Denne tredelte serien viser hvordan du bruker grafiske nevrale nettverk (GNN) og Amazon Neptun for å generere filmanbefalinger ved hjelp av IMDb og Box Office Mojo Movies/TV/OTT lisensierbar datapakke, som gir et bredt spekter av underholdningsmetadata, inkludert over 1 milliard brukervurderinger; kreditter for mer enn 11 millioner rollebesetnings- og besetningsmedlemmer; 9 millioner film-, TV- og underholdningstitler; og globale billettkontorrapporteringsdata fra mer enn 60 land. Mange AWS medie- og underholdningskunder lisensierer IMDb-data gjennom AWS datautveksling for å forbedre innholdsoppdagelsen og øke kundeengasjement og -oppbevaring.
In Del 1, diskuterte vi applikasjonene til GNN-er, og hvordan vi kan transformere og forberede IMDb-dataene våre for spørring. I dette innlegget diskuterer vi prosessen med å bruke Neptun til å generere innebygginger som brukes til å utføre vårt søk utenfor katalogen i del 3. Vi går også over Amazon Neptune ML, maskinlæringsfunksjonen (ML) til Neptune, og koden vi bruker i utviklingsprosessen vår. I del 3 går vi gjennom hvordan vi kan bruke kunnskapsgrafinnbyggingene våre på et søk utenfor katalogen.
Løsningsoversikt
Store tilkoblede datasett inneholder ofte verdifull informasjon som kan være vanskelig å trekke ut ved å bruke spørringer basert på menneskelig intuisjon alene. ML-teknikker kan hjelpe med å finne skjulte korrelasjoner i grafer med milliarder av relasjoner. Disse korrelasjonene kan være nyttige for å anbefale produkter, forutsi kredittverdighet, identifisere svindel og mange andre brukstilfeller.
Neptune ML gjør det mulig å bygge og trene nyttige ML-modeller på store grafer i timer i stedet for uker. For å oppnå dette bruker Neptune ML GNN-teknologi drevet av Amazon SageMaker og Deep Graph Library (DGL) (som er åpen kildekode). GNN-er er et voksende felt innen kunstig intelligens (se for eksempel En omfattende undersøkelse om grafiske nevrale nettverk). For en praktisk veiledning om bruk av GNN-er med DGL, se Lær grafiske nevrale nettverk med Deep Graph Library.
I dette innlegget viser vi hvordan du bruker Neptune i vår pipeline for å generere innbygginger.
Følgende diagram viser den generelle flyten av IMDb-data fra nedlasting til generering av innebygging.
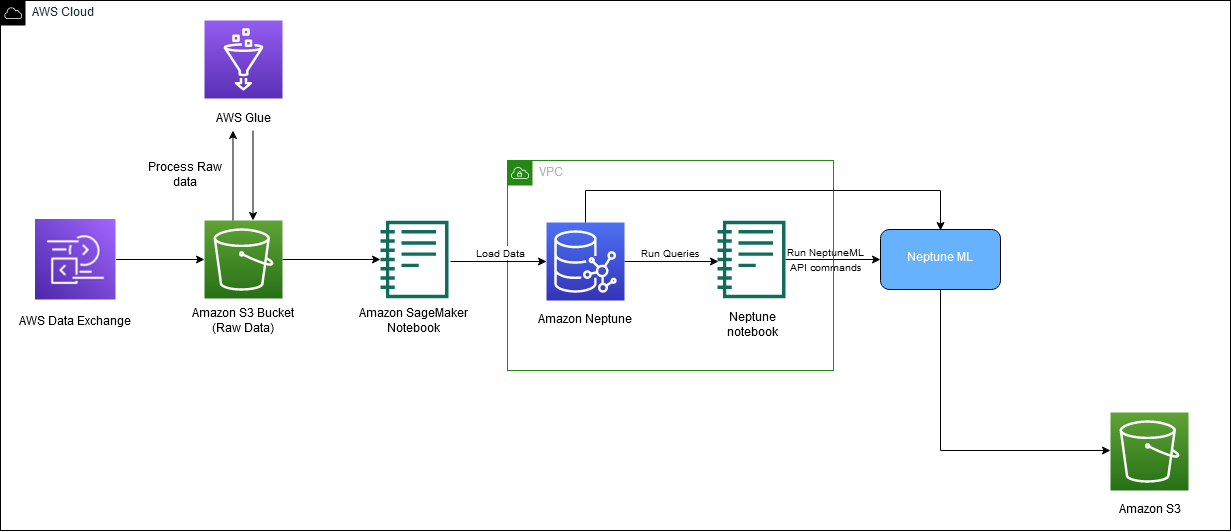
Vi bruker følgende AWS-tjenester for å implementere løsningen:
I dette innlegget leder vi deg gjennom følgende trinn på høyt nivå:
- Sett opp miljøvariabler
- Opprett en eksportjobb.
