Amazon SageMaker Studio kan hjelpe deg med å bygge, trene, feilsøke, distribuere og overvåke modellene dine og administrere arbeidsflytene for maskinlæring (ML). Amazon SageMaker-rørledninger lar deg bygge en sikker, skalerbar og fleksibel MLOps-plattform i studio.
I dette innlegget forklarer vi hvordan du kjører PySpark-behandlingsjobber i en pipeline. Dette gjør det mulig for alle som ønsker å trene en modell ved å bruke Pipelines til også å forhåndsbehandle treningsdata, etterbehandle slutningsdata eller evaluere modeller ved hjelp av PySpark. Denne muligheten er spesielt relevant når du skal behandle data i stor skala. I tillegg viser vi hvordan du kan optimalisere PySpark-trinnene dine ved hjelp av konfigurasjoner og Spark UI-logger.
Rørledninger er en Amazon SageMaker verktøy for å bygge og administrere ende-til-ende ML-rørledninger. Det er en fullt administrert on-demand-tjeneste, integrert med SageMaker og andre AWS-tjenester, og derfor oppretter og administrerer ressurser for deg. Dette sikrer at forekomster bare klargjøres og brukes når rørledningene kjøres. Videre er Pipelines støttet av SageMaker Python SDK, slik at du kan spore din datalinje og gjenbrukstrinn ved å bufre dem for å lette utviklingstiden og kostnadene. En SageMaker-rørledning kan bruke behandlingstrinn å behandle data eller utføre modellevaluering.
Ved behandling av data i stor skala bruker ofte dataforskere og ML-ingeniører PySpark, et grensesnitt for Apache Spark i Python. SageMaker gir forhåndsbygde Docker-bilder som inkluderer PySpark og andre avhengigheter som er nødvendige for å kjøre distribuerte databehandlingsjobber, inkludert datatransformasjoner og funksjonsutvikling ved bruk av Spark-rammeverket. Selv om disse bildene lar deg raskt begynne å bruke PySpark i behandlingsjobber, krever storskala databehandling ofte spesifikke Spark-konfigurasjoner for å optimalisere den distribuerte databehandlingen til klyngen opprettet av SageMaker.
I vårt eksempel lager vi en SageMaker-pipeline som kjører et enkelt behandlingstrinn. For mer informasjon om hvilke andre trinn du kan legge til i en pipeline, se Rørledningstrinn.
SageMaker-behandlingsbibliotek
SageMaker Processing kan kjøre med spesifikke rammer (for eksempel SKlearnProcessor, PySparkProcessor eller Hugging Face). Uavhengig av rammeverket som brukes, hver Behandler trinn krever følgende:
- Trinnnavn – Navnet som skal brukes for SageMaker-rørledningstrinnet
- Trinn-argumenter – Argumentene for din
ProcessingStep
I tillegg kan du oppgi følgende:
- Konfigurasjonen for trinnbufferen din for å unngå unødvendige kjøringer av trinnet ditt i en SageMaker-pipeline
- En liste over trinnnavn, trinnforekomster eller trinnsamlingsforekomster som
ProcessingStepavhenger - Visningsnavnet til
ProcessingStep - En beskrivelse av
ProcessingStep - Eiendomsfiler
- Prøv retningslinjer på nytt
Argumentene overleveres til ProcessingStep. Du kan bruke sagemaker.spark.PySparkProcessor or sagemaker.spark.SparkJarProcessor klasse for å kjøre Spark-applikasjonen din inne i en behandlingsjobb.
Hver prosessor kommer med sine egne behov, avhengig av rammeverket. Dette illustreres best ved hjelp av PySparkProcessor, hvor du kan sende tilleggsinformasjon for å optimalisere ProcessingStep videre, for eksempel via configuration parameter når du kjører jobben din.
Kjør SageMaker Processing-jobber i et sikkert miljø
det er beste praksis å opprette en privat Amazon VPC og konfigurere den slik at jobbene dine ikke er tilgjengelige over det offentlige internett. SageMaker Processing-jobber lar deg spesifisere de private undernettene og sikkerhetsgruppene i VPC-en din, samt aktivere nettverksisolering og trafikkkryptering mellom containere ved hjelp av NetworkConfig.VpcConfig forespørselsparameter for CreateProcessingJob API. Vi gir eksempler på denne konfigurasjonen ved å bruke SageMaker SDK i neste avsnitt.
