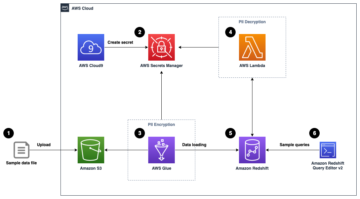
Organizacje wykorzystują swoje dane do rozwiązywania złożonych problemów, rozpoczynając małe, przeprowadzając iteracyjne eksperymenty i udoskonalając rozwiązanie. Chociaż nie można ignorować potęgi eksperymentów, organizacje muszą być ostrożne, jeśli chodzi o opłacalność takich eksperymentów. Poświęcanie czasu na tworzenie podstawowej infrastruktury umożliwiającej eksperymenty dodatkowo zwiększa koszty.
Deweloperzy potrzebują zintegrowanego środowiska programistycznego (IDE) do eksploracji danych i debugowania przepływów pracy oraz różnych profili obliczeniowych do uruchamiania tych przepływów pracy. Jeśli wybierzesz Amazon EMR w takich przypadkach możesz użyć IDE o nazwie Studio Amazon EMR do eksploracji danych, transformacji, kontroli wersji i debugowania oraz uruchamiania zadań platformy Spark w celu przetwarzania dużych ilości danych. Wdrażanie Amazon EMR na Amazon EKS upraszcza zarządzanie, zmniejsza koszty i poprawia wydajność. Jednak inżynier danych lub administrator IT musi poświęcić czas na tworzenie podstawowej infrastruktury, konfigurowanie zabezpieczeń i tworzenie zarządzanego punktu końcowego, z którym użytkownicy mogą się łączyć. Oznacza to, że takie projekty muszą czekać, aż ci eksperci stworzą infrastrukturę.
W tym poście pokazujemy, jak inżynier danych lub administrator IT może wykorzystać Architektura referencyjna AWS Analytics (ARA), aby przyspieszyć wdrażanie infrastruktury, oszczędzając w organizacji zarówno czas, jak i pieniądze wydane na te eksperymenty z analizą danych. Używamy biblioteki do wdrożenia Amazon Elastic Kubernetes (Amazon EKS), skonfiguruj go do korzystania z Amazon EMR na EKS i wdróż wirtualny klaster i zarządzanymi punktami końcowymi oraz EMR Studio. Następnie można uruchamiać zadania w klastrze wirtualnym lub przeprowadzać eksploracyjną analizę danych za pomocą Zeszyty Jupyter w Amazon EMR Studio i Amazon EMR w EKS. Poniższa architektura przedstawia infrastrukturę, którą wdrożysz za pomocą architektury referencyjnej AWS Analytics.

Wymagania wstępne
Aby śledzić dalej, musisz mieć konto AWS, które jest ładowane za pomocą Zestaw programistyczny AWS Cloud (CDK AWS). Aby uzyskać instrukcje, patrz Bootstrapping. Poniższy samouczek używa języka TypeScript i wymaga wersji 2 lub nowszej zestawu AWS CDK. Jeśli nie masz zainstalowanego AWS CDK, zobacz Zainstaluj CDK AWS.
Skonfiguruj projekt AWS CDK
Aby wdrożyć zasoby przy użyciu ARA, musisz najpierw skonfigurować projekt AWS CDK i zainstalować bibliotekę ARA. Wykonaj następujące kroki:
- Utwórz folder o nazwie emr-eks-app:
- Zainicjuj projekt AWS CDK w pustym katalogu i uruchom następujące polecenie:
- Zainstaluj bibliotekę ARA:
- W pliku lib/emr-eks-app.ts zaimportuj bibliotekę ARA w następujący sposób. Pierwsza linia wywołuje bibliotekę ARA, druga definiuje polityki AWS Identity and Access Management (IAM):
Utwórz i zdefiniuj klaster EKS oraz moc obliczeniową
Aby utworzyć EMR na EKS wirtualny klaster, musisz najpierw wdrożyć klaster EKS. Biblioteka ARA definiuje konstrukcję o nazwie EmrEksCluster. Konstrukcja udostępnia klaster EKS, umożliwia Role uprawnień dla kont usługii wdraża zestaw kontrolerów pomocniczych, takich jak kontroler menedżera certyfikatów (potrzebny przez zarządzany punkt końcowy używany przez Amazon EMR Studio), a także automatyczny skaler klastra, aby mieć elastyczny klaster i oszczędzać koszty, gdy żadne zadanie nie jest przesyłane do klastra .
