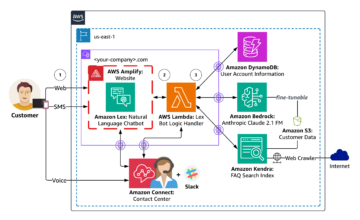
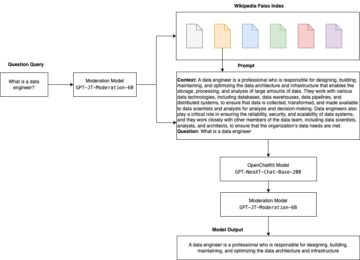
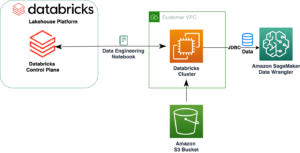
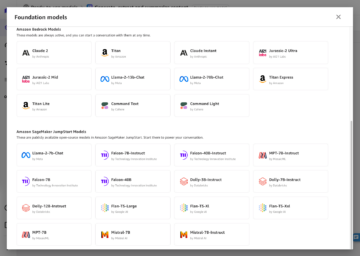
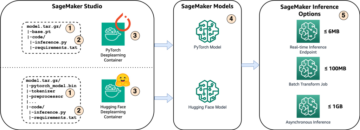
Amazon Sage Maker to w pełni zarządzana usługa uczenia maszynowego (ML). Dzięki SageMaker analitycy danych i programiści mogą szybko i łatwo budować i trenować modele ML, a następnie bezpośrednio wdrażać je w gotowym do produkcji środowisku hostowanym. Zapewnia zintegrowaną instancję notatnika Jupyter do tworzenia, zapewniającą łatwy dostęp do źródeł danych w celu eksploracji i analizy, dzięki czemu nie musisz zarządzać serwerami. Zapewnia również wspólne Algorytmy ML które są zoptymalizowane pod kątem wydajnej pracy z bardzo dużymi danymi w środowisku rozproszonym.
Wnioskowanie w czasie rzeczywistym SageMaker jest idealne dla obciążeń wymagających interakcji w czasie rzeczywistym i małych opóźnień. Dzięki wnioskowaniu w czasie rzeczywistym SageMaker możesz wdrażać punkty końcowe REST, które są wspierane przez określony typ instancji z określoną ilością mocy obliczeniowej i pamięci. Wdrożenie punktu końcowego SageMaker działającego w czasie rzeczywistym to dla wielu klientów tylko pierwszy krok na drodze do produkcji. Chcemy być w stanie zmaksymalizować wydajność punktu końcowego, aby osiągnąć docelową liczbę transakcji na sekundę (TPS), przestrzegając jednocześnie wymagań dotyczących opóźnień. Duża część optymalizacji wydajności na potrzeby wnioskowania polega na upewnieniu się, że wybrano właściwy typ instancji i zliczanie do punktu końcowego.
W tym poście opisano najlepsze praktyki dotyczące testowania obciążenia punktu końcowego SageMaker w celu znalezienia odpowiedniej konfiguracji dla liczby instancji i rozmiaru. Może to pomóc nam zrozumieć minimalne wymagania dotyczące aprowizowanej instancji, aby spełnić nasze wymagania dotyczące opóźnień i TPS. Stamtąd zagłębiamy się w to, jak możesz śledzić i rozumieć metryki i wydajność punktu końcowego SageMaker za pomocą Amazon Cloud Watch metryka.
Najpierw porównujemy wydajność naszego modelu w pojedynczej instancji, aby zidentyfikować TPS, który może obsłużyć zgodnie z naszymi akceptowalnymi wymaganiami dotyczącymi opóźnień. Następnie ekstrapolujemy wyniki, aby zdecydować, ile instancji potrzebujemy, aby obsłużyć nasz ruch produkcyjny. Na koniec symulujemy ruch na poziomie produkcyjnym i konfigurujemy testy obciążenia dla punktu końcowego SageMaker w czasie rzeczywistym, aby potwierdzić, że nasz punkt końcowy może obsłużyć obciążenie na poziomie produkcyjnym. Cały zestaw kodu dla przykładu jest dostępny poniżej Repozytorium GitHub.
Przegląd rozwiązania
W tym poście wdrażamy wstępnie przeszkolony Przytulanie twarzy Model DistilBERT z Przytulanie twarzy Hub. Ten model może wykonywać wiele zadań, ale wysyłamy ładunek specjalnie do analizy tonacji i klasyfikacji tekstu. Przy tym przykładowym ładunku dążymy do osiągnięcia 1000 TPS.