PySpark ProcessingStep i SageMaker Pipelines
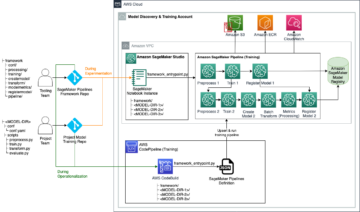
For dette eksempelet antar vi at du har Studio utplassert i et sikkert miljø som allerede er tilgjengelig, inkludert VPC, VPC-endepunkter, sikkerhetsgrupper, AWS identitets- og tilgangsadministrasjon (IAM) roller, og AWS nøkkelstyringstjeneste (AWS KMS)-taster. Vi antar også at du har to bøtter: en for artefakter som kode og logger, og en for dataene dine. De basic_infra.yaml filen gir eksempel AWS skyformasjon kode for å sørge for nødvendig forutsetningsinfrastruktur. Eksempelkoden og distribusjonsveiledningen er også tilgjengelig på GitHub.
Som et eksempel setter vi opp en rørledning som inneholder en enkelt ProcessingStep der vi bare leser og skriver abalone datasett ved hjelp av Spark. Kodeeksemplene viser deg hvordan du setter opp og konfigurerer ProcessingStep.
Vi definerer parametere for pipeline (navn, rolle, buckets og så videre) og trinnspesifikke innstillinger (forekomsttype og antall, rammeversjon og så videre). I dette eksemplet bruker vi et sikkert oppsett og definerer også undernett, sikkerhetsgrupper og trafikkkryptering mellom containere. For dette eksemplet trenger du en pipeline-utførelsesrolle med SageMaker full tilgang og en VPC. Se følgende kode:
{ "pipeline_name": "ProcessingPipeline", "trial": "test-blog-post", "pipeline_role": "arn:aws:iam::<ACCOUNT_NUMBER>:role/<PIPELINE_EXECUTION_ROLE_NAME>", "network_subnet_ids": [ "subnet-<SUBNET_ID>", "subnet-<SUBNET_ID>" ], "network_security_group_ids": [ "sg-<SG_ID>" ], "pyspark_process_volume_kms": "arn:aws:kms:<REGION_NAME>:<ACCOUNT_NUMBER>:key/<KMS_KEY_ID>", "pyspark_process_output_kms": "arn:aws:kms:<REGION_NAME>:<ACCOUNT_NUMBER>:key/<KMS_KEY_ID>", "pyspark_helper_code": "s3://<INFRA_S3_BUCKET>/src/helper/data_utils.py", "spark_config_file": "s3://<INFRA_S3_BUCKET>/src/spark_configuration/configuration.json", "pyspark_process_code": "s3://<INFRA_S3_BUCKET>/src/processing/process_pyspark.py", "process_spark_ui_log_output": "s3://<DATA_S3_BUCKET>/spark_ui_logs/{}", "pyspark_framework_version": "2.4", "pyspark_process_name": "pyspark-processing", "pyspark_process_data_input": "s3a://<DATA_S3_BUCKET>/data_input/abalone_data.csv", "pyspark_process_data_output": "s3a://<DATA_S3_BUCKET>/pyspark/data_output", "pyspark_process_instance_type": "ml.m5.4xlarge", "pyspark_process_instance_count": 6, "tags": { "Project": "tag-for-project", "Owner": "tag-for-owner" }
}
For å demonstrere, kjører følgende kodeeksempel et PySpark-skript på SageMaker Processing i en pipeline ved å bruke PySparkProcessor:
# import code requirements
# standard libraries import
import logging
import json # sagemaker model import
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.pipeline_experiment_config import PipelineExperimentConfig
from sagemaker.workflow.steps import CacheConfig
from sagemaker.processing import ProcessingInput
from sagemaker.workflow.steps import ProcessingStep
from sagemaker.workflow.pipeline_context import PipelineSession
from sagemaker.spark.processing import PySparkProcessor from helpers.infra.networking.networking import get_network_configuration
from helpers.infra.tags.tags import get_tags_input
from helpers.pipeline_utils import get_pipeline_config def create_pipeline(pipeline_params, logger): """ Args: pipeline_params (ml_pipeline.params.pipeline_params.py.Params): pipeline parameters logger (logger): logger Returns: () """ # Create SageMaker Session sagemaker_session = PipelineSession() # Get Tags tags_input = get_tags_input(pipeline_params["tags"]) # get network configuration network_config = get_network_configuration( subnets=pipeline_params["network_subnet_ids"], security_group_ids=pipeline_params["network_security_group_ids"] ) # Get Pipeline Configurations pipeline_config = get_pipeline_config(pipeline_params) # setting processing cache obj logger.info("Setting " + pipeline_params["pyspark_process_name"] + " cache