In lib/emr-eks-app.ts, dodaj następujący wiersz:
Aby dowiedzieć się więcej o właściwościach, które można dostosować, zobacz EmrEksClusterProps. Istnieją dwa obowiązkowe parametry w EmrEksCluster konstrukcja: Pierwsza to eksAdminRoleArn rola jest obowiązkowa i jest rolą używaną do interakcji z platformą kontrolną Kubernetes. Ta rola musi mieć uprawnienia administracyjne do utworzyć lub zaktualizować klaster. Drugi parametr to autoscaling, ten parametr umożliwia wybór mechanizmu autoskalowania Stolarz or natywny autoskaler klastra Kubernetes. Na tym blogu będziemy używać Karpentera i zalecamy jego użycie ze względu na szybsze autoskalowanie, uproszczone zarządzanie węzłami i udostępnianie. Teraz możesz przystąpić do definiowania mocy obliczeniowej.
Jednym ze sposobów definiowania węzłów procesu roboczego w Amazon EKS jest użycie zarządzanych grup węzłów. Używamy jednej grupy węzłów o nazwie tooling, w którym odbywa się rdzenie, kontroler wejścia, menedżer certyfikatów, Stolarz i wszelkie inne pod, które są niezbędne do działania EMR w zadaniach EKS lub ManagedEndpoint. Definiujemy również domyślne Karpenter Zaopatrzenie które definiują pojemność, która ma być wykorzystana do zadań przesłanych przez EMR na EKS. Ci dostawcy są zoptymalizowani pod kątem różnych przypadków użycia platformy Spark (zadania krytyczne, zadania niekrytyczne, eksperymenty i sesje interaktywne). Konstrukcja umożliwia również przesłanie własnego dostawcy usług zdefiniowanych przez manifest Kubernetes za pomocą metody o nazwie addKarpenterProvisioner. Omówmy predefiniowane Provisioners.
Domyślne konfiguracje aprowizatorów
Domyślne moduły obsługi administracyjnej są ustawione do szybkiego eksperymentowania i są zawsze tworzony domyślnie. Jeśli jednak nie chcesz ich używać, możesz ustawić defaultNodeGroups parametr false EmrEksCluster właściwości w czasie tworzenia. Dostawcy są zdefiniowani w następujący sposób i są tworzeni w każdej z podsieci używanych przez Amazon EKS:
- Zaopatrzenie krytyczne – Jest przeznaczony do obsługi zadań z agresywnymi umowami SLA i jest wrażliwy na czas. Dostawca korzysta z Instancji On-Demand, które nie są zatrzymywane, w przeciwieństwie do Instancji Spot, a ich cykl życia przebiega przez jedno z zadań. Węzły używają magazynów instancji, które są dyskami NVMe fizycznie podłączonymi do hosta, które oferują wysoką przepływność operacji we/wy, co pozwala na lepszą wydajność platformy Spark, ponieważ jest używany jako tymczasowy magazyn na wypadek wycieku i losowania dysku. Typy instancji używane w węźle należą do rodziny m6gd. Instancje używają Grawiton AWS procesor, który oferuje lepszy stosunek ceny do wydajności niż procesory x86. Aby użyć tego dostawcy w swoich zadaniach, możesz użyć następujących przykładowa konfiguracja, o którym mowa w ww nadpisanie konfiguracji EMR w sprawie składania ofert pracy w EKS.
- Niekrytyczny dostawca usług – Ten dostawca usług wykorzystuje Instancje Spot, aby zaoszczędzić na kosztach zadań, które nie są czasochłonne lub zadań, które są wykorzystywane do eksperymentów. Ten węzeł używa instancji Spot, ponieważ zadania nie są krytyczne i mogą zostać przerwane. Te instancje można zatrzymać, jeśli instancja zostanie odzyskana. Typy instancji używane w węźle należą do rodziny m6gd, sterownik jest typu On-Demand, a executory są instancjami na miejscu.
- Dostawca notebooków – Provisioner służy do uruchamiania zarządzanych punktów końcowych, które są używane przez Amazon EMR Studio do eksploracji danych przy użyciu Amazon EMR na EKS. Instancje należą do rodziny t3 i są dostępne na żądanie dla sterowników i Spot Instances dla wykonawców, aby utrzymać niskie koszty. Jeśli instancje executorów są zatrzymane, nowe są uruchamiane przez Karpentera. Jeśli instancje executorów są zatrzymywane zbyt często, można zdefiniować własne instancje korzystające z instancji On-Demand.
Poniższy link zawiera więcej szczegółów na temat sposobu definiowania każdego dostawcy usług. Jedna właściwość importu zdefiniowana w domyślnych aprowizatorach to jedna dla każdego AZ. Jest to ważne, ponieważ pozwala obniżyć koszty transferu sieci między AZ, gdy Spark uruchamia losowanie.
W tym poście używamy domyślnych dostawców, więc nie musisz dodawać żadnych wierszy kodu dla tej sekcji. Jeśli chcesz dodać własnych Provisioners, możesz skorzystać z tej metody addKarpenterProvisioner zastosować własne manifesty. Możesz użyć metod pomocniczych w Utils klasa jak readYamlDocument czytać dokument YAML i loadYaml załaduj pliki YAML i przekaż je jako argumenty do addKarpenterProvisioner Metoda.
