ZOO Digital tilbyr ende-til-ende lokalisering og medietjenester for å tilpasse originalt TV- og filminnhold til forskjellige språk, regioner og kulturer. Det gjør globalisering enklere for verdens beste innholdsskapere. Stolt på av de største navnene innen underholdning, leverer ZOO Digital høykvalitets lokalisering og medietjenester i stor skala, inkludert dubbing, teksting, skripting og overholdelse.
Typiske arbeidsflyter for lokalisering krever manuell høyttalerdiaarisering, der en lydstrøm segmenteres basert på høyttalerens identitet. Denne tidkrevende prosessen må fullføres før innhold kan dubbes til et annet språk. Med manuelle metoder kan en 30-minutters episode ta mellom 1–3 timer å lokalisere. Gjennom automatisering har ZOO Digital som mål å oppnå lokalisering på under 30 minutter.
I dette innlegget diskuterer vi distribusjon av skalerbare maskinlæringsmodeller (ML) for å diariere medieinnhold ved hjelp av Amazon SageMaker, med fokus på WhisperX modell.
Bakgrunn
ZOO Digitals visjon er å gi en raskere behandling av lokalisert innhold. Dette målet er flaskehalser av den manuelt intensive øvelsen sammensatt av den lille arbeidsstyrken av dyktige folk som kan lokalisere innhold manuelt. ZOO Digital jobber med over 11,000 600 frilansere og lokaliserte over 2022 millioner ord i XNUMX alene. Tilgangen på dyktige folk blir imidlertid overgått av den økende etterspørselen etter innhold, noe som krever automatisering for å hjelpe med lokaliseringsarbeidsflyter.
Med et mål om å akselerere lokaliseringen av innholdsarbeidsflyter gjennom maskinlæring, engasjerte ZOO Digital AWS Prototyping, et investeringsprogram fra AWS for å bygge arbeidsmengder sammen med kunder. Engasjementet fokuserte på å levere en funksjonell løsning for lokaliseringsprosessen, samtidig som det ga praktisk opplæring til ZOO Digital-utviklere på SageMaker, Amazon Transcribeog Amazon Oversett.
Kundeutfordring
Etter at en tittel (en film eller en episode av en TV-serie) har blitt transkribert, må høyttalere tildeles hvert talesegment slik at de kan tildeles korrekt til stemmeartistene som er rollebesetning for å spille karakterene. Denne prosessen kalles høyttalerdiarisering. ZOO Digital står overfor utfordringen med å diariere innhold i stor skala samtidig som det er økonomisk levedyktig.
Løsningsoversikt
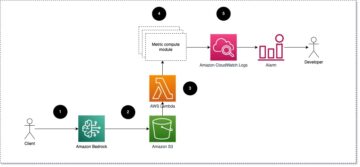
I denne prototypen lagret vi de originale mediefilene i en spesifisert Amazon enkel lagringstjeneste (Amazon S3) bøtte. Denne S3-bøtten ble konfigurert til å sende ut en hendelse når nye filer oppdages i den, og utløse en AWS Lambda funksjon. For instruksjoner om hvordan du konfigurerer denne utløseren, se veiledningen Bruke en Amazon S3-utløser for å starte en Lambda-funksjon. Deretter påkalte Lambda-funksjonen SageMaker-endepunktet for slutning ved bruk av Boto3 SageMaker Runtime-klient.
De WhisperX modell, basert på OpenAIs Whisper, utfører transkripsjoner og diarisering for medieressurser. Den er bygget på Raskere hvisking reimplementering, og tilbyr opptil fire ganger raskere transkripsjon med forbedret tidsstempeljustering på ordnivå sammenlignet med Whisper. I tillegg introduserer den høyttalerdiarisering, som ikke finnes i den originale Whisper-modellen. WhisperX bruker Whisper-modellen for transkripsjoner, den Wav2Vec2 modell for å forbedre tidsstempeljusteringen (sikre synkronisering av transkribert tekst med lydtidsstempler), og pyannote modell for diarisering. FFmpeg brukes til å laste inn lyd fra kildemedier, som støtter ulike medieformater. Den transparente og modulære modellarkitekturen tillater fleksibilitet, fordi hver komponent i modellen kan byttes ut etter behov i fremtiden. Det er imidlertid viktig å merke seg at WhisperX mangler fulle administrasjonsfunksjoner og ikke er et produkt på bedriftsnivå. Uten vedlikehold og støtte er det kanskje ikke egnet for produksjonsdistribusjon.