configuration 3 to 30 days") cache_config = CacheConfig(enable_caching=True, expire_after="p30d") # Create PySpark Processing Step logger.info("Creating " + pipeline_params["pyspark_process_name"] + " processor") # setting up spark processor processing_pyspark_processor = PySparkProcessor( base_job_name=pipeline_params["pyspark_process_name"], framework_version=pipeline_params["pyspark_framework_version"], role=pipeline_params["pipeline_role"], instance_count=pipeline_params["pyspark_process_instance_count"], instance_type=pipeline_params["pyspark_process_instance_type"], volume_kms_key=pipeline_params["pyspark_process_volume_kms"], output_kms_key=pipeline_params["pyspark_process_output_kms"], network_config=network_config, tags=tags_input, sagemaker_session=sagemaker_session ) # setting up arguments run_ags = processing_pyspark_processor.run( submit_app=pipeline_params["pyspark_process_code"], submit_py_files=[pipeline_params["pyspark_helper_code"]], arguments=[ # processing input arguments. To add new arguments to this list you need to provide two entrances: # 1st is the argument name preceded by "--" and the 2nd is the argument value # setting up processing arguments "--input_table", pipeline_params["pyspark_process_data_input"], "--output_table", pipeline_params["pyspark_process_data_output"] ], spark_event_logs_s3_uri=pipeline_params["process_spark_ui_log_output"].format(pipeline_params["trial"]), inputs = [ ProcessingInput( source=pipeline_params["spark_config_file"], destination="/opt/ml/processing/input/conf", s3_data_type="S3Prefix", s3_input_mode="File", s3_data_distribution_type="FullyReplicated", s3_compression_type="None" ) ], ) # create step pyspark_processing_step = ProcessingStep( name=pipeline_params["pyspark_process_name"], step_args=run_ags, cache_config=cache_config, ) # Create Pipeline pipeline = Pipeline( name=pipeline_params["pipeline_name"], steps=[ pyspark_processing_step ], pipeline_experiment_config=PipelineExperimentConfig( pipeline_params["pipeline_name"], pipeline_config["trial"] ), sagemaker_session=sagemaker_session ) pipeline.upsert( role_arn=pipeline_params["pipeline_role"], description="Example pipeline", tags=tags_input ) return pipeline def main(): # set up logging logger = logging.getLogger(__name__) logger.setLevel(logging.INFO) logger.info("Get Pipeline Parameter") with open("ml_pipeline/params/pipeline_params.json", "r") as f: pipeline_params = json.load(f) print(pipeline_params) logger.info("Create Pipeline") pipeline = create_pipeline(pipeline_params, logger=logger) logger.info("Execute Pipeline") execution = pipeline.start() return execution if __name__ == "__main__": main()
Som vist i den foregående koden, overskriver vi standard Spark-konfigurasjoner ved å tilby configuration.json som en ProcessingInput. Vi bruker a configuration.json filen som ble lagret i Amazon enkel lagringstjeneste (Amazon S3) med følgende innstillinger:
[ { "Classification":"spark-defaults", "Properties":{ "spark.executor.memory":"10g", "spark.executor.memoryOverhead":"5g", "spark.driver.memory":"10g", "spark.driver.memoryOverhead":"10g", "spark.driver.maxResultSize":"10g", "spark.executor.cores":5, "spark.executor.instances":5, "spark.yarn.maxAppAttempts":1 "spark.hadoop.fs.s3a.endpoint":"s3.<region>.amazonaws.com", "spark.sql.parquet.fs.optimized.comitter.optimization-enabled":true } }
]
Vi kan oppdatere standard Spark-konfigurasjon enten ved å sende filen som en ProcessingInput eller ved å bruke konfigurasjonsargumentet når du kjører run() funksjon.
Spark-konfigurasjonen er avhengig av andre alternativer, som forekomsttypen og antall forekomster som er valgt for behandlingsjobben. Den første vurderingen er antall forekomster, vCPU-kjernene som hver av disse forekomstene har, og forekomstminnet. Du kan bruke Spark UI or CloudWatch-forekomstberegninger og logger for å kalibrere disse verdiene over flere gjentakelser.
