I datasyn er semantisk segmentering oppgaven med å klassifisere hver piksel i et bilde med en klasse fra et kjent sett med etiketter slik at piksler med samme etikett deler visse egenskaper. Den genererer en segmenteringsmaske av inngangsbildene. For eksempel viser følgende bilder en segmenteringsmaske av cat merkelapp.
 |
 |
I november 2018, Amazon SageMaker kunngjorde lanseringen av SageMaker semantiske segmenteringsalgoritme. Med denne algoritmen kan du trene modellene dine med et offentlig datasett eller ditt eget datasett. Populære bildesegmenteringsdatasett inkluderer Common Objects in Context (COCO) datasettet og PASCAL Visual Object Classes (PASCAL VOC), men klassene til etikettene deres er begrenset, og det kan være lurt å trene en modell på målobjekter som ikke er inkludert i offentlige datasett. I dette tilfellet kan du bruke Amazon SageMaker Ground Truth for å merke ditt eget datasett.
I dette innlegget demonstrerer jeg følgende løsninger:
- Bruke Ground Truth til å merke et semantisk segmenteringsdatasett
- Transformere resultatene fra Ground Truth til det nødvendige inndataformatet for SageMaker innebygde semantiske segmenteringsalgoritme
- Bruke den semantiske segmenteringsalgoritmen for å trene en modell og utføre inferens
Merking av semantisk segmenteringsdata
For å bygge en maskinlæringsmodell for semantisk segmentering, må vi merke et datasett på pikselnivå. Ground Truth gir deg muligheten til å bruke menneskelige annotatorer gjennom Amazon Mekanisk Turk, tredjepartsleverandører eller din egen private arbeidsstyrke. For å lære mer om arbeidsstyrker, se Opprett og administrer arbeidsstyrker. Hvis du ikke ønsker å administrere merkearbeidsstyrken på egen hånd, Amazon SageMaker Ground Truth Plus er et annet flott alternativ som en ny nøkkelferdig datamerkingstjeneste som lar deg lage opplæringsdatasett av høy kvalitet raskt og reduserer kostnadene med opptil 40 %. For dette innlegget viser jeg deg hvordan du manuelt merker datasettet med Ground Truth-autosegment-funksjonen og crowdsource-merking med en Mechanical Turk-arbeidsstyrke.
Manuell merking med Ground Truth
I desember 2019 la Ground Truth til en automatisk segmenteringsfunksjon til brukergrensesnittet for merking av semantisk segmentering for å øke merkinggjennomstrømningen og forbedre nøyaktigheten. For mer informasjon, se Automatisk segmentering av objekter når du utfører merking av semantisk segmentering med Amazon SageMaker Ground Truth. Med denne nye funksjonen kan du fremskynde merkeprosessen på segmenteringsoppgaver. I stedet for å tegne en tettsittende polygon eller bruke penselverktøyet til å fange et objekt i et bilde, tegner du bare fire punkter: øverst, nederst, lengst til venstre og lengst til høyre på objektet. Ground Truth tar disse fire punktene som input og bruker algoritmen Deep Extreme Cut (DEXTR) for å produsere en tettsittende maske rundt objektet. For en opplæring som bruker Ground Truth for merking av semantisk bildesegmentering, se Bilde semantisk segmentering. Følgende er et eksempel på hvordan autosegmenteringsverktøyet genererer en segmenteringsmaske automatisk etter at du har valgt de fire ytterpunktene til et objekt.


Crowdsourcing-merking med en Mechanical Turk-arbeidsstyrke
Hvis du har et stort datasett og du ikke vil manuelt merke hundrevis eller tusenvis av bilder selv, kan du bruke Mechanical Turk, som gir en etterspørsel, skalerbar, menneskelig arbeidsstyrke for å fullføre jobber som mennesker kan gjøre bedre enn datamaskiner. Mechanical Turk-programvaren formaliserer jobbtilbud til tusenvis av arbeidere som er villige til å utføre stykkevis arbeid når det passer dem. Programvaren henter også utført arbeid og kompilerer det for deg, rekvirenten, som betaler arbeiderne for tilfredsstillende arbeid (kun). For å komme i gang med Mechanical Turk, se Introduksjon til Amazon Mechanical Turk.
Opprett en merkejobb
Følgende er et eksempel på en Mechanical Turk-merkejobb for et havskilpaddedatasett. Havskilpaddedatasettet er fra Kaggle-konkurransen Ansiktsgjenkjenning for havskilpadder, og jeg valgte 300 bilder av datasettet for demonstrasjonsformål. Havskilpadde er ikke en vanlig klasse i offentlige datasett, så den kan representere en situasjon som krever merking av et massivt datasett.
- Velg på SageMaker-konsollen Merking jobber i navigasjonsruten.
- Velg Lag merkejobb.
- Skriv inn et navn for jobben din.
- Til Inndataoppsett, plukke ut Automatisert dataoppsett.
Dette genererer et manifest av inndata. - Til S3-plassering for input-datasett, skriv inn banen for datasettet.

