Ten post został napisany wspólnie z Babu Srinivasanem i Robertem Waltersem z MongoDB.
Przesyłanie strumieniowe zarządzane przez Amazon dla Apache Kafka (Amazon MSK) to w pełni zarządzana usługa Apache Kafka o wysokiej dostępności. Amazon MSK ułatwia pozyskiwanie i przetwarzanie danych przesyłanych strumieniowo w czasie rzeczywistym oraz łatwe wykorzystywanie tych danych w ekosystemie AWS. Z Bezserwerowe Amazon MSK, możesz automatycznie udostępniać wymagane zasoby i zarządzać nimi, aby zapewnić pojemność strumieniowania na żądanie i pamięć masową dla swoich aplikacji.
Amazon MSK obsługuje również integrację źródeł danych, takich jak MongoDB Atlas przez Amazon MSK Połącz. MSK Connect umożliwia bezserwerową integrację danych MongoDB z Amazon MSK przy użyciu Złącze MongoDB dla Apache Kafki.
Atlas MongoDB bez serwera zapewnia usługi bazodanowe, które dynamicznie skalują się w górę iw dół wraz z rozmiarem i przepustowością danych — a koszty są odpowiednio skalowane. Najlepiej nadaje się do zarządzania aplikacjami o zmiennych wymaganiach przy minimalnej konfiguracji. Zapewnia wysoką wydajność i niezawodność dzięki automatycznej aktualizacji, szyfrowaniu, bezpieczeństwu, pomiarom i funkcjom tworzenia kopii zapasowych wbudowanym w infrastrukturę MongoDB Atlas.
MSK Serverless to rodzaj klastra dla Amazon MSK. Podobnie jak MongoDB Atlas Serverless, MSK Serverless automatycznie aprowizuje i skaluje zasoby obliczeniowe i magazynowe. Możesz teraz tworzyć kompleksowe bezserwerowe przepływy pracy. Możesz zbudować bezserwerowy potok przesyłania strumieniowego z bezserwerowym pozyskiwaniem przy użyciu MSK Serverless i bezserwerowej pamięci masowej przy użyciu MongoDB Atlas. Ponadto obsługuje teraz MSK Connect prywatne nazwy hostów DNS. Dzięki temu bezserwerowe instancje MSK mogą łączyć się z bezserwerowymi klastrami MongoDB za pośrednictwem Prywatny link AWS, zapewniając bezpieczną łączność między platformami.
Jeśli interesuje Cię korzystanie z klastra bezserwerowego, zobacz Integracja MongoDB z Amazon Managed Streaming dla Apache Kafka (MSK).
W tym poście pokazano, jak zaimplementować bezserwerowy potok przesyłania strumieniowego za pomocą MSK Serverless, MSK Connect i MongoDB Atlas.
Omówienie rozwiązania
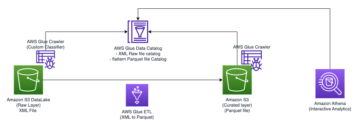
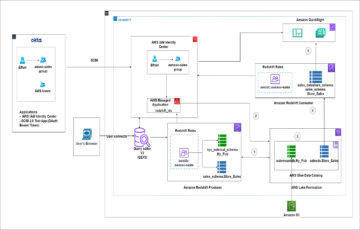
Poniższy diagram ilustruje naszą architekturę rozwiązania.
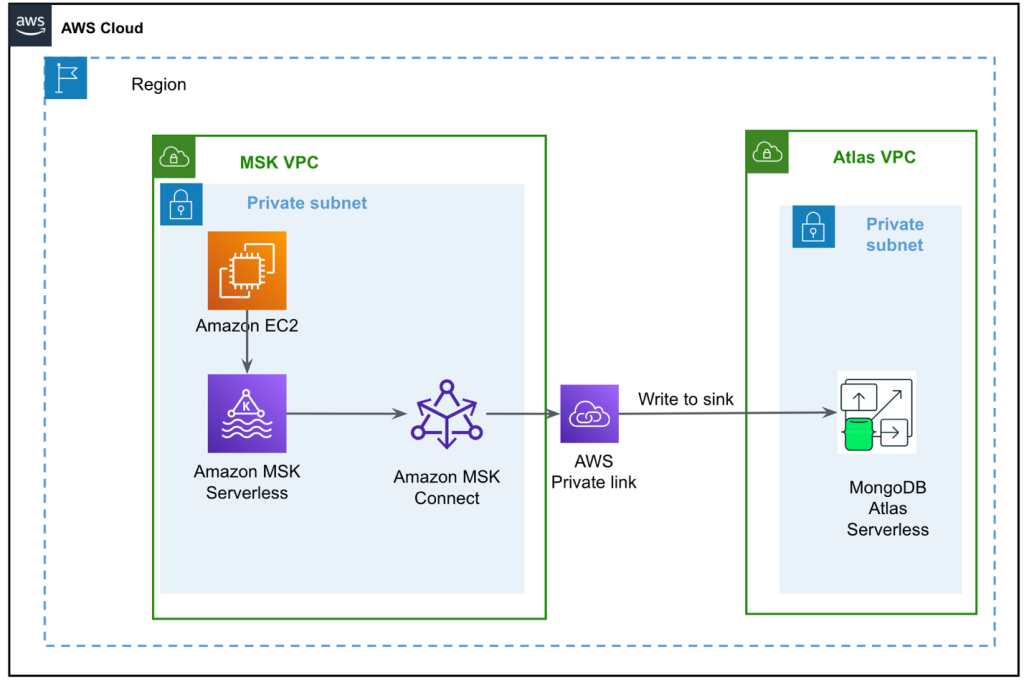
Przepływ danych rozpoczyna się od Elastyczna chmura obliczeniowa Amazon (Amazon EC2) instancja klienta, która zapisuje rekordy w temacie MSK. W miarę napływu danych instancja MongoDB Connector for Apache Kafka zapisuje dane w kolekcji w klastrze MongoDB Atlas Serverless. W celu zapewnienia bezpiecznej łączności między dwiema platformami tworzone jest połączenie AWS PrivateLink między klastrem MongoDB Atlas a VPC zawierającym instancję MSK.