Wdróż punkt końcowy w czasie rzeczywistym
W tym poście przyjęto założenie, że wiesz, jak wdrożyć model. Odnosić się do Stwórz swój punkt końcowy i wdróż swój model aby zrozumieć wewnętrzne elementy hostingu punktu końcowego. Na razie możemy szybko wskazać ten model w Hugging Face Hub i wdrożyć punkt końcowy w czasie rzeczywistym za pomocą następującego fragmentu kodu:
Przetestujmy szybko nasz punkt końcowy za pomocą przykładowego ładunku, którego chcemy użyć do testowania obciążenia:

Pamiętaj, że tworzymy kopię zapasową punktu końcowego przy użyciu jednego Elastyczna chmura obliczeniowa Amazon (Amazon EC2) instancja typu ml.m5.12xlarge, która zawiera 48 vCPU i 192 GiB pamięci. Liczba procesorów wirtualnych jest dobrym wskaźnikiem współbieżności, jaką może obsłużyć instancja. Ogólnie rzecz biorąc, zaleca się przetestowanie różnych typów instancji, aby upewnić się, że mamy instancję, która ma zasoby, które są właściwie wykorzystywane. Aby zobaczyć pełną listę instancji SageMaker i odpowiadającej im mocy obliczeniowej dla wnioskowania w czasie rzeczywistym, zobacz Cennik Amazon SageMaker.
Wskaźniki do śledzenia
Zanim przejdziemy do testów obciążenia, konieczne jest zrozumienie, jakie metryki należy śledzić, aby zrozumieć podział wydajności punktu końcowego SageMaker. CloudWatch to podstawowe narzędzie do rejestrowania, którego używa SageMaker, aby pomóc Ci zrozumieć różne metryki opisujące wydajność Twojego punktu końcowego. Możesz wykorzystać dzienniki CloudWatch do debugowania wywołań punktów końcowych; wszystkie instrukcje rejestrowania i drukowania, które masz w kodzie wnioskowania, są przechwytywane tutaj. Aby uzyskać więcej informacji, patrz Jak działa Amazon Cloud Watch.
Istnieją dwa różne rodzaje metryk, które CloudWatch obejmuje dla SageMaker: metryki na poziomie instancji i metryki wywołania.
Metryki na poziomie instancji
Pierwszym zestawem parametrów do rozważenia są metryki na poziomie instancji: CPUUtilization i MemoryUtilization (dla instancji opartych na GPU, GPUUtilization). Dla CPUUtilization, na początku w CloudWatch możesz zobaczyć wartości procentowe powyżej 100%. Ważne jest, aby uświadomić sobie CPUUtilization, wyświetlana jest suma wszystkich rdzeni procesora. Na przykład, jeśli instancja za punktem końcowym zawiera 4 procesory wirtualne, oznacza to, że zakres wykorzystania wynosi do 400%. MemoryUtilizationnatomiast mieści się w przedziale 0-100%.
W szczególności możesz użyć CPUUtilization aby uzyskać głębsze zrozumienie, czy masz wystarczającą lub nawet nadmiarową ilość sprzętu. Jeśli masz niewykorzystaną instancję (mniej niż 30%), możesz potencjalnie zmniejszyć typ instancji. I odwrotnie, jeśli wykorzystanie wynosi około 80–90%, warto wybrać instancję z większą mocą obliczeniową/pamięcią. Z naszych testów wynika, że wykorzystanie Twojego sprzętu wynosi około 60–70%.
Metryki wywołania
Jak sugeruje nazwa, metryki wywołań umożliwiają śledzenie kompleksowego opóźnienia wszelkich wywołań do punktu końcowego. Metryki wywołań można wykorzystać do przechwytywania liczby błędów i typów błędów (5xx, 4xx itd.), które mogą wystąpić w punkcie końcowym. Co ważniejsze, możesz zrozumieć rozkład opóźnień połączeń z punktami końcowymi. Wiele z tego można uchwycić ModelLatency i OverheadLatency metryki, jak pokazano na poniższym diagramie.