- Til Oppgavekategori, velg Bilde.
- Til Oppgavevalg, plukke ut Semantisk segmentering.

- Til Arbeidertyper, plukke ut Amazon Mekanisk Turk.
- Konfigurer innstillingene for oppgavetidsavbrudd, oppgavens utløpstid og pris per oppgave.

- Legg til en etikett (for dette innlegget,
sea turtle), og gi instruksjoner for merking. - Velg Opprett.

Etter at du har konfigurert merkejobben, kan du sjekke merkefremdriften på SageMaker-konsollen. Når den er merket som fullført, kan du velge jobben for å sjekke resultatene og bruke dem til de neste trinnene.

Datasetttransformasjon
Etter at du har fått utdataene fra Ground Truth, kan du bruke SageMaker innebygde algoritmer for å trene en modell på dette datasettet. Først må du klargjøre det merkede datasettet som det forespurte inngangsgrensesnittet for SageMaker semantiske segmenteringsalgoritme.
Forespurte inndatakanaler
SageMaker semantisk segmentering forventer at treningsdatasettet ditt blir lagret på Amazon enkel lagringstjeneste (Amazon S3). Datasettet i Amazon S3 forventes å bli presentert i to kanaler, en for train og en for validation, bruker fire kataloger, to for bilder og to for merknader. Merknader forventes å være ukomprimerte PNG-bilder. Datasettet kan også ha et etikettkart som beskriver hvordan merknadstilordningene er etablert. Hvis ikke, bruker algoritmen en standard. For slutninger aksepterer et endepunkt bilder med en image/jpeg innholdstype. Følgende er den nødvendige strukturen til datakanalene:
Hvert JPG-bilde i tog- og valideringskatalogen har et tilsvarende PNG-etikettbilde med samme navn i train_annotation og validation_annotation kataloger. Denne navnekonvensjonen hjelper algoritmen med å assosiere en etikett med dens tilsvarende bilde under trening. Toget, train_annotation, validering og validation_annotation kanaler er obligatoriske. Merknadene er en-kanals PNG-bilder. Formatet fungerer så lenge metadataene (modusene) i bildet hjelper algoritmen med å lese merknadsbildene til et enkeltkanals 8-bits usignert heltall.
Utdata fra Ground Truth-merkejobben
Utdataene generert fra Ground Truth-merkejobben har følgende mappestruktur:
Segmenteringsmaskene er lagret i s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Hvert merknadsbilde er en .png-fil oppkalt etter indeksen til kildebildet og tidspunktet da denne bildemerkingen ble fullført. Følgende er for eksempel kildebildet (Image_1.jpg) og segmenteringsmasken generert av Mechanical Turk-arbeidsstyrken (0_2022-02-10T17:41:04.724225.png). Legg merke til at indeksen til masken er forskjellig fra tallet i kildebildenavnet.
 |
 |
Utdatamanifestet fra merkejobben er i /manifests/output/output.manifest fil. Det er en JSON-fil, og hver linje registrerer en tilordning mellom kildebildet og etiketten og andre metadata. Følgende JSON-linje registrerer en tilordning mellom det viste kildebildet og dets merknad:
Kildebildet heter Image_1.jpg, og merknadens navn er 0_2022-02-10T17:41: 04.724225.png. For å forberede dataene som de nødvendige datakanalformatene til SageMaker semantiske segmenteringsalgoritmen, må vi endre merknadsnavnet slik at det har samme navn som kilde-JPG-bildene. Og vi må også dele opp datasettet i train og validation kataloger for kildebilder og merknader.
Transform utdataene fra en Ground Truth-merkejobb til det forespurte inndataformatet
For å transformere utdataene, fullfør følgende trinn:
- Last ned alle filene fra merkejobben fra Amazon S3 til en lokal katalog:
- Les manifestfilen og endre navnene på merknaden til de samme navnene som kildebildene:
- Del opp tog- og valideringsdatasettene:
- Lag en katalog i det nødvendige formatet for datakanalene for semantisk segmenteringsalgoritme:
- Flytt tog- og valideringsbildene og deres merknader til de opprettede katalogene.
- For bilder, bruk følgende kode:
- For merknader, bruk følgende kode:
- Last opp tog- og valideringsdatasettene og deres merknadsdatasett til Amazon S3:
SageMaker semantisk segmenteringsmodellopplæring
I denne delen går vi gjennom trinnene for å trene din semantiske segmenteringsmodell.
Følg eksempelnotisboken og sett opp datakanaler
Du kan følge instruksjonene i Semantisk segmenteringsalgoritme er nå tilgjengelig i Amazon SageMaker for å implementere den semantiske segmenteringsalgoritmen til ditt merkede datasett. Denne prøven bærbare viser et ende-til-ende eksempel som introduserer algoritmen. I notatboken lærer du hvordan du trener og er vert for en semantisk segmenteringsmodell ved å bruke det fullstendig konvolusjonelle nettverket (FCN) algoritme som bruker Pascal VOC datasett for trening. Fordi jeg ikke planlegger å trene en modell fra Pascal VOC-datasettet, hoppet jeg over trinn 3 (dataforberedelse) i denne notatboken. I stedet opprettet jeg direkte train_channel, train_annotation_channe, validation_channelog validation_annotation_channel ved å bruke S3-stedene der jeg lagret bildene og kommentarene mine:
Juster hyperparametre for ditt eget datasett i SageMaker estimator
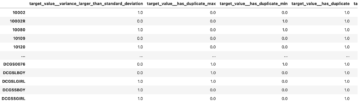
Jeg fulgte notatboken og laget et SageMaker-estimatorobjekt (ss_estimator) for å trene opp segmenteringsalgoritmen min. En ting vi må tilpasse for det nye datasettet er inne ss_estimator.set_hyperparameters: vi må endre num_classes=21 til num_classes=2 (turtle og background), og jeg endret også epochs=10 til epochs=30 fordi 10 bare er for demoformål. Deretter brukte jeg p3.2xlarge-forekomsten for modelltrening ved innstilling instance_type="ml.p3.2xlarge". Treningen ble fullført på 8 minutter. Den beste MIoU (Mean Intersection over Union) på 0.846 oppnås ved epoke 11 med en pix_acc (prosentandelen av piksler i bildet som er klassifisert riktig) på 0.925, som er et ganske bra resultat for dette lille datasettet.
Modellinferensresultater
Jeg var vert for modellen på en lavpris ml.c5.xlarge-instans:
Til slutt forberedte jeg et testsett med 10 skilpaddebilder for å se resultatet av den trente segmenteringsmodellen:
Følgende bilder viser resultatene.