I dette samarbeidet har vi distribuert og evaluert WhisperX på SageMaker, ved å bruke en endepunkt for asynkron inferens å være vert for modellen. SageMaker asynkrone endepunkter støtter opplastingsstørrelser på opptil 1 GB og inkluderer funksjoner for automatisk skalering som effektivt reduserer trafikkøkninger og sparer kostnader i lavkonjunkturer. Asynkrone endepunkter er spesielt godt egnet for behandling av store filer, som filmer og TV-serier i vårt brukstilfelle.
Følgende diagram illustrerer kjerneelementene i eksperimentene vi utførte i dette samarbeidet.
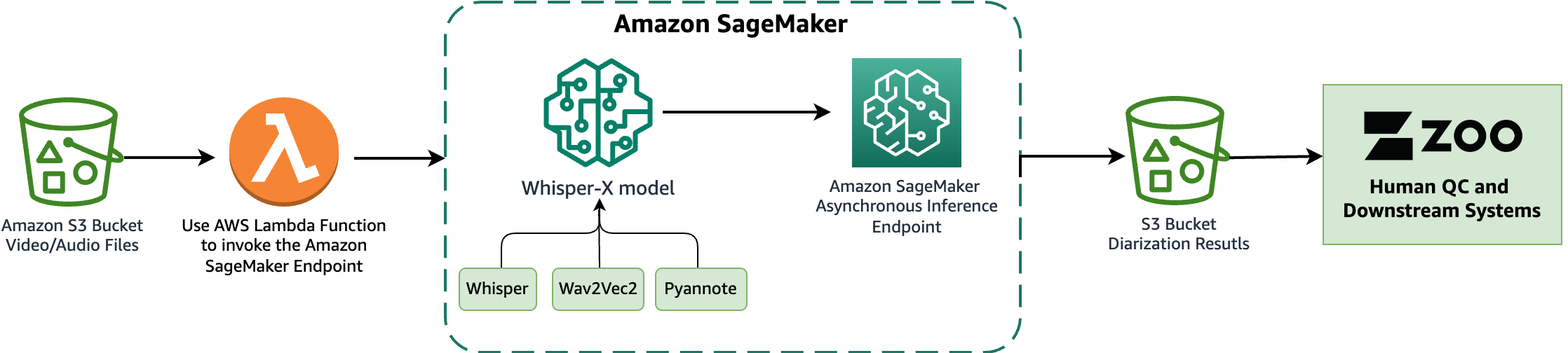
I de følgende avsnittene fordyper vi oss i detaljene rundt distribusjon av WhisperX-modellen på SageMaker, og evaluerer diarisasjonsytelsen.
Last ned modellen og dens komponenter
WhisperX er et system som inkluderer flere modeller for transkripsjon, tvungen justering og diarisering. For jevn SageMaker-drift uten behov for å hente modellartefakter under inferens, er det viktig å forhåndslaste ned alle modellartefakter. Disse gjenstandene blir deretter lastet inn i SageMaker-serveringsbeholderen under initiering. Fordi disse modellene ikke er direkte tilgjengelige, tilbyr vi beskrivelser og eksempelkode fra WhisperX-kilden, og gir instruksjoner om nedlasting av modellen og dens komponenter.
