Amazon Kendra er en brukervennlig intelligent søketjeneste som lar deg integrere søkefunksjoner med applikasjonene dine slik at brukere kan finne informasjon lagret på tvers av datakilder som Amazon enkel lagringstjeneste , OneDrive og Google Drive; applikasjoner som SalesForce, SharePoint og Service Now; og relasjonsdatabaser som Amazon Relational Database Service (Amazon RDS). Ved å bruke Amazon Kendra-koblinger kan du synkronisere data fra flere innholdslagre med din Amazon Kendra-indeks. Når sluttbrukere stiller spørsmål om naturlig språk, bruker Amazon Kendra maskinlæringsalgoritmer (ML) for å forstå konteksten og gi de mest relevante svarene.
Amazon Kendras S3-kontakt støtter indeksering av dokumenter og tilhørende metadata lagret i en S3-bøtte. Det er ofte slik at du vil forsikre deg om at applikasjoner som kjører inne i en VPC kun har tilgang til spesifikke S3-bøtter, og i mange tilfeller må tilkoblingen ikke krysse internett for å nå offentlige endepunkter. Mange kunder eier imidlertid flere S3-bøtter, hvorav noen er tilgjengelige for VPC-endepunkter for Amazon S3. I dette innlegget beskriver vi hvordan du bruker den oppdaterte Amazon Kendra S3-kontakten med VPC-støtte for bruk av VPC-endepunkter.
Dette innlegget inneholder trinnene for å hjelpe deg med å lage en bedriftssøkemotor på AWS ved å bruke Amazon Kendra ved å koble til dokumenter som er lagret i en S3-bøtte som kun er tilgjengelig fra en VPC. For mer informasjon, se forbedre bedriftssøk med Amazon Kendra. Innlegget demonstrerer også hvordan du konfigurerer koblingen for Amazon S3 og konfigurerer hvordan indeksen din synkroniseres med datakilden når innholdet i datakilden endres.
Oversikt over løsning
Det er tre hovedforbedringer til Amazon Kendra S3-kontakt :
- VPC-støtte – Koblingen støtter nå bruk av din Amazon Virtual Private Cloud (Amazon VPC) nettverk. Du kan nå trygt koble til Amazon S3 ved å bruke VPC-endepunkter for Amazon S3 ved å spesifisere VPC-tilkobling, subnett og sikkerhetsgrupper.
- To synkroniseringsmoduser – Når du planlegger synkronisering av en datakilde i Amazon S3 til en Amazon Kendra-indeks, kan du nå velge å kjøre i Full synkroniseringsmodus eller Ny, endret og slettet dokumentsynkroniseringsmodus. I full synkroniseringsmodus, hver gang synkroniseringen kjører, skanner den objekter i hver mappe under rotbanen den ble konfigurert til å gjennomsøke og tar inn alle dokumenter på nytt. Full oppdatering lar deg tilbakestille indeksen uten å måtte slette og opprette en ny datakilde. I synkroniseringsmodus for nye, modifiserte og slettede dokumenter behandler den hver gang synkroniseringsjobben kjører bare objekter som ble lagt til, endret eller slettet siden siste gjennomgang. Inkrementelle gjennomganger kan redusere kjøretid og kostnader når de brukes med datasett som regelmessig legger til nye objekter til eksisterende datakilder.
- Ytterligere inkluderings- og eksklusjonsmønstre for dokumenter: I tillegg til prefikser introduserer vi mønstre for inkludering eller ekskludering av dokumenter fra indeksen din. To støttede mønstertyper er Unix-stil glob eller filtyper. Du kan nå legge til et regulært uttrykksmønster for å inkludere spesifikke mapper eller ekskludere mapper, filtyper eller spesifikke filer fra datakilden. Dette kan være nyttig for delte datalagre som inneholder innhold som tilhører ulike kategorier, klassifiseringer og filtyper.