Połączenia ModelLatency Metryka przechwytuje czas, jaki zajmuje wnioskowanie w kontenerze modelu za punktem końcowym SageMaker. Zwróć uwagę, że kontener modelu zawiera również dowolny niestandardowy kod lub skrypty wnioskowania, które zostały przekazane do wnioskowania. Ta jednostka jest rejestrowana w mikrosekundach jako metryka wywołania i ogólnie można wykreślić percentyl w CloudWatch (p99, p90 itd.), aby sprawdzić, czy osiągasz docelowe opóźnienie. Pamiętaj, że na opóźnienie modelu i kontenera może mieć wpływ kilka czynników, takich jak:
- Niestandardowy skrypt wnioskowania – Niezależnie od tego, czy zaimplementowałeś własny kontener, czy korzystałeś z kontenera opartego na SageMaker z niestandardowymi procedurami obsługi wnioskowania, najlepszą praktyką jest profilowanie skryptu w celu wychwytywania wszelkich operacji, które szczególnie wydłużają opóźnienie.
- Protokół komunikacyjny – Rozważ połączenia REST i gRPC z serwerem modelu w kontenerze modelu.
- Optymalizacje frameworka modelu – Jest to specyficzne dla frameworka, na przykład z TensorFlow, istnieje wiele zmiennych środowiskowych, które można dostosować, które są specyficzne dla usługi TF Serving. Sprawdź, jakiego kontenera używasz i czy są jakieś optymalizacje specyficzne dla frameworka, które możesz dodać w skrypcie lub jako zmienne środowiskowe do wstrzyknięcia do kontenera.
OverheadLatency jest mierzony od momentu otrzymania żądania przez SageMaker do momentu zwrócenia odpowiedzi klientowi, pomniejszony o opóźnienie modelu. Ta część jest w dużej mierze poza twoją kontrolą i mieści się w czasie zajętym przez koszty ogólne SageMaker.
Całkowite opóźnienie zależy od wielu czynników i niekoniecznie jest sumą ModelLatency plus OverheadLatency. Na przykład, jeśli klient tworzy plik InvokeEndpoint Wywołanie interfejsu API przez Internet, z perspektywy klienta, całkowite opóźnienie wynosiłoby internet + ModelLatency + OverheadLatency. W związku z tym podczas testowania obciążenia punktu końcowego w celu dokładnego porównania samego punktu końcowego zaleca się skupienie się na metrykach punktu końcowego (ModelLatency, OverheadLatency, InvocationsPerInstance), aby dokładnie porównać punkt końcowy SageMaker. Wszelkie problemy związane z całkowitym opóźnieniem można następnie odizolować oddzielnie.
Kilka pytań do rozważenia w przypadku opóźnień typu end-to-end:
- Gdzie jest klient, który wywołuje Twój punkt końcowy?
- Czy są jakieś warstwy pośrednie między Twoim klientem a środowiskiem wykonawczym SageMaker?
Automatyczne skalowanie
W tym poście nie omawiamy konkretnie skalowania automatycznego, ale jest to ważne, aby zapewnić odpowiednią liczbę wystąpień na podstawie obciążenia. W zależności od wzorców ruchu możesz dołączyć plik zasady automatycznego skalowania do punktu końcowego SageMaker. Istnieją różne opcje skalowania, takie jak TargetTrackingScaling, SimpleScaling, StepScaling. Dzięki temu punkt końcowy może automatycznie skalować się w górę i w dół na podstawie wzorca ruchu.
Powszechną opcją jest śledzenie celów, w ramach którego można określić zdefiniowaną przez siebie metrykę CloudWatch lub niestandardową metrykę i skalować ją w poziomie. Częstym wykorzystaniem automatycznego skalowania jest śledzenie InvocationsPerInstance metryczny. Po zidentyfikowaniu wąskiego gardła w określonym TPS często można użyć go jako metryki do skalowania do większej liczby instancji, aby móc obsłużyć szczytowe obciążenia ruchu. Aby uzyskać głębszy podział punktów końcowych SageMaker z automatycznym skalowaniem, zobacz Konfigurowanie punktów końcowych wnioskowania z automatycznym skalowaniem w Amazon SageMaker.
Testowanie obciążenia
Chociaż używamy Locust do wyświetlania, w jaki sposób możemy załadować test na dużą skalę, jeśli próbujesz dopasować rozmiar instancji za punktem końcowym, Polecający wnioskowanie SageMaker jest bardziej wydajną opcją. Dzięki narzędziom do testowania obciążenia innych firm musisz ręcznie wdrażać punkty końcowe w różnych instancjach. Dzięki Recommenderowi wnioskowania możesz po prostu przekazać tablicę typów instancji, dla których chcesz załadować test, a SageMaker uruchomi się Oferty pracy dla każdego z tych przypadków.
