Gartner, Inc. anslår det dårlige datakostnader organisasjoner i gjennomsnitt 12.9 millioner USD årlig.
Vi håndterer Petabytes med data daglig, og datakvalitetsproblemer er vanlige med slike store datamengder. Dårlige data koster organisasjoner penger, omdømme og tid. Derfor er det svært viktig å overvåke og validere datakvaliteten kontinuerlig.
Dårlige data inkluderer unøyaktig informasjon, manglende data, feil informasjon, data som ikke samsvarer og dupliserte data. Dårlige data vil resultere i feil dataanalyse, noe som resulterer i dårlige beslutninger og ineffektive strategier.
Experian datakvalitet fant at gjennomsnittlig bedrift mister 12 % av inntektene på grunn av utilstrekkelig data. Bortsett fra penger, lider bedrifter også tap av bortkastet tid.
Å identifisere uregelmessighetene i data før behandling vil hjelpe organisasjoner med å få mer verdifull innsikt i kundeatferden deres og bidra til reduserte kostnader.
Biblioteket med store forventninger hjelper organisasjoner med å verifisere og hevde slike uregelmessigheter i dataene med mer enn 200+ ut-av-boksen-regler lett tilgjengelig.
Great Expectations er et åpen kildekode Python-bibliotek som hjelper oss med å validere data. Store forventninger gi et sett med metoder eller funksjoner til hjelpe dataingeniørene raskt validere et gitt datasett.
I denne artikkelen vil vi se på trinnene som er involvert i å validere dataene ved Great Expectations-biblioteket.
GE er som enhetstester for data. GE gir påstander kalt Expectations for å anvende noen regler på dataene som testes. For eksempel skal ikke polise-ID/-nummer stå tomt for et forsikringsdokument. For å sette opp og kjøre GE, må du følge trinnene nedenfor. Selv om det er flere måter å jobbe med GE på (ved å bruke CLI), vil jeg forklare den programmatiske måten å sette opp ting på i denne artikkelen. All kildekoden som er forklart i denne artikkelen er tilgjengelig i denne GitHub repo.
Trinn 1: Sett opp datakonfigurasjonen
GE har et konsept med butikker. Butikker er ikke annet enn den fysiske plasseringen på disken der den kan lagre forventningene (regler/påstander), kjøredetaljer, sjekkpunktdetaljer, valideringsresultater og datadokumenter (statiske HTML-versjoner av valideringsresultatene). Klikk her for å lære mer om butikker.
GE støtter ulike butikkstøtter. I denne artikkelen bruker vi fillager-backend og standardinnstillinger. GE støtter andre butikkstøtter som AWS (Amazon Web Services) S3, Azure Blobs, PostgreSQL osv. Se dette til vite mer om backends. Kodebiten nedenfor viser en veldig enkel datakonfigurasjon:
STORE_FOLDER = "/Users/saisyam/work/github/great-expectations-sample/ge_data"
#Setup data config
data_context_config = DataContextConfig( datasources = {}, store_backend_defaults = FilesystemStoreBackendDefaults(root_directory=STORE_FOLDER)
) context = BaseDataContext(project_config = data_context_config)
Konfigurasjonen ovenfor bruker fillagerets backend med standardinnstillinger. GE vil automatisk opprette de nødvendige mappene som trengs for å oppfylle forventningene. Vi vil legge til datakilder i neste trinn.
Trinn 2: Konfigurer datakildekonfigurasjon
GE støtter tre typer datakilder:
- pandaer
- Spark
- SQLAlchemy
Datakildekonfigurasjon forteller GE å bruke en spesifikk utførelsesmotor for å behandle det angitte datasettet. Hvis du for eksempel konfigurerer datakilden din til å bruke Pandas-utførelsesmotoren, må du gi en Pandas-dataramme med data til GE for å oppfylle dine forventninger. Nedenfor er et eksempel på bruk av Pandas som datakilde:
datasource_config = { "name": "sales_datasource", "class_name": "Datasource", "module_name": "great_expectations.datasource", "execution_engine": { "module_name": "great_expectations.execution_engine", "class_name": "PandasExecutionEngine", }, "data_connectors": { "default_runtime_data_connector_name": { "class_name": "RuntimeDataConnector", "module_name": "great_expectations.datasource.data_connector", "batch_identifiers": ["default_identifier_name"], }, },
}
context.add_datasource(**datasource_config)
Vennligst se denne dokumentasjonen for mer informasjon om datakilder.