I tillegg kan executor- og driverinnstillingene optimaliseres ytterligere. For eksempel på hvordan du regner ut disse, se Beste praksis for vellykket håndtering av minne for Apache Spark-applikasjoner på Amazon EMR.
Deretter, for driver- og eksekveringsinnstillinger, anbefaler vi å undersøke committer-innstillingene for å forbedre ytelsen når du skriver til Amazon S3. I vårt tilfelle skriver vi Parkett-filer til Amazon S3 og setter "spark.sql.parquet.fs.optimized.comitter.optimization-enabled”Til sant.
Om nødvendig for en tilkobling til Amazon S3, et regionalt endepunkt "spark.hadoop.fs.s3a.endpoint” kan spesifiseres i konfigurasjonsfilen.
I dette eksempelet er PySpark-skriptet spark_process.py (som vist i følgende kode) laster en CSV-fil fra Amazon S3 inn i en Spark-dataramme, og lagrer dataene som Parkett tilbake til Amazon S3.
Merk at eksempelkonfigurasjonen vår ikke er proporsjonal med arbeidsbelastningen fordi lesing og skriving av abalone-datasettet kan gjøres på standardinnstillinger på én forekomst. Konfigurasjonene vi nevnte bør defineres basert på dine spesifikke behov.
# import requirements
import argparse
import logging
import sys
import os
import pandas as pd # spark imports
from pyspark.sql import SparkSession
from pyspark.sql.functions import (udf, col)
from pyspark.sql.types import StringType, StructField, StructType, FloatType from data_utils import( spark_read_parquet, Unbuffered
) sys.stdout = Unbuffered(sys.stdout) # Define custom handler
logger = logging.getLogger(__name__)
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(logging.Formatter("%(asctime)s %(message)s"))
logger.addHandler(handler)
logger.setLevel(logging.INFO) def main(data_path): spark = SparkSession.builder.appName("PySparkJob").getOrCreate() spark.sparkContext.setLogLevel("ERROR") schema = StructType( [ StructField("sex", StringType(), True), StructField("length", FloatType(), True), StructField("diameter", FloatType(), True), StructField("height", FloatType(), True), StructField("whole_weight", FloatType(), True), StructField("shucked_weight", FloatType(), True), StructField("viscera_weight", FloatType(), True), StructField("rings", FloatType(), True), ] ) df = spark.read.csv(data_path, header=False, schema=schema) return df.select("sex", "length", "diameter", "rings") if __name__ == "__main__": logger.info(f"===============================================================") logger.info(f"================= Starting pyspark-processing =================") parser = argparse.ArgumentParser(description="app inputs") parser.add_argument("--input_table", type=str, help="path to the channel data") parser.add_argument("--output_table", type=str, help="path to the output data") args = parser.parse_args() df = main(args.input_table) logger.info("Writing transformed data") df.write.csv(os.path.join(args.output_table, "transformed.csv"), header=True, mode="overwrite") # save data df.coalesce(10).write.mode("overwrite").parquet(args.output_table) logger.info(f"================== Ending pyspark-processing ==================") logger.info(f"===============================================================")
For å dykke ned i å optimalisere Spark-behandlingsjobber, kan du bruke CloudWatch-loggene så vel som Spark-grensesnittet. Du kan opprette Spark-grensesnittet ved å kjøre en behandlingsjobb på en SageMaker-notatbokforekomst. Du kan se Spark UI for behandlingsjobbene som kjører i en pipeline by kjører historieserveren i en SageMaker-notebook-forekomst hvis Spark UI-loggene ble lagret på samme Amazon S3-plassering.
Rydd opp
Hvis du fulgte veiledningen, er det god praksis å slette ressurser som ikke lenger brukes for å slutte å påløpe kostnader. Sørg for å slett CloudFormation-stabelen som du brukte til å opprette ressursene dine. Dette vil slette stabelen som er opprettet, så vel som ressursene den opprettet.
konklusjonen
I dette innlegget viste vi hvordan du kjører en sikker SageMaker Processing-jobb ved å bruke PySpark i SageMaker Pipelines. Vi demonstrerte også hvordan du kan optimalisere PySpark ved å bruke Spark-konfigurasjoner og konfigurere prosesseringsjobben din til å kjøre i en sikker nettverkskonfigurasjon.