WhisperX bruker seks modeller:
De fleste av disse modellene kan fås fra Klemme ansiktet ved hjelp av huggingface_hub-biblioteket. Vi bruker følgende download_hf_model() funksjon for å hente disse modellartefaktene. Et tilgangstoken fra Hugging Face, generert etter å ha akseptert brukeravtalene for følgende pyannote-modeller, kreves:
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization" def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str: """ Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to :param model_name: HuggingFace model name (and an optional version, appended with @[version]) :param hf_token: HuggingFace access token authorized to access the requested model :param local_model_dir: The local directory to download the model to :return: The subdirectory within local_modeL_dir that the model is downloaded to """ model_subdir = model_name.split('@')[0] huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False) return model_subdir
VAD-modellen hentes fra Amazon S3, og Wav2Vec2-modellen hentes fra torchaudio.pipelines-modulen. Basert på følgende kode kan vi hente alle modellenes artefakter, inkludert de fra Hugging Face, og lagre dem i den spesifiserte lokale modellkatalogen:
def fetch_models(hf_token: str, local_model_dir="./models"): """ Fetches all required models to run WhisperX locally without downloading models every time :param hf_token: A huggingface access token to download the models :param local_model_dir: The directory to download the models to """ # Fetch Faster Whisper's Large V2 model from HuggingFace download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir) # Fetch WhisperX's VAD Segmentation model from S3 vad_model_dir = "whisperx/vad" if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"): os.makedirs(f"{local_model_dir}/{vad_model_dir}") urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin") # Fetch the Wav2Vec2 alignment model torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"}) # Fetch pyannote's Speaker Diarization model from HuggingFace download_hf_model(model_name=DIARIZATION_MODEL, hf_token=hf_token, local_model_dir=local_model_dir) # Read in the Speaker Diarization model config to fetch models and update with their local paths with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file: diarization_config = yaml.safe_load(file) embedding_model = diarization_config['pipeline']['params']['embedding'] embedding_model_dir = download_hf_model(model_name=embedding_model, hf_token=hf_token, local_model_dir=local_model_dir) diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}" segmentation_model = diarization_config['pipeline']['params']['segmentation'] segmentation_model_dir = download_hf_model(model_name=segmentation_model, hf_token=hf_token, local_model_dir=local_model_dir) diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin" with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file: yaml.safe_dump(diarization_config, file) # Read in the Speaker Embedding model config to update it with its local path speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml" with open(speechbrain_hyperparams_path, 'r') as file: speechbrain_hyperparams = file.read() speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}") with open(speechbrain_hyperparams_path, 'w') as file: file.write(speechbrain_hyperparams)
Velg riktig AWS Deep Learning Container for å betjene modellen
Etter at modellartefaktene er lagret ved hjelp av den foregående eksempelkoden, kan du velge forhåndsbygd AWS Deep Learning-beholdere (DLC-er) fra følgende GitHub repo. Når du velger Docker-bildet, bør du vurdere følgende innstillinger: rammeverk (Hugging Face), oppgave (inferens), Python-versjon og maskinvare (for eksempel GPU). Vi anbefaler å bruke følgende bilde: 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 Dette bildet har alle nødvendige systempakker forhåndsinstallert, for eksempel ffmpeg. Husk å erstatte [REGION] med AWS-regionen du bruker.
For andre nødvendige Python-pakker, opprett en requirements.txt fil med en liste over pakker og deres versjoner. Disse pakkene vil bli installert når AWS DLC bygges. Følgende er tilleggspakkene som trengs for å være vert for WhisperX-modellen på SageMaker:
Lag et inferensskript for å laste modellene og kjøre inferens
Deretter lager vi en egendefinert inference.py skript for å skissere hvordan WhisperX-modellen og dens komponenter lastes inn i beholderen og hvordan slutningsprosessen skal kjøres. Skriptet inneholder to funksjoner: model_fn og transform_fn. De model_fn funksjonen påkalles for å laste modellene fra deres respektive plasseringer. Deretter overføres disse modellene til transform_fn funksjon under inferens, hvor transkripsjons-, justering- og diariseringsprosesser utføres. Følgende er et kodeeksempel for inference.py:
import io
import json
import logging
import tempfile
import time import torch
import whisperx DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu' def model_fn(model_dir: str) -> dict: """ Deserialize and return the models """ logging.info("Loading WhisperX model") model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2", device=DEVICE, language="en", compute_type="float16", vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"}) logging.info("Loading alignment model") align_model, metadata = whisperx.load_align_model(language_code="en", device=DEVICE, model_name="WAV2VEC2_ASR_BASE_960H", model_dir=f"{model_dir}/wav2vec2") logging.info("Loading diarization model") diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml", device=DEVICE) return { 'model': model, 'align_model': align_model, 'metadata': metadata, 'diarization_model': diarization_model } def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str): """ Load in audio from the request, transcribe and diarize, and return JSON output """ # Start a timer so that we can log how long inference takes start_time = time.time() # Unpack the models whisperx_model = model['model'] align_model = model['align_model'] metadata = model['metadata'] diarization_model = model['diarization_model'] # Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it logging.info("Loading audio") with io.BytesIO(request_body) as file: tfile = tempfile.NamedTemporaryFile(delete=False) tfile.write(file.read()) audio = whisperx.load_audio(tfile.name) # Run transcription logging.info("Transcribing audio") result = whisperx_model.transcribe(audio, batch_size=16) # Align the outputs for better timings logging.info("Aligning outputs") result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False) # Run diarization logging.info("Running diarization") diarize_segments = diarization_model(audio) result = whisperx.assign_word_speakers(diarize_segments, result) # Calculate the time it took to perform the transcription and diarization end_time = time.time() elapsed_time = end_time - start_time logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds") # Return the results to be stored in S3 return json.dumps(result), response_content_type
Innenfor modellens katalog, ved siden av requirements.txt fil, sikre tilstedeværelsen av inference.py i en kodeunderkatalog. De models katalogen skal ligne følgende:
Lag en tarball av modellene
Etter at du har opprettet modellene og kodekatalogene, kan du bruke følgende kommandolinjer til å komprimere modellen til en tarball (.tar.gz-fil) og laste den opp til Amazon S3. I skrivende stund, ved å bruke den raskere hviskende Large V2-modellen, er den resulterende tarballen som representerer SageMaker-modellen 3 GB i størrelse. For mer informasjon, se Modellvertsmønstre i Amazon SageMaker, del 2: Komme i gang med å distribuere sanntidsmodeller på SageMaker.