Trinn 3: Lag en forventningspakke og legg til forventninger
Dette trinnet er den avgjørende delen. I dette trinnet vil vi lage en suite og legge til forventninger til suiten. Du kan vurdere en suite som en gruppe forventninger som vil kjøre som en batch. Forventningene vi skaper her er å validere en eksempelsalgsrapport. Du kan laste ned sales.csv filen.
Kodebiten nedenfor viser hvordan du oppretter en suite og legger til forventninger. Vi vil legge til to forventninger til suiten vår.
# Create expectations suite and add expectations
suite = context.create_expectation_suite(expectation_suite_name="sales_suite", overwrite_existing=True) expectation_config_1 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_in_set", kwargs={ "column": "product_group", "value_set": ["PG1", "PG2", "PG3", "PG4", "PG5", "PG6"] }
) suite.add_expectation(expectation_configuration=expectation_config_1) expectation_config_2 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_unique", kwargs={ "column": "id" }
) suite.add_expectation(expectation_configuration=expectation_config_2)
context.save_expectation_suite(suite, "sales_suite")
Den første forventningen, «expect_column_values_to_be_in_set» sjekker om kolonneverdiene (product_group) er lik noen av verdiene i det gitte verdisettet. Den andre forventningen sjekker om «id»-kolonneverdiene er unike.
Når forventningene er lagt til og lagret, kan vi nå kjøre disse forventningene på et datasett som vi vil se i trinn 4.
Trinn 4: Last inn og valider dataene
I dette trinnet vil vi laste inn CSV-filen vår i pandas.DataFrame og opprette et sjekkpunkt for å kjøre forventningene vi opprettet ovenfor.
# load and validate data
df = pd.read_csv("./sales.csv") batch_request = RuntimeBatchRequest( datasource_name="sales_datasource", data_connector_name="default_runtime_data_connector_name", data_asset_name="product_sales", runtime_parameters={"batch_data":df}, batch_identifiers={"default_identifier_name":"default_identifier"}
) checkpoint_config = { "name": "product_sales_checkpoint", "config_version": 1, "class_name":"SimpleCheckpoint", "expectation_suite_name": "sales_suite"
}
context.add_checkpoint(**checkpoint_config)
results = context.run_checkpoint( checkpoint_name="product_sales_checkpoint", validations=[ {"batch_request": batch_request} ]
)
Vi oppretter en batchforespørsel for våre data, og gir datakildenavnet, som vil fortelle GE å bruke en spesifikk utførelsesmotor, i vårt tilfelle, Pandas. Vi oppretter en sjekkpunktkonfigurasjon og validerer deretter batchforespørselen vår mot sjekkpunktet. Du kan legge til flere batchforespørsler hvis forventningene gjelder dataene i batchen i ett enkelt sjekkpunkt. `run_checkpoint`-metoden returnerer resultatet i JSON-format og kan brukes til videre behandling eller analyser.