Wdróż klaster wirtualny i rolę wykonawczą
Klaster wirtualny to przestrzeń nazw Kubernetes, w której zarejestrowany jest Amazon EMR; kiedy przesyłasz zadanie, moduły sterownika i modułu wykonawczego są uruchomione w powiązanej przestrzeni nazw. The EmrEksCluster konstrukcja oferuje metodę o nazwie addEmrVirtualCluster, który tworzy dla Ciebie wirtualny klaster. Metoda trwa EmrVirtualClusterOptions jako parametr, który ma następujące atrybuty:
- Nazwa – Nazwa wirtualnego klastra.
- utwórzPrzestrzeńNazw – Opcjonalne pole, które tworzy przestrzeń nazw EKS. Jest to typ Boolean i domyślnie nie tworzy oddzielnej przestrzeni nazw EKS, więc wirtualny klaster jest tworzony w domyślnej przestrzeni nazw.
- eksPrzestrzeń nazw – Nazwa przestrzeni nazw EKS, która ma zostać połączona z wirtualnym klastrem EMR. Jeśli nie podano żadnej przestrzeni nazw, konstrukcja używa domyślnej przestrzeni nazw.
- In
lib/emr-eks-app.ts, dodaj następujący wiersz, aby utworzyć wirtualny klaster:Teraz tworzymy rolę wykonawczą, która jest rolą IAM używaną przez sterownik i wykonawcę do interakcji z usługami AWS. Zanim będziemy mogli utworzyć rolę wykonawczą dla Amazon EMR, musimy najpierw utworzyć plik
ManagedPolicy. Zauważ, że w poniższym kodzie tworzymy zasady zezwalające na dostęp do zasobnika Amazon Simple Storage Service (Amazon S3) i dzienników Amazon CloudWatch. - In
lib/emr-eks-app.ts, dodaj następujący wiersz, aby utworzyć zasady:Jeśli chcesz korzystać z AWS Glue Data Catalog, dodaj jego uprawnienie w poprzedniej polityce.
Teraz tworzymy rolę wykonawczą dla Amazon EMR na EKS przy użyciu polityki zdefiniowanej w poprzednim kroku przy użyciu
createExecutionRolemetoda instancji. Pody sterownika i executora mogą następnie przyjąć tę rolę, aby uzyskać dostęp do danych i je przetwarzać. Rola jest określona w taki sposób, że mogą ją przyjąć tylko zasobniki w przestrzeni nazw klastra wirtualnego. Aby dowiedzieć się więcej o warunku zaimplementowanym przez tę metodę w celu ograniczenia dostępu do roli tylko do zasobników utworzonych przez Amazon EMR na EKS w przestrzeni nazw klastra wirtualnego, zobacz Używanie ról wykonywania zadań z Amazon EMR na EKS. - In
lib/emr-eks-app.ts, dodaj następujący wiersz, aby utworzyć rolę wykonawczą:Powyższy kod tworzy rolę IAM o nazwie
execRoleJobz polityką IAM zdefiniowaną wemrekspolicyi ograniczony do przestrzeni nazwdataanalysis. - Na koniec wyprowadzamy parametry, które są ważne dla przebiegu zadania:
Wdróż Amazon EMR Studio i udostępnij użytkownikom
Aby wdrożyć EMR Studio do eksploracji danych i tworzenia zadań, biblioteka ARA ma konstrukcję o nazwie NotebookPlatform. Ta konstrukcja umożliwia wdrożenie dowolnej liczby EMR Studios (w ramach limitu konta) i skonfigurowanie ich z odpowiednim trybem uwierzytelniania oraz przypisanie do nich użytkowników. Aby dowiedzieć się więcej o trybach uwierzytelniania dostępnych w Amazon EMR Studio, zobacz Wybierz tryb uwierzytelniania dla Amazon EMR Studio.
Konstrukcja tworzy wszystkie niezbędne role i zasady IAM wymagane przez Amazon EMR Studio. Tworzy również wiadro S3, w którym wszystkie notebooki są przechowywane przez Amazon EMR Studio. Wiadro jest zaszyfrowane za pomocą a klucz zarządzany przez klienta (CMK) wygenerowany przez stos AWS CDK. Poniższe kroki pokazują, jak utworzyć własne studio EMR za pomocą konstrukcji.
Konstrukcja platformy notebooka trwa NotebookPlatformProps jako właściwość, która pozwala zdefiniować EMR Studio, przestrzeń nazw, nazwę EMR Studio i jego tryb uwierzytelniania.