Szarańcza
W tym przykładzie używamy Szarańcza, narzędzie do testowania obciążenia typu open source, które można zaimplementować przy użyciu języka Python. Locust jest podobny do wielu innych narzędzi do testowania obciążenia typu open source, ale ma kilka konkretnych zalet:
- Łatwa konfiguracja – Jak zademonstrujemy w tym poście, przekażemy prosty skrypt w języku Python, który można łatwo zrefaktoryzować pod kątem określonego punktu końcowego i ładunku.
- Rozproszony i skalowalny – Szarańcza jest oparta na zdarzeniach i wykorzystuje dziać się pod maską. Jest to bardzo przydatne do testowania wysoce współbieżnych obciążeń i symulowania tysięcy jednoczesnych użytkowników. Możesz osiągnąć wysoki TPS za pomocą jednego procesu działającego w Locust, ale ma on również rozproszone generowanie obciążenia funkcja, która umożliwia skalowanie w poziomie do wielu procesów i komputerów klienckich, co omówimy w tym poście.
- Metryki szarańczy i interfejs użytkownika – Locust rejestruje również jako metrykę opóźnienie typu end-to-end. Może to pomóc w uzupełnieniu danych CloudWatch, aby uzyskać pełny obraz testów. Wszystko to jest rejestrowane w interfejsie użytkownika Locust, w którym można śledzić jednoczesnych użytkowników, pracowników i nie tylko.
Aby lepiej zrozumieć Locust, sprawdź ich dokumentacja.
Konfiguracja Amazon EC2
Możesz skonfigurować Locust w dowolnym środowisku, które jest dla Ciebie kompatybilne. W tym poście skonfigurowaliśmy instancję EC2 i zainstalowaliśmy tam Locusta, aby przeprowadzić nasze testy. Używamy instancji c5.18xlarge EC2. Należy również wziąć pod uwagę moc obliczeniową po stronie klienta. Czasami, gdy zabraknie mocy obliczeniowej po stronie klienta, często nie jest to rejestrowane i jest mylone jako błąd punktu końcowego SageMaker. Ważne jest, aby umieścić klienta w lokalizacji o wystarczającej mocy obliczeniowej, która może obsłużyć obciążenie, które testujesz. W naszej instancji EC2 używamy Ubuntu Deep Learning AMI, ale możesz użyć dowolnego AMI, o ile możesz poprawnie skonfigurować Locust na maszynie. Aby zrozumieć, jak uruchomić instancję EC2 i połączyć się z nią, zapoznaj się z samouczkiem Rozpocznij pracę z instancjami Amazon EC2 Linux.
Interfejs użytkownika Locust jest dostępny przez port 8089. Możemy go otworzyć, dostosowując nasze reguły grupy bezpieczeństwa ruchu przychodzącego dla instancji EC2. Otwieramy również port 22, abyśmy mogli połączyć się przez SSH z instancją EC2. Rozważ ograniczenie źródła do określonego adresu IP, z którego uzyskujesz dostęp do instancji EC2.

Po nawiązaniu połączenia z instancją EC2 konfigurujemy środowisko wirtualne Pythona i instalujemy otwarte API Locust za pośrednictwem CLI:
Jesteśmy teraz gotowi do pracy z Locustem w celu testowania obciążenia naszego punktu końcowego.
Testowanie szarańczy
Wszystkie testy obciążenia Locust są przeprowadzane w oparciu o Plik szarańczy które zapewniasz. Ten plik Locust definiuje zadanie dla testu obciążenia; tutaj definiujemy nasz Boto3 wywołanie interfejsu API invoke_endpoint. Zobacz następujący kod:
W powyższym kodzie dostosuj parametry wywołania punktu końcowego wywołania, aby pasowały do określonego wywołania modelu. Używamy InvokeEndpoint API korzystające z następującego fragmentu kodu w pliku Locust; to jest nasz punkt uruchomienia testu obciążenia. Plik Locust, którego używamy to szarańcza_script.py.
Teraz, gdy mamy gotowy skrypt Locust, chcemy uruchomić rozproszone testy Locust, aby przetestować naszą pojedynczą instancję, aby dowiedzieć się, jaki ruch może obsłużyć nasza instancja.