Resultater
Når vi har kjørt forventningene til datasettet vårt, lager GE et statisk HTML-dashbord med resultatene for sjekkpunktet vårt. Resultatene inneholder antall evaluerte forventninger, vellykkede forventninger, mislykkede forventninger og suksessprosenter. Eventuelle poster som ikke samsvarer med de gitte forventningene vil bli uthevet på siden. Nedenfor er et eksempel for vellykket utførelse:
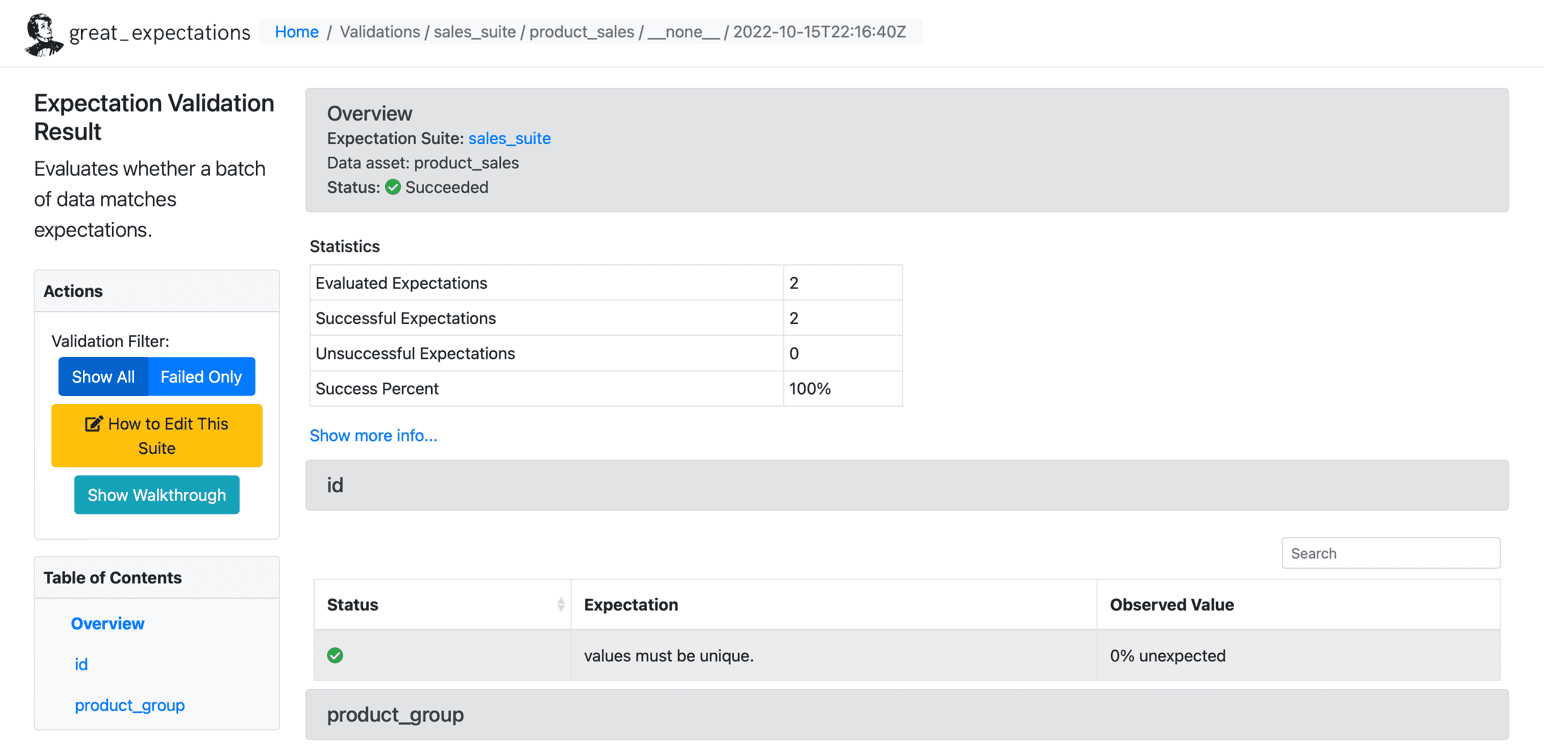