- In
lib/emr-eks-app.ts, dodaj następujący wiersz:W tym poście używamy użytkowników IAM, abyś mógł łatwo odtworzyć go na swoim koncie. Jeśli jednak masz już federację IAM lub jednokrotne logowanie (SSO), możesz ich używać zamiast użytkowników IAM. Aby dowiedzieć się więcej o parametrach
NotebookPlatformProps, odnosić się do NotatnikPlatformaRekwizyty.Następnie musimy utworzyć i przypisać użytkowników do Amazon EMR Studio. W tym celu konstrukcja ma metodę o nazwie
addUserktóry pobiera listę użytkowników i albo przypisuje ich do Amazon EMR Studio w przypadku SSO, albo aktualizuje zasady IAM, aby umożliwić dostęp do Amazon EMR Studio dla określonych użytkowników IAM. Użytkownik może również mieć wiele zarządzanych punktów końcowych, a każdy użytkownik może mieć zdefiniowaną wersję Amazon EMR. Mogą korzystać z innego zestawu instancji Amazon Elastic Compute Cloud (Amazon EC2) i różnych uprawnień przy użyciu ról wykonywania zadań. - In
lib/emr-eks-app.ts, dodaj następujący wiersz:W powyższym kodzie, ze względu na zwięzłość, ponownie używamy tej samej zasady IAM, którą utworzyliśmy w roli wykonawczej.
Należy zauważyć, że konstrukcja optymalizuje liczbę tworzonych zarządzanych punktów końcowych. Jeśli dwa punkty końcowe mają taką samą nazwę, tworzony jest tylko jeden.
- Teraz, gdy zdefiniowaliśmy nasze wdrożenie, możemy je wdrożyć:
Przykładowy projekt, który zawiera wszystkie kroki przewodnika, można znaleźć w następującym serwisie GitHub składnica.
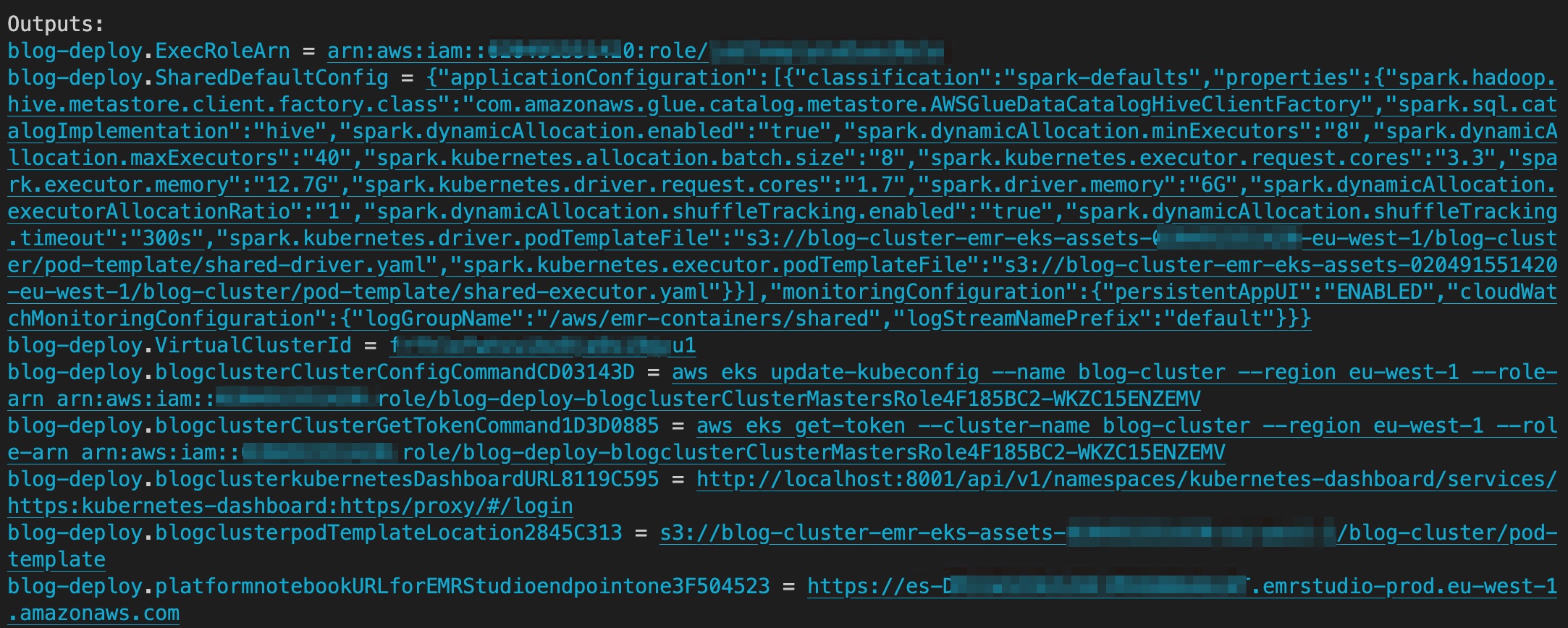
Po zakończeniu wdrażania dane wyjściowe zawierają zasobnik S3 zawierający zasoby dla podTemplate, link do EMR Studio i identyfikator wirtualnego klastra EMR Studio. Poniższy zrzut ekranu przedstawia dane wyjściowe AWS CDK po zakończeniu wdrażania.
