Mange selskaper er overveldet av det store volumet av dokumenter de må behandle, organisere og klassifisere for å betjene kundene sine bedre. Eksempler på slike kan være lånesøknader, skatteangivelse og fakturering. Slike dokumenter mottas oftere i bildeformater og er for det meste flersidige og i lavkvalitetsformat. For å være mer konkurransedyktige og kostnadseffektive, og for å være sikre og kompatible på samme tid, må disse selskapene utvikle sine dokumentbehandlingsevner for å redusere behandlingstiden og forbedre klassifiseringsnøyaktigheten på en automatisert og skalerbar måte. Disse selskapene står overfor følgende utfordringer i behandlingen av dokumenter:
- Utføre moderering av dokumentene for å oppdage upassende, uønsket eller støtende innhold
- Manuell dokumentklassifisering, som tas i bruk av mindre selskaper, er tidkrevende, feilutsatt og dyrt
- OCR-teknikker med regelbaserte systemer er ikke intelligente nok og kan ikke tilpasses endringer i dokumentformat
- Bedrifter som tar i bruk maskinlæring (ML)-tilnærminger har ofte ikke ressurser til å skalere modellen for å håndtere topper i innkommende dokumentvolum
Dette innlegget takler disse utfordringene og gir en arkitektur som effektivt løser disse problemene. Vi viser hvordan du kan bruke Amazon-anerkjennelse og amazontekst å optimalisere og redusere menneskelig innsats i dokumentbehandling. Amazon Rekognition identifiserer modereringsetiketter i dokumentet ditt og klassifiserer dem ved hjelp av Amazon Rekognition Egendefinerte etiketter. Amazon Textract trekker ut tekst fra dokumentene dine.
I dette innlegget dekker vi å bygge to ML-rørledninger (opplæring og slutning) for å behandle dokumenter uten behov for manuell innsats eller tilpasset kode. Trinnene på høyt nivå i slutningspipelinen inkluderer:
- Utfør moderering av opplastede dokumenter ved hjelp av Amazon Rekognition.
- Klassifiser dokumenter i forskjellige kategorier, for eksempel W-2-er, fakturaer, kontoutskrifter og lønnsslipper ved å bruke egendefinerte etiketter for anerkjennelse.
- Trekk ut tekst fra dokumenter som trykt tekst, håndskrift, skjemaer og tabeller ved hjelp av Amazon Textract.
Løsningsoversikt
Denne løsningen bruker følgende AI-tjenester, serverløse teknologier og administrerte tjenester for å implementere en skalerbar og kostnadseffektiv arkitektur:
- Amazon DynamoDB - En nøkkelverdi og dokumentdatabase som leverer ensifret ytelse på millisekunder i alle målestokk.
- Amazon EventBridge – En serverløs hendelsesbuss for å bygge hendelsesdrevne applikasjoner i stor skala ved å bruke hendelser generert fra applikasjonene dine, integrert programvare som en tjeneste (SaaS) applikasjoner og AWS-tjenester.
- AWS Lambda – En serverløs databehandlingstjeneste som lar deg kjøre kode som svar på utløsere som endringer i data, endringer i systemtilstand eller brukerhandlinger.
- Amazon-anerkjennelse – Bruker ML til å identifisere objekter, personer, tekst, scener og aktiviteter i bilder og videoer, samt oppdage upassende innhold.
- Amazon Rekognition Egendefinerte etiketter – Bruker AutoML for datasyn og overføringslæring for å hjelpe deg med å trene tilpassede modeller for å identifisere objekter og scener i bilder som er spesifikke for bedriftens behov.
- Amazon Simple Storage Service (Amazon S3) – Fungerer som objektlager for dokumentene dine og gir mulighet for sentral administrasjon med finjusterte tilgangskontroller.
- Amazon Step-funksjoner – En serverløs funksjonsorkestrator som gjør det enkelt å sekvensere Lambda-funksjoner og flere tjenester til forretningskritiske applikasjoner.
- amazontekst - Bruker ML for å trekke ut tekst og data fra skannede dokumenter i PDF-, JPEG- eller PNG-format.