Kilde: Store forventninger
Nedenfor er et eksempel på den mislykkede forventningen:
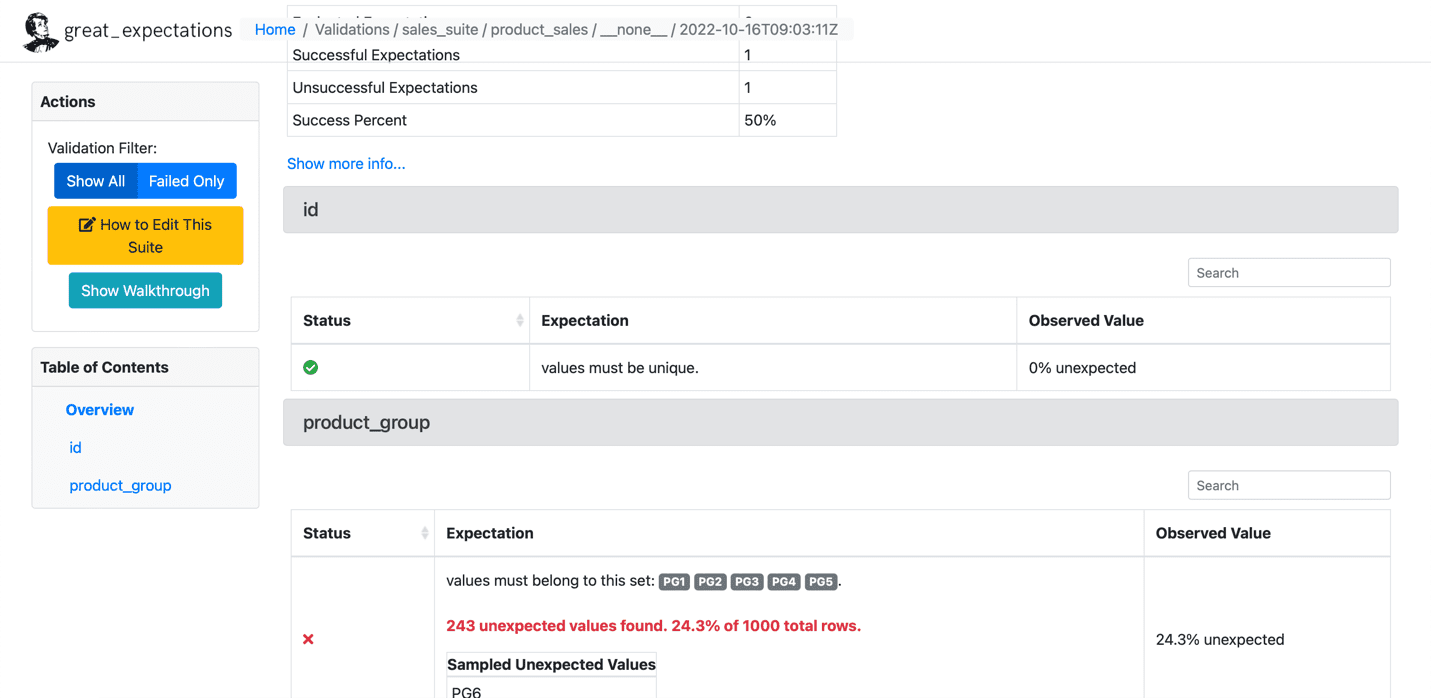
Kilde: Store forventninger
Vi har satt opp GE i fire trinn og har gjennomført forventninger på et gitt datasett. GE har mer avanserte funksjoner som å skrive dine tilpassede forventninger, som vi vil dekke i fremtidige artikler. Mange organisasjoner bruker GE mye for å tilpasse kundenes krav og skrive tilpassede forventninger.