Tryb rozproszony Locust jest nieco bardziej złożony niż jednoprocesowy test Locust. W trybie rozproszonym mamy jednego podstawowego i wielu pracowników. Podstawowy proces roboczy instruuje pracowników, jak odradzać i kontrolować równoczesnych użytkowników, którzy wysyłają żądanie. W naszym dystrybuowane.sh skrypt, domyślnie widzimy, że 240 użytkowników zostanie rozdzielonych między 60 pracowników. Zauważ, że --headless flaga w Locust CLI usuwa funkcję interfejsu użytkownika Locust.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
Najpierw uruchamiamy test rozproszony na pojedynczej instancji wspierającej punkt końcowy. Chodzi o to, że chcemy w pełni zmaksymalizować pojedynczą instancję, aby zrozumieć liczbę instancji potrzebną do osiągnięcia docelowego TPS przy zachowaniu naszych wymagań dotyczących opóźnień. Pamiętaj, że jeśli chcesz uzyskać dostęp do interfejsu użytkownika, zmień plik Locust_UI zmienną środowiskową na True i weź publiczny adres IP swojej instancji EC2 i zamapuj port 8089 na adres URL.
Poniższy zrzut ekranu przedstawia nasze metryki CloudWatch.

W końcu zauważyliśmy, że chociaż początkowo osiągamy TPS na poziomie 200, zaczynamy zauważać błędy 5xx w naszych dziennikach po stronie klienta EC2, jak pokazano na poniższym zrzucie ekranu.
Możemy to również zweryfikować, patrząc w szczególności na nasze wskaźniki na poziomie instancji CPUUtilization.
 Tutaj zauważamy
Tutaj zauważamy CPUUtilization prawie 4,800%. Nasza instancja ml.m5.12x.large ma 48 vCPU (48 * 100 = 4800~). To nasyca całą instancję, co również pomaga wyjaśnić nasze błędy 5xx. Obserwujemy również wzrost ModelLatency.
Wygląda na to, że nasza pojedyncza instancja zostaje przewrócona i nie ma mocy obliczeniowej, aby wytrzymać obciążenie przekraczające 200 TPS, które obserwujemy. Naszym docelowym TPS jest 1000, więc spróbujmy zwiększyć liczbę instancji do 5. Może to być nawet więcej w ustawieniach produkcyjnych, ponieważ po pewnym czasie obserwowaliśmy błędy przy 200 TPS.

Widzimy zarówno w dziennikach Locust UI, jak i CloudWatch, że mamy TPS prawie 1000 z pięcioma instancjami wspierającymi punkt końcowy.

 Jeśli zaczniesz doświadczać błędów nawet przy tej konfiguracji sprzętu, pamiętaj o monitorowaniu
Jeśli zaczniesz doświadczać błędów nawet przy tej konfiguracji sprzętu, pamiętaj o monitorowaniu CPUUtilization aby zrozumieć pełny obraz hostingu punktów końcowych. Bardzo ważne jest, aby zrozumieć wykorzystanie sprzętu, aby zobaczyć, czy potrzebujesz skalować w górę, czy nawet w dół. Czasami problemy na poziomie kontenera prowadzą do błędów 5xx, ale if CPUUtilization jest niski, oznacza to, że to nie twój sprzęt, ale coś na poziomie kontenera lub modelu może prowadzić do tych problemów (na przykład nie ustawiono odpowiedniej zmiennej środowiskowej dla liczby pracowników). Z drugiej strony, jeśli zauważysz, że twoja instancja jest w pełni nasycona, jest to znak, że musisz albo zwiększyć obecną flotę instancji, albo wypróbować większą instancję z mniejszą flotą.
Chociaż zwiększyliśmy liczbę instancji do 5, aby obsłużyć 100 TPS, widzimy, że ModelLatency wskaźnik jest nadal wysoki. Wynika to z nasycenia instancji. Ogólnie sugerujemy, aby dążyć do wykorzystania zasobów instancji między 60 a 70%.
Sprzątać
Po przetestowaniu obciążenia pamiętaj o wyczyszczeniu wszelkich zasobów, których nie będziesz wykorzystywać za pośrednictwem konsoli SageMaker lub przez usuń_punkt końcowy Wywołanie API Boto3. Ponadto upewnij się, że zatrzymałeś instancję EC2 lub inną konfigurację klienta, aby nie ponosić żadnych dalszych opłat.