Prześlij oferty pracy

Ponieważ używamy domyślnych aprowizatorów, użyjemy podTemplate która jest zdefiniowana przez konstrukcję dostępną w pliku Repozytorium ARA GitHub. Są one przesyłane przez konstrukcję do zasobnika S3 o nazwie <clustername>-emr-eks-assets; wystarczy, że odniesiesz się do nich w swojej pracy w Spark. W tym zadaniu używasz również parametrów zadania w danych wyjściowych na końcu wdrożenia AWS CDK. Te parametry umożliwiają korzystanie z AWS Glue Data Catalog i wdrażanie najlepszych praktyk Spark na Kubernetes, takich jak dynamicAllocation i kolokacja strąków. Na końcu cdk deploy ARA wyświetli przykładowe konfiguracje zadań z wymienionymi wcześniej najlepszymi praktykami, których można użyć do przesłania pracy. Możesz przesłać pracę w następujący sposób.
Uruchomienie zadania to jednostka pracy, taka jak plik Spark JAR, która jest przesyłana do EMR w klastrze EKS. Rozpoczynamy pracę za pomocą start-job-run Komenda. Uwaga, której możesz użyć SparkSubmitParameters aby określić ścieżkę Amazon S3 do szablonu pod, jak pokazano w następującym poleceniu:
Kod przyjmuje następujące wartości:
- – Identyfikator wirtualnego klastra EMR
- – Nazwa Twojej pracy w Spark
- – Rola wykonawcza, którą utworzyłeś
- – Identyfikator URI Amazon S3 Twojej pracy w Spark
- – Identyfikator URI Amazon S3 szablonu sterownika, który można uzyskać z danych wyjściowych AWS CDK
- – Identyfikator URI Amazon S3 szablonu executora
- – Twoja nazwa grupy dzienników CloudWatch
- – Twój prefiks strumienia dziennika CloudWatch
Możesz przejść do konsoli Amazon EMR, aby sprawdzić status swojego zadania i przejrzeć dzienniki. Stan można również sprawdzić, uruchamiając plik describe-job-run polecenie:
Eksploruj dane za pomocą Amazon EMR Studio
W tej sekcji pokazujemy, jak utworzyć obszar roboczy w Amazon EMR Studio i połączyć się z punktem końcowym zarządzanym przez Amazon EKS z obszaru roboczego. W danych wyjściowych użyj łącza do Amazon EMR Studio, aby przejść do wdrożenia EMR Studio. Musisz zalogować się w IAM nazwa użytkownika podałeś w addUser Metoda.
Utwórz obszar roboczy
Aby utworzyć obszar roboczy, wykonaj następujące kroki:
- Zaloguj się do EMR Studio utworzonego przez AWS CDK.
- Dodaj Utwórz obszar roboczy.
- Wprowadź nazwę obszaru roboczego i opcjonalny opis.
- Wybierz Dopuszczać Współpraca w obszarze roboczym jeśli chcesz pracować z innymi użytkownikami Studio w tym obszarze roboczym w czasie rzeczywistym.
- Dodaj Utwórz obszar roboczy.

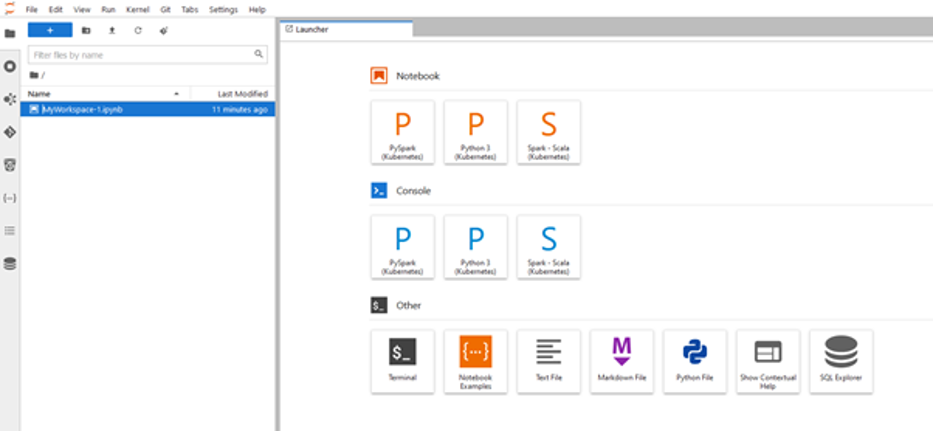
Po utworzeniu obszaru roboczego wybierz go z listy obszarów roboczych, aby otworzyć środowisko JupyterLab.