Forutsetninger
For dette gjennomgangen bør du ha følgende forutsetninger:
Opprett og konfigurer dokumentlageret ditt
Før du kan opprette en indeks i Amazon Kendra, må du laste dokumenter i en S3-bøtte. Denne delen inneholder instruksjoner om hvordan du oppretter en S3-bøtte, henter filene og legger dem i bøtta. Etter å ha fullført alle trinnene i denne delen, har du en datakilde som Amazon Kendra kan bruke.
- På AWS-administrasjonskonsoll, i Region-listen, velg US East (N. Virginia) eller en hvilken som helst region etter eget valg Amazon Kendra er tilgjengelig i.
- Velg Tjenester.
- Under oppbevaring, velg S3.
- Velg på Amazon S3-konsollen Lag bøtte.
- Under Generell konfigurasjon, Gi følgende informasjon:
- For bøttenavn, skriv
kendrapost-{your account id}. - For Region, velg den samme regionen som du bruker til å distribuere din Amazon Kendra-indeks (dette innlegget bruker
us-east-1). - Under Bøtteinnstillinger, forum Blokker offentlig tilgang, la alt være med standardverdiene.
- For bøttenavn, skriv
- Under Avanserte innstillinger, la alt være med standardverdiene.
- Velg Lag bøtte.
- Last ned AWS_Whitepapers.zip og pakke ut filene.
- På Amazon S3-konsollen velger du skuffen du nettopp opprettet, og velger Last opp.
- Last opp mappene
Best Practices,Databases,GeneralogMachine Learningfra den utpakkede filen.
Inne i bøtten din skal du nå se fire mapper.
Legg til en datakilde
A datakilde er et sted som lagrer dokumentene for indeksering. Du kan synkronisere datakilder automatisk med en Amazon Kendra-indeks for å sikre at søk korrekt gjenspeiler nye, oppdaterte eller slettede dokumenter i kildelagerene.
Etter å ha fullført alle trinnene i denne delen, vil du ha en datakilde knyttet til Amazon Kendra. For mer informasjon, se Legge til dokumenter fra en datakilde.
Før du fortsetter, sørg for at indeksopprettingen er fullført og at indeksen viser som Aktiv. For mer informasjon, se Opprette en indeks.
- På Amazon Kendra-konsollen, naviger til indeksen din (for dette innlegget,
kendra-blog-index). - På
kendra-blog-indexside, velg Legg til datakilder.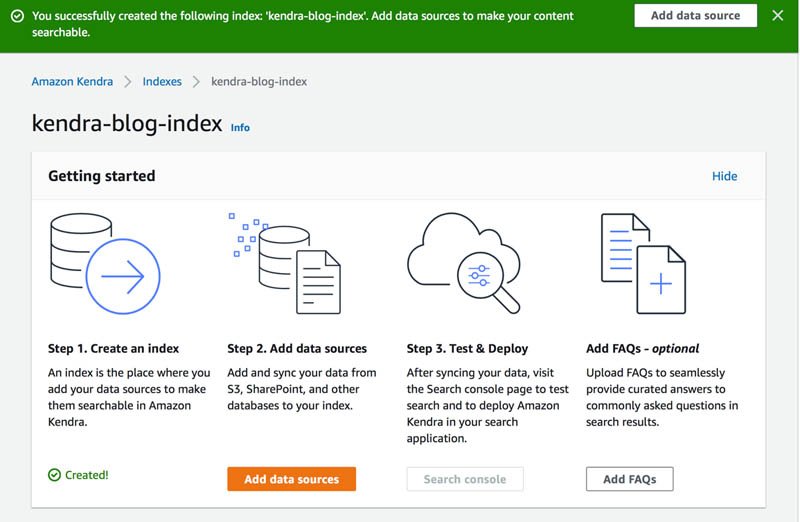
- Velg under Amazon S3 Legg til kontakt.

For mer informasjon om de forskjellige datakildene som Amazon Kendra støtter, se Legge til dokumenter fra en datakilde.