Som et neste trinn kan du utforske hvordan du kan automatisere hele modellens livssyklus og hvordan kunder bygde sikre og skalerbare MLOps-plattformer ved å bruke SageMaker-tjenester.
Om forfatterne
 Maren Suilmann er dataforsker ved AWS profesjonelle tjenester. Hun jobber med kunder på tvers av bransjer og avslører kraften til AI/ML for å oppnå forretningsresultater. Maren har vært hos AWS siden november 2019. På fritiden liker hun kickboksing, fotturer til flott utsikt og brettspillkvelder.
Maren Suilmann er dataforsker ved AWS profesjonelle tjenester. Hun jobber med kunder på tvers av bransjer og avslører kraften til AI/ML for å oppnå forretningsresultater. Maren har vært hos AWS siden november 2019. På fritiden liker hun kickboksing, fotturer til flott utsikt og brettspillkvelder.
 Maira Ladeira Tanke er ML-spesialist ved AWS. Med bakgrunn innen datavitenskap, har hun 9 års erfaring med å arkitekte og bygge ML-applikasjoner med kunder på tvers av bransjer. Som teknisk leder hjelper hun kunder med å akselerere oppnåelsen av forretningsverdi gjennom nye teknologier og innovative løsninger. På fritiden liker Maira å reise og tilbringe tid med familien et varmt sted.
Maira Ladeira Tanke er ML-spesialist ved AWS. Med bakgrunn innen datavitenskap, har hun 9 års erfaring med å arkitekte og bygge ML-applikasjoner med kunder på tvers av bransjer. Som teknisk leder hjelper hun kunder med å akselerere oppnåelsen av forretningsverdi gjennom nye teknologier og innovative løsninger. På fritiden liker Maira å reise og tilbringe tid med familien et varmt sted.
 Pauline Ting er dataforsker i AWS profesjonelle tjenester team. Hun støtter kunder i å oppnå og akselerere deres forretningsresultat ved å utvikle AI/ML-løsninger. På fritiden liker Pauline å reise, surfe og prøve nye dessertsteder.
Pauline Ting er dataforsker i AWS profesjonelle tjenester team. Hun støtter kunder i å oppnå og akselerere deres forretningsresultat ved å utvikle AI/ML-løsninger. På fritiden liker Pauline å reise, surfe og prøve nye dessertsteder.
 Donald Fossouo er Sr Data Architect i AWS profesjonelle tjenester team, som hovedsakelig jobber med Global Finance Service. Han engasjerer seg med kunder for å skape innovative løsninger som adresserer kundenes forretningsproblemer og akselererer innføringen av AWS-tjenester. På fritiden liker Donald å lese, løpe og reise.
Donald Fossouo er Sr Data Architect i AWS profesjonelle tjenester team, som hovedsakelig jobber med Global Finance Service. Han engasjerer seg med kunder for å skape innovative løsninger som adresserer kundenes forretningsproblemer og akselererer innføringen av AWS-tjenester. På fritiden liker Donald å lese, løpe og reise.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/run-secure-processing-jobs-using-pyspark-in-amazon-sagemaker-pipelines/
- :er
- $OPP
- 1
- 10
- 100
- 2019
- 5G
- 9
- a
- Om oss
- akselerere
- akselerer
- adgang
- tilgjengelig
- Oppnå
- prestasjon
- oppnå
- tvers
- tillegg
- Ytterligere
- Tilleggsinformasjon
- adresse
- Adopsjon
- AI / ML
- allerede
- Selv
- Amazon
- Amazon SageMaker
- Amazon SageMaker-rørledninger
- og
- noen
- Apache
- Apache Spark
- api
- app
- Søknad
- søknader
- ER
- argument
- argumenter
- AS
- At
- automatisere
- tilgjengelig
- unngå
- AWS
- tilbake
- bakgrunn
- basert
- BE
- fordi
- BEST
- borde
- bygge
- bygger
- Bygning
- bygget
- virksomhet
- by
- cache
- beregne
- CAN
- saken
- Kanal
- avgifter
- valgt ut
- klasse
- klassifisering
- Cluster
- kode
- samling