Segmenteringsmaskene til havskilpaddene ser nøyaktige ut, og jeg er fornøyd med dette resultatet trent på et 300-bilders datasett merket av Mechanical Turk-arbeidere. Du kan også utforske andre tilgjengelige nettverk som f.eks pyramide-scene-parsing-nettverk (PSP) or DeepLab-V3 i eksempelnotisboken med datasettet ditt.
Rydd opp
Slett endepunktet når du er ferdig med det for å unngå å pådra deg fortsatte kostnader:
konklusjonen
I dette innlegget viste jeg hvordan du kan tilpasse merking av semantisk segmenteringsdata og modelltrening ved hjelp av SageMaker. Først kan du sette opp en merkejobb med autosegmenteringsverktøyet eller bruke en Mechanical Turk-arbeidsstyrke (samt andre alternativer). Hvis du har mer enn 5,000 objekter, kan du også bruke automatisert datamerking. Deretter transformerer du utdataene fra Ground Truth-merkejobben til de nødvendige inputformatene for SageMaker innebygde semantisk segmenteringstrening. Etter det kan du bruke en akselerert databehandlingsforekomst (som p2 eller p3) for å trene en semantisk segmenteringsmodell med følgende bærbare og distribuer modellen til en mer kostnadseffektiv instans (som ml.c5.xlarge). Til slutt kan du gjennomgå slutningsresultatene på testdatasettet ditt med noen få linjer med kode.
Kom i gang med SageMaker semantisk segmentering datamerking og modellopplæring med favorittdatasettet ditt!
om forfatteren
 Kara Yang er en dataforsker i AWS Professional Services. Hun brenner for å hjelpe kunder med å nå sine forretningsmål med AWS skytjenester. Hun har hjulpet organisasjoner med å bygge ML-løsninger på tvers av flere bransjer som produksjon, bilindustri, miljømessig bærekraft og romfart.
Kara Yang er en dataforsker i AWS Professional Services. Hun brenner for å hjelpe kunder med å nå sine forretningsmål med AWS skytjenester. Hun har hjulpet organisasjoner med å bygge ML-løsninger på tvers av flere bransjer som produksjon, bilindustri, miljømessig bærekraft og romfart.
- Myntsmart. Europas beste Bitcoin og Crypto Exchange.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. FRI TILGANG.
- CryptoHawk. Altcoin Radar. Gratis prøveperiode.
- Kilde: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- Om oss
- akselerere
- akselerert
- nøyaktig
- Oppnå
- oppnådd
- tvers
- la til
- Aerospace
- algoritme
- algoritmer
- Alle
- Amazon
- annonsert
- En annen
- rundt
- Førsteamanuensis
- Automatisert
- automatisk
- automotive
- tilgjengelig
- AWS
- bakgrunn
- fordi
- BEST
- Bedre
- mellom
- bygge
- innebygd
- virksomhet
- fangst
- saken
- viss
- endring
- kanaler
- Velg
- klasse
- klasser
- klassifisert
- Cloud
- skytjenester
- kode
- Felles
- konkurranse
- fullføre
- datamaskin
- datamaskiner
- databehandling
- selvtillit
- Konsoll
- innhold
- bekvemmelighet
- Tilsvarende
- kostnadseffektiv
- Kostnader
- skape
- opprettet
- Kunder
- tilpasse
- dato
- dataforsker
- dyp
- demonstrere
- utplassere
- forskjellig
- direkte
- tegning
- under
- hver enkelt
- muliggjør
- ende til ende
- Endpoint
- Enter
- miljømessige
- etablert
- eksempel
- Unntatt
- forventet
- forventer
- utforske
- ekstrem
- Face
- Trekk
- Først
- følge
- etter
- format
- fra
- generert
- Mål
- god
- grå
- flott
- lykkelig
- hjulpet
- hjelpe
- hjelper
- høykvalitets
- vert
- Hvordan
- Hvordan
- HTTPS
- menneskelig
- Mennesker
- Hundrevis
- bilde
- bilder
- iverksette
- forbedre
- inkludere
- inkludert
- Øke
- indeks
- bransjer
- informasjon
- inngang
- f.eks
- Interface
- kryss
- innføre
- IT
- Jobb
- Jobb
- kjent
- Etiketten
- merking
- etiketter
- stor
- lansere
- LÆRE
- læring
- Nivå
- Begrenset
- linje
- linjer
- Liste
- lokal
- plassering
- steder
- Lang
- Se
- maskin
- maskinlæring
- administrer
- obligatorisk
- manuelt
- produksjon
- kart
- kartlegging
- maske
- masker
- massive
- mekanisk
- kunne
- ML
- modell
- modeller
- mer
- flere
- navn
- navngiving
- Navigasjon
- nettverk
- nettverk
- neste
- bærbare
- Antall
- Tilbud
- Alternativ
- alternativer
- organisasjoner
- Annen
- egen
- lidenskapelig
- prosent
- utfører
- poeng
- polygon
- Populær
- Forbered
- pen
- pris
- privat
- prosess
- produsere
- profesjonell
- gi
- gir
- offentlig
- formål
- raskt
- RE
- poster
- representere
- påkrevd
- Krever
- Resultater
- anmeldelse
- samme
- skalerbar
- Forsker
- SEA
- segmentering
- valgt
- tjeneste
- Tjenester
- sett
- innstilling
- Del
- Vis
- vist
- Enkelt
- situasjon
- liten
- So
- Software
- Solutions
- splittet
- startet
- lagring
- Bærekraft
- Target
- oppgaver
- lag
- test
- De
- Kilden
- ting
- tredjeparts
- tusener
- Gjennom
- gjennomstrømning
- tid
- verktøy
- Tog
- Kurs
- Transform
- union
- bruke
- validering
- leverandører
- syn
- HVEM
- Arbeid
- arbeidere
- arbeidsstyrke
- virker
- Din