Ten post przeprowadzi Cię przez następujące kroki:
- Utwórz bezserwerowy klaster MSK.
- Utwórz klaster MongoDB Atlas Serverless.
- Skonfiguruj wtyczkę MSK.
- Utwórz klienta EC2.
- Skonfiguruj temat MSK.
- Skonfiguruj złącze MongoDB dla Apache Kafka jako ujście.
Skonfiguruj bezserwerowy klaster MSK
Aby utworzyć bezserwerowy klaster MSK, wykonaj następujące kroki:
- W konsoli Amazon MSK wybierz Klastry w okienku nawigacji.
- Dodaj Utwórz klaster.
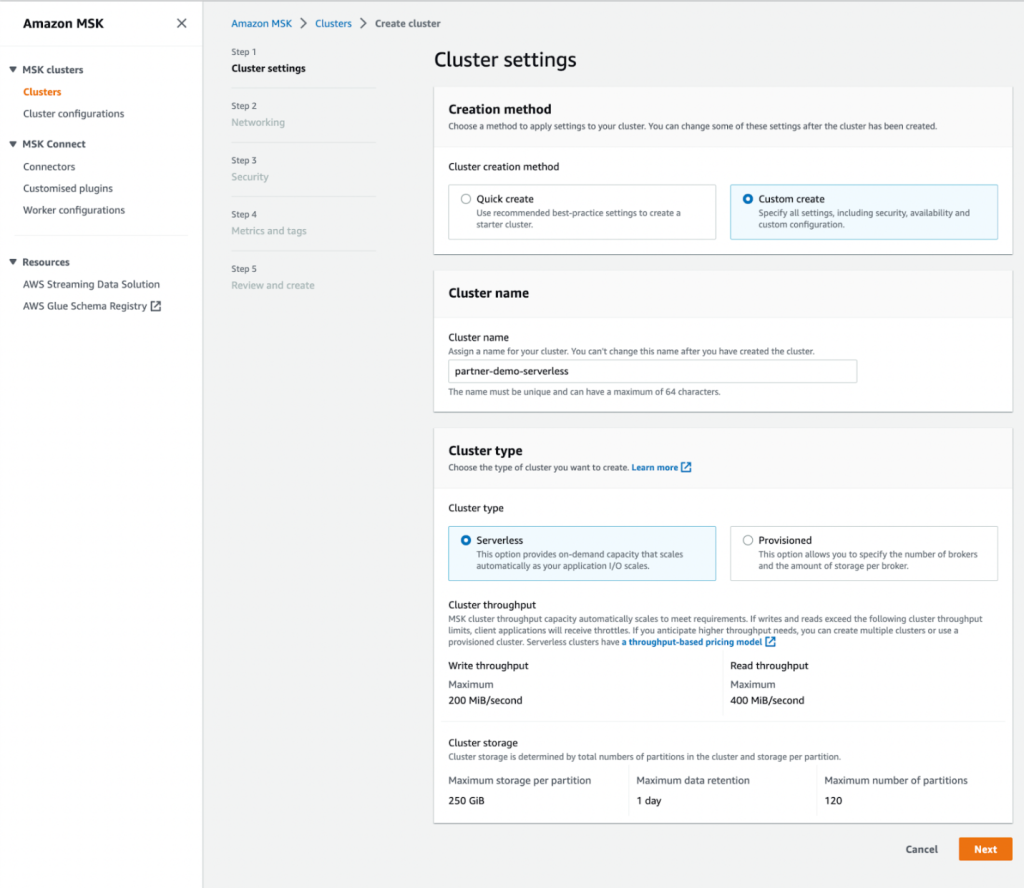
- W razie zamówieenia projektu Metoda tworzenia, Wybierz Niestandardowe tworzenie.
- W razie zamówieenia projektu Nazwa klastra, wchodzić
MongoDBMSKCluster. - W razie zamówieenia projektu Typ klastraWybierz Bezserwerowe.
- Dodaj Następna.
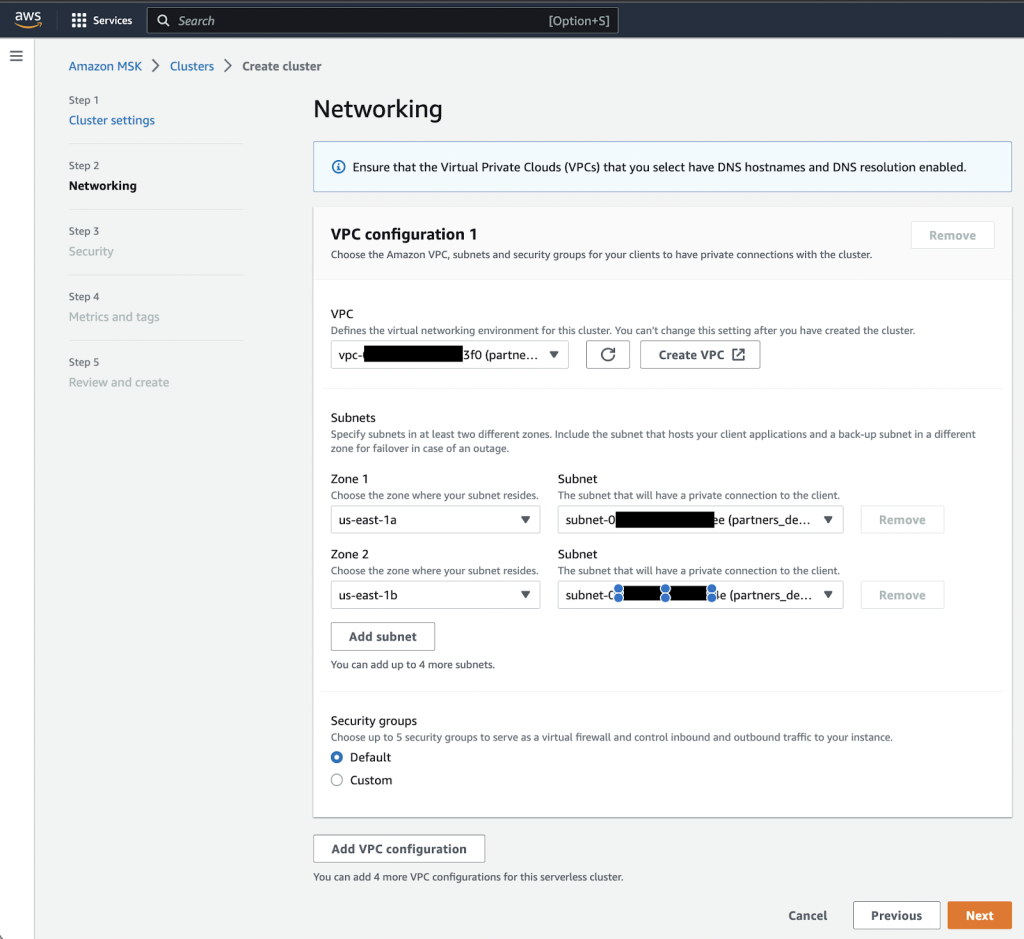
- Na Sieci określ swój VPC, strefy dostępności i odpowiadające im podsieci.