Podsumowanie
W tym poście opisaliśmy, w jaki sposób możesz przetestować swój punkt końcowy SageMaker w czasie rzeczywistym. Omówiliśmy również, jakie metryki należy oceniać podczas testowania obciążenia punktu końcowego, aby zrozumieć podział wydajności. Koniecznie sprawdź Polecający wnioskowanie SageMaker aby lepiej zrozumieć odpowiednie rozmiary instancji i więcej technik optymalizacji wydajności.
O autorach
 Marek Karp jest architektem ML w zespole SageMaker Service. Koncentruje się na pomaganiu klientom w projektowaniu, wdrażaniu i zarządzaniu obciążeniami ML na dużą skalę. W wolnym czasie lubi podróżować i poznawać nowe miejsca.
Marek Karp jest architektem ML w zespole SageMaker Service. Koncentruje się na pomaganiu klientom w projektowaniu, wdrażaniu i zarządzaniu obciążeniami ML na dużą skalę. W wolnym czasie lubi podróżować i poznawać nowe miejsca.
 Ram Vegiraju jest architektem ML w zespole SageMaker Service. Koncentruje się na pomaganiu klientom w budowaniu i optymalizowaniu ich rozwiązań AI/ML w Amazon SageMaker. W wolnym czasie uwielbia podróżować i pisać.
Ram Vegiraju jest architektem ML w zespole SageMaker Service. Koncentruje się na pomaganiu klientom w budowaniu i optymalizowaniu ich rozwiązań AI/ML w Amazon SageMaker. W wolnym czasie uwielbia podróżować i pisać.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- Zdolny
- powyżej
- do przyjęcia
- dostęp
- dostępny
- Dostęp
- dokładnie
- Osiągać
- w poprzek
- dodatek
- adres
- Po
- przed
- AI / ML
- Cel
- Wszystkie kategorie
- pozwala
- Chociaż
- Amazonka
- Amazon EC2
- Amazon Sage Maker
- ilość
- analiza
- i
- api
- na około
- Szyk
- dołączać
- autoring
- samochód
- automatycznie
- dostępny
- AWS
- z powrotem
- poparła
- poparcie
- na podstawie
- bo
- za
- jest
- Benchmark
- korzyści
- Korzyści
- BEST
- Najlepsze praktyki
- pomiędzy
- ciało
- awaria
- budować
- C + +
- wezwanie
- Połączenia
- Może uzyskać
- zdobyć
- przechwytuje
- zapasy
- pewien
- zmiana
- Opłaty
- ZOBACZ
- klasa
- klasyfikacja
- klient
- kod
- wspólny
- zgodny
- obliczać
- równoległy
- Prowadzenie
- systemu
- Potwierdzać
- Skontaktuj się
- połączony
- połączenia
- Rozważać
- wynagrodzenie
- Konsola
- Pojemnik
- zawiera
- kontekst
- kontrola
- Odpowiedni
- mógłby
- pokrywa
- obejmuje
- CPU
- Stwórz
- istotny
- Aktualny
- zwyczaj
- Klientów
- dane
- głęboko
- głęboka nauka
- głębiej
- Domyślnie
- Definiuje
- wykazać
- W zależności
- zależy
- rozwijać
- wdrażanie
- opisać
- opisane
- Wnętrze
- deweloperzy
- różne
- bezpośrednio
- omówione
- Wyświetlacz
- dystrybuowane
- Nie
- nie
- na dół
- każdy
- z łatwością
- wydajny
- skutecznie
- bądź
- Umożliwia
- koniec końców
- Punkt końcowy
- Cały
- Środowisko
- błąd
- Błędy
- niezbędny
- Eter (ETH)
- Parzyste
- przykład
- wyjątek
- wykonać
- doświadczać
- Wyjaśniać
- eksploracja
- odkryj
- Exploring
- eksport
- niezwykle
- Twarz
- Czynniki
- Spada
- znajomy
- Cecha
- kilka
- filet
- W końcu
- Znajdź
- i terminów, a
- FLOTA
- Skupiać
- koncentruje
- następujący
- format
- Framework
- częsty
- od
- pełny
- w pełni
- dalej
- Ogólne
- ogólnie
- otrzymać
- miejsce
- dobry
- wykres
- większy
- Zarządzanie
- Grupy
- uchwyt
- Zaoszczędzić
- sprzęt komputerowy