Poniższy zrzut ekranu pokazuje, jak wygląda terminal. Aby uzyskać więcej informacji na temat interfejsu użytkownika, patrz Zapoznaj się z interfejsem użytkownika Workspace.
Połącz się z EMR na zarządzanym punkcie końcowym EKS
Możesz łatwo połączyć się z EMR na zarządzanym punkcie końcowym EKS z obszaru roboczego.
- W okienku nawigacji na Klastry Menu, wybierz Klaster EMR na EKS dla Typ klastra.
Klastry wirtualne pojawiają się w menu rozwijanym EMR Cluster on EKS, a punkt końcowy pojawia się w menu rozwijanym Endpoint. Jeśli istnieje wiele punktów końcowych, pojawiają się one tutaj i można łatwo przełączać się między punktami końcowymi z obszaru roboczego. - Wybierz odpowiedni punkt końcowy i wybierz opcję Dołącz.

Pracuj z notatnikiem
Możesz teraz otworzyć notatnik i połączyć się z preferowanym jądrem, aby wykonać swoje zadania. Na przykład możesz wybrać jądro PySpark, jak pokazano na poniższym zrzucie ekranu.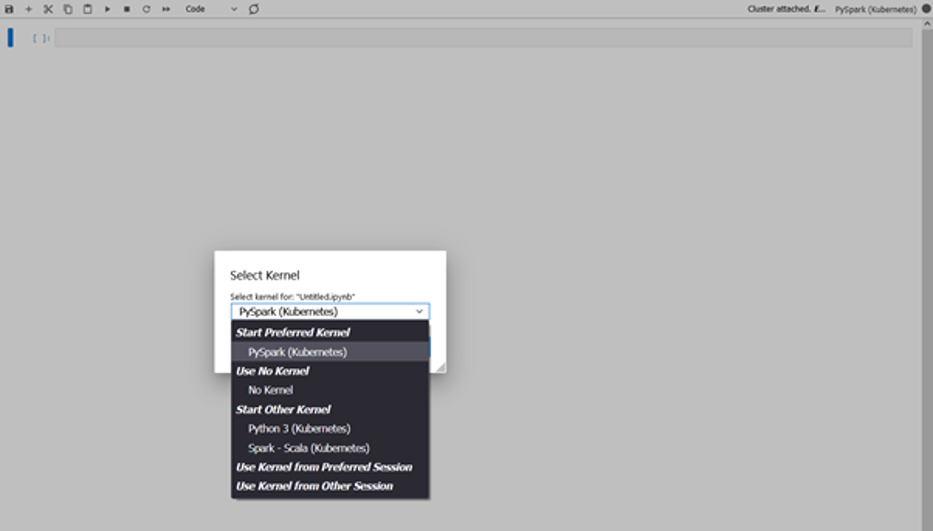
Eksploruj swoje dane
Pierwszym krokiem naszego ćwiczenia eksploracji danych jest utworzenie sesji Spark, a następnie załadowanie zestawu danych taksówek w Nowym Jorku z wiadra S3 do ramka danych. Użyj następującego bloku kodu, aby załadować dane do ramki danych. Skopiuj identyfikator URI Amazon S3 dla lokalizacji, w której znajduje się zestaw danych w Amazon S3.
Po załadowaniu danych do ramki danych zastępujemy dane current_date kolumnę z rzeczywistą bieżącą datą, policz liczbę wierszy i zapisz dane w pliku Parquet:
Poniższy zrzut ekranu pokazuje wynik naszego notebooka działającego w Amazon EMR Studio oraz z PySpark działającym w Amazon EMR na EKS.
Sprzątać
Aby posprzątać po tym poście, biegnij cdk destroy.
Wnioski
W tym poście pokazaliśmy, jak można wykorzystać ARA do szybkiego wdrożenia infrastruktury analizy danych i rozpoczęcia eksperymentowania z danymi. Pełny przykład, do którego odwołuje się ten post, można znaleźć w pliku Repozytorium GitHub. Architektura referencyjna AWS Analytics implementuje typowe wzorce Analytics i najlepsze praktyki AWS, oferując gotowe do użycia konstrukcje do eksperymentów. Jednym ze wzorców jest siatka danych, z którą możesz zapoznać się, jak w tym celu wykorzystać blogu.
Możesz także odkrywać inne konstrukcje oferowane w tej bibliotece eksperymentować z usługami AWS Analytics przed przeniesieniem obciążenia do produkcji.