- Opprett en databehandlingsjobb.
- Send inn en treningsjobb.
- Last ned embeddings.
Kode for Neptune ML-kommandoer
Vi bruker følgende kommandoer som en del av implementeringen av denne løsningen:
Vi bruker neptune_ml export for å sjekke statusen eller starte en Neptune ML eksportprosess, og neptune_ml training for å starte og sjekke statusen til en Neptune ML modelltreningsjobb.
For mer informasjon om disse og andre kommandoer, se Bruke Neptune arbeidsbenk magi i notatbøkene dine.
Forutsetninger
For å følge med på dette innlegget bør du ha følgende:
- An AWS-konto
- Kjennskap til SageMaker, Amazon S3 og AWS CloudFormation
- Grafer data som er lastet inn i Neptun-klyngen (se Del 1 for mer informasjon)
Sett opp miljøvariabler
Før vi begynner, må du sette opp miljøet ditt ved å angi følgende variabler: s3_bucket_uri og processed_folder. s3_bucket_uri er navnet på bøtta som ble brukt i del 1 og processed_folder er Amazon S3-lokasjonen for utdata fra eksportjobben.
Opprett en eksportjobb
I del 1 opprettet vi en SageMaker notatbok og eksporttjeneste for å eksportere dataene våre fra Neptune DB-klyngen til Amazon S3 i det nødvendige formatet.
Nå som dataene våre er lastet inn og eksporttjenesten er opprettet, må vi opprette en eksportjobb og starte den. For å gjøre dette bruker vi NeptuneExportApiUri og opprette parametere for eksportjobben. I den følgende koden bruker vi variablene expo og export_params. Sett expo til din NeptuneExportApiUri verdi, som du kan finne på Utganger fanen i CloudFormation-stakken. Til export_params, bruker vi endepunktet til Neptun-klyngen og oppgir verdien for outputS3path, som er Amazon S3-lokasjonen for utdata fra eksportjobben.
For å sende inn eksportjobben, bruk følgende kommando:
For å sjekke statusen til eksportjobben, bruk følgende kommando:
Etter at jobben er fullført, still inn processed_folder variabel for å gi Amazon S3-plasseringen til de behandlede resultatene:
Opprett en databehandlingsjobb
Nå som eksporten er ferdig, oppretter vi en databehandlingsjobb for å forberede dataene for Neptune ML-treningsprosessen. Dette kan gjøres på flere forskjellige måter. For dette trinnet kan du endre job_name og modelType variabler, men alle andre parametere må forbli de samme. Hoveddelen av denne koden er modelType parameter, som enten kan være heterogene grafmodeller (heterogeneous) eller kunnskapsgrafer (kge).
Eksportjobben inkluderer også training-data-configuration.json. Bruk denne filen til å legge til eller fjerne eventuelle noder eller kanter som du ikke vil gi til trening (hvis du for eksempel vil forutsi koblingen mellom to noder, kan du fjerne den koblingen i denne konfigurasjonsfilen). For dette blogginnlegget bruker vi den originale konfigurasjonsfilen. For ytterligere informasjon, se Redigere en treningskonfigurasjonsfil.
Opprett databehandlingsjobben din med følgende kode:
For å sjekke statusen til eksportjobben, bruk følgende kommando:
Send inn en treningsjobb
Etter at prosesseringsjobben er fullført, kan vi begynne treningsjobben vår, det er der vi lager innbyggingene våre. Vi anbefaler en forekomsttype på ml.m5.24xlarge, men du kan endre denne for å passe dine databehov. Se følgende kode:
Vi skriver ut variabelen training_results for å få ID for treningsjobben. Bruk følgende kommando for å sjekke statusen til jobben din:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Last ned embeddings
Etter at treningsjobben er fullført, er det siste trinnet å laste ned de rå innbyggingene. Følgende trinn viser deg hvordan du laster ned innebygginger opprettet ved å bruke KGE (du kan bruke samme prosess for RGCN).
I følgende kode bruker vi neptune_ml.get_mapping() og get_embeddings() for å laste ned kartfilen (mapping.info) og den rå innebyggingsfilen (entity.npy). Deretter må vi kartlegge de riktige innebyggingene til deres tilsvarende IDer.