- Zanotuj strefy dostępności i podsieci, których użyjesz później.
- Dodaj Następna.
- Dodaj Utwórz klaster.
Gdy klaster jest dostępny, jego status to Active.

Utwórz klaster MongoDB Atlas Serverless
Aby utworzyć klaster MongoDB Atlas, postępuj zgodnie z instrukcjami Pierwsze kroki z Atlasem instruktaż. Pamiętaj, że na potrzeby tego wpisu musisz utworzyć instancję bezserwerową.
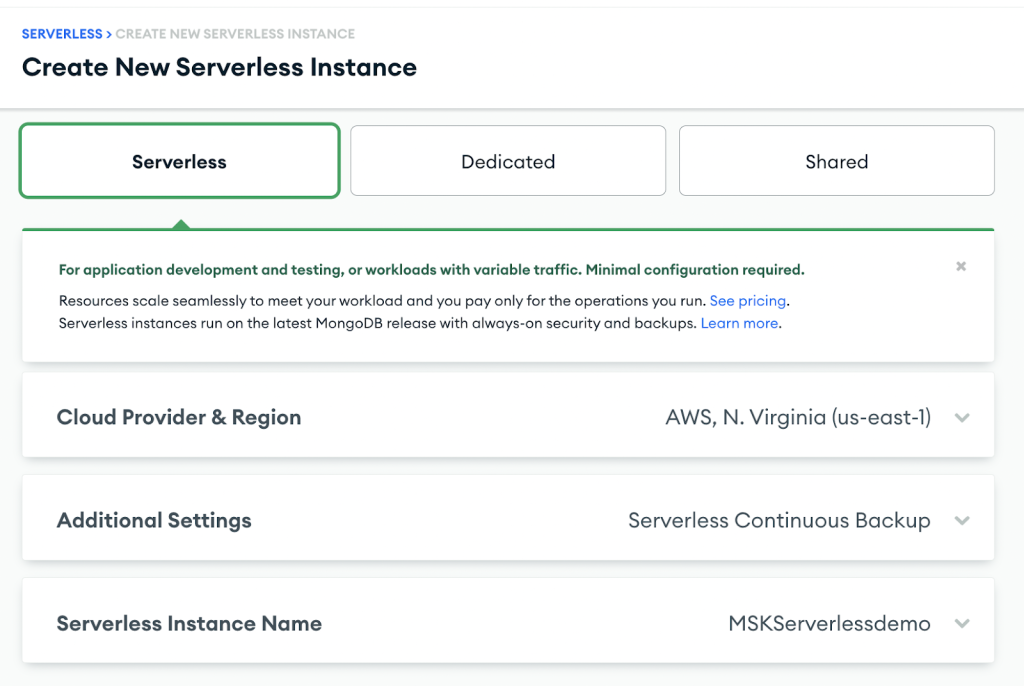
Po utworzeniu klastra skonfiguruj prywatny punkt końcowy AWS, wykonując następujące czynności:
- Na Bezpieczeństwo menu, wybierz Dostęp do sieci.

- Na Prywatny punkt końcowy kartę, wybierz Instancja bezserwerowa.

- Dodaj Utwórz nowy punkt końcowy.
- W razie zamówieenia projektu Instancja bezserwerowa, wybierz właśnie utworzoną instancję.
- Dodaj Potwierdzać.
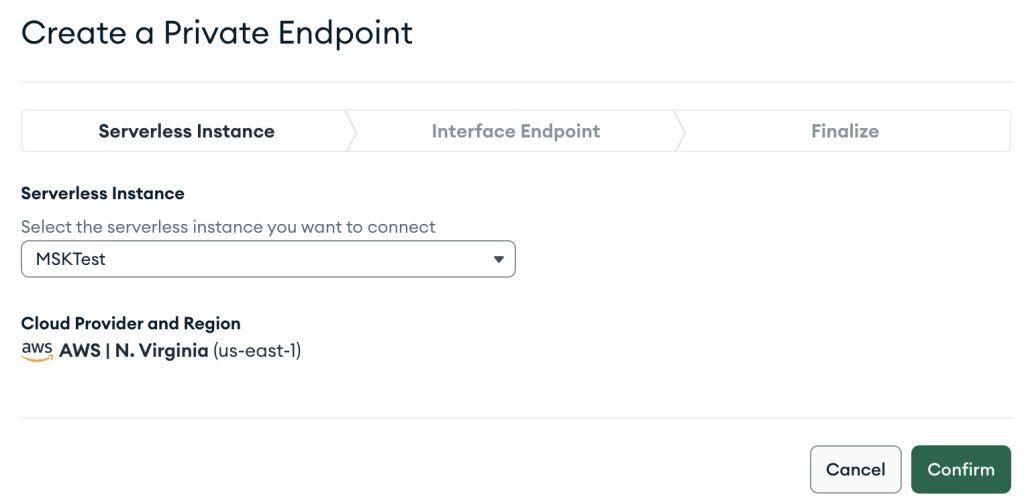
- Podaj konfigurację punktu końcowego VPC i wybierz Następna.