Lag en SageMaker-modell og distribuer et endepunkt med en asynkron prediktor
Nå kan du opprette SageMaker-modellen, endepunktkonfigurasjonen og asynkront endepunkt med AsyncPredictor ved å bruke tarballmodellen som ble opprettet i forrige trinn. For instruksjoner, se Opprett et asynkront inferensendepunkt.
Evaluer diarisasjonsytelsen
For å vurdere diarisasjonsytelsen til WhisperX-modellen i ulike scenarier, valgte vi tre episoder hver fra to engelske titler: en dramatittel bestående av 30-minutters episoder, og en dokumentartittel bestående av 45-minutters episoder. Vi brukte Pyannotes metrikkverktøysett, pyannote.metrics, for å beregne diarisasjonsfeilrate (DER). I evalueringen fungerte manuelt transkriberte og diariserte transkripsjoner levert av ZOO som grunnsannheten.
Vi definerte DER som følger:

Totalt er lengden på jordsannhetsvideoen. FA (False Alarm) er lengden på segmenter som anses som tale i spådommer, men ikke i grunnsannhet. Miss er lengden på segmenter som anses som tale i grunnsannhet, men ikke i prediksjon. Feil, Også kalt Forvirring, er lengden på segmenter som er tildelt forskjellige høyttalere i prediksjon og grunnsannhet. Alle enhetene måles i sekunder. De typiske verdiene for DER kan variere avhengig av den spesifikke applikasjonen, datasettet og kvaliteten på diariseringssystemet. Merk at DER kan være større enn 1.0. En lavere DER er bedre.
For å kunne beregne DER for et stykke medie, kreves en grunnsannhetsdiarisering samt WhisperX-transkriberte og diariserte utdata. Disse må analyseres og resultere i lister over tupler som inneholder en høyttaleretikett, talesegmentstarttid og talesegmentsluttid for hvert talesegment i media. Høyttaleretikettene trenger ikke samsvare mellom WhisperX- og jordsannhetsdiarisene. Resultatene er hovedsakelig basert på tidspunktet for segmentene. pyannote.metrics tar disse tuplene av grunnsannhetsdiarisasjoner og utdatadiarisasjoner (referert til i pyannote.metrics-dokumentasjonen som referanse og hypotese) for å beregne DER. Tabellen nedenfor oppsummerer resultatene våre.
| Videotype | DER | Riktig | Miss | Feil | Falsk alarm |
| Drama | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| Dokumentar | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| Gjennomsnitt | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
Disse resultatene avslører en betydelig ytelsesforskjell mellom drama- og dokumentartitlene, med modellen som oppnår betydelig bedre resultater (ved å bruke DER som en samlet beregning) for dramaepisodene sammenlignet med dokumentartittelen. En nærmere analyse av titlene gir innsikt i potensielle faktorer som bidrar til dette ytelsesgapet. En nøkkelfaktor kan være den hyppige tilstedeværelsen av bakgrunnsmusikk som overlapper med tale i dokumentartittelen. Selv om forbehandling av media for å forbedre diarisasjonsnøyaktigheten, for eksempel fjerning av bakgrunnsstøy for å isolere tale, var utenfor omfanget av denne prototypen, åpner det veier for fremtidig arbeid som potensielt kan forbedre ytelsen til WhisperX.
konklusjonen
I dette innlegget utforsket vi samarbeidspartnerskapet mellom AWS og ZOO Digital, ved å bruke maskinlæringsteknikker med SageMaker og WhisperX-modellen for å forbedre arbeidsflyten for diarisering. AWS-teamet spilte en sentral rolle i å hjelpe ZOO med å lage prototyper, evaluere og forstå den effektive distribusjonen av tilpassede ML-modeller, spesielt designet for diarisering. Dette inkluderte å inkludere automatisk skalering for skalerbarhet ved bruk av SageMaker.
