoritme, optimerer Autopilot ytelsen ved hjelp av en søkeprosess for hyperparameteroptimalisering. Dette omtales ofte som trening og tuning av modellen. Dette bidrar til syvende og sist med å produsere en modell som nøyaktig kan gi spådommer på data den aldri har sett. Autopilot sporer automatisk modellens ytelse, og rangerer deretter de endelige modellene basert på beregninger som beskriver en modells nøyaktighet og presisjon.

Du har også muligheten til å distribuere hvilken som helst av de rangerte modellene enten ved å velge modellen (høyreklikk) og velge Implementer modell, eller ved å velge modellen i den rangerte listen og velge Implementer modell.
Lag batch-forutsigelser ved å bruke en modell fra Autopilot
Når autopiloteksperimentet ditt er fullført, kan du bruke den opplærte modellen til å kjøre batchprediksjoner på test- eller holdout-datasettet ditt for evaluering. Du kan deretter sammenligne de forutsagte etikettene med forventede etiketter hvis test- eller holdout-datasettet ditt er forhåndsmerket. Dette er i hovedsak en måte å sammenligne en modells spådommer med sannheten. Hvis flere av modellens spådommer samsvarer med de sanne etikettene, kan vi generelt kategorisere modellen som god ytelse. Du kan også kjøre batch-prediksjoner for å merke umerkede data. Du kan enkelt oppnå det samme ved å bruke høynivå SageMaker Python SDK med noen få linjer med kode.
Beskriv et tidligere kjørt autopiloteksperiment
Vi må først trekke ut informasjonen fra et tidligere fullført autopiloteksperiment. Vi kan bruke AutoML-klassen fra SageMaker Python SDK for å lage et automl-objekt som innkapsler informasjonen fra et tidligere Autopilot-eksperiment. Du kan bruke eksperimentnavnet du definerte da du initialiserte autopiloteksperimentet. Se følgende kode:
Med automl-objektet kan vi enkelt beskrive og gjenskape den best trente modellen, som vist i følgende utdrag:
I noen tilfeller vil du kanskje bruke en annen modell enn den beste modellen rangert av autopilot. For å finne en slik kandidatmodell kan du bruke automl-objektet og iterere gjennom listen over alle eller de beste N modellkandidatene og velge modellen du vil gjenskape. For dette innlegget bruker vi en enkel Python For-løkke for å iterere gjennom en liste over modellkandidater:
Tilpass slutningsresponsen
Når vi gjenskaper enten den beste eller en hvilken som helst annen av Autopilots trente modeller, kan vi tilpasse inferensresponsen for modellen ved å legge til den ekstra parameteren inference_response_keys, som vist i det foregående eksempelet. Du kan bruke denne parameteren for både binære eller multiklasse klassifiseringsproblemtyper:
- predicted_label – Den spådde klassen.
- sannsynlighet – I binær klassifisering, sannsynligheten for at resultatet er forutsagt som den andre eller True-klassen i målkolonnen. I flerklasseklassifisering, sannsynligheten for vinnerklassen.
- etiketter – En liste over alle mulige klasser.
- sannsynligheter – En liste over alle sannsynligheter for alle klasser (rekkefølge samsvarer med etiketter).
Fordi problemet vi tar tak i i dette innlegget er binær klassifisering, angir vi denne parameteren som følger i de foregående utdragene mens vi opprettet modellene:
Lag transformator og kjør batch-prediksjoner
Til slutt, etter at vi har gjenskapt kandidatmodellene, kan vi lage en transformator for å starte batchprediksjonsjobben, som vist i de følgende to kodebitene. Mens vi oppretter transformatoren, definerer vi spesifikasjonene til klyngen for å kjøre batchjobben, for eksempel antall forekomster og type. Batch-inngangen og -utgangen er Amazon S3-lokasjonene der våre datainnganger og -utganger er lagret. Batch-prediksjonsjobben drives av SageMaker batch-transformasjon.
Når jobben er fullført, kan vi lese batchutdataene og utføre evalueringer og andre nedstrømshandlinger.