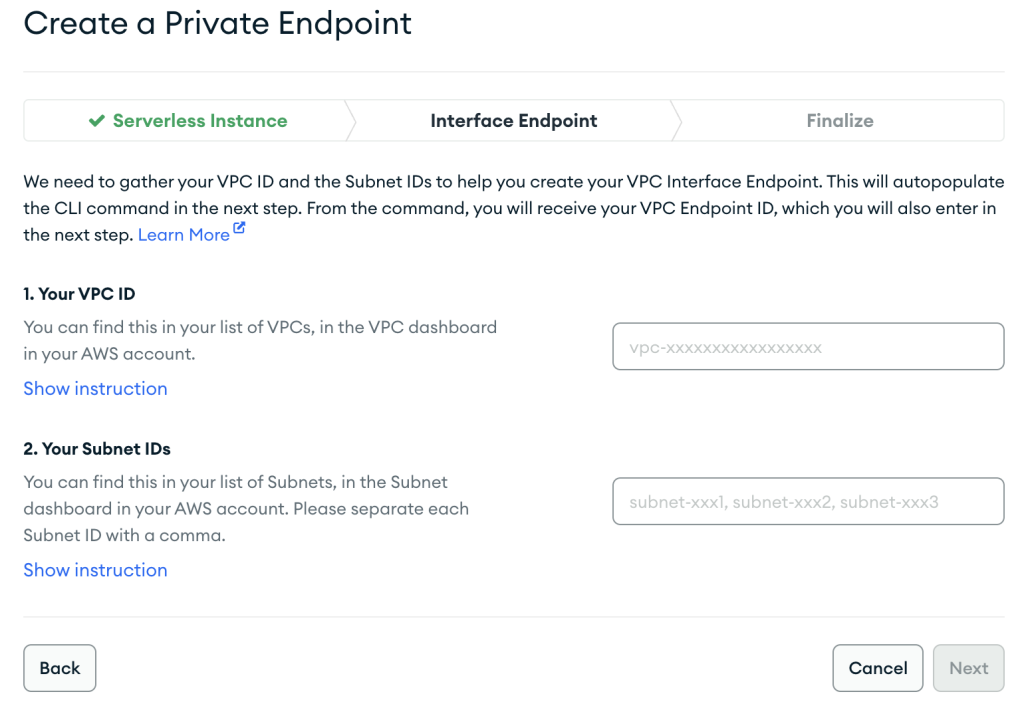
- Podczas tworzenia zasobu AWS PrivateLink upewnij się, że określiłeś dokładnie te same VPC i podsieci, które były używane wcześniej podczas tworzenia konfiguracji sieciowej dla bezserwerowej instancji MSK.
- Dodaj Następna.
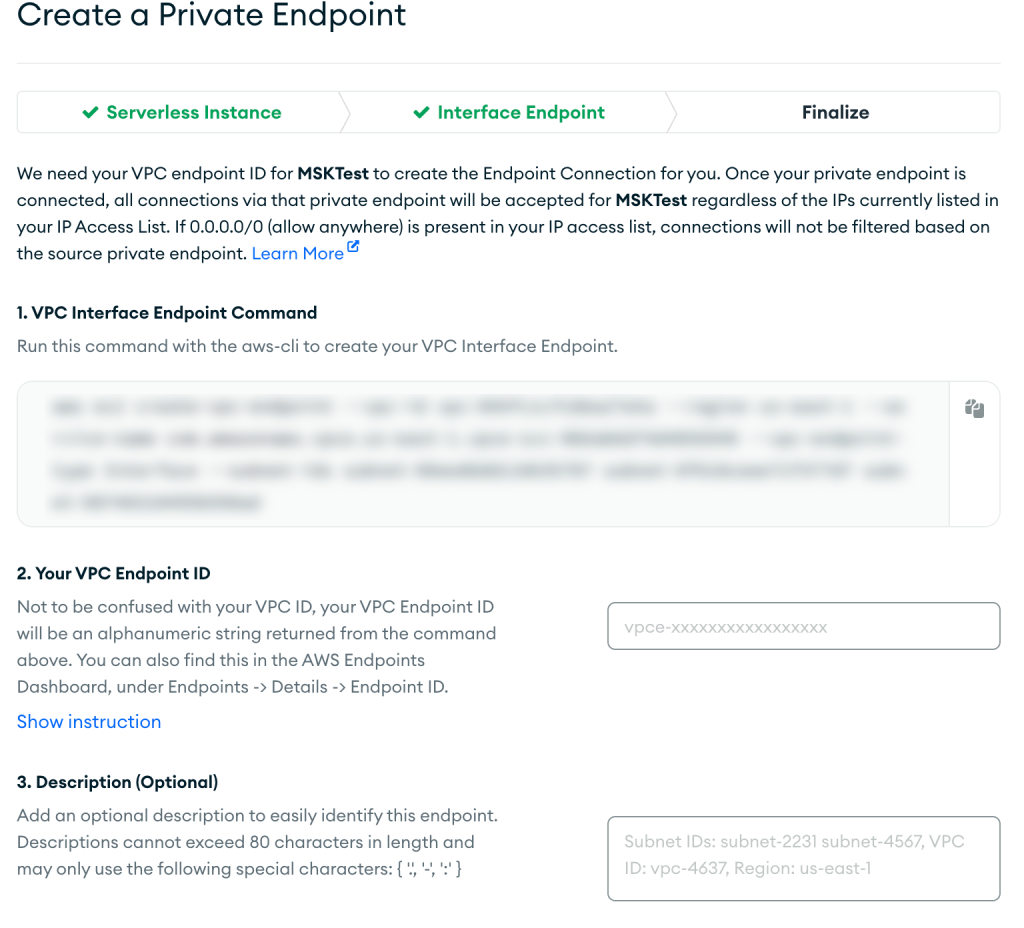
- Postępuj zgodnie z instrukcjami na Sfinalizować stronę, a następnie wybierz Potwierdzać po utworzeniu punktu końcowego VPC.