Utnyttelse av AI for diarisering vil føre til betydelige besparelser i både kostnader og tid ved generering av lokalisert innhold for ZOO. Ved å hjelpe transkriberere med å raskt og presist opprette og identifisere høyttalere, adresserer denne teknologien oppgavens tradisjonelt tidkrevende og feilutsatte natur. Den konvensjonelle prosessen involverer ofte flere gjennomganger gjennom videoen og ytterligere kvalitetskontrolltrinn for å minimere feil. Bruken av AI for diarisering muliggjør en mer målrettet og effektiv tilnærming, og øker dermed produktiviteten innen en kortere tidsramme.
Vi har skissert nøkkeltrinn for å distribuere WhisperX-modellen på SageMaker asynkrone endepunkt, og oppfordrer deg til å prøve det selv ved å bruke den medfølgende koden. For ytterligere innsikt i ZOO Digitals tjenester og teknologi, besøk ZOO Digital sin offisielle side. For detaljer om distribusjon av OpenAI Whisper-modellen på SageMaker og ulike slutningsalternativer, se Vær vert for Whisper-modellen på Amazon SageMaker: utforsk slutningsalternativer. Del gjerne tankene dine i kommentarene.
Om forfatterne
 Ying Hou, PhD, er Machine Learning Prototyping Architect ved AWS. Hennes primære interesseområder omfatter Deep Learning, med fokus på GenAI, Computer Vision, NLP og tidsseriedataprediksjon. På fritiden liker hun å tilbringe gode øyeblikk med familien, fordype seg i romaner og gå på fotturer i nasjonalparkene i Storbritannia.
Ying Hou, PhD, er Machine Learning Prototyping Architect ved AWS. Hennes primære interesseområder omfatter Deep Learning, med fokus på GenAI, Computer Vision, NLP og tidsseriedataprediksjon. På fritiden liker hun å tilbringe gode øyeblikk med familien, fordype seg i romaner og gå på fotturer i nasjonalparkene i Storbritannia.
 Ethan Cumberland er AI-forskningsingeniør ved ZOO Digital, hvor han jobber med å bruke AI og maskinlæring som hjelpeteknologier for å forbedre arbeidsflyter innen tale, språk og lokalisering. Han har bakgrunn fra programvareteknikk og forskning innen sikkerhets- og politidomenet, med fokus på å trekke ut strukturert informasjon fra nettet og utnytte ML-modeller med åpen kildekode for å analysere og berike innsamlede data.
Ethan Cumberland er AI-forskningsingeniør ved ZOO Digital, hvor han jobber med å bruke AI og maskinlæring som hjelpeteknologier for å forbedre arbeidsflyter innen tale, språk og lokalisering. Han har bakgrunn fra programvareteknikk og forskning innen sikkerhets- og politidomenet, med fokus på å trekke ut strukturert informasjon fra nettet og utnytte ML-modeller med åpen kildekode for å analysere og berike innsamlede data.
 Gaurav Kaila leder AWS Prototyping-teamet for Storbritannia og Irland. Teamet hans jobber med kunder på tvers av ulike bransjer for å ide og samutvikle forretningskritiske arbeidsbelastninger med et mandat til å akselerere innføringen av AWS-tjenester.