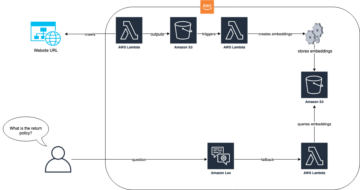
Følgende diagram illustrerer arkitekturen til inferensrørledningen.
 Arbeidsflyten vår inkluderer følgende trinn:
Arbeidsflyten vår inkluderer følgende trinn:
- Brukeren laster opp dokumenter til S3-inngangen.
- Opplastingen utløser en Amazon S3 hendelsesvarsling å levere sanntidshendelser direkte til EventBridge. Amazon S3-arrangementene som matcher "
object created” filter definert for en EventBridge-regel starter arbeidsflyten for trinnfunksjoner. - Step Functions-arbeidsflyten utløser en serie Lambda-funksjoner, som utfører følgende oppgaver:
- Den første funksjonen utfører forbehandlingsoppgaver og foretar API-kall til Amazon Rekognition:
- Hvis de innkommende dokumentene er i bildeformat (som JPG eller PNG), kaller funksjonen opp Amazon Rekognition API og gir dokumentene som S3-objekter. Men hvis dokumentet er i PDF-format, strømmer funksjonen bildebytene når den kaller Amazon Rekognition API.
- Hvis et dokument inneholder flere sider, deler funksjonen opp dokumentet i individuelle sider og lagrer dem i en mellomliggende mappe i S3-utgangen før de behandles individuelt.
- Når forbehandlingsoppgavene er fullført, foretar funksjonen et API-kall til Amazon Rekognition for å oppdage upassende, uønsket eller støtende innhold, og foretar et nytt API-kall til den trente Rekognition Custom Labels-modellen for å klassifisere dokumenter.
- Den andre funksjonen foretar et API-kall til Amazon Textract for å starte en jobb for å trekke ut tekst fra inndatadokumentet og lagre den i utdata S3-bøtten.
- Den tredje funksjonen lagrer dokumentmetadata som modereringsetikett, dokumentklassifisering, klassifiseringssikkerhet, Amazon Textract jobb-ID og filbane i en DynamoDB-tabell.
- Den første funksjonen utfører forbehandlingsoppgaver og foretar API-kall til Amazon Rekognition:
Du kan justere arbeidsflyten i henhold til dine krav, for eksempel kan du legge til en naturlig språkbehandlingsfunksjon (NLP) i denne arbeidsflyten ved å bruke Amazon Comprehend for å få innsikt i den utpakkede teksten.
Opplæringspipeline
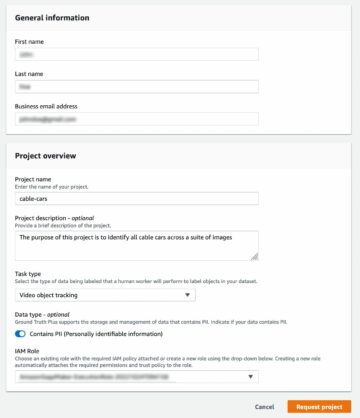
Før vi distribuerer denne arkitekturen, trener vi en tilpasset modell for å klassifisere dokumenter i forskjellige kategorier ved å bruke Rekognition Custom Labels. I opplæringspipelinen merker vi dokumentene vha Amazon SageMaker Ground Truth. Vi bruker deretter de merkede dokumentene til å trene en modell med Rekognition Custom Labels. I dette eksemplet bruker vi en Amazon SageMaker notebook for å utføre disse trinnene, men du kan også kommentere bilder ved å bruke Rekognition Custom Labels-konsollen. For instruksjoner, se Merking av bilder.
datasett
For å trene modellen bruker vi følgende offentlige datasett som inneholder W2-er og fakturaer:
Du kan bruke et annet datasett som er relevant for din bransje.
Tabellen nedenfor oppsummerer datasettdelingen mellom trening og testing.
| Klasse | Treningssett | Testsett |
| Fakturaer | 352 | 75 |
| W-2s | 86 | 16 |
| Totalt | 438 | 91 |
Distribuer treningspipelinen med AWS CloudFormation
Du distribuerer en AWS skyformasjon mal for å skaffe det nødvendige AWS identitets- og tilgangsadministrasjon (IAM) roller og komponenter i opplæringspipelinen, inkludert en SageMaker notebook-forekomst.