Po pomyślnym zakończeniu nowy prywatny punkt końcowy zostanie wyświetlony na liście, jak pokazano na poniższym zrzucie ekranu.
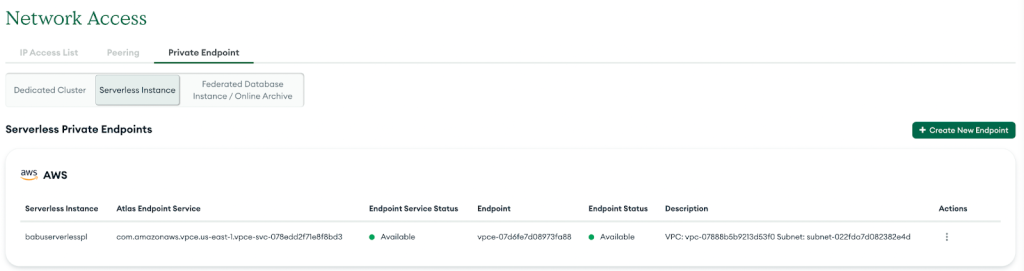
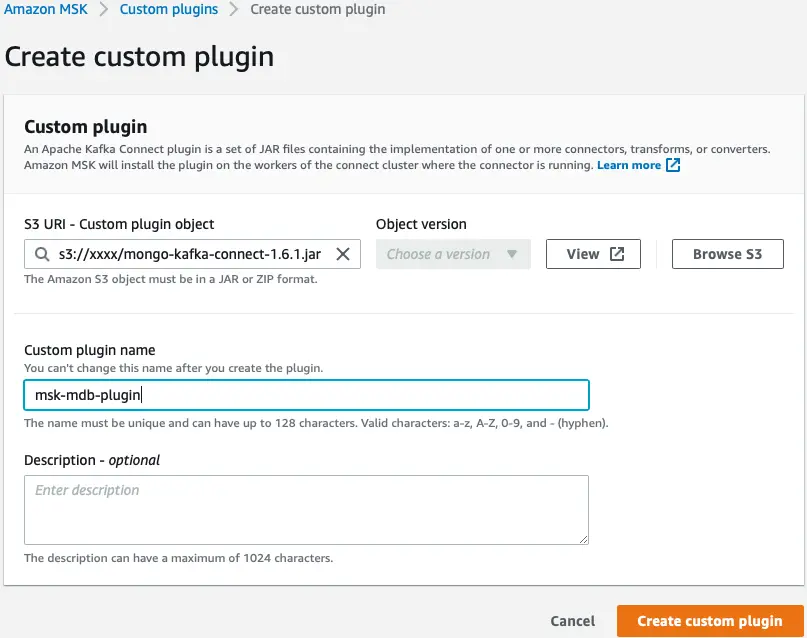
Skonfiguruj wtyczkę MSK
Następnie tworzymy niestandardową wtyczkę w Amazon MSK przy użyciu złącza MongoDB dla Apache Kafka. Złącze należy przesłać do pliku Usługa Amazon Simple Storage (Amazon S3), zanim będziesz mógł utworzyć wtyczkę. Aby pobrać złącze MongoDB dla Apache Kafka, zobacz Pobierz plik JAR oprogramowania sprzęgającego.
- W konsoli Amazon MSK wybierz Dostosowane wtyczki w okienku nawigacji.
- Dodaj Utwórz niestandardową wtyczkę.
- W razie zamówieenia projektu Identyfikator URI S3, wprowadź lokalizację S3 pobranego oprogramowania sprzęgającego.
- Dodaj Utwórz niestandardową wtyczkę.
Skonfiguruj klienta EC2
Następnie skonfigurujmy instancję EC2. Używamy tej instancji do tworzenia tematu i wstawiania danych do tematu. Aby uzyskać instrukcje, zapoznaj się z sekcją Skonfiguruj klienta EC2 w poście Integracja MongoDB z Amazon Managed Streaming dla Apache Kafka (MSK).
Utwórz temat w klastrze MSK
Aby utworzyć temat Kafki, musimy najpierw zainstalować Kafka CLI.
- Na instancji klienta EC2 najpierw zainstaluj Javę:
sudo yum install java-1.8.0
- Następnie uruchom następujące polecenie, aby pobrać Apache Kafka:
wget https://archive.apache.org/dist/kafka/2.6.2/kafka_2.12-2.6.2.tgz
- Rozpakuj plik tar za pomocą następującego polecenia:
tar -xzf kafka_2.12-2.6.2.tgz
Dystrybucja Kafki zawiera folder bin z narzędziami, które można wykorzystać do zarządzania tematami.
- Idź do
kafka_2.12-2.6.2katalog i wydaj następującą komendę, aby utworzyć temat Kafki w bezserwerowym klastrze MSK:
bin/kafka-topics.sh --create --topic sandbox_sync2 --bootstrap-server <BOOTSTRAP SERVER> --command-config=bin/client.properties --partitions 2
Możesz skopiować punkt końcowy serwera ładowania początkowego na Wyświetl informacje o kliencie strona dla bezserwerowego klastra MSK.