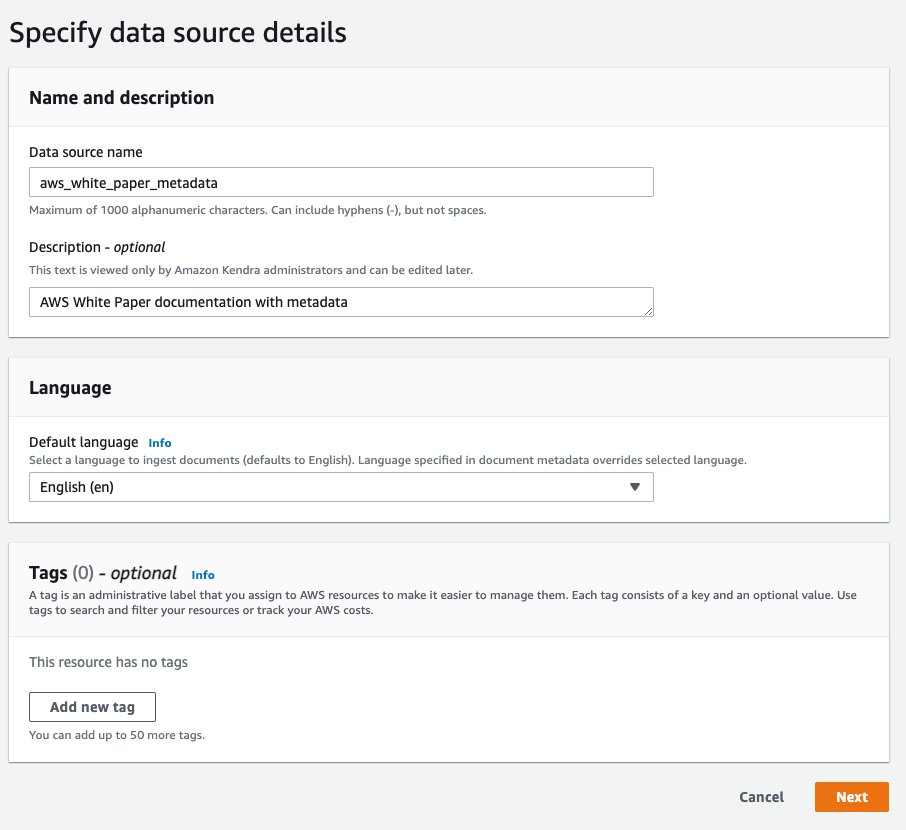
- på Spesifiser datakildedetaljer seksjon, for Navn på datakilde, Tast inn
aws_white_paper. - Til Beskrivelse, Tast inn
AWS White Paper documentation. - Velg neste.
Nå oppretter du en AWS identitets- og tilgangsadministrasjon (IAM) rolle for Amazon Kendra.
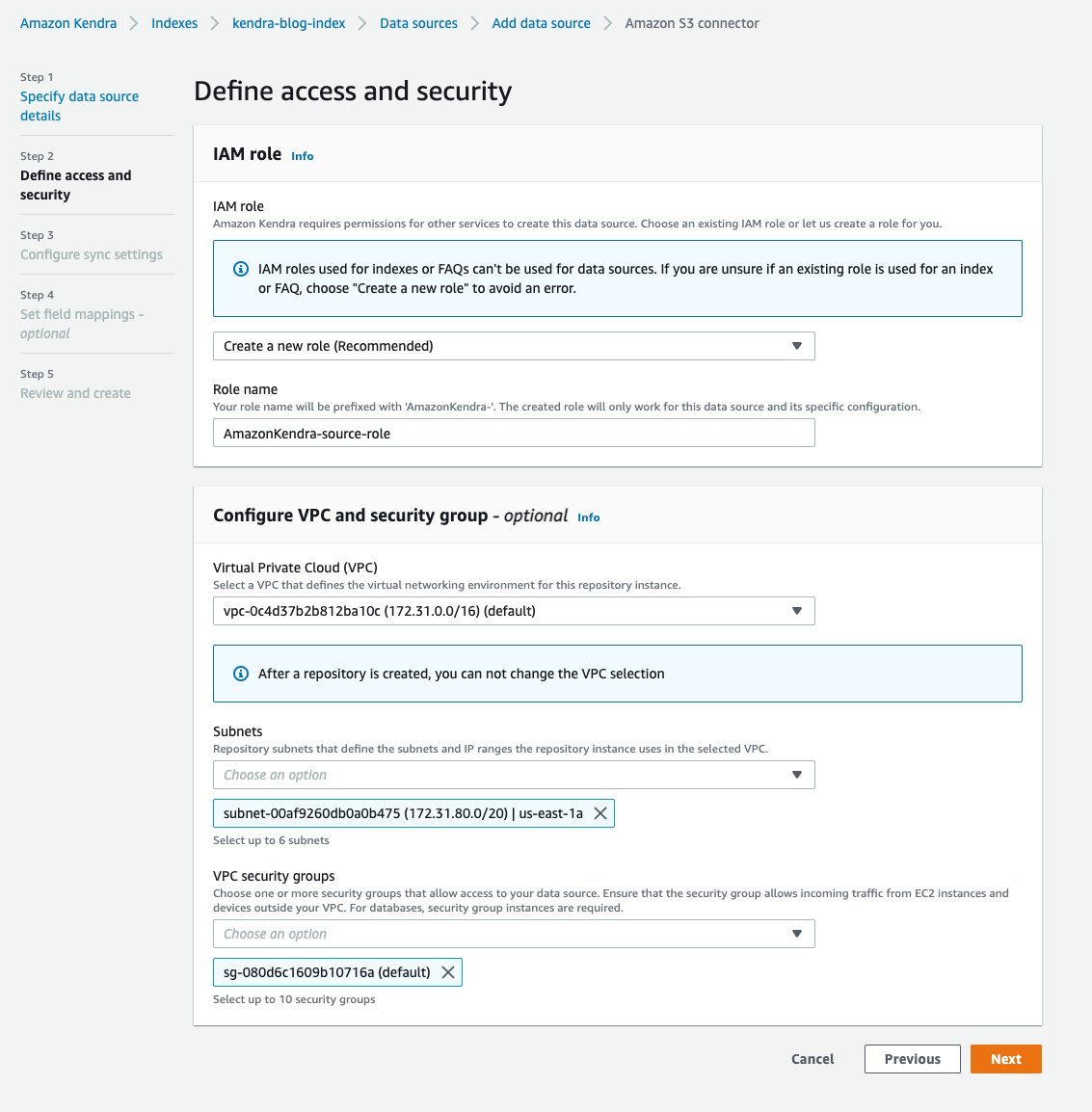
- på Definer tilgang og sikkerhet side, for IAM-rolle delen velger Lag en ny rolle.
- Skriv inn for Rollenavn
source-role(rollenavnet ditt er prefikset medAmazonKendra-). - på Konfigurer VPC og sikkerhet seksjon, velg din VPC, og skriv inn din Subnett og VPC-sikkerhetsgrupper.
For mer informasjon om å koble din Amazon Kendra til din Amazon Virtual Private Cloud, se Konfigurere Amazon Kendra til å bruke en VPC.
- Velg neste.
- på Konfigurer synkroniseringsinnstillinger side, for Angi datakildeplasseringen, skriv inn S3-skuffen du opprettet:
kendrapost-{your account id}. - Permisjon Metadata filer prefiks mappeplassering blank.
Som standard lagres metadatafiler i samme katalog som dokumentene. Hvis du vil plassere disse filene i en annen mappe, kan du legge til et prefiks. For mer informasjon, se Amazon S3 dokumentmetadata.
- Til Velg dekrypteringsnøkkel, la den ikke være valgt.
- Til Ekstra konfigurasjon, kan du legge til et mønster for å inkludere eller ekskludere bestemte mapper eller filer. For dette innlegget beholder du standardverdiene.
- Til Synkroniseringsmodus velge Nye, endrede eller slettede dokumenter synkroniseres.
- Til Frekvens, velg Kjør på forespørsel.
Dette trinnet definerer frekvensen som datakilden synkroniseres med Amazon Kendra-indeksen.
- Velg neste.

- på Angi feltkartlegginger side, behold standardverdiene.