O autorach
 Lotfiego Mouhiba jest starszym architektem rozwiązań pracującym dla zespołu sektora publicznego w Amazon Web Services. Pomaga klientom z sektora publicznego w regionie EMEA realizować ich pomysły, tworzyć nowe usługi i wprowadzać innowacje dla obywateli. W wolnym czasie Lotfi lubi jeździć na rowerze i biegać.
Lotfiego Mouhiba jest starszym architektem rozwiązań pracującym dla zespołu sektora publicznego w Amazon Web Services. Pomaga klientom z sektora publicznego w regionie EMEA realizować ich pomysły, tworzyć nowe usługi i wprowadzać innowacje dla obywateli. W wolnym czasie Lotfi lubi jeździć na rowerze i biegać.
 Sandipana Bhaumika jest starszym architektem ds. rozwiązań analitycznych z siedzibą w Londynie. Pracował z klientami z różnych branż, takich jak bankowość i usługi finansowe, opieka zdrowotna, energetyka, produkcja i handel detaliczny, pomagając im rozwiązywać złożone wyzwania za pomocą platform danych na dużą skalę. W AWS koncentruje się na strategicznych klientach w Wielkiej Brytanii i Irlandii oraz pomaga klientom przyspieszyć ich podróż do chmury i wprowadzać innowacje za pomocą usług analitycznych i uczenia maszynowego AWS. Uwielbia grać w badmintona i czytać książki.
Sandipana Bhaumika jest starszym architektem ds. rozwiązań analitycznych z siedzibą w Londynie. Pracował z klientami z różnych branż, takich jak bankowość i usługi finansowe, opieka zdrowotna, energetyka, produkcja i handel detaliczny, pomagając im rozwiązywać złożone wyzwania za pomocą platform danych na dużą skalę. W AWS koncentruje się na strategicznych klientach w Wielkiej Brytanii i Irlandii oraz pomaga klientom przyspieszyć ich podróż do chmury i wprowadzać innowacje za pomocą usług analitycznych i uczenia maszynowego AWS. Uwielbia grać w badmintona i czytać książki.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/accelerate-your-data-exploration-and-experimentation-with-the-aws-analytics-reference-architecture-library/
- 1
- 10
- 100
- 11
- 6G
- 7
- 9
- a
- O nas
- przyśpieszyć
- dostęp
- zarządzanie dostępem
- Konto
- Konta
- w poprzek
- działania
- Dodaje
- administracyjny
- Po
- agresywny
- Wszystkie kategorie
- przydział
- pozwala
- już
- Chociaż
- Amazonka
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- analiza
- analityka
- i
- Apache
- Aplikacja
- zjawić się
- Aplikuj
- właściwy
- architektura
- argumenty
- Aktywa
- powiązany
- dołączać
- atrybuty
- Uwierzytelnianie
- autoring
- samochód
- dostępny
- AWS
- Klej AWS
- Zarządzanie tożsamością i dostępem AWS (IAM)
- Bankowość
- na podstawie
- bo
- zanim
- poniżej
- BEST
- Najlepsze praktyki
- Ulepsz Swój
- pomiędzy
- Blokować
- Blog
- Książki
- budować
- budowniczy
- nazywa
- Połączenia
- Pojemność
- walizka
- Etui
- katalog
- ostrożny
- CD
- świadectwo
- wyzwania
- ZOBACZ
- Dodaj
- Obywatele
- klasa
- klasyfikacja
- klient
- Chmura
- Grupa
- kod
- Kolumna
- COM
- wspólny
- kompletny
- kompleks
- obliczać
- warunek
- Skontaktuj się
- Konsola
- skonstruować
- zawiera
- kontrola
- kontroler
- Koszty:
- Koszty:
- Stwórz
- stworzony
- tworzy
- Tworzenie
- tworzenie
- krytyczny
- Aktualny
- Klientów
- dostosować
- dane
- analiza danych
- Analityka danych
- inżynier danych
- Data
- data i godzina
- dedykowane
- Domyślnie
- Definiuje
- rozwijać
- wdrażanie
- Wdrożenie
- wdraża się
- opis
- detale
- oprogramowania
- różne
- dyskutować
- dokument
- Nie
- nie
- kierowca
- każdy
- z łatwością
- efekt
- bądź
- EMEA
- włączony
- Umożliwia
- umożliwiając
- szyfrowane
- Punkt końcowy
- inżynier
- Środowisko
- Eter (ETH)
- przykład
- egzekucja
- Ćwiczenie
- eksperyment
- eksperci
- eksploracja
- Analiza danych rozpoznawczych