For å laste ned RGCN-er, følg den samme prosessen med et nytt treningsjobbnavn ved å behandle dataene med parameteren modelType satt til heterogeneous, og tren deretter modellen med parameteren modelName satt til rgcn se her. for flere detaljer. Når det er ferdig, ring get_mapping og get_embeddings funksjoner for å laste ned din nye mapping.info og entity.npy filer. Etter at du har enhets- og tilordningsfilene, er prosessen for å lage CSV-filen identisk.
Til slutt laster du opp innebyggingene dine til ønsket Amazon S3-plassering:
Sørg for at du husker denne S3-plasseringen, du må bruke den i del 3.
Rydd opp
Når du er ferdig med å bruke løsningen, sørg for å rydde opp i eventuelle ressurser for å unngå pågående kostnader.
konklusjonen
I dette innlegget diskuterte vi hvordan du bruker Neptune ML til å trene GNN-innbygginger fra IMDb-data.
Noen relaterte applikasjoner for innbygging av kunnskapsgrafer er konsepter som søk utenfor katalogen, innholdsanbefalinger, målrettet annonsering, forutsigelse av manglende lenker, generelt søk og kohortanalyse. Utenfor katalogsøk er prosessen med å søke etter innhold du ikke eier, og finne eller anbefale innhold i katalogen din som er så nær det brukeren søkte på som mulig. Vi dykker dypere inn i søk utenfor katalogen i del 3.
Om forfatterne
 Matthew Rhodes er en dataforsker jeg jobber i Amazon ML Solutions Lab. Han spesialiserer seg på å bygge Machine Learning-pipelines som involverer konsepter som Natural Language Processing og Computer Vision.
Matthew Rhodes er en dataforsker jeg jobber i Amazon ML Solutions Lab. Han spesialiserer seg på å bygge Machine Learning-pipelines som involverer konsepter som Natural Language Processing og Computer Vision.
 Divya Bhargavi er dataforsker og vertikal leder for media og underholdning ved Amazon ML Solutions Lab, hvor hun løser forretningsproblemer med høy verdi for AWS-kunder ved hjelp av maskinlæring. Hun jobber med bilde-/videoforståelse, anbefalingssystemer for kunnskapsgrafer, brukstilfeller for prediktiv annonsering.
Divya Bhargavi er dataforsker og vertikal leder for media og underholdning ved Amazon ML Solutions Lab, hvor hun løser forretningsproblemer med høy verdi for AWS-kunder ved hjelp av maskinlæring. Hun jobber med bilde-/videoforståelse, anbefalingssystemer for kunnskapsgrafer, brukstilfeller for prediktiv annonsering.
 Gaurav Rele er dataforsker ved Amazon ML Solution Lab, hvor han jobber med AWS-kunder på tvers av forskjellige vertikaler for å akselerere bruken av maskinlæring og AWS Cloud-tjenester for å løse deres forretningsutfordringer.
Gaurav Rele er dataforsker ved Amazon ML Solution Lab, hvor han jobber med AWS-kunder på tvers av forskjellige vertikaler for å akselerere bruken av maskinlæring og AWS Cloud-tjenester for å løse deres forretningsutfordringer.
 Karan Sindwani er dataforsker ved Amazon ML Solutions Lab, hvor han bygger og implementerer dyplæringsmodeller. Han har spesialisert seg på området datasyn. På fritiden liker han å gå tur.
Karan Sindwani er dataforsker ved Amazon ML Solutions Lab, hvor han bygger og implementerer dyplæringsmodeller. Han har spesialisert seg på området datasyn. På fritiden liker han å gå tur.
 Soji Adeshina er en Applied Scientist ved AWS hvor han utvikler grafiske nevrale nettverksbaserte modeller for maskinlæring på grafoppgaver med applikasjoner for svindel og misbruk, kunnskapsgrafer, anbefalingssystemer og biovitenskap. På fritiden liker han å lese og lage mat.
Soji Adeshina er en Applied Scientist ved AWS hvor han utvikler grafiske nevrale nettverksbaserte modeller for maskinlæring på grafoppgaver med applikasjoner for svindel og misbruk, kunnskapsgrafer, anbefalingssystemer og biovitenskap. På fritiden liker han å lese og lage mat.
 Vidya Sagar Ravipati er en leder ved Amazon ML Solutions Lab, hvor han utnytter sin store erfaring innen distribuerte systemer i stor skala og sin lidenskap for maskinlæring for å hjelpe AWS-kunder på tvers av ulike bransjevertikaler med å akselerere deres AI og skyadopsjon.