- pomoc
- pomoc
- pomaga
- tutaj
- Wysoki
- wysoko
- kaptur
- gospodarz
- hostowane
- Hosting
- W jaki sposób
- How To
- HTML
- HTTPS
- Piasta
- pomysł
- idealny
- zidentyfikowane
- zidentyfikować
- Rezultat
- wdrożenia
- realizowane
- importować
- ważny
- in
- obejmuje
- Zwiększać
- wzrosła
- wskazuje
- wskazanie
- Informacja
- początkowo
- zainstalować
- przykład
- zintegrowany
- interaktywne
- Internet
- inwokuje
- IP
- Adres IP
- odosobniony
- problemy
- IT
- samo
- json
- duży
- w dużej mierze
- większe
- Utajenie
- uruchomić
- nioski
- prowadzić
- prowadzący
- nauka
- poziom
- linux
- Lista
- mało
- załadować
- masa
- lokalizacja
- długo
- poszukuje
- Partia
- niski
- maszyna
- uczenie maszynowe
- maszyny
- robić
- Dokonywanie
- zarządzanie
- zarządzane
- ręcznie
- wiele
- mapa
- Maksymalizuj
- znaczy
- Poznaj nasz
- Spotkanie
- Pamięć
- metryczny
- Metryka
- może
- minimum
- ML
- Moda
- model
- modele
- monitor
- jeszcze
- bardziej wydajny
- wielokrotność
- Nazwa
- prawie
- koniecznie
- Potrzebować
- Nowości
- notatnik
- numer
- ONE
- koncepcja
- open source
- operacje
- optymalizacja
- Optymalizacja
- zoptymalizowane
- Option
- Opcje
- zamówienie
- Inne
- zewnętrzne
- własny
- malować
- parametry
- część
- minęło
- Przeszłość
- ścieżka
- Wzór
- wzory
- Szczyt
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- perspektywa
- wybierać
- obraz
- kawałek
- Miejsce
- Miejsca
- plato
- Analiza danych Platona
- PlatoDane
- plus
- punkt
- Post
- potencjalnie
- power
- praktyka
- praktyki
- Urządzenie prognozujące
- pierwotny
- problemy
- wygląda tak
- procesów
- Produkcja
- Profil
- właściwy
- prawidłowo
- zapewniać
- zapewnia
- zaopatrzenie
- publiczny
- Python
- pytania
- szybko
- zasięg
- gotowy
- w czasie rzeczywistym
- zrealizować
- otrzymuje
- Zalecana
- region
- związane z
- zażądać
- wymagania
- Zasoby
- odpowiedź
- REST
- dalsze
- Efekt
- powraca
- reguły
- run
- bieganie
- sagemaker
- Wnioskowanie SageMakera
- Skala
- skalowaniem
- Naukowcy
- Zakres
- skrypty
- druga
- bezpieczeństwo
- wydaje
- SAMEGO SIEBIE
- wysyłanie
- sentyment
- usługa
- służąc
- zestaw
- ustawienie
- w panelu ustawień
- ustawienie
- kilka
- powinien
- pokazane
- Targi
- znak
- podobny
- Prosty
- po prostu
- pojedynczy
- Rozmiar
- mniejszy
- So
- Rozwiązania
- coś
- Źródło
- Źródła
- Ikra
- specyficzny
- swoiście
- Spin
- standard
- początek
- rozpoczęty
- oświadczenia
- Ewolucja krok po kroku
- Nadal
- Stop
- stres
- starać się
- taki
- wystarczający
- Garnitur
- Wspaniały
- uzupełnienie
- Brać
- trwa
- cel
- Zadanie
- zadania
- zespół
- Techniki
- test
- Testowe uruchomienie
- Testowanie
- Testy
- Klasyfikacja tekstu
- Połączenia
- Źródło
- ich
- innych firm
- tysiące
- Przez
- czas
- czasy
- do
- narzędzie
- narzędzia
- Tps
- śledzić
- Śledzenie
- ruch drogowy
- Pociąg
- transakcje
- Podróżowanie
- prawdziwy
- Tutorial
- typy
- Ubuntu
- ui
- dla
- zrozumieć
- zrozumienie
- jednostka
- URL
- us
- posługiwać się
- Użytkownicy
- wykorzystać
- wykorzystany
- wykorzystuje
- Wykorzystując
- różnorodność
- zweryfikować
- przez
- Wirtualny
- Co
- czy
- który
- Podczas
- będzie
- w ciągu
- Praca
- pracownik
- pracowników
- by
- pisanie
- Twój
- zefirnet