Saisyam Dampuri kommer med 18+ års erfaring med programvareutvikling og brenner for å utforske nye teknologier og verktøy. Han jobber for tiden som Sr. Cloud Architect i Anblicks, TX, USA. Selv om han ikke koder, vil han være opptatt med fotografering, matlaging og reiser.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://www.kdnuggets.com/2023/01/overcome-data-quality-issues-great-expectations.html?utm_source=rss&utm_medium=rss&utm_campaign=overcome-your-data-quality-issues-with-great-expectations
- 1
- 11
- 18 +
- 9
- a
- Om oss
- ovenfor
- la til
- avansert
- mot
- Alle
- Amazon
- Amazon Web Services
- analyse
- analytics
- og
- hverandre
- Påfør
- Artikkel
- artikler
- automatisk
- tilgjengelig
- gjennomsnittlig
- AWS
- Azure
- Backend
- dårlig
- dårlige data
- før du
- under
- som heter
- saken
- Sjekker
- klienter
- Cloud
- kode
- Koding
- Kolonne
- Felles
- Selskaper
- Selskapet
- konsept
- Konfigurasjon
- Vurder
- kontekst
- matlaging
- Kostnader
- dekke
- skape
- opprettet
- skaper
- avgjørende
- I dag
- skikk
- kunde
- kundeatferd
- tilpasse
- daglig
- dashbord
- dato
- dataanalyse
- datakvalitet
- datasett
- avtale
- avgjørelser
- mislighold
- detaljer
- Utvikling
- dokument
- nedlasting
- Motor
- estimater
- etc
- Eter (ETH)
- evaluert
- eksempel
- henrette
- gjennomføring
- forventning
- forventninger
- erfaring
- Forklar
- forklarte
- Utforske
- Mislyktes
- Egenskaper
- filet
- Først
- følge
- Forbes
- format
- funnet
- RAMME
- fra
- funksjoner
- videre
- framtid
- Gevinst
- ge
- gitt
- flott
- Gruppe
- hjelpe
- hjelper
- her.
- Fremhevet
- Hvordan
- Hvordan
- HTML
- HTTPS
- stort
- viktig
- in
- unøyaktig
- Inc.
- inkluderer
- informasjon
- innsikt
- forsikring
- involvert
- saker
- IT
- JSON
- KDnuggets
- LÆRE
- Bibliotek
- laste
- plassering
- Se
- taper
- tap
- mange
- Match
- metode
- metoder
- millioner
- mangler
- penger
- Overvåke
- mer
- flere
- navn
- nødvendig
- Trenger
- nødvendig
- Ny
- Ny teknologi
- neste
- Antall
- åpen kildekode
- organisasjoner
- Annen
- Overcome
- pandaer
- del
- lidenskapelig
- fotografering
- fysisk
- plato
- Platon Data Intelligence
- PlatonData
- politikk
- postgresql
- prosess
- prosessering
- programma
- gi
- forutsatt
- gir
- gi
- Python
- kvalitet
- raskt
- poster
- Redusert
- rapporterer
- omdømme
- anmode
- forespørsler
- Krav
- resultere
- resulterende
- Resultater
- avkastning
- inntekter
- regler
- Kjør
- salg
- Sekund
- Tjenester
- sett
- innstilling
- bør
- Viser
- Enkelt
- enkelt
- Software
- programvareutvikling
- noen
- kilde
- kildekoden
- Kilder
- spesifikk
- Trinn
- Steps
- oppbevare
- butikker
- strategier
- suksess
- vellykket
- vellykket
- slik
- suite
- Støtter
- Technologies
- forteller
- test
- tester
- De
- Kilden
- deres
- ting
- tre
- tid
- til
- verktøy
- Traveling
- TX
- typer
- etter
- unik
- enhet
- us
- USD
- bruke
- VALIDERE
- validering
- Verdifull
- Verdier
- ulike
- verifisere
- volumer
- måter
- web
- webtjenester
- om
- hvilken
- mens
- vil
- Arbeid
- arbeid
- skrive
- skriving
- år
- Din
- zephyrnet

![Hvordan øke hastigheten på SQL-spørringer ved å bruke indekser [Python Edition] - KDnuggets](https://platoaistream.net/wp-content/uploads/2023/08/how-to-speed-up-sql-queries-using-indexes-python-edition-kdnuggets-360x203.png)