- Start følgende CloudFormation-mal i US East (N. Virginia)-regionen:

- Til Stabelnavn, skriv inn et navn, for eksempel
document-processing-training-pipeline. - Velg neste.
- på Evner og transformasjoner seksjonen, merk av i avmerkingsboksen for å bekrefte at AWS CloudFormation kan opprette IAM-ressurser.
- Velg Lag stabel.
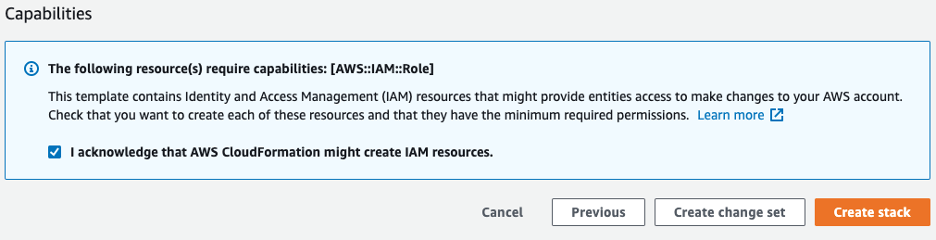
Stabeldetaljsiden skal vise statusen til stabelen som CREATE_IN_PROGRESS. Det kan ta opptil 5 minutter før statusen endres til CREATE_COMPLETE. Når den er ferdig, kan du se utgangene på Utganger fanen.
- Etter at stabelen er lansert, åpner du SageMaker-konsollen og velger Notatboksforekomster i navigasjonsnavnet.
- Se etter en forekomst med
DocProcessingNotebookInstance-prefiks og vent til statusen er InService. - Under handlinger, velg Åpne Jupyter.

Kjør eksempelnotisboken
Gjør følgende for å kjøre notatblokken:
- Velg
Rekognition_Custom_Labelseksempel notatbok.
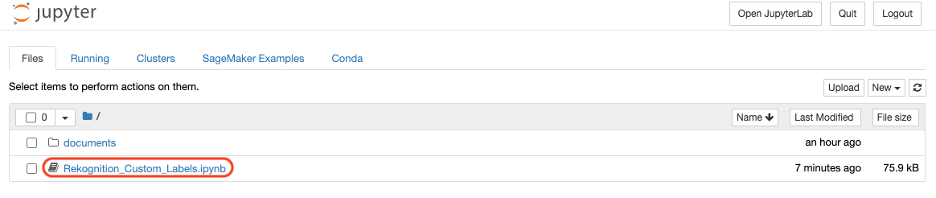
- Velg Kjør for å kjøre cellene i eksempelnotisboken i rekkefølge.

Notebooken demonstrerer hele livssyklusen for å forberede trenings- og testbilder, merke dem, lage manifestfiler, trene en modell og kjøre den trente modellen med Rekognition Custom Labels. Alternativt kan du trene og kjøre modellen ved å bruke Rekognition Custom Labels-konsollen. For instruksjoner, se Trene en modell (konsoll).
Notatboken er selvforklarende; du kan følge trinnene for å fullføre opplæringen av modellen.
- Noter
ProjectVersionArnfor å sørge for inferensrørledningen i et senere trinn.
For SageMaker-notebook-forekomster belastes du for forekomsttypen du velger, basert på bruksvarigheten. Hvis du er ferdig med å trene modellen, kan du stoppe forekomsten av den bærbare datamaskinen for å unngå utgifter til ledige ressurser.