Gaurav Kaila leder AWS Prototyping-teamet for Storbritannia og Irland. Teamet hans jobber med kunder på tvers av ulike bransjer for å ide og samutvikle forretningskritiske arbeidsbelastninger med et mandat til å akselerere innføringen av AWS-tjenester.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 000
- 1
- 10
- 100
- 11
- 2%
- 2022
- 220
- 28
- 30
- 350
- 7
- 8
- a
- I stand
- akselerere
- akseptere
- adgang
- tilgjengelig
- nøyaktighet
- Oppnå
- oppnå
- tvers
- tilpasse
- Ytterligere
- I tillegg
- adresser
- Adopsjon
- Etter
- aggregat
- avtaler
- AI
- ai forskning
- sikte
- mål
- alarm
- justere
- justering
- innretting
- Alle
- tillater
- alene
- sammen
- også
- Selv
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- analysere
- analyse
- og
- En annen
- Søknad
- tilnærming
- hensiktsmessig
- arkitektur
- ER
- områder
- Artister
- AS
- vurdere
- Eiendeler
- tildelt
- bistå
- bistå
- At
- lyd
- autorisert
- auto
- Automatisering
- veier
- AWS
- bakgrunn
- basert
- BE
- fordi
- vært
- før du
- være
- BEST
- Bedre
- mellom
- Beyond
- Biggest
- BIN
- både
- bygget
- virksomhet
- men
- by
- bytes
- beregne
- som heter
- CAN
- saken
- utfordre
- tegn
- Velg
- nærmere
- kode
- samarbeid
- samarbeids
- samlet
- kommentarer
- sammenlignet
- Terminado
- samsvar
- komponent
- komponenter
- forsterket
- komprimere
- datamaskin
- Datamaskin syn
- gjennomført
- konfigurert
- konfigurering
- Vurder
- ansett
- Består
- Container
- inneholder
- inneholder
- innhold
- innholdsskapere
- medvirkende
- kontroll
- konvensjonell
- Kjerne
- riktig
- Kostnad
- Kostnader
- kunne
- prosessor
- skape
- opprettet
- Opprette
- skaperne
- kritisk
- kulturer
- skikk
- Kunder
- dato
- dyp
- dyp læring
- def
- definert
- levere
- leverer
- dybden
- Etterspørsel
- avhengig
- utplassere
- utplassert
- utplasserings
- distribusjon
- designet
- detaljer
- oppdaget
- utviklere
- enhet
- diagram
- DIKT
- forskjell
- forskjellig
- digitalt
- Bokstaver
- direkte
- kataloger
- katalog
- diskutere
- diverse
- Docker
- dokumentar
- dokumentasjon
- domene
- ikke
- nedlasting
- Nedlasting
- Drama
- dubbet
- under
- hver enkelt
- enklere
- økonomisk
- Effektiv
- effektiv
- effektivt
- elementer
- ellers
- embedding
- ansette
- muliggjør
- omfatte
- oppmuntre
- slutt
- ende til ende
- Endpoint
- endepunkter
- engasjert
- engasjement
- ingeniør
- Ingeniørarbeid
- Engelsk
- forbedre
- berikende
- sikre
- sikrer
- bedriftsnivå
- Entertainment
- episode
- Episoder
- feil
- feil
- avgjørende
- Eter (ETH)
- evaluere
- evaluert
- evaluere
- evaluering
- Event
- Hver
- eksempel
- Øvelse
- eksperimenter
- utforsket
- Utforske
- Face
- ansikter
- faktor
- faktorer
- falsk
- familie
- raskere
- Egenskaper
- føler
- Hentet
- filet
- Filer
- fleksibilitet
- Fokus
- fokuserte
- fokusering
- etter
- følger
- Til
- tvang
- formater
- fire
- Rammeverk
- Gratis
- hyppig
- fra
- fullt
- funksjon
- funksjonelle
- funksjoner
- videre
- framtid
- mellomrom
- genai
- generert
- genererer
- få
- GitHub
- globalisering
- mål
- GPU
- Ground
- hands-on
- maskinvare
- he
- her
- høykvalitets
- vandreturer
- hans
- vert
- Hosting
- TIMER
- Hvordan
- Men
- HTML
- http
- HTTPS
- Klem ansikt
- identifisering
- Identitet
- if
- illustrerer
- bilde
- importere
- forbedre
- forbedret
- in
- inkludert
- inkluderer
- Inkludert
- innlemme
- innlemme
- økende
- bransjer
- informasjon
- initiering
- innsikt
- installerte
- instruksjoner
- intensiv
- interesse
- inn
- Introduserer
- investering
- påkalt
- innebærer
- Irland
- IT
- DET ER
- jpg
- JSON
- nøkkel
- nøkkelfaktor
- Etiketten
- etiketter
- mangler
- Språk
- språk
- stor
- større
- føre
- Fører
- læring
- Lengde
- utnytte
- Bibliotek
- linjer
- Liste
- lister
- laste
- lasting
- lokal
- Lokalisering
- lokalt
- steder
- logg
- logging
- Lang
- lavere
- maskin
- maskinlæring
- Maskinlæringsteknikker
- vedlikehold
- GJØR AT
- ledelse
- Mandat
- håndbok
- manuelt
- Match
- Kan..