Oppsummering
I dette innlegget demonstrerte vi hvordan du raskt og enkelt kan lage batch-forutsigelser ved å bruke autopilottrente modeller for evalueringene dine etter trening. Vi brukte SageMaker Studio til å initialisere et autopiloteksperiment for å lage en modell for å forutsi kundefragang. Deretter refererte vi til Autopilots beste modell for å kjøre batch-prediksjoner ved å bruke automl-klassen med SageMaker Python SDK. Vi brukte også SDK for å utføre batch-prediksjoner med andre modellkandidater. Med Autopilot utforsket og forhåndsbehandlet vi dataene våre automatisk, og skapte deretter flere ML-modeller med ett klikk, slik at SageMaker kan ta seg av å administrere infrastrukturen som trengs for å trene og tune modellene våre. Til slutt brukte vi batch-transformasjon for å lage spådommer med modellen vår ved å bruke minimal kode.
For mer informasjon om autopilot og dens avanserte funksjoner, se Automatiser modellutvikling med Amazon SageMaker Autopilot. For en detaljert gjennomgang av eksemplet i innlegget, ta en titt på følgende eksempel notisbok.
Om forfatterne
 Arunprasath Shankar er en kunstig intelligens og maskinlæring (AI / ML) spesialistløsningsarkitekt med AWS, som hjelper globale kunder å skalere sine AI-løsninger effektivt og effektivt i skyen. På fritiden liker Arun å se sci-fi-filmer og lytte til klassisk musikk.
Arunprasath Shankar er en kunstig intelligens og maskinlæring (AI / ML) spesialistløsningsarkitekt med AWS, som hjelper globale kunder å skalere sine AI-løsninger effektivt og effektivt i skyen. På fritiden liker Arun å se sci-fi-filmer og lytte til klassisk musikk.
 Peter Chung er en løsningsarkitekt for AWS, og brenner for å hjelpe kunder med å avdekke innsikt fra dataene deres. Han har bygget løsninger for å hjelpe organisasjoner med å ta datadrevne beslutninger i både offentlig og privat sektor. Han innehar alle AWS-sertifiseringer samt to GCP-sertifiseringer. Han liker kaffe, matlaging, å være aktiv og tilbringe tid med familien.
Peter Chung er en løsningsarkitekt for AWS, og brenner for å hjelpe kunder med å avdekke innsikt fra dataene deres. Han har bygget løsninger for å hjelpe organisasjoner med å ta datadrevne beslutninger i både offentlig og privat sektor. Han innehar alle AWS-sertifiseringer samt to GCP-sertifiseringer. Han liker kaffe, matlaging, å være aktiv og tilbringe tid med familien.
- "
- 000
- 100
- Om oss
- adgang
- Logg inn
- handlinger
- aktiv
- avansert
- AI
- algoritme
- algoritmer
- Alle
- Amazon
- AREA
- kunstig
- kunstig intelligens
- Kunstig intelligens og maskinlæring
- Automatisert
- gjennomsnittlig
- AWS
- BEST
- grensen
- Bygning
- virksomhet
- hvilken
- saker
- klassifisering
- Cloud
- kode
- Kaffe
- Kolonne
- Opprette
- Kunder
- dato
- utplassere
- Utvikling
- forskjellig
- Tidlig
- lett
- Endpoint
- Miljø
- eksempel
- gjennomføring
- forventet
- eksperiment
- familie
- Trekk
- Egenskaper
- Først
- etter
- fullt
- generere
- Global
- hjelpe
- hjelper
- historisk
- holder
- Hvordan
- Hvordan
- HTTPS
- umiddelbar
- informasjon
- Infrastruktur
- innsikt
- Intelligens
- internasjonalt
- IT
- Jobb
- Jobb
- kjent
- etiketter
- større
- læring
- linje
- Liste
- Lytting
- lokal
- plassering
- steder
- maskin
- maskinlæring
- administrerende
- manuelt
- Match
- Metrics
- ML
- Mobil
- modell
- modeller
- Filmer
- musikk
- Antall
- tilby
- på nett
- optimalisering
- Alternativ
- rekkefølge
- organisasjoner
- Annen
- ellers
- ytelse
- mulig
- prediksjon
- Spådommer
- privat
- Problem
- prosess
- produsere
- Profil
- gi
- gir
- offentlig
- raskt
- Raw
- sanntids
- rekord
- poster
- Rapporter
- svar
- Resultater
- Kjør
- rennende
- Skala
- SDK
- Søk
- sektorer
- tjeneste
- sett
- innstilling
- Enkelt
- Solutions
- LØSE
- utgifter
- Begynn
- Tilstand
- opphold
- lagring
- studio
- Target
- oppgaver
- test
- Gjennom
- tid
- topp
- Kurs
- Transform
- TX
- avdekke
- us
- bruke
- Voice
- vente
- om
- HVEM
- innenfor