Distribuer inferensrørledningen med AWS CloudFormation
For å distribuere inferensrørledningen, fullfør følgende trinn:
- Start følgende CloudFormation-mal i US East (N. Virginia)-regionen:
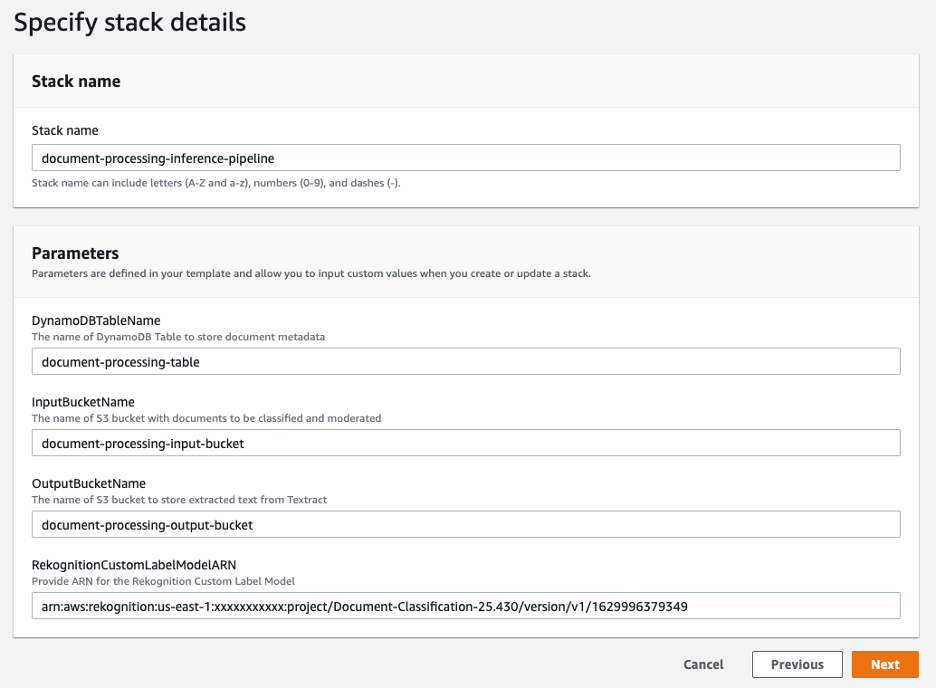
- Til Stabelnavn, skriv inn et navn, for eksempel
document-processing-inference-pipeline. - Til DynamoDBTableName, skriv inn et unikt DynamoDB-tabellnavn; for eksempel,
document-processing-table. - Til InputBucketName, skriv inn et unikt navn for S3-bøtten som stabelen lager; for eksempel,
document-processing-input-bucket.
Inndatadokumentene lastes opp til denne bøtten før de behandles. Bruk bare små bokstaver og ingen mellomrom når du oppretter navnet på inndataområdet. Videre oppretter denne operasjonen en ny S3-bøtte, så ikke bruk navnet på en eksisterende bøtte. For mer informasjon, se Regler for navn på bøtte.
- Til OutputBucketName, skriv inn et unikt navn for utdatabøtten din; for eksempel d
ocument-processing-output-bucket.
Denne bøtten lagrer utdatadokumentene etter at de er behandlet. Den lagrer også sider med flersidige PDF-inndatadokumenter etter at de er delt av Lambda-funksjonen. Følg de samme navnereglene som inndatabøtten.
- Til AnerkjennelseCustomLabelModelARN, Skriv inn
ProjectVersionArnverdien du noterte fra Jupyter-notisboken. - Velg neste.
- På Konfigurer stakkalternativer side, angi eventuelle tilleggsparametere for stakken, inkludert koder.
- Velg neste.
- på Evner og transformasjoner seksjonen, merk av i avmerkingsboksen for å erkjenne at AWS CloudFormation kan opprette IAM-ressurser.
- Velg Lag stabel.
Stabeldetaljsiden skal vise statusen til stabelen som CREATE_IN_PROGRESS. Det kan ta opptil 5 minutter før statusen endres til CREATE_COMPLETE. Når den er ferdig, kan du se utgangene på Utganger fanen.
Behandle et dokument gjennom rørledningen
Vi har distribuert både opplærings- og inferenspipelines, og er nå klare til å bruke løsningen og behandle et dokument.
- Åpne inndatabøtten på Amazon S3-konsollen.
- Last opp et eksempeldokument til S3-mappen.
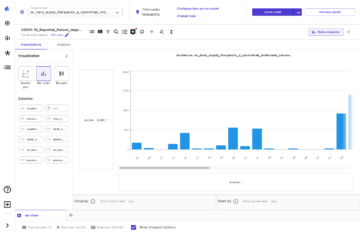
Dette starter arbeidsflyten. Prosessen fyller DynamoDB-tabellen med dokumentklassifisering og modereringsetiketter. Utgangen fra Amazon Textract leveres til utgangs S3-bøtten i TextractOutput mappe.