- målte
- Media
- metadata
- metoder
- metrisk
- Metrics
- millioner
- minimere
- minutter
- Minske
- ML
- modell
- modeller
- modulære
- moduler
- Moments
- mer
- for det meste
- film
- Filmer
- flere
- musikk
- må
- navn
- navn
- nasjonal
- nasjonalparker
- Natur
- nødvendig
- Trenger
- nødvendig
- Ny
- nlp
- Bråk
- spesielt
- note
- innhentet
- of
- tilby
- tilby
- offisiell
- ofte
- on
- ONE
- åpen kildekode
- OpenAI
- åpner
- drift
- alternativer
- or
- original
- OS
- Annen
- vår
- ut
- omriss
- skissert
- produksjon
- utganger
- enn
- pakker
- parker
- del
- spesielt
- Partnerskap
- bestått
- passerer
- banen
- baner
- mønstre
- Ansatte
- utføre
- ytelse
- utført
- utfører
- brikke
- rørledning
- sentral
- plato
- Platon Data Intelligence
- PlatonData
- Spille
- spilt
- politi
- Post
- potensiell
- potensielt
- nettopp
- prediksjon
- Spådommer
- tilstedeværelse
- presentere
- forrige
- primære
- prosess
- Prosesser
- prosessering
- Produkt
- Produksjon
- produktivitet
- program
- prototype
- prototyping
- gi
- forutsatt
- gir
- gi
- Python
- kvalitet
- R
- Sats
- Lese
- ekte
- sanntids
- anbefaler
- referere
- referert
- region
- regioner
- husker
- fjerne
- erstatte
- representerer
- anmode
- Forespurt
- krever
- påkrevd
- Krav
- forskning
- de
- resultere
- resulterende
- Resultater
- retur
- avkastning
- avsløre
- Rolle
- Kjør
- rennende
- runtime
- s
- sagemaker
- sample
- Spar
- lagret
- Besparelser
- skalerbarhet
- skalerbar
- Skala
- skalering
- scenarier
- omfang
- script
- sekunder
- seksjoner
- sikkerhet
- segmentet
- segmentering
- segmenter
- valgt
- velge
- Serien
- servert
- Tjenester
- servering
- innstillinger
- Del
- hun
- bør
- signifikant
- Enkelt
- SIX
- Størrelse
- størrelser
- dyktig
- liten
- glatter
- So
- Software
- software engineering
- løsning
- kilde
- Høyttaler
- høyttalere
- spesifikk
- spesielt
- spesifisert
- tale
- utgifter
- pigger
- Begynn
- startet
- Trinn
- Steps
- lagring
- lagret
- Story
- stream
- effektivisere
- strukturert
- I ettertid
- betydelig
- slik
- egnet
- levere
- støtte
- Støtte
- byttet
- raskt
- synkronisering
- system
- bord
- Ta
- tar
- målrettet
- Oppgave
- lag
- teknikker
- Technologies
- Teknologi
- midlertidig
- tekst
- enn
- Det
- De
- Fremtiden
- sikkerheten
- Storbritannia
- deres
- Dem
- deretter
- derved
- Disse
- de
- denne
- De
- tre
- Gjennom
- tid
- Tidsserier
- tidkrevende
- tidsramme
- ganger
- tidsstempel
- timings
- Tittel
- titler
- til
- token
- tok
- verktøykasse
- lommelykt
- tradisjonelt
- trafikk
- Kurs
- gjennomsiktig
- utløse
- utløsende
- klarert
- Sannhet
- prøve
- tutorial
- tv
- TV-serie
- to
- typisk
- Uk
- etter
- under 30
- forståelse
- lomper
- Oppdater
- upon
- bruke
- bruk sak
- brukt
- Bruker
- bruker
- ved hjelp av
- benyttes
- bruker
- Verdier
- ulike
- variere
- versjon
- versjoner
- levedyktig
- video
- syn
- Besøk
- Voice
- W
- var
- we
- web
- webtjenester
- VI VIL
- når
- mens
- Hviske
- vil
- med
- innenfor
- uten
- ord
- Arbeid
- arbeidsflyt
- arbeidsflyt
- arbeidsstyrke
- virker
- Verdens
- skriving
- yaml
- du
- Din
- deg selv
- zephyrnet
- ZOO