- Velg neste.

- På Gjennomgå og opprett side, velg Legg til datakilde.
- Naviger tilbake til Kendra-indeksen.
- Velg din Datakilde, velg deretter Synkroniser nå for å synkronisere dokumentene med Amazon Kendra-indeksen.

Varigheten av denne prosessen avhenger av antall dokumenter du indekserer. For denne brukstilfellet kan det ta 15 minutter, hvoretter du skal se en melding om at synkroniseringen var vellykket. I delen Synkroniser kjøringshistorikk kan du se at 40 dokumenter ble synkronisert.

Din Amazon Kendra-indeks er nå klar for spørringer med naturlig språk. Når du søker i indeksen din, bruker Amazon Kendra alle dataene og metadataene som er oppgitt for å returnere de mest nøyaktige svarene på søket ditt. På Amazon Kendra-konsollen velger du Søk etter indeksert innhold. I spørringsfeltet starter du med et søk som "Hvilken AWS-tjeneste har 11 niere med holdbarhet?"
For mer informasjon om spørring i indeksen, se Spørre en indeks
Synkroniser datakildeendringer for å søke i indeksen
Datakilden din er satt opp til å synkronisere alle nye, endrede eller slettede data. Før du kan synkronisere datakilden trinnvis med en indeks i Amazon Kendra, må du laste nye dokumenter inn i en S3-bøtte.
- På Amazon S3-konsollen velger du skuffen du nettopp opprettet, og velger Last opp.
- Last opp mappene
SecurityogWell_Architectedfra den utpakkede filen.
Nå kan du synkronisere de nye dokumentene som er lagt til S3-bøtten:
- Velg på Amazon Kendra-konsollen Datakilder og velg deretter S3-datakilden.
- Velg Synkroniser nå.
Varigheten av denne prosessen avhenger av antall dokumenter du indekserer. For dette brukstilfellet kan det ta 15 minutter, hvoretter du skulle se en melding om at synkroniseringen var vellykket.
på Synkroniser kjørelogg delen, kan du se at 20 dokumenter ble synkronisert.

Indekser datakilden på nytt
I et scenario der datakilden har gammel informasjon, kan du nå indeksere datakilden på nytt uten å måtte slette og opprette en ny datakilde. For å endre synkroniseringsmodusen og indeksere datakilden på nytt, fullfør følgende trinn:
- Velg på Amazon Kendra-konsollen Datakilder og velg deretter S3-datakilden.
- På handlinger meny, velg Rediger.
- Velg neste å flytte til Trinn 3 – Konfigurer siden for synkroniseringsinnstillinger.
- For synkroniseringsmodus, velg Full synkronisering.
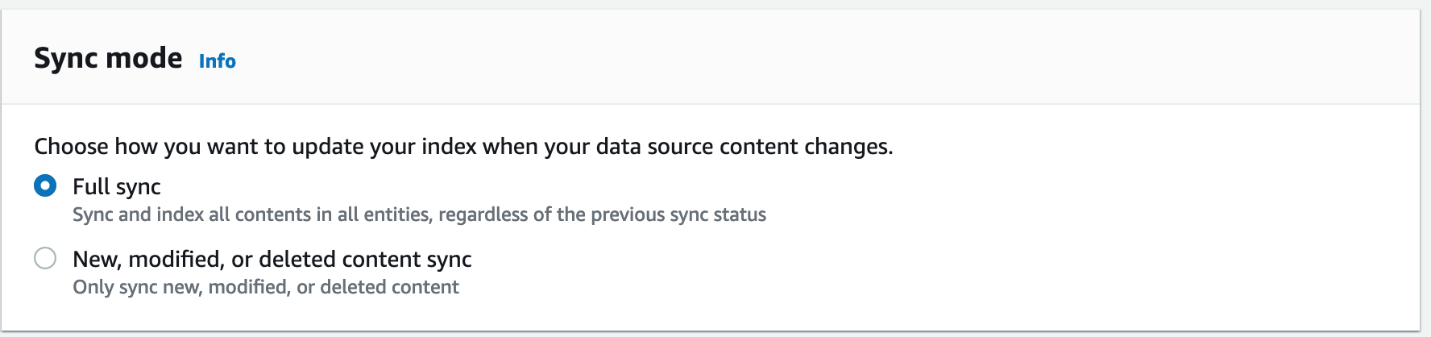
- Til Frekvens, velg Kjør på forespørsel.