Vi sendte inn noen forskjellige eksempeldokumenter til arbeidsflyten og mottok følgende informasjon fylt ut i DynamoDB-tabellen.
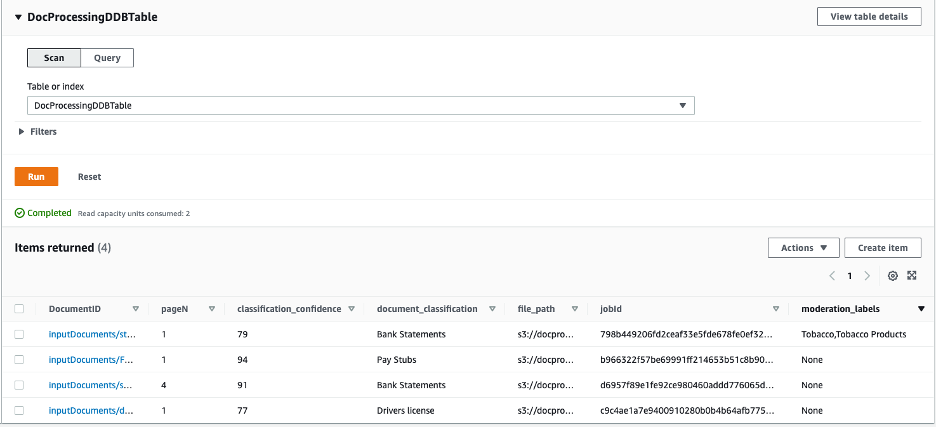
Hvis du ikke ser elementer i DynamoDB-tabellen eller dokumenter lastet opp i S3-utdatabøtten, sjekk Amazon CloudWatch-logger for den tilsvarende Lambda-funksjonen og se etter potensielle feil som forårsaket feilen.
Rydd opp
Fullfør følgende trinn for å rydde opp i ressurser som er distribuert for denne løsningen:
- På CloudFormation-konsollen velger du Stabler.
- Velg stablene som er distribuert for denne løsningen.
- Velg Delete.
Disse trinnene sletter ikke S3-bøttene, DynamoDB-tabellen og den trente Rekognition Custom Labels-modellen. Du fortsetter å pådra deg lagringskostnader hvis de ikke blir slettet. Du bør slette disse ressursene direkte via deres respektive tjenestekonsoller hvis du ikke lenger trenger dem.
konklusjonen
I dette innlegget presenterte vi en skalerbar, sikker og automatisert tilnærming til å moderere, klassifisere og behandle dokumenter. Bedrifter på tvers av flere bransjer kan bruke denne løsningen til å forbedre virksomheten og betjene kundene sine bedre. Det gir mulighet for raskere dokumentbehandling og høyere nøyaktighet, og reduserer kompleksiteten ved datautvinning. Det gir også bedre sikkerhet og overholdelse av personopplysningslovgivningen ved å redusere den menneskelige arbeidsstyrken som er involvert i behandlingen av innkommende dokumenter.
For mer informasjon, se Guide for egendefinerte etiketter for Amazon Rekognition, Amazon Rekognition utviklerveiledning og Amazon Textract utviklerveiledning. Hvis du er ny på Amazon Rekognition Custom Labels, kan du prøve det ved å bruke vårt gratis nivå, som varer i 3 måneder og inkluderer 10 gratis treningstimer per måned og 4 gratis inferenstimer per måned. Amazon Rekognition gratis nivå inkluderer behandling av 5,000 bilder per måned i 12 måneder. Amazon Textract gratis nivå varer også i tre måneder og inkluderer 1,000 sider per måned for Detect Document Text API.
Om forfatterne
 Jay Rao er en hovedløsningsarkitekt ved AWS. Han liker å gi teknisk og strategisk veiledning til kunder og hjelpe dem med å designe og implementere løsninger på AWS.
Jay Rao er en hovedløsningsarkitekt ved AWS. Han liker å gi teknisk og strategisk veiledning til kunder og hjelpe dem med å designe og implementere løsninger på AWS.