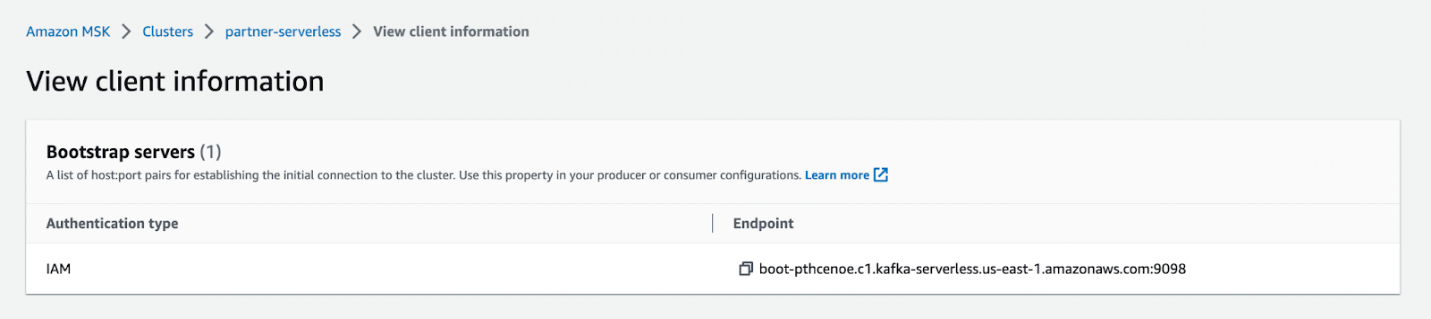
Uwierzytelnianie IAM można skonfigurować, postępując zgodnie z poniższymi instrukcjami instrukcje.
Skonfiguruj złącze zlewu
Teraz skonfigurujmy złącze ujścia, aby wysłać dane do instancji MongoDB Atlas Serverless.
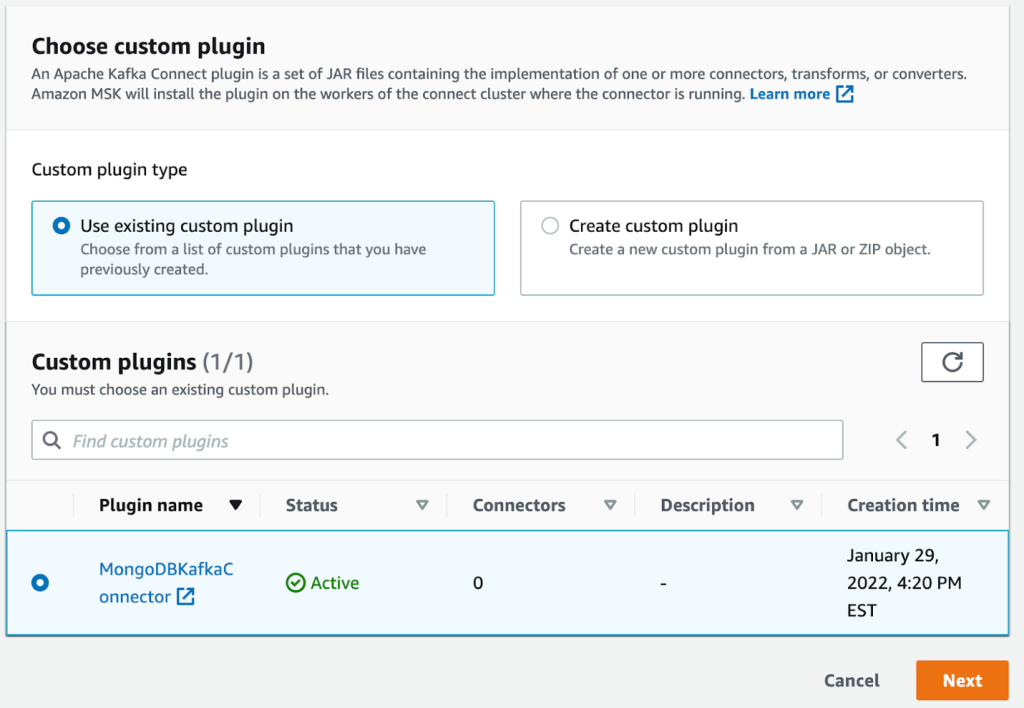
- W konsoli Amazon MSK wybierz Złącza w okienku nawigacji.
- Dodaj Utwórz łącznik.
- Wybierz wtyczkę, którą utworzyłeś wcześniej.
- Dodaj Następna.
- Wybierz utworzoną wcześniej bezserwerową instancję MSK.
- Wprowadź konfigurację połączenia jako następujący kod:
Upewnij się, że połączenie z instancją MongoDB Atlas Serverless odbywa się przez AWS PrivateLink. Aby uzyskać więcej informacji, patrz Bezpieczne łączenie aplikacji z płaszczyzną danych MongoDB Atlas za pomocą AWS PrivateLink.
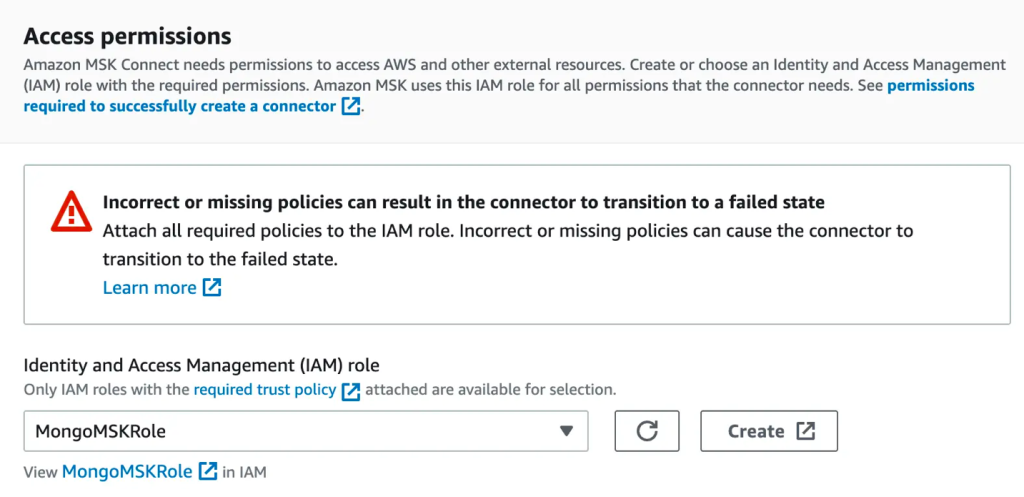
- W Uprawnienia dostępu sekcja, utwórz AWS Zarządzanie tożsamością i dostępem (IAM) rola z wymagana polityka zaufania.