- odkryj
- fabryka
- członków Twojej rodziny
- szybciej
- Federacja
- pole
- filet
- Akta
- budżetowy
- usługi finansowe
- Znajdź
- i terminów, a
- koncentruje
- obserwuj
- następujący
- następujący sposób
- FRAME
- od
- pełny
- Funkcje
- dalej
- wygenerowane
- otrzymać
- GitHub
- Go
- Zarządzanie
- Grupy
- Hadoop
- opieki zdrowotnej
- pomoc
- pomaga
- tutaj
- Wysoki
- Ul
- gospodarz
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- IAM
- pomysły
- tożsamość
- zarządzanie tożsamością i dostępem
- Zarządzanie tożsamością i dostępem (IAM)
- wdrożenia
- realizowane
- narzędzia
- importować
- ważny
- poprawia
- in
- przemysłowa
- Informacja
- Infrastruktura
- wprowadzać innowacje
- zainstalować
- przykład
- zamiast
- instrukcje
- zintegrowany
- interakcji
- interaktywne
- Interfejs
- przerwane
- Irlandia
- IT
- Praca
- Oferty pracy
- podróż
- json
- Trzymać
- Kubernetes
- duży
- na dużą skalę
- UCZYĆ SIĘ
- nauka
- Dźwignia
- Biblioteka
- LIMIT
- Linia
- linie
- LINK
- powiązany
- Lista
- Katalogowany
- załadować
- lokalizacja
- Londyn
- WYGLĄD
- niski
- maszyna
- uczenie maszynowe
- zarządzane
- i konserwacjami
- kierownik
- obowiązkowe
- produkcja
- wiele
- znaczy
- mechanizm
- Pamięć
- Menu
- metoda
- metody
- Moda
- pieniądze
- jeszcze
- wielokrotność
- Nazwa
- O imieniu
- Nawigacja
- Nawigacja
- niezbędny
- Potrzebować
- potrzebne
- wymagania
- sieć
- Nowości
- I Love New York
- węzeł
- węzły
- notatnik
- laptopy
- numer
- oferta
- oferowany
- Oferty
- ONE
- koncepcja
- zoptymalizowane
- Optymalizuje
- organizacja
- organizacji
- Inne
- własny
- chleb
- parametr
- parametry
- ścieżka
- Wzór
- wzory
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- pozwolenie
- uprawnienia
- Fizycznie
- Miejsce
- Platforma
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- gra
- pods
- polityka
- polityka
- Post
- power
- praktyki
- Korzystny
- poprzedni
- problemy
- wygląda tak
- Procesor
- Produkcja
- profile
- projekt
- projektowanie
- niska zabudowa
- własność
- pod warunkiem,
- zapewnia
- zaopatrzenie
- publiczny
- szybko
- szybki
- Czytaj
- Czytający
- gotowy
- real
- w czasie rzeczywistym
- zrealizować
- polecić
- dokumentacja
- zmniejszyć
- zmniejsza
- zarejestrowany
- obsługi produkcji rolnej, która zastąpiła
- reprezentować
- zażądać
- Wymaga
- Zasoby
- ograniczać
- dalsze
- detaliczny
- Rola
- role
- run
- bieganie
- wzgląd
- taki sam
- Zapisz
- oszczędność
- druga
- Sekcja
- sektor
- bezpieczeństwo
- senior
- wrażliwy
- usługa
- Usługi
- Sesja
- zestaw
- pokazać
- pokazane
- Targi
- Shuffle
- znak
- Prosty
- uproszczony
- pojedynczy
- Rozmiar
- mały
- So
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- Iskra
- specjalista
- wydać
- spędził
- Spot
- SQL
- stos
- początek
- rozpoczęty
- Startowy
- oświadczenia
- Rynek
- Ewolucja krok po kroku
- Cel
- zatrzymany
- przechowywanie
- przechowywany
- sklep
- Strategiczny
- strumień
- studio
- studia
- uległość
- Zatwierdź
- składane
- podsieci
- taki
- odpowiedni
- w zestawie
- Wspierający
- Przełącznik
- trwa
- zadania
- zespół
- szablon
- tymczasowy
- terminal
- Połączenia
- UK
- ich
- Przez
- wydajność
- czas
- do
- także
- Kwota produktów:
- przenieść
- Transformacja
- przejście
- prawdziwy
- Tutorial
- typy
- Maszynopis
- Uk
- zasadniczy
- jednostka
- Aktualizacja
- Nowości
- przesłanych
- URI
- posługiwać się
- Użytkownik
- Interfejs użytkownika
- Użytkownicy
- Użytkowe
- wartość
- Wartości
- wersja
- kontrola wersji
- Zobacz i wysłuchaj
- Wirtualny
- Tom
- czekać
- sieć
- usługi internetowe
- Co
- który
- będzie
- w ciągu
- Praca
- pracował
- pracownik
- przepływów pracy
- pracujący
- napisać
- jamla
- Twój
- zefirnet