- Velg neste.
- på Angi feltkartlegginger side, behold standardverdiene.
- Velg neste.
- På Gjennomgå og opprett side, velg Oppdater.
Nå kan du synkronisere de nye dokumentene som er lagt til S3-bøtten.
- Velg på Amazon Kendra-konsollen Datakilder og velg deretter S3-datakilden.
- Velg Synkroniser nå.
på Synkroniser kjørelogg kan du se at alle dokumenter ble synkronisert uavhengig av forrige synkroniseringsstatus under den modifiserte kolonnen.

Rydd opp
For å unngå fremtidige kostnader og for å rydde ut ubrukte roller og retningslinjer, slett ressursene du opprettet:
- På Amazon Kendra-indeksen, velg Indekser i navigasjonsruten.
- Velg indeksen du opprettet og på handlinger meny, velg Delete.
- For å bekrefte sletting, skriv Slett når du blir bedt om det og velg Delete.
Vent til du får bekreftelsesmeldingen; prosessen kan ta opptil 15 minutter.
- På Amazon S3 -konsollen, slett S3-bøtten.
- På IAM-konsollen, slett de tilsvarende IAM-rollene.
konklusjonen
I dette innlegget lærte du hvordan du bruker Amazon Kendra til å distribuere en bedriftssøketjeneste ved å bruke en sikker tilkobling til Amazon S3 som ikke krever en internettgateway eller NAT-enhet (Network Address Translation). Du kan aktivere raskere synkroniseringer for dokumentene dine ved å bruke synkroniseringsmodus.
Det er mange tilleggsfunksjoner som vi ikke dekket. For eksempel:
- Du kan aktivere brukerbasert tilgangskontroll for Amazon Kendra-indeksen din, og begrense tilgangen til dokumenter basert på tilgangskontrollene du allerede har konfigurert.
- Du kan kartlegge objektattributter til Amazon Kendra-indeksattributter, og aktivere dem for fasetering, søk og visning i søkeresultatene.
- Du kan raskt finne informasjon fra nettsider (HTML-tabeller) ved hjelp av Amazon Kendra-tabellsøk
For å lære mer om Amazon Kendra, se Amazon Kendra utviklerveiledning.
Om forfatterne
 Maran Chandrasekaran er Senior Solutions Architect hos Amazon Web Services, og jobber med våre bedriftskunder. Utenom jobben elsker han å reise.
Maran Chandrasekaran er Senior Solutions Architect hos Amazon Web Services, og jobber med våre bedriftskunder. Utenom jobben elsker han å reise.
 Arjun Agrawal er programvareingeniør hos AWS, og jobber for tiden med et Amazon Kendra-team på en bedriftssøkemotor. Han er lidenskapelig opptatt av ny teknologi og å løse problemer i den virkelige verden. Utenom jobben elsker han å gå tur og reise.