- Dodaj Następna.
- Sprecyzować Dzienniki Amazon CloudWatch jako opcję dostarczania dziennika.
- Uzupełnij swoje złącze.
Gdy stan łącznika zmieni się na Aktywny, potok jest gotowy.

Wstaw dane do tematu MSK
Na swoim kliencie EC2 wstaw dane do tematu MSK przy użyciu kafka-console-producer w sposób następujący:
Aby zweryfikować, czy dane pomyślnie przepływają z tematu Kafki do bezserwerowego klastra MongoDB, używamy interfejsu MongoDB Atlas.

Jeśli napotkasz jakiekolwiek problemy, sprawdź pliki dziennika. W tym przykładzie użyliśmy CloudWatch do odczytania zdarzeń wygenerowanych z Amazon MSK i MongoDB Connector for Apache Kafka.

Sprzątać
Aby uniknąć naliczania przyszłych opłat, wyczyść utworzone zasoby. Najpierw usuń klaster MSK, łącznik i instancję EC2:
- W konsoli Amazon MSK wybierz Klastry w okienku nawigacji.
- Wybierz swój klaster i na Akcje menu, wybierz Usuń.
- Dodaj Złącza w okienku nawigacji.
- Wybierz swoje złącze i wybierz Usuń.
- Dodaj Dostosowane wtyczki w okienku nawigacji.
- Wybierz swoją wtyczkę i wybierz Usuń.
- Na konsoli Amazon EC2 wybierz Instancje w okienku nawigacji.
- Wybierz utworzoną instancję.
- Dodaj Stan instancji, A następnie wybierz Zakończ instancję.
- Na Amazon VPC konsola, wybierz Punkty końcowe w okienku nawigacji.
- Wybierz utworzony punkt końcowy i na Akcje menu, wybierz Usuń punkty końcowe VPC.
Teraz możesz usunąć klaster Atlas i AWS PrivateLink:
- Zaloguj się do konsoli klastra Atlas.
- Przejdź do klastra bezserwerowego, który ma zostać usunięty.
- Z rozwijanego menu opcji wybierz Zakończyć.
- Nawiguj do Dostęp do sieci
- Wybierz prywatny punkt końcowy.
- Wybierz instancję bezserwerową.
- Z rozwijanego menu opcji wybierz Zakończyć.

Podsumowanie
W tym poście pokazaliśmy, jak zbudować bezserwerowy potok przetwarzania strumieniowego przy użyciu MSK Serverless i MongoDB Atlas Serverless. Dzięki MSK Serverless możesz automatycznie udostępniać wymagane zasoby i zarządzać nimi w razie potrzeby. Użyliśmy łącznika MongoDB wdrożonego w MSK Connect, aby bezproblemowo zintegrować dwie usługi, a także użyliśmy klienta EC2 do wysłania przykładowych danych do tematu MSK. MSK Connect obsługuje teraz Prywatne nazwy hostów DNS, umożliwiając korzystanie z prywatnych nazw domen między usługami. W tym poście łącznik użył domyślnych serwerów DNS VPC do rozpoznania prywatnej nazwy DNS specyficznej dla strefy dostępności. Ta konfiguracja AWS PrivateLink umożliwiła bezpieczną i prywatną łączność między instancją MSK Serverless a instancją MongoDB Atlas Serverless.
Aby kontynuować naukę, zapoznaj się z następującymi zasobami:
O autorach

Igor Aleksiejew jest starszym architektem rozwiązań partnerskich w AWS w domenie Data and Analytics. W swojej roli Igor współpracuje ze strategicznymi partnerami, pomagając im budować złożone architektury zoptymalizowane pod kątem AWS. Przed dołączeniem do AWS jako Data/Solution Architect zrealizował wiele projektów w domenie Big Data, w tym kilka jezior danych w ekosystemie Hadoop. Jako Data Engineer był zaangażowany w zastosowanie AI/ML do wykrywania nadużyć i automatyzacji biura.
 Kiran Matty jest głównym menedżerem produktu w Amazon Web Services (AWS) i współpracuje z zespołem Amazon Managed Streaming for Apache Kafka (Amazon MSK) z siedzibą w Palo Alto w Kalifornii. Pasjonuje się tworzeniem wydajnych usług przesyłania strumieniowego i usług analitycznych, które pomagają przedsiębiorstwom realizować krytyczne przypadki użycia.
Kiran Matty jest głównym menedżerem produktu w Amazon Web Services (AWS) i współpracuje z zespołem Amazon Managed Streaming for Apache Kafka (Amazon MSK) z siedzibą w Palo Alto w Kalifornii. Pasjonuje się tworzeniem wydajnych usług przesyłania strumieniowego i usług analitycznych, które pomagają przedsiębiorstwom realizować krytyczne przypadki użycia.
 Babu Srinivasana jest starszym architektem rozwiązań partnerskich w MongoDB. W swojej obecnej roli współpracuje z AWS przy tworzeniu integracji technicznych i architektur referencyjnych dla rozwiązań AWS i MongoDB. Ma ponad dwudziestoletnie doświadczenie w technologiach baz danych i chmur. Pasjonuje się dostarczaniem rozwiązań technicznych klientom współpracującym z wieloma globalnymi integratorami systemów (GSI) w różnych regionach.
Babu Srinivasana jest starszym architektem rozwiązań partnerskich w MongoDB. W swojej obecnej roli współpracuje z AWS przy tworzeniu integracji technicznych i architektur referencyjnych dla rozwiązań AWS i MongoDB. Ma ponad dwudziestoletnie doświadczenie w technologiach baz danych i chmur. Pasjonuje się dostarczaniem rozwiązań technicznych klientom współpracującym z wieloma globalnymi integratorami systemów (GSI) w różnych regionach.