- COM
- databehandling
- Konfigurasjon
- konfigurasjoner
- tilkobling
- hensyn
- Kostnad
- kunne
- skape
- opprettet
- skaper
- Opprette
- skikk
- kunde
- Kunder
- dato
- databehandling
- datavitenskap
- dataforsker
- Dager
- Misligholde
- definert
- demonstrere
- demonstrert
- avhengig
- avhengig
- avhenger
- utplassere
- utplassert
- distribusjon
- beskrivelse
- utvikle
- Utvikling
- Vise
- distribueres
- distribuert databehandling
- distribuert databehandling
- Docker
- sjåfør
- hver enkelt
- enten
- Emery
- Nye teknologier
- muliggjøre
- muliggjør
- kryptering
- ende til ende
- Endpoint
- Ingeniørarbeid
- Ingeniører
- sikrer
- Hele
- Miljø
- feil
- spesielt
- Eter (ETH)
- evaluere
- evaluering
- Selv
- eksempel
- eksempler
- henrette
- gjennomføring
- erfaring
- Forklar
- utforske
- Face
- familie
- Trekk
- filet
- Filer
- finansiere
- Først
- fleksibel
- fulgt
- etter
- Til
- RAMME
- Rammeverk
- Gratis
- fra
- FS
- fullt
- fullt
- funksjon
- funksjoner
- videre
- Dess
- spill
- få
- Global
- god
- flott
- Gruppens
- veilede
- Hadoop
- Ha
- høyde
- hjelpe
- hjelper
- vandreturer
- historie
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- IAM
- ICS
- Identitet
- bilder
- importere
- import
- forbedre
- in
- inkludere
- Inkludert
- uavhengig
- bransjer
- info
- informasjon
- Infrastruktur
- innovative
- inngang
- f.eks
- integrert
- Interface
- Internet
- isolasjon
- IT
- gjentakelser
- DET ER
- Jobb
- Jobb
- jpg
- JSON
- nøkkel
- nøkler
- storskala
- føre
- læring
- Lengde
- utleie
- bibliotekene
- Livssyklus
- i likhet med
- Liste
- laster
- plassering
- lenger
- maskin
- maskinlæring
- gjøre
- administrer
- fikk til
- ledelse
- forvalter
- administrerende
- Minne
- nevnt
- melding
- ML
- MLOps
- modell
- modeller
- Overvåke
- mer
- flere
- navn
- navn
- nødvendig
- Trenger
- nødvendig
- behov
- nettverk
- nettverk
- Ny
- neste
- bærbare
- November
- Antall
- of
- on
- På etterspørsel
- ONE
- Optimalisere
- optimalisert
- optimalisere
- alternativer
- rekkefølge
- OS
- Annen
- Utfallet
- produksjon
- egen
- eieren
- pandaer
- parameter
- parametere
- passere
- Passerer
- banen
- utføre
- ytelse
- rørledning
- steder
- plato
- Platon Data Intelligence
- PlatonData
- Post
- makt
- praksis
- praksis
- privat
- problemer
- prosess
- prosessering
- prosessor
- profesjonell
- prosjekt
- egenskaper
- gi
- gir
- gi
- forsyning
- offentlig
- Python
- raskt
- Lese
- Lesning
- anbefaler
- regional
- relevant
- anmode
- Krav
- Krever
- Ressurser
- retur
- avkastning
- Rolle
- roller
- Kjør
- rennende
- sagemaker
- SageMaker-rørledninger
- samme
- Spar
- skalerbar
- Vitenskap
- Forsker
- forskere
- Seksjon
- sikre
- sikkerhet
- tjeneste
- Tjenester
- Session
- sett
- innstilling
- innstillinger
- oppsett
- Kjønn
- bør
- Vis
- presentere
- vist
- Enkelt
- ganske enkelt
- siden
- enkelt
- So
- Solutions
- Spark
- spesialist
- spesifikk
- spesifisert
- utgifter
- SQL
- stable
- Standard
- Begynn
- Start
- Trinn
- Steps
- Stopp
- lagring
- studio
- subnett
- vellykket
- Støttes
- Støtter
- lag
- Teknisk
- Technologies
- Det
- De
- deres
- Dem
- derfor
- Disse
- Gjennom
- tid
- til
- verktøy
- spor
- trafikk
- Tog
- Kurs
- transformasjoner
- forvandlet
- Traveling
- prøve
- sant
- tutorial
- typer
- ui
- avdukingen
- Oppdater
- bruke
- verdi
- Verdier
- versjon
- av
- Se
- visninger
- varm
- VI VIL
- Hva
- hvilken
- vil
- med
- innenfor
- arbeidsflyt
- arbeidsflyt
- arbeid
- virker
- skrive
- skriving
- yaml
- år
- Din
- zephyrnet