Arjun Agrawal er programvareingeniør hos AWS, og jobber for tiden med et Amazon Kendra-team på en bedriftssøkemotor. Han er lidenskapelig opptatt av ny teknologi og å løse problemer i den virkelige verden. Utenom jobben elsker han å gå tur og reise.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/search-for-answers-accurately-using-amazon-kendra-s3-connector-with-vpc-support/
- 10
- 100
- 11
- 7
- a
- Om oss
- adgang
- tilgjengelig
- Logg inn
- nøyaktig
- nøyaktig
- tvers
- la til
- tillegg
- Ytterligere
- adresse
- Etter
- algoritmer
- Alle
- tillater
- allerede
- Amazon
- Amazon Kendra
- Amazon RDS
- Amazon Web Services
- og
- svar
- søknader
- assosiert
- attributter
- automatisk
- tilgjengelig
- unngå
- AWS
- tilbake
- basert
- basis
- før du
- evner
- saken
- saker
- kategorier
- viss
- Endringer
- avgifter
- valg
- Velg
- klassifisering
- Cloud
- Kolonne
- fullføre
- fullført
- Bekrefte
- Koble
- Tilkobling
- tilkobling
- Konsoll
- inneholder
- innhold
- kontekst
- fortsetter
- kontroll
- kontroller
- riktig
- Tilsvarende
- Kostnad
- dekke
- skape
- opprettet
- skaperverket
- I dag
- Kunder
- dato
- Database
- databaser
- datasett
- Misligholde
- definerer
- demonstrerer
- avhenger
- utplassere
- beskrive
- Utvikler
- enhet
- forskjellig
- Vise
- dokument
- dokumenter
- ikke
- stasjonen
- slitestyrke
- øst
- lett-å-bruke
- muliggjøre
- muliggjør
- Motor
- ingeniør
- Enter
- Enterprise
- bedriftskunder
- Enterprise Søk
- Eter (ETH)
- Hver
- alt
- eksempel
- eksisterende
- Egenskaper
- felt
- filet
- Filer
- Finn
- etter
- Frekvens
- fra
- fullt
- framtid
- gateway
- få
- Gruppens
- å ha
- hjelpe
- Fottur
- historie
- Hvordan
- Hvordan
- Men
- HTML
- HTTPS
- IAM
- Identitet
- forbedringer
- in
- inkludere
- inkludering
- indeks
- informasjon
- instruksjoner
- integrere
- Intelligent
- Internet
- innføre
- uansett
- IT
- Jobb
- Hold
- Språk
- Siste
- LÆRE
- lært
- læring
- Permisjon
- knyttet
- Liste
- laste
- plassering
- maskin
- maskinlæring
- Hoved
- gjøre
- ledelse
- mange
- kart
- Meny
- melding
- metadata
- minutter
- ML
- Mote
- moduser
- modifisert
- modifisere
- mer
- mest
- flytte
- flere
- navn
- Naturlig
- Naturlig språk
- Naviger
- Navigasjon
- Trenger
- nettverk
- nettverk
- Ny
- Antall
- objekt
- gjenstander
- OneDrive
- utenfor
- egen
- brød
- Papir
- lidenskapelig
- banen
- Mønster
- mønstre
- Sted
- plato
- Platon Data Intelligence
- PlatonData
- Politikk
- Post
- forutsetninger
- forrige
- privat
- problemer
- prosess
- Prosesser
- gi
- forutsatt
- gir
- offentlig
- spørsmål
- raskere
- raskt
- å nå
- klar
- virkelige verden
- redusere
- reflektere
- region
- regelmessig
- relevant
- krever
- Ressurser
- begrense
- Resultater
- retur
- Rolle
- roller
- root
- Kjør
- rennende
- Salesforce
- samme
- scenario
- planlegge
- Søk
- søkemotor
- Seksjon
- sikre
- sikkert
- sikkerhet
- senior
- tjeneste
- Tjenester
- sett
- innstillinger
- delt
- sharepoint
- bør
- Viser
- Enkelt
- siden
- So
- Software
- Software Engineer
- Solutions
- løse
- noen
- kilde
- Kilder
- spesifikk
- Begynn
- status
- Trinn
- Steps
- lagring
- lagret
- butikker
- stil
- subnett
- subnett
- vellykket
- slik
- støtte
- Støttes
- Støtter
- synkronisering
- Ta
- lag
- Teknologi
- De
- Kilden
- deres
- tre
- tid
- til
- Oversettelse
- reiser
- typer
- etter
- forstå
- unix
- ubrukt
- oppdatert
- us
- bruke
- bruk sak
- Brukere
- Verdier
- Virginia
- virtuelle
- walkthrough
- web
- webtjenester
- hvilken
- hvit
- hvitt papir
- innenfor
- uten
- Arbeid
- arbeid
- Din
- zephyrnet
- Zip