 Roberta Waltersa jest obecnie Senior Product Managerem w MongoDB. Przed MongoDB Rob spędził 17 lat w firmie Microsoft, pracując na różnych stanowiskach, w tym zarządzając programami w zespole SQL Server, konsultując i zajmując się przedsprzedażą techniczną. Rob jest współautorem trzech patentów dotyczących technologii używanych w SQL Server i był głównym autorem kilku książek technicznych na temat SQL Server. Rob jest obecnie aktywnym blogerem w MongoDB Blogs.
Roberta Waltersa jest obecnie Senior Product Managerem w MongoDB. Przed MongoDB Rob spędził 17 lat w firmie Microsoft, pracując na różnych stanowiskach, w tym zarządzając programami w zespole SQL Server, konsultując i zajmując się przedsprzedażą techniczną. Rob jest współautorem trzech patentów dotyczących technologii używanych w SQL Server i był głównym autorem kilku książek technicznych na temat SQL Server. Rob jest obecnie aktywnym blogerem w MongoDB Blogs.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/build-a-serverless-streaming-pipeline-with-amazon-msk-serverless-amazon-msk-connect-and-mongodb-atlas/
- 10
- 100
- 7
- a
- O nas
- dostęp
- odpowiednio
- w poprzek
- aktywny
- dodatek
- Po
- AI / ML
- pozwala
- Amazonka
- Amazon EC2
- Amazon Web Services
- Amazon Web Services (AWS)
- Analityczny
- analityka
- i
- Apache
- Apache Kafka
- aplikacje
- Stosowanie
- architektura
- Przybywa
- atlas
- Uwierzytelnianie
- autor
- zautomatyzowane
- automatycznie
- Automatyzacja
- dostępność
- dostępny
- AWS
- backup
- na podstawie
- podstawa
- staje się
- zanim
- BEST
- pomiędzy
- Duży
- Big Data
- blogi
- Książki
- Bootstrap
- budować
- Budowanie
- wybudowany
- California
- Pojemność
- Etui
- Zmiany
- Opłaty
- ZOBACZ
- Dodaj
- klient
- Chmura
- Grupa
- kod
- kolekcja
- kolekcje
- kompletny
- kompleks
- obliczać
- systemu
- Skontaktuj się
- połączenie
- Łączność
- Konsola
- consulting
- kontynuować
- Odpowiedni
- Koszty:
- Stwórz
- stworzony
- Tworzenie
- tworzenie
- krytyczny
- Aktualny
- Obecnie
- zwyczaj
- Klientów
- dane
- inżynier danych
- Baza danych
- lat
- Domyślnie
- dostawa
- wymagania
- wdrażane
- detale
- Wykrywanie
- Dialog
- 分配
- dns
- domena
- NAZWY DOMEN
- na dół
- pobieranie
- Wcześniej
- z łatwością
- Ekosystem
- umożliwiając
- szyfrowanie
- koniec końców
- Punkt końcowy
- inżynier
- Wchodzę
- przedsiębiorstwa
- Eter (ETH)
- wydarzenia
- przykład
- doświadczenie
- Korzyści
- filet
- Akta
- i terminów, a
- pływ
- Przepływy
- obserwuj
- następujący
- następujący sposób
- oszustwo
- wykrywanie oszustw
- od
- w pełni
- przyszłość
- wygenerowane
- geografie
- Globalne
- Hadoop
- pomoc
- pomoc
- tutaj
- Wysoki
- wysoko
- W jaki sposób
- How To
- HTML
- HTTPS
- IAM
- tożsamość
- wdrożenia
- realizowane
- in
- obejmuje
- Włącznie z
- Informacja
- Infrastruktura
- zainstalować
- przykład
- instrukcje
- integrować
- integracja
- integracje
- zainteresowany
- zaangażowany
- problem
- problemy
- IT
- Java
- łączący
- kafka
- Klawisz
- prowadzić
- nauka
- Lista
- lokalizacja
- robić
- WYKONUJE
- zarządzanie
- zarządzane
- i konserwacjami
- kierownik
- wiele
- Menu
- Metryka
- Microsoft
- minimalny
- MongoDB
- jeszcze
- wielokrotność
- Nazwa
- Nazwy
- Nawigacja
- Potrzebować
- wymagania
- sieć
- Dostęp do sieci
- sieci
- Nowości
- Biurowe
- Option
- Opcje
- Palo Alto
- chleb
- partnerem
- wzmacniacz
- namiętny
- Patenty
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- rurociąg
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- wtyczka
- Post
- poprzedni
- Główny
- Wcześniejszy
- prywatny
- wygląda tak
- Produkt
- product manager
- Program
- projektowanie
- niska zabudowa
- zapewniać
- zapewnia
- że
- zaopatrzenie
- cele
- Czytaj
- gotowy
- real
- w czasie rzeczywistym
- zrealizować
- dokumentacja
- niezawodność
- wymagany
- Zasób
- Zasoby
- ROBERT
- Rola
- role
- run
- taki sam
- Skala
- waga
- płynnie
- Sekcja
- bezpieczne
- bezpiecznie
- bezpieczeństwo
- senior
- Bezserwerowe
- usługa
- Usługi
- w panelu ustawień
- kilka
- pokazać
- pokazane
- Prosty
- Rozmiar
- rozwiązanie
- Rozwiązania
- Źródło
- Źródła
- spędził
- SQL
- rozpoczęty
- rozpocznie
- Rynek
- Cel
- przechowywanie
- Strategiczny
- Partnerzy strategiczni
- Streaming
- podsieci
- podsieci
- sukces
- Z powodzeniem
- taki
- podpory
- system
- zadania
- zespół
- Techniczny
- Technologies
- Połączenia
- ich
- trzy
- Przez
- czas
- do
- narzędzia
- aktualny
- tematy
- Zaufaj
- Tutorial
- ui
- uaktualnienie
- przesłanych
- posługiwać się
- wartość
- różnorodny
- zweryfikować
- przez
- sieć
- usługi internetowe
- będzie
- w ciągu
- przepływów pracy
- pracujący
- działa
- lat
- Twój
- zefirnet
- Strefy