Vidya Sagar Ravipati er en leder ved Amazon ML Solutions Lab, hvor han utnytter sin store erfaring innen distribuerte systemer i stor skala og sin lidenskap for maskinlæring for å hjelpe AWS-kunder på tvers av ulike bransjevertikaler med å akselerere deres AI og skyadopsjon.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Om oss
- misbruk
- akselerere
- tvers
- Ytterligere
- Tilleggsinformasjon
- Adopsjon
- Annonsering
- Etter
- AI
- Alle
- alene
- Amazon
- Amazon ML Solutions Lab
- analyse
- og
- søknader
- anvendt
- Påfør
- hensiktsmessig
- AREA
- kunstig
- kunstig intelligens
- AWS
- basert
- mellom
- Milliarder
- milliarder
- Blogg
- Eske
- box office
- bygge
- Bygning
- bygger
- virksomhet
- ring
- saken
- saker
- katalog
- utfordringer
- endring
- avgifter
- sjekk
- Lukke
- Cloud
- skyadopsjon
- skytjenester
- Cluster
- kode
- Cohort
- fullføre
- omfattende
- datamaskin
- Datamaskin syn
- databehandling
- konsepter
- Gjennomføre
- Konfigurasjon
- tilkoblet
- innhold
- Tilsvarende
- land
- skape
- opprettet
- kreditt
- studiepoeng
- kunde
- Kundedeltakelse
- Kunder
- dato
- databehandling
- dataforsker
- datasett
- dyp
- dyp læring
- dypere
- Distribueres
- detaljer
- Utvikling
- utvikler
- dgl
- forskjellig
- Funnet
- diskutere
- diskutert
- distribueres
- distribuerte systemer
- ikke
- nedlasting
- enten
- Emery
- Endpoint
- engasjement
- Entertainment
- enhet
- Miljø
- Eter (ETH)
- eksempel
- erfaring
- eksportere
- trekke ut
- Trekk
- Noen få
- felt
- filet
- Filer
- Finn
- finne
- flyten
- følge
- etter
- format
- svindel
- fra
- fullt
- funksjoner
- general
- generere
- generasjonen
- få
- Global
- Go
- graf
- grafer
- hands-on
- Hard
- hjelpe
- nyttig
- skjult
- høyt nivå
- TIMER
- Hvordan
- Hvordan
- HTML
- HTTPS
- menneskelig
- identiske
- identifisering
- iverksette
- implementere
- forbedre
- in
- inkluderer
- Inkludert
- Øke
- indeks
- industri
- info
- informasjon
- f.eks
- i stedet
- Intelligens
- involvere
- IT
- Jobb
- JSON
- nøkkel
- kunnskap
- lab
- Språk
- stor
- storskala
- Siste
- føre
- læring
- utnytter
- Bibliotek
- Tillatelse
- Life
- Life Sciences
- LINK
- lenker
- plassering
- maskin
- maskinlæring
- Hoved
- GJØR AT
- leder
- mange
- kart
- kartlegging
- Media
- medium
- medlemmer
- metadata
- millioner
- mangler
- ML
- modell
- modeller
- mer
- film
- navn
- Naturlig
- Natural Language Processing
- Trenger
- behov
- Neptune
- nettverksbasert
- nettverk
- nevrale nettverk
- Ny
- noder
- bærbare
- Office
- pågående
- original
- Annen
- samlet
- egen
- pakke
- parameter
- parametere
- del
- lidenskap
- rørledning
- plato
- Platon Data Intelligence
- PlatonData
- mulig
- Post
- makt
- powered
- forutsi
- forutsi
- Forbered
- Skrive ut
- problemer
- prosess
- prosessering
- Produkter
- Profil
- gi
- gir
- område
- rangeringer
- Raw
- Lesning
- anbefaler
- Anbefaling
- anbefalinger
- anbefale
- i slekt
- Relasjoner
- forbli
- husker
- fjerne
- Rapportering
- påkrevd
- Ressurser
- Resultater
- oppbevaring
- sagemaker
- samme
- VITENSKAPER
- Forsker
- Søk
- søker
- Serien
- tjeneste
- Tjenester
- sett
- innstilling
- bør
- Vis
- løsning
- Solutions
- LØSE
- løser
- spesialisert
- stable
- Begynn
- status
- Trinn
- Steps
- oppbevare
- send
- slik
- Dress
- Survey /Inspeksjonsfartøy
- Systemer
- målrettet
- oppgaver
- teknikker
- Teknologi
- De
- Området
- deres
- Gjennom
- tid
- titler
- til
- Tog
- Kurs
- Transform
- sant
- tutorial
- tv
- forståelse
- bruke
- bruk sak
- Bruker
- Verdifull
- verdi
- enorme
- versjon
- vertikaler
- syn
- måter
- uker
- Hva
- hvilken
- bred
- Bred rekkevidde
- vil
- arbeid
- virker
- Din
- zephyrnet