 Uchenna Egbe er Associate Solutions Architect hos AWS. Han bruker fritiden sin på å undersøke om urter, te, supermat og hvordan han kan inkludere dem i sitt daglige kosthold.
Uchenna Egbe er Associate Solutions Architect hos AWS. Han bruker fritiden sin på å undersøke om urter, te, supermat og hvordan han kan inkludere dem i sitt daglige kosthold.
- Myntsmart. Europas beste Bitcoin og Crypto Exchange.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. FRI TILGANG.
- CryptoHawk. Altcoin Radar. Gratis prøveperiode.
- Kilde: https://aws.amazon.com/blogs/machine-learning/moderate-classify-and-process-documents-using-amazon-rekognition-and-amazon-textract/
- "
- 000
- 10
- 100
- 116
- 12 måneder
- Om oss
- adgang
- tvers
- handlinger
- Aktiviteter
- Ytterligere
- AI
- AI-tjenester
- Amazon
- En annen
- api
- søknader
- tilnærming
- arkitektur
- Førsteamanuensis
- Automatisert
- AWS
- Bank
- før du
- fakturering
- grensen
- Eske
- bygge
- Bygning
- buss
- virksomhet
- ring
- evner
- forårsaket
- sentral
- utfordringer
- endring
- ladet
- avgifter
- Velg
- klassifisering
- kode
- Selskaper
- konkurranse
- samsvar
- kompatibel
- Beregn
- datamaskin
- selvtillit
- Konsoll
- inneholder
- innhold
- fortsette
- Tilsvarende
- kostnadseffektiv
- dekke
- skape
- skaper
- Opprette
- skikk
- Kunder
- dato
- Database
- levert
- leverer
- utplassere
- utplassert
- utforming
- detaljer
- Utvikler
- Kosthold
- forskjellig
- direkte
- dokumenter
- effektivt
- innsats
- innsats
- Enter
- Event
- hendelser
- utvikle seg
- eksempel
- eksempler
- eksisterende
- ekstrakter
- Face
- Failure
- raskere
- Først
- følge
- etter
- skjema
- format
- skjemaer
- Gratis
- funksjon
- funksjoner
- Dess
- håndtere
- hjelpe
- hjelpe
- høyere
- Hvordan
- Men
- HTTPS
- menneskelig
- identifisere
- Identitet
- bilde
- iverksette
- forbedre
- inkludere
- inkluderer
- Inkludert
- individuelt
- bransjer
- industri
- informasjon
- inngang
- innsikt
- integrert
- Intelligent
- involvert
- IT
- Jobb
- merking
- etiketter
- Språk
- lansert
- læring
- Lovgivning
- maskin
- maskinlæring
- GJØR AT
- fikk til
- ledelse
- håndbok
- Match
- kunne
- ML
- modell
- modeller
- Måned
- måneder
- mer
- flere
- Naturlig
- Navigasjon
- nødvendig
- behov
- bærbare
- åpen
- drift
- Optimalisere
- rekkefølge
- Betale
- Ansatte
- ytelse
- personlig
- personlig informasjon
- potensiell
- Principal
- problemer
- prosess
- prosessering
- gi
- gir
- gi
- offentlig
- sanntids
- mottatt
- redusere
- redusere
- relevant
- Ressurser
- svar
- regler
- Kjør
- rennende
- skalerbar
- Skala
- Scener
- sikre
- sikkerhet
- Serien
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- Enkelt
- So
- Software
- programvare som en tjeneste
- solid
- løsning
- Solutions
- løser
- mellomrom
- splittet
- spagaten
- stable
- starter
- Tilstand
- uttalelser
- status
- opphold
- lagring
- oppbevare
- butikker
- Strategisk
- innsendt
- vellykket
- system
- Systemer
- oppgaver
- skatt
- Teknisk
- teknikker
- Technologies
- test
- Testing
- Gjennom
- tid
- tidkrevende
- ganger
- Kurs
- overføre
- unik
- us
- bruke
- verdi
- Verifisering
- videoer
- Se
- Virginia
- syn
- volum
- vente
- uten
